介绍
LLM
大型语言模型(英语:large language model,LLM),也称大语言模型,是由具有大量参数(通常数十亿个权重或更多)的人工神经网络组成的一类语言模型。在进行语言理解与分析(如文本分类、信息抽取)后,可以赋能用于语言生成(含文本创作、对话、机器翻译)、知识问答与推理等工作。
Qwen2.5
Qwen2.5是一款由阿里根据自己的预训练策略、优化目标和数据筛选方法,不断迭代,开源的基础模型。
SakuraLLM
SakuraLLM也在不断的迭代。通过SakuraLLM的介绍主页我们知道SakuraLLM目前的发布版本基于Qwen2.5进行微调,其宗旨是提供可控可离线自部署的、ACGN风格的日中翻译模型。
实践
得益于SakuraLLM提供高于网络词典的翻译质量,我们可以配合其他工具,在免费非商用的前提下,为我们实现漫画翻译以及日语视频生成中午字幕这些满足个人娱乐的功能。
前置准备
首先说一下博主的机器配置
显卡 ROG STRIX GeForce RTX® 4080 16GB GDDR6X 猛禽
CPU i7-13700KF
内存 32.0 GB
获取翻译模型
首先这里介绍一下模型中的大模型中0.5B, 1.5B, 3B, 7B, 14B, 32B是什么意思
这些数字(0.5B, 1.5B, 3B, 7B, 14B, 32B)通常表示大语言模型(如GPT、BERT等)中的参数数量,单位是十亿(B代表“Billion”)。参数是模型学习的关键部分,它们决定了模型的复杂性和能力。具体来说:
- 0.5B 表示模型有 5 亿个参数。
- 1.5B 表示模型有 15 亿个参数。
- 3B 表示模型有 30 亿个参数。
- 7B 表示模型有 70 亿个参数。
- 14B 表示模型有 140 亿个参数。
- 32B 表示模型有 320 亿个参数。
随着参数数量的增加,模型的计算能力和表示能力通常也会提高,但这也意味着需要更多的计算资源和数据来训练模型。大模型(如 GPT-3、GPT-4)通常有数百亿甚至数千亿个参数。
目前发布的正式版模型如下,参考上述我的设备规格目前我选用的是sakura-14b-qwen2.5-v1.0-iq4xs.gguf
| 模型 | 显存大小 | 模型规模 |
|---|---|---|
| sakura-7b-qwen2.5-v1.0-iq4xs.gguf | 8G/10G | 7B |
| sakura-14b-qwen2.5-v1.0-iq4xs.gguf | 11G/12G/16G | 14B |
| sakura-14b-qwen2.5-v1.0-q6k.gguf | 24G | 14B |
p.s. 如果无法连接到HuggingFace服务器,可将链接中的huggingface.co改成hf-mirror.com,使用hf镜像站下载。
安装Python
因为对于大模型的丰富生态支持,因此大多数工具都是基于Python来开发,因此我们需要在官方网站下载并安装python-3.12.4
启动模型
为了更简化操作,我用使用了SakuraLLMServer来启动模型,根据提示把翻译模型放到文件夹中启动即可。
文件结构如下
SakuraLLMServer\llama\...
\00_Core.bat
\01_1280_NP16.bat
\sakura-14b-qwen2.5-v1.0-iq4xs.gguf
\...| 显存大小 | 模型规模 | 启动脚本 |
|---|---|---|
| 8G/10G | 7B | 01_1280_NP16.bat |
| 11G | 14B | 01_1280_NP4.bat |
| 12G | 14B | 01_1280_NP6.bat |
| 16G/24G | 14B | 01_1280_NP16.bat |
结合我的配置启动01_1280_NP16.bat脚本即可

下面两个功能的使用默认已经做好前置准备
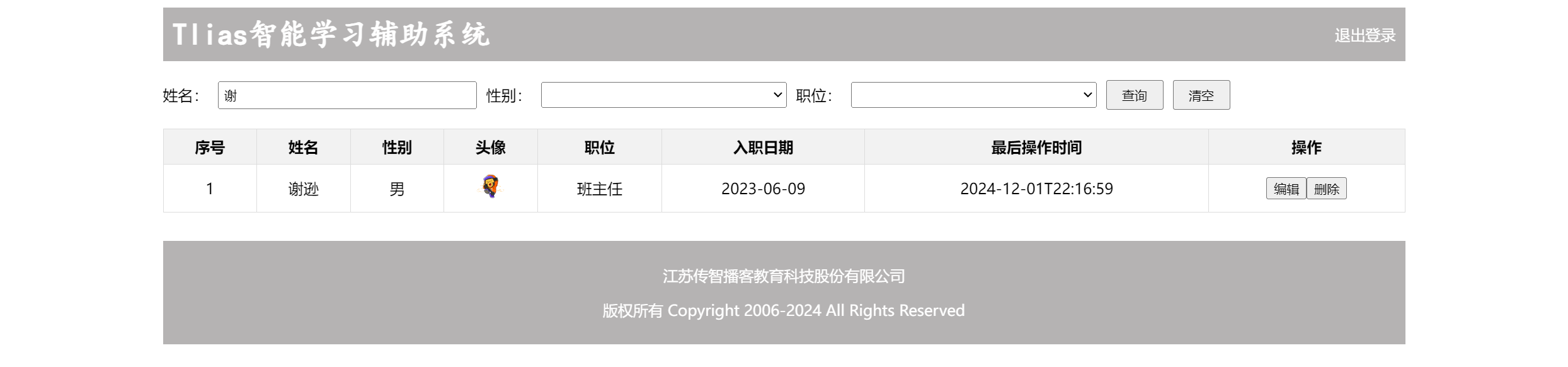
漫画翻译
一张漫画使用程序翻译大概需要通过日文识别、日译中翻译、译文漫画重嵌3个步骤。
遵从不使用第三方整合下载(防病毒)的原则自行部署,目前我部署成功的项目是BallonsTranslator: 深度学习辅助漫画翻译工具, 支持一键机翻和简单的图像/文本编辑,如果我们使用BallonsTranslator进行漫画翻译,那么他具体的操作流程如下

使用本文描述的的部署方式,不想自己手动配置环境,需要能正常访问互联网
1. 从 MEGA 或 Google Drive 下载 BallonsTranslator_dev_src_with_gitpython.7z,正常来说执行launch_win.bat即可。
1.1 但是因为各种原因,有可能项目相关的lib没办法正常下载,因此在上述描述的数据载体中下载data 和 ballontrans_pylibs_win.7z,下载并放到所属文件夹即可
2.打开应用后配置Sakura,因为项目本身早已对SakuraLLM进行对接,下面的参数默认即可

3.选择我们图片所在的文件夹点击RUN


应用日志


日语视频生成中文字幕
一个视频使用程序翻译大概需要通过让提取音频、识别音频提取对话内容、对话字幕进行日译中3个步骤。
目前我部署成功的项目是VoiceTransl,使用VoiceTransl进行字幕生成与翻译,那么他具体的操作流程如下

1. 根据提示下载最新版本的VoiceTransl
1.1 把sakura的模型放置到llama文件夹下
文件结构如下
_internal/llama/
sakura-14b-qwen2.5-v1.0-iq4xs.gguf2. VoiceTransl本身不带语音识别模型的因此我们要自行下载 faster-whisper-large-v3 、DLL文件和EXE文件 ,放到whisper-faster文件夹下
文件结构如下
faster-whisper-large-v3/
config.json
model.bin
preprocessor_config.json
tokenizer.json
vocabulary.json
cublas64_11.dll
cublasLt64_11.dll
cudnn_cnn_infer64_8.dll
cudnn_ops_infer64_8.dll
zlibwapi.dll
whisper-faster.exe3. 设置模型

4. 选择需要翻译的视频

程序会在调用faster-whisper-large-v3提取音频内容后,自行调用sakuraLLm进行翻译


不过通过开源模型来进行识别音频,那么就代表了不一定能进行百分百的对话识别,如我使用的这个视频【IGN】PC版《最终幻想7 重生》游戏特性介绍视频识别到的对话内容大概只有60%,可能是因为有背景配乐的原因。因此要完整的视频字幕我们需要或多或少的给翻译的字幕文件进行对话内容步充。
AiNiee
这里我发现的一个问题,就是VoiceTransl自行调用模型文件进行翻译的效率比较一般,鉴于我对字幕srt文件的认识,他本质上是一个txt文件,因此我打算利用AiNiee对txt文件进行翻译,发现测试效率比VoiceTransl自己调用的方式高,使用AiNiee进行汉化的方式如下:

1. 下载并解压AiNiee
2. 使用SakuraLLM接口,设置项目类型为Txt小说文件,确保SakuraLLMServer已正常启动

2. 把字幕的.srt后缀改成的.txt文件后缀放到AiNiee的input文件夹,开始翻译即可,翻译成功后文件会放到output文件夹


感悟
目前开源大模型,更多的是适合给自己赋能,希望后续能通过更多的了解带来更多好玩的内容
参考:大型语言模型WIKI
Qwen2.5: 基础模型
【LLM】从零开始训练大模型
SakuraLLM
【VoiceTransl】离线AI全自动烤肉 支持多语言 支持字幕合成