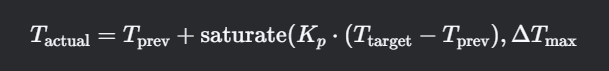面试中经常被问到:
-
有一个亿qq号,找出重复的
-
给你512m内存,找出5g文件中最大的数字
-
订单超时实现精准关单
…
当然,还有经常遇到的问题:
-
接口业务逻辑复杂或查数据库慢,相应耗时高
-
网络因为丢包导致服务请求异常
-
分布式事务的空回滚、挂起
…
这些问题看似诡异且难解,但都可以通过一些基本且常用的方法解决,你会发现这些方法无论是几十年前的第一代计算机,还是现在火热的AI都在使用,贯穿在业务应用系统到计算机CPU、内存硬件设计的每个阶段和细节(无论是软件还是硬件都包含这些)。
这些基本的思想不会因为时代而淘汰,更不会被元宇宙、大模型而取代。
下面我列出这些常用的设计思路(解题思路),你可以用于面试或者放在平时工作中。这些思想基本都是围绕着:性能、可靠性、可扩展性、用户体验、可观测性产生的。
-
分而治之:大数据量拆分成多个小数据处理(大问题拆小问题逐一解决),常见的实现:分布式数据库把上亿的数据分散到不同机器节点上进行计算。分而治之之后就是结果的聚合,这进一步引入了复杂度,如果有一台无限多大算力和存储的计算机,恐怕不拆分实现起来更简单。
-
缓存与时空权衡:利用空间换时间,常见的实现:CPU L1 L2缓存、guava缓存、cdn缓存、redis缓存等。而当空间占用达到一定阈值时,耗时就可以适当舍弃,因为投入产出比并不高,为了提高1ms的耗时,占用几百GB的内存空间是不可能的,所以缓存满了会通过LRU算法淘汰或写入磁盘。
-
算法与数据结构:程序=算法+数据结构,加快数据查询或计算速度的方法就是选用合适的算法和数据结构,常见的实现:InnoDB的b+树索引、TiDB的LSM树索引、ES的倒排索引、epoll的红黑树。算法和数据结构不只包括教科书上说的排序、查找,同样我们日常编写代码产生的设计模式、良好的编码过程都是算法与数据结构的组合。我们需要了解常用的算法与数据结构的原理,从而优化系统性能。需要注意的是,传统教科书会把算法与数据结构分开讲解,但没有数据结构,谈算法毫无意义。
-
冗余:冗余带来可靠性,航天系统中使用备份的冗余单元确保火箭和太空站的正常运作,动物中成对出现的器官,DNA中大量的冗余信息都保证了生物体的可靠生存。计算机中常见的实现:数据库主从复制,主挂了从被选为主继续对外提供服务、业务对等集群部署。冗余也可提高性能,分布式环境下(包括集群环境下)经常使用从节点处理读请求,数据库设计中表冗余字段,可以避免跨表查询产生的IO提高性能。冗余的代价就是付出更多的资源,这是实打实的RMB。
-
职责分离:最常见的就是数据库的主从,主复制写入数据,从同步主的数据后提供读的服务。在领域驱动设计中,职责分离也是一种常用的设计手段,对用户行为产生的事件拆分出不同指责的命令,如:读命令和写命令,再配合数据库的主从复制结构实现整体的职责分离。在部署结构中,一个工程中不同的接口重要程度以及应对的流量不同,可以分核心与非核心进行部署,为核心业务提供更强大的算力。职责分离并不适合于单体或者简单的业务逻辑中,职责分离适用于复杂的系统,降低系统复杂性,应用于简单的业务系统中,会让系统变得复杂。
-
重试:重试在网络请求中最常出现,应用代码中调用别人的接口,对方超时会进行重试,TCP协议上也存在超时重传机制,内存通过ECC纠错和重传避免地球磁场产生的bit位反转。通常对于网络请求重试是有讲究的,这包括了几个策略:异常后立刻重试、重试N次后停止、等待N秒后重试X次,这些策略存在的价值在于,被调用方若因为故障导致的超时或失败,进行重试无疑会加大被调用方的压力,所以调用方实现重试时必须想清楚采用何种策略。同时,出现重试也意味着系统存在问题,如果不解决可能激发更大的问题,重试也会导致用户体验下降。
-
failback failover failfast:这三个单词含义分别是:
a.failback:失效自动恢复,在主节点恢复后,将服务从备用节点切换回原主节点的过程,强调“恢复原主”。常见的实现:一部分数据库在主节点恢复后再且回去。
b.failover:失效转移,当主组件发生故障时,自动将服务切换到备用系统,确保业务连续性。其核心是“主备切换”,常见于高可用架构中。常见的实现:ES的主副本故障切换到从副本。
c.failfast:快速失败,在检测到潜在错误时立即终止操作并抛出异常错误扩散,核心是“快速暴露问题”。常见的实现:ArrayList的并发修改、接口参数检查。
-
并行:现代计算机系统(包括应用层的业务系统)是通过不同阶段构建并行计算组合而成的。在微观的CPU指令执行上通过流水线并行执行微指令,在宏观的代码上通过多线程利用多逻辑核进行加速计算,再大一点会通过分布式集群实现并行计算。虽说并行提高的算力,但在这么高度的并行流程中,就会存在各种各样的问题,主要包括:执行的依赖关系与顺序、共享数据的并行写安全、为解决共享数据并行写安全问题引入的互斥竞争、并行部分成功和部分失败的问题。这几个本质上都是数据安全问题。解决这些问题会适当牺牲并行的能力降级为串行,也可能让并行计算的结果失效。所以在算力性能和数据安全问题之间要进行取舍。
-
共享与不可变模式:上面说到并行存在数据安全问题,产生问题的原因根本是数据存在共享。共享的好处在于节省存储空间,如果不想通过加锁把并行改成串行,那么可以使用不可变模式。实现不可变模式包括:
a.final:让数据不可变更,最常见的是java.lang.String,如果需要变更创建新的对象。
b.COW(copy on write):写时复制,只有在数据写入时候拷贝出一个副本,基于副本修改数据。常见的实现:Linux操作系统的fork创建子进程。
不可变模式的两种方法都需要更多的空间,但避免了锁的竞争。
-
分层:分层是计算机系统设计时最常见的手段,通过合理的分层隔离各个层级之间的差异,屏蔽内部实现细节,提升系统的可扩展性,常见的分层如:TCP网络四层、MVC分层等。Any problem in computer science can be solved by anther layer of indirection,即:算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。这句经典的理论已不知出自何处,但无数的先例都是基于此,调节CPU和硬盘之间的性能差是通过加了一个内存实现的,调节CPU和内存之间的性能差是通过加了L1 L2 L3缓存实现的,用户到服务器之间可以通过反向代理、cdn做很多事情。分层与职责分离一样,在复杂系统设计上是必要的。
-
分解与复用:分层的概念本质是在系统架构中体现的,这是宏观上的设计思想。而在细节之处,我们通过各种设计模式、抽象与封装,分割出原子的模块、服务、方法,可以说通过分解把复杂的系统大卸八块,分解出来的结果就是可以实现复用。最简单的例子:抽出鉴权模块,购买商品下单、访问个人中心等页面都不需要关心鉴权的业务逻辑,直接依赖鉴权模块即可。
-
反馈:系统应该有一个完善的自反馈机制,确保自身的可靠,比如系统感知到失败后自动降级,人工降级等。同时提供了友好的监控能够让我们发现潜在的问题,这一点Linux做的非常好,内核提供了大量的可观测机制,如:ebpf、tracepoint、ftrace、kprobes、syslog、kdb等。作为应用系统,我们可以通过上报功能模块的用户点击和曝光事件、接口的请求量、响应耗时等指标到ELK中进行分析。一些互联网大厂应对突发流量也是通过结合监控系统与k8s实现自动扩缩容。
希望你能基于上面谈到的12个设计方法,在面试或工作中多加思考,设计就是在不断的取舍,即使是有上面的方法做铺垫,也无法做到完美的设计方案。“取舍”俩字不应只有架构师懂得,产品经理、码农都需要有这样的思想,才能合作完成一个不完美但可不断完善的产品,为用户提供更好的体验,为企业带来更多的价值。


![[创业之路-366]:投资尽职调查 - 尽调核心逻辑与核心影响因素:价值、估值、退出、风险、策略](https://i-blog.csdnimg.cn/img_convert/e89b45843e25ffa70c9fc54c3bec98b8.png)