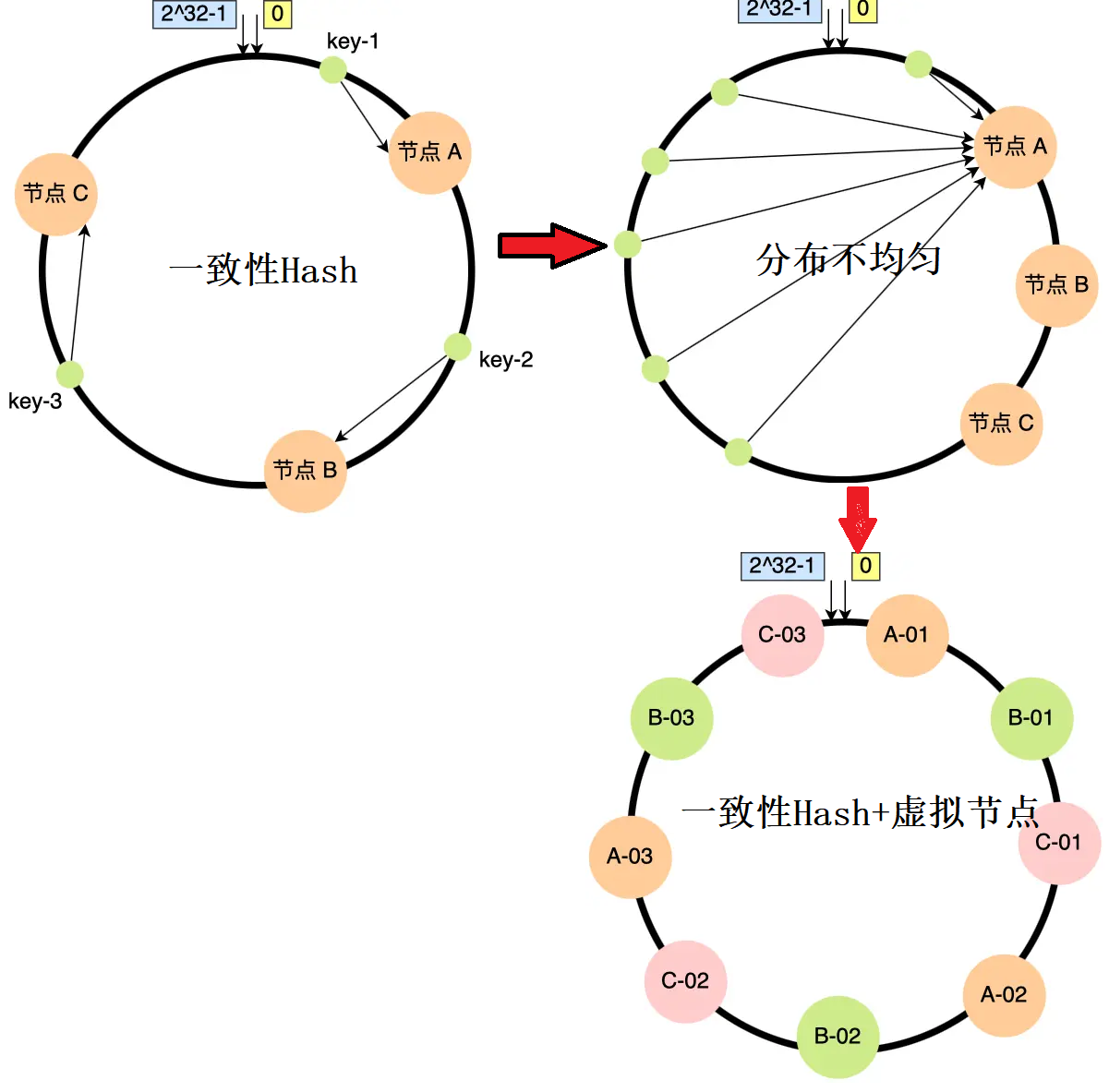
构建一个基于神经网络的肾脏疾病预测模型
1. 数据预处理
- 加载数据:读取
kidney_disease.csv文件,加载患者医疗数据。 - 删除冗余特征:移除与预测目标无关的列(如
al,su等),保留关键特征(如年龄、血压、血糖等)。 - 处理缺失值:用
np.nan_to_num将缺失值(NaN)替换为0,但此方法可能不适用于分类特征(例如“是否有糖尿病”列中0可能代表“否”)。
2. 特征工程
- 标签定义:假设数据最后一列(第8列)是分类标签(如
classification),标记患者是否患病(二分类问题)。 - 分类变量编码:对分类特征(如
dm(糖尿病)、cad(冠心病)、appet(食欲))进行独热编码(One-Hot Encoding),将其转换为数值形式供模型处理。
3. 数据标准化与分割
- 标准化:使用
StandardScaler对数值型特征进行标准化(均值0,方差1),消除量纲差异。 - 数据分割:按8:2比例划分训练集和测试集,确保模型评估的客观性。
4. 神经网络建模
- 模型结构:
- 输入层:11个输入节点(对应特征数量)。
- 隐藏层:2层全连接层,每层6个神经元,激活函数为ReLU。
- 输出层:1个神经元,激活函数为Sigmoid,输出患病概率(0~1)。
- 训练配置:
- 损失函数:二元交叉熵(
binary_crossentropy),适用于二分类问题。 - 优化器:Adam,自适应调整学习率。
- 批次训练:每批次7个样本,共训练20轮(epochs)。
- 损失函数:二元交叉熵(
5. 模型评估
- 预测与阈值处理:对测试集预测概率大于0.5的样本判定为患病。
- 性能指标:
- 混淆矩阵:计算真阳性、假阳性等分类结果。
- 准确率:统计模型正确预测的比例。
# 导入必要库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from keras.models import Sequential
from keras.layers import Dense
# 数据预处理
df = pd.read_csv('kidney_disease.csv')
to_drop = ['al','su','rbc','pc','pcc','ba','bgr','pcv','sod','pot','bu','wc','rc','htn','pe','ane']
df.drop(to_drop, axis=1, inplace=True)
df = df.dropna() # 删除缺失值
# 分割特征与标签
X = df.drop(['id', 'classification'], axis=1) # 假设标签列名是'classification'
y = df['classification'].apply(lambda x: 1 if x.lower().strip() == 'ckd' else 0) # 处理标签格式
# 分类列处理
categorical_cols = ['dm', 'cad', 'appet']
for col in categorical_cols:
# 清洗字符串数据(统一小写并去除空格)
X[col] = X[col].astype(str).str.strip().str.lower()
# 生成哑变量
dummies = pd.get_dummies(X[col], prefix=col, drop_first=True)
X = pd.concat([X, dummies], axis=1)
X = X.drop(categorical_cols, axis=1)
# 数据标准化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1, stratify=y) # 添加分层抽样
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# 模型构建
classifier = Sequential()
classifier.add(Dense(units=6, activation='relu', input_dim=X_train.shape[1], kernel_initializer='he_uniform')) # 更合适的初始化方法
classifier.add(Dense(units=6, activation='relu', kernel_initializer='he_uniform'))
classifier.add(Dense(units=1, activation='sigmoid', kernel_initializer='he_uniform'))
classifier.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练
classifier.fit(X_train, y_train, batch_size=7, epochs=20)
# 评估
y_pred = classifier.predict(X_test) > 0.5
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("Accuracy:", accuracy_score(y_test, y_pred))