共享单车出行规律与决定因素的空间交互分析——以北京六大区为例
原文:Spatial Interaction Analysis of Shared Bicycles Mobility Regularity and Determinants: A Case Study of Six Main Districts, Beijing
这篇文章主要研究了北京六个主要城区共享单车的流动规律和影响因素,通过构建空间交互网络和使用指数随机图模型(ERGM)进行分析。以下是文章的主要内容和发现:
1.研究背景和目的
- 自2014年以来,共享单车作为一种新型的“互联网+共享”出行模式逐渐兴起,尤其是在新冠疫情期间,共享单车系统(BSS)成为一种广泛流行的可持续出行方式。
- 研究共享单车的流动规律和影响因素对于合理部署共享单车和城市规划至关重要。
好的,以下是对文章研究方法部分的详细介绍:
2. 研究区域和数据来源
2.1 研究区域选择
- 选取北京的六个主要城区(东城、西城、海淀、丰台、石景山和朝阳)作为研究区域,这六个城区是北京的核心功能区,集中了约60%的北京总人口和近70%的产业,人口密集、流动复杂。
2.2 数据来源
- 共享单车数据:使用与企业合作的共享单车数据,包含自行车ID号、时间、经纬度等属性,数据采集时间间隔为3小时,通过关联同一自行车在不同时间的位置点,确定其起始点和终点,生成轨迹数据。数据采集时间为5月至8月,排除异常天气等因素后,选取5月17日至23日这一周的数据进行分析,其中17日至21日为工作日,22日和23日为周末。
- 其他数据:包括POI数据(如交通设施、金融服务、住宅区、购物餐饮、教育机构等的空间分布信息)、路网数据(城市道路、地铁等不同等级道路数据)、建筑数据和各街块的房价数据等,用于分析共享单车的出行模式及其影响因素。
2.3 旅行网络构建
- 网络结构组成:将居民的出行活动视为网络中的边,街道作为网络中的节点,形成一个有向网络。边的方向代表出行活动的方向,边的权重则表示出行活动的数量。
- 网络构建过程:通过关联同一自行车在不同时间的位置点,确定其在街块内的起始点和终点,从而生成街道之间的出行轨迹。以这些轨迹为基础,构建出以街道为节点的旅行网络。
2.4 旅行网络特征描述
- 网络密度:用于衡量网络中节点之间的连接程度,计算公式为网络中实际存在的边数与可能存在的最大边数之比。网络密度越大,说明网络结构越复杂,节点之间的联系越紧密,相互影响程度越高。
- 节点强度:分为入强度和出强度,分别表示流入和流出某节点的边的权重之和。通过计算节点的入强度和出强度,可以进一步得到净流量比率(NFR),用于衡量节点的受欢迎程度。若NFR大于0,说明该节点的流入强度大于流出强度,受欢迎程度较高;反之则较低。
2.5 旅行网络影响因素分析
-
指数随机图模型(ERGM):ERGM是一种用于分析关系数据的统计模型,能够解释网络结构的形成和内部机制。它将网络视为一种随机图,并通过一系列网络结构统计量来描述网络的特性和形成机制。模型的基本形式为:
P θ ( M = m ) = 1 k exp ( ∑ H θ H g H ( m ) ) P_\theta (M = m) = \frac{1}{k} \exp \left( \sum_H \theta_H g_H(m) \right) Pθ(M=m)=k1exp(H∑θHgH(m))
其中,( g(m) ) 表示与矩阵 ( m ) 相关的网络统计量, θ \theta θ 是相关网络统计量的估计参数向量。若参数为正(负),表示在控制其他统计量的情况下,该统计量出现的概率比随机预期更高(低),对网络结构的形成有正(负)影响。 -
变量选择:
- 网络结构变量:包括边的数量、相互性、传递性等,用于描述网络的基本结构特征。
- 节点属性变量:包括房价、建筑密度、路网密度、交通设施、购物餐饮场所、金融服务、住宅区、教育机构等,这些变量反映了街道的不同特征和属性,可能对共享单车的出行行为产生影响。
-
模型训练和评估:使用R语言中的statnet包进行ERGM模型的估计、模拟、比较和测试。采用经典马尔可夫链蒙特卡洛最大似然估计(MCMC MLE)方法训练模型参数,并以赤池信息准则(AIC)和贝叶斯信息准则(BIC)作为模型拟合效果的评估指标,指标值越小,模型效果越好。
3. 结论
3.1 网络结构分析
- 网络结构差异:基于不同时间段的数据构建了共享单车旅行网络,该网络包含122个节点,每个节点代表一个街块。工作日的网络结构显示,大多数旅行活动发生在相邻的街道之间,这验证了共享单车通常是一种短距离出行方式的特点。在工作日期间,某些街道如Huaxiang District Office和Xincun Sub-district Office的交通流量较大,这可能是因为人们的出行目的通常与工作相关,共享单车被用作短距离通勤工具。相比之下,周末的网络结构更为复杂,旅行流量涉及多个街块的情况明显多于工作日,这表明更多人选择在周末使用共享单车进行长距离出行,且出行目的地的多样性增加。
- 流量强度差异:通过比较工作日和周末的网络结构图,可以看出工作日的流量强度相对集中在特定区域,而周末的流量则更为分散,且街块之间的互动更强。
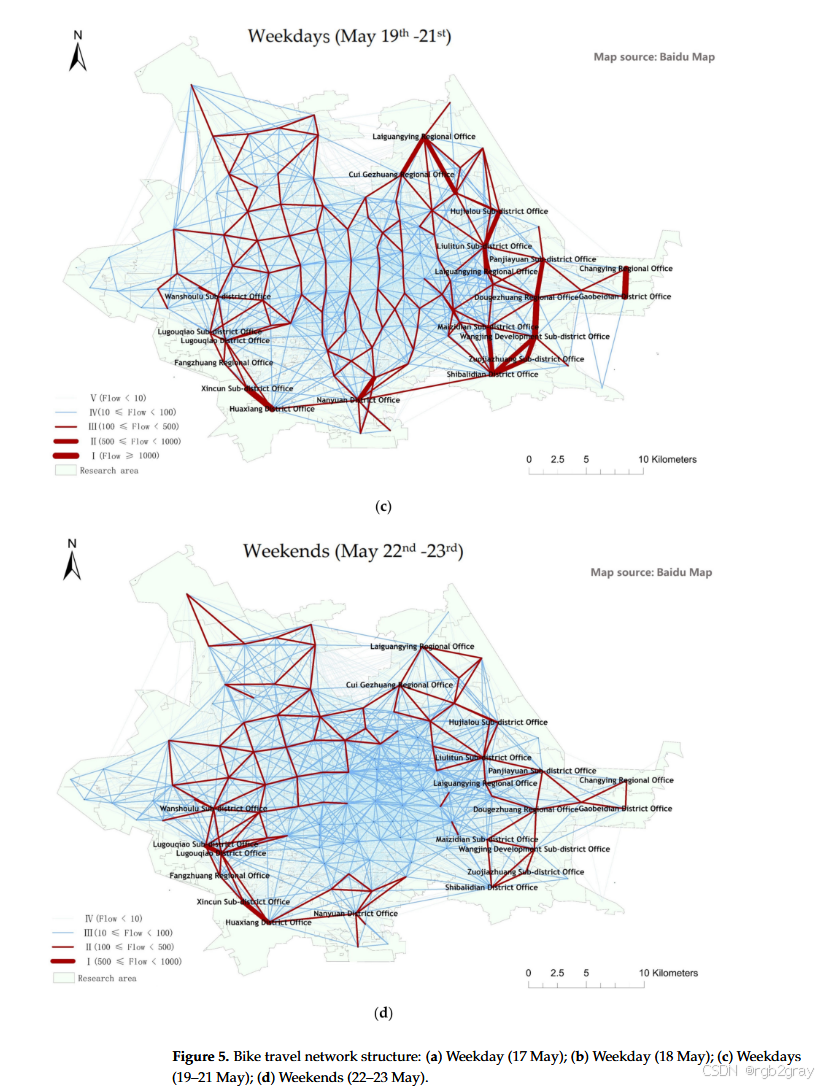
3.2 旅行网络特征分析
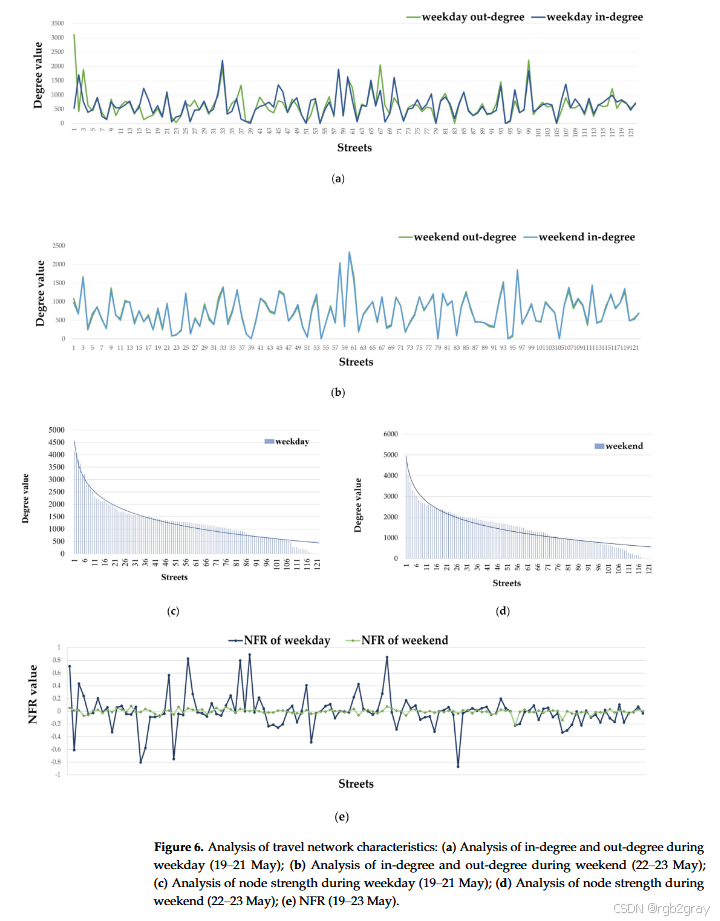
- 网络密度和节点可访问性:计算了工作日和周末的空间交互网络的网络密度和节点可访问性。结果表明,周末的网络密度大于工作日,这表明周末各街道之间的互动更为活跃,流量也更大。此外,工作日同一街块的入度和出度差异较大,而周末同一街块的入度和出度较为接近,这反映了居民在工作日和周末的出行目的存在明显差异。
- 节点强度分布:无论是在工作日还是周末,大多数街块的节点强度呈现出幂律分布,符合复杂网络的无标度特性。这表明少数街块具有较高的节点强度,而大多数街块的节点强度接近平均水平。
- 净流量比率(NFR):工作日的NFR值差异较大,许多街道的NFR值显示出较大的正负值,这说明在工作日,某些街道可能是就业集中区,而另一些街道可能是居住集中区。居民在工作日的出行目的较为明确,从居住区到就业区的出行流量较大。而在周末,各街块的NFR值波动较小,这表明各街块的流入和流出流量大致相等,居民的出行模式相对复杂,出行目的更加多样化。
3.3 旅行网络影响因素分析
- ERGM模型结果:使用R语言的statnet包对ERGM模型进行估计,采用经典马尔可夫链蒙特卡洛最大似然估计(MCMC MLE)方法训练模型参数,并以赤池信息准则(AIC)和贝叶斯信息准则(BIC)作为模型拟合效果的评估指标。模型结果表明,所有选取的影响因素都对共享单车旅行网络的形成具有正向影响。
- 影响因素的重要性排序:建筑密度(Bden)的影响系数最大,无论是工作日还是周末,建筑密度对出行行为的促进作用都最为显著。其次,房价(Price)和住宅区数量(Res)的影响系数也较高,仅次于建筑密度。这表明街道的建筑密度、房价和住宅区数量是影响共享单车出行的关键因素。
- 时间差异分析:比较工作日和周末的影响因素系数,发现金融服务(Fin)在工作日对共享单车出行的影响大于其他因素,而在周末,金融服务、路网密度(Rden)、交通设施(Tra)、购物餐饮(SaD)和教育机构(Edu)的影响系数较为接近,表明周末共享单车旅行网络的形成是多种因素共同作用的结果。
4. 研究意义
- 该研究不仅为共享单车的合理布局和相关政策的制定提供了重要参考,还为其他城市的共享单车系统建设提供了借鉴。
- 研究结果有助于优化共享单车的调度和管理,提高其利用率,缓解城市交通压力。
5. 研究局限和未来方向
- 文章指出,未来的研究可以进一步扩展影响因素的范围,细化数据属性,并改进复杂网络的构建方法。
- 建议增加居民属性数据,如职业、性别和年龄,以更准确地分析出行目的。
- 提出未来研究可以使用公共数据集来提高研究的可重复性,并扩大时间覆盖范围以发现更有价值的出行规律。
6.例子
好的,以下是一些与文章内容相关的 Python 代码示例,这些代码涵盖了数据预处理、网络构建、特征计算和可视化等方面。
1. 数据预处理
import pandas as pd
import numpy as np
from datetime import datetime
# 读取共享单车数据
bike_data = pd.read_csv('shared_bike_data.csv')
# 转换时间格式
bike_data['timestamp'] = pd.to_datetime(bike_data['timestamp'])
# 按时间间隔(3小时)分组
time_intervals = pd.date_range(start='2023-05-17', end='2023-05-23', freq='3H')
bike_data['time_interval'] = pd.cut(bike_data['timestamp'], bins=time_intervals, include_lowest=True)
# 确定起始点和终点
bike_data = bike_data.sort_values(by=['bike_id', 'timestamp'])
bike_data['next_lon'] = bike_data.groupby('bike_id')['lon'].shift(-1)
bike_data['next_lat'] = bike_data.groupby('bike_id')['lat'].shift(-1)
# 生成轨迹数据
trajectories = bike_data[['bike_id', 'lon', 'lat', 'next_lon', 'next_lat', 'time_interval']].dropna()
2. 网络构建
import networkx as nx
# 创建有向图
G = nx.DiGraph()
# 添加节点(街块)
street_blocks = trajectories['start_street_block'].unique()
for block in street_blocks:
G.add_node(block)
# 添加边(出行轨迹)
for _, row in trajectories.iterrows():
start_block = row['start_street_block']
end_block = row['end_street_block']
weight = row['count'] # 假设有一个计数列
if G.has_edge(start_block, end_block):
G.edges[start_block, end_block]['weight'] += weight
else:
G.add_edge(start_block, end_block, weight=weight)
3. 网络特征计算
# 计算网络密度
network_density = nx.density(G)
print(f'Network Density: {network_density}')
# 计算节点强度
in_strength = dict(G.in_degree(weight='weight'))
out_strength = dict(G.out_degree(weight='weight'))
# 计算净流量比率(NFR)
nfr = {node: in_strength.get(node, 0) - out_strength.get(node, 0) for node in G.nodes()}
4. 可视化
import matplotlib.pyplot as plt
# 绘制网络图
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_size=[v * 10 for v in out_strength.values()],
node_color=[v for v in in_strength.values()], cmap='viridis')
plt.show()
# 绘制节点强度分布
plt.hist(in_strength.values(), bins=20, alpha=0.5, label='In-Strength')
plt.hist(out_strength.values(), bins=20, alpha=0.5, label='Out-Strength')
plt.legend()
plt.show()
# 绘制净流量比率分布
plt.hist(nfr.values(), bins=20)
plt.axvline(0, color='r', linestyle='dashed', linewidth=1)
plt.show()
5. ERGM 模型(Python 中没有直接的 ERGM 实现,可以使用 R 的 statnet 包)
# 使用 R 的 statnet 包(通过 rpy2 调用)
import rpy2.robjects as robjects
from rpy2.robjects.packages import importr
# 导入 R 包
ergm = importr('ergm')
# 转换网络为 R 的 network 对象
from rpy2.robjects import pandas2ri
pandas2ri.activate()
G_r = pandas2ri.py2rpy(G)
# 定义模型公式
formula = 'edges + mutual + transitive triples + nodecov("Bden") + nodecov("Price") + nodecov("Res")'
# 估计 ERGM 模型
robjects.r('''
model <- ergm(G_r ~ edges + mutual + triangle + nodecov("Bden") + nodecov("Price") + nodecov("Res"),
control = control.ergm(parallel=4))
''')
# 获取模型结果
results = robjects.r('summary(model)')
print(results)
6. 数据可视化(工作日和周末对比)
import seaborn as sns
# 分离工作日和周末数据
weekday_data = bike_data[bike_data['is_weekday'] == 1]
weekend_data = bike_data[bike_data['is_weekday'] == 0]
# 计算网络密度
weekday_density = nx.density(weekday_G)
weekend_density = nx.density(weekend_G)
# 绘制密度对比
sns.barplot(x=['Weekday', 'Weekend'], y=[weekday_density, weekend_density])
plt.title('Network Density Comparison')
plt.show()
# 绘制节点强度分布
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.histplot([v for v in weekday_in_strength.values()], bins=20)
plt.title('Weekday In-Strength Distribution')
plt.subplot(1, 2, 2)
sns.histplot([v for v in weekend_in_strength.values()], bins=20)
plt.title('Weekend In-Strength Distribution')
plt.show()