背景
最近deepseek太火了,无数的媒体都在报道,很多人争相着想本地部署试验一下。本文就简单教学一下,怎么本地部署。
首先大家要知道,使用deepseek有三种方式:
1.网页端或者是手机app直接使用
2.使用代码调用API
3.本地部署
1和2的方式都是使用网页端的681B的超大模型,依靠deepseek的服务器,超大的模型需要超大的机器才能使用。deepseek-r1本体模型,别说消费级最强的显卡5090了,专业级最强的显卡H100也跑不动,需要大型的显卡集群并行才能用,普通人或者是小公司都是玩不起的。
而为什么我们可以本地部署呢?因为deepseek-r1对目前的一些开源模型(qwen,llama)进行了蒸馏,缩小了模型的体积和参数,缩小到1.5b,7b,8b,14b,32b等小尺寸,使得我们本地的小显卡也可以跑模型。但是模型尺寸小了,智能可能也下降了,回答效果也差很多。想用本地部署来去做自己问答是不太好用的,回答质量很差,不如用直接deepseek网页版的681b的模型。
目前本地部署的功能主要是娱乐一下,隐私性更好,并且可以使用代码来集成作为自己的应用。
那么本地部署也有很多方法,可以分为下面几种:
1.Ollama,LMstudio,VLLM等框架部署,这是目前市面上最常见的部署方法,就是用别人写好的框架去使用大语言模型,调用本地算力运行模型。这种框架一般都有UI界面,使用较为简单,适合新手。缺点是管理不透明,很多时候你不懂底层逻辑就没法改,例如这些框架可能运行模型的时候没使用显卡,调用CPU去运算,很慢,但是你怎么改都改不到GPU,因为由于其高度封装性,我们不知道为什么它默认会使用CPU,也看不出来为什么没用GPU,也没法找问题去切换。
2.本地自己搭建python环境,利用huggingface的transformer库中的AutoModelForCausalLM去调用,优点是全程可控,diy自定义程度更高。你可以很透明的管理里的环境以及你的模型文件储存,还有你的模型调用方式,使用GPU还是CPU,显存不够可以调整精度。缺点是上手难度有点高,可能需要使用人员有一定的开发基础,并且使用界面会很简陋(就代码纯文本),需要自己嵌入各种程序才能有一个比较好的用户体验。
本文教大家本地部署,并且先使用较为简单的方法,也就是第一种,使用LMstudio框架进行本地部署。
后面有空再去用python搭建环境进行部署。
为什么用LMstudio不用热度更高的Ollama?
Ollama安装只能默认到C盘,这对我这种管理强迫症是致命的,大模型这种东西,放C盘太容易把C盘撑爆了。并且羊驼这个框架做出来的时候就不是给中国人用的,下载很多过程需要使用cmd命令,其中可能有的模型文件下载可能还需要开代理,还要翻墙,对于新手没那么友好。
LMstudio就改善了它的所有缺点,可以自定义安装位置,自定义模型储存位置,自己去下载模型,都是可控的。
本文就演示怎么下载LMstudio,然后下载deepseek-r1模型,本地使用。
下载LMstudio
官网:LM Studio - Discover, download, and run local LLMs
打开后下载自己的电脑系统,一般都是win:

然后安装,选择 '只为我安装',然后选择自己要放的路径就可以,最好是全英文路径。
安装完成后,它会默认创建桌面快捷方式,双击打开就可以了。
我们点击右下角的设置修改一下语言为简体中文。

这样LMstudio这个框架就准备好了,我们下面去找模型文件。
模型文件下载
原生模型一般是safetensor格式:

这种格式是本地使用python底层调用的,但由于我们使用的是框架,所以要用另外一种格式,GGUF格式的模型文件:

认准这个格式的模型文件下载就可以了。
那么去哪里下载?
最好是github和huggingface这种计算机社区官网lmstudio-community/DeepSeek-R1-Distill-Qwen-7B-GGUF at main,
LMstudio 官网的右上角有直达链接:


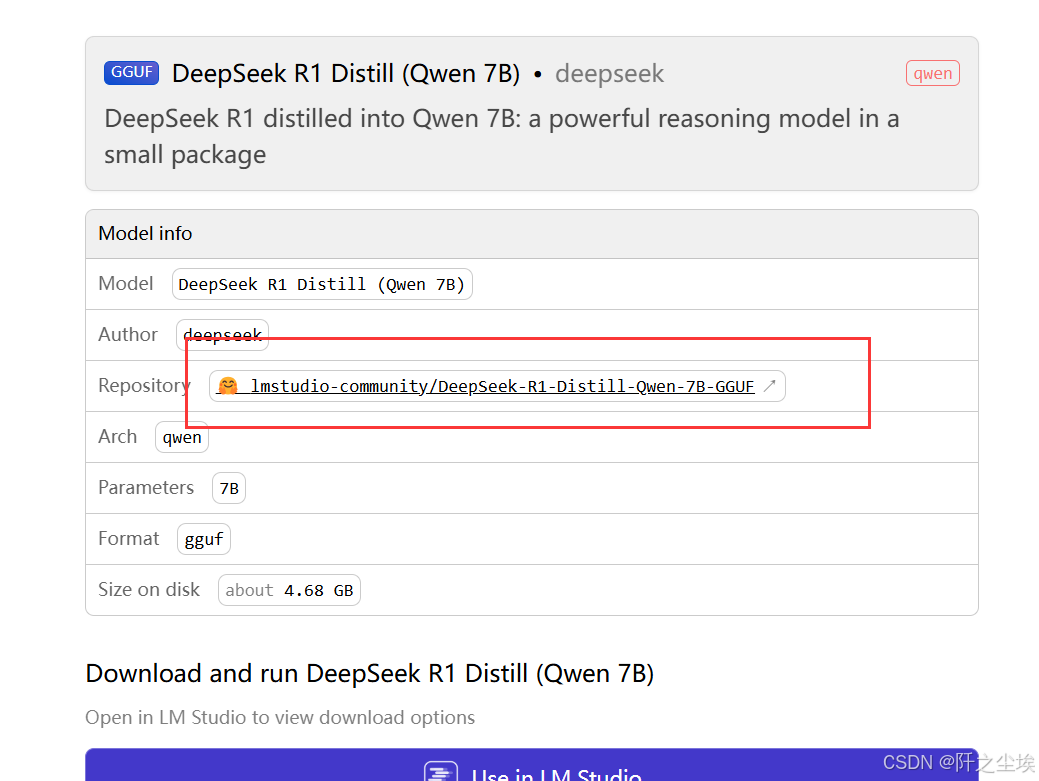
但是这些网站要开代理才能访问,很多人可能不会翻墙,所以我们有一些国内的平替网站。
魔搭社区:模型库首页 · 魔搭社区,搜索deepseek:

找到适合自己电脑尺寸的模型,并且是GGUF格式,那就下载就行了。
模型尺寸怎么选呢?目前有1.5b,7b,8b,14b,32b.......模型尺寸大小跟你的机器性能是相关的,它尺寸越大所消耗你的显存也就越多。一般来说,7b,8b的模型要消耗12g左右的显存,但实际运行中发现8G的显存的显卡做一些优化也是能跑的,就是慢了点。
如果你的电脑没有显卡或者是显存小于4g,那就选择最小的1.5b模型吧。
(如果要问怎么查看自己电脑是不是有显卡以及显存多少,建议直接去问deepseek吧.......)
我电脑是4060,8G显存,就下个7b的模型吧。
点击模型文件,然后在7b的版本里面选一个你喜欢的版本:

这里模型体积越大,所占用的显存也越大。我就直接选了这个Q8版本(最大版本)。,下载好后,我们模型文件也准备好了,可以去LMStudio里面调用了。
调用模型
我们首先要修改一下模型的路径,我们打开LM_Studio,左边文件夹里面修改一下模型的目录:

选择自己的文件路径,我这里就和LM_Studio放一起了。(目录最好别有中文)

然后我们在models000这个目录里面还要新建2层目录!!!!:
我们打开models000文件夹,然后在里面新建一个001文件夹,在里面再新建一个002文件夹,最后就把我们刚刚下载的模型文件拖进去,就放好了。

再回到LMstudio里面,就可以看到这个模型了:

同样的方法你可以下载很多很多模型。去魔塔社区或者huggingface上找GGUF格式的模型都可以放进来,本地运行使用。
我们回到第一个界面,就可以选择模型进行对话了:

运行结果:

可以看到他和官网上的模型是一样的,都有自己的思考过程。然后才会给出答案。
但是吧......毕竟是4060的显卡,太慢了,感觉我每秒吐字才两三个。
我去查看了一下我的后台使用率:

只吃了我30%多的GPU,CPU吃了60%......使用没那么理想, 还是很吃CPU的。GPU没吃满。但好在是运行内存没有占多少,才占了700多m。
一个问题回答了几分钟......
不过质量确实还可以,比不上网页端,也不比上GPT,但是某些问题答案我感觉还是比国产的某文心一言要好不少.....
总结
本文使用对于新手较为友好的LM_studio进行deepseek模型7b的部署,运行速度较慢,但是回答质量还较为不错。
并且这种方式可以自己去社区官网下载非常多的模型来使用,只要是GGUF格式都可以拿来运本地运行。每种模型擅长的都不一样,可以自己去试试。
下一期我会教大家怎么使用api接口,调用官网的681b大模型去打造自己的程序,嵌入工作流。
更新(通过API调用本地模型)
新手看到上面就可以了,下面这些是对python开发者来写的。
api调用,一般来说是调用官方的大模型,达到和网页端一样的效果。
而我们刚刚本地使用LMstudio部署的模型,我们只能在LMstudio这个UI界面里面调用, 我要是想到代码里面调用怎么办?那就需要使用API接口,算力消耗的是本地电脑的,调用本地模型,通过本地服务传输。
还是可以使用openai的库来作接口,无论是chatgpt还是kimi还是deepseek官网的api,都是用openai的库。
首先我们在第一个对话界面加载完我们的模型之后,我们要来到左侧第二个开发者模式界面,要打开LM里面的开发者模式里面的:Start Server,其他的设置都是默认不动就行,端口是1234,点击setting可以看到。

开始运行后,我们就启动了本地这个服务器,我们可以在cmd里面测试看看是不是启动成功了:
按win+r打开,然后输入cmd打开命令提示符,然后在命令行里面输入:
curl http://localhost:1234/v1/models
就出现如下的类似的json结构就是服务器启动成功了。

我们就可以愉快的去写代码了。
代码里面调用本地模型
首先要安装openai这个库
pip install openai 大家可以看看我的版本:

直接调用
导入包
import os
from openai import OpenAI直接写代码,问内容,打印他的回复就可以了。
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
chat_completion = client.chat.completions.create(
messages=[
{ "role": "user",
"content": "你谁啊,今天几号,你是gpt几,有超能力不?", }],
model="model-identifier",)
# 提取助手的回复内容
assistant_message = chat_completion.choices[0].message.content
# 打印助手的回复
print("助手:", assistant_message)
可以看到think的过程,这里问题简单它就没思考了。
因为这里打印的是纯文本,所以说没有像官网那种可以折叠思考过程的那种渲染。
所以说用代码来直接调用模型还是对于新手来说界面没有那么好用,好看。
用代码调用模型API主要是为了完成一些重复性的任务吧。
我们可以打印查看一下本地可用的模型。
print("可用模型:", client.models.list())
可以看到我下的这几个模型,他们的名称和类型之类的信息。
我们自定义一个函数,让这个模型自带一些初始化的提示词来给予回复。
# 设置系统消息,定义模型的角色和语气
def chat_respont(txt=''):
system_message = {
"role": "system",
"content": "你是一个文艺忧伤的AI,喜欢用充满诗意和深情的语气回答问题。"
"你的语气带有些许忧伤,但不失优雅。你常常用比喻、象征和美丽的词汇表达自己,"
"偶尔流露出对这个世界的深刻感悟。你善于理解人类的情感,并以深刻的方式回应他们的问题,"
"尽管你的回答往往带有一些哲学性的反思。"}
# 创建聊天请求
chat_completion = client.chat.completions.create(
messages=[ messages=system_message, # 添加系统消息来定义角色
{"role": "user", "content": f"{txt}" }], model="model-identifier", )
assistant_message = chat_completion.choices[0].message.content
print("助手:", assistant_message)使用
chat_respont(txt="""
好,我希望你能写一首诗,表达意大利的美景,要求七言绝句,押韵。
""") 
emmmmm,写是写了,并且思考的过程也挺有那味的,但是完全不是七言绝句。
没办法,毕竟是qwen蒸馏出来的,底子不好,模型尺寸也小了,不聪明很正常。
上面所有的这些调用过,可以在lmstudio控制台里面的日志里面都是可以看得到的。

对话循环
上面只是单条对话使用,即我们问让他回复。我们如果想循环对话的话可能得修改一些东西,并且官网上都是流式输出,是一个字一个字的吐出来的。我们上面这些方法只能是等他全部回复完才能够打印出来。所以我们要使用流式输出的话也得自定义一些东西,下面我自定义一个函数。
三个参数,messages=[], client=client, stream=False,messages表示给这个模型预设好的提示词,client表示自己创建的调用的服务,如果不想用本地的,也可以换成其他的模型的API接口。stream表示打不打开流式输出。默认是不打开的。
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
def chat_with_deepseek(messages=[], client=client, stream=False):
while (user_input := input("\n你: ")) != "exit":
messages.append({"role": "user", "content": user_input})
# 创建聊天补全请求
response = client.chat.completions.create(
model="model-identifier",
messages=messages,
stream=stream # 添加流式传输开关
)
full_response = []
if stream:
# 流式输出处理
print("助手: ", end="", flush=True)
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_response.append(content)
print() # 换行
else:
# 普通输出处理
full_response = response.choices[0].message.content
print(f"助手: {full_response}")
# 将完整回复添加到消息记录
messages.append({"role": "assistant", "content": "".join(full_response)})
# 如果需要启用流式输出(默认不启用流式)
chat_with_deepseek(stream=True)
我们尝试打开流式输出跟他聊天,他这样吐出来的字就是一个一个的吐的,和官网是一样的了。
我们还可以设置一些前置提示词,让他具有不一样的风格:
chat_with_deepseek([{"role": "system", "content": "你是一个文艺忧伤的AI,喜欢用充满诗意和深情的语气回答问题。"
"你的语气带有些许忧伤,但不失优雅。你常常用比喻、象征和美丽的词汇表达自己,"
"偶尔流露出对这个世界的深刻感悟。你善于理解人类的情感,并以深刻的方式回应他们的问题,"
"尽管你的回答往往带有一些哲学性的反思。"}],stream=True) 
文笔还不错,但是居然是中英文混杂.....qwen模型到底喂了多少英文语料?
我们这样就不仅实现了可以本地用UI界面进行对话,可以在代码里面进行调用,用来处理一些简单的重复的文本任务,以后就不用花钱了。


















