前言
本文将用 c++ 实现一个终端计算器:
- 能进行加减乘除、取余乘方运算
- 读取命令行输入,输出计算结果
- 当输入表达式存在语法错误时,报告错误,但程序应能继续运行
- 当输出 ‘q’ 时,退出计算器
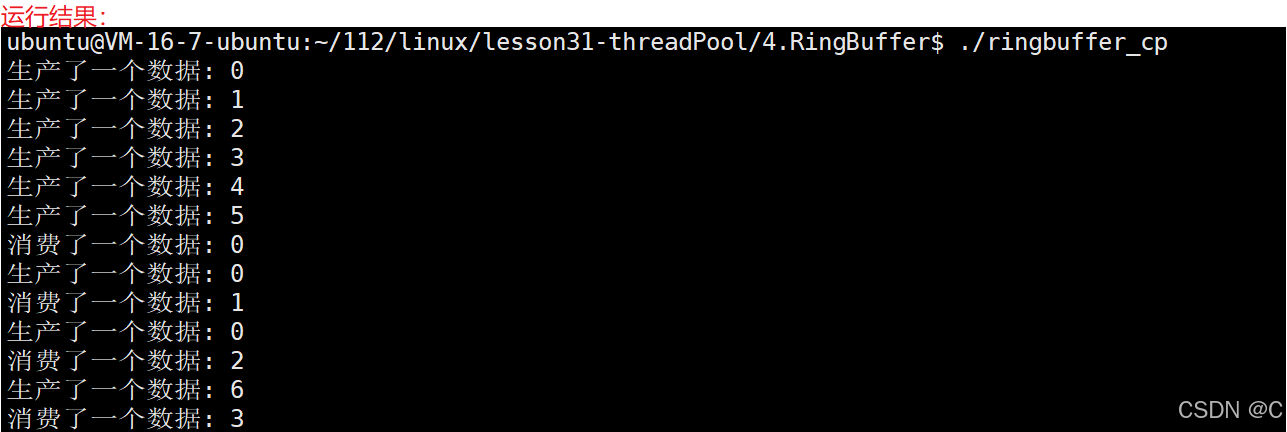
【简单演示】

【源码位置】 Calculator 的 src_old 目录下
如果读者学过编译原理,那么实现简易计算器对你来说将轻而易举;倘若你没学过也没关系,本文将从初学者的角度带领你做出满足上述要求的计算器。
一、词法分析
假设有如下的表达式:
> 10 + 1
那么计算器将输出:= 11。
对于计算器而言,“10 + 1” 仅仅是一串字符,它是怎么”看懂“的,又是怎么计算的呢?
举一个大家都懂的例子:翻译英语。
给定一英语 “hello world.”,你为什么能翻译出它的意思?因为你学过 “hello”、“world” 两个单词,知道他们的意思,所以你会翻译这句话。也就是说,学过单词的你,这句话在你的眼中相当于两个连续的单词:“hello”、“world”;但如果你没学过英语,可能你看到的就是一个一个的字母而已 ‘h’、‘e’、‘l’ … 这就是词法分析,简单说就是识别出字符串中基本单元——单词 (token)。
再来分析上述例子:“10 + 1”
从人的角度来看,接收这串字符,你将识别出这些 token: “10”、“+”、“1”;接着,你明白 “10” 是一个数字,“+” 是一个加法运算符,“1” 是一个数字,此时你明白这是一个加法式子,你便能计算出结果为 “11”。因此,计算器第一步应该像学英语一样先学习单词,让它能像人一样识别字符串中的 token,这就是第一步词法分析。
1. TokenKind
学习英语单词时,不仅要背翻译,还要记忆词性(动词、形容词等),这样的目的是为了之后的语法分析,比如:主语后往往接一个动词。
对于计算器也是类似的,识别出一个 token 后,计算器将关心这个 token 的
- kind(相当于词性):它是一个数字,还是一个运算符?
- value(相当于翻译):token("10”).value = 10, token(‘+’).value = +
根据上述描述,你可能想到的方案如下:
class Token
{
public:
std::string value; // 字符串存储值
TokenKind kind; // 枚举类 TokenKind 标识类型字段
};
这个方案可行,但比较复杂:
- 对于数字来说:只需要先判断 kind,即可得到 value
- 对于运算符来说:也需要先判断 kind,再取 value
看下面的方案:
class Token
{
public:
std::string value;
char kind;
};
该方案用 char 替代了 TokenKind,为什么呢?对于运算符 ‘+’、‘-’、‘*’、‘/’、‘%’、‘^’,你会发现他们都是单字符,同时各不相同,而且都是非字母数字字符,那么这么做就有一个好处:对于运算符来说,kind 就是 value,这能简化后面的编码(语法分析部分可体会到)。
因此,对于 Token 的设计采用第二种方案。
2. Token
上一部分说到,Token 有两个字段:value、kind。对于运算符来说,仅 kind 字段有效;对于数字来说,两字段均有效。也就是说 value 仅当 kind 表示数字时有效,因此,我采用自己设计的 Number 类(代码位于 Number 文件夹下) 来存储 value:
class Token
{
public:
static const char kd_null = '`'; // null
static const char kd_number = 'n'; // number
static const char kd_quit = 'q'; // 结束程序
public:
Token() :val{ }, kind{ kd_null } { }
~Token() = default;
public:
bool is_null() const { return kind == kd_null; }
public: /* 方便后续编码 */
Number val;
char kind;
};
3. TokenStream
c++ 的 cin 关联到控制台输入,将输入字符视为字符流,可以使用 cin.get() 获取流中的第一个字符。这是不是跟词法分析的任务很像:从表达式中识别出 token,并一个个地返回。
class TokenStream
{
public:
TokenStream(std::istream& is);
~TokenStream() = default;
public:
bool eof() const;
Token get(); // 返回流中的第一个 token
Token peek(); // 查看流中的第一个 token
private:
std::istream& _is; // 与输入流相关联,从其中读取 token
bool _eof; // 是否到流的结尾
bool _full; // _buffer 是否满了
Token _buffer; // 缓冲区
};
在语法分析中,常常需要提前读取下一个 token:
简单举个例子:运算符后应该跟一个数字或者左括号(“1 + 1”、“1 + (2 - 1)”)。那么如果当前处理的 token.kind == ‘+’,那么下一个 token 要么是数字,要么是左括号,两种情况处理结果不一样。为此,应该需要提前读取下一个 token,即 peek( ) 函数:与 get( ) 不同的是,peek( ) 仅仅是查看流中的下一个 token(假设是 X),调用后此时流中的第一个 token 仍然是 X;但是调用 get( ) 将返回流中的第一个 token,即 X 被读取了,此后流中的第一个 token 不再是 X。
为了实现 peek( ) 函数,TokenStream 引入缓冲区:_full 标记缓冲区是否已经满了,_buffer 保存当前流中的第一个 token:

Token TokenStream::peek()
{
if (!_full) {
_buffer = get();
_full = true;
}
return _buffer;
}
此类的难点在 get( ) 的实现:如何从流中识别出下一个 token。
在之前的分析,流中的 token 有如下几种:
number、‘q’、‘+’、‘-’、‘*’、‘/’、‘%’、'^‘、null (用来表示流已经没有 token 了,即到了流的末尾)
对于除了 number 的其他都是单字符,非常容易识别出;难点在于如何识别 number。下面来介绍如何识别 number:
number 包括 整数、浮点数
引入 “文法” 的概念,你可以简单理解为语法,它描述一种语言生成的方式。
先以最简单的整数(int)为例:+1、1、-1都是整数,即除去第一位的符号位,其余都是数字(digit),因此 int 对应文法如下:
- int ⇒ ‘+’ digit digits | ‘-’ digit digits | digit digits
- digits ⇒ digit digits | ‘’
- digit ⇒ ‘0’ | ‘1’ | ‘2’ | ‘3’ | ‘4’ | ‘5’ | ‘6’ | ‘7’ | ‘8’ | ‘9’
【解释】
- 整数可以是
- ‘+’ 后必须先接单个数字 (digit) 再接数字串 (digits)
- ’-‘ 后必须先接单个数字再接数字串
- 单个数字后接数字串
- 数字串可以是
- 单个数字后接数字串
- 空串 ( ‘’ )
- 单个数字为 ‘0’ ~ ‘9’
对此即可写对应程序识别出 int。
【示例程序】
std::string get_digits(std::istream& is) /* digits ⇒ digit digits | '' */
{
std::string digits;
while (isdigit(is.peek()))
digits.push_back(is.get());
return digits;
}
std::string get_int(std::istream& is)
{
std::string num;
char c = is.get();
switch (c) {
case '+': case '-': /* '+' digit digits | '-' digit digits */
{
num.push_back(c);
if (isdigit(is.peek())) {
num.push_back(is.get());
num += get_digits(is);
}
else throw std::string{"bad number"};
break;
}
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9': /* digit digits */
{
num.push_back(c);
num += get_digits(is);
break;
}
default: throw std::string{"bad number"};
}
return num;
}
类似的,可以对应写出 number 识别程序:
【注意】“.123” 也视为 number
- 文法
- number ⇒ int | int float | float
- float ⇒ ‘.’ int
- 程序
std::string get_float(std::istream& is)
{
if (is.peek() != '.') throw std::string{"bad float"};
std::string res;
res.push_back(is.get());
res += get_int(is);
return res;
}
std::string get_number(std::istream& is)
{
char c = is.peek();
std::string num;
switch (c) {
case '.':
{
num = get_float(is);
break;
}
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
{
num = get_int(is);
if (is.peek() == '.') num += get_float(is);
break;
}
default: throw std::string{"bad number"};
}
return num;
}
上述为示例程序,在计算器程序中,我将使用自己设计的 Number 类,此类重载了输入运算符,即你可如下使用 Number:
Number num;
cin >> num; // 如果读取 num 失败,将设置流状态 (cin.fail() == true)
因此 get( ) 函数如下:
Token TokenStream::get()
{
if (_full) { // 先读取缓冲区中的 token
_full = false;
return _buffer;
}
Token token;
if (_eof) return token;
while (true) {
char c = _is.peek();
if (_is.eof()) {
_eof = true;
return Token{};
}
switch (c) {
case ' ': /* 跳过空格 */
{
_is.get();
continue;
}
case '0': case '1': case '2': case '3': case '4': case '5':
case '6': case '7': case '8': case '9': case '.':
{
Number num;
_is >> num;
if (_is.fail()) throw CalExcep{"illegal number"};
token.kind = Token::kd_number;
token.val = num;
return token;
}
case globe::ADD: case globe::SUB: case globe::MUL: case globe::DIV: case globe::MOD:
case globe::POW: case globe::LBRA: case globe::RBRA: case globe::QUIT:
{
token.kind = _is.get();
return token;
}
default:
throw CalExcep{ "illegal terminal character: '" + std::string{c} + "'" };
}
}
return token;
}
阅读上面代码,你可能注意到一个问题:以 ‘+’、‘-’ 开头的为什么不当作数字去读取?看下面这个输入
1+1
‘+’ 之后紧接着是 ‘1’,倘若将它识别为 ‘+1’,这个输入将被识别为 ‘1’、‘+1’ 两个数字,那么语法分析处将报错:这不是一个合法表达式;但显然我们知道它是合法的。说到这里你可能会选择将 ‘+’、‘-’ 开头的不再当作数字,而是当作运算符,这种做法是正确的。倘若有如下输入
-1+1
你会发现上述输入将被识别为 “-”、“1”、“+”、“1”,这样的 token 流在语法分析处可通过计算器文法设计解决。
二、语法分析
从网上搜索计算器文法如下:
- expr ⇒ term | expr ‘+’ term | expr ‘-’ term
- term ⇒ factor | term ‘*’ factor | term ‘/’ factor | term ‘%’ factor
- factor ⇒ primary | primary ‘^’ factor
- primary ⇒ ‘(’ expr ‘)’ | number | ‘-’ number | ‘+’ number
[上面的每个式子称为 “产生式”]
此文法能正确描述出表达式,倘如你要问这文法是怎么来的,额,反正我不知道-_-。举个例子来看此文法是怎么描述表达式的:
先举一个简单的例子:
expr ⇒ term ⇒ factor ⇒ primay ⇒ number
因此单独一个数字也是表达式:“100” 是一个合法表达式。
expr
⇒ expr ‘+’ term ⇒ term ‘+’ term ⇒ primay ‘+’ term ‘*’ factor
⇒ ‘-’ number ‘+’ factor ‘*’ number ⇒ ‘-’ number + number ‘*’ number
也就是说 “-1 + 1 * 1” 是一个合法表达式。
上边的两个例子展示了如何通过文法产生合法表达式,下面来看它的逆过程:已知一表达式,检查是否满足文法要求,这就是语法分析。
先看简单例子:
1 + 1
假如它是合法表达式,那么一定存在如下推导:
expr ⇒ … ⇒ number ‘+’ number
现在就要寻找是否存在这样的推导。观察文法,有 ‘+’ 的是 “expr ⇒ expr ‘+’ term”,因此第一步推导如下:
expr ⇒ expr ‘+’ term ⇒ … ⇒ number ‘+’ number
那么接下来就是找出是否存在 “expr ⇒ … ⇒ number”,显然有,因为
expr ⇒ term ⇒ factor ⇒ primay ⇒ number
同时也找到了 “term ⇒ … ⇒ number”,所以,“1 + 1” 满足文法,它是合法表达式。这个过程可用树形结构来表示:

看一个较为复杂的例子:

上面是人的角度来选取文法产生式的,但我们的目标是用程序实现。先看第一个文法产生式:
expr ⇒ term | expr ‘+’ term | expr ‘-’ term
那么对应伪代码应该为
expr()
{
case 1: term();
case 2: expr(); get('+'); term();
case 3: expr(); get('-'); term();
other : throw "bad expression";
}
将此伪代码转为 c++ 代码,需要解决一个问题:怎么判断什么情况下选用 case 1、case 2、case 3。你可能想到只需要判断在 term( )、expr( )、expr( ) 之后的下一个 token 是什么即可。那来看下面的输入:
2 * 3 + 1
从 expr 出发,第一次调用 case 1: term( ),即用 term( ) 去分析 “2 * 3 + 1”,那么一定会分析出这是一个非法表达式(因为 term 一定不能产生出 ‘+’),那么就无法判断下一个 token 了,显然这样做是不对的;应该回溯到 expr( ),再次判断 case 2、case 3,当都不满足时,才抛出异常 “bad expression”。
这样做的确可以,但由于用到回溯算法,效率自然不会高。有没有什么方法提高效率呢?改写文法,构造预测分析表。
此处涉及到编译原理 LL文法 知识,读者如果有兴趣可自行了解,不了解也无所谓,在下面只需要会根据 LL(1) 预测分析表 编写代码即可。
在这里对文法先进行消除左递归,合并左公因子 得到满足 LL 文法要求的新文法:
- expr ⇒ term E
- E ⇒ ‘+’ term E | - term E | ‘’
- term ⇒ factor T
- T ⇒ ‘*’ factor T | ‘/’ factor T | ‘’
- factor ⇒ primary F
- F ⇒ ^ factor | ‘’
- primary ⇒ ‘(’ expr ‘)’ | number | ‘+’ number | ‘-’ number
利用 FIRST集、FOLLOW集 构造出 LL(1) 预测分析表 (想了解的可点击此处):
| ( | + | - | * | / | % | ^ | ) | number | eof | |
|---|---|---|---|---|---|---|---|---|---|---|
| expr | term E | term E | term E | term E | ||||||
| E | ‘+’ term E | ‘-’ term E | ‘’ | ‘’ | ||||||
| term | factor T | factor T | factor T | factor T | ||||||
| T | ‘’ | ‘’ | ‘*’ factor T | ‘/’ factor T | ‘%’ factor T | ‘’ | ‘’ | |||
| factor | primary F | primary F | primary F | primary F | ||||||
| F | ‘’ | ‘’ | ‘’ | ‘’ | ‘’ | ‘^’ factor | ‘’ | ‘’ | ||
| primary | ‘(’ expr ‘)’ | ‘+’ number | ‘-’ number | number |
【说明】
- 第一行表示终结符,表达式的基本单元,即 token
- 第一列为产生式左部
- eof 表示当前为流的末尾(无 token 可读取)
- ‘’ 表示空串
- 为空 (不是空串) 的地方表示出现语法错误
- 第二行第一列:表示在 expr( ) 分析时,如果下一个 token 为 ‘(’,则应使用产生式 “expr ⇒ term E”;由于产生式右部第一个单元为 term,不是终结符,进入 term 分析
- 第三行第三列:表示在 E( ) 分析时,如果下一个 token 为 ‘+’,则应使用产生式 “E ⇒ ‘+’ term E”;由于产生式右部第一个单元为 ‘+’,是终结符并且等于当前 token,则读取此 token,此时产生式转为 “E ⇒ term E”,进入 term 分析。
【举例如何使用预测分析表】
-
表达式为:“1 + 1”:
- 此时正在分析 expr,下一个 token = number(‘1’),使用 “expr ⇒ term E”,进入 term 分析
- 此时正在分析 term,下一个 token = number(‘1’),使用 “term ⇒ factor T”,则新的产生式为 “expr ⇒ factor T E”,进入 factor 分析
- 此时正在分析 factor,下一个 token = number(‘1’),使用 “factor ⇒ primary F”,则新的产生式为 “expr ⇒ primary F T E”,进入 primary 分析
- 此时正在分析 primary,下一个 token = number(‘1’),使用 “primary ⇒ number”,新的产生式为 “expr ⇒ number F T E”,由于 number 为终结符,恰好与 token 相同,故读取此 token,新的产生式为 “expr ⇒ F T E”,进入 F 分析
- 此时正在分析 F,下一个 token = ‘+’,使用 " F ⇒ ‘’ "(F 转为空串),新的产生式为 “expr ⇒ T E”,进入 T 分析
- 此时正在分析 T,下一个 token = ‘+’,使用 " T ⇒ ‘’ ",新的产生式为 “expr ⇒ E”,进入 E 分析
- … …(以此类推)
- 最终的产生式为 " expr ⇒ ‘’ "(expr 转为空串),因此语法分析结束,并且语法正确。 (如果最终产生式不为空串,语法分析错误)
-
表达式为:" / 1":
- 此时正在分析 expr,下一个 token = ‘/’,但是对应的预测分析表第二行第六列为空,因此语法错误
-
表达式为:“+”
- 此时正在分析 expr,下一个 token = ‘+’,使用 “expr ⇒ term E”,进入 term 分析
- 此时正在分析 term,下一个 token = ‘+’,使用 “term ⇒ factor T”,新的产生式为 “expr ⇒ factor T E”,进入 factor 分析
- 此时正在分析 factor,下一个 token = ‘+’,使用 “factor ⇒ primary F”,新的产生式为 “expr ⇒ primary F T E”,进入 primary 分析
- 此时正在分析 primary,下一个 token = ‘+’,使用 “primary ⇒ ‘+’ number”,新的产生式为 “expr ⇒ ‘+’ number F T E”,产生式右部第一个单元 ‘+’ 与当前 token 相同,故读取当前 token,新的产生式为 “expr ⇒ number F T E”,下一个 token = eof,但是产生式第一个单元为终结符 number,与 eof 不相等,因此语法分析错误。
根据上述描述,设计出 Calculator 类:
class Calculator
{
public:
Calculator() = default;
~Calculator() = default;
public:
/* 计算 expression 结果并返回 */
Number calculate(const std::string& expression);
private:
void expr (TokenStream& ts);
void E (TokenStream& ts);
void term (TokenStream& ts);
void T (TokenStream& ts);
void factor (TokenStream& ts);
void F (TokenStream& ts);
void primary(TokenStream& ts);
private:
Number _val; /* 接受结果 */
};
_val 用于接收计算结果,在语义分析部分会使用到。
以 T 分析为例:(其他都类似)
void Calculator::T(TokenStream& ts)
{
auto peek = ts.peek();
switch (peek.kind) {
case globe::MUL: // T ⇒ '*' factor T
{
ts.get();
factor(ts);
T(ts);
break;
}
case globe::DIV: // T ⇒ '/' factor T
{
ts.get();
factor(ts);
T(ts);
break;
}
case globe::MOD: // T ⇒ '%' factor T
{
ts.get();
factor(ts);
T(ts);
break;
}
case globe::RBRA: case globe::ADD: // T ⇒ ''
case globe::SUB: case Token::tk_null: break;
default: throw CalExcep{"lack of operator"}; // throw
}
}
三、语义分析
前面我们分析了词法、语法,都是在分析表达式的合法性,并没有去计算表达式的结果,在此部分变便来完成这个任务。
还是以英语翻译为例:
一个简单英语文法:
- 英语句子’⇒ 主语 动词
- 主语 ⇒ “I” | “You”
- 动词 ⇒ “see” | “say”
那么对于输入:“I see”,对应语法树为:

在语法树中,每个节点是文法的一部分,在这里给节点引入属性值这一字段,在原文法中引入语义动作:需要执行的程序片段,用 { } 包围
引入语义动作的英语文法:
- 英语句子’⇒ 主语 动词
{英语句子.val = 主语.val + 动词.val}- 主语 ⇒ “I”
{ 主语.val = "I" 的翻译 }- 主语 ⇒ “You”
{ 主语.val = "You" 的翻译 }- 动词 ⇒ “see”
{ 动词.val = "see" 的翻译 }- 动词 ⇒ “say”
{ 动词.val = "say" 的翻译 }
为此,含有语义动作的语法树变为:

所以,当我们引入语义动作后,完成了英语翻译这一任务。类似的,计算器语义分析也是如此:只需要在计算器表达式文法加入合适的语义动作,便能完成计算任务。
如何添加合适的语义动作呢?可以通过语法树来分析:
以 “1 + 1” 为例:

在上图中:“primary --> 1” 对应 “primary ⇒ number”,primary.val 应等于 number.value,因此有
primary ⇒ number {primary.val = number.value}
在树的根部处对应 “expr ⇒ expr ‘+’ term”,expr.val 应等于 expr.val + term.val,故有
expr ⇒ expr ‘+’ term {expr.val = expr.val + term.val}
其他的也是如此类推,当然上图使用的文法是原文法
- expr ⇒ term | expr ‘+’ term | expr ‘-’ term
- term ⇒ factor | term ‘*’ factor | term ‘/’ factor | term ‘%’ factor
- factor ⇒ primary | primary ‘^’ factor
- primary ⇒ ‘(’ expr ‘)’ | number | ‘-’ number | ‘+’ number
不是 LL 文法:
- expr ⇒ term E
- E ⇒ ‘+’ term E | - term E | ‘’
- term ⇒ factor T
- T ⇒ ‘*’ factor T | ‘/’ factor T | ‘’
- factor ⇒ primary F
- F ⇒ ^ factor | ‘’
- primary ⇒ ‘(’ expr ‘)’ | number | ‘+’ number | ‘-’ number
本文实现的计算器使用的是 LL 文法,如何给它加入语义动作呢?方法也是先画语法分析树,在根据自己的理解,自底向上地进行节点属性值的赋值,由此推导出语义动作。
读者可自行推导,下面是我自己采用的另外一种方法:不用节点属性值赋值,而是用一个变量保存结果(即之前说的 _val 成员变量),这样做的好处是减少了许多不必要的赋值。
- expr ⇒ term E
- E ⇒
{left = _val}‘+’ term{_val = left + _val}E- E ⇒
{left = _val}‘-’ term{_val = left - _val}E- E ⇒ ‘’
- term ⇒ factor T
- T ⇒
{left = _val}‘*’ factor{_val = left * _val}T- T ⇒
{left = _val}‘/’ factor{_val = left / _val}T- T ⇒ ‘’
- factor ⇒ primary F
- F ⇒
{left = _val}^ factor{_val = left ^ _val}- F ⇒ ‘’
- primary ⇒ ‘(’ expr ‘)’
- primary ⇒ number
{_val = number}- primary ⇒ ‘+’ number
{_val = number}- primary ⇒ ‘-’ number
{ _val = -1 * number}
则在 expr 分析完毕后,_val 就是计算器计算的结果。
【说明】E ⇒ {left = _val} ‘+’ term {_val = left + _val} E
在分析 E 时,先需要执行语义动作 {left = _val},保存左值(+、-、*、/、%、^ 都是二元运算符,因此在 ‘+’ 之前需要保存左值 left),之后读取 token(‘+’),然后进行 term 分析,此时 _val 保存的是右值,故执行 {_val = left + _val},结果等于 左值(left) + 右值(_val),之后再进行 E 分析。
当然可能你看到上述文法会感觉很疑惑,无法理解,最好理解的方式是自己画语法树,然后 debug 代码一步一步地理解,如果你有耐心的话。
【源码位置】 Calculator 的 src_old 目录下