一、配置torch
1.Libtorch下载
该内容看了【Libtorch 一】libtorch+win10环境配置_vsixtorch-CSDN博客的博客,作为笔记用。我自己搭建后可以正常运行。
下载地址为windows系统下各种LibTorch下载地址_libtorch 百度云-CSDN博客
下载解压后的目录为:
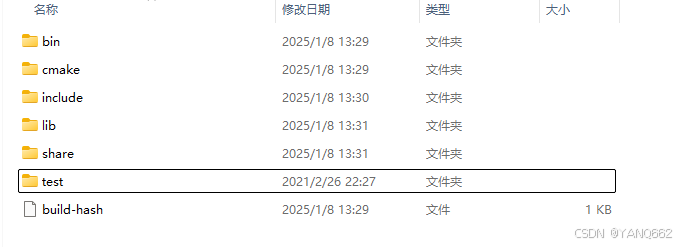
2.vs 2022配置Torch
首先,创建一个新的项目和一个新的cpp文件。
然后,在界面选择release和X64,如下图所示:
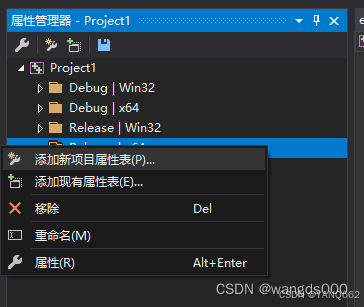
在属性管理器中【添加新项目属性表】
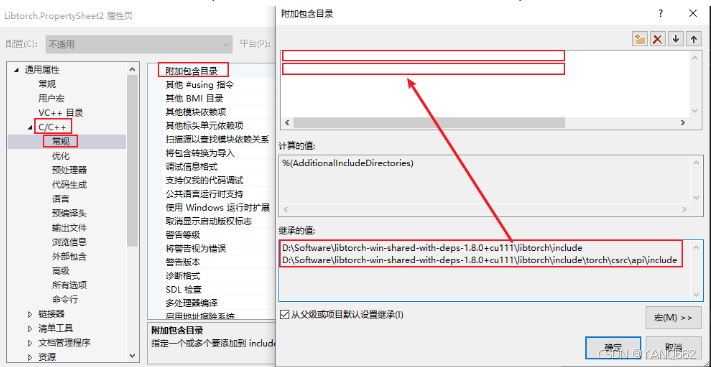
打开项目属性,在【附加包含目录】中添加
E:\Environmentc\libtorch\include
E:\Environmentc\libtorch\include\torch\csrc\api\include
在【附加库目录】中添加
E:\Environmentc\libtorch\lib
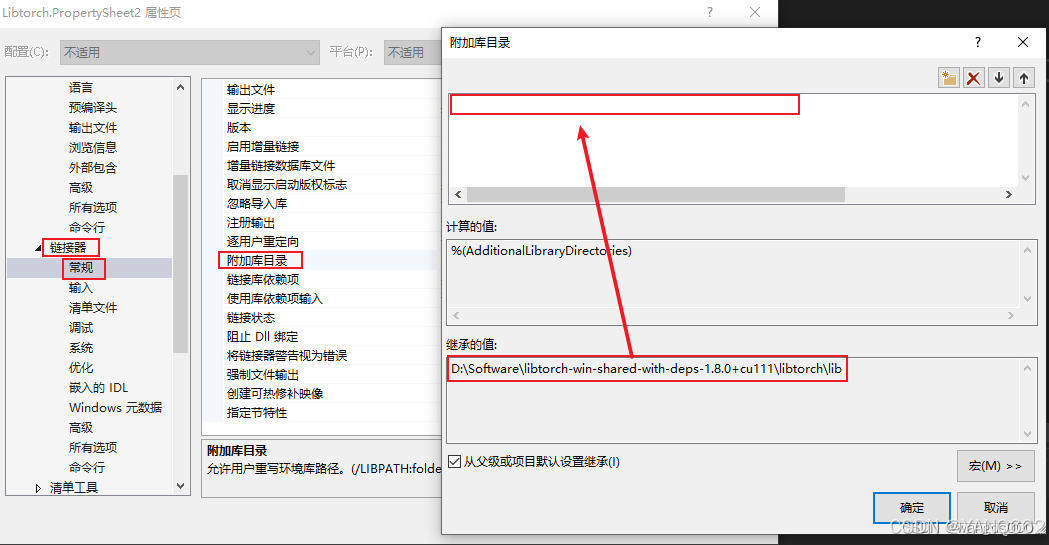
在【附加依赖项】中添加D:\libtorch-win-shared-with-deps-1.8.0+cu111\libtorch\lib文件夹下所有的 *.lib文件。
asmjit.lib
c10.lib
c10d.lib
c10_cuda.lib
caffe2_detectron_ops_gpu.lib
caffe2_module_test_dynamic.lib
caffe2_nvrtc.lib
clog.lib
cpuinfo.lib
dnnl.lib
fbgemm.lib
fbjni.lib
gloo.lib
gloo_cuda.lib
libprotobuf-lite.lib
libprotobuf.lib
libprotoc.lib
mkldnn.lib
pthreadpool.lib
pytorch_jni.lib
torch.lib
torch_cpu.lib
torch_cuda.lib
XNNPACK.lib完成上述配置后,在计算机【环境变量–系统变量】中添加
E:\Environmentc\libtorch\lib
E:\Environmentc\libtorch\bin
此外,libtorc加载GPU模型时,还需在打开工程项目属性页配置CUDA命令行:
/INCLUDE:"?ignore_this_library_placeholder@@YAHXZ"
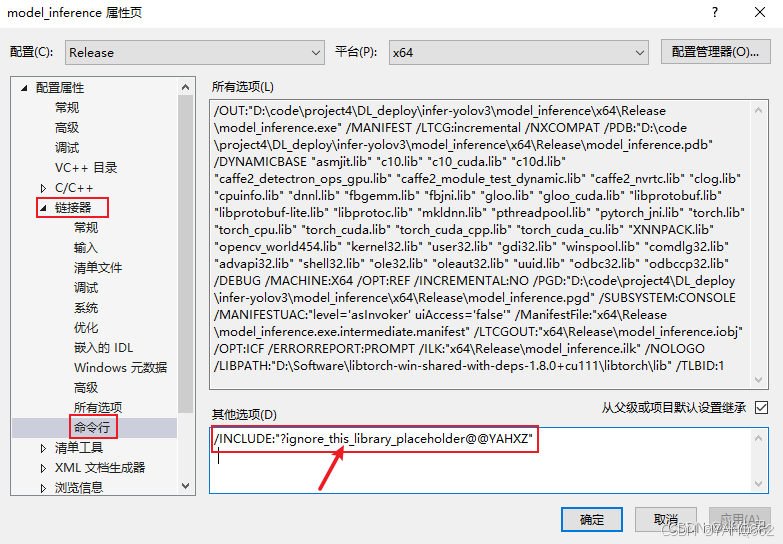
此时完成所有配置。测试代码如下:
#include <torch/torch.h>
//#include <cuda.h>
//#include <cuda_runtime.h>
//#include "device_launch_parameters.h"
#include <iostream>
int main() {
torch::Tensor tensor = torch::rand({ 2, 3 });
if (torch::cuda::is_available()) {
std::cout << "CUDA is available! Training on GPU" << std::endl;
/*int devCount;
cudaGetDeviceCount(&devCount);
std::cout << devCount << std::endl;*/
auto tensor_cuda = tensor.cuda();
std::cout << tensor_cuda << std::endl;
}
else
{
std::cout << "CUDA is not available! Training on CPU" << std::endl;
std::cout << tensor << std::endl;
}
std::cin.get();
}若出现由于找不到c10.dll(或其他libtorch/lib中的.dll动态库),无法继续执行代码的报错,则作以下修改:
在属性界面的 调试=>环境 里添加libtorch动态库的路径:
PATH=D:\Code_Lib\libtorch\lib;%PATH%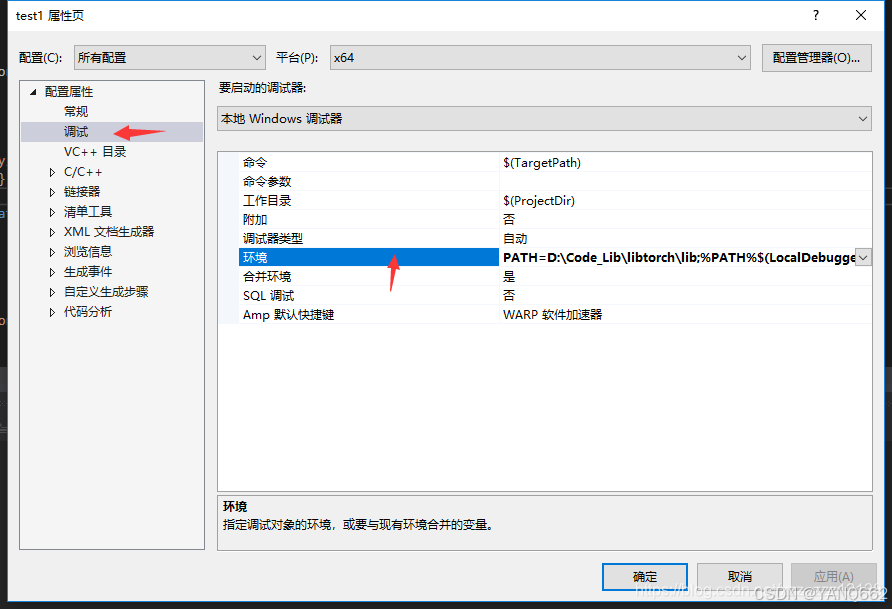
至此,torch配置完成。
二、配置cuda
该内容看了Windows10+VisualStudio2022+CUDA11.7环境配置_vs配置cuda-CSDN博客的博客,作为笔记用,本人搭建后可以运行。
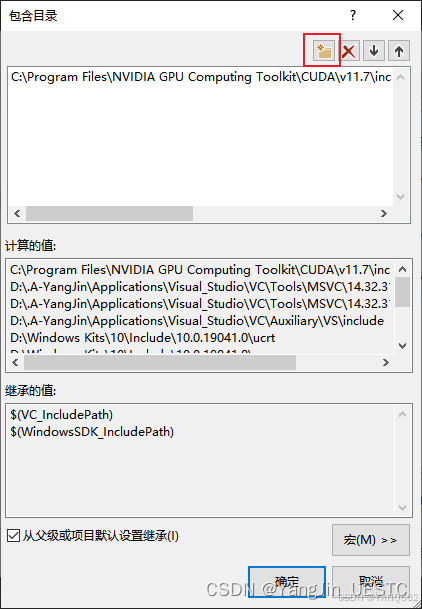
右键项目→属性→ 配置属性→ VC++目录→ 包含目录,添加以下目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\include
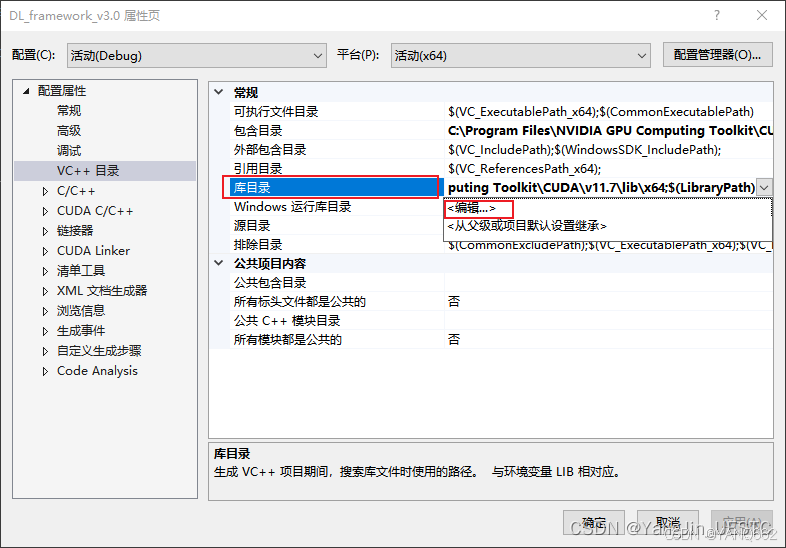
→ 库目录,添加以下目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib\x64
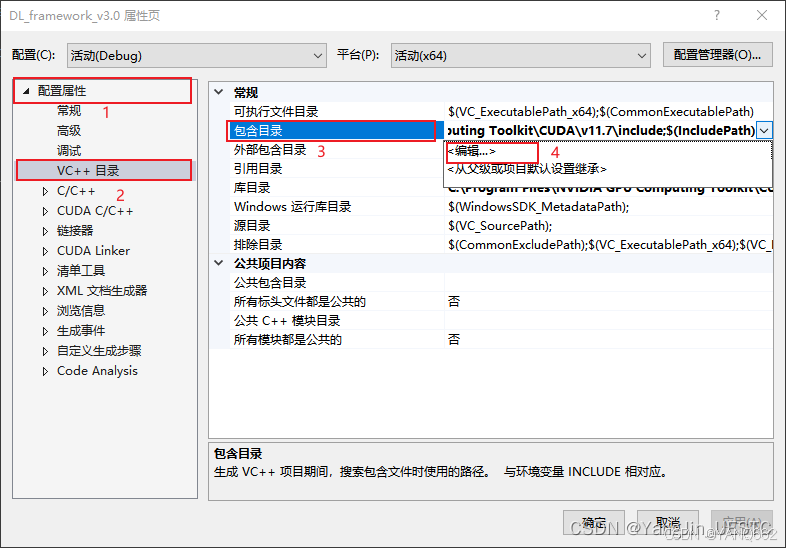
右键项目→ 属性→ 配置属性→ 链接器→ 常规→ 附加库目录,添加以下目录:
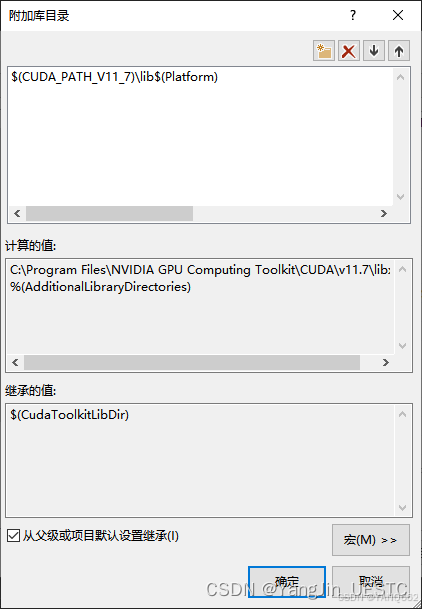
\$(CUDA_PATH_V11_7)\lib$(Platform)(查看环境变量改变CUDA_PATH_V11_7,v11_7指的安装的cuda版本)
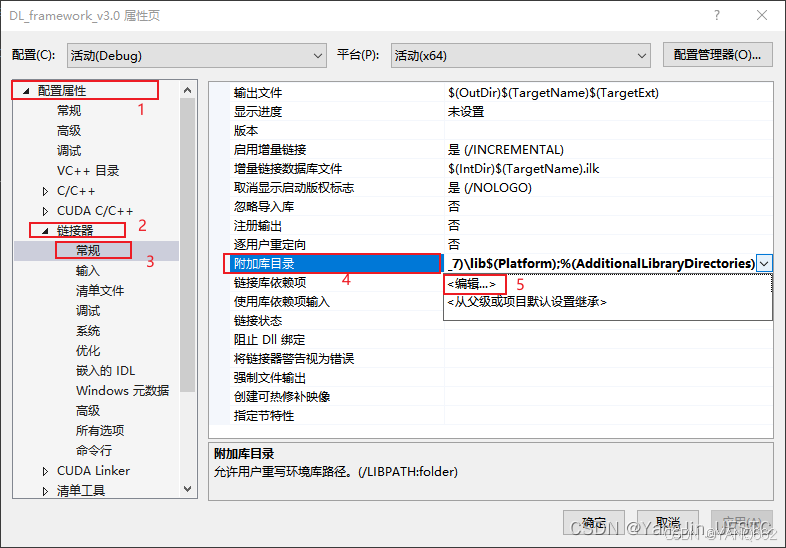
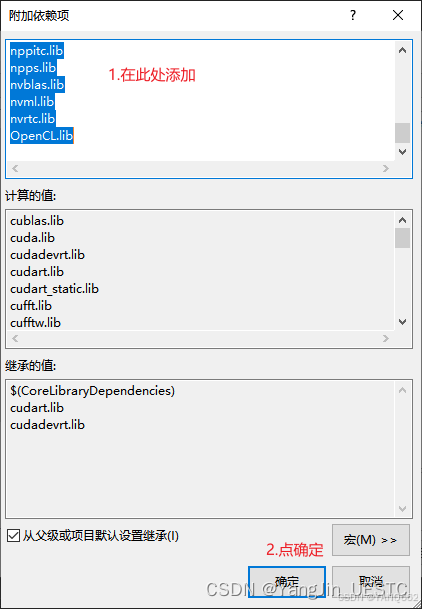
右键项目→ 属性→ 配置属性→ 链接器→ 输入→ 附加依赖项,添加以下库:
cublas.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cufft.lib
cufftw.lib
curand.lib
cusolver.lib
cusparse.lib
nppc.lib
nppial.lib
nppicc.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvml.lib
nvrtc.lib
OpenCL.lib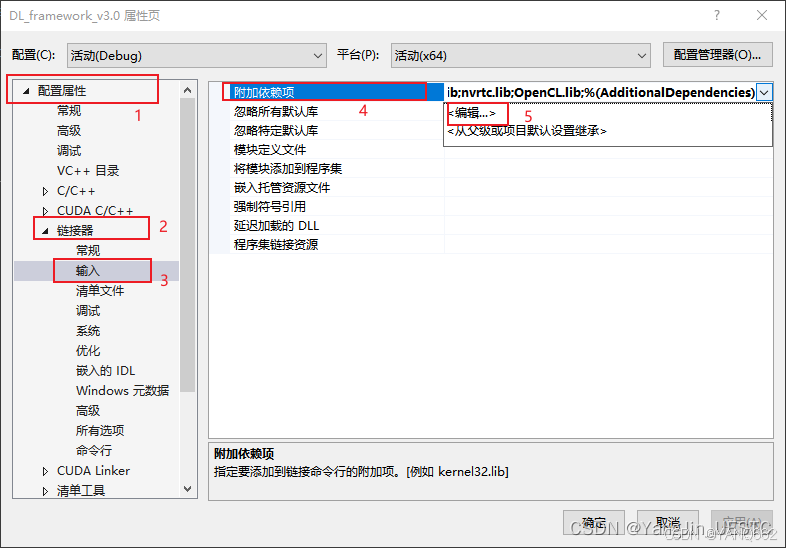
测试程序如下:
#include <iostream>
#include <cuda_runtime.h>
#include <cublas_v2.h>
const int N = 3; // 矩阵大小
int main() {
// 初始化CUBLAS库
cublasHandle_t handle;
cublasCreate(&handle);
// 定义矩阵大小
int lda = N;
int ldb = N;
int ldc = N;
// 分配内存并初始化矩阵
float A[N * N] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
float B[N * N] = { 9, 8, 7, 6, 5, 4, 3, 2, 1 };
float C[N * N] = { 0 };
// 在GPU上分配内存并将矩阵传输到GPU
float* d_A, * d_B, * d_C;
cudaMalloc((void**)&d_A, N * N * sizeof(float));
cudaMalloc((void**)&d_B, N * N * sizeof(float));
cudaMalloc((void**)&d_C, N * N * sizeof(float));
cudaMemcpy(d_A, A, N * N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, N * N * sizeof(float), cudaMemcpyHostToDevice);
// 执行矩阵相乘
float alpha = 1.0f;
float beta = 0.0f;
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N, &alpha, d_A, lda, d_B, ldb, &beta, d_C, ldc);
// 将结果从GPU传回CPU
cudaMemcpy(C, d_C, N * N * sizeof(float), cudaMemcpyDeviceToHost);
// 打印结果
std::cout << "Matrix C:" << std::endl;
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
std::cout << C[i * N + j] << " ";
}
std::cout << std::endl;
}
// 清理内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// 销毁CUBLAS句柄
cublasDestroy(handle);
return 0;
}至此,cuda环境安装完成。



















