先来简单看下PPO和GRPO的区别:

-
PPO:通过奖励和一个“评判者”模型(critic 模型)评估每个行为的“好坏”(价值),然后小步调整策略,确保改进稳定。
-
GRPO:通过让模型自己生成一组结果(比如回答或行为),比较它们的相对质量(优势),然后优化策略。它的特点是不需要额外的“评判者”模型(critic 模型),直接用组内比较来改进。
个人理解记录,供参考。
1. GRPO目标函数的数学原理
GRPO的目标函数如下:
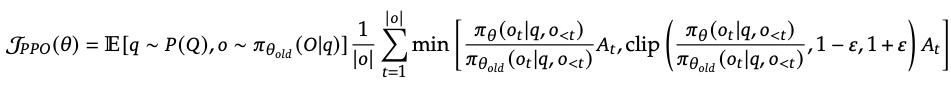
这个函数看起来复杂,但我们可以将其拆解为几个关键部分,逐一分析其作用和意义。GRPO的目标函数由两大部分组成:策略梯度更新项和KL散度正则化项。我们分别分析它们的作用。
1.1 策略梯度更新项
策略梯度部分是目标函数的主要成分,形式为:
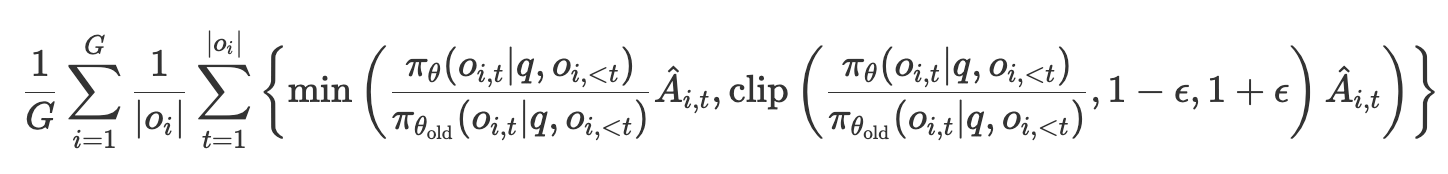
核心思想
这一部分的目标是通过策略梯度调整 θ \theta θ,使策略 π θ \pi_{\theta} πθ 在有利动作( A ^ i , t > 0 \hat{A}_{i,t} > 0 A^i,t>0)上提高概率,在不利动作( A ^ i , t < 0 \hat{A}_{i,t} < 0 A^i,t<0)上降低概率。为了避免更新过于激进,GRPO引入了剪切机制。
概率比
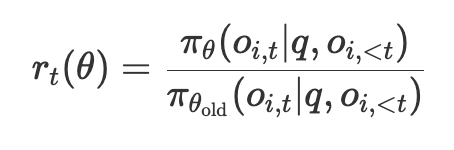
这是当前策略与旧策略在动作 o i , t o_{i,t} oi,t 上的概率比。若 r t ( θ ) > 1 r_t(\theta) > 1 rt(θ)>1,表示当前策略更倾向于选择该动作;若 r t ( θ ) < 1 r_t(\theta) < 1 rt(θ)<1,则倾向于减少该动作。
剪切操作
clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) \text{clip} \left( r_t(\theta), 1 - \epsilon, 1 + \epsilon \right) clip(rt(θ),1−ϵ,1+ϵ)
剪切操作将 r t ( θ ) r_t(\theta) rt(θ) 限制在 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ] 区间内:
- 如果 r t ( θ ) < 1 − ϵ r_t(\theta) < 1 - \epsilon rt(θ)<1−ϵ,则被截断为 1 − ϵ 1 - \epsilon 1−ϵ;
- 如果 r t ( θ ) > 1 + ϵ r_t(\theta) > 1 + \epsilon rt(θ)>1+ϵ,则被截断为 1 + ϵ 1 + \epsilon 1+ϵ。
这限制了策略更新的幅度,防止单次更新偏离旧策略太远。
最小值操作
min ( r t ( θ ) A ^ i , t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) \min \left( r_t(\theta) \hat{A}_{i,t}, \text{clip} \left( r_t(\theta), 1 - \epsilon, 1 + \epsilon \right) \hat{A}_{i,t} \right) min(rt(θ)A^i,t,clip(rt(θ),1−ϵ,1+ϵ)A^i,t)
- 当 A ^ i , t > 0 \hat{A}_{i,t} > 0 A^i,t>0(动作有利)时, min \min min 选择较小的值,确保更新不会过于增加概率。
- 当 A ^ i , t < 0 \hat{A}_{i,t} < 0 A^i,t<0(动作不利)时, min \min min 同样选择较小的值(即较大的负值),限制概率减少的幅度。
这种设计类似于PPO算法,通过剪切和最小值操作增强训练稳定性。
平均操作
- 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} ∣oi∣1∑t=1∣oi∣: 对单个轨迹内的所有时间步取平均。
- 1 G ∑ i = 1 G \frac{1}{G} \sum_{i=1}^{G} G1∑i=1G: 对所有 G G G 个轨迹取平均。
- E q ∼ P ( Q ) , { o i } ∼ π θ old \mathbb{E}_{q \sim P(Q), \{o_i\} \sim \pi_{\theta_{\text{old}}}} Eq∼P(Q),{oi}∼πθold: 在状态和轨迹分布上取期望。
这些平均和期望操作使目标函数能够泛化到不同的状态和轨迹。
2.2 KL散度正则化项
β D KL ( π θ ∣ ∣ π ref ) \beta D_{\text{KL}}(\pi_{\theta}||\pi_{\text{ref}}) βDKL(πθ∣∣πref)
作用
KL散度(Kullback-Leibler divergence)衡量当前策略 π θ \pi_{\theta} πθ 与参考策略 π ref \pi_{\text{ref}} πref 之间的差异。负号和权重 β \beta β 表示这是一个惩罚项,目标是限制 π θ \pi_{\theta} πθ 偏离 π ref \pi_{\text{ref}} πref 过远。
意义
- 当 D KL D_{\text{KL}} DKL 较大时,惩罚增加,迫使策略更新更加保守。
- β \beta β 控制正则化强度: β \beta β 越大,策略变化越小。
2. GRPO算法的整体工作流程

GRPO是一种基于组奖励的策略优化算法,其工作流程可以分为以下几个步骤:
-
采样响应(Sample G responses)
对于每个输入问题 $ q_i $,从旧策略 $ \pi_{\theta_{\text{old}}} $ 中采样 $ G $ 个响应 $ {o_i}_{i=1}^{G} $。这些响应可以看作是对问题的多种可能回答,图示中用粉色方块表示“prompts”(输入问题),绿色方块表示“completions”(生成响应)。 -
分配奖励(Assign rewards based on rules)
根据预定义的规则为每个响应分配奖励 $ R_i $。奖励可能基于回答的质量(如准确性、流畅性等),图示中用蓝色方块表示“rewards”。 -
计算优势(Compute advantages)
通过比较每个响应的奖励与组内统计值,计算优势值 $ A_i $。具体公式为:
A i = R i − mean ( group ) std ( group ) A_i = \frac{R_i - \text{mean}(\text{group})}{\text{std}(\text{group})} Ai=std(group)Ri−mean(group)
其中,$ \text{mean}(\text{group}) $ 是组内奖励的平均值,$ \text{std}(\text{group}) $ 是标准差。优势值 $ A_i $ 反映了每个响应相对于组内平均表现的优劣,图示中用紫色方块表示“advantages”。 -
更新策略(Update the policy)
通过最大化目标函数 $ J_{\text{GRPO}}(\theta) $,调整策略参数 $ \theta ,以提高高优势值( ,以提高高优势值( ,以提高高优势值( A_i > 0 )响应的生成概率,同时降低低优势值( )响应的生成概率,同时降低低优势值( )响应的生成概率,同时降低低优势值( A_i < 0 $)响应的概率。 -
KL散度惩罚(KL Divergence penalty)
为避免新策略 π θ \pi_{\theta} πθ 过于偏离参考模型 π ref \pi_{\text{ref}} πref,引入KL散度惩罚项 − β D KL ( π θ ∣ ∣ π ref ) -\beta D_{\text{KL}}(\pi_{\theta}||\pi_{\text{ref}}) −βDKL(πθ∣∣πref)。这一正则化措施确保策略更新的稳定性并保留通用推理能力,图示中用橙色方块表示“$ D_{\text{KL}} $”。
整个流程通过迭代优化实现:从输入问题到生成响应,再到奖励分配和优势计算,最后更新策略,形成一个闭环。
3. 为什么GRPO算法有效?
- GRPO通过消除传统强化学习算法(如PPO)中需要的一个单独价值函数模型,显著提高了效率。这个模型通常需要额外的内存和计算资源,而GRPO的做法降低了这些需求,使其更适合处理大型语言模型。
稳健的优势估计 - GRPO采用基于群体的优势估计方法。它为每个提示生成多个响应,并使用群体的平均奖励作为基准。这种方法无需依赖另一个模型的预测,提供了一种更稳健的政策评估方式,有助于减少方差并确保学习稳定性。
- GRPO直接将Kullback-Leibler(KL)散度纳入损失函数中。这有助于控制策略更新,防止策略与参考策略偏离过多,从而保持训练的稳定性。
4. 几个GRPO复现deepseek-R1-zero的流程代码repo
- https://github.com/Jiayi-Pan/TinyZero
- https://github.com/Unakar/Logic-RL
关于作者:余俊晖,主要研究方向为自然语言处理、大语言模型、文档智能。曾获CCF、Kaggle、ICPR、CCL、CAIL等国内外近二十项AI算法竞赛/评测冠亚季军。发表SCI、顶会等文章多篇,专利数项。