文章作者:
石强,镜舟科技解决方案架构师
赵恒,StarRocks TSC Member
👉 加入 StarRocks x AI 技术讨论社区 https://mp.weixin.qq.com/s/61WKxjHiB-pIwdItbRPnPA
RAG 和向量索引简介
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合外部知识检索与 AI 生成的技术,弥补了传统大模型知识静态、易编造信息的缺陷,使回答更加准确且基于实时信息。
RAG 的核心流程
检索(Retrieval)
-
用户输入问题后,RAG 从外部数据库(如维基百科、企业文档、科研论文等)检索相关内容。
-
检索工具可以是向量数据库、搜索引擎或传统数据库。
生成(Generation)
-
将检索到的相关信息与用户输入一起输入生成模型(如 GPT、LLaMA 等),生成更准确的回答。
-
模型基于检索内容“增强”输出,而非仅依赖内部参数化知识。
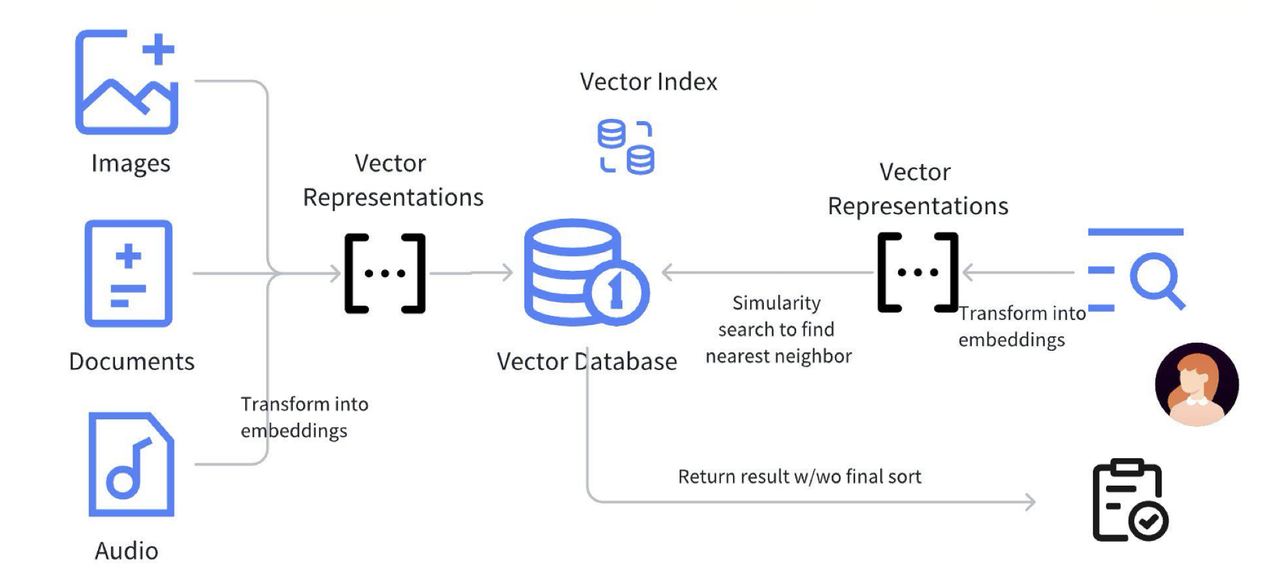
上图展示了 RAG 的标准流程。首先,图片、文档、视频和音频等数据经过预处理,转换为 Embedding 并存入向量数据库。Embedding 通常是高维 float 数组,借助向量索引(如 HNSW、IVF)进行相似性搜索,加速高效检索。
向量索引通过近似最近邻(ANN)算法优化查询效率,减少高维计算负担。语义搜索匹配用户问题与知识库中的相关内容,使回答基于真实信息,从而降低大模型的“幻觉”风险,提升回答的自然性和可靠性。
关于向量检索的更多介绍,可以参考 腾讯大数据基于 StarRocks 的向量检索探索 这篇文章。这里不再展开说明。
StarRocks + DeepSeek 的典型 RAG 应用场景
DeepSeek 负责生成高质量 Embedding 和回答,StarRocks 提供实时高效的向量检索,二者结合可构建更智能、更精准的 AI 解决方案。
企业级知识库
适用场景:
-
企业内部知识库(文档搜索、FAQ)
-
法律、金融、医药等专业领域问答
-
代码搜索、软件开发文档查询
方案:
-
文档嵌入(DeepSeek 负责): 将企业知识库、FAQ、技术文档等数据转换为向量。
-
存储+索引(StarRocks 负责): 使用 HNSW 或 IVFPQ 存储向量存储在 StarRocks 中,支持高效检索。
-
检索增强生成(RAG 负责): 用户输入问题 → DeepSeek 生成查询向量 → StarRocks 进行向量匹配 → 返回相关文档 → DeepSeek 结合文档生成最终回答。
AI 客服与智能问答
适用场景:
-
智能客服(银行、证券、电商)
-
法律、医疗等专业咨询
-
技术支持自动问答
方案:
-
客户对话日志嵌入(DeepSeek 负责): 训练 LLM 处理用户意图,转换历史聊天记录为向量。
-
存储+索引(StarRocks 负责): 采用向量索引让客服系统能够高效查找相似案例。
-
检索增强(RAG 负责): 结合历史客服对话 + 知识库 + DeepSeek LLM 生成答案。
示例流程:
-
用户问:“我如何更改银行卡预留手机号?”
-
StarRocks 检索到 3 个最相似的客户服务记录
-
DeepSeek 结合这 3 条历史记录 + 预设 FAQ,生成精准回答
操作演示
系统组成
-
DeepSeek:提供文本向量化(embedding)和答案生成能力
-
StarRocks:高效存储和检索向量数据(3.4+版本支持向量索引)
实现流程:
| 步骤 | 负责组件 | 具体实现 |
| 1.环境准备 | Ollama StarRocks | 用 Ollama 在本地机器上便捷地部署和运行大型语言模型 |
| 2.数据向量化 | DeepSeek-Embedding | 文本 → 3584 维向量 |
| 3.存储向量 | StarRocks | 创建表,存入向量 |
| 4.近似最近邻搜索 | StarRocks 向量索引 | IVFPQ / HNSW 检索 |
| 5.检索增强 | 模拟 RAG 逻辑 | 结合检索数据 |
| 6.生成答案 | DeepSeek LLM | 生成基于真实数据的回答 |
1.环境准备
1.1 DeepSeek 本地部署
Tips: 以下内容使用的是 macbook 进行 demo 演示
1.1.1 使用 ollama 安装本地模型
在本地部署 DeepSeek 时,Ollama 主要起到模型管理和提供推理接口的作用,支持运行多个不同的 LLM,并允许用户在本地切换和管理不同的模型。
-
下载 ollama:https://ollama.com/
-
安装 deepseek-r1:7b
# 该命令会自动下载并加载模型ollama run deepseek-r1:7b

Tips: 如果想使用云端 LLM(如 DeepSeek 的官方 API),需要获取并填写 API Key
访问 DeepSeek 官网(https://platform.deepseek.com)后注册账号并登录;在仪表盘中创建 API Key(通常在 “API Keys” 或 “Developer” 部分),复制生成的密钥(如 sk-xxxxxxxxxxxxxxxx)。
1.1.2 Deepseek 初步使用
启动 deepseek
执行 ollama run deepseek-r1:7b 直接进入交互模式1.1.3 Deepseek 性能优化
直接在命令行设置参数:(参数单次生效)
OLLAMA_GPU_LAYERS=35 \OLLAMA_CPU_THREADS=6 \OLLAMA_BATCH_SIZE=128 \OLLAMA_CONTEXT_SIZE=4096 \ollama run deepseek-r1:7b
1.1.4 deepseek 使用

显而易见:直接使用 deepseek 进行问答,返回的答案是不符合预期的,需要对知识进行修正
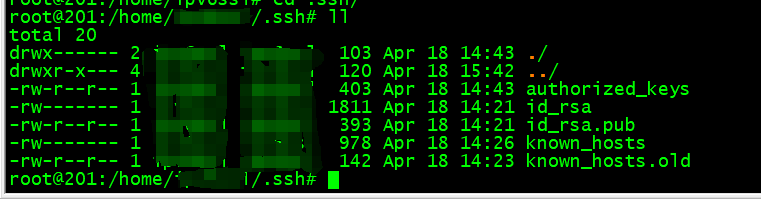
1.2 StarRocks 准备工作
1.2.1 集群部署
版本需求:3.4 及以上
1.2.2 配置设置
打开 vector index
ADMIN SET FRONTEND CONFIG ("enable_experimental_vector" = "true");1.2.3 建库建表
建库:
create database knowledge_base;建表:存储知识库向量
CREATE TABLE enterprise_knowledge (
id BIGINT AUTO_INCREMENT,
content TEXT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX vec_idx (embedding) USING VECTOR (
"index_type" = "hnsw",
"dim" = "3584",
"metric_type" = "l2_distance",
"M" = "16",
"efconstruction" = "40"
)
) ENGINE=OLAP
PRIMARY KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);Tips: DeepSeek 的 deepseek-r1:7b 模型(7B 参数版本)默认生成高维嵌入向量,通常是 3584 维
2.将文本转成向量
测试通过 deepseek 将文本转为 3584 维向量
curl -X POST http://localhost:11434/api/embeddings -d '{"model": "deepseek-r1:7b", "prompt": "产品保修期是一年。"}'下面将转化的向量数据保存在 StarRocks 中
3.知识存储 (存储向量到 StarRocks)
import pymysql
import requests
def get_embedding(text):
url = "http://localhost:11434/api/embeddings"
payload = {"model": "deepseek-r1:7b", "prompt": text}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()["embedding"]
try:
content = "StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。"
embedding = get_embedding(content)
# 将 Python 列表转换为 StarRocks 的数组格式
embedding_str = "[" + ",".join(map(str, embedding)) + "]" # 例如:[0.1,0.2,0.3]
conn = pymysql.connect(
host='X.X.X.X',
port=9030,
user='root',
password='sr123456',
database='knowledge_base'
)
cursor = conn.cursor()
# 使用格式化的数组字符串
sql = "INSERT INTO enterprise_knowledge (content, embedding) VALUES (%s, %s)"
cursor.execute(sql, (content, embedding_str))
conn.commit()
print(f"Inserted: {content} with embedding {embedding[:5]}...")
except requests.RequestException as e:
print(f"Embedding API error: {e}")
except pymysql.Error as db_err:
print(f"Database error: {db_err}")
finally:
if 'cursor' in locals():
cursor.close()
if 'conn' in locals():
conn.close()操作演示
4.知识提取 (检索向量 & 输出结果)
import pymysql
import requests
# 获取嵌入向量的函数
def get_embedding(text):
url = "http://localhost:11434/api/embeddings"
payload = {"model": "deepseek-r1:7b", "prompt": text}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()["embedding"]
# 从 StarRocks 查询相似内容的函数
def search_knowledge_base(query_embedding):
try:
conn = pymysql.connect(
host='39.98.110.249',
port=9030,
user='root',
password='sr123456',
database='knowledge_base'
)
cursor = conn.cursor()
# 将查询向量转换为 StarRocks 的数组格式
embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"
# 使用 L2 距离搜索最相似的记录
sql = """
SELECT content, l2_distance(embedding, %s) AS distance
FROM enterprise_knowledge
ORDER BY distance ASC
LIMIT 1
"""
cursor.execute(sql, (embedding_str,))
result = cursor.fetchone()
if result:
return result[0] # 返回最匹配的 content
else:
return "未找到相关信息。"
except pymysql.Error as db_err:
print(f"Database error: {db_err}")
return "查询失败。"
finally:
if 'cursor' in locals():
cursor.close()
if 'conn' in locals():
conn.close()
# 主流程
try:
query = "StarRocks 的愿景是什么?"
query_embedding = get_embedding(query) # 将查询转化为向量
answer = search_knowledge_base(query_embedding) # 从知识库检索答案
print(f"问题: {query}")
print(f"回答: {answer}")
except requests.RequestException as e:
print(f"Embedding API error: {e}")
except Exception as e:
print(f"Error: {e}")执行效果

补充说明:到目前为止的流程仅依赖 StarRocks 进行向量检索,未利用 DeepSeek LLM 进行生成,导致回答生硬且缺乏上下文整合,影响自然性和准确性。为提升效果,应引入 RAG 机制,使检索结果与生成模型深度融合,从而优化回答质量并减少幻觉问题。
5.加入 RAG 增强
5.1 将查询知识库的结果,返回给 DeepSeek LLM ,优化回答质量
构造 RAG Prompt
def build_rag_prompt(query, retrieved_content):
prompt = f"""
[系统指令] 你是企业智能客服,基于以下知识回答用户问题:
[知识上下文] {retrieved_content}
[用户问题] {query}
"""
return prompt
# 调用 DeepSeek 生成回答
def generate_answer(prompt):
url = "http://localhost:11434/api/generate"
payload = {"model": "deepseek-r1:7b", "prompt": prompt}
try:
response = requests.post(url, json=payload)
response.raise_for_status()
full_response = ""
for line in response.text.splitlines():
if line.strip(): # 过滤空行
try:
json_obj = json.loads(line)
if "response" in json_obj:
full_response += json_obj["response"] # 只提取答案
if json_obj.get("done", False):
break
except json.JSONDecodeError as e:
print(f"JSON 解析错误: {e}, line: {line}")
return clean_response(full_response.strip()) # 处理并去掉 <think>XXX</think>
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return "生成失败。"5.2 创建 RAG 过程表:
用于记录用户问题、检索结果和生成回答,保存上下文,方便进行长对话,至于长对话,用户可自行探索。
customer_service_log 表建表语句如下:
CREATE TABLE customer_service_log (
id BIGINT AUTO_INCREMENT,
user_id VARCHAR(50),
question TEXT NOT NULL,
question_embedding ARRAY<FLOAT> NOT NULL,
retrieved_content TEXT,
generated_answer TEXT,
timestamp DATETIME NOT NULL,
feedback TINYINT DEFAULT NULL
) ENGINE=OLAP
PRIMARY KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);6.优化后的版本
6.1 知识提取代码
6.1.1 知识提取
import pymysql
import requests
import json
from datetime import datetime
import logging
import re
# 获取嵌入向量
def get_embedding(text):
url = "http://localhost:11434/api/embeddings"
payload = {"model": "deepseek-r1:7b", "prompt": text,"stream": "true"}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()["embedding"]
# 从 StarRocks 检索知识
def search_knowledge_base(query_embedding):
try:
conn = pymysql.connect(
host='X.X.X.X',
port=9030,
user='root',
password='sr123456',
database='knowledge_base'
)
cursor = conn.cursor()
embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"
sql = """
SELECT content, l2_distance(embedding, %s) AS distance
FROM enterprise_knowledge
ORDER BY distance ASC
LIMIT 3
"""
cursor.execute(sql, (embedding_str,))
results=cursor.fetchall()
content=""
for result in results:
content+=result[0]
return content
except pymysql.Error as db_err:
print(f"Database error: {db_err}")
return "查询失败。"
finally:
cursor.close()
conn.close()
def build_rag_prompt(query, retrieved_content):
prompt = f"""
[系统指令] 你是企业智能客服,基于以下知识回答用户问题:
[知识上下文] {retrieved_content}
[用户问题] {query}
"""
return prompt
# 调用 DeepSeek 生成回答
def generate_answer(prompt):
url = "http://localhost:11434/api/generate"
payload = {"model": "deepseek-r1:7b", "prompt": prompt}
try:
response = requests.post(url, json=payload)
response.raise_for_status()
full_response = ""
for line in response.text.splitlines():
if line.strip(): # 过滤空行
try:
json_obj = json.loads(line)
if "response" in json_obj:
full_response += json_obj["response"] # 只提取答案
if json_obj.get("done", False):
break
except json.JSONDecodeError as e:
print(f"JSON 解析错误: {e}, line: {line}")
return clean_response(full_response.strip()) # 处理并去掉 <think>XXX</think>
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return "生成失败。"
# 记录对话日志
def log_conversation(user_id, question, question_embedding, retrieved_content, generated_answer):
try:
conn = pymysql.connect(
host='X.X.X.X',
port=9030,
user='root',
password='sr123456',
database='knowledge_base'
)
cursor = conn.cursor()
embedding_str = "[" + ",".join(map(str, question_embedding)) + "]"
sql = """
INSERT INTO customer_service_log (user_id, question, question_embedding, retrieved_content, generated_answer, timestamp)
VALUES (%s, %s, %s, %s, %s, NOW())
"""
cursor.execute(sql, (user_id, question, embedding_str, retrieved_content, generated_answer))
conn.commit()
except pymysql.Error as db_err:
print(f"Database error: {db_err}")
finally:
cursor.close()
conn.close()
def clean_response(text):
# 去掉所有 <think>xxx</think> 结构
return re.sub(r"<think>.*?</think>", "", text, flags=re.DOTALL).strip()
# 主流程
def rag_pipeline(user_id, query):
try:
logging.info(f"开始处理查询: {query}")
query_embedding = get_embedding(query)
logging.info("获取嵌入向量成功")
retrieved_content = search_knowledge_base(query_embedding)
logging.info(f"检索到内容: {retrieved_content[:50]}...") # 只展示前50字符
prompt = build_rag_prompt(query, retrieved_content)
generated_answer = generate_answer(prompt)
logging.info(f"生成回答: {generated_answer[:50]}...")
log_conversation(user_id, query, query_embedding, retrieved_content, generated_answer)
logging.info("日志记录完成")
return generated_answer
except Exception as e:
logging.error(f"发生错误: {e}", exc_info=True)
return "处理失败。"
# 测试
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
user_id = "user123"
query = "StarRocks 的愿景是什么?"
answer = rag_pipeline(user_id, query)
print(f"问题: {query}")
print(f"回答: {answer}")6.1.2 操作演示

总结一下 RAG 增强后的执行流程:
输入:用户输入问题
数据向量化:DeepSeek Embedding
StarRocks 向量索引,在 enterprise_knowledge 表中检索最相似的知识
增强(Augmentation):将检索结果与问题组合成 Prompt,传递给 DeepSeek
生成回答:调用 DeepSeek 生成增强后的回答
记录日志:将问题、检索结果和生成回答存入 customer_service_log
返回结果:将生成的回答返回给用户
6.2 加上 web 可视化界面
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>智能问答客服系统</title>
<script>
async function askQuestion() {
let question = document.getElementById("question").value;
let response = await fetch("/ask", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({ question: question })
});
let data = await response.json();
document.getElementById("answer").innerText = data.answer;
}
</script>
</head>
<body>
<h1>智能问答客服系统</h1>
<input type="text" id="question" placeholder="请输入您的问题">
<button onclick="askQuestion()">提问</button>
<p id="answer"></p>
</body>
</html>6.3 完整问答后台服务代码
6.3.1 代码结构如下
6.3.2 知识存储代码
import pymysql
import requests
def get_embedding(text):
url = "http://localhost:11434/api/embeddings"
payload = {"model": "deepseek-r1:7b", "prompt": text}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()["embedding"]
try:
content = "StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。"
embedding = get_embedding(content)
# 将 Python 列表转换为 StarRocks 的数组格式
embedding_str = "[" + ",".join(map(str, embedding)) + "]" # 例如:[0.1,0.2,0.3]
conn = pymysql.connect(
host='X.X.X.X',
port=9030,
user='root',
password='sr123456',
database='knowledge_base'
)
cursor = conn.cursor()
# 使用格式化的数组字符串
sql = "INSERT INTO enterprise_knowledge (content, embedding) VALUES (%s, %s)"
cursor.execute(sql, (content, embedding_str))
conn.commit()
print(f"Inserted: {content} with embedding {embedding[:5]}...")
except requests.RequestException as e:
print(f"Embedding API error: {e}")
except pymysql.Error as db_err:
print(f"Database error: {db_err}")
finally:
if 'cursor' in locals():
cursor.close()
if 'conn' in locals():
conn.close()6.3.3 知识提取
import pymysql
import requests
import json
import logging
import re
from flask import Flask, request, jsonify, render_template
app = Flask(__name__)
# 配置日志
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
# 获取嵌入向量
def get_embedding(text):
url = "http://localhost:11434/api/embeddings"
payload = {"model": "deepseek-r1:7b", "prompt": text, "stream": "true"}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()["embedding"]
# 从 StarRocks 检索知识
def search_knowledge_base(query_embedding):
try:
conn = pymysql.connect(
host='X.X.X.X',
port=9030,
user='root',
password='sr123456',
database='knowledge_base'
)
cursor = conn.cursor()
embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"
sql = """
SELECT content, l2_distance(embedding, %s) AS distance
FROM enterprise_knowledge
ORDER BY distance ASC
LIMIT 3
"""
cursor.execute(sql, (embedding_str,))
results=cursor.fetchall()
content=""
for result in results:
content+=result[0]
# result = cursor.fetchone()
return content
except pymysql.Error as db_err:
print(f"Database error: {db_err}")
return "查询失败。"
finally:
cursor.close()
conn.close()
# 构造 RAG Prompt
def build_rag_prompt(query, retrieved_content):
return f"""
[系统指令] 你是企业智能客服,基于以下知识回答用户问题:
[知识上下文] {retrieved_content}
[用户问题] {query}
"""
# 调用 DeepSeek 生成回答
def generate_answer(prompt):
url = "http://localhost:11434/api/generate"
payload = {"model": "deepseek-r1:7b", "prompt": prompt}
try:
response = requests.post(url, json=payload)
response.raise_for_status()
full_response = ""
for line in response.text.splitlines():
if line.strip():
try:
json_obj = json.loads(line)
if "response" in json_obj:
full_response += json_obj["response"]
if json_obj.get("done", False):
break
except json.JSONDecodeError as e:
logging.warning(f"JSON 解析错误: {e}, line: {line}")
return clean_response(full_response.strip()) # 处理并去掉 <think>XXX</think>
except requests.exceptions.RequestException as e:
logging.error(f"请求失败: {e}")
return "生成失败。"
# 记录对话日志
def log_conversation(user_id, question, question_embedding, retrieved_content, generated_answer):
try:
conn = pymysql.connect(
host='X.X.X.X',
port=9030,
user='root',
password='sr123456',
database='knowledge_base'
)
cursor = conn.cursor()
embedding_str = "[" + ",".join(map(str, question_embedding)) + "]"
sql = """
INSERT INTO customer_service_log (user_id, question, question_embedding, retrieved_content, generated_answer, timestamp)
VALUES (%s, %s, %s, %s, %s, NOW())
"""
cursor.execute(sql, (user_id, question, embedding_str, retrieved_content, generated_answer))
conn.commit()
except pymysql.Error as db_err:
logging.error(f"数据库错误: {db_err}")
finally:
cursor.close()
conn.close()
# 清理回答内容,去掉 <think>XXX</think>
def clean_response(text):
return re.sub(r"<think>.*?</think>", "", text, flags=re.DOTALL).strip()
# RAG 处理流程
def rag_pipeline(user_id,query):
try:
logging.info(f"开始处理查询: {query}")
query_embedding = get_embedding(query)
logging.info("获取嵌入向量成功")
retrieved_content = search_knowledge_base(query_embedding)
logging.info(f"检索到内容: {retrieved_content[:50]}...") # 只展示前50字符
prompt = build_rag_prompt(query, retrieved_content)
generated_answer = generate_answer(prompt)
logging.info(f"生成回答: {generated_answer[:50]}...")
log_conversation(user_id, query, query_embedding, retrieved_content, generated_answer)
logging.info("日志记录完成")
return generated_answer
except Exception as e:
logging.error(f"发生错误: {e}", exc_info=True)
return "处理失败。"
# Flask API
@app.route("/")
def index():
return render_template("index.html") # 渲染前端页面
@app.route("/ask", methods=["POST"])
def ask():
user_id="sr_01"
data = request.json
question = data.get("question", "")
result=rag_pipeline(user_id,question)
answer = f"问题:{question}。\n 回答:{result}"
return jsonify({"answer": answer})
if __name__ == "__main__":
user_id = "sr"
app.run(host="0.0.0.0", port=9033, debug=True)6.3.4 效果演示


参考文档:
Deepseek 搭建:https://zhuanlan.zhihu.com/p/20803691410
Vector index 资料:https://docs.starrocks.io/zh/docs/table_design/indexes/vector_index/
StarRocks AI 共创计划:让数据分析更智能!
AI 时代已来,StarRocks 正在加速进化!我们诚邀社区开发者、数据工程师和 AI 爱好者一起探索 “AI + 数据分析” 的无限可能。无论你是擅长算法优化、应用落地,还是热爱技术布道,这里都有你的舞台!
🌟 你的贡献,能让 StarRocks 更强大!我们期待你在以下方向大展身手:
AI 增强分析:用 LLM、RAG 优化查询、智能 SQL 生成、自然语言交互
工具 & 插件:开发 AI 扩展、模型集成、自动化运维方案
实战案例:分享你的 AI+StarRocks 应用 Demo(附代码/视频更佳!)
🎁 丰厚奖励
Top 10 优秀贡献者将获得 StarRocks 社区荣誉 + 2000 积分奖励(详情参考 StarRocks 布道师计划)
优秀项目有机会被官方推荐,并整合进 StarRocks 生态
📢 立即行动!👉 在社区论坛分享你的创意或 AI 实践:https://forum.mirrorship.cn/