第二篇讲解了如何本地安装大模型,然后编写一个基于js+springboot的项目,通过页面实现对话的功能。实际上,上面的demo用到是deepseek提供的接口,那么deepseek共提供了多少接口呢?这就要讨论到deepseek的接口库了,即api。本文介绍deepseek的官网api,以及提供了哪些接口可以供我们调用,能完成哪些功能。
一.api的官方地址
首先进入官方地址:https://www.deepseek.com/ 找到入口:
进入api开放平台
用手机号登录之后,进入页面:
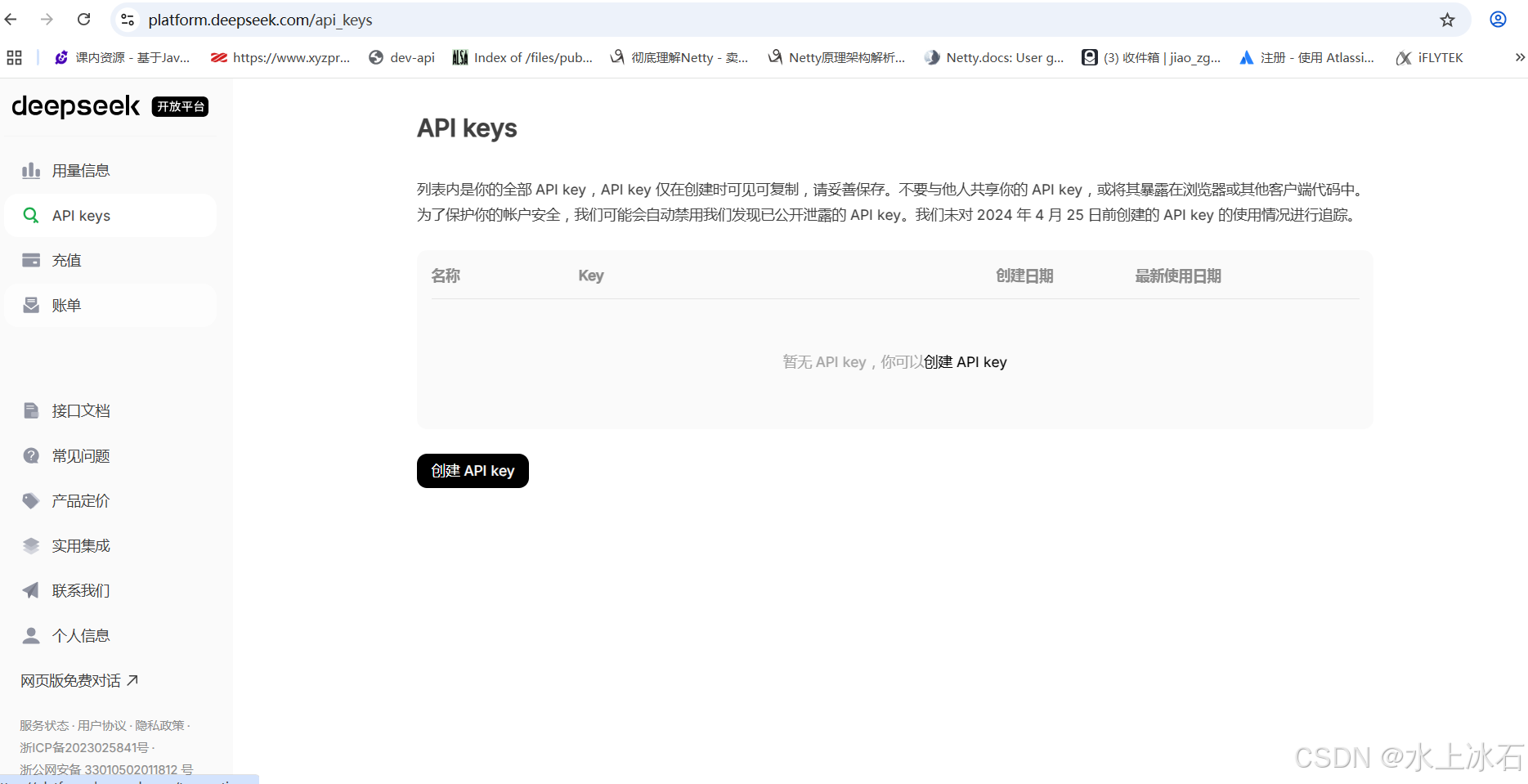 右侧点击 接口文档
右侧点击 接口文档
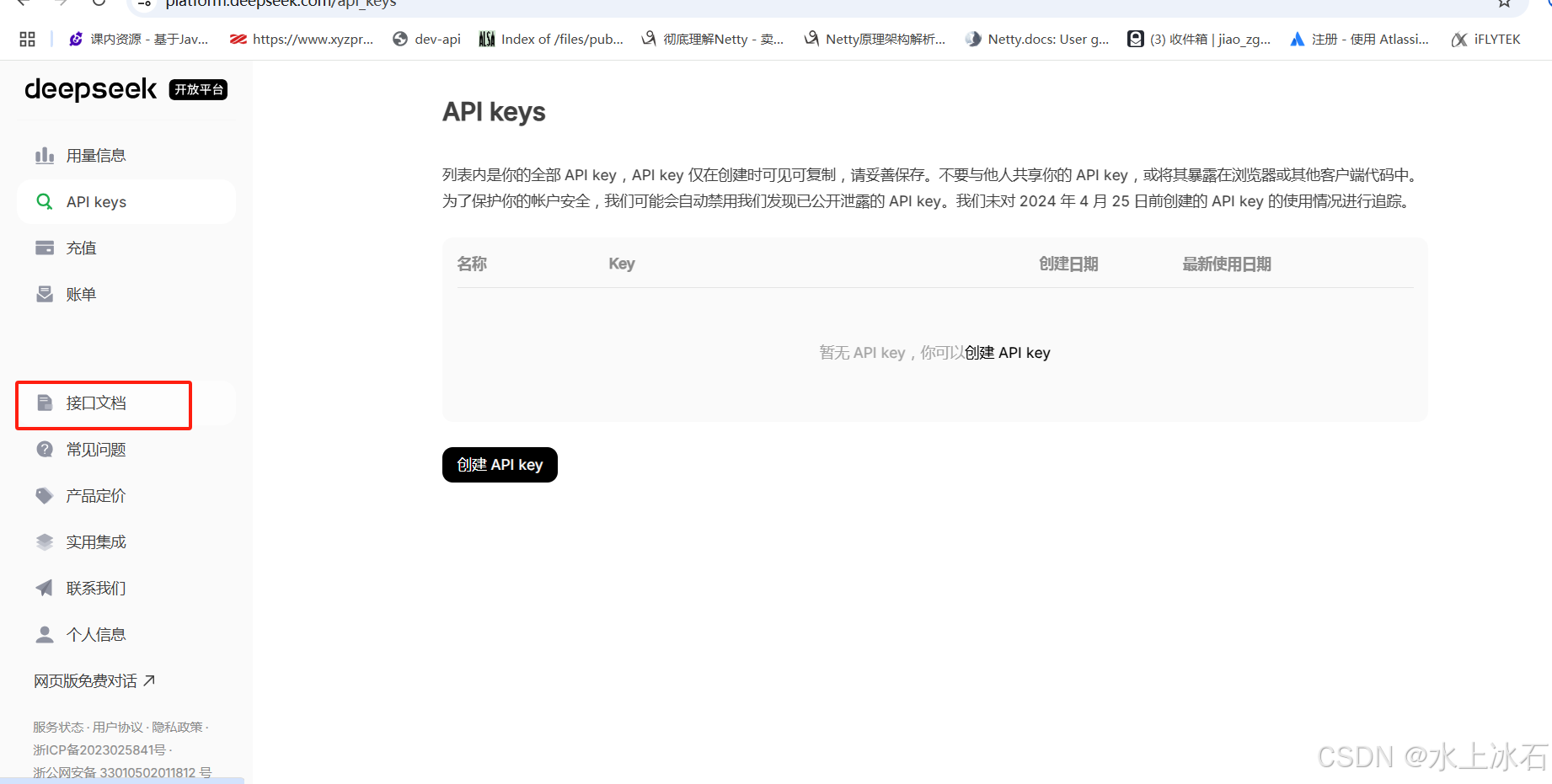 进入api文档界面
进入api文档界面
右侧主要关注这三部分:快速开始 、API 文档、API 指南

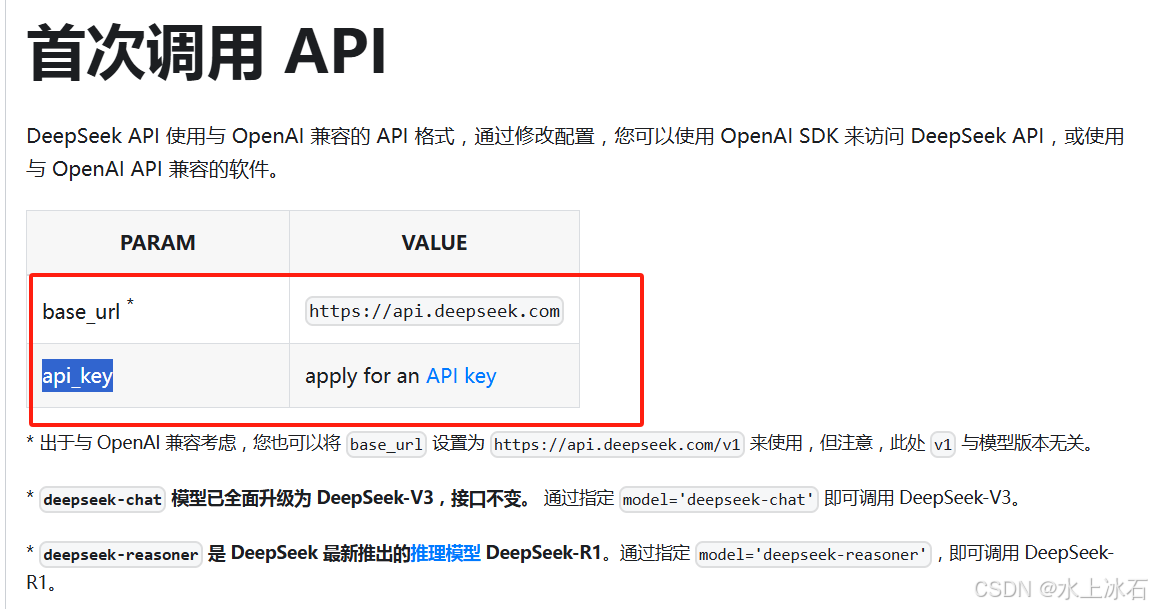
快速开始:通过该章,可以快速进入demo编写的阶段(调用的如果是官网开放的模型,需要配置官方的base_url和api_key,如果使用的是本地自己部署的,则只需要地址,不需要密码)
接下来我们分别来介绍这三部分
二.开放接口的详细内容
1.快速开始
1.1 这章节告诉我们通过什么网址,端口和方式来访问模型提供的开放功能。
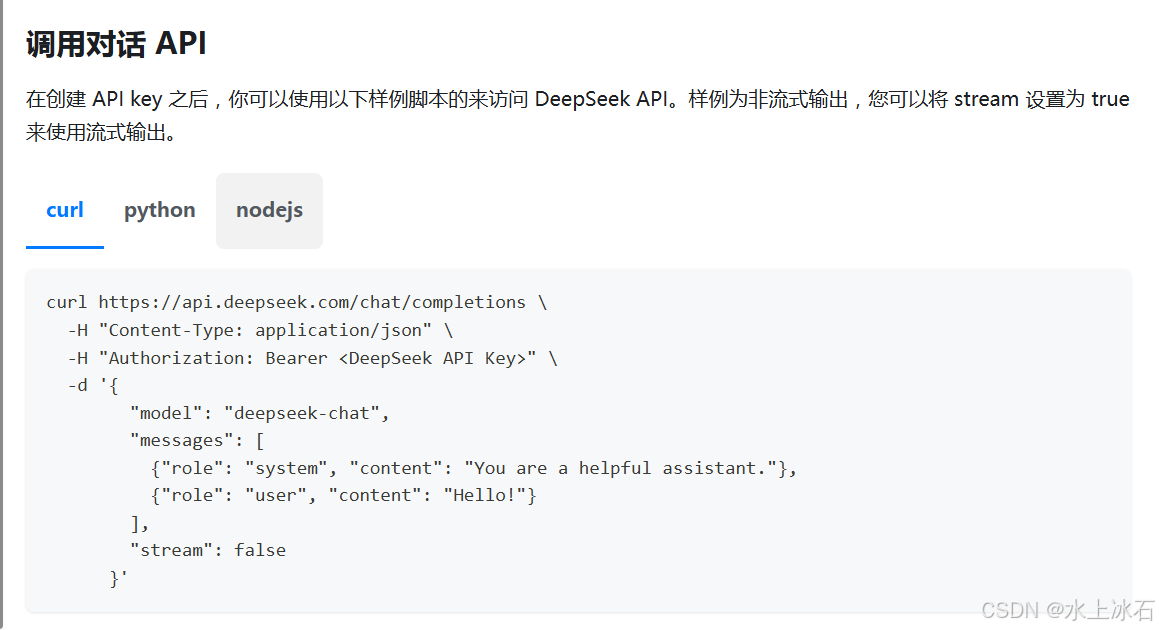 提供了curl方式,python语言和nodejs的调用示例。
提供了curl方式,python语言和nodejs的调用示例。
本文一nodejs为例:
// Please install OpenAI SDK first: `npm install openai`
import OpenAI from "openai";
const openai = new OpenAI({
baseURL: 'https://api.deepseek.com',
apiKey: '<DeepSeek API Key>'
});
async function main() {
const completion = await openai.chat.completions.create({
messages: [{ role: "system", content: "You are a helpful assistant." }],
model: "deepseek-chat",
});
console.log(completion.choices[0].message.content);
}
main();上篇文章是以java编写的,当然本质上都是http协议的接口,通过java的http客户端代码也可以很方便的调用,这里参考上文,不再赘述。
1.2 Temperature
Temperature 属性是大模型很重要的一个配置项,通俗理解是用来表示模型的“想象力”的,这个值越大,其发散能力越强,聚集能力也相应变弱。
不同的配置适合不同的场合,就好像左右脑,有的逻辑思维强,需要用大脑左半球,感性的知识需要用大脑右半球,这里的 代码生成/数学解题 等配置成0 最合适,不适合发散, 创意类写作/诗歌创作类的需要发散思维的,需要配置更高一些,例如官网给的示例1.5.这里需要根据自己的业务场合进行配置。默认1.0,适合数据分析和数据抽取的业务场景,特别提到通用对话最好也也配置一下,改为1.3

1.3 token用量
token用量也是大模型自然语言的非常重要的一个概念,直观的理解为“字”或“词”;通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token。
一般情况下模型中 token 和字数的换算比例大致如下:
- 1 个英文字符 ≈ 0.3 个 token。
- 1 个中文字符 ≈ 0.6 个 token。

这个值一般也是我们量化计算机算力的一个指标。
2.API 文档
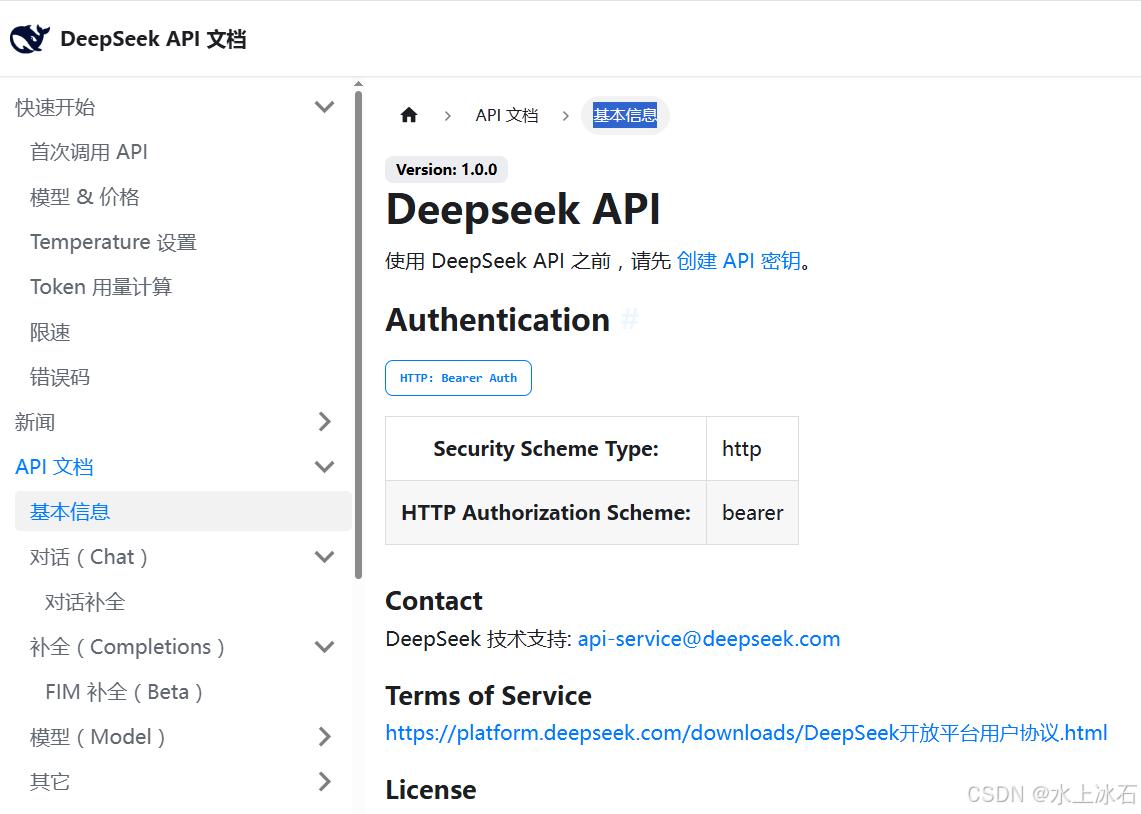
2.1 基本信息
这里定义了http接口的
HTTP Authorization Scheme为bearer
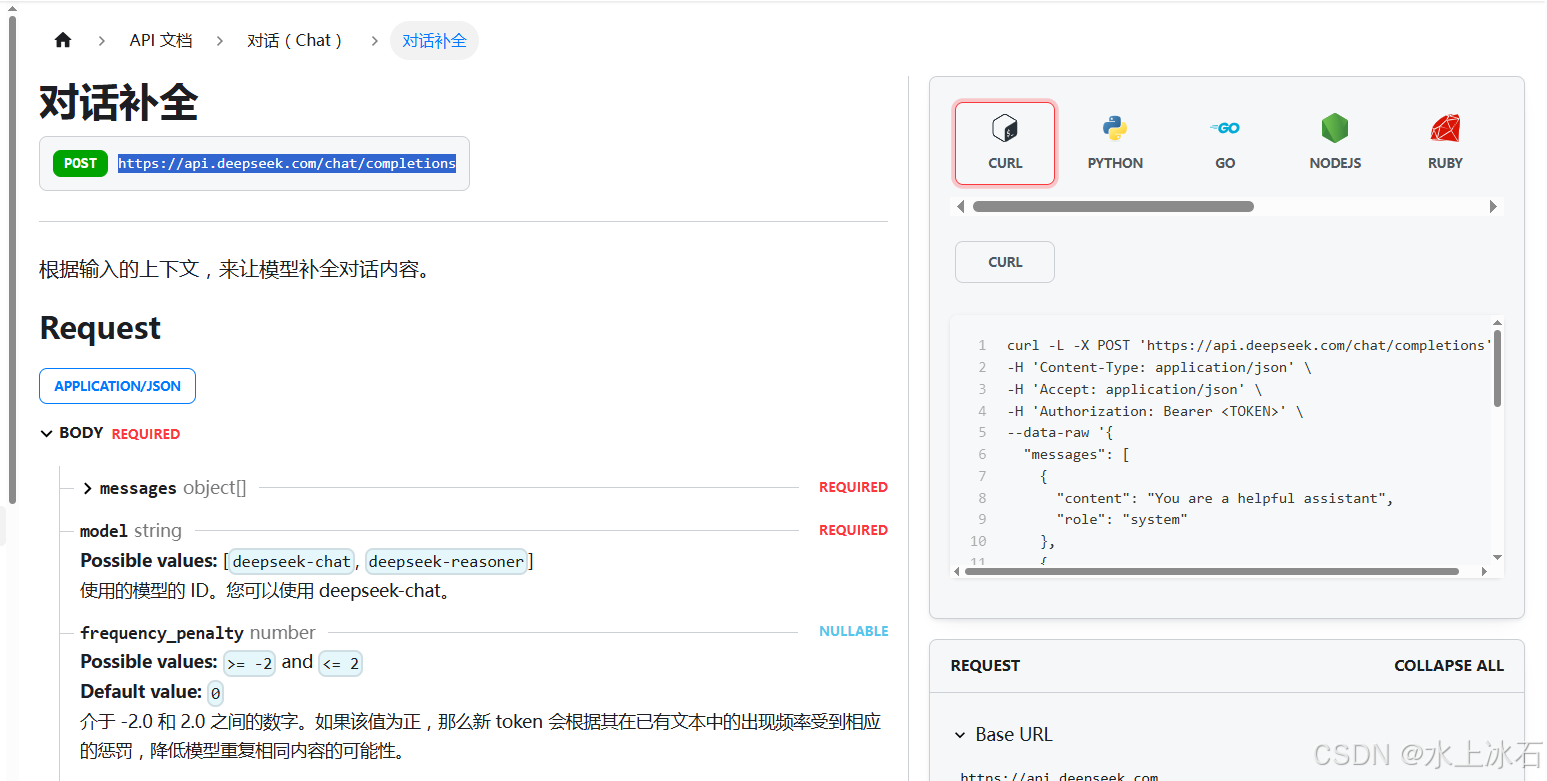
2.2 对话补全接口
详细解释了一个接口:
https://api.deepseek.com/chat/completions
这个接口是用来做对话补全的,包括接口的入参和返回结构。也是http接口,post的,
调用接口的示例如下:
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("application/json");
RequestBody body = RequestBody.create(mediaType, "{\n \"messages\": [\n {\n \"content\": \"You are a helpful assistant\",\n \"role\": \"system\"\n },\n {\n \"content\": \"Hi\",\n \"role\": \"user\"\n }\n ],\n \"model\": \"deepseek-chat\",\n \"frequency_penalty\": 0,\n \"max_tokens\": 2048,\n \"presence_penalty\": 0,\n \"response_format\": {\n \"type\": \"text\"\n },\n \"stop\": null,\n \"stream\": false,\n \"stream_options\": null,\n \"temperature\": 1,\n \"top_p\": 1,\n \"tools\": null,\n \"tool_choice\": \"none\",\n \"logprobs\": false,\n \"top_logprobs\": null\n}");
Request request = new Request.Builder()
.url("https://api.deepseek.com/chat/completions")
.method("POST", body)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/json")
.addHeader("Authorization", "Bearer <TOKEN>")
.build();
Response response = client.newCall(request).execute();这个接口其实跟我们通过网页对话是类似的参数,采样温度的设置,token长度的设置
可以选择返回是流式输出还是json模式
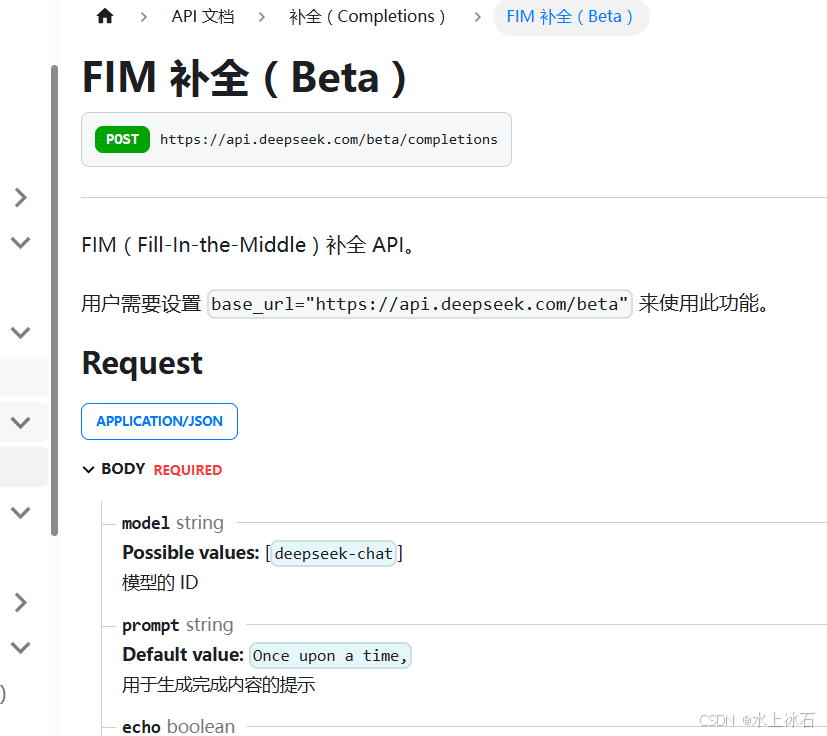
2.3FIM 补全(Beta)
接口地址:https://api.deepseek.com/beta/completions
特别注意:
用户需要设置 base_url="https://api.deepseek.com/beta" 来使用此功能。
同样是一个http接口,具体不详细赘述
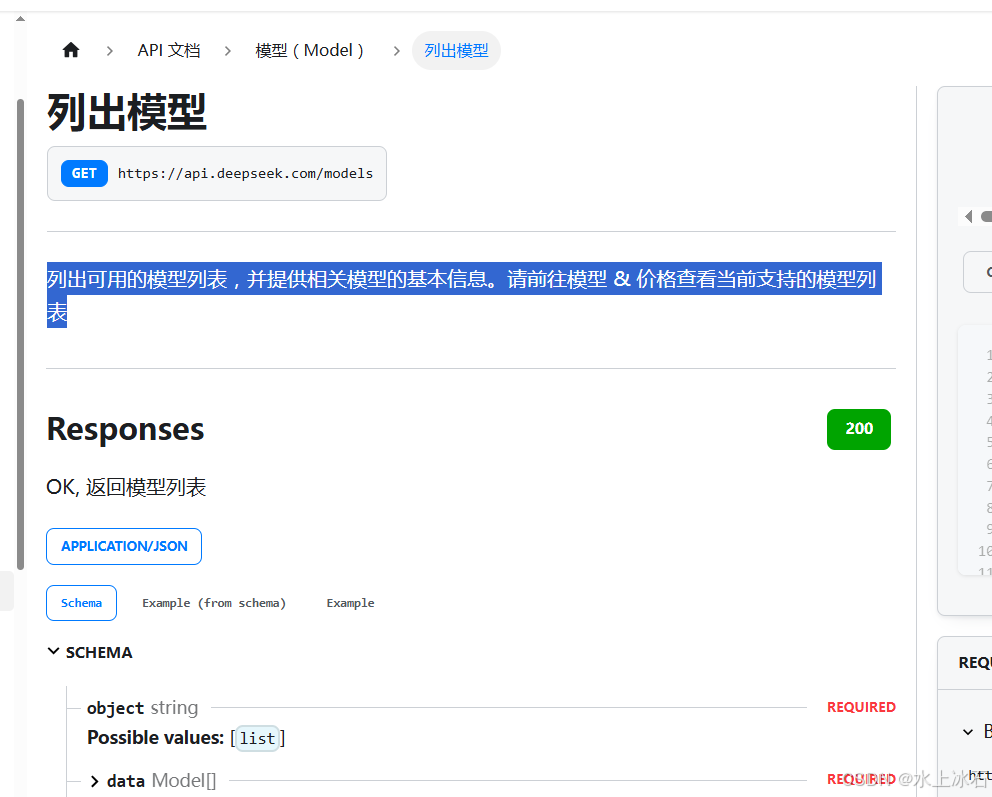
2.4 模型(Model)列出模型
接口地址:
https://api.deepseek.com/models
get方式接口
列出可用的模型列表,并提供相关模型的基本信息。
代码示例:
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("text/plain");
RequestBody body = RequestBody.create(mediaType, "");
Request request = new Request.Builder()
.url("https://api.deepseek.com/models")
.method("GET", body)
.addHeader("Accept", "application/json")
.addHeader("Authorization", "Bearer <TOKEN>")
.build();
Response response = client.newCall(request).execute();3.API 指南
https://api-docs.deepseek.com/zh-cn/guides/reasoning_model
本章是做了几个概念的解释
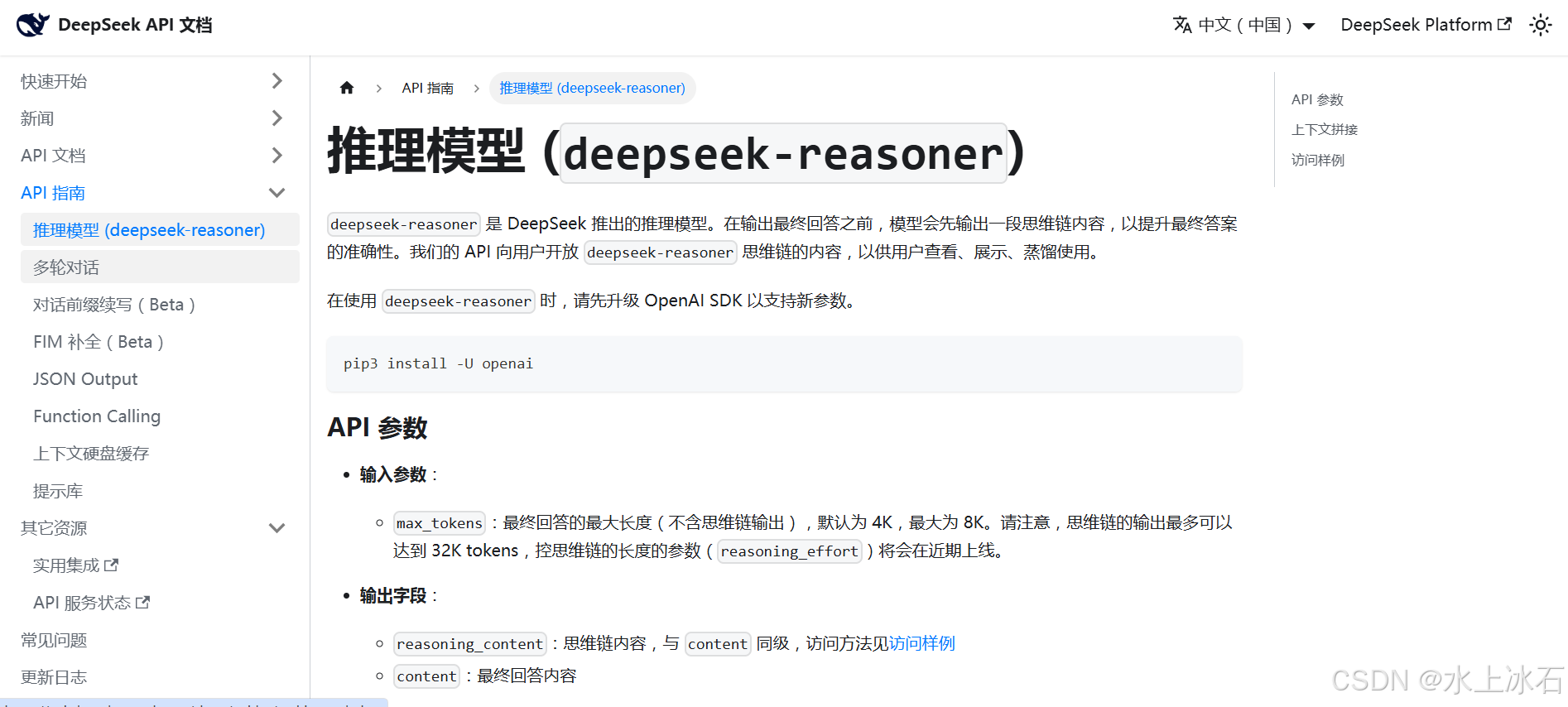
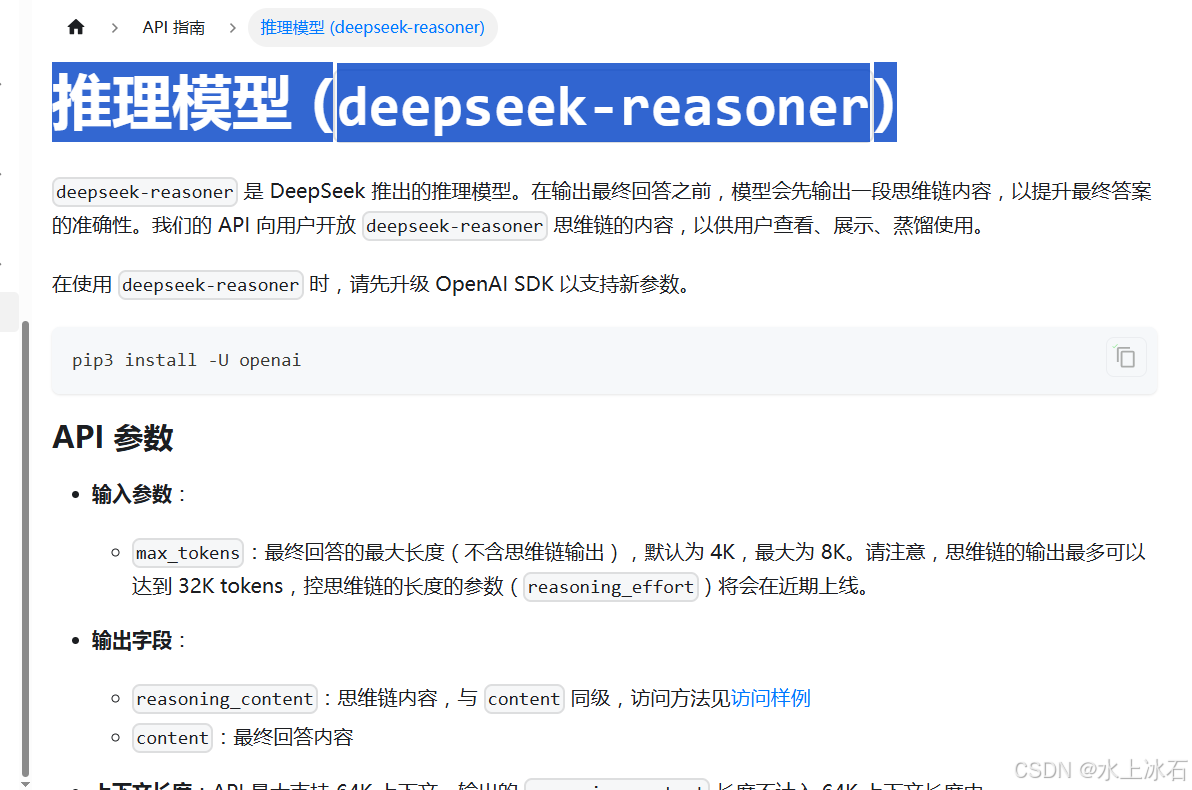
3.1推理模型 (deepseek-reasoner)
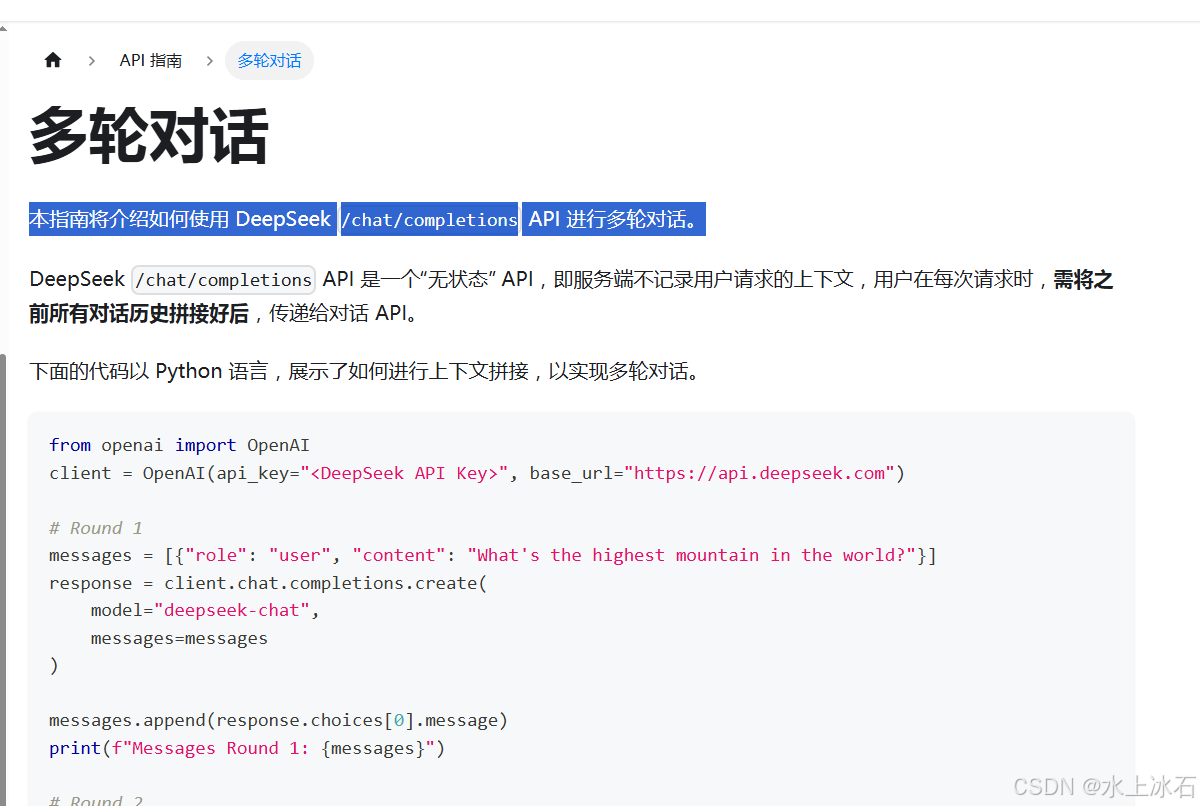
3.2多轮对话
本指南将介绍如何使用 DeepSeek /chat/completions API 进行多轮对话。
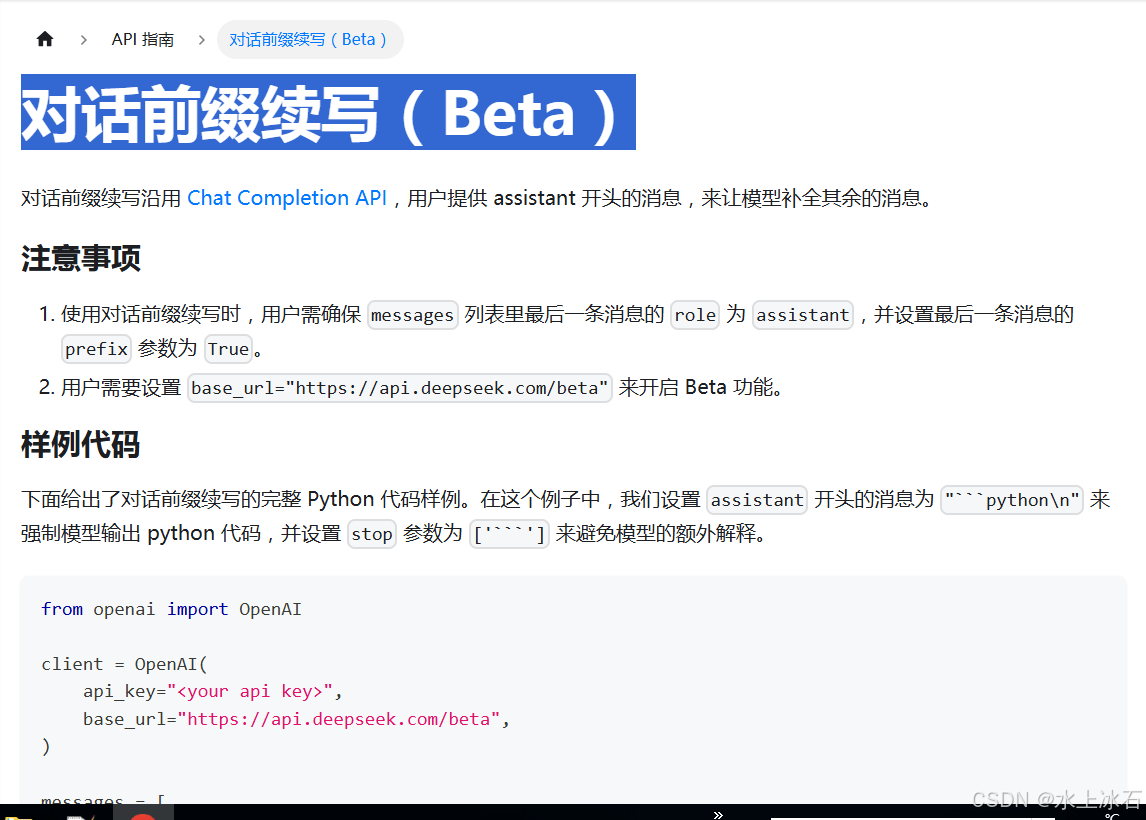
3.3对话前缀续写(Beta)
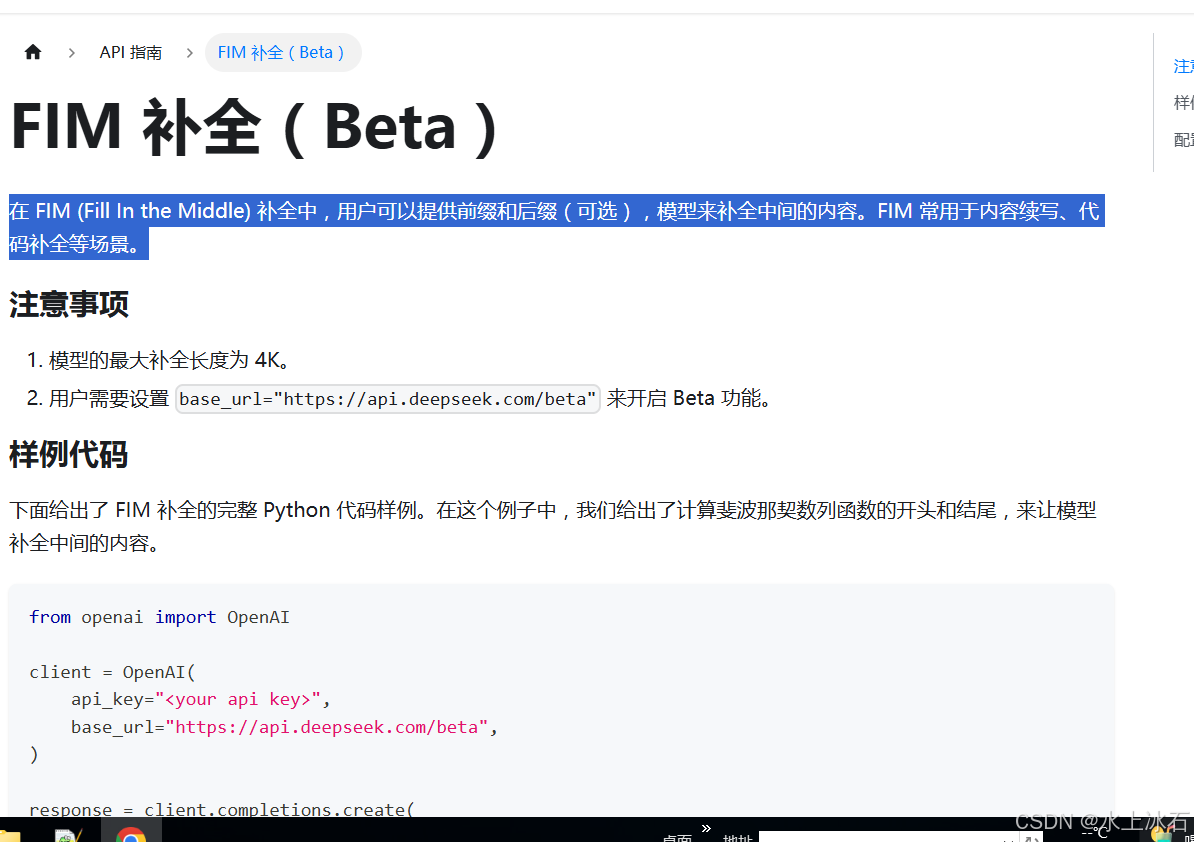
3.4FIM 补全(Beta)
在 FIM (Fill In the Middle) 补全中,用户可以提供前缀和后缀(可选),模型来补全中间的内容。FIM 常用于内容续写、代码补全等场景。
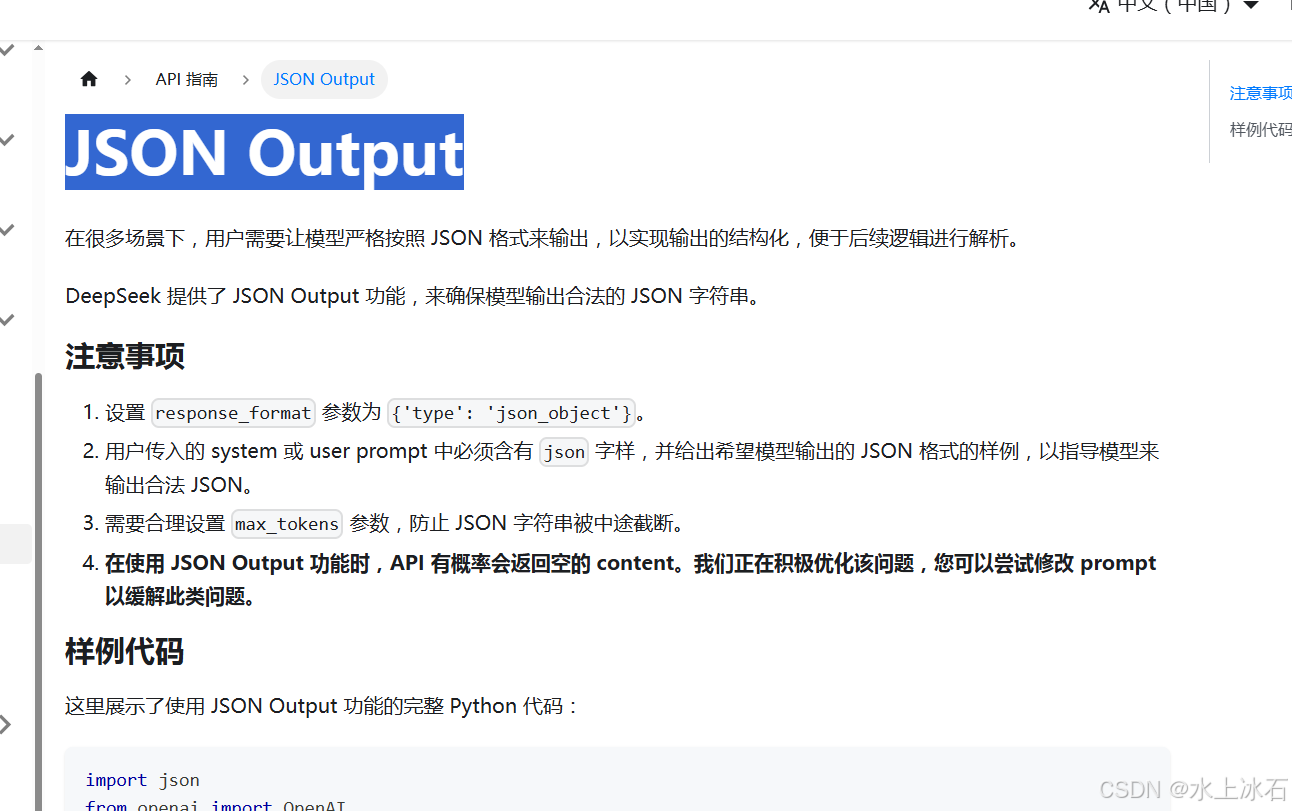
3.5JSON Output
在很多场景下,用户需要让模型严格按照 JSON 格式来输出,以实现输出的结构化,便于后续逻辑进行解析。
DeepSeek 提供了 JSON Output 功能,来确保模型输出合法的 JSON 字符串。
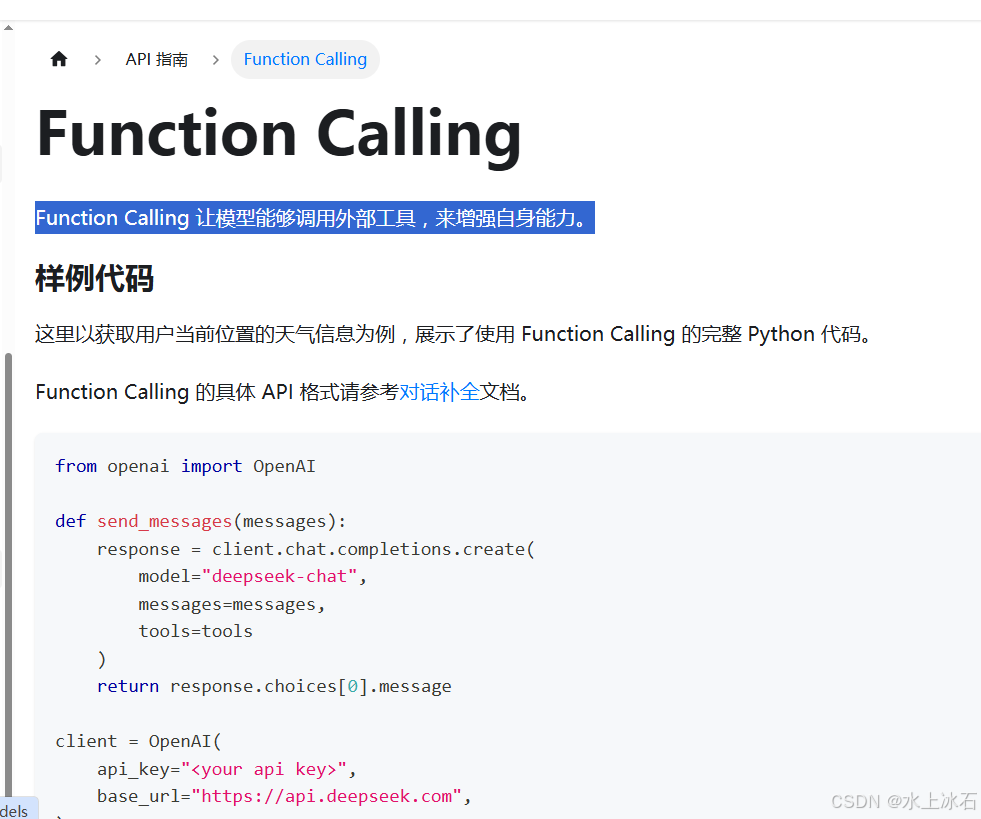
3.6Function Calling
Function Calling 让模型能够调用外部工具,来增强自身能力。
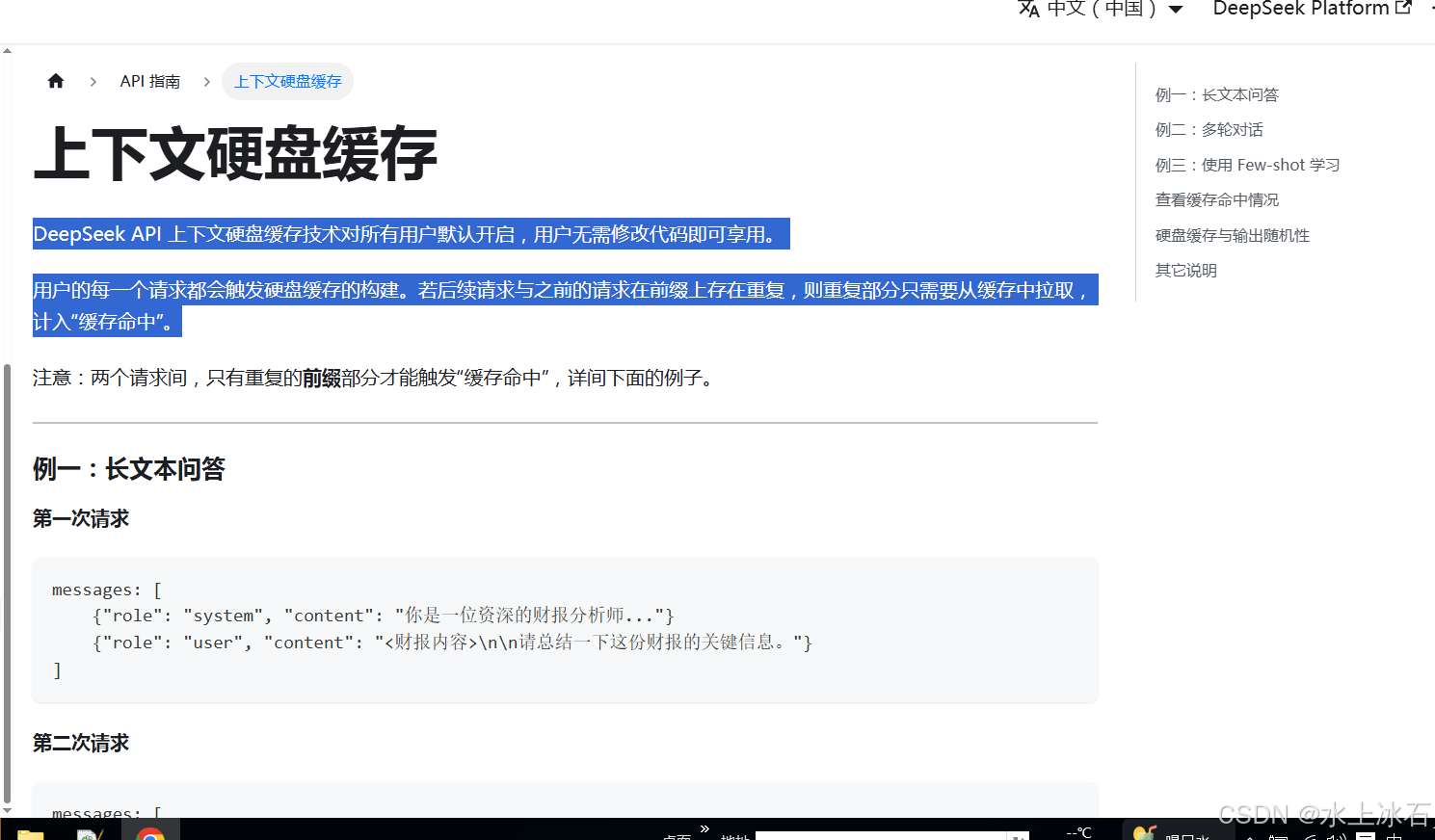
3.7上下文硬盘缓存
DeepSeek API 上下文硬盘缓存技术对所有用户默认开启,用户无需修改代码即可享用。
用户的每一个请求都会触发硬盘缓存的构建。若后续请求与之前的请求在前缀上存在重复,则重复部分只需要从缓存中拉取,计入“缓存命中”。
3.8提示库
各种提示样例,学习demo

三.总结
通过上面的介绍,我们就基本掌握了deepseek提供的基础的开发api功能,我们可以通过学习掌握这些api接口,来在自己的项目中调用所需接口,完成我们自己的业务功能,实现和我们的项目的嵌入。当然这是程序员的工作,并不是没有编程基础的人做的事情,希望我们能够尽快掌握并进入大模型的业务开发中,实现工作效率和业务效率的双重提升
通过本章我们已经可以完成deepseek的应用开发了。但是这一步还不够,我们下一步需要了解大模型本身更多原理性的知识,下一章我会讲解如何获取并下载开源的deepseek源码,并通过源码来分析deepseek的架构,以及怎样学习deepseek更核心和模型本身的知识