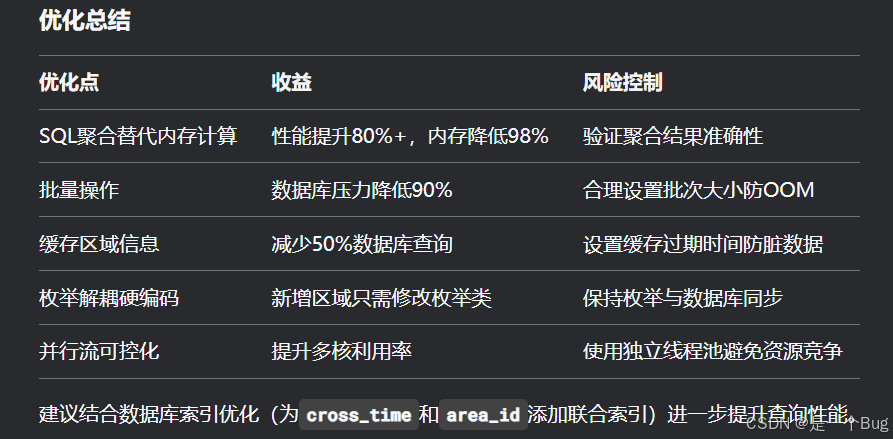
多进程的回顾

-
多进程概念:
-
操作系统能够同时管理多个进程(PID:1, PID:2, PID:3),每个进程可以独立执行一系列指令。
-
-
进程结构:
-
每个进程拥有自己的代码段、数据段、堆和栈。
-
进程控制块(PCB)记录了进程的状态和上下文,如程序计数器(PC)、寄存器值(如ax, bx)等。
-
-
内存管理:
-
进程通过映射表管理虚拟地址到物理地址的转换,确保进程间的内存隔离。
-
-
进程状态:
-
进程可以处于不同的状态,如运行态、阻塞态(如等待磁盘I/O操作完成)。
-
-
进程切换:
-
操作系统负责在不同进程间进行切换,以实现多任务并发执行。
-
-
进程通信和同步:
-
进程间需要通信和同步机制来协调工作,如共享数据时需要同步。
-
-
操作系统的角色:
-
操作系统负责管理所有进程,包括进程的创建、调度、切换和终止。
-
线程的概念

进程和线程切换的原理及区别总结如下
-
进程的组织:
-
进程通过状态(如新建、就绪、运行、阻塞、终止)和队列(如就绪队列、阻塞队列)进行组织。
-
-
进程切换:
-
进程切换涉及保存当前进程状态(上下文),选择下一个进程,并恢复其状态,实现进程间的切换。
-
-
线程的概念:
-
线程是进程内的轻量级执行单元,共享进程的资源,如内存空间和文件描述符。
-
用户级线程在用户态执行,不涉及内核态资源切换,因此切换代价较小。
-
-
线程切换的优势:
-
线程切换速度快,因为不需要切换内存地址空间,只需切换指令执行序列(即程序计数器PC)。
-
线程适合实现并发执行,提高系统资源利用率和响应速度。
-
-
进程与线程的区别:
-
进程是资源分配的基本单位,拥有独立的内存空间。
-
线程共享进程的资源,但可独立调度和执行。
-
进程切换涉及资源和状态的全面切换,而线程切换通常只涉及执行状态的切换。
-
-
用户级线程:
-
用户级线程完全在用户态运行,由用户程序控制,不涉及内核态资源管理。
-
用户级线程的创建、调度和销毁不需要内核干预,由线程库管理。
-
总结
进程和线程是操作系统实现多任务处理的两种机制。进程提供资源隔离,而线程提供轻量级的并发执行。线程切换比进程切换更高效,因为线程切换不需要切换内存地址空间
多线程的实用性

-
多执行序列的实用性:
-
多个执行序列(线程)可以在单个地址空间(进程)内有效运行。
-
这种模型在现代操作系统中非常实用,特别是在图形用户界面(GUI)应用程序中。
-
-
网页浏览器中的线程使用:
-
一个线程用于从服务器接收数据。
-
一个线程用于显示文本内容。
-
一个线程用于处理图片(例如解压缩)。
-
一个线程用于显示图片。
-
-
线程资源共享:
-
线程之间需要共享某些资源,例如从服务器接收的数据需要在不同线程间传递,以便正确显示网页内容。
-
尽管每个线程执行不同的任务,但它们可能需要访问相同的数据或资源。
-
-
资源管理和同步:
-
操作系统需要管理这些线程如何共享资源,例如通过互斥锁、信号量等同步机制来防止数据竞争条件和保证数据一致性。
-
线程间正确的同步是实现高效多线程应用程序的关键。
-
-
用户界面的一致性:
-
所有的文本和图片最终都显示在同一个屏幕上,要求线程协作无间断地更新用户界面。
-
综上所述,多个执行序列加上单个地址空间的模型不仅实用,而且是现代操作系统中实现多任务并行和资源有效管理的基础。线程作为轻量级的执行单元,能够提高程序的响应性和执行效率,但也需要仔细的资源管理和同步控制来确保程序的正确性和稳定性。
多线程的具体实现
总览

上面网页的代码示例
void WebExplorer()
{
char URL[] = "http://cms.hit.edu.cn";
char buffer[1000];
pthread_create(..., GetData, URL, buffer);
pthread_create(..., Show, buffer);
}
void GetData(char *URL, char *p) { ... }
void Show(char *p) { ... }-
WebExplorer函数是浏览器的主函数,它定义了一个URL字符串和一个缓冲区buffer,用于存储从URL下载的数据。 -
使用
pthread_create函数创建了两个线程,一个用于下载数据(GetData函数),另一个用于显示数据(Show函数)。 -
GetData函数负责从指定的URL下载数据,并将其存储在buffer中。 -
Show函数负责将buffer中的数据展示出来。
执行流程图
执行流程图展示了这两个线程的执行流程和交互:
-
GetData线程在10:05开始连接并下载文本数据,假设在10:07下载完成。 -
下载完成后,
GetData线程通过yield操作主动让出CPU,使得Show线程有机会执行。 -
Show线程在10:00开始执行,负责显示文本数据。 -
在显示文本数据后,
Show线程也通过yield操作让出CPU,使得GetData线程可以继续执行下载图片的操作。
解释说明
-
pthread_create函数用于创建线程,其参数包括线程属性、线程函数和传递给线程函数的参数。 -
yield操作是线程主动让出CPU的行为,允许其他线程有机会执行。这在用户级线程中非常常见,用于实现线程间的协作和调度。、
那么我们接下来来探讨这两个函数到底要怎么实现
Yield的简单实现
主要讲解了在操作系统中如何通过编程实现线程切换,以及yield函数在线程切换中的作用。下面我将结合这些图和文字,详细解释yield函数是如何一步一步实现的。

图1:Create和Yield的核心概念
-
核心是Yield:
yield函数是实现线程切换的核心。通过yield,一个线程可以主动放弃CPU的使用权,让其他线程有机会执行。 -
Create的作用:
create函数用于创建新的线程,它需要制造出第一次切换时应该的样子,即设置好线程的初始状态,包括程序计数器(PC)和栈指针(ESP)。

图2:两个执行序列与一个栈
-
问题描述:图中展示了两个函数
A()和C(),每个函数中都有一个yield调用。问题是,由于两个函数共用一个栈,当一个函数执行yield时,会将返回地址压入栈中。但是,如果直接从栈中弹出返回地址继续执行,可能会导致执行流程错误地跳转到另一个函数中。因此,需要一种机制来正确地管理这些返回地址,确保每个函数在自己的栈中正确执行。

图3:从一个栈到两个栈
-
引入TCB:为了解决图2中的问题,引入了线程控制块(TCB)的概念。每个线程都有自己的TCB和栈,这样在执行
yield时,可以保存当前线程的栈指针到TCB中,并从另一个线程的TCB中恢复栈指针,从而实现正确的线程切换。 -
Yield的实现:
yield函数首先保存当前线程的栈指针到其TCB中,然后从另一个线程的TCB中恢复栈指针,最后通过跳转到保存的返回地址来继续执行。这样,每个线程都可以在自己的栈中独立执行,而不会干扰到其他线程。
代码说明
yield 函数的代码实现
void Yield()
{
TCB1.esp = esp; // 保存当前线程的栈指针到其TCB中
esp = TCB2.esp; // 从下一个线程的TCB中恢复栈指针
// jmp 204; // 应该去掉,因为返回地址已经在栈中
}-
保存当前线程的栈指针:
-
TCB1.esp = esp;这行代码将当前线程的栈指针(ESP)保存到当前线程的TCB中。这是为了在后续切换回当前线程时能够恢复其栈状态。
-
-
切换到下一个线程的栈指针:
-
esp = TCB2.esp;这行代码将ESP寄存器的值更新为下一个线程的栈指针,从而实现栈的切换。
-
yield 函数的作用
yield 函数在多线程环境中用于实现线程间的协作式切换。具体作用包括:
-
线程切换:允许当前线程主动放弃CPU控制权,使调度器有机会调度其他线程执行。
-
栈切换:通过保存和恢复栈指针,实现线程间栈空间的切换。
-
程序计数器(PC)切换:虽然代码中没有直接修改PC,但通过栈管理,确保了线程切换后能从正确的地址继续执行。
Create的简单实现

图示说明
-
图示:展示了内存布局,包括两个栈(Stack1和Stack2)、堆(Heap)、数据段和代码段。
-
栈:每个线程有自己的栈,用于存储函数调用的返回地址和其他局部变量。
-
TCB:每个线程有自己的TCB,用于存储线程的状态信息,包括栈指针(ESP)。
ThreadCreate函数的实现
-
函数定义:
void ThreadCreate(A) -
步骤:
-
分配TCB:使用
malloc分配内存用于存储TCB。 -
分配栈:使用
malloc分配内存用于线程的栈。 -
设置栈指针:将栈的起始地址赋值给TCB中的ESP字段。这里假设栈从高地址向低地址增长,所以栈指针指向栈的起始地址。
-
设置初始执行地址:将线程的起始函数地址(如
A函数的地址)放入栈中,这样当线程开始执行时,它将从指定的函数开始执行。
-
代码示例
void ThreadCreate(void (*func)()) {
TCB *tcb = malloc(sizeof(TCB)); // 分配TCB
void *stack = malloc(STACK_SIZE); // 分配栈空间
*stack = (void *)func; // 将函数地址放入栈中
tcb->esp = stack; // 设置栈指针
// 启动线程执行
}总结
通过ThreadCreate函数,操作系统可以在用户态下创建新的线程,每个线程有自己的TCB和栈。这种用户级线程的实现方式不需要内核支持,可以提高程序的并发性和响应性。
create和yield结合

1. WebExplorer 函数
void WebExplorer() // main()
{
ThreadCreate(GetData, URL, buffer);
while(1) Yield();
}用途:
-
这是主函数,用于初始化并启动多线程Web浏览器。
-
调用
ThreadCreate来创建一个新线程,该线程执行GetData函数以下载数据。 -
进入一个无限循环,在每次迭代中调用
Yield函数,以允许其他线程运行。
2. GetData 函数
void GetData(char *URL, char *p)
{
连接URL; 下载; Yield();
...
}用途:
-
负责从指定的 URL 下载数据。
-
执行下载操作后,调用
Yield函数以让出CPU,允许其他线程(如显示线程)运行。
3. ThreadCreate 函数
void ThreadCreate(func, arg1)
{
申请栈; 申请TCB; func等入栈; 关联TCB与栈;
...
}用途:
-
创建一个新的线程。
-
为新线程分配栈和TCB(线程控制块)。
-
将线程的起始函数地址压入栈中。
-
关联TCB和栈,以便线程可以正确地开始执行。
4. Yield 函数
void Yield()
{
压入现场; esp放在当前TCB中; Next(); 从下个TCB取出esp; 弹栈切换线程;
}用途:
-
实现线程切换。
-
保存当前线程的状态(将ESP压入栈中),并从下一个线程的TCB中恢复栈指针(ESP),从而切换到下一个线程。
-
通过这种方式,允许多个线程交替执行,实现多任务并发处理。
这些代码片段展示了如何在用户态下实现简单的多线程并发模型,包括线程的创建、执行和切换。






![[Vue warn]: Duplicate keys detected: ‘xxx‘. This may cause an update error.](https://i-blog.csdnimg.cn/direct/04c377479d67440f98e4538bbd99bc15.png)