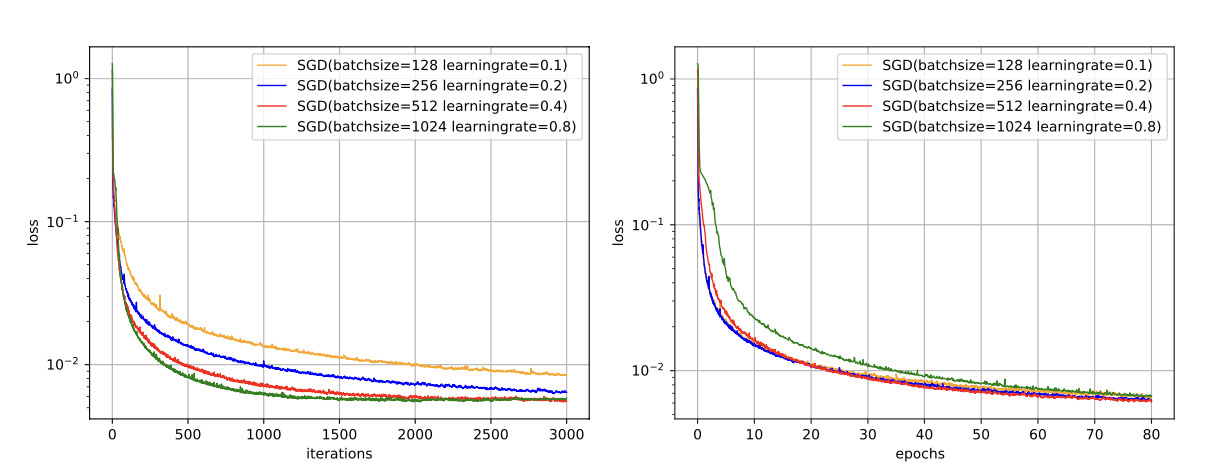
从代码实现理解Vision Permutator:WeightedPermuteMLP模型解析
随着人工智能的快速发展,视觉识别任务变得越来越重要。最近提出的Vision Permutator架构为这一领域带来了新的思路,它通过可学习的排列操作重新定义了特征交互的方式。
今天我们将深入解析Vision Permutator的核心组件——WeightedPermuteMLP模块,并通过代码实现来理解它的设计思想和工作原理。
Vision Permutator概述
传统的视觉模型大多基于CNN或Transformer架构。Vision Permutator提出了一种全新的网络结构,通过可学习的排列操作替代了传统模型中的池化和卷积操作。这种创新的设计显著提升了模型性能,同时降低了计算复杂度。
在论文《Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition》中,研究者提出了基于MLP的 Vision Transformer 替代方案——Permute MLP。该架构通过参数化排列实现了全局特征交互,从而达到了与Transformer相当或更优的效果。
WeightedPermuteMLP代码解析
让我们先来看一下WeightedPermuteMLP类的具体实现:
class WeightedPermuteMLP(nn.Module):
def __init__(self,dim,seg_dim=8, qkv_bias=False, proj_drop=0.):
super().__init__()
self.seg_dim=seg_dim
self.mlp_c=nn.Linear(dim,dim,bias=qkv_bias)
self.mlp_h=nn.Linear(dim,dim,bias=qkv_bias)
self.mlp_w=nn.Linear(dim(dim,dim,bias=qkv_bias)
self.reweighting=MLP(dim,dim//4,dim*3)
self.proj=nn.Linear(dim,dim)
self.proj_drop=nn.Dropout(proj_drop)
def forward(self,x) :
B,H,W,C=x.shape
c_embed=self.mlp_c(x)
S=C//self.seg_dim
h_embed=x.reshape(B,H,W,self.seg_dim,S).permute(0,3,2,1,4).reshape(B,self.seg_dim,W,H*S)
h_embed=self.mlp_h(h_embed).reshape(B,self.seg_dim,W,H,S).permute(0,3,2,1,4).reshape(B,H,W,C)
w_embed=x.reshape(B,H,W,self.seg_dim,S).permute(0,3,1,2,4).reshape(B,self.seg_dim,H,W*S)
w_embed=self.mlp_w(w_embed).reshape(B,self.seg_dim,H,W,S).permute(0,2,3,1,4).reshape(B,H,W,C)
weight=(c_embed+h_embed+w_embed).permute(0,3,1,2).flatten(2).mean(2)
weight=self.reweighting(weight).reshape(B,C,3).permute(2,0,1).softmax(0).unsqueeze(2).unsqueeze(2)
x=c_embed*weight[0]+w_embed*weight[1]+h_embed*weight[2]
x=self.proj_drop(self.proj(x))
return x
模块初始化
在__init__方法中:
mlp_c,mlp_h,mlp_w分别对应channel、height、width方向的MLP层。reweighting模块用于对不同方向的特征进行重新加权。- 最后通过一个投影层和Dropout完成最终的输出计算。
前向传播过程
-
特征提取:
- 通过三个不同的MLP分别提取channel、height、width方向的特征。
-
权重计算:
- 将不同方向的特征进行叠加,经过flatten和平均池化操作后输入到reweighting模块,得到每个通道的三组权重。
- 使用softmax对权重进行归一化处理。
-
加权合并:
- 根据计算出的三个权重值,将channel、width、height方向的特征按比例相加,融合得到最终的输出特征。
-
投影输出:
- 通过线性变换将特征维度恢复到原始维度,并应用Dropout防止过拟合。
实验验证
我们可以通过以下代码进行简单的实验验证:
if __name__ == '__main__':
input=torch.randn(64,8,8,512)
seg_dim=8
block=WeightedPermuteMLP(512,seg_dim)
out=block(input)
print(out.shape) # 输出: torch.Size([64, 8, 8, 512])
从实验输出可以看到,模型成功保持了输入的尺寸不变,即在不改变特征图尺寸的情况下实现了特征的非线性变换和全局交互。
总结与展望
WeightedPermuteMLP模块通过创新性的思路,将特征交互的方式从简单的通道加法转变为基于权重的自适应融合。这种设计思想既降低了计算复杂度,又提升了模型性能。
对于未来的研究,我们可以关注以下几个方向:
- 多尺度特征融合:尝试在不同尺度上应用类似的设计思想。
- 动态权重调整:研究如何进一步提升权重的自适应能力。
- 轻量化设计:探索减少计算量的方法,使模型能够部署到更多场景。
Vision Permutator给我们展示了一种全新的思考方式,在特征交互和网络架构设计方面提供了新的视角。相信随着研究的深入,还会有更多的创新和突破涌现出来。


![[原理分析]安卓15系统大升级:Doze打盹模式提速50%,续航大幅增强,省电提升率5%](https://i-blog.csdnimg.cn/direct/bb1d0fc65b0d41879deda6c772486111.png)