
康琪:京东物流高级技术专家、StarRocks & Apache Flink Contributor
导读:本文整理自京东物流高级技术专家在 StarRocks 年度峰会上的分享,UData 平台从存算一体到存算分离架构演进后,查询性能得到提升。Cache hit 时,P95 和 P99 查询延迟小于 10 秒,与存算一体架构相当;Cache miss时,查询响应不超过 1 分钟,远优于 Hive。
在 OSS 性能和降本方面,存储成本减少了 90%,主要得益于从本地 SSD 转向 OSS 对象存储。同时,利用 HPA 进行弹性扩缩容,计算资源成本降低了约 30%。
一、京东物流一站式自助分析场景
1.1 京东物流一站式自助分析场景
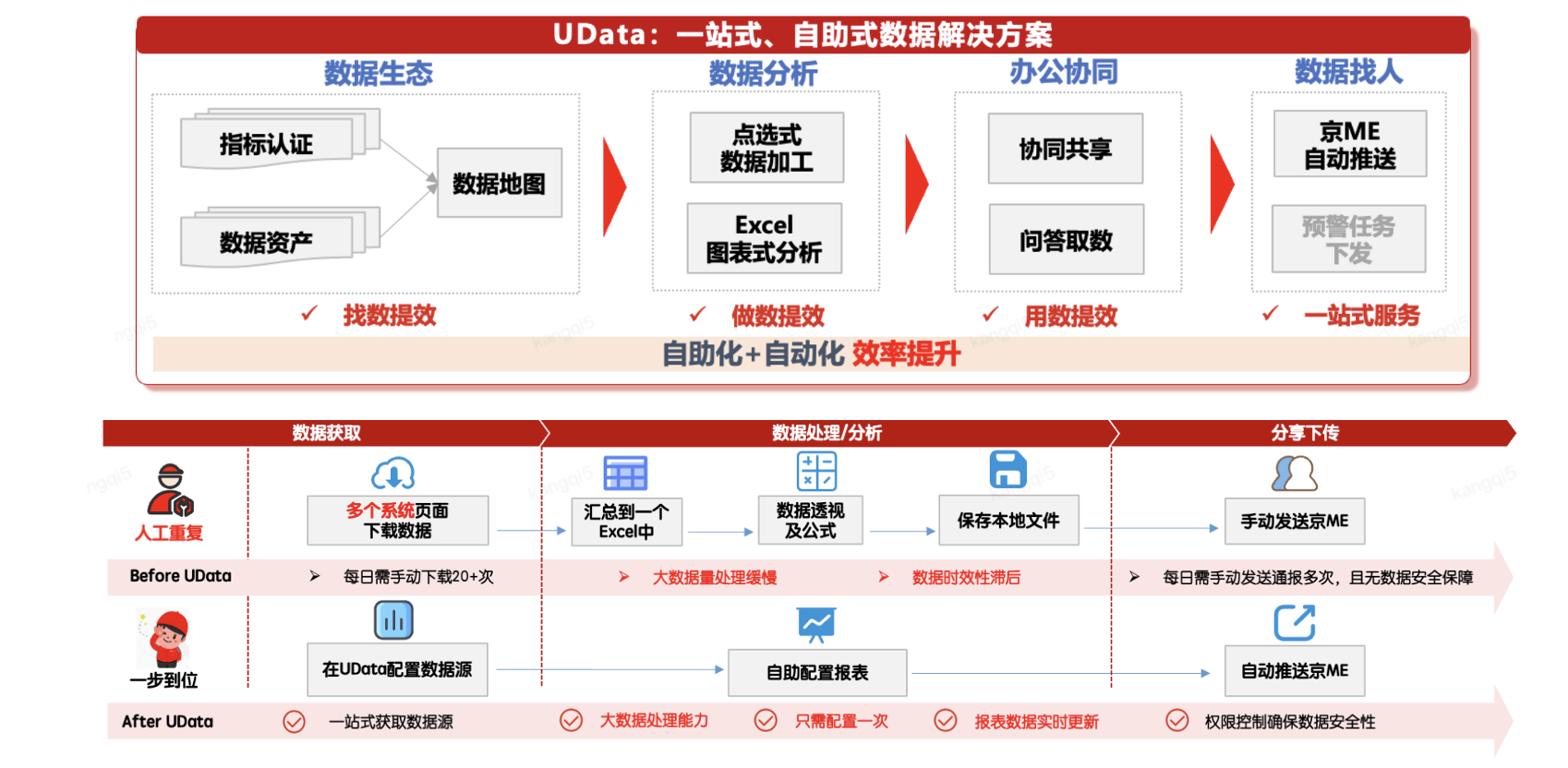
作为全国领先的快递、快运及供应链一体化服务商,我们的业务量十分庞大,每天产生的数据量极为可观。相应地,数据分析需求也十分旺盛,目前每天约有 10 万名一线业务人员需要频繁查看数据。
在 UData 平台建设之前,业务人员需要从多个系统手动下载所需数据,再通过 Excel 进行拼接、透视分析和公式计算,最后将结果保存至本地并线下分享。这种方式不仅操作繁琐,效率低下,还存在数据泄露的风险。因此,我们搭建了 UData——一款一站式、自助式的数据分析平台,旨在提供高效、安全的数据信息获取与处理能力。
UData 具备自动接入、点选式数据加工、数据集成共享及推送等核心功能。一线人员只需在平台上配置所需的数据源,并通过可视化操作或 SQL 编写逻辑,即可快速生成所需数据。最终,数据可以通过内部京ME系统或邮件自动推送,实现全流程自动化,极大提升业务人员的数据使用体验。
UData 平台的底层架构依托 StarRocks,其高性能的实时数据摄入、联邦查询及湖仓一体三大核心能力,全面满足了物流数据分析的需求。借助 StarRocks 的强大支持,我们成功构建了一站式物流全链路数据分析解决方案,涵盖从单个包裹的流转状态到整个省区的业务达成率等多维度分析。
1.2 UData产品架构
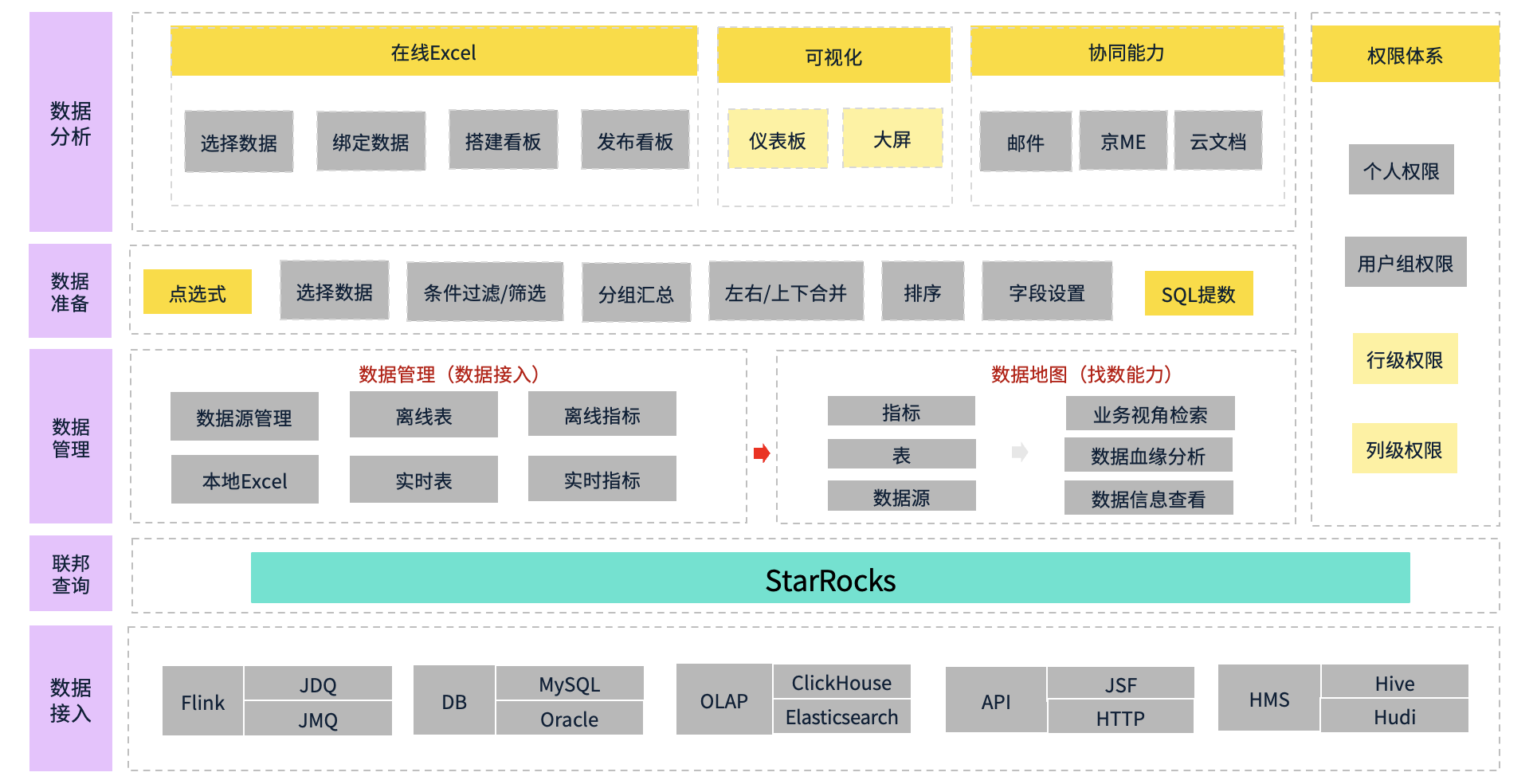
从数据接入层来看,我们支持多种数据源,包括实时数据、数据库、OLAP 引擎、API 接口以及传统离线数据仓库。实时数据(分钟级更新)通过 Flink 从内部消息队列 JDQ、JMQ 直接写入 StarRocks 内表。传统数据库如 MySQL、Oracle 以及 OLAP 引擎(如 ClickHouse、Elasticsearch)均可作为外表接入。此外,我们还支持 API 方式接入数据,例如内部 JSF 服务(类似Dubbo 或 HTTP 接口)。在离线数仓方面,基于 Hive Metastore(HMS) 体系,我们支持 Hive、Hudi 等离线数据源。
联邦查询层依托 StarRocks 进行数据整合,外表数据通过 Catalog 方式接入,实时数据则写入内表,确保查询的高效性和实时性。在数据管理与分析层,用户可通过数据接入模块自助配置所需数据集和表,甚至直接导入 Excel。系统会存储离线表和实时表,并通过数据地图管理表源数据、指标元数据和数据元数据,方便用户进行分析或业务检索。
在数据准备阶段,系统以在线 Excel 或 SQL 数据集的形式向用户提供数据。具备 SQL 能力的用户可直接编写 SQL 进行数据提取,而不具备 SQL 能力的用户则可通过点选式界面进行筛选和查询,功能等效于 SQL 中的 SPJ(选择、投影、连接) 语句,实现便捷的数据获取。
最终,数据应用层支持多种下游应用方式,包括在线 Excel、可视化大屏、仪表板等,或通过跨部门共享,实现高效、安全的数据流转。
1.3 StarRocks 的运用规模
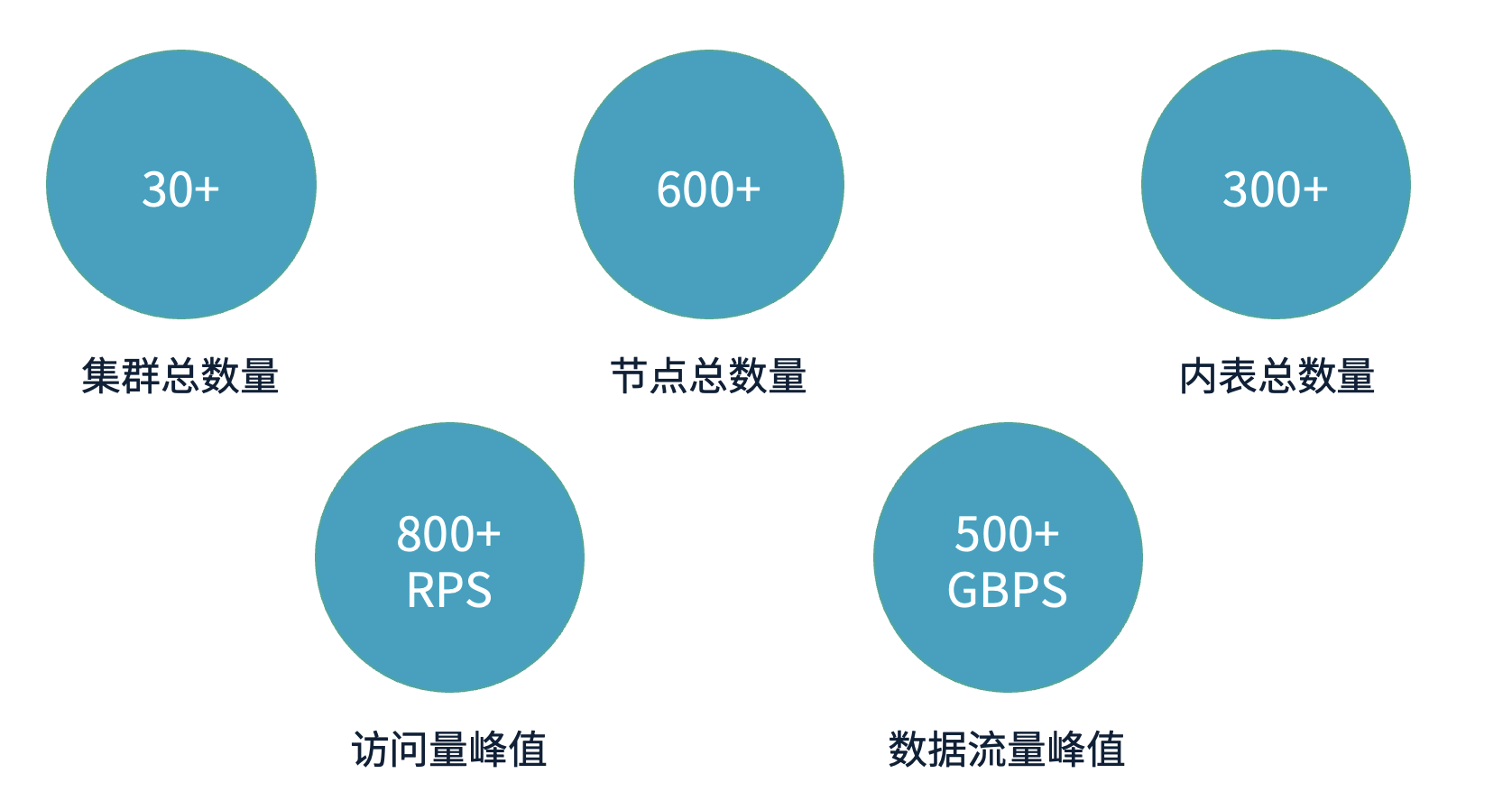
在存算分离方案实施之前,我们 StarRocks 的应用规模已达到较高水平,具体情况如下:
-
集群规模:30+
-
计算节点(BE 节点):600+
-
内表数量:300 +
-
访问量峰值:业务查询峰值约 800+ RPS
-
流量峰值:可达 500+ GB/s
二、存算一体向存算分离演进
2.1为什么需要存算分离
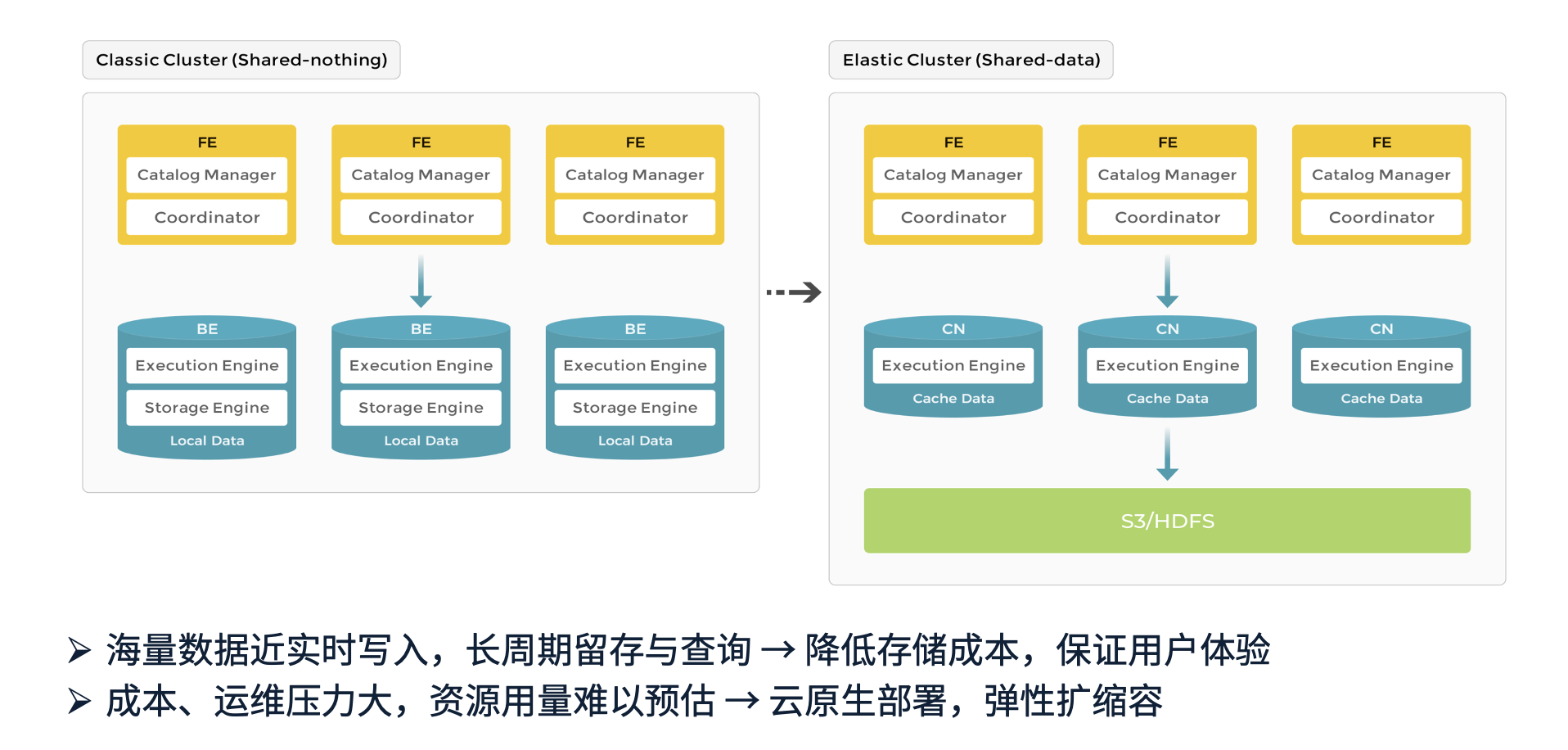
尽管当前我们已构建了大规模的存算一体集群,但仍然需要向存算分离架构演进,主要基于以下几点考虑:
-
数据存储需求的增长
我们的业务涉及海量数据的实时写入,同时还需支持长周期数据留存与查询。例如,不同运单的闭环周期可能是 7 天、15 天,部分特殊业务的闭环周期甚至长达 1-2 年。此外,业务分析中常涉及同比、环比计算,需要跨年、跨月进行数据对比。
-
存储成本的挑战
在存算一体架构下,所有数据都存储在 SSD 上以保证高性能。然而,随着数据量增长,存储成本大幅上升,甚至超过计算资源的瓶颈,导致不得不通过扩容来支撑业务需求。而存算分离能够降低存储成本,同时维持高效查询体验。
-
计算资源的弹性不足
存算一体架构缺乏弹性伸缩能力,导致资源利用率难以优化。例如,在大促等业务高峰期,计算资源需求剧增,但难以准确预估所需的预留资源,增加了运维和成本压力。
-
云原生与弹性扩缩容
采用存算分离架构,可顺势实现云原生部署,支持计算与存储的独立扩缩容。
2.2 部署存算分离集群
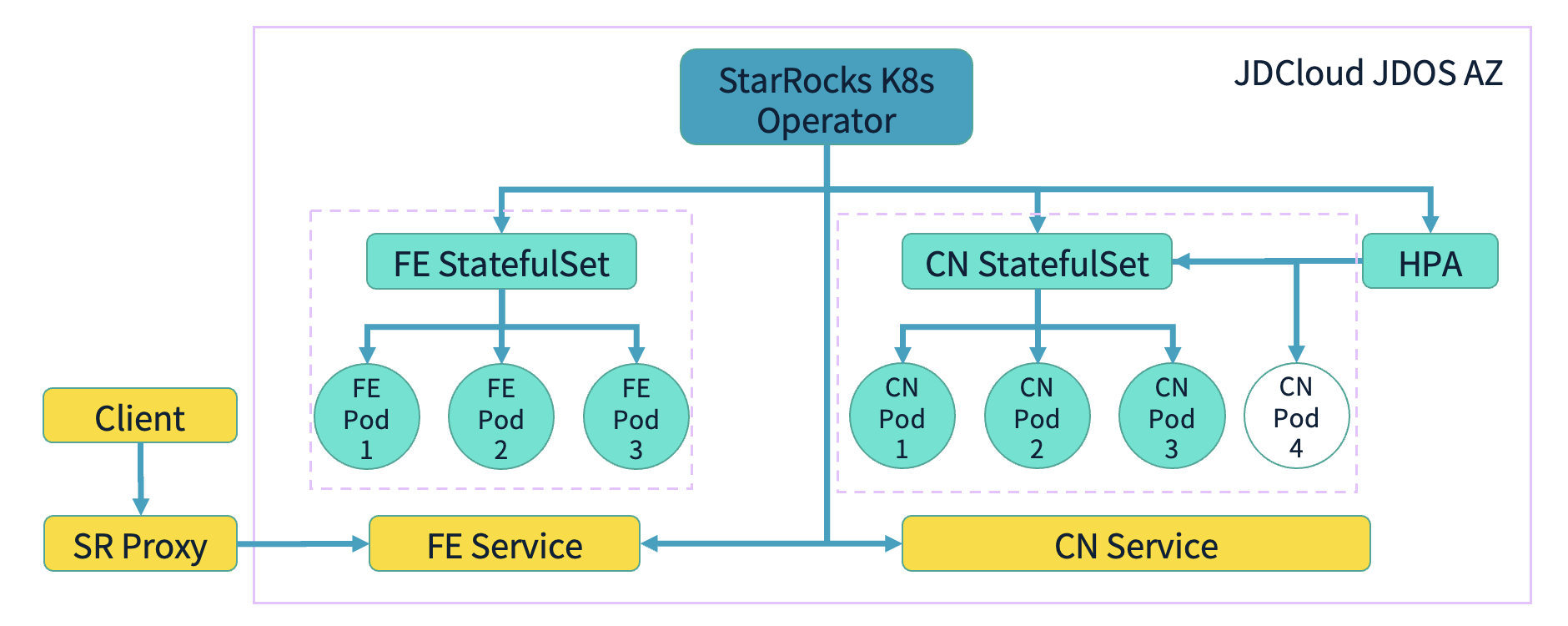
我们在内部采用 K8S 部署方式搭建存算分离集群,并依托京东云 JDOS 作为底层支撑。JDOS 是京东云高度定制化的 K8S 方案,为我们提供了稳定可靠的运行环境。在关键业务集群上,我们采用双可用区(AZ)容灾机制,在每个可用区部署独立集群,并通过 StarRocks Proxy 实现灵活的流量调度。例如,当 AZ1 集群发生故障时,流量可快速切换至 AZ2。
在底层架构上,我们采用配备万兆网卡和 SSD 的高性能物理机,以优化存算分离架构下 OSS 访问和本地缓存的 I/O 性能。此外,我们借助 StarRocks 社区提供的 K8S Operator 进行部署,使 FE 和 CN 组件的 Specs 在 CRD 文件中固化,实现自动化调优。例如,不同规格(16C64G、32C128G)的实例可直接按照预设参数进行配置,用户仅需部署 CRD 文件,即可完成集群启动与优化,而无需关心更细节的参数调优。
2.3 表、存储与 OSS Bucket 映射
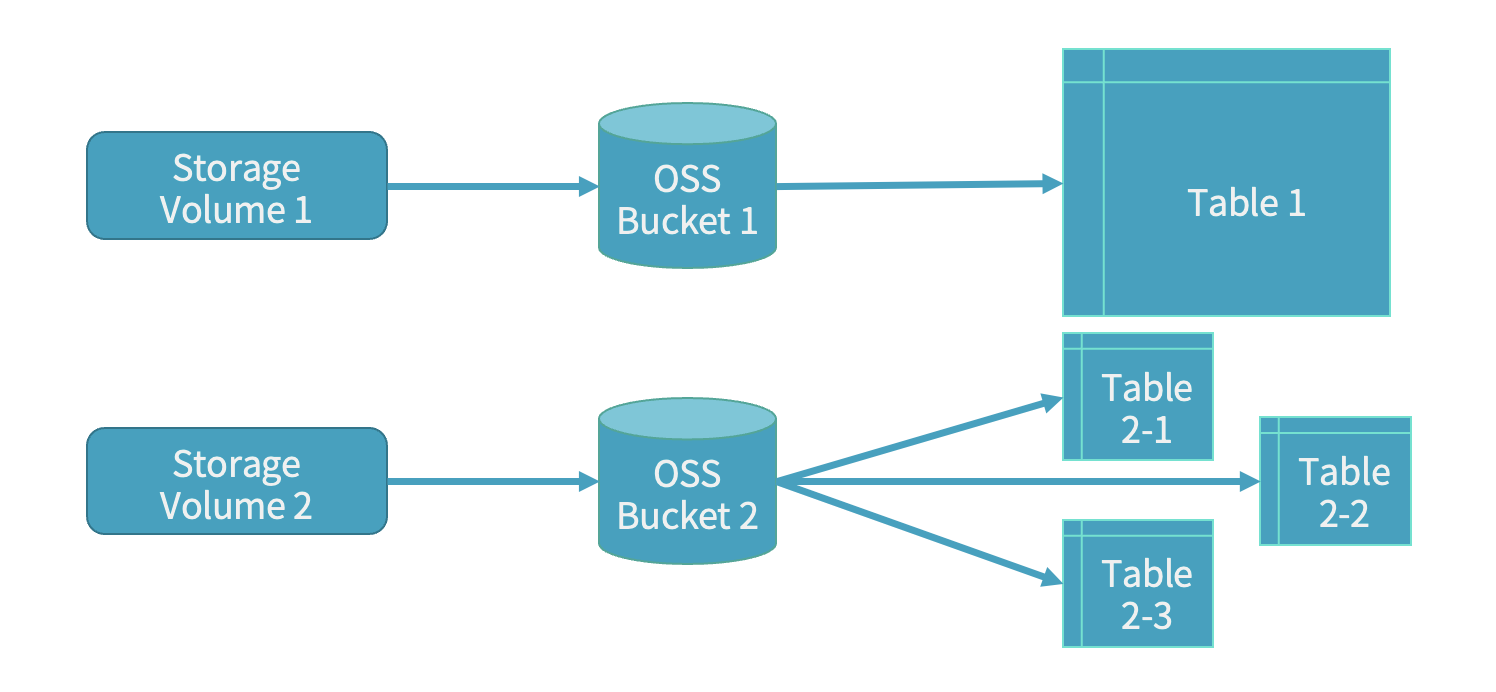
在存算分离架构中,引入了“存储卷(Storage Volume)”的概念,实际上对应云 OSS 的 Bucket。在 StarRocks 端,存算分离模式可与京东云 OSS 完美兼容。然而,由于 OSS 的每个 Bucket 存在流量、IOPS 等限制,为避免单个 Bucket 存储过多表导致性能瓶颈,我们对表与 Bucket 的映射进行了优化:大表独享一个 Bucket,以保证高吞吐;小表则根据流量预估,合并存储至同一个 Bucket,以提高资源利用率。
此外,在存算分离集群中,我们新增了一张元数据表,用于维护 Table、存储卷与 Bucket 之间的映射关系。由于默认情况下无法通过 Information Schema 查看存储卷的具体分布,这一改进使我们能够及时查询每个存储卷上存储的表,避免因误用导致的性能瓶颈。
2.4 实时写入存量分离表
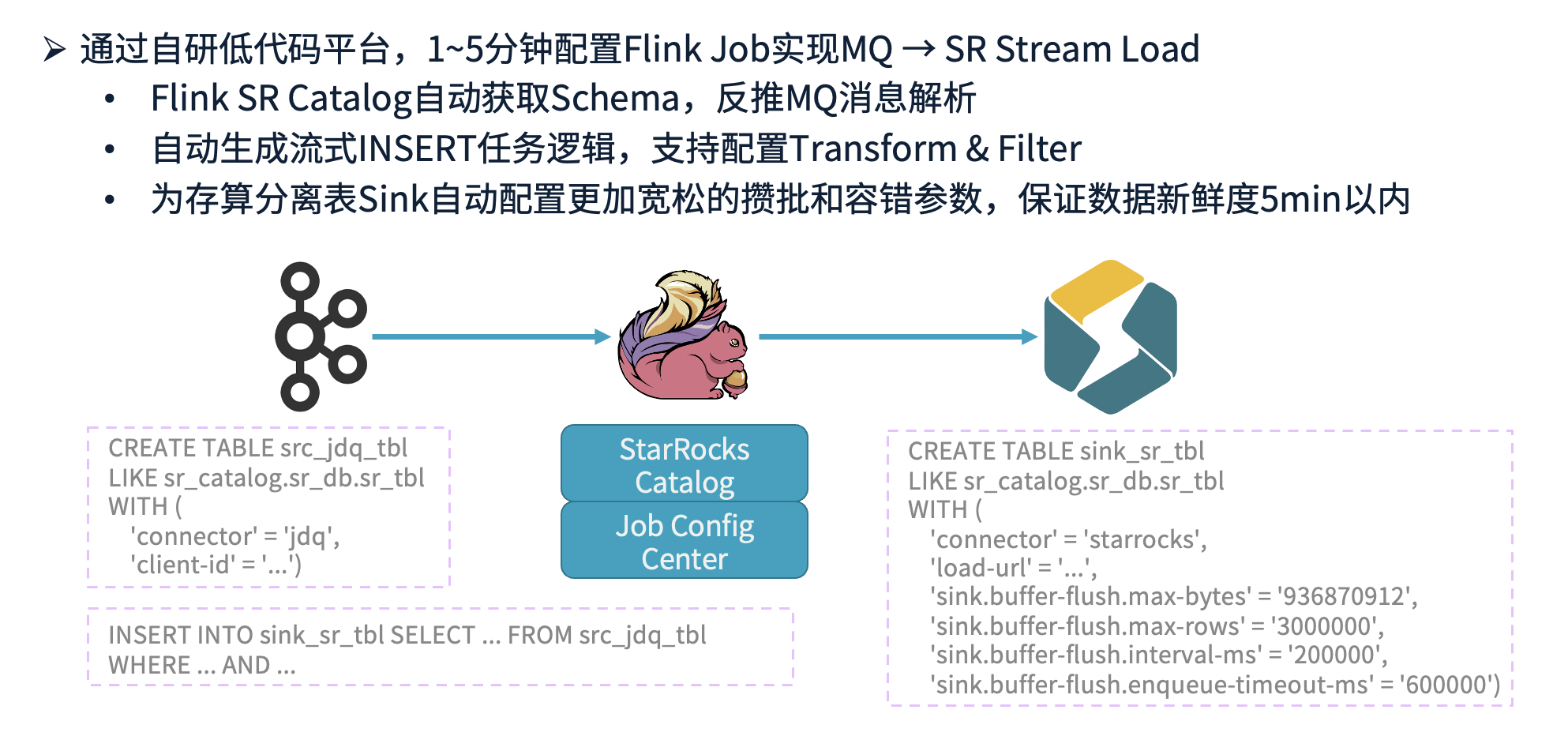
在实时数据写入 StarRocks 方面,我们全部采用 Flink 进行数据导入,这已成为非常成熟的方案。依托自研的低代码平台,用户可通过配置式操作(点选或拖拽)快速搭建数据同步任务。对于简单的同步任务,最快可在 1 分钟内完成配置,最慢也仅需 5 分钟。数据通过 MQ 传输,并利用 StarRocks 的 Stream Load 机制,由 Flink 写入 StarRocks 集群。
在 Flink 与 StarRocks 的集成方面,我们针对 StarRocks Catalog 进行了优化。StarRocks Catalog 采用反推策略,从 StarRocks 元数据中获取存算分离表的 Schema,并以此推导 Kafka 流表的 Schema。这样即使流表没有 Schema Registry 也能顺利推导出 Schema。
此外,在数据写入过程中,INSERT 任务通常涉及 ETL 操作,如 SELECT FROM WHERE 语句中的Transform和筛选Filter。在我们的平台中,这些 SQL 语句可由系统自动生成,用户无需手动编写,仅在特殊需求时进行调整,实现开箱即用的便捷体验。
由于存算分离架构涉及 OSS 访问瓶颈等因素,我们在存算分离表的 Sink 端默认采用较为宽松的批量缓冲与容错参数。结合我们的业务场景,数据量巨大但对时效性的要求相对不太高,大部分数据延迟在 3-5 分钟内即可满足用户需求。因此,这种参数配置既能满足业务需求,又降低了系统I/O负担。
三、性能表现与降本增效
3.1 写入吞吐数据
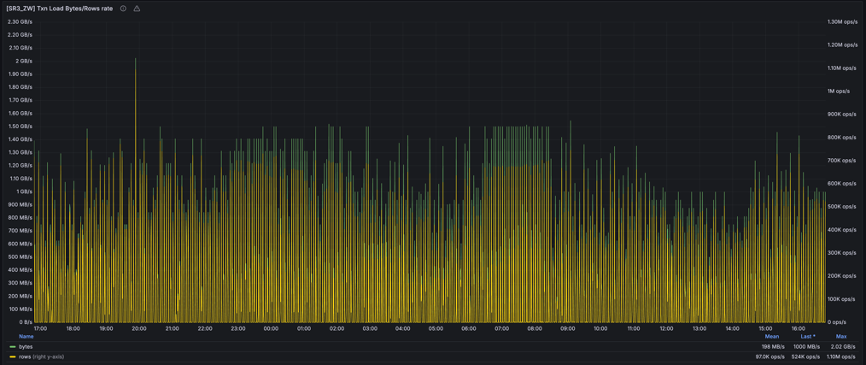
在部分业务迁移至存算分离架构后,我们对其性能表现和成本优化情况进行了评估。以下是某天的数据写入吞吐量统计,展示了平日业务运行状态。
以单张大表为例,其日均新增数据量可达数十亿条,日均更新次数则高达数百亿,部分场景甚至接近千亿级别。为优化写入性能,我们启用了 Batch Publish Version 这一关键优化策略。在该优化机制的支持下,存算分离集群的写入吞吐量基本与同等规模的存算一体集群保持一致。
值得注意的是,该存算分离集群仅由 5 个节点组成,但依然能够支撑如此高负载的数据写入。
3.2 查询性能
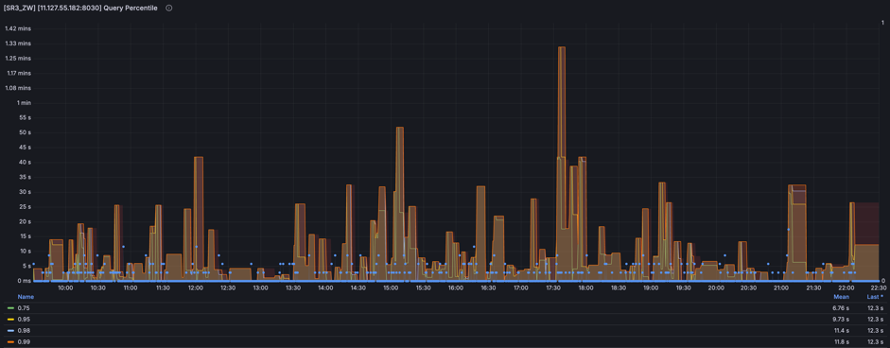
在查询场景方面,用户通常需要执行 同比、环比分析或长周期查询,这类查询模式类似于传统离线数仓的 OLAP 查询方式。因此,用户在 StarRocks 上的查询方式往往与其在 Hive 上的使用习惯保持一致,即一次性扫描大量分区,查询数十亿行数据。
为评估存算分离架构下的查询性能,我们在 5 个 CN 节点 规模的集群上进行了测试,并将 Cache TTL 设定为 20 天。
-
Cache hit 场景:由于大多数用户查询的仍然是近线数据,因此缓存命中率较高。在此情况下,P95 和 P99 查询延迟均小于 10 秒,与同规模的存算一体集群性能相近。
-
Cache miss 场景:查询响应时间仍然在可接受范围内,极少超过 1 分钟,整体远优于 Hive 体系下的查询速度,能够满足用户的分析需求。
3.3 OSS 性能与降本效果
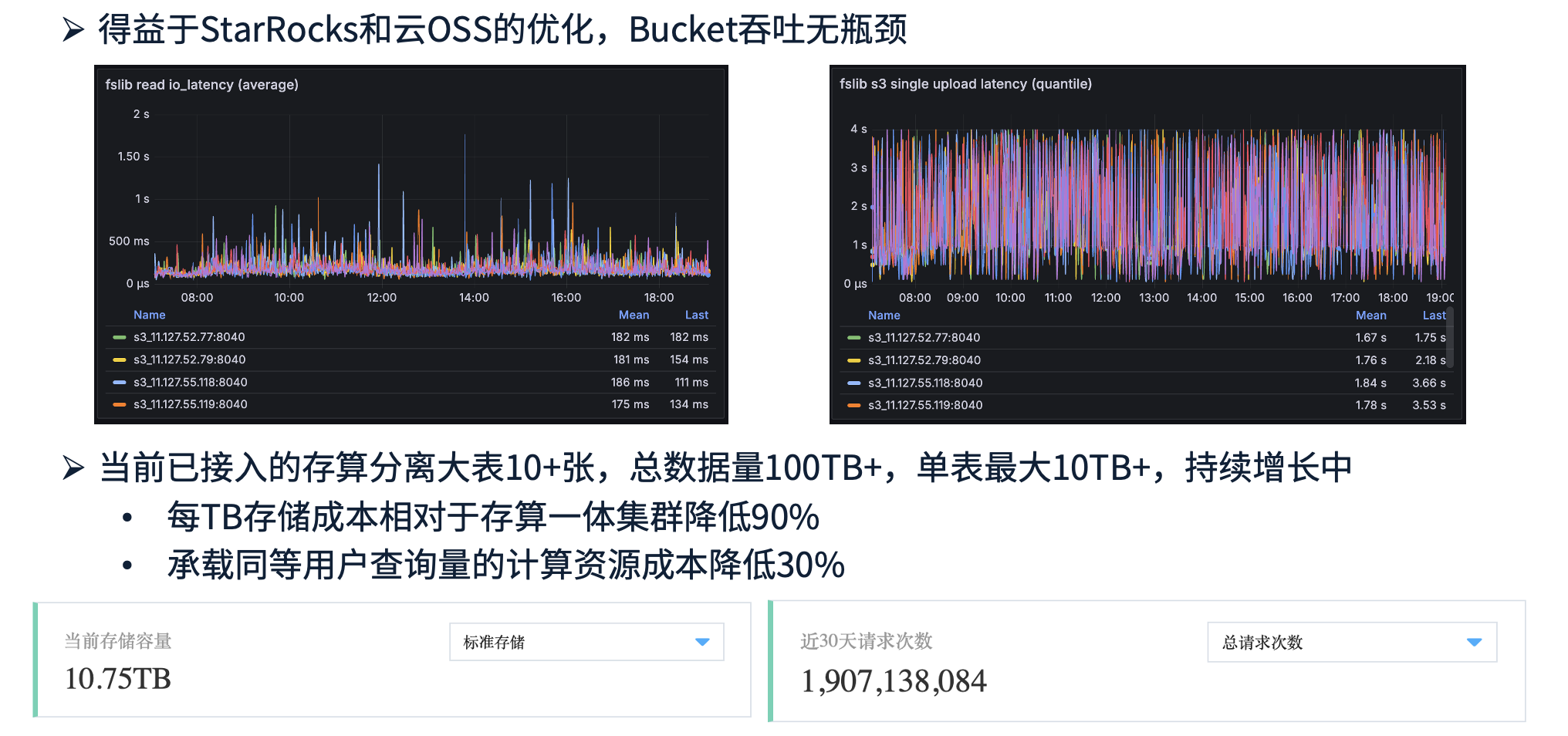
在存算分离架构下,StarRocks 对 S3 访问进行了多项优化,同时云厂商的 OSS 方案 也针对自身存储系统进行了优化,使得 Bucket 的吞吐能力不会成为瓶颈。
以某张大规模读写查询的表为例,其对应的 Bucket 读取 I/O 延迟稳定在 2 秒以内,上传延迟保持在 4 秒以内,整体性能表现稳定可靠。
存算分离后,每 TB 的存储成本相比原存算一体架构降低 90%,主要得益于原架构基于本地 SSD,而存算分离利用了 对象存储(OSS),极大降低了存储开销。通过 HPA(Horizontal Pod Autoscaler) 进行弹性扩缩容,根据实际负载动态调整计算资源,相较于原架构,同等查询量下计算资源成本降低约 30%。
四、稳定性保障与调优实践
4.1 Compaction 调优
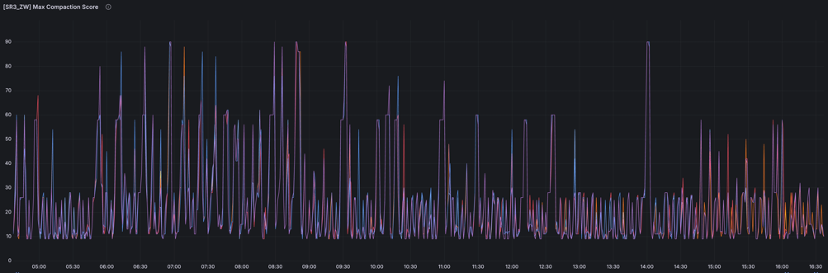
在存算分离架构下,我们对稳定性保障和调优进行了专项优化,尤其是在 Compaction 机制、吞吐优化和监控预警 方面。首先,我们发现 StarRocks 默认对 CN(Compute Node)节点的 Compaction 处理较为保守,因此在确保 CN 规格足够的情况下,我们直接增大了 Compaction 线程数和线程池队列。同时,为了更好地利用 OSS 的大吞吐能力,我们调整了 Base Compaction 和 Cumulative Compaction 的触发逻辑,使得 Cumulative Compaction 更容易触发并能更快完成,从而减少对大批量写入的干扰。
此外,我们对 Compaction Score 设立了严格的监控和预警机制,以防止其无限制增长影响查询性能。一旦监测到异常情况,我们可以及时调整参数,确保系统运行在合理范围内。在更新的StarRocks 3.3版本中,我们更可以配置合理的 Ingestion Slowdown 阈值,配合 Flink Sink 的反压机制,一同调控写入速度。
4.2 Vacuum 调优


在存算分离架构下,Vacuum 机制 对于存储量至关重要,但往往容易被忽视。Vacuum 主要用于清理历史无效数据,可以理解为 OSS 的 GC 过程。Compaction 完成后,旧版本的数据文件仍会留在 OSS 中,而 Vacuum 线程则负责清理这些无用文件,避免存储资源的浪费。如果 Vacuum 运行不及时,可能会导致 SHOW DATA 命令展示的数据量与 OSS Bucket 实际存储量存在较大差异,进而增加存储成本。
为了确保 Vacuum 机制的高效运行,我们需要重点关注一些关键监控指标,比如当前队列中 delete file tasks,以及 OSS 上 Metadata 遍历的延迟。如果任务积压过多或遍历延迟过大,可能意味着 Vacuum 线程处理能力不足,或者写入过于激进。这时,我们可能需要适当暂停写入,优先让 Vacuum 任务执行完成,使 Meta 维持在合理水平。此外,FE Leader 日志中会输出 Vacuum Daemon 的运行状态,若观察到 hasError = true 的日志,则需要进一步排查是 CN 计算资源的瓶颈,还是写入压力导致 Vacuum 处理压力大。
Vacuum 在 CN 节点执行时,默认复用存算一体架构下就存在的 release snapshot 线程池,但线程池的默认容量较小(仅为5),同时进行 GC 的分区并行度也有限(默认为8),因此需要根据数据量适当调整参数,以避免在大批量写入场景下出现性能瓶颈。此外,在业务高峰期(如双十一)查询流量激增时,若 Vacuum 过于激进,可能会导致查询所依赖的 Meta 文件被提前删除,从而引发 404 查询失败。因此,在查询压力大的情况下,我们需要适当扩大历史版本的保留时间(Grace Period),以确保用户查询的稳定性。
4.3 分区查询硬限制
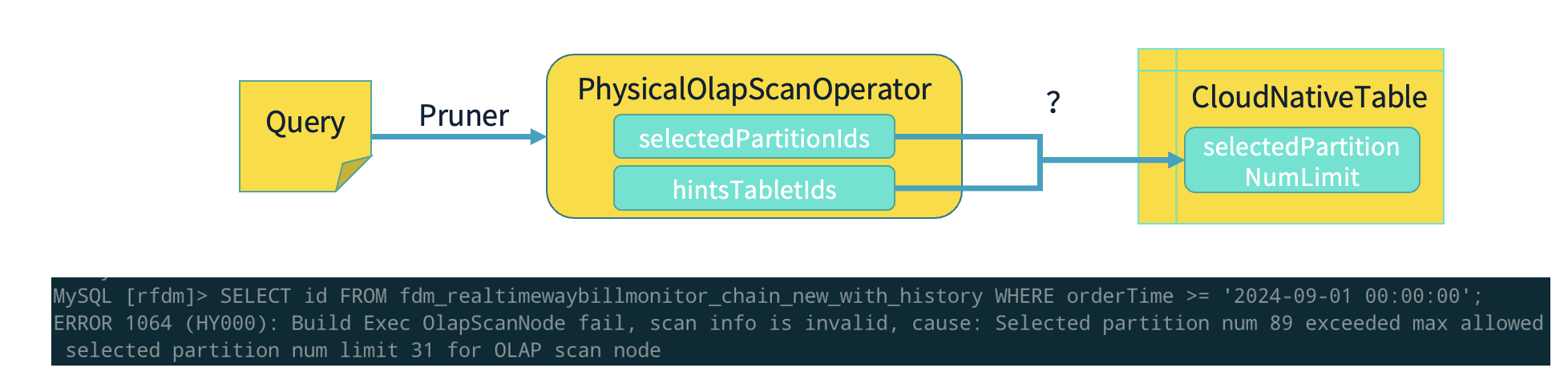
关于分区查询的硬限制,实际上是在存算分离的集群中,当数据积累到一定规模时,为了避免查询全表扫描(主要是针对没有做分区裁剪的 SQL 查询),我们需要加以限制。方法是在 CloudNativeTable 定义中加入 selectedPartitionNumLimit 建表参数,并在建表时根据业务特点,设置单条查询最大允许扫描的分区数(如31)。这样,如果用户在查询时没有按照分区进行裁剪,或者提交了超出预设查询范围的 SQL,系统会直接拒绝该查询,并给出明确的错误提示。
这个限制是基于业务需求来设定的,目的是保证集群在处理大量数据时不至于因为不合理的查询而导致性能瓶颈,或者因资源过度消耗导致集群不可用。
不过,也有一些特殊情况。比如在 StarRocks 内部,统计信息的收集和 CBO 的执行是必须对所有数据进行扫描的,包括可能会使用到 tablet hint 进行查询的情况。为了确保 CBO 的准确性,这类查询即使没有分区裁剪,也需要被放行。因此,我们在实现这个限制时需要特别考虑到这些特殊查询场景,避免影响到优化器的正常运行。
4.4优化统计信息收集

在统计信息收集的优化方面,我们对默认的全量统计信息收集策略进行了调整,以避免对业务高峰期的查询性能造成影响。默认情况下,统计信息的收集是按照全量的方式进行的,并且是有调度时间的,但这种调度有时可能会发生在业务高峰期(比如下午 3 点到 4 点),这时候大量的统计信息收集操作可能会影响查询时效性,特别是当某些表的分区数量特别多,尽管单个分区的数据量不大,但分区数的增多会导致表的 Tablet 数达到几万个,比如我们最大表的 Tablet 数量为 64,000 多个。
为了解决这个问题,我们对统计信息的收集策略做出了优化:将全量统计信息的收集调整到凌晨没有业务高峰的时间段进行,而在平时的工作时间则采用增量收集策略。这种方式确保了在高峰期间,统计信息的收集不会影响正常的查询性能,同时在夜间进行全量收集,有助于 CBO 更好地进行查询优化。
五、未来规划
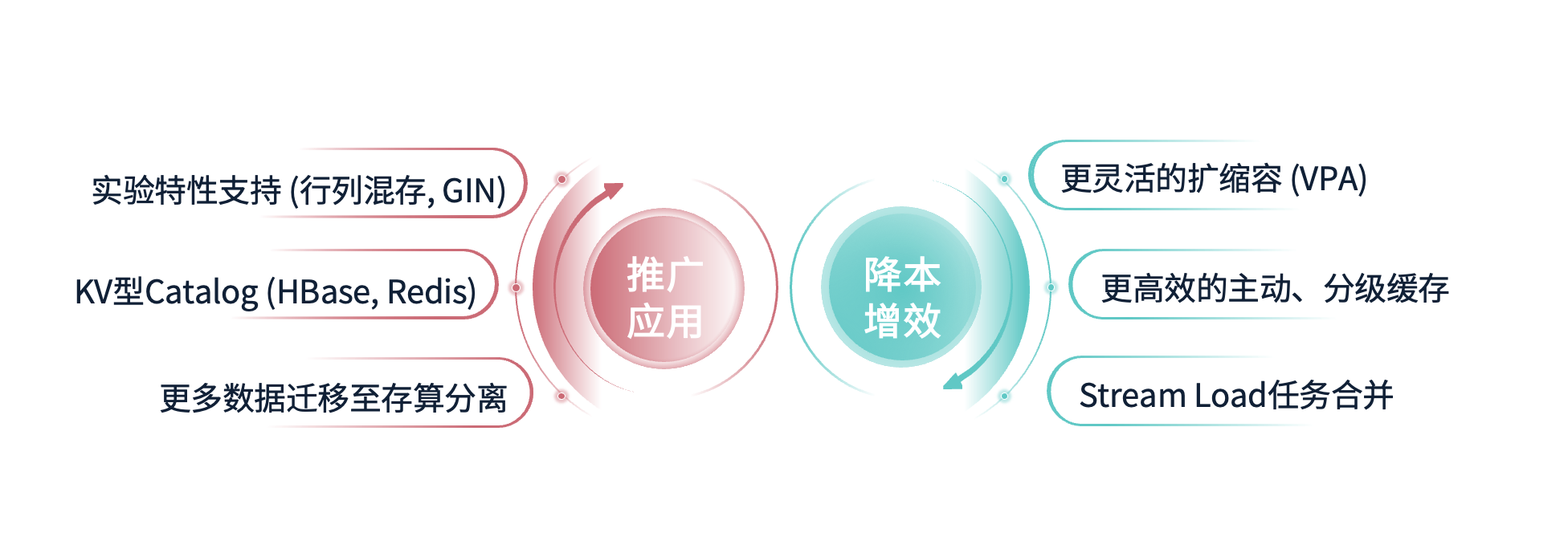
然后最后是我们未来的计划,未来计划主要分两大块,即推广应用和降本增效。
在推广应用方面,我们的首要目标是将更多的数据迁移到存算分离集群中,进一步发挥存算分离架构的优势。其次,我们计划尝试构建 KV 型的 Catalog,目前在内部有许多维度数据存储在 Redis 和 HBase 中,我们希望能够将这些数据接入到 StarRocks 中,形成更为统一的数据访问层。此外,我们还计划支持更多实验特性。虽然目前存算一体支持的某些特性在存算分离中尚未支持,但我们关注的特性如行列混存(Columnar-Row Hybrid Storage)和倒排索引(GIN)等,预计会与社区合作,共同推进这些特性的实现。
降本增效的三大主要策略:
1. Stream Load任务合并
在迁移到存算分离架构后,我们的Stream Load任务受益于OSS的高吞吐量,整体负载比之前有所降低。因此,传统上一个Stream Load任务对应一个数据源的方式不再必要。我们可以在一个Flink任务中合并多个Stream Load任务链路,通过并行处理多个流数据,优化流式数据的写入效率。
2. 更高效的主动缓存管理
在存算分离架构下,虽然基本的缓存机制已经搭建完毕,但对于一些重要且对时效性要求极高的用户场景(如大屏数据展示),我们将通过更主动的缓存策略提升系统的响应速度。具体来说,我们将大数据集预先加载到高效缓存系统(如Redis),这样当用户查询时,系统能够快速响应,而无需从OSS或计算节点重新拉取数据。
3. 灵活的扩缩容能力
存算分离架构带来的弹性扩缩容能力使得资源的配置更加灵活和高效。在大多数情况下,基于HPA(可以自动根据负载来调整集群的节点数,但在一些复杂场景下,我们还计划引入VPA(Vertical Pod Autoscaler),以便在不改变节点数量的前提下,动态调整节点规格,提升单个节点的计算能力。
更多交流,联系我们:StarRocks


![[C++] 智能指针 进阶](https://i-blog.csdnimg.cn/direct/a0e152ccc8d94c8db4dd4bf1005f0c63.png#pic_center)
















![[ 春秋云境 ] Initial 仿真场景](https://i-blog.csdnimg.cn/direct/a9c5b7e8d58f4b7389552793b8e64597.png#pic_center)