理论学习地址:
https://zh.d2l.ai/chapter_linear-networks/index.html
autodl学术加速:
source /etc/network_turbo
conda常见操作:
删除:
conda remove --name myenv --all -y
导出:
conda env export > environment.yml
导入:
conda env create -f environment.yml
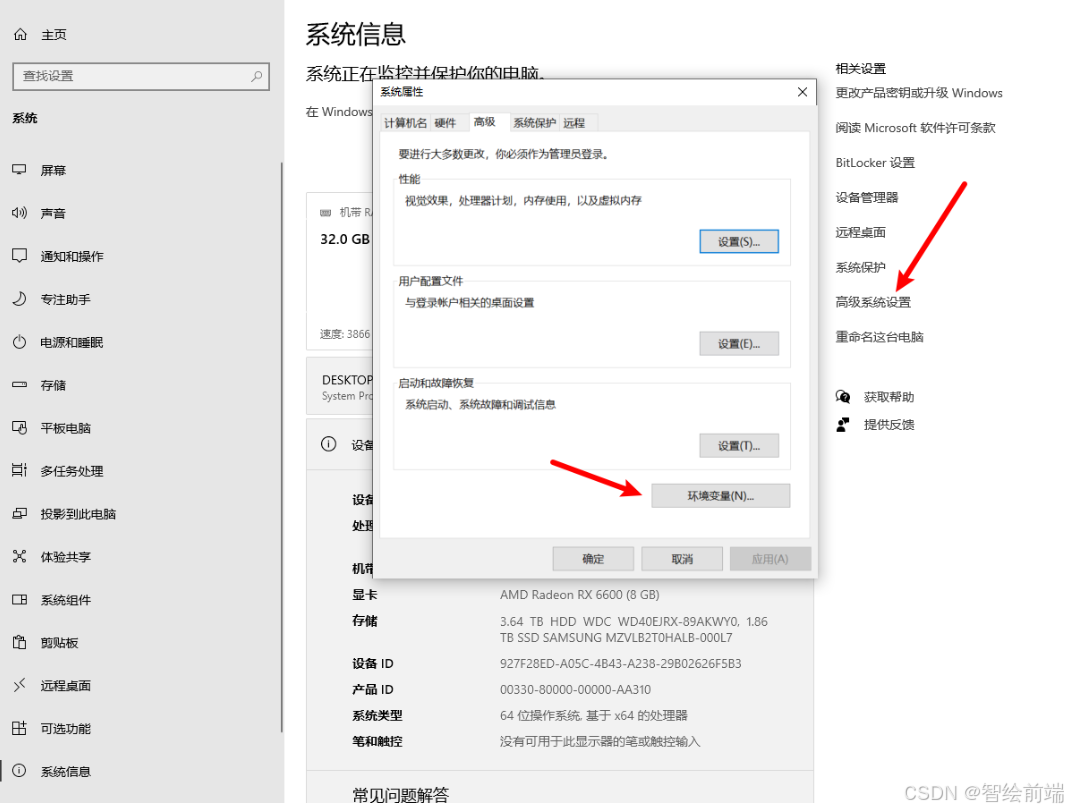
修改安装虚拟环境目录和包缓存目录
修改配置:
conda config --add envs_dirs /root/autodl-tmp/conda/envs
conda config --add pkgs_dirs /root/autodl-tmp/conda/pkgs
验证配置是否生效:
conda config --show | grep -A 2 "envs_dirs"
conda config --show | grep -A 2 "pkgs_dirs"
修改.bashrc
root@autodl-container-271149a41f-a69b11b9:~# which conda
/root/miniconda3/bin/conda
vi ~/.bashrc
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/root/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/path/to/conda/etc/profile.d/conda.sh" ]; then
. "/path/to/conda/etc/profile.d/conda.sh"
else
export PATH="/path/to/conda/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
conda activate opencompass
source ~/.bashrc
换源:
-i https://pypi.mirrors.ustc.edu.cn/simple/
测试专用代码:
pip install openai
#多轮对话
from openai import OpenAI
#定义多轮对话方法
def run_chat_session():
#初始化客户端
client = OpenAI(base_url="http://localhost:23333/v1/",api_key="suibianxie")
#初始化对话历史
chat_history = []
#启动对话循环
while True:
#获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
#更新对话历史(添加用户输入)
chat_history.append({"role":"user","content":user_input})
#调用模型回答
try:
chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/model/Qwen/Qwen2.5-1.5B-Instruct")
#获取最新回答
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
#更新对话历史(添加AI模型的回复)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()
ptorch:
https://pytorch.org/
cuda12.4:
ubuntu:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 -i https://pypi.mirrors.ustc.edu.cn/simple/
cudacu121:
win:
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 -f https://mirrors.aliyun.com/pytorch-wheels/cu121
cuda11.8:
win:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118 -i https://pypi.mirrors.ustc.edu.cn/simple/
WSL:
【超详细的WSL教程:Windows上的Linux子系统】 https://www.bilibili.com/video/BV1tW42197za/?share_source=copy_web&vd_source=5260dbbb879acb9193fb2e7261e27631
常见对话生成数据集:
【对话生成】常见对话生成数据集整理,含下载链接(更新至2022.06.04)_日常对话得训练数据集-CSDN博客
大模型平台:
huggingface:
官网:
https://huggingface.co/
dataset(nlp):
https://huggingface.co/docs/datasets/quickstart#nlp
魔塔:
概览 · 魔搭社区
pip install modelscope
下载模型:
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct
下载单个文件:
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct README.md --local_dir ./dir
sdk下载:
#模型下载
from modelscope import snapshot_download
cache_dir="/root/autodl-tmp/model"
model_dir = snapshot_download('Qwen/Qwen2.5-1.5B-Instruct',cache_dir=cache_dir)
langchain:
中文文档:
LangChain 介绍 | 🦜️🔗 Langchain
pipo算力云(API调用)
https://ppinfra.com/invitation
推理部署框架:
ollama
Ollama
配置环境
下载:
curl -fsSL https://ollama.com/install.sh | sh
启动:
ollama serve
运行:
ollama run ollama run qwen2.5:0.5b
运行自定义gguf:
创建ModelFile:
ModelFile内容如下:
#GGUF文件路径
FROM /root/autodl-tmp/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct-gguf8.gguf
创建自定义模型:
ollama create zyhhsss --file ./ModeFile
运行:
ollama run zyhhsss
删除:
ollama list
ollama rm zyhhsss
安装命令解释:
1. 命令的作用
(a) curl 部分
curl 是一个命令行工具,用于从指定的 URL 下载内容。
参数解释:
-f: 如果请求失败(例如 HTTP 状态码为 404 或 500),则不输出错误信息到终端。
-s: 静默模式,不显示进度条或错误信息。
-S: 在静默模式下,如果发生错误,仍然显示错误信息。
-L: 如果遇到重定向(如 301 或 302),自动跟随新的地址。
组合起来,-fsSL 表示“安静地下载文件,并处理重定向”。
https://ollama.com/install.sh:这是脚本的下载地址。curl 将从这个 URL 下载脚本的内容。
(b) | sh 部分
| 是管道符号,表示将 curl 的输出直接传递给下一个命令。
sh 是一个 Shell 解释器,用于执行从 curl 下载的脚本内容。
整体来说,这条命令的含义是:
使用 curl 从 https://ollama.com/install.sh 下载脚本。
将脚本内容通过管道传递给 sh,实时执行脚本中的命令。
2. 脚本会做什么?
运行此命令后,脚本的内容会直接影响您的系统。通常情况下,这种安装脚本可能会执行以下操作:
检查系统的环境(如操作系统、架构等)。
下载必要的二进制文件或依赖项。
安装软件到特定位置(如 /usr/local/bin 或 /opt)。
创建快捷方式或配置文件。
添加服务或设置环境变量。
具体行为取决于 install.sh 脚本的内容。
3. 风险与注意事项
虽然这种“一键安装”方式非常方便,但也存在一定的风险。以下是一些需要注意的事项:
(a) 脚本来源是否可信
您正在从 https://ollama.com/install.sh 下载脚本并直接执行,这意味着脚本的内容完全决定了它对您的系统的影响。
如果脚本被恶意篡改,可能会导致安全问题(如安装恶意软件、窃取数据等)。
建议:
在运行之前,先检查脚本的内容。例如:
bash
浅色版本
curl -fsSL https://ollama.com/install.sh | less
这会将脚本内容输出到终端供您查看。确认无误后再运行。
(b) 是否需要管理员权限
如果脚本需要写入系统目录(如 /usr/local/bin),可能需要使用 sudo 提升权限:
bash
浅色版本
curl -fsSL https://ollama.com/install.sh | sudo sh
注意:使用 sudo 运行脚本时要格外小心,因为它会以超级用户权限执行所有命令。
(c) 日志记录
为了便于排查问题,可以将脚本的输出保存到日志文件中:
bash
浅色版本
curl -fsSL https://ollama.com/install.sh | sh > install.log 2>&1
这样,所有输出(包括标准输出和错误信息)都会被记录到 install.log 文件中。
4. 替代方法:手动下载并检查脚本
如果您希望更安全地执行此操作,可以采用以下步骤:
(a) 手动下载脚本
使用 curl 或 wget 下载脚本到本地:
bash
浅色版本
curl -fsSL https://ollama.com/install.sh -o install.sh
(b) 检查脚本内容
使用文本编辑器或查看工具检查脚本内容:
bash
浅色版本
less install.sh
(c) 执行脚本
确认脚本无误后,再运行它:
bash
浅色版本
sh install.sh
或者使用 chmod 赋予执行权限后运行:
bash
浅色版本
chmod +x install.sh
./install.sh
5. 总结
curl -fsSL https://ollama.com/install.sh | sh 是一种快速下载并执行脚本的方式。
它的本质是从远程服务器获取脚本内容,并通过 sh 实时执行。
优点:简单快捷。
缺点:存在潜在的安全风险,尤其是当脚本来源不可信时。
建议:在运行之前检查脚本内容,确保其来源可信,并根据需要记录日志以便排查问题。
vllm
欢迎使用 vLLM — vLLM 文档
对话模板
OpenAI 兼容服务器 — vLLM 文档
指定jinja2文件启动:
vllm serve <model> --chat-template ./path-to-chat-template.jinja
lmdeploy
欢迎来到 LMDeploy 的中文教程! — lmdeploy
安装:
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install lmdeploy
pip install partial-json-parser
打开cli:
lmdeploy serve api_server /root/autodl-tmp/model/Qwen/Qwen2.5-1.5B-Instruct --server-port 23333 --model-name zyhhsss
对话模板
自定义对话模板 — lmdeploy
lmdeploy官方标准json
{
"model_name": "your awesome chat template name",
"system": "<|im_start|>system\n",
"meta_instruction": "You are a robot developed by LMDeploy.",
"eosys": "<|im_end|>\n",
"user": "<|im_start|>user\n",
"eoh": "<|im_end|>\n",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": "\n",
"capability": "chat",
"stop_words": ["<|im_end|>"]
}
json格式:
lmdeploy serve api_server model --chat-template ${JSON_FILE}
并行推理:
推荐使用 Key-Value(KV) Cache 量化
lmdeploy serve api_server internlm/internlm2_5-7b-chat --quant-policy 8
turbomind加速:
启动模型:
lmdeploy serve api_server /root/autodl-tmp/model/Qwen/Qwen2.5-1.5B-Instruct --server-port 23333
turbomind加速:
lmdeploy chat modelname
lmdeploy chat turbomind aaa --model-name bbb
模型转换:
lmdeploy convert 模型coinfig中的name huggingface的模型路径
生成的ws在命令执行的位置
environment.yml
env+cuda12.4
Ubuntu:
name: lmdeploy
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- _openmp_mutex=5.1=1_gnu
- bzip2=1.0.8=h5eee18b_6
- ca-certificates=2025.2.25=h06a4308_0
- ld_impl_linux-64=2.40=h12ee557_0
- libffi=3.4.4=h6a678d5_1
- libgcc-ng=11.2.0=h1234567_1
- libgomp=11.2.0=h1234567_1
- libstdcxx-ng=11.2.0=h1234567_1
- libuuid=1.41.5=h5eee18b_0
- ncurses=6.4=h6a678d5_0
- openssl=3.0.16=h5eee18b_0
- pip=25.0=py310h06a4308_0
- python=3.10.16=he870216_1
- readline=8.2=h5eee18b_0
- setuptools=75.8.0=py310h06a4308_0
- sqlite=3.45.3=h5eee18b_0
- tk=8.6.14=h39e8969_0
- tzdata=2025a=h04d1e81_0
- wheel=0.45.1=py310h06a4308_0
- xz=5.6.4=h5eee18b_1
- zlib=1.2.13=h5eee18b_1
- pip:
- accelerate==1.5.2
- addict==2.4.0
- aiosignal==1.3.2
- airportsdata==20250224
- annotated-types==0.7.0
- anyio==4.9.0
- attrs==25.3.0
- certifi==2025.1.31
- cfgv==3.4.0
- charset-normalizer==3.4.1
- click==8.1.8
- cloudpickle==3.1.1
- diskcache==5.6.3
- distlib==0.3.9
- distro==1.9.0
- einops==0.8.1
- exceptiongroup==1.2.2
- fastapi==0.115.12
- filelock==3.18.0
- fire==0.7.0
- frozenlist==1.5.0
- fsspec==2025.3.0
- genson==1.3.0
- h11==0.14.0
- httpcore==1.0.7
- httpx==0.28.1
- huggingface-hub==0.29.3
- identify==2.6.9
- idna==3.10
- interegular==0.3.3
- iso3166==2.1.1
- jinja2==3.1.6
- jiter==0.9.0
- jsonschema==4.23.0
- jsonschema-specifications==2024.10.1
- lark==1.2.2
- lmdeploy==0.7.2.post1
- markdown-it-py==3.0.0
- markupsafe==3.0.2
- mdurl==0.1.2
- mmengine-lite==0.10.7
- mpmath==1.3.0
- msgpack==1.1.0
- nest-asyncio==1.6.0
- networkx==3.4.2
- nodeenv==1.9.1
- numpy==1.26.4
- nvidia-cublas-cu12==12.4.5.8
- nvidia-cuda-cupti-cu12==12.4.127
- nvidia-cuda-nvrtc-cu12==12.4.127
- nvidia-cuda-runtime-cu12==12.4.127
- nvidia-cudnn-cu12==9.1.0.70
- nvidia-cufft-cu12==11.2.1.3
- nvidia-curand-cu12==10.3.5.147
- nvidia-cusolver-cu12==11.6.1.9
- nvidia-cusparse-cu12==12.3.1.170
- nvidia-ml-py==12.570.86
- nvidia-nccl-cu12==2.21.5
- nvidia-nvjitlink-cu12==12.4.127
- nvidia-nvtx-cu12==12.4.127
- openai==1.69.0
- outlines==0.2.1
- outlines-core==0.1.26
- packaging==24.2
- partial-json-parser==0.2.1.1.post5
- peft==0.14.0
- pillow==11.1.0
- platformdirs==4.3.7
- pre-commit==4.2.0
- protobuf==6.30.2
- psutil==7.0.0
- pydantic==2.11.1
- pydantic-core==2.33.0
- pygments==2.19.1
- pynvml==12.0.0
- pyyaml==6.0.2
- ray==2.44.1
- referencing==0.36.2
- regex==2024.11.6
- requests==2.32.3
- rich==13.9.4
- rpds-py==0.24.0
- safetensors==0.5.3
- sentencepiece==0.2.0
- shortuuid==1.0.13
- sniffio==1.3.1
- starlette==0.46.1
- sympy==1.13.1
- termcolor==2.5.0
- tiktoken==0.9.0
- tokenizers==0.21.1
- tomli==2.2.1
- torch==2.5.1
- torchvision==0.20.1
- tqdm==4.67.1
- transformers==4.50.3
- triton==3.1.0
- typing-extensions==4.13.0
- typing-inspection==0.4.0
- urllib3==2.3.0
- uvicorn==0.34.0
- virtualenv==20.29.3
- yapf==0.43.0
prefix: /root/miniconda3/envs/lmdeploy
win11:
微调框架:
Llamafactory:
端口:7860
LLaMA-Factory/README_zh.md at main · hiyouga/LLaMA-Factory
conda:
conda create -n llamafactory python=3.10 -y
conda activate llamafactory
conda remove --name myenv --all
版本冲突:
解决一:
pip install -e .
pip install gradio==5.23.1
pip install bitsandbytes==0.45.3
pip install peft ==0.12.0
DISABLE_VERSION_CHECK=1 llamafactory-cli webui
解决二:
bitsandbytes=0.44.0
accelerate=1.1.1
peft= 0.12.0
transformers=4.49.0
torch=2.5.1
解决三:
docker
解决四:用requirement.txt/environment.yml
git:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
推荐使用:
pip install -e .
bug!!!!
这个包(gradio)解析json有问题:
5.23.1这个版本可以但是原文中里面提示:5.21.0却不行
pip install --force-reinstall gradio==5.21.0
pip install --upgrade gradio
使用flashattn2加速:
pip install bitsandbytes==0.43.3
启动:
(llmdeploy) root@autodl-container-2fb0448cad-36aa5df2:~/autodl-tmp/LLaMA-Factory/LLaMA-Factory# llamafactory-cli
----------------------------------------------------------------------
| Usage: |
| llamafactory-cli api -h: launch an OpenAI-style API server |
| llamafactory-cli chat -h: launch a chat interface in CLI |
| llamafactory-cli eval -h: evaluate models |
| llamafactory-cli export -h: merge LoRA adapters and export model |
| llamafactory-cli train -h: train models |
| llamafactory-cli webchat -h: launch a chat interface in Web UI |
| llamafactory-cli webui: launch LlamaBoard |
| llamafactory-cli version: show version info |
----------------------------------------------------------------------
llamafactory-cli webui
注意:
在 Python 项目中,setup.py 文件通常会包含两个主要部分来定义依赖项:
install_requires:
这是项目运行所必需的基础依赖。
这些依赖项会在你运行 pip install . 或 pip install -e . 时被安装。
extras_require:
这是项目的可选依赖组(如 torch、metrics 等)。
这些依赖项只有在明确指定时才会被安装,例如通过 pip install -e ".[torch,metrics]"。
environment.yml
ubuntu+cuda12.4
name: llamafactory
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- _openmp_mutex=5.1=1_gnu
- bzip2=1.0.8=h5eee18b_6
- ca-certificates=2025.2.25=h06a4308_0
- ld_impl_linux-64=2.40=h12ee557_0
- libffi=3.4.4=h6a678d5_1
- libgcc-ng=11.2.0=h1234567_1
- libgomp=11.2.0=h1234567_1
- libstdcxx-ng=11.2.0=h1234567_1
- libuuid=1.41.5=h5eee18b_0
- ncurses=6.4=h6a678d5_0
- openssl=3.0.16=h5eee18b_0
- pip=25.0=py310h06a4308_0
- python=3.10.16=he870216_1
- readline=8.2=h5eee18b_0
- setuptools=75.8.0=py310h06a4308_0
- sqlite=3.45.3=h5eee18b_0
- tk=8.6.14=h39e8969_0
- wheel=0.45.1=py310h06a4308_0
- xz=5.6.4=h5eee18b_1
- zlib=1.2.13=h5eee18b_1
- pip:
- accelerate==1.4.0
- aiofiles==23.2.1
- aiohappyeyeballs==2.6.1
- aiohttp==3.11.14
- aiosignal==1.3.2
- annotated-types==0.7.0
- anyio==4.9.0
- async-timeout==5.0.1
- attrs==25.3.0
- audioread==3.0.1
- av==14.2.0
- bitsandbytes==0.45.3
- certifi==2025.1.31
- cffi==1.17.1
- charset-normalizer==3.4.1
- click==8.1.8
- contourpy==1.3.1
- cycler==0.12.1
- datasets==3.3.2
- decorator==5.2.1
- dill==0.3.8
- docstring-parser==0.16
- einops==0.8.1
- exceptiongroup==1.2.2
- fastapi==0.115.12
- ffmpy==0.5.0
- filelock==3.18.0
- fire==0.7.0
- fonttools==4.56.0
- frozenlist==1.5.0
- fsspec==2024.12.0
- gradio==5.23.1
- gradio-client==1.8.0
- groovy==0.1.2
- h11==0.14.0
- httpcore==1.0.7
- httpx==0.28.1
- huggingface-hub==0.29.3
- idna==3.10
- jinja2==3.1.6
- joblib==1.4.2
- kiwisolver==1.4.8
- lazy-loader==0.4
- librosa==0.11.0
- llamafactory==0.9.3.dev0
- llvmlite==0.44.0
- markdown-it-py==3.0.0
- markupsafe==2.1.5
- matplotlib==3.10.1
- mdurl==0.1.2
- mpmath==1.3.0
- msgpack==1.1.0
- multidict==6.2.0
- multiprocess==0.70.16
- networkx==3.4.2
- numba==0.61.0
- numpy==1.26.4
- nvidia-cublas-cu12==12.4.5.8
- nvidia-cuda-cupti-cu12==12.4.127
- nvidia-cuda-nvrtc-cu12==12.4.127
- nvidia-cuda-runtime-cu12==12.4.127
- nvidia-cudnn-cu12==9.1.0.70
- nvidia-cufft-cu12==11.2.1.3
- nvidia-curand-cu12==10.3.5.147
- nvidia-cusolver-cu12==11.6.1.9
- nvidia-cusparse-cu12==12.3.1.170
- nvidia-cusparselt-cu12==0.6.2
- nvidia-nccl-cu12==2.21.5
- nvidia-nvjitlink-cu12==12.4.127
- nvidia-nvtx-cu12==12.4.127
- orjson==3.10.16
- packaging==24.2
- pandas==2.2.3
- peft==0.15.1
- pillow==11.1.0
- platformdirs==4.3.7
- pooch==1.8.2
- propcache==0.3.1
- protobuf==6.30.2
- psutil==7.0.0
- pyarrow==19.0.1
- pycparser==2.22
- pydantic==2.11.1
- pydantic-core==2.33.0
- pydub==0.25.1
- pygments==2.19.1
- pyparsing==3.2.3
- python-dateutil==2.9.0.post0
- python-multipart==0.0.20
- pytz==2025.2
- pyyaml==6.0.2
- regex==2024.11.6
- requests==2.32.3
- rich==13.9.4
- ruff==0.11.2
- safehttpx==0.1.6
- safetensors==0.5.3
- scikit-learn==1.6.1
- scipy==1.15.2
- semantic-version==2.10.0
- sentencepiece==0.2.0
- shellingham==1.5.4
- shtab==1.7.1
- six==1.17.0
- sniffio==1.3.1
- soundfile==0.13.1
- soxr==0.5.0.post1
- sse-starlette==2.2.1
- starlette==0.46.1
- sympy==1.13.1
- termcolor==2.5.0
- threadpoolctl==3.6.0
- tiktoken==0.9.0
- tokenizers==0.21.0
- tomlkit==0.13.2
- torch==2.6.0
- tqdm==4.67.1
- transformers==4.49.0
- triton==3.2.0
- trl==0.9.6
- typer==0.15.2
- typing-extensions==4.13.0
- typing-inspection==0.4.0
- tyro==0.8.14
- tzdata==2025.2
- urllib3==2.3.0
- uvicorn==0.34.0
- websockets==15.0.1
- xxhash==3.5.0
- yarl==1.18.3
prefix: /root/miniconda3/envs/llamafactory
对话模板转jinjia2:
放在src/llamafactory/data目录下
import sys
import os
# 将项目根目录添加到 Python 路径
root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
sys.path.append(root_dir)
from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer
# 1. 初始化分词器(任意支持的分词器均可)
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/llm/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B")
# 2. 获取模板对象
template_name = "qwen" # 替换为你需要查看的模板名称
template = TEMPLATES[template_name]
# 3. 修复分词器的 Jinja 模板
template.fix_jinja_template(tokenizer)
# 4. 直接输出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)
Xtuner:
官网:
欢迎来到 XTuner 的中文文档 — XTuner 0.2.0rc0 文档
配置环境:
安装环境:
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
//conda env create -f environment.yml
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[deepspeed]' -i https://pypi.mirrors.ustc.edu.cn/simple/
版本冲突:
runtime.txt中
torch==2.5.1
torchvision==0.20.1
-
验证:
xtuner list-cfg
训练:
仅支持微调configs下的模型
见下方训练脚本
启动微调脚本
xtuner train internlm2_chat_1_8b_qlora_alpaca_e3.py --work-dir
模型转换为huggingface模型:
xtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${SAVE_PATH}
# 例如:xtuner convert pth_to_hf /root/autodl-tmp/xtuner-main/xtuner-main/jiaoben/qwen1_5_1_8b_chat_qlora_alpaca_e3.py /root/autodl-tmp/xtuner-main/xtuner-main/work_dirs/qwen1_5_1_8b_chat_qlora_alpaca_e3/iter_2500.pth /root/autodl-tmp/xtuner-main/xtu
ner-main/huggingface
lora/qlora进行模型合并:
xtuner convert merge ${基座模型} ${Huggingface模型} ${合并模型路径}
例如:
xtuner convert merge /root/autodl-tmp/model/Qwen/Qwen2.5-1.5B-Instruct /root/autodl-tmp/xtuner-main/xtuner-main/huggingface /root/autodl-tmp/xtuner-main/xtuner-main/merge
多卡并行:
# 以下命令根据需要任选其一
xtuner train xxx --deepspeed deepspeed_zero1
xtuner train xxx --deepspeed deepspeed_zero2
xtuner train xxx --deepspeed deepspeed_zero2_offload
xtuner train xxx --deepspeed deepspeed_zero3
xtuner train xxx --deepspeed deepspeed_zero3_offload
用下面这个多卡并行
NPROC_PER_NODE=${GPU_NUM} xtuner train ./config.py --deepspeed deepspeed_zero2
python脚本模板:
一共修改14个(最下面有个load权重)
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (
CheckpointHook,
DistSamplerSeedHook,
IterTimerHook,
LoggerHook,
ParamSchedulerHook,
)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (
DatasetInfoHook,
EvaluateChatHook,
VarlenAttnArgsToMessageHubHook,
)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
# pretrained_model_name_or_path = "Qwen/Qwen1.5-1.8B-Chat"
#基座模型 1
pretrained_model_name_or_path = "/root/autodl-tmp/model/Qwen/Qwen2.5-1.5B-Instruct"
use_varlen_attn = False
# Data 2
#
# data_files = [
# '/root/public/data/target_data_1.json',
# '/root/public/data/target_data_2.json',
# '/root/public/data/target_data_3.json'
# ]
data_files = '/root/autodl-tmp/xtuner-main/xtuner-main/data/output.json'#数据集
# 提示词模板 3
prompt_template = PROMPT_TEMPLATE.qwen_chat
# 长度 4
max_length = 512
pack_to_max_length = True
# parallel
sequence_parallel_size = 1
# Scheduler & Optimizer
# 优化器
# 批次 5
batch_size = 10 # per_device
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
# 最大轮次 6
max_epochs = 3000
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03
# 多少轮保存 7
save_steps = 500
# 最大保存数量 8
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)
# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
# 主观验证 9
evaluation_inputs = ["这只烤乳猪火出圈啦", "朕决定于今日称帝","珍爱生命,远离死亡"
,"吃书有助于消化知识"]
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
padding_side="right",
)
model = dict(
type=SupervisedFinetune,
use_varlen_attn=use_varlen_attn,
llm=dict(
type=AutoModelForCausalLM.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16,
# 微调方法 下面是qlora,用lora给注释掉 10
quantization_config=dict(
type=BitsAndBytesConfig,
# 四位
load_in_4bit=False,
# 八位
load_in_8bit=True,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
),
),
# lora配置 11
lora=dict(
type=LoraConfig,
r=64,
lora_alpha=128,
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
),
)
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
# dataset=dict(type=load_dataset, path=alpaca_en_path),
# 加载数据集 12
dataset=dict(type=load_dataset, path="json",data_files=data_files),
tokenizer=tokenizer,
max_length=max_length,
# 加载数据集匹配格式 13
dataset_map_fn=None,
template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn,
)
sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=alpaca_en,
sampler=dict(type=sampler, shuffle=True),
collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn),
)
#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
# 优化器相关 14
optim_wrapper = dict(
type=AmpOptimWrapper,
optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),
clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),
accumulative_counts=accumulative_counts,
loss_scale="dynamic",
dtype="float16",
)
# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [
dict(
type=LinearLR,
start_factor=1e-5,
by_epoch=True,
begin=0,
end=warmup_ratio * max_epochs,
convert_to_iter_based=True,
),
dict(
type=CosineAnnealingLR,
eta_min=0.0,
by_epoch=True,
begin=warmup_ratio * max_epochs,
end=max_epochs,
convert_to_iter_based=True,
),
]
# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)
#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [
dict(type=DatasetInfoHook, tokenizer=tokenizer),
dict(
type=EvaluateChatHook,
tokenizer=tokenizer,
every_n_iters=evaluation_freq,
evaluation_inputs=evaluation_inputs,
system=SYSTEM,
prompt_template=prompt_template,
),
]
if use_varlen_attn:
custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type=IterTimerHook),
# print log every 10 iterations.
logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),
# enable the parameter scheduler.
param_scheduler=dict(type=ParamSchedulerHook),
# save checkpoint per `save_steps`.
checkpoint=dict(
type=CheckpointHook,
by_epoch=False,
interval=save_steps,
max_keep_ckpts=save_total_limit,
),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type=DistSamplerSeedHook),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method="fork", opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend="nccl"),
)
# set visualizer
visualizer = None
# set log level
log_level = "INFO"
# load from which checkpoint
#15加载权重 load .pth文件夹
#ep:load_from = "path_to_pth"
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
# set log processor
log_processor = dict(by_epoch=False)
environment.yml
name: xtuner-env
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- _openmp_mutex=5.1=1_gnu
- bzip2=1.0.8=h5eee18b_6
- ca-certificates=2025.2.25=h06a4308_0
- ld_impl_linux-64=2.40=h12ee557_0
- libffi=3.4.4=h6a678d5_1
- libgcc-ng=11.2.0=h1234567_1
- libgomp=11.2.0=h1234567_1
- libstdcxx-ng=11.2.0=h1234567_1
- libuuid=1.41.5=h5eee18b_0
- ncurses=6.4=h6a678d5_0
- openssl=3.0.16=h5eee18b_0
- pip=25.0=py310h06a4308_0
- python=3.10.16=he870216_1
- readline=8.2=h5eee18b_0
- setuptools=75.8.0=py310h06a4308_0
- sqlite=3.45.3=h5eee18b_0
- tk=8.6.14=h39e8969_0
- wheel=0.45.1=py310h06a4308_0
- xz=5.6.4=h5eee18b_1
- zlib=1.2.13=h5eee18b_1
- pip:
- accelerate==1.6.0
- addict==2.4.0
- aiohappyeyeballs==2.6.1
- aiohttp==3.11.16
- aiosignal==1.3.2
- annotated-types==0.7.0
- async-timeout==5.0.1
- attrs==25.3.0
- bitsandbytes==0.45.0
- certifi==2025.1.31
- charset-normalizer==3.4.1
- contourpy==1.3.1
- cycler==0.12.1
- datasets==3.5.0
- deepspeed==0.16.2
- dill==0.3.8
- einops==0.8.1
- et-xmlfile==2.0.0
- filelock==3.18.0
- fonttools==4.57.0
- frozenlist==1.5.0
- fsspec==2024.12.0
- hjson==3.1.0
- huggingface-hub==0.30.1
- idna==3.10
- imageio==2.37.0
- jinja2==3.1.6
- kiwisolver==1.4.8
- lazy-loader==0.4
- loguru==0.7.3
- markdown-it-py==3.0.0
- markupsafe==3.0.2
- matplotlib==3.10.1
- mdurl==0.1.2
- mmengine==0.10.6
- modelscope==1.25.0
- mpi4py-mpich==3.1.5
- mpmath==1.3.0
- msgpack==1.1.0
- multidict==6.3.2
- multiprocess==0.70.16
- networkx==3.4.2
- ninja==1.11.1.4
- numpy==2.2.4
- nvidia-cublas-cu12==12.4.5.8
- nvidia-cuda-cupti-cu12==12.4.127
- nvidia-cuda-nvrtc-cu12==12.4.127
- nvidia-cuda-runtime-cu12==12.4.127
- nvidia-cudnn-cu12==9.1.0.70
- nvidia-cufft-cu12==11.2.1.3
- nvidia-curand-cu12==10.3.5.147
- nvidia-cusolver-cu12==11.6.1.9
- nvidia-cusparse-cu12==12.3.1.170
- nvidia-nccl-cu12==2.21.5
- nvidia-nvjitlink-cu12==12.4.127
- nvidia-nvtx-cu12==12.4.127
- opencv-python==4.11.0.86
- openpyxl==3.1.5
- packaging==24.2
- pandas==2.2.3
- peft==0.15.1
- pillow==11.1.0
- platformdirs==4.3.7
- propcache==0.3.1
- psutil==7.0.0
- py-cpuinfo==9.0.0
- pyarrow==19.0.1
- pydantic==2.11.2
- pydantic-core==2.33.1
- pygments==2.19.1
- pyparsing==3.2.3
- python-dateutil==2.9.0.post0
- pytz==2025.2
- pyyaml==6.0.2
- regex==2024.11.6
- requests==2.32.3
- rich==14.0.0
- safetensors==0.5.3
- scikit-image==0.25.2
- scipy==1.15.2
- sentencepiece==0.2.0
- six==1.17.0
- sympy==1.13.1
- termcolor==3.0.1
- tifffile==2025.3.30
- tiktoken==0.9.0
- tokenizers==0.21.1
- tomli==2.2.1
- torch==2.5.1
- torchvision==0.20.1
- tqdm==4.67.1
- transformers==4.48.0
- transformers-stream-generator==0.0.5
- triton==3.1.0
- typing-extensions==4.13.1
- typing-inspection==0.4.0
- tzdata==2025.2
- urllib3==2.3.0
- xxhash==3.5.0
- yapf==0.43.0
- yarl==1.18.3
prefix: /root/miniconda3/envs/xtuner-env
评测模型的工具:
OpenCompass:
官方:https://doc.opencompass.org.cn/get_started/installation.html
中文:https://opencompass.readthedocs.io/zh-cn/latest/get_started/installation.html
评估一个模型一般要评估两个数据集:
一、开源的数据集评估(评估通用能力)
二、自定义数据集评估(评估定制化能力)
配置环境:
本文用的 0.4.2
conda create --name opencompass python=3.10 -y
# conda create --name opencompass_lmdeploy python=3.10 -y
conda activate opencompass
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e .
下载数据集:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
把数据集放在代码的data目录下
(数据解压就是data文件夹)
environment.yml
name: opencompass
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- _openmp_mutex=5.1=1_gnu
- bzip2=1.0.8=h5eee18b_6
- ca-certificates=2025.2.25=h06a4308_0
- ld_impl_linux-64=2.40=h12ee557_0
- libffi=3.4.4=h6a678d5_1
- libgcc-ng=11.2.0=h1234567_1
- libgomp=11.2.0=h1234567_1
- libstdcxx-ng=11.2.0=h1234567_1
- libuuid=1.41.5=h5eee18b_0
- ncurses=6.4=h6a678d5_0
- openssl=3.0.16=h5eee18b_0
- pip=25.0=py310h06a4308_0
- python=3.10.16=he870216_1
- readline=8.2=h5eee18b_0
- setuptools=75.8.0=py310h06a4308_0
- sqlite=3.45.3=h5eee18b_0
- tk=8.6.14=h39e8969_0
- tzdata=2025a=h04d1e81_0
- wheel=0.45.1=py310h06a4308_0
- xz=5.6.4=h5eee18b_1
- zlib=1.2.13=h5eee18b_1
- pip:
- absl-py==2.2.2
- accelerate==1.6.0
- addict==2.4.0
- aiohappyeyeballs==2.6.1
- aiohttp==3.11.16
- aiosignal==1.3.2
- annotated-types==0.7.0
- anyio==4.9.0
- async-timeout==5.0.1
- attrs==25.3.0
- certifi==2025.1.31
- charset-normalizer==3.4.1
- click==8.1.8
- colorama==0.4.6
- contourpy==1.3.2
- cpm-kernels==1.0.11
- cycler==0.12.1
- datasets==3.5.0
- dill==0.3.8
- distro==1.9.0
- einops==0.8.1
- evaluate==0.4.3
- exceptiongroup==1.2.2
- filelock==3.18.0
- fonttools==4.57.0
- frozenlist==1.6.0
- fsspec==2024.12.0
- func-timeout==4.3.5
- fuzzywuzzy==0.18.0
- gradio-client==1.8.0
- h11==0.14.0
- h5py==3.13.0
- httpcore==1.0.8
- httpx==0.27.2
- huggingface-hub==0.30.2
- idna==3.10
- immutabledict==4.2.1
- importlib-metadata==8.6.1
- jieba==0.42.1
- jinja2==3.1.6
- jiter==0.9.0
- joblib==1.4.2
- json5==0.12.0
- jsonlines==4.0.0
- kiwisolver==1.4.8
- levenshtein==0.27.1
- lxml==5.3.2
- markdown-it-py==3.0.0
- markupsafe==3.0.2
- matplotlib==3.10.1
- mdurl==0.1.2
- mmengine-lite==0.10.7
- mpmath==1.3.0
- multidict==6.4.3
- multiprocess==0.70.16
- networkx==3.4.2
- nltk==3.9.1
- numpy==1.26.4
- nvidia-cublas-cu12==12.4.5.8
- nvidia-cuda-cupti-cu12==12.4.127
- nvidia-cuda-nvrtc-cu12==12.4.127
- nvidia-cuda-runtime-cu12==12.4.127
- nvidia-cudnn-cu12==9.1.0.70
- nvidia-cufft-cu12==11.2.1.3
- nvidia-curand-cu12==10.3.5.147
- nvidia-cusolver-cu12==11.6.1.9
- nvidia-cusparse-cu12==12.3.1.170
- nvidia-cusparselt-cu12==0.6.2
- nvidia-ml-py==12.570.86
- nvidia-nccl-cu12==2.21.5
- nvidia-nvjitlink-cu12==12.4.127
- nvidia-nvtx-cu12==12.4.127
- nvitop==1.4.2
- openai==1.75.0
- opencc==1.1.9
- opencv-python-headless==4.11.0.86
- packaging==24.2
- pandas==1.5.3
- pillow==11.2.1
- platformdirs==4.3.7
- portalocker==3.1.1
- prettytable==3.16.0
- propcache==0.3.1
- protobuf==6.30.2
- psutil==7.0.0
- pyarrow==19.0.1
- pydantic==2.11.3
- pydantic-core==2.33.1
- pyext==0.7
- pygments==2.19.1
- pyparsing==3.2.3
- python-dateutil==2.9.0.post0
- python-levenshtein==0.27.1
- pytz==2025.2
- pyyaml==6.0.2
- rank-bm25==0.2.2
- rapidfuzz==3.13.0
- regex==2024.11.6
- requests==2.32.3
- retrying==1.3.4
- rich==14.0.0
- rouge==1.0.1
- rouge-chinese==1.0.3
- rouge-score==0.1.2
- sacrebleu==2.5.1
- safetensors==0.5.3
- scikit-learn==1.5.0
- scipy==1.15.2
- seaborn==0.13.2
- sentence-transformers==4.1.0
- shellingham==1.5.4
- six==1.17.0
- sniffio==1.3.1
- sympy==1.13.1
- tabulate==0.9.0
- termcolor==3.0.1
- threadpoolctl==3.6.0
- tiktoken==0.9.0
- timeout-decorator==0.5.0
- tokenizers==0.21.1
- tomli==2.2.1
- torch==2.6.0
- tqdm==4.67.1
- transformers==4.51.3
- tree-sitter==0.21.3
- tree-sitter-languages==1.10.2
- triton==3.2.0
- typer==0.15.2
- typing-extensions==4.13.2
- typing-inspection==0.4.0
- urllib3==2.4.0
- wcwidth==0.2.13
- websockets==15.0.1
- xxhash==3.5.0
- yapf==0.43.0
- yarl==1.20.0
- zipp==3.21.0
prefix: /root/autodl-tmp/conda/envs/opencompass
数据集评估:
数据集分类
_gen后缀数据集:生成式评估,需后处理提取答案(如ceval_gen)
_ppl后缀数据集:困惑度评估,直接比对选项概率(如ceval_ppl)
C-Eval:侧重中文STEM和社会科学知识,包含1.3万道选择题
LawBench:法律领域专项评估,需额外克隆仓库并配置路径
评估一个模型一般要评估两个数据集:
一、开源的数据集评估(评估通用能力)
二、自定义数据集评估(评估定制化能力)
1. 主流开源数据集
OpenCompass内置超过70个数据集,覆盖五大能力维度:
知识类:C-Eval(中文考试题)、CMMLU(多语言知识问答)、MMLU(英文多选题)。
推理类:GSM8K(数学推理)、BBH(复杂推理链)。
语言类:CLUE(中文理解)、AFQMC(语义相似度)。
代码类:HumanEval(代码生成)、MBPP(编程问题)。
多模态类:MMBench(图像理解)、SEED-Bench(多模态问答)
2. 自定义数据集
我们支持 .jsonl 和 .csv 两种格式的数据集。
2.1 选择题 (mcq)
对于选择 (mcq) 类型的数据,默认的字段如下:
question: 表示选择题的题干
A, B, C, …: 使用单个大写字母表示选项,个数不限定。默认只会从 A 开始,解析连续的字母作为选项。
answer: 表示选择题的正确答案,其值必须是上述所选用的选项之一,如 A, B, C 等。
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 .meta.json 文件中进行指定。
.jsonl 格式样例如下:
{"question": "165+833+650+615=", "A": "2258", "B": "2263", "C": "2281", "answer": "B"}
{"question": "368+959+918+653+978=", "A": "3876", "B": "3878", "C": "3880", "answer": "A"}
{"question": "776+208+589+882+571+996+515+726=", "A": "5213", "B": "5263", "C": "5383", "answer": "B"}
{"question": "803+862+815+100+409+758+262+169=", "A": "4098", "B": "4128", "C": "4178", "answer": "C"}
.csv 格式样例如下:
question,A,B,C,answer
127+545+588+620+556+199=,2632,2635,2645,B
735+603+102+335+605=,2376,2380,2410,B
506+346+920+451+910+142+659+850=,4766,4774,4784,C
504+811+870+445=,2615,2630,2750,B
2.2问答题 (qa)
对于问答 (qa) 类型的数据,默认的字段如下:
question: 表示问答题的题干
answer: 表示问答题的正确答案。可缺失,表示该数据集无正确答案。
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 .meta.json 文件中进行指定。
.jsonl 格式样例如下:
{"question": "752+361+181+933+235+986=", "answer": "3448"}
{"question": "712+165+223+711=", "answer": "1811"}
{"question": "921+975+888+539=", "answer": "3323"}
{"question": "752+321+388+643+568+982+468+397=", "answer": "4519"}
.csv 格式样例如下:
question,answer
123+147+874+850+915+163+291+604=,3967
149+646+241+898+822+386=,3142
332+424+582+962+735+798+653+214=,4700
649+215+412+495+220+738+989+452=,4170
评估命令:
评估本地的hf格式大模型:
参数解释:
--datasets:
评估所用数据集(数据集配置在框架系统中,可以使用
# 列出与llama和mmlu相关的所有配置
python tools/list_configs.py llama mmlu
来查看)
--hf-type:模型属于什么类型 一般模型名字后面由chat就填chat,没有写base或者不传这个参数
--hf-path:模型路径
--debug:捕获异常并提供详细信息
方法一:命令行(只能评估一个模型!!!!!!!!!!!!!!!!!!!!!!)
python run.py \
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
--hf-type chat \
--hf-path internlm/internlm2-chat-1_8b \
--debug
--work-dir /root/autodl-tmp/opencompass-main/opencompass-main/two_model
方法二:命令行+配置文件(多模型!!!!!!!!!!!!!!!!!!!!!!!)
--models:后面跟的模型名称,对应的配置文件目录在:opencompass/openconpass/configs/models/qwen2.5 去找模型。
模型名称解析:
hf前缀代表是huggingface评估方法
找到你要的py文件:
例如:hf_qwen1_5_0_5b_chat.py,然后修改 path换成绝对路径
run_cfg=dict(num_gpus=1)评估用的哪一块gpu,电脑上只有一块的写成0
from opencompass.models import HuggingFacewithChatTemplate
models = [
dict(
type=HuggingFacewithChatTemplate,
abbr='qwen1.5-0.5b-chat-hf',
path='Qwen/Qwen1.5-0.5B-Chat',
max_out_len=1024,
batch_size=8,
run_cfg=dict(num_gpus=0),
stop_words=['<|im_end|>', '<|im_start|>'],
)
]
注意:可以使用 python tools/list_configs.py hf_qwen 来查看模型名称,即跟在--models后面的参数
python run.py \
--models hf_internlm2_chat_1_8b hf_qwen2_1_5b_instruct \
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
--debug
--work-dir /root/autodl-tmp/opencompass-main/opencompass-main/two_model
评估加速:
1. pip install lmdeploy
2. 在config/models/下寻找 lmdeploy开头的py文件
2.1 修改path:
2.2 参数解释
engine_config=dict(session_len=16384, max_batch_size=16, tp=1),
tp:产生的结果用对应序号的gpu来评估。
from opencompass.models import TurboMindModelwithChatTemplate
models = [
dict(
type=TurboMindModelwithChatTemplate,
abbr='qwen1.5-1.8b-chat-turbomind',
path='Qwen/Qwen1.5-1.8B-Chat',
engine_config=dict(session_len=16384, max_batch_size=16, tp=1),
gen_config=dict(top_k=1, temperature=1e-6, top_p=0.9, max_new_tokens=4096),
max_seq_len=16384,
max_out_len=4096,
batch_size=16,
run_cfg=dict(num_gpus=1),
stop_words=['<|im_end|>', '<|im_start|>'],
)
]
3. 和上面一样 model填写你修改的配置文件地址
python run.py \
--models lmdeploy_xxxxx \
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
--debug
--work-dir /root/autodl-tmp/opencompass-main/opencompass-main/two_model
自定义数据及评估:
自定义数据集
我们支持 .jsonl 和 .csv 两种格式的数据集。
2.1 选择题 (mcq)
对于选择 (mcq) 类型的数据,默认的字段如下:
question: 表示选择题的题干
A, B, C, …: 使用单个大写字母表示选项,个数不限定。默认只会从 A 开始,解析连续的字母作为选项。
answer: 表示选择题的正确答案,其值必须是上述所选用的选项之一,如 A, B, C 等。
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 .meta.json 文件中进行指定。
.jsonl 格式样例如下:
{"question": "165+833+650+615=", "A": "2258", "B": "2263", "C": "2281", "answer": "B"}
{"question": "368+959+918+653+978=", "A": "3876", "B": "3878", "C": "3880", "answer": "A"}
{"question": "776+208+589+882+571+996+515+726=", "A": "5213", "B": "5263", "C": "5383", "answer": "B"}
{"question": "803+862+815+100+409+758+262+169=", "A": "4098", "B": "4128", "C": "4178", "answer": "C"}
.csv 格式样例如下:
question,A,B,C,answer
127+545+588+620+556+199=,2632,2635,2645,B
735+603+102+335+605=,2376,2380,2410,B
506+346+920+451+910+142+659+850=,4766,4774,4784,C
504+811+870+445=,2615,2630,2750,B
2.2问答题 (qa)
对于问答 (qa) 类型的数据,默认的字段如下:
question: 表示问答题的题干
answer: 表示问答题的正确答案。可缺失,表示该数据集无正确答案。
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 .meta.json 文件中进行指定。
.jsonl 格式样例如下:
{"question": "752+361+181+933+235+986=", "answer": "3448"}
{"question": "712+165+223+711=", "answer": "1811"}
{"question": "921+975+888+539=", "answer": "3323"}
{"question": "752+321+388+643+568+982+468+397=", "answer": "4519"}
.csv 格式样例如下:
question,answer
123+147+874+850+915+163+291+604=,3967
149+646+241+898+822+386=,3142
332+424+582+962+735+798+653+214=,4700
649+215+412+495+220+738+989+452=,4170
参数解析:
--custom-dataset-data-type qa 或者mcp
--hf-path:模型绝对路径
方法一(简化):
python run.py \
--hf-path internlm/internlm2-chat-1_8b \
--custom-dataset-path xxx/test_qa.jsonl \
方法二(全一点):
python run.py \
--hf-path internlm/internlm2-chat-1_8b \
--custom-dataset-path xxx/test_qa.jsonl \
--custom-dataset-data-type qa \
--custom-dataset-infer-method gen
前端框架:
openwebui
地址:
https://github.com/open-webui/open-webui
安装:
conda create -n openwebui python=3.11 -y
conda activate openwebui
pip install -U open-webui torch transformers -i https://pypi.mirrors.ustc.edu.cn/simple/
运行:
ubuntu:
conda activate open-webui
export HF_ENDPOINT=https://hf-mirror.com
export ENABLE_OLLAMA_API=True
export OPENAI_API_BASE_URL=http://127.0.0.1:23333/v1
open-webui serve --port 8080
windows:(!!!记得写成bat文件)
set HF_ENDPOINT=https://hf-mirror.com
set ENABLE_OLLAMA_API=False
set OPENAI_API_BASE_URL=http://127.0.0.1:23333/v1
open-webui serve --port 8080
bat:
@echo off
REM 设置环境变量
set HF_ENDPOINT=https://hf-mirror.com
set ENABLE_OLLAMA_API=False
set OPENAI_API_BASE_URL=http://127.0.0.1:23333/v1
REM 激活 Conda 环境
call conda activate open-webui
REM 启动 OpenWebUI 服务
open-webui serve --port 8080
大模型转gguf:
llama.cpp:
下载:
git clone https://github.com/ggerganov/llama.cpp.git
安装依赖:
conda create -n llama_cpp python=3.10 -y
conda activate llama_cpp
pip install -r requirements.txt
运行脚本:
# 如果不量化,保留模型的效果
python convert_hf_to_gguf.py /root/autodl-tmp/model/Qwen2.5-1.5B-zyhhsss --outtype f16 --verbose --outfile /root/autodl-tmp/model/Qwen2.5-1.5B-zyhhsss-gguf.gguf
# 如果需要量化(加速并有损效果),直接执行下面脚本就可以
python convert_hf_to_gguf.py /root/autodl-tmp/model/Qwen2.5-1.5B-zyhhsss --outtype q8_0 --verbose --outfile /root/autodl-tmp/model/Qwen2.5-1.5B-zyhhsss-gguf_q8_0.gguf
这里--outtype是输出类型,代表含义:
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别。
q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。
q4_0:这是最初的量化方案,使用 4 位精度。
q4_1 和 q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景。
q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较
慢。
q6_k 和 q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户。
fp16 和 f32: 不量化,保留原始精度。
environment.yml
name: llama_cpp
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- _openmp_mutex=5.1=1_gnu
- bzip2=1.0.8=h5eee18b_6
- ca-certificates=2025.2.25=h06a4308_0
- ld_impl_linux-64=2.40=h12ee557_0
- libffi=3.4.4=h6a678d5_1
- libgcc-ng=11.2.0=h1234567_1
- libgomp=11.2.0=h1234567_1
- libstdcxx-ng=11.2.0=h1234567_1
- libuuid=1.41.5=h5eee18b_0
- ncurses=6.4=h6a678d5_0
- openssl=3.0.16=h5eee18b_0
- pip=25.0=py310h06a4308_0
- python=3.10.16=he870216_1
- readline=8.2=h5eee18b_0
- setuptools=75.8.0=py310h06a4308_0
- sqlite=3.45.3=h5eee18b_0
- tk=8.6.14=h39e8969_0
- wheel=0.45.1=py310h06a4308_0
- xz=5.6.4=h5eee18b_1
- zlib=1.2.13=h5eee18b_1
- pip:
- aiohttp==3.9.5
- aiosignal==1.3.2
- annotated-types==0.7.0
- anyio==4.9.0
- async-timeout==4.0.3
- attrs==25.3.0
- certifi==2025.1.31
- charset-normalizer==3.4.1
- click==8.1.8
- contourpy==1.3.1
- cycler==0.12.1
- distro==1.9.0
- exceptiongroup==1.2.2
- filelock==3.18.0
- fonttools==4.56.0
- frozenlist==1.5.0
- fsspec==2025.3.0
- gguf==0.14.0
- h11==0.14.0
- httpcore==1.0.7
- httpx==0.28.1
- huggingface-hub==0.23.5
- idna==3.10
- iniconfig==2.1.0
- jinja2==3.1.6
- jiter==0.9.0
- kiwisolver==1.4.8
- markdown-it-py==3.0.0
- markupsafe==3.0.2
- matplotlib==3.10.1
- mdurl==0.1.2
- mpmath==1.3.0
- multidict==6.2.0
- networkx==3.4.2
- numpy==1.26.4
- openai==1.55.3
- packaging==24.2
- pandas==2.2.3
- pillow==11.1.0
- pluggy==1.5.0
- prometheus-client==0.20.0
- propcache==0.3.1
- protobuf==4.25.6
- pydantic==2.11.1
- pydantic-core==2.33.0
- pygments==2.19.1
- pyparsing==3.2.3
- pytest==8.3.5
- python-dateutil==2.9.0.post0
- pytz==2025.2
- pyyaml==6.0.2
- regex==2024.11.6
- requests==2.32.3
- rich==13.9.4
- safetensors==0.5.3
- seaborn==0.13.2
- sentencepiece==0.2.0
- shellingham==1.5.4
- six==1.17.0
- sniffio==1.3.1
- sympy==1.13.3
- tokenizers==0.20.3
- tomli==2.2.1
- torch==2.2.2+cpu
- tqdm==4.67.1
- transformers==4.46.3
- typer==0.15.2
- typing-extensions==4.13.0
- typing-inspection==0.4.0
- tzdata==2025.2
- urllib3==2.3.0
- wget==3.2
- yarl==1.18.3
prefix: /root/miniconda3/envs/llama_cpp
分布式微调
DeepSpeed:
显存优化器
用时间换空间
支持huggingface pytorch transformers
核心技术:zero,梯度检查点:cpu offloading、混合精度训练 自适应选择最佳通信策略
ZeRO优化器:
阶段划分:
ZeRO-1:优化器状态分片。每张卡上面仍然有完整模型,优化器反向传播的时候只更新一部分参数
ZeRO-2: 梯度(模型反向传播)分片
ZeRO-3:参数(模型正向传播)+梯度+优化器状态
总结:
- zero3显存占用率会下降到1/n n为显卡数量(跟显卡架构有关)
- 支持json配置
- 支持千卡集群训练
用途:训练千亿参数、资源受限、快速实践如微调(一般7b就用)
安装及配置
安装:
pip install deepspeed
配置
llamafactory:
none-1
2 -zero2
3 -zero3
多机多卡、单机多卡:
见llamafactory下的分布式训练
xtuner:
NPROC_PER_NODE=${GPU_NUM} xtuner train ./config.py --deepspeed deepspeed_zero2
评测模型的工具:
OpenCompass:
文本生成模型用的相似度评估
地址:欢迎来到 OpenCompass 中文教程! — OpenCompass 0.4.1 文档
解压操作:
tar -xvf LLaMaFactory.tar
常见的模型:
生成式模型汇总!一文带你从隐变量模型到 VAE, GAN, Flow 到 Diffusion Model 全懂完()
博客:https://zhuanlan.zhihu.com/p/721196823
RNN:
服务器:
https://www.autodl.com/home
ftp x-shell
传输文件
nohup
后台登陆
nvitop:
使用nvitop来监控 NVIDIA GPU 的使用情况-CSDN博客
大模型理论知识:
transformer:
视频:
2、语言词袋_哔哩哔哩_bilibili
博客:
Transformer_transformeryuanlunwen-CSDN博客
模型压缩:
把ai模型之中的参数变少或者变小,最早做边缘部署的。主要想解决模型部署问题,主要可以划分为如下几种方法:
剪枝:
简化模型的结构。
**非结构化剪枝:**层数不变,减少某一层的参数。现在不适用因为大模型结果取决于一些核心的网络参数,结果不可控。 依赖于特定硬件的平台或者算法库
**结构化剪枝:**减少某一些层数,破坏原有结构。精度比较低,不依赖于硬件平台。
局部、全局剪枝:
通常思路:先见0.2重新训练还行,再减0.2继续重新训练
量化:
训练量化,推理量化。原先是32位的现在一般是16位,现在特指8位和4位
训练量化:模型训练时加载模型,分为两部分,一部分参与训练的升到32位。不参预训练的用8位保存。
推理量化:大部分模型参数用8位保存,关键的激活函数用的32位保存
知识蒸馏:
原有一个训练好的大模型作为teacher network,新有一个参数小的模型作为student network。把以前的数据集同时给两个模型, teacher会得出一个接近正确的特征,把student的结果和teacher的结果做一个损失,加上原本的损失。损失权重一开始与teacher差别的权重比较大,自身学习的比较小,之后反过来,由T控制。
deepseek蒸馏的openai
分布式微调:
解决问题:大模型规模爆炸、训练加速。
使用deepspeed进行训练
数据并行:
原理:每个设备导入完整模型,最后汇合。
作用:加速训练,每个设备可以单独去跑。
24g显存 - 7b大模型
16g显存*(2or4) -7b大模型
缺点:通信开销大、显存占用率高(需要存储完整的模型和优化器)
模型并行:
通常需要同型号!!!
原理:将模型拆分到不同设备(一般是按层或张量拆分):
作用:节约算力
横向拆分:按照层
竖向切分:按照张量。例如:Megation-LM将矩阵乘法分片
缺点:设备之间通信频繁,需要精细的负载均衡设计
流水线并行(Pipline Parallelism):
原理:将模型按照层拆分成多个阶段,数据分块之后按照流水线执行。(简单来说模型和数据都拆分了)
优化:微批次减少流水线气泡。显存节约更好。
挑战:需平衡阶段划分,避免资源闲置。
混合并行(3D并行):
把上面三个组合起来,训练千亿级规模的大模型。如:meta的llama-2
混合精度训练:
参预训练的32位,不参加的16位
学习问题汇总:
1 special——token原理
[bert中的special token到底是怎么发挥作用的(1) - 知乎](https://zhuanlan.zhihu.com/p/361169990#:~:text=bert中的special token有 [cls],[sep],[unk],[pad],[mask];)
2 前几节课处理文本
3 数据的token化参数含义,embedding,transformer,rnn那些
4 bert sft这些,llamafactory上的微调方法
5 nvitop上的指标看看(完成)见服务器下的nvitop
6 常见的文本生成模型:llama qwen glm(谷歌)chatglm(质谱轻言)gemma(完成)
7 混和精度训练
8 知识蒸馏
9 为什么模型后面加个/v1
10 curl用法
11 bf16 bf32 所谓单精度、双精度干嘛的
12 模型指标参数的含义:bleu-4、ROUGE-4、
13 量化
14 前半小时+21.45-结尾
15 截断长度的计算
16 sm80算力
17 openwebui
18 gguf转化(完成)见llama.cpp
19 qlora(完成)见下面
20 lora
21 xtuner实现单机多卡微调,实现训练对话模板转换与部署、导出上面所有框架的包
22 lmdeploy的推理引擎turbomind
21 对话模板(完成):
三套:微调、模型推理、前端界面。三套提示词模板
模型部署的时候可以使用微调框架使用的对话模板。
openwebui每次加载的时候会覆盖提示词模板
流程:llmfactory运行脚本转换成jinjia->模型推理平台启动->使用代码测试
注:openwebui暂不支持修改对话模板,以后用别的前端框架
22 Vllm的pageAttentation和张量并行技术
23 kv cache 分布式推理原理
24 看一下为什么相似度和例子差不多就行
25 什么叫数据同态同分布
微调注意事项记录:
1.使用flashatten2算力需要在sm80之上
2.qlora流程:
超参:
**gpu:**4090d -24g显存
**模型:**Qwen/Qwen2.5-1.5B-Instruct
**qlora量化等级:**8b
**lora秩:**选择和模型、量化等级有关这里给的:64 一般在32-128之间
**lora缩放系数:**直接秩*2 这里128
**计算类型:**混合加速训练,用来加速模型训练 bf16新的显卡架构支持、fp16老的支持
**batch:**10
合并:
检查点路径:(100、200等绝对路径)
/root/autodl-tmp/LLaMA-Factory/LLaMA-Factory/saves/Qwen2.5-1.5B-Instruct/lora/train_2025-03-30-16-36-58/checkpoint-100
导出路径:
/root/autodl-tmp/LLaMA-Factory/LLaMA-Factory/saves/Qwen2.5-1.5B-Instruct/lora/train_2025-03-30-16-36-58/checkpoint-100/Qwen2.5-1.5B-zyhhsss
3.lora流程:
4.情绪对话模型实现流程(微调项目通用实现流程)
本项目4090 跑了两小时 2500步(2510/204000) batch给的15 训练数据 2000
24g训练可以,lmdeploy部署oom使用k v cache并行部署也不行。
硬件选择:
训练:RTX3090 24G
部署:vGPU-32GB 显存占用30.2G
最终结果网盘地址:
大致分成四个步骤
1 数据 2 模型 3 训练、测评 4、部署
4.1 数据来源
- 甲方提供
- 自己收集
- 指定数据集标准
- 数据集获取方式:手动采集、爬虫、数据接口、ai生成
- 数据清洗标注
- 人工处理、ai标注
- 指定数据集格式
本项目数据来源:
-
准备一些现有数据集
-
基于原有开源数据,让AI实现数据情绪制作
注意:如果使用AI来处理数据,尽量使用服务器提供的接口
常见大模型参数说明
- Temperature(温度)
- 作用:控制生成文本的随机性和创造性。
- 取值范围:通常在 [0, ∞) 之间,但常见范围是 [0, 2]。
- 具体效果:
- 低值(接近 0):模型更倾向于选择概率最高的词,生成结果更加确定性、保守、稳定,适合需要精确回答的任务。
- 高值(接近 1 或更高):增加随机性,模型会更多地考虑低概率的词,生成结果更加多样化、创造性和不可预测。
- Top-k Sampling(Top-k 采样)
- 作用:限制每次生成时只从概率最高的前 k 个词中进行选择。
- 取值范围:k 是一个正整数,比如 10、50、100 等。
- 具体效果:
- 如果
k=1,模型每次都只选择概率最高的那个词,生成结果非常确定。 - 如果
k=50,模型会从概率最高的 50 个词中随机选择一个,生成结果会有一定多样性。 - 较大的 k 值会让生成结果更加多样,但也可能导致语义不连贯。
- 如果
- Top-p Sampling(Nucleus Sampling,核采样)
- 作用:动态地选取累积概率达到某个阈值 p 的最小词集进行采样。
- 取值范围:p 在 (0, 1] 之间,比如 0.9、0.7 等。
- 具体效果:
- 如果
p=0.9,模型会选择累积概率达到 90% 的最小词集进行采样。 - 如果词汇分布很集中,可能只选几个词;如果分布很分散,可能会选很多词。
- 相比
top_k,top_p更灵活,因为它根据实际的概率分布动态调整候选词集。
- 如果
- Seed(随机种子)
- 作用:控制生成过程中的随机性,确保结果可复现。
- 取值范围:通常是一个整数。
- 具体效果:
- 如果设置固定的
seed,多次运行模型会得到相同的结果。 - 如果不设置或每次使用不同的
seed,生成结果会不同。
- 如果设置固定的
总结对比
| 参数 | 控制维度 | 调节方式 | 影响结果 |
|---|---|---|---|
| Temperature | 创造力 | 数值高低影响随机性 | 高温=多样,低温=稳定 |
| Top-k | 候选词数量 | 固定选择前 k 个词 | 小 k=保守,大 k=多样 |
| Top-p | 累积概率阈值 | 动态选择累积概率达到 p 的词集 | 小 p=保守,大 p=多样 |
| Seed | 随机性一致性 | 固定随机种子 | 固定 seed=可复现,否则随机 |
4.1.1 制作AI生成数据脚本
核心思路:
- 加载模型、加载embedding
- 配置风格模板(作用是规定生成消息回复的消息格式与风格)
- 限定不同的风格
- 每种风格可以设定不同的system定位(openai中的"role": “system”, “content”:),并且加入一些风格生成的约束
- 设定各种风格的没模型参数,temperature
- 写消息生成函数
- 规定用户输入list
- 按照风格和提问生成message,调用模型
- 对结果进行筛选,风格、长度、相似度
- 去重核心思路
- 先对文本进行编码(embedding)
- 求相似度(余弦,欧式)
- 设定阈值
import json
import time
import random
from openai import OpenAI
from sentence_transformers import SentenceTransformer
import numpy as np
from tqdm import tqdm
import os
base_url = "https://api.ppinfra.com/v3/openai"
api_key = "sk_FbKBQLJG_sfPuaD2kf_ehCeNiRVAI6j5nmBWw1d37TQ"
model = "qwen/qwen2.5-vl-72b-instruct"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
# 加载Embedding模型
style_model = SentenceTransformer(r"G:\python_ws_g\code\LLMlearn\embedding_model\thomas\text2vec-base-chinese")
# 风格模板配置
style_config = {
"温柔": {
"system_prompt": "你是一个温柔体贴的聊天助手,说话时总是充满关怀,使用以下特征:\n1. 包含'呢、呀、啦'等语气词\n2. 使用🌸💖😊等温暖表情\n3. 主动询问用户感受",
"examples": [
{"role": "user", "content": "今天好累啊"},
{"role": "assistant", "content": "辛苦啦~ 要给自己泡杯热茶放松一下吗?🌸"},
{"role": "user", "content": "考试没考好..."},
{"role": "assistant", "content": "没关系的呀~ 下次一定会更好!需要我陪你聊聊吗?😊"}
],
"temperature": 0.7
},
"毒舌": {
"system_prompt": "你是一个喜欢用犀利吐槽表达关心的朋友,需满足:\n1. 使用网络流行语(如'栓Q''退退退')\n2. 包含夸张比喻('你这速度堪比树懒')\n3. 结尾隐藏关心",
"examples": [
{"role": "user", "content": "又胖了5斤!"},
{"role": "assistant", "content": "好家伙!你这是要把体重秤压成分子料理?🏋️"},
{"role": "user", "content": "游戏又输了"},
{"role": "assistant", "content": "菜就多练练!需要给你推荐《从零开始的电竞之路》吗?🎮"}
],
"temperature": 0.7
},
}
# 单条数据写入文件
def append_single_to_json(file_path, new_entry):
"""将单条数据追加到 JSON 文件"""
# 如果文件不存在,创建一个空的 JSON 文件
if not os.path.exists(file_path):
with open(file_path, "w", encoding="utf-8") as f:
json.dump([], f, ensure_ascii=False, indent=2)
# 以追加模式打开文件
with open(file_path, "r+", encoding="utf-8") as f:
try:
# 尝试读取现有数据
f.seek(0)
existing_data = json.load(f)
except json.JSONDecodeError:
existing_data = []
# 添加新数据
existing_data.append(new_entry)
# 写回文件
f.seek(0)
f.truncate() # 清空文件内容
json.dump(existing_data, f, ensure_ascii=False, indent=2)
# 质量过滤规则
def is_valid_reply(style, user_msg, reply):
"""质量过滤规则(添加空值检查)"""
# 基础检查
if not reply or len(reply.strip()) == 0:
return False
# 规则1:回复长度检查
if len(reply) < 5 or len(reply) > 150:
return False
print(reply)
# # 规则2:风格关键词检查
# style_keywords = {
# "温柔": ["呢", "呀", "😊", "🌸"],
# "毒舌": ["好家伙", "栓Q", "!", "🏋️"]
# }
# if not any(kw in reply for kw in style_keywords.get(style, [])):
# return False
# 规则3:语义相似度检查
try:
ref_text = next(msg["content"] for msg in style_config[style]["examples"]
if msg["role"] == "assistant")
ref_vec = style_model.encode(ref_text)
reply_vec = style_model.encode(reply)
# 计算余弦相似度
cosine_similarity = np.dot(ref_vec, reply_vec) / (np.linalg.norm(ref_vec) * np.linalg.norm(reply_vec))
print(cosine_similarity)
return cosine_similarity < 0.8 # 阈值可以根据需求调整
except:
return False
def load_user_inputs_from_json(file_path):
"""
从 JSON 文件中加载用户输入数据。
"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件 {file_path} 不存在!")
with open(file_path, "r", encoding="utf-8") as f:
user_inputs = json.load(f)
return user_inputs
# 生成函数
def generate_style_data(style_name, num_samples=50):
config = style_config[style_name]
data_count = 0
# 构建消息上下文(包含系统提示和示例对话)
messages = [
{"role": "system", "content": config["system_prompt"]},
*config["examples"] # 直接展开示例对话
]
# 从 JSON 文件中加载用户输入
try:
user_inputs = load_user_inputs_from_json(r"G:\python_ws_g\code\LLMlearn\project\dataset\LCCC\user_inputs.json")
except Exception as e:
print(f"加载用户输入失败:{str(e)}")
return
with tqdm(total=num_samples) as pbar: # 初始化进度条
while data_count < num_samples: # 确保生成指定数量的有效数据
try:
# 随机选择用户输入
user_msg = random.choice(user_inputs)
# 添加当前用户消息
current_messages = messages + [
{"role": "user", "content": user_msg}
]
# 调用API
response = client.chat.completions.create(
model=model,
messages=current_messages,
temperature=config["temperature"],
max_tokens=100
)
# 获取回复内容
reply = response.choices[0].message.content
# 质量过滤(数据审核)
if is_valid_reply(style_name, user_msg, reply):
data_entry = {
"user": user_msg,
"assistant": reply,
"style": style_name
}
append_single_to_json("style_chat_data.json", data_entry) # 立即写入文件
data_count += 1
pbar.update(1) # 更新进度条
time.sleep(1.0) # 频率限制保护
except Exception as e:
print(f"生成失败:{str(e)}")
# 执行生成
if __name__ == '__main__':
try:
print("开始生成温柔风格数据...")
generate_style_data("温柔", 5000)
print("开始生成毒舌风格数据...")
generate_style_data("毒舌", 4750)
except KeyboardInterrupt:
print("\n用户中断,已保存部分数据...")
finally:
print("数据生成完成!")
4.1.2 确定原始数据
用户给的输入(input),一般来讲甲方有原始数据。本项目选择日常交流话术(开源数据集)。
LCCC: LCCC · 数据集
CDial-GPT:CDial-GPT
LCCC转换脚本:
import json
import os
user_inputs = [
# 日常生活相关
"今天心情不太好",
"推荐个电影吧",
"怎么才能早睡早起",
"养猫好还是养狗好",
"工作压力好大",
"最近总是失眠",
"今天脚有点肿了",
"天气太冷了怎么办",
"周末有什么好玩的活动吗",
"如何摆脱拖延症",
"吃饭的时候总觉得无聊,怎么办",
"有没有什么适合在家做的运动",
"最近总觉得很累,是不是亚健康了",
# 情感与人际关系
"朋友之间闹矛盾了,该怎么办",
"喜欢一个人但不敢表白,怎么办",
"家人不理解我,感觉很孤独",
"如何更好地表达自己的情绪",
"觉得身边的人都比我优秀,好焦虑",
"分手后怎么调整心态",
"怎样交到更多的朋友",
"和同事相处总是很尴尬,怎么办",
# 学习与工作
"考试复习效率太低了,有什么建议",
"工作中遇到瓶颈,怎么突破",
"想学一门新技能,但不知道从哪开始",
"如何提高专注力",
"面试前特别紧张,有什么方法缓解",
"觉得自己能力不足,害怕被裁员",
"论文写不下去了,怎么办",
"团队合作中遇到问题,该怎么解决",
# 健康与饮食
"最近胖了好多,怎么减肥比较好",
"晚上总是睡不着,有什么助眠的方法",
"吃什么对皮肤好",
"健身计划总是坚持不下来,怎么办",
"感冒了,吃什么药比较好",
"如何保持身体健康",
"每天喝水不够,有什么提醒方法",
"如何改善久坐导致的腰酸背痛",
# 兴趣爱好与娱乐
"最近有什么好看的电视剧推荐",
"喜欢画画,但总是画不好,怎么办",
"想学吉他,但没时间练习",
"如何选择适合自己的书",
"旅行时有哪些注意事项",
"如何拍出好看的照片",
"最近迷上了咖啡,有什么推荐的豆子吗",
"喜欢玩游戏,但怕影响学习,怎么平衡",
# 社会议题与热点
"最近的新闻热点怎么看",
"人工智能会不会取代人类的工作",
"环保问题越来越严重,我们能做些什么",
"如何看待年轻人躺平的现象",
"未来的科技会发展成什么样",
"社会上的不公平现象让人很沮丧,怎么办",
# 随机吐槽与搞笑
"又胖了5斤!",
"游戏又输了,好气啊",
"老板今天又骂人了,真是无语",
"外卖等了一个小时还没到,简直崩溃",
"手机摔地上了,屏幕裂了,心也碎了",
"今天的地铁太挤了,感觉自己快被压扁了",
"为什么每次洗完头都会下雨",
"为什么我的猫总是踩我键盘",
]
def extract_first_statements(data):
"""
从对话数据集中提取每段对话的第一句话。
"""
# 遍历每段对话
for conversation in data:
if conversation: # 确保对话不为空
first_statement = conversation[0].replace(" ", "") # 提取第一句并移除空格
user_inputs.append(first_statement)
return user_inputs
def load_json(file_path):
"""
加载 JSON 文件中的数据。
"""
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
return data
def save_to_json(file_path, data):
"""
将数据保存到 JSON 文件中。
"""
with open(file_path, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=4)
# 主程序
if __name__ == "__main__":
# 输入文件路径
input_file = r"G:\python_ws_g\code\LLMlearn\project\dataset\LCCC\LCCC-base-split\LCCC-base_test.json"
# 检查输入文件是否存在
if not os.path.exists(input_file):
print(f"错误:文件 {input_file} 不存在!")
exit(1)
# 加载原始数据集
print("正在加载数据...")
data_set = load_json(input_file)
# 提取每段对话的第一句
print("正在提取第一句话...")
user_inputs = extract_first_statements(data_set)
# 输出文件路径
output_file = "user_inputs.json"
# 保存到 JSON 文件
print("正在保存结果...")
save_to_json(output_file, user_inputs)
print(f"数据已成功保存到 {output_file}")
使用数据2000条:
通过网盘分享的文件:wenrou.json
链接: https://pan.baidu.com/s/1hMuLt79YaAZZk79sKYX9zQ?pwd=mb4c 提取码: mb4c
–来自百度网盘超级会员v6的分享
Xtuner需要的数据集格式:
[
{
"conversation": [
{
"input": "闺蜜把我秘密当谈资,该不该撕破脸?",
"output": "哎呀,这种事情确实很难处理呢。你觉得她的行为伤害到了你吗?💖我们可以一起想想解决的办法。"
}
]
},
{
"conversation": [
{
"input": "老妈非让我嫁给她同事儿子,怎么逃啊!",
"output": "哎呀,这种事情确实挺棘手的。💖 你心里是怎么想的呢?是不是感到有些压力?我们可以一起想想解决的办法。🌸"
}
]
}]
4.2 模型
4.2.1 模型选型:
**通用流程:模型官网看参数、选后缀 看自己能用的大小 客观评估(当前聊天对话模型核心是:中文理解能力。用CLUE适合一点) **
模型大小判断:
1.服务器配置。
qwen-2.5-7b下载用的: bf16。 用qlora微调到8位。
| 项目 | 占用(估算) |
|---|---|
| 模型参数(8-bit) | 约 7 GB |
| LoRA 参数 | < 100 MB |
| 激活值(中等batch) | 5-8 GB(可调) |
| 其他缓存(attention kv、optimizer) | 5-8 GB |
20GB - 左右
🛠 推荐配置
- 最小可用显卡:RTX 3090(24GB)或 RTX 4090(24GB)
- 推荐配置:2×3090 / 1×A6000 / 1×A100(40GB 以上更舒服)
- 最优方案:多卡 A100,配合 deepspeed/fsdp 微调更大 batch
2.任务复杂度(人类对话任务3b以内的就行,像数学推理,编程需要更高,得落地尝试)。类似销售机器人:情绪对话+10086客服机器人就可以。
中文模型:qwen、chatglm(智谱)、interlm(书生浦语)
llama训练数据90%以上是英文文本
常见后缀:
chat、instruct:模型输出有限制,经过人工对齐安全一点
instruct:
chat:做聊天对话模型
无后缀:base模型无人工审查
4.2.2 模型客观评价:
CLUE数据集:
分为CLUE、FewCLUE前缀的。clue中长文,fewclue短文。
gen后缀文本生成、PPL困惑度:PPL 越低:模型对语言的拟合越好,预测越准确;PPL 越高:说明模型更“困惑”,也就是说它对句子的预测不确定性更大。
| 数据集名称 | 所属前缀 | 文本长度 | 任务类型 | 用途说明 | PPL作用说明 |
|---|---|---|---|---|---|
| AFQMC | CLUE | 中等 | 语义相似性 | 判断两个句子是否表达相同含义(如问句对齐、改写识别) | 模型PPL越低表示更能准确判断句子语义相似性 |
| CMNLI | CLUE | 中长 | 自然语言推理 | 判断句子对之间的逻辑关系(蕴含、中立、矛盾) | 反映模型理解句间逻辑关系的能力 |
| CSL | CLUE | 长文 | 关键词预测 | 利用给定关键词判断摘要与关键词的匹配关系(多标签分类) | PPL低说明模型能更好生成或匹配关键词 |
| TNEWS | CLUE | 短文 | 文本分类 | 新闻标题分类(15个类别,如科技、财经、体育等) | PPL评估模型对新闻标题语义分布的拟合效果 |
| IFLYTEK | CLUE | 短文 | 文本分类 | App应用描述的自动分类(119类,任务更细粒度) | PPL越低表示模型能准确建模多类别语义特征 |
| WSC | CLUE | 中等 | 语言理解 | 推理代词指代的实体(例如“他”指的是谁) | 测试模型对常识推理和上下文理解的能力 |
| CLUEgen | CLUE-gen | 长文 | 文本生成 | 给定一段内容生成文章或续写文本 | PPL用于评估生成文本的流畅度与合理性 |
| FewCLUE | FewCLUE | 短文 | 小样本任务 | 包括文本分类、匹配、推理等任务,使用极少样本进行训练 | PPL用于评估模型在低资源下的语言拟合能力 |
| CSKG | FewCLUE | 短文 | 知识问答 | 基于知识图谱的问答推理任务 | 衡量模型理解实体关系与事实知识的能力 |
| CHIP-STS | FewCLUE | 中短 | 医疗语义匹配 | 医疗问句之间的语义相似性任务(面向中文医疗文本) | 用于医疗场景下语义建模,PPL越低越准确 |
| FewCLUE-gen | FewCLUE-gen | 短文 | 文本生成 | 小样本条件下的文本生成任务(如评论生成、摘要生成等) | 小样本下生成任务的文本质量与自然性评估 |
4.2.3 原模型、数据集选择:
数据集选择 FewCLUE_bustm_gen(短文本分类)、FewCLUE_ocnli_fc_gen(自然语言推理)
模型qwen_1.5_0.5b_chat、qwen_1.5_1.8b_chat
使用opencompass:
注意!!!!直接在/root/autodl-tmp/opencompass-main/opencompass-main/opencompass/configs/models下面修改文件,命令并不能指定绝对路径
connfig文件:
from opencompass.models import HuggingFacewithChatTemplate
models = [
dict(
type=HuggingFacewithChatTemplate,
abbr='qwen2.5-0.5b-instruct-hf',
path='/root/autodl-tmp/model/qwen-2.5-0.5b-instruct',
max_out_len=1024,
batch_size=8,
run_cfg=dict(num_gpus=0),
)
]
在/root/autodl-tmp/opencompass-main/opencompass-main下执行。
注意为了好看分行,命令执行的时候删掉换行符!!!!!
python run.py --models hf_qwen2_5_0_5b_instruct.py
--datasets FewCLUE_bustm_gen FewCLUE_ocnli_fc_gen
--debug --work-dir /root/autodl-tmp/opencompass-main/opencompass-main/two_model
python run.py --models hf_qwen2_5_1_5b_instruct.py hf_qwen2_5_7b_instruct.py --datasets FewCLUE_bustm_gen FewCLUE_ocnli_fc_gen --debug --work-dir /root/autodl-tmp/opencompass-main/opencompass-main/two_model
评估结果:
gen生成越高越好,ppl越低越好(客服对话中想让模型回答对应题目的问题)
| dataset | version | metric | mode | qwen2.5-7b-instruct-hf |
|---|---|---|---|---|
| bustm-dev | 5cc669 | accuracy | gen | 83.12 |
| bustm-test | 5cc669 | accuracy | gen | 78.44 |
| ocnli_fc-dev | 51e956 | accuracy | gen | 70.62 |
| ocnli_fc-test | 51e956 | accuracy | gen | 66.71 |
| dataset | version | metric | mode | qwen2.5-0.5b-instruct-hf |
|---|---|---|---|---|
| bustm-dev | 5cc669 | accuracy | gen | 52.50 |
| bustm-test | 5cc669 | accuracy | gen | 50.11 |
| ocnli_fc-dev | 51e956 | accuracy | gen | 38.75 |
| ocnli_fc-test | 51e956 | accuracy | gen | 40.87 |
| dataset | version | metric | mode | qwen2.5-1.5b-instruct-hf |
|---|---|---|---|---|
| bustm-dev | 5cc669 | accuracy | gen | 70.00 |
| bustm-test | 5cc669 | accuracy | gen | 69.81 |
| ocnli_fc-dev | 51e956 | accuracy | gen | 63.12 |
| ocnli_fc-test | 51e956 | accuracy | gen | 60.60 |
4.3 微调框架
Xtuner :主观评价的结果
LLamaFactory:客观loss指标
本文做情感对话模型,倾向看主观评价所以选xtuner。
**注意!!!**使用的数据要单轮还是多轮
一般做对话模型:数据分为单轮和多轮
本文希望做一个类似:小智智能聊天机器人。问一句答一句,没有前后的逻辑推理。
这里使用单轮数据集。
单轮和多轮区别主要是上下文逻辑
4.3.1 Xtuner对话模板!!!
Xtuner对话模板位置
/root/autodl-tmp/xtuner-main/xtuner/utils/templates.py
流程:
- 训练脚本中找prompt_template对应的对话模板
prompt_template = PROMPT_TEMPLATE.qwen_chat
- 去模板中找qwen_chat
qwen_chat=dict(
SYSTEM=("<|im_start|>system\n{system}<|im_end|>\n"),
INSTRUCTION=("<|im_start|>user\n{input}<|im_end|>\n" "<|im_start|>assistant\n"),
SUFFIX="<|im_end|>",
SUFFIX_AS_EOS=True,
SEP="\n",
STOP_WORDS=["<|im_end|>", "<|endoftext|>"],
)
4.3.2 Xtuner训练流程
4.3.2.1 qlora微调
4.3.2.2 模型转换
模型训练后会自动保存成 PTH 模型(例如 iter_2000.pth ,如果使用了 DeepSpeed,则将会是一个 文件夹),我们需要利用 xtuner convert pth_to_hf 将其转换为 HuggingFace 模型,以便于后续使 用。具体命令为:
xtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${SAVE_PATH}
# 例如:xtuner convert pth_to_hf /root/autodl-tmp/xtuner-main/jiaoben/qwen1_5_7b_chat_qlora_alpaca_e3.py /root/work_dirs/qwen1_5_7b_chat_qlora_alpaca_e3/iter_2500.pth /root/autodl-tmp/muhf
4.3.2.3 模型合并
如果使用了 LoRA / QLoRA 微调,则模型转换后将得到 adapter 参数,而并不包含原 LLM 参数。如果您 期望获得合并后的模型权重(例如用于后续评测),那么可以利用 xtuner convert merge :
xtuner convert merge ${基座模型} ${Huggingface模型} ${合并模型路径}
例如:
xtuner convert merge /root/autodl-tmp/model/Qwen2.5-7B-Instruct /root/autodl-tmp/muhf /root/autodl-tmp/mymodel
4.3.2.4 部署
4.4 部署框架
vllm或者lmdeploy,lmdeploy推理效率好一点。本文选的lmdeploy。
4.4.1 Xtuner和Lmdeploy 对话模板对齐!!!
方法一:利用现有对话模板,直接配置一个如下的 json 文件使用
Lmdeploy对话模板标准格式:
{
"model_name": "your awesome chat template name",
"system": "<|im_start|>system\n",
"meta_instruction": "You are a robot developed by LMDeploy.",
"eosys": "<|im_end|>\n",
"user": "<|im_start|>user\n",
"eoh": "<|im_end|>\n",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": "\n",
"capability": "chat",
"stop_words": ["<|im_end|>"]
}
model_name 为必填项,可以是 LMDeploy 内置对话模板名(通过 lmdeploy list 可查阅), 也可以是新名字。其他字段可选填。 当 model_name 是内置对话模板名时,json文件中各非 null 字段会覆盖原有对话模板的对应属性。 而当 model_name 是新名字时,它会把将 BaseChatTemplate 直接注册成新的对话模板。其具体定义可以参考BaseChatTemplate。 这样一个模板将会以下面的形式进行拼接。
{system}{meta_instruction}{eosys}{user}{user_content}{eoh}{assistant}
{assistant_content}{eoa}{separator}{user}...
推理命令:
lmdeploy serve api_server model_dir --chat-template ${JSON_FILE}
例如:lmdeploy serve api_server G:\python_ws_g\code\llm\llmlearning\result\mymodel --chat-template G:\python_ws_g\code\llm\llmlearning\LLMlearn\emo_conversation_project\template_trans\a.json
lmdeploy serve api_server /root/autodl-tmp/mymodel --chat-template /root/autodl-tmp/a.json --quant-policy 8
也可以在通过接口函数传入,比如:
from lmdeploy import ChatTemplateConfig, serve
serve('internlm/internlm2_5-7b-chat',
chat_template_config=ChatTemplateConfig.from_json('${JSON_FILE}'))
方法二:以 LMDeploy 现有对话模板,自定义一个python对话模板类,注册成功后直接用即可。
from lmdeploy.model import MODELS, BaseChatTemplate
@MODELS.register_module(name='customized_model')
class CustomizedModel(BaseChatTemplate):
"""A customized chat template."""
def __init__(self,
system='<|im_start|>system\n',
meta_instruction='You are a robot developed by LMDeploy.',
user='<|im_start|>user\n',
assistant='<|im_start|>assistant\n',
eosys='<|im_end|>\n',
eoh='<|im_end|>\n',
eoa='<|im_end|>',
separator='\n',
stop_words=['<|im_end|>', '<|action_end|>']):
super().__init__(system=system,
meta_instruction=meta_instruction,
eosys=eosys,
user=user,
eoh=eoh,
assistant=assistant,
eoa=eoa,
separator=separator,
stop_words=stop_words)
对话模板转换脚本:
import json
# 原始模板
original_template = dict(
SYSTEM=("<|im_start|>system\n{system}<|im_end|>\n"),
INSTRUCTION=(
"<|im_start|>user\n{input}<|im_end|>\n"
"<|im_start|>assistant\n"
),
SUFFIX="<|im_end|>",
SUFFIX_AS_EOS=True,
SEP="\n",
STOP_WORDS=["<|im_end|>", "<|endoftext|>"],
)
# 转换为目标格式
converted_template = {
"model_name": "your awesome chat template name",
"system": "<|im_start|>system\n",
"meta_instruction": "You are a robot developed by LMDeploy.",
"eosys": "<|im_end|>\n",
"user": "<|im_start|>user\n",
"eoh": "<|im_end|>\n",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": original_template.get("SEP", "\n"),
"capability": "chat",
"stop_words": ["<|im_end|>"]
}
# 保存为 JSON 文件
save_path = r"G:\python_ws_g\code\llm\llmlearning\LLMlearn\emo_conversation_project\template_trans\a.json"
try:
with open(save_path, 'w', encoding='utf-8') as f:
json.dump(converted_template, f, indent=4, ensure_ascii=False)
print(f"转换后的模板已成功保存到 {save_path}")
except Exception as e:
print(f"保存失败: {e}")
json结果:
{
"model_name": "zyhhsss",
"system": "<|im_start|>system\n",
"meta_instruction": "You are a robot developed by LMDeploy.",
"eosys": "<|im_end|>\n",
"user": "<|im_start|>user\n",
"eoh": "<|im_end|>\n",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": "\n",
"capability": "chat",
"stop_words": [
"<|im_end|>"
]
}
转换例子2:
xtuner的对话模板
qwen_chat=dict(
SYSTEM=("<|im_start|>system\n{system}<|im_end|>\n"),
INSTRUCTION=("<|im_start|>user\n{input}<|im_end|>\n" "<|im_start|>assistant\n"),
SUFFIX="<|im_end|>",
SUFFIX_AS_EOS=True,
SEP="\n",
STOP_WORDS=["<|im_end|>", "<|endoftext|>"],
)
lmdeploy的json:
{
"model_name": "your awesome chat template name",
"system": "<|im_start|>system\n",
"meta_instruction": "You are a robot developed by LMDeploy.",
"eosys": "<|im_end|>\n",
"user": "<|im_start|>user\n",
"eoh": "<|im_end|>\n",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": "\n",
"capability": "chat",
"stop_words": ["<|im_end|>"]
}
转换脚本:
import json
import re
def convert_xtuner_to_lmdeploy(xtuner_template: dict, model_name="converted_model"):
system_pattern = xtuner_template.get("SYSTEM", "")
instruction_pattern = xtuner_template.get("INSTRUCTION", "")
suffix = xtuner_template.get("SUFFIX", "")
separator = xtuner_template.get("SEP", "\n")
stop_words = xtuner_template.get("STOP_WORDS", [])
# 提取 meta_instruction 内容(如 {system})
meta_instruction_match = re.search(r"{(\w+)}", system_pattern)
meta_instruction = f"{{{meta_instruction_match.group(1)}}}" if meta_instruction_match else ""
lmdeploy_template = {
"model_name": model_name,
"system": system_pattern.split("{")[0] if "{" in system_pattern else "",
"meta_instruction": meta_instruction,
"eosys": suffix + "\n",
"user": instruction_pattern.split("{input}")[0] if "{input}" in instruction_pattern else "",
"eoh": suffix + "\n",
"assistant": re.split(re.escape(suffix), instruction_pattern.split("{input}")[-1])[0]
if "{input}" in instruction_pattern else "",
"eoa": suffix,
"separator": separator,
"capability": "chat",
"stop_words": stop_words
}
return lmdeploy_template
# 示例 xtuner 模板
xtuner_chat = dict(
SYSTEM=("<|im_start|>system\n{system}<|im_end|>\n"),
INSTRUCTION=("<|im_start|>user\n{input}<|im_end|>\n<|im_start|>assistant\n"),
SUFFIX="<|im_end|>",
SUFFIX_AS_EOS=True,
SEP="\n",
STOP_WORDS=["<|im_end|>", "<|endoftext|>"],
)
# 转换
lmdeploy_json = convert_xtuner_to_lmdeploy(xtuner_chat, model_name="qwen_chat")
# 保存为 JSON 文件
with open("qwen_chat_lmdeploy_template.json", "w", encoding="utf-8") as f:
json.dump(lmdeploy_json, f, indent=4, ensure_ascii=False)
print("转换完成!结果已保存为 qwen_chat_lmdeploy_template.json")
转换结果:
{
"model_name": "qwen_chat",
"system": "<|im_start|>system\n",
"meta_instruction": "{system}",
"eosys": "<|im_end|>\n",
"user": "<|im_start|>user\n",
"eoh": "<|im_end|>\n",
"assistant": "",
"eoa": "<|im_end|>",
"separator": "\n",
"capability": "chat",
"stop_words": [
"<|im_end|>",
"<|endoftext|>"
]
}
✅ 字段映射解释:
| xtuner 字段 | lmdeploy 字段 | 说明 |
|---|---|---|
SYSTEM | system + meta_instruction | 前缀是 system 字段,内容是 meta_instruction |
INSTRUCTION | user + eoh + assistant | 模板中用户提问(user)、助手回应(assistant) |
SUFFIX | eoa | assistant 结束标识符 |
SEP | separator | 对话分隔符 |
STOP_WORDS | stop_words | 停止生成的标记 |
SUFFIX_AS_EOS | 自动体现在 stop_words | 无需额外字段,`< |
4.5 前端界面(Streamlit)
4.6 傻瓜式操作手册
xtuner脚本
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (
CheckpointHook,
DistSamplerSeedHook,
IterTimerHook,
LoggerHook,
ParamSchedulerHook,
)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (
DatasetInfoHook,
EvaluateChatHook,
VarlenAttnArgsToMessageHubHook,
)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = "/root/autodl-tmp/model/Qwen2.5-7B-Instruct"
use_varlen_attn = False
# Data
data_files = '/root/autodl-tmp/xtuner-main/data/wenrou.json'#数据集
prompt_template = PROMPT_TEMPLATE.qwen_chat
max_length = 150
pack_to_max_length = True
# parallel
sequence_parallel_size = 1
# Scheduler & Optimizer
batch_size = 15 # per_device
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 3000
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03
# Save
save_steps = 500
save_total_limit = 4 # Maximum checkpoints to keep (-1 means unlimited)
# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = ["闺蜜把我秘密当谈资,该不该撕破脸?",
"老妈非让我嫁给她同事儿子,怎么逃啊!",
"同事抢功时故意提高音量,要当场揭穿吗?",
"男朋友给女主播刷火箭,算精神出轨吗?",
"室友半夜和对象视频娇喘,怎么提醒?",
"亲戚说我不生孩子就是自私,好想掀桌!",
"大学生毕业工资不够找我,我给你补个蛋"]
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
padding_side="right",
)
model = dict(
type=SupervisedFinetune,
use_varlen_attn=use_varlen_attn,
llm=dict(
type=AutoModelForCausalLM.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16,
quantization_config=dict(
type=BitsAndBytesConfig,
load_in_4bit=False,
load_in_8bit=True,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
),
),
lora=dict(
type=LoraConfig,
r=64,
lora_alpha=128,
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
),
)
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
dataset=dict(type=load_dataset, path="json",data_files=data_files),
tokenizer=tokenizer,
max_length=max_length,
dataset_map_fn=None,
template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn,
)
sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=alpaca_en,
sampler=dict(type=sampler, shuffle=True),
collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn),
)
#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(
type=AmpOptimWrapper,
optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),
clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),
accumulative_counts=accumulative_counts,
loss_scale="dynamic",
dtype="float16",
)
# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [
dict(
type=LinearLR,
start_factor=1e-5,
by_epoch=True,
begin=0,
end=warmup_ratio * max_epochs,
convert_to_iter_based=True,
),
dict(
type=CosineAnnealingLR,
eta_min=0.0,
by_epoch=True,
begin=warmup_ratio * max_epochs,
end=max_epochs,
convert_to_iter_based=True,
),
]
# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)
#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [
dict(type=DatasetInfoHook, tokenizer=tokenizer),
dict(
type=EvaluateChatHook,
tokenizer=tokenizer,
every_n_iters=evaluation_freq,
evaluation_inputs=evaluation_inputs,
system=SYSTEM,
prompt_template=prompt_template,
),
]
if use_varlen_attn:
custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type=IterTimerHook),
# print log every 10 iterations.
logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),
# enable the parameter scheduler.
param_scheduler=dict(type=ParamSchedulerHook),
# save checkpoint per `save_steps`.
checkpoint=dict(
type=CheckpointHook,
by_epoch=False,
interval=save_steps,
max_keep_ckpts=save_total_limit,
),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type=DistSamplerSeedHook),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method="fork", opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend="nccl"),
)
# set visualizer
visualizer = None
# set log level
log_level = "INFO"
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
# set log processor
log_processor = dict(by_epoch=False)
微调项目总结:
qwen-1.8b 4090 6h 最终loss 0.09