目录
cors解决跨域
依赖注入使用
分层服务注册
缓存方法使用
内存缓存使用
缓存过期清理
缓存存在问题
分布式的缓存
cors解决跨域
前后端分离已经成为一种越来越流行的架构模式,由于跨域资源共享(cors)是浏览器的一种安全机制,它会阻止前端应用向不同域的服务器发起请求,保护用户的隐私和数据安全。为了在前后端分离的应用中确保前端可以安全地访问后端的接口,不会受到浏览器的跨域限制,这里我们可以通过后端进行相应的cors配置。
首先我们先搭建一下.net core webapi的框架,不了解的可以参考我之前的文章:地址 ,然后我们配置了一个登录的接口,返回的结果是记录的类型,然后固定了一下登录成功的用户和密码,如下所示:
/// <summary>
/// 登录验证
/// </summary>
/// <param name="res"></param>
/// <returns></returns>
public record LoginRequest(string UserName, string Password);
public record ProcessInfo(long Id, string Name, long WorkingSet); // 记录类型
public record LoginResponse(bool OK, ProcessInfo[]? ProcessInfos);
[HttpPost]
[Route("login/user")] // 特性路由
public LoginResponse Login(LoginRequest res)
{
if (res.UserName == "admin" && res.Password == "123456")
{
var items = Process.GetProcesses().Select(x => new ProcessInfo(x.Id, x.ProcessName, x.WorkingSet64));
return new LoginResponse(true, items.ToArray()); // 返回记录类型
}
else
{
return new LoginResponse(false, null);
}
}然后我们就需要在入口文件Program.cs中配置一下我们允许要跨域的源,这里我们直接输入前端运行服务器的域名和端口即可,然后设置允许规则,这里我们正常就都允许,如果想配置部分允许的话,通过With函数进行筛选即可,如下:
// 配置跨域策略
builder.Services.AddCors(options =>
{
options.AddDefaultPolicy(builder =>
{
builder.WithOrigins("http://localhost:3000") // 允许跨域的源
.AllowAnyHeader() // 允许任何头
.AllowAnyMethod() // 允许任何方法
.AllowCredentials() // 允许携带凭证
.WithExposedHeaders("X-Custom-Header"); // 暴露自定义头信息
});
});
app.UseCors(); // 使用跨域策略
然后前端的话,这里我们就使用react框架通过axios发起请求,不了解react的朋友,可参加我之前的文章:地址 ,然后我们通过如下的一个示例代码进行请求的发起:
import axios from "axios"
import { useState } from "react"
const WebApi = () => {
const [userName, setUserName] = useState<string>('')
const [password, setPassword] = useState<string>('')
const [processInfo, setProcessInfo] = useState<any>([])
const reqPost = () => {
axios.post('http://localhost:5263/First/login/user', { userName: userName, password: password }).then(res => {
if (res.data.ok) {
setProcessInfo(res.data.processInfos)
} else {
alert('登录失败, 请重新登录!')
}
})
}
return (
<div>
账户: <input type="text" onChange={(e: any) => setUserName(e.target.value)} /> <br />
密码: <input type="password" onChange={(e: any) => setPassword(e.target.value)} /> <br />
<button onClick={() => reqPost()}>发起请求</button>
{processInfo.map((item: any) => <div key={item.id}>{item.name}</div>)}
</div>
)
}
export default WebApi最终呈现的效果如下所示:

依赖注入使用
依赖注入通过将对象的创建和管理交给框架,而不是在类内部直接创建,可以有效地解耦各个模块,使得每个组件都能够独立地进行测试和维护。这对于实现前后端分离的架构至关重要,因为它允许开发者更灵活地控制和管理后端服务,使得前端与后端的交互更加清晰、可靠。具体可以参考我之前的文章:地址 ,这里不再赘述,然后接下来我们开始演示在WebAPI中如何使用依赖注入:
构造函数注入服务操作:传统且经典的创建依赖注入
创建服务:这里我们直接可以创建一个两数相加的服务函数,如下所示:
namespace netCoreWebApi
{
public class Calculator
{
public int Add(int i1, int i2)
{
return i1 + i2;
}
}
}服务注册:然后我们在入口文件中进行服务注册,如下所示:
builder.Services.AddScoped<Calculator>(); // 注册Calculator服务依赖注入:然后我们在控制器文件中通过构造函数进行服务注入:
using Microsoft.AspNetCore.Mvc;
using netCoreWebApi.WebCore;
namespace netCoreWebApi.Controllers
{
[ApiController]
[Route("api/[controller]/[action]")]
[ApiExplorerSettings(GroupName = nameof(ApiVersionInfo.V1))]
public class FirstController : ControllerBase
{
private readonly Calculator calculator;
public FirstController(Calculator calculator)
{
this.calculator = calculator;
}
[HttpGet]
public int Add1()
{
return calculator.Add(1, 2);
}
}
}允许项目得到的结果如下所示,果然是3:

低使用频率服务:一些耗时的依赖注入可能会影响其他接口的调用,这里我们需要使用该注入方式进行解决,一般的接口创建不需要使用该服务,只有调用频率不高且资源的创建比较消耗资源的服务才会使用
创建服务:这里我们直接可以创建一个比较耗费资源的扫描文件服务函数,如下所示:
namespace netCoreWebApi
{
public class SearchService
{
private string[] files;
public SearchService()
{
this.files = Directory.GetFiles("d:/","*.exe", SearchOption.AllDirectories);
}
public int Count
{
get
{
return this.files.Length;
}
}
}
}服务注册:然后我们在入口文件中进行服务注册,如下所示:
builder.Services.AddScoped<SearchService>(); // 注册SearchService服务依赖注入:然后我们在控制器文件中通过构造函数进行服务注入,把Action用到的服务通过Action的参数注入,在这个参数上标注[FromServices],和Action的其他参数不冲突,只有Action方法才能使用[FromServices],普通的类默认不支持,如下所示:
[HttpGet]
public int Test1([FromServices]SearchService searchService) // 只有请求这个方法时才会注入SearchService
{
return searchService.Count;
}如下当请求耗费较多资源的时候,请求时间才会过长,请求其他不耗费资源的接口,正常请求:

分层服务注册
从上面的依赖服务注册使用我们可以了解到,当我们想进行依赖注入的使用,都需要在入口文件进行服务的注册,但是项目一旦庞大起来或者说服务一旦多起来,多人协作开发的时候再要求所有的服务都必须注册在入口文件中就会导致一些问题的冲突,如下所示就是典型的例子:

这里我们需要对服务注册进行解耦操作,即进行分层处理。在分层项目中,让各个项目负责各自的服务注册,这里我们需要先安装一下下面这个依赖包:

然后这里我们创建多个类库,模拟多个服务的使用,然后将这些服务引用到项目上:

然后在每个项目中创建一个或多个实现IModuleInitializer接口的类,然后将服务注册的函数写道该接口类当中,如下所示:

然后我们通过反射原理,将服务注册的函数来映射到入口函数当中,具体代码如下所示:
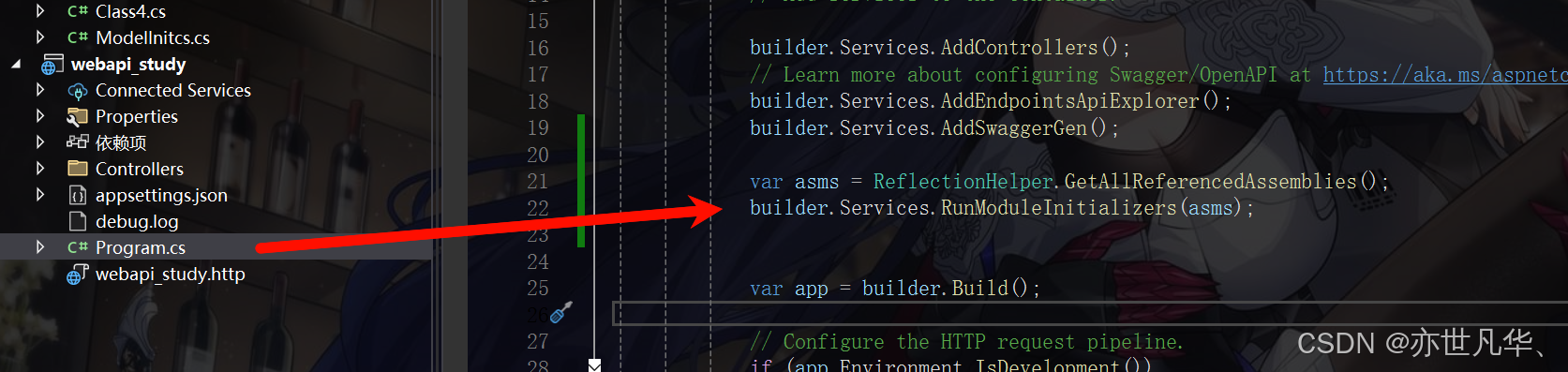
然后我们再次运行项目,发现我们的服务还是成功被运行起来了,如下所示:

缓存方法使用
缓存:是系统优化中简单又有效的工具,投入小收效大,数据库中的索引等简单有效的优化功能本质上都是缓存,其将经常访问的数据存储在一个快速访问的存储区域(如内存)中,从而减少对数据库或其他慢速存储系统的重复访问。缓存能够显著提高应用程序的性能,尤其是在需要频繁读取大量数据时。
客户端响应缓存:RFC7324是HTTP协议中对缓存进行控制的规范,其中重要的是cache-control这个响应报文头,服务器如果返回cache-control: max-age-60,则表示服务器指示浏览器端可以缓存这个响应内容60秒
这里我们只需要给进行缓存控制的控制器的操作方法添加ResponseCache这个Attribute,.net core会自动添加cache-control报文头,如下所示我们设置了一个获取当前时间的接口,正常情况下每次请求接口都是最新的时间,这里添加了缓存20秒导致了请求在20秒之内的数据都是不变的:


服务端响应缓存:服务端缓存整个HTTP响应,而不是仅仅缓存其中的数据或部分内容。这样,服务器可以直接返回已经缓存的响应,而不需要重新处理请求和生成新的响应。服务端响应缓存可以显著提高性能,特别是在处理重复的请求时。
如果.net core中安装了响应缓存中间件,那么.net core不仅会继续根据[ResponseCache]设置来生成cache-control响应报文头来设置客户端缓存,而且服务器端也会按照[ResponseCache]的设置来对响应进行服务器端缓存,使用方法如下所示,在入口文件处在app.MapControllers()之前添加app.UseResponseCaching(),请确保如果你的项目如果存在app.UseCors()的话,该函数的调用也要写在app.UseResponseCaching()之前,如下所示:

注意,如果你勾选了浏览器当中的禁用缓存的按钮,不仅是客户端,服务器端在请求的时候由于带上了no-cache,服务器端也会禁用掉所有的缓存:
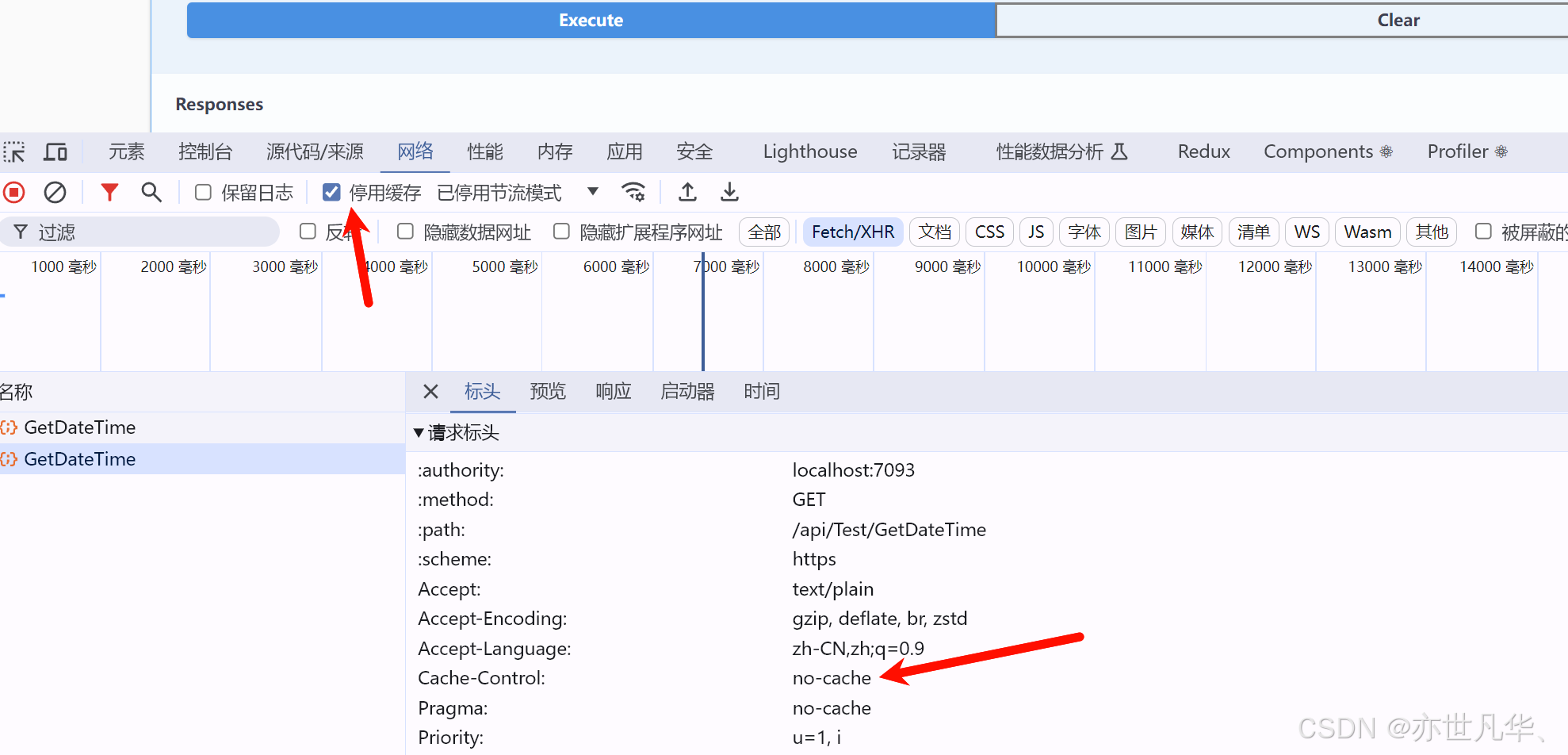
当然服务器缓存还是很鸡肋的,它无法解决恶意请求带给服务器的压力,服务器响应缓存还有很大的限制,包括但不限于:响应状态码为200的GET或者HEAD响应才能被缓存;报文头中不能含有Authorization、Set-Cookie等,为了解决这些问题我们还需要采用内存或者分布式进行缓存。
内存缓存使用
内存缓存:是指将数据存储在计算机的内存中以便快速访问和提高系统性能的一种技术,通常内存缓存用于存储那些频繁访问且计算或获取成本较高的数据,目的是减少从磁盘或其他慢速存储设备中读取数据的次数,从而加速应用程序的响应速度。
内存缓存的数据保存在当前运行的网站程序的内存中,是和进程相关的。因为在Web服务器中多个不同的网站是运行在不同的进程中的,因此不同的网站的内存缓存是不会相互干扰的,而且网站重启之后内存缓存中的所有数据也就都被清空了。内存缓存的使用方法如下所示:
注册内存缓存服务:这里我们需要先在入口文件进行内存缓存服务的注册,如下所示:
builder.Services.AddMemoryCache(); // 添加内存缓存服务这里我们先创建一个MyDbContext来模拟一下数据库当中的数据,并设置一个函数返回数据:
namespace webapi_study
{
public class MyDbContext
{
public static Task<Book?> GetByIdAsync(long id)
{
var result = GetById(id);
return Task.FromResult(result);
}
public static Book? GetById(long id)
{
switch (id)
{
case 0:
return new Book(0, "C#", "张三");
case 1:
return new Book(1, "Java", "李四");
case 2:
return new Book(2, "Python", "王五");
default:
return null;
}
}
}
}接下来我们在控制器的接口中注册一下缓存服务,通过GetOrCreateAsync函数拿到缓存当中的数据,如果缓存当中没有数据的话我们就正常请求接口拿到数据即可,如下所示:
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Caching.Memory;
namespace webapi_study.Controllers
{
[ApiController]
[Route("api/[controller]/[action]")]
public class TestController : ControllerBase
{
private readonly IMemoryCache cache; // 注入缓存服务
private readonly ILogger<TestController> logger; // 注入日志服务
public TestController(IMemoryCache cache, ILogger<TestController> logger)
{
this.cache = cache;
this.logger = logger;
}
[HttpGet]
public async Task<ActionResult<Book?>> GetBookById(long id)
{
// 1) 从缓存中获取数据 2)从数据库中获取数据 3)返回给调用者并将数据存入缓存
logger.LogInformation($"开始执行GetBookById: {id}");
Book? b = await cache.GetOrCreateAsync("book" + id, async (e) =>
{
logger.LogInformation($"缓存中没有找到,到数据库中查一查,id={id}");
return await MyDbContext.GetByIdAsync(id);
});
logger.LogInformation($"GetOrCreateAsync结果是:{id}");
if (b == null)
{
return NotFound($"Book with id {id} not found");
}
else
{
return b;
}
}
}
}最终呈现的效果如下所示,我们请求两次接口,第一次请求数据库中的数据因为没有缓存数据,所有是请求的接口,第二次是由于缓存中已经存在数据了,我们就直接拿到缓存当中的数据即可:

缓存过期清理
上面我们简单的介绍了一下内存缓存的简单使用,但是上面的例子中缓存是不会过期的,除非重启服务器进行重置操作,但是重置服务器的代价太大了,这里我们需要对在数据改变的时候缓存的处理,如下所示:
手动清理缓存:在数据改变的时候调用Remove或者Set来删除或修改缓存(优点:及时)
设置过期时间:只要过期时间比较短,缓存数据不一致的清空也不会持续太少时间,可以通过两种过期时间策略进行:绝对过期时间;滑动过期时间
绝对过期时间:顾名思义就是我设置了一个过期时间,超过这个时间缓存自动被清除,如下所示:

滑动过期时间:顾名思义就是只要在缓存没过期的时候请求一次,缓存就会自动续命一段时间:

两种过期时间混用:使用滑动过期时间策略,如果一个缓存项一直被频繁访问,那么这个缓存项就会一直被续期而不会过期,可以对一个缓存项同时设定滑动过期时间和绝对过期时间,并且把绝对过期时间设定比滑动过期时间长,这样缓存项的内容会在绝对过期时间内随着访问被滑动续期,但是一旦超过了绝对过期时间,缓存项就会被删除,如下所示:

总结:无论使用哪种过期时间策略,程序中都会存在缓存不一致的清空,部分系统(博客系统等)无所谓,部分系统不能忍受(比如金融),可以通过其他机制获取数据源改变的消息,再通过代码调用IMemoryCache的Set方法更新缓存。
缓存存在问题
在内存缓存中,缓存穿透和缓存雪崩是两种常见且需要特别注意的问题,下面简要讨论这两个问题及其解决方法:
缓存穿透:是指查询的数据在缓存中不存在,并且每次查询都直接访问数据库。通常缓存穿透发生在以下几种情况:
1)查询的请求数据根本不在数据库中(例如,恶意请求或数据不存在)。
2)数据被误删除或没有被正确存入缓存。
造成影响:
1)每次请求都访问数据库,导致数据库负载加重,降低系统性能。
2)缓存无法有效提高访问速度,因为每次都需要从数据库中读取数据。解决方案如下:
缓存空结果:对于一些常见的不存在数据(例如查询某个ID的数据返回为空),可以将“空”数据也缓存起来。设置一个较短的过期时间防止数据库不断查询相同的无效数据:

缓存雪崩:是指缓存中的大量数据在同一时刻过期或失效,导致大量请求同时访问数据库,造成数据库压力剧增,甚至崩溃。常见的触发场景是:
1)大量缓存失效:如果缓存的失效时间设置相同或接近,那么这些缓存项会在同一时刻失效,导致大量请求同时查询数据库。
2)数据库访问压力骤增:所有缓存失效后,系统会将大量的请求直接发送到数据库,从而加重数据库负载。
造成影响:
1)短时间内大量请求集中访问数据库,容易造成数据库崩溃或性能严重下降。
2)数据库的负载激增,可能导致响应延迟和系统整体性能下降。
解决方案如下:
在基础过期时间之上再加一个随机的过期时间:

分布式的缓存
分布式缓存是一种将缓存数据分布在多个节点上的技术,目的是提高系统的可扩展性、可用性和性能。在大型系统中,单一的缓存节点往往无法满足高并发、高可用的需求,分布式缓存应运而生。
分布式内存缓存:如果集群节点的数量非常多的话,这样的重复查询也同样可能会把数据库压垮

分布式缓存服务器: 分布式缓存是指将缓存数据分布到多个不同的服务器节点上,这些节点共同协作提供缓存服务。用户的请求通过负载均衡的方式访问不同的缓存节点。常见的分布式缓存技术有:
1)Redis:最流行的分布式缓存系统之一,支持内存存储和丰富的数据结构。
2)Memcached:另一个常见的分布式缓存,适合简单的键值对缓存场景。
3)Alibaba Tair:阿里巴巴自研的分布式缓存系统,主要服务于大规模的互联网应用。

.net core中提供了统一的分布式缓存服务器的操作接口IDistributedCache,用法和内存缓存类似,分布式缓存和内存缓存的区别在于:缓存值的类型为byte[],需要我们进行类型转换,也提供了一些安装string类型存取缓存值的扩展方法,如下所示:
| 方法 | 说明 |
|---|---|
| Task<byte[]>GetAsync(string key) | 查询缓存键key对应的缓存值,返回值是byte[]类型,如果对应的缓存不存在,则返回null。 |
| Task RefreshAsync(string key) | 刷新缓存键key对应的缓存项,会对设置了滑动过期时间的缓存项续期。 |
| Task RemoveAsync(string key) | 删除缓存键key对应的缓存项 |
| Task SetAsync(string key, byte[] value,DistributedCacheEntryOptions options) | 设置缓存键key对应的缓存项:value属性为byte类型的缓存值,注意value不能是null值 |
| Task<string> GetStringAsync(string key) | 按照string类型查询缓存键key对应的缓存值,返回值是string类型,如果对应的缓存不存在则返回null。 |
| Task SetStringAsync(string key. string value,DistributedCacheEntryOptions options) | 设置缓存键key对应的缓存项,value属性为string类型的缓存值,注意value不能是null值。 |
对于用什么做缓存服务器,用SQL Server做缓存其性能并不好;Memcached是缓存专用,性能非常高但是集群、高可用等方面比较弱,而且有”缓存键的最大长度为250字节“等限制,可以安装EnyimMemcachedCore这个第三方NuGet包;Redis不局限于缓存,Redis做缓存服务器比Memcached性能稍差,但是Redis的高可用、集群等方面非常强大,适合在数据量大、高可用性等场合使用,可以按照如下插件进行使用:

然后我们在入口文件进行服务注册:
builder.Services.AddStackExchangeRedisCache(options =>
{
options.Configuration = "localhost:6379"; // 配置连接字符串
options.InstanceName = "SampleInstance"; // 配置实例名称,避免缓存冲突
});然后我们在控制器当中构造分布式缓存的服务:

然后通过GetStringAsync函数构造当前的id,来判断当前是否存在缓存
[HttpGet]
public async Task<ActionResult<Book?>> GetBookById1(long id)
{
Book? book;
string? s = await disCache.GetStringAsync("book" + id);
if (s == null)
{
book = await MyDbContext.GetByIdAsync(id);
await disCache.SetStringAsync("book" + id, JsonSerializer.Serialize(book));
}
else
{
book = JsonSerializer.Deserialize<Book?>(s);
}
if (book == null)
{
return NotFound($"Book with id {id} not found");
}
else
{
return book;
}
}通过redis服务器可以看到我们的缓存信息:


















![python算法和数据结构刷题[3]:哈希表、滑动窗口、双指针、回溯算法、贪心算法](https://i-blog.csdnimg.cn/direct/00558cf97fac4c2b8ce7730479114ce6.png)
