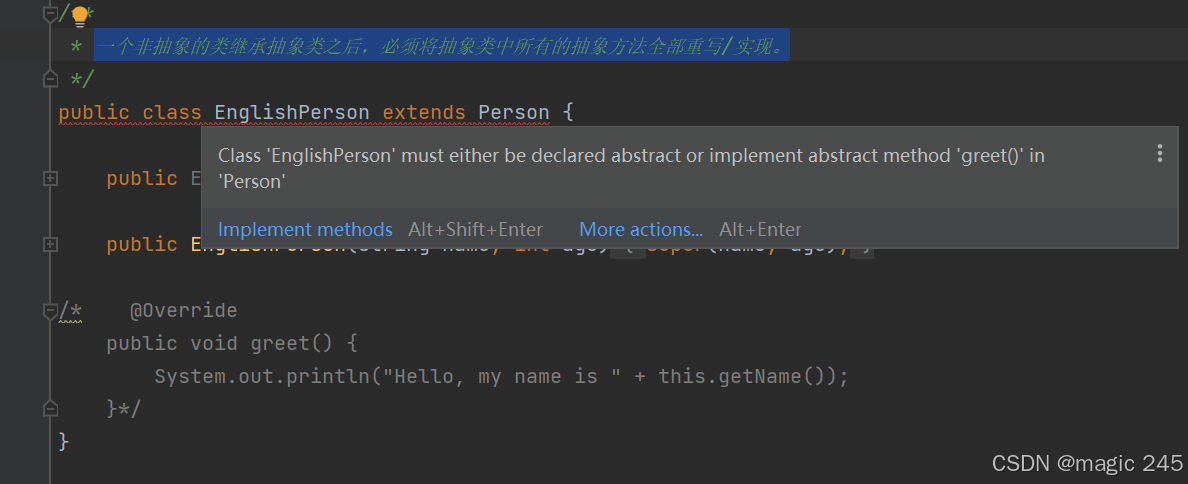
本文将通过一个具体的例子,展示如何使用 Python 和 scikit-learn 库中的 GaussianNB 模型,对二维散点数据进行分类,并可视化分类结果。
1. 数据准备
假设我们有两个类别的二维散点数据,每个类别包含若干个点。我们将这些点分别存储为 NumPy 数组,并为每个点分配一个类别标签。
import numpy as np
# 类别 1 的点集
class1_points = np.array([[1.9, 1.2],
[1.5, 2.1],
[1.9, 0.5],
[1.5, 0.9],
[0.9, 1.2],
[1.1, 1.7],
[1.4, 1.1]])
# 类别 2 的点集
class2_points = np.array([[3.2, 3.2],
[3.7, 2.9],
[3.2, 2.6],
[1.7, 3.3],
[3.4, 2.6],
[4.1, 2.3],
[3.0, 2.9]])
# 合并数据
X = np.vstack((class1_points, class2_points))
# 创建标签
y = np.array([0] * len(class1_points) + [1] * len(class2_points))2. 训练朴素贝叶斯模型
朴素贝叶斯分类器基于贝叶斯定理,假设特征之间相互独立。GaussianNB 是一种适用于连续数值型数据的朴素贝叶斯分类器,它假设每个特征的分布符合高斯分布。
from sklearn.naive_bayes import GaussianNB
# 初始化朴素贝叶斯分类器
model = GaussianNB()
# 训练模型
model.fit(X, y)3. 可视化分类结果
为了更好地理解模型的分类效果,我们可以绘制散点图,并显示决策边界。这有助于直观地观察模型如何区分两个类别。
import matplotlib.pyplot as plt
# 创建网格点
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
# 预测网格点的类别
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界和散点图
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Naive Bayes Decision Boundary')
plt.show()可视化结果展示:

4. 预测新数据点
训练好的模型可以用于对新的数据点进行分类。我们将提供一些新的数据点,并使用模型预测它们的类别。
# 新数据点
new_points = np.array([[2.0, 2.0],
[3.5, 3.0]])
# 预测新数据点的类别
new_predictions = model.predict(new_points)
print("New points predictions:", new_predictions)预测结果:

5. 完整代码
以下是完整的代码实现,包括数据准备、模型训练、可视化和新数据点的预测。
import numpy as np
from sklearn.naive_bayes import GaussianNB
import matplotlib.pyplot as plt
# 类别 1 的点集
class1_points = np.array([[1.9, 1.2],
[1.5, 2.1],
[1.9, 0.5],
[1.5, 0.9],
[0.9, 1.2],
[1.1, 1.7],
[1.4, 1.1]])
# 类别 2 的点集
class2_points = np.array([[3.2, 3.2],
[3.7, 2.9],
[3.2, 2.6],
[1.7, 3.3],
[3.4, 2.6],
[4.1, 2.3],
[3.0, 2.9]])
# 合并数据
X = np.vstack((class1_points, class2_points))
# 创建标签
y = np.array([0] * len(class1_points) + [1] * len(class2_points))
# 初始化朴素贝叶斯分类器
model = GaussianNB()
# 训练模型
model.fit(X, y)
# 创建网格点
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
# 预测网格点的类别
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界和散点图
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Naive Bayes Decision Boundary')
plt.show()
# 新数据点
new_points = np.array([[2.0, 2.0],
[3.5, 3.0]])
# 预测新数据点的类别
new_predictions = model.predict(new_points)
print("New points predictions:", new_predictions)