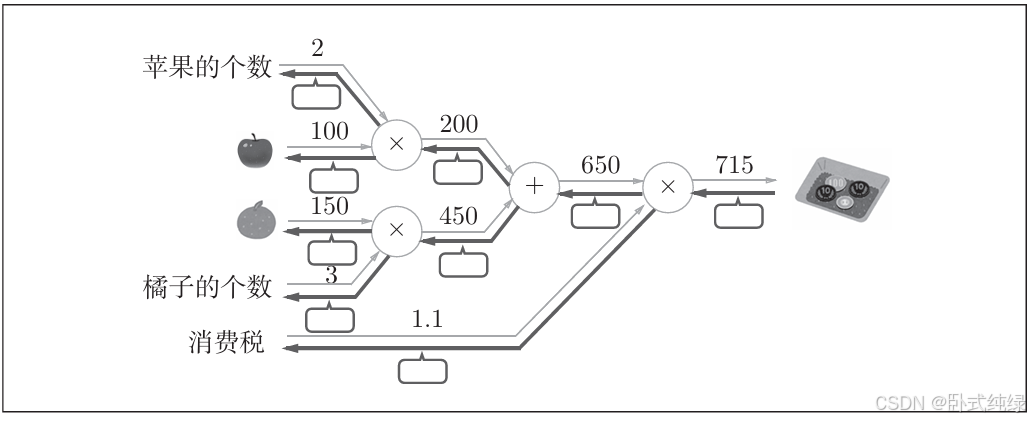
6、锁
1、分类:
- 全局锁:锁住数据库中的所有表
- 表级锁:每次操作锁住整张表
- 行级锁:每次操作锁住对应行的数据
2、全局锁
加锁后,整个实例只能进行读取操作,从而保证数据的完成性和一致性。
特点:
- 如果在主库上备份,那末在设备备份期间都不能执行更新操作,业务基本上就得停摆。
- 如果在从库上备份,那末在备份期间从库不能执行主库同步过来的二进制日志,会导致主从延迟
innoDB引擎中,可以通过参数来实现不加锁的一致性数据备份: --single-transaction
3、表级锁
分类:
- 表锁
- 表共享读锁
- 不会阻塞其他客户端的读取操作,会阻塞其他数据的写锁操作。同时,当前客户端也不能进行修改、增新操作。
- 表独占写锁
- 当前客户端既能读也能写,其他客户端,既不能读,也不能写。
- 语法:
- 加锁:
lock tables 表明... read/write - 解锁:
unlock tables 或者 客户端连接断开
- 加锁:
- 表共享读锁
- 元数据锁
-
元数据锁简称:
MDL,是系统自动加上的锁,MDL锁主要作用是维护表元数据的一致性,在表上有活动事务时,不可以对元数据进行写入操作,为了避免DML,与DDL的冲突,保证读写的正确性 -
元数据锁的分类:
- 在MySQL5.5中,引入了MDL。
- 当对一张表进行增删改查的时候,加MDL读锁(共享锁)
- 当对表结构变更操作时,加MDL写锁(排他锁)
-
解读(意思就是):当开启一个事务时,并执行增删改查的操作时,元数据锁就会自动加上,但是,这是共享锁,也就是,两个事务都可以查询,修改操作,但是如果另一个连接想要修改表结构,那末就会处于阻塞状态,因为修改表结构的加的是排他锁,与共享读锁互斥,因此处于阻塞状态,直到事务被提交后,才能修改表结构。
-
- 意向锁
- 为了避免DML在执行时,加的行锁与表锁的冲突,在innoDB中引入了意向锁,使得表锁不用检查每行数据是否加锁,使用意向锁来减少表锁的检查。意向锁表示,需要在哪一行上进行的操作。
- 执行情况:
- 原来:当执行根据id更新数据库表中的某一行数据时,会在这一行加上行锁,但是当另一个客户端需要加表锁的时候,会逐行检查是否有行锁的存在。效率极低。
- 现在(加了意向锁后):当加行锁的时候,同时会给这张表加上意向锁,当另一个客户端需要加表锁的时候,就会先去检查这个意向锁是否与自己要获取的锁兼容,如果兼容,获取锁成功,如果不兼容,获取锁失败。
- 意向锁的分类:
- 意向共享锁:与表锁共享锁(读锁)兼容,与表锁排他锁互斥(写锁)
- 意向排他锁:与表锁共享锁(读锁)、表锁排他锁都互斥(写锁),但是意向锁之间不会互斥。
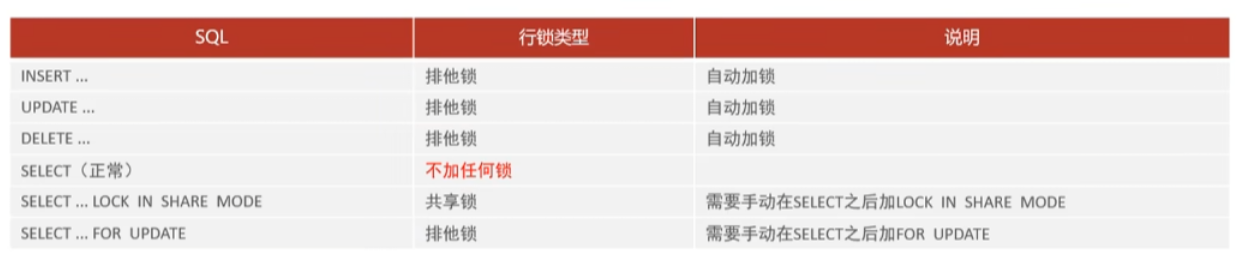
4、行级锁
- 每次操作对应的行数据,锁的粒度最小,发生所冲突的概率低,应用在innoDB引擎中。行锁主要是通过对索引的索引项加锁来实现的,而不是对记录加的锁
- 分类:
-
行锁:锁定单个记录的锁,防止其他事务对此进行的更新、删除操作。在RC,RR的隔离级别下都支持。
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。(共享锁和共享锁兼容,与排他锁互斥)
- 排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。(与共享锁和排他锁都互斥)
-
间隙锁:锁定索引记录的间隙,确保索引记录的间隙不变,防止其他事务在这个间隙进行插入操作,防止出现幻读。仅在RR的隔离级别下支持。
- 索引上的等值查询(唯一索引),给不存在的记录加锁时,优化为间隙锁。
- 比如:数据库中有3,5的索引,但是我更新的数据的id为4的时候,显然 4 不存在,此时会在3、5之间的间隙加上锁,及其他事务不能插入3、5之间。
- 索引上的等值查询(普通索引),向右遍历时,最后一个值不满足查询条件时,会退化为间隙锁。
- 索引上的范围查询(唯一索引),会访问到不满足条件的第一个值为止,也会加上临键锁
- 索引上的等值查询(唯一索引),给不存在的记录加锁时,优化为间隙锁。
-
临键锁:行锁和间隙锁的结合,可以锁住间隙并且可以锁住间隙。仅在RR隔离级别下支持,间隙锁可以共存。
-
**注意:**行级锁 和 元数据锁 可以同时持有,当插入数据时,MySQL 会自动加上行级锁,同时也会加上元数据锁,这样,行级锁保证事务的隔离性,元数据锁保证表结构的稳定性。
7、InnoDB引擎详解
1、逻辑存储结构
1、逻辑存储结构图:
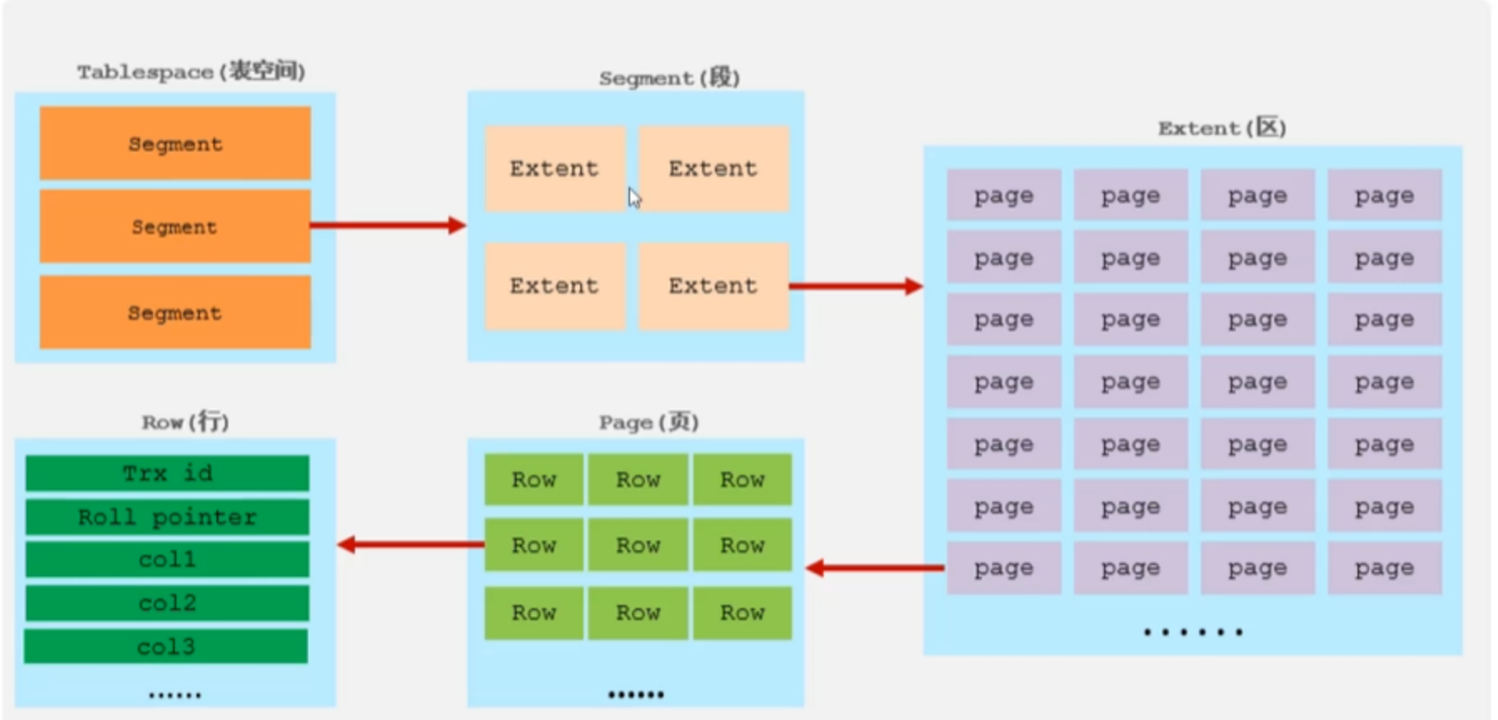
2、结构的存储特点:
- 表空间:
- 表空间对应一个(ibd)文件,一个mysql实例可以对应多个表空间,用于储存记录,索引等数据信息。
- 段:
- 数据段、索引段、回滚段,innoDB是索引组织表,数据段就是B+树的叶子节点、索引段即为B+树的非叶子节点。段用来管理多个区。
- 区:
- 表空间的单元结构,每个区的大小为 1M,默认情况下,InnoDB 存储引擎页大小为 16 K,集一个区中一共有64个连续的页。
- 页:
- 是innoDB 存储引擎磁盘管理的最小单位,每个页的大小默认为16kB。为保证页的连续性,InnoDB 存储引擎每次从磁盘申请4-5个区。
- 行:
- innoDB 存储的数据
2、架构
1、内存结构:
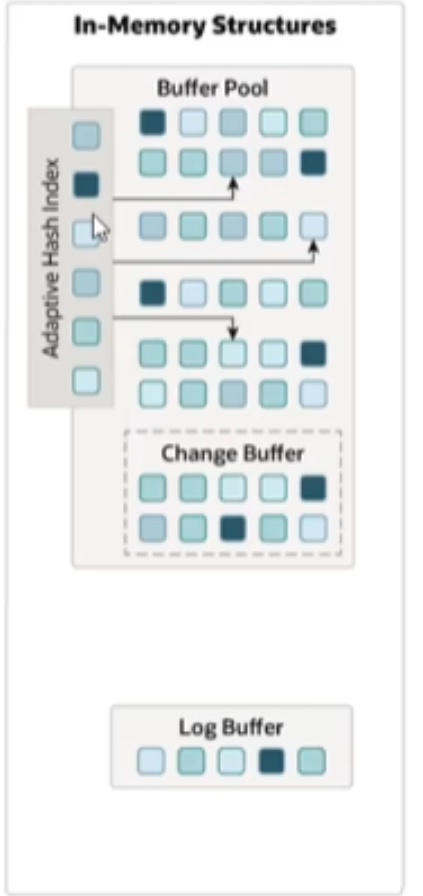
Buffer Pool:- 缓冲区是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池中没有数据,则从磁盘上加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
- 缓冲池以Page页为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三种类型:
free page:空闲page,未被使用。clean page:被使用page,数据没有修改过。dirty page:脏页,被使用page,数据被修改过,也是数据与磁盘的数据产生了不一致。
Change Buffer:更改缓冲区(针对于非聚集索引,二级索引),在执行DML语句时,如果这些Page没有在Buffer Pool中,不会直接操作磁盘,而是将数据变更存在数据变更区,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。Adaptive Hash index:自适应hash索引,用于优化对Buffer Pool数据的查询。innoDB存储引擎会监控对表上个索引页的查询,如果观察到hash索引可以提升速度,则建立hash索引,称之为自适hash索引。- 自适应hash索引,无需人工干预,是系统根据情况自动完成。
log buffer:- 日志缓冲区,用来保存要写入到磁盘中的
log日志数据,默认大小为16MB,日志缓冲区的日志会定期刷新到磁盘中,如果需要更新,插入,或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘I/O
- 日志缓冲区,用来保存要写入到磁盘中的
2、磁盘结构
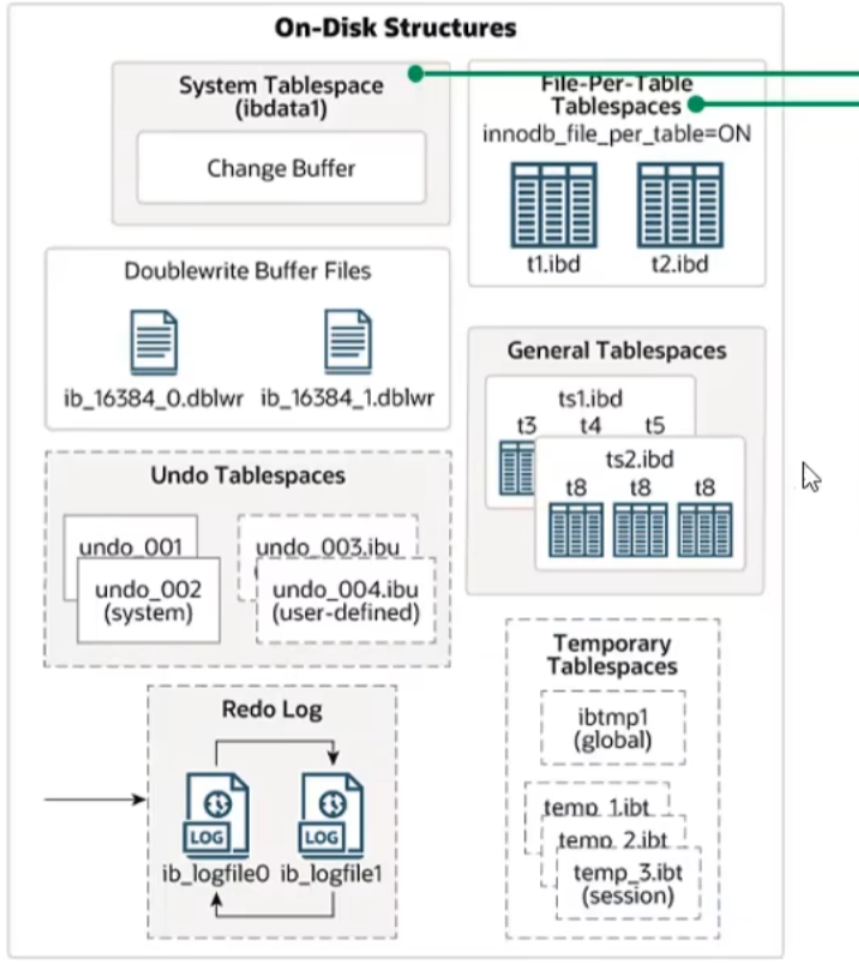
System Tablespace:系统表空间是更改缓冲区的存储区域,如果表是在系统表空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引结构。File-Per-Table Tablespaces:每个表的文件表空间包含单个innoDB表的数据和索引,并存储在文件系统上的每个数据文件中。General Tablespaces:通用表空间,需要通过CREATE TABLESPACE 语法建造,在创建表时,可以指定该表的空间Undo Tablespaces:撤销 表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间,用于初储存undo log 日志Temporary Tablespaces:InnoDB 使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。Doublewrite Buffer Files:双写缓存区,innoDB 引擎将数据页从Buffer Pool 刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。#ib_16384_0.dblwr、#ib_16384_1.dblwrRedo Log:重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲以及重做日志文件,前者是内存,后者是磁盘中。当事务提交后,会把所有修改信息都会存到该日志中,用于在刷新脏页的磁盘时,发生错误时,进行数据的恢复。
3、后天线程
1、后台线程的作用:用于将缓冲池中的数据,再合适的时机写入到磁盘文件中。
2、后台线程:
-
Master Thread核心后台线程,负责调度其他线程,还负责将缓冲区中的数据异步刷新到磁盘中,保持数据的一致性。还包括脏页的刷新,合并插入缓存、undo 页的回收。
-
IO Thread在InnoDB 存储引擎中,使用了大量的AIO**(异步io)**来处理IO请求,这样可以极大地提高数据库的性能,而IO Thread 只要负责这些IO请求的回调。
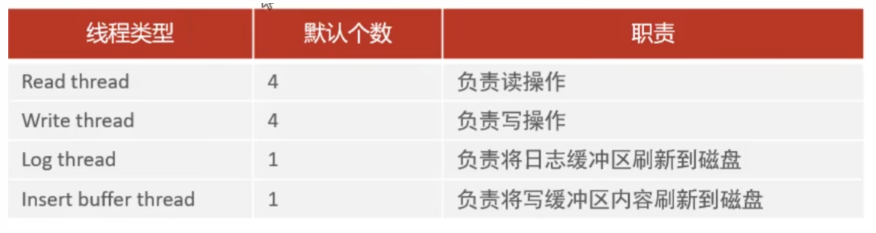
-
Purge Thread主要用于回收事务已经提交了的 undo log ,在事务提交后,undo log 可能不用了,就用它来回收。
-
Page Cleaner Thread协助Master Thread 刷新脏页到磁盘的线程,它可以减轻Master Thread 的工作压力,减少阻塞
3、事务的原理
1、基本概述
- 原子性、一致性、持久性:是通过底层的两个日志文件来实现的,redo log 、undo log
- 隔离性:是通过锁机制和MVCC(多版本并发控制)来实现的。
2、详细解释
- 持久性
- 利用
redo log实现。重做日志,记录事务提交时的数据物理页修改,是用来实现事务持久化。 - 该日志主要分为两个部分
- 重做缓冲日志:
redo log buffer,存在于内存中,记录事务提交时的物理修改。 - 重做日志文件:
redo log file,存在于磁盘中。
- 重做缓冲日志:
- 过程:当对缓冲区的数据进行增删改之后,会首先将数据页的变化记录到
redo log buffer中,在事务提交后,会直接将redo log buffer中的数据刷新到磁盘文件中,之后在脏页刷新的时候出错了,就可以通过redo log file来进行恢复。 - 注意:为什么不在提交事务的时候直接将脏页刷新到磁盘,而是通过
redo log来实现,因为,直接刷新存在严重的性能问题因为一个事务中,一定包含很多条语句,每条语句的数据不一定相同,会涉及到很多随机磁盘IO,而log都是追加的,因此是顺序磁盘IO同时redo log记录的是,某个页的某个数据从什么值变成什么值。
- 利用
- 原子性
undo log用于回滚日志,记录数据被修改前的信息,作用包含两个:提供回滚和MVCC(多版本并发控制)undo log是逻辑日志。可以认为当delete一条记录时,undo log会记录一条对应的 insert 记录,反之亦然,当update一条记录时,他记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录中读取到相应的内容,并进行回滚,从而保证数据的原子性(主要时回滚),实际上就是记录的是旧版本的数据。Undo log销毁:undo log在事务执行时产生,,事务提交时,并不会立即删除,因为这些事务有肯能涉及到MVCCUndo log存储:undo log采用段的方式进行回滚和记录,存放在rollback、segment回滚段中,内部包含1024个undo log segment
4、MVCC
1、MVCC-基本概念
-
当前读
-
读取的时记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁,对于我们日常的操作,如:
select … lock in share mode(共享锁),等就是一种当前读。
-
-
快照读
- 简单的 select(不加锁) 就是快照读,快照读的就是记录的可见版本,有可能是历史版本,不加锁,是非阻塞读。`
Read Committed(读已提交):每次select都生成一个快照Repeatable Read(可重复读):开启事务后的第一条select语句就是快照读,后续的select语句读取的就是第一次的快照因此才实现的可重复读。Serializable:快照读会退化为当前读
- 简单的 select(不加锁) 就是快照读,快照读的就是记录的可见版本,有可能是历史版本,不加锁,是非阻塞读。`
-
MVCC
- 全称
Multi-Version-Concurrency Contry,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、undo log 、readView
- 全称
2、MVCC-实现原理
-
记录中的隐藏字段
DB_TRX_ID:最近修改事务ID,记录插入这条记录或最后一次修改该条记录的事务ID。DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本。DB_ROW_ID:隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。
在 MySQL 中可以使用 ibd2sdi xxx.ibd 来查看ibd文件
-
undo log
-
回滚日志,在insert、update、delete 的时候产生的便于数据回滚的日志。
当
insert的时候,产生的undo log 日志只在回滚时需要,在事务提交后,可被立即删除。而update、delete的时候产生的日志,不仅在回滚的时候需要,在快照读时也需要,不会被立即删除。
-
-
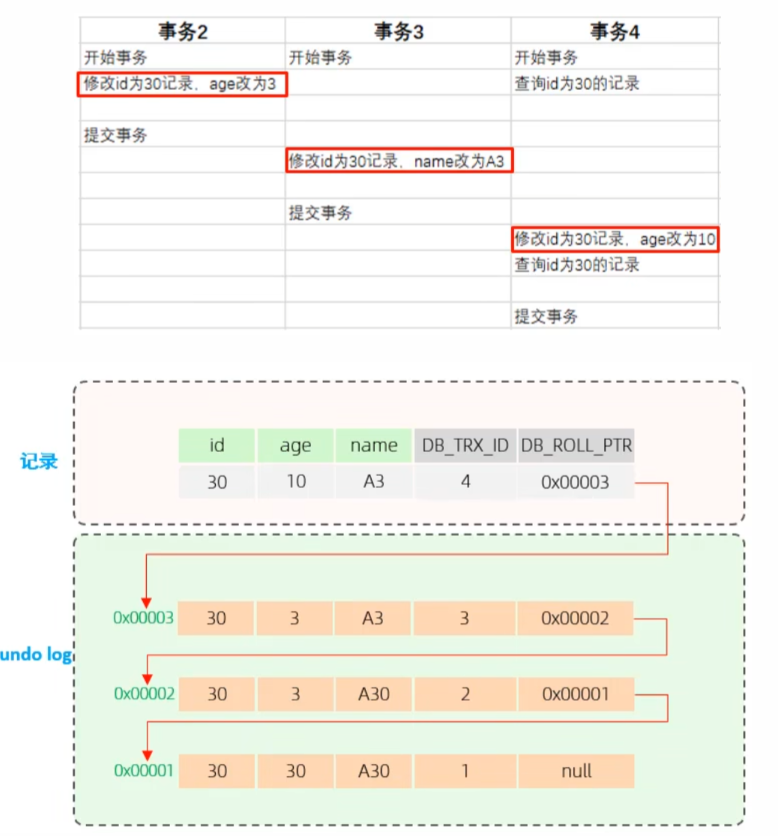
undo log 版本链
不同事务或相同事务对同一条记录进行修改,会导致该记录的undo log 产生一条记录版本链,链表的头部是最新的旧记录,链表尾部是最早的旧记录。
-
readview
ReadView(读视图)是 快照读 ,就是一个快照,在进行快读时生成,SQL执行时MVCC提取数据的依据,记录并维护系统中当前活跃的事务(未提交)id。- 包含四个核心字段
m_ids:当前活跃的事务id集合min_trx_id:最小活跃事务idmax_trx_id:预分配事务id,当前最大事务id + 1creator_trx_id:ReadView 创建者 id,每个快照读都会生成一个ReadView视图,因此都有一个对应的 creator_trx_id也即是当前事务的 id,这个字段只是存一下而不是生成,每个事务开始时,都生成自己对应的id
- 具体的undo log 数据链访问规则。
- 首先明确
trx_id:就是数据库中该行数据的隐藏字段DB_TRX_ID的值。
 - 生成时机:
- 生成时机: Read Committed(读已提交):在事务中,每次执行快照读,都会生成Repeatable Read(可重复读):仅在第一次快照都时生成,后续复用(注意:这里复用的只是ReadView,而不是数据,因为后续如果两次查询中间本事务修改了,也会读取到本事务修改后的数据,因为第一条规则),因为只有第一次时快照读,同时,如果在两次查询中间修改了该条数据,由于第一条匹配规则,还是会读取当前事务所修改的记录,而不是旧的数据(有解释一遍)。
- 首先明确
![[Swift]pod install成功后运行项目报错问题error: Sandbox: bash(84760) deny(1)](https://i-blog.csdnimg.cn/direct/7e137ccdde864b25801967e4e8484698.png)