专家混合(MoE)大语言模型:免费的嵌入模型新宠
今天,我们深入探讨一种备受瞩目的架构——专家混合(Mixture-of-Experts,MoE)大语言模型,它在嵌入模型领域展现出了独特的魅力。
一、MoE 架构揭秘
(一)MoE 是什么?
MoE 是一种包含多个被称为“专家”子网的架构,每个子网专注于不同的数据任务或方面。其优势显著,在保持甚至提升模型质量的同时,能够以比相同或更大规模的传统模型更少的计算量进行预训练。例如,Mixtral 8x7B 在众多评估数据集上就超越了 LLaMA 2 70B。
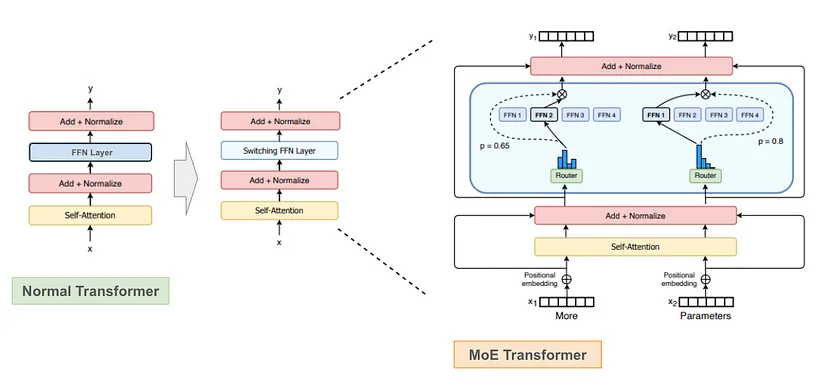
在基于变压器的 MoE 架构中,主要有两个关键组件。一是 MoE 层,它取代了变压器架构中的前馈网络(FFN)层。每个 MoE 层包含若干专家(如上图示例中有 4 个专家),每个专家由简单的 FFN 层构成。需要注意的是,变压器的其他组件,如自注意力层,在不同专家间共享相同权重,这使得 MoE 的权重数量并非简单的累加。像 Mixtral 8x7B 的权重并非 8x7 = 56B,而是 47B,原因就在于此。
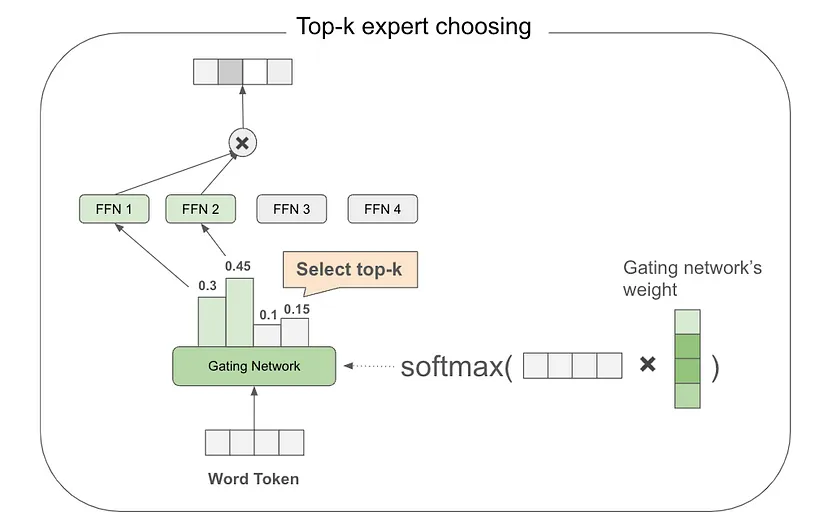
另一个重要组件是门控网络(gating network)或路由器(router)。它负责接收输入令牌,并为每个令牌选择最相关的专家。比如,在示例中,路由器左侧会选择第二个专家来处理“more”令牌,而对于“Parameters”令牌则选择第一个专家。通常,门控网络会选择与给定令牌最相关的 top - k 个专家,并将令牌发送给选定的专家(如 Mixtral 8x7B 选择 top - 2 专家)。
其选择过程是通过将输入单词令牌与门控网络权重进行点积运算,再应用 softmax 函数来计算专家的重要概率,从而依据概率选取 top - k 相关专家。具有这种门控网络的 MoE 被称为稀疏 MoE。
(二)MoE 如何作为嵌入模型工作?
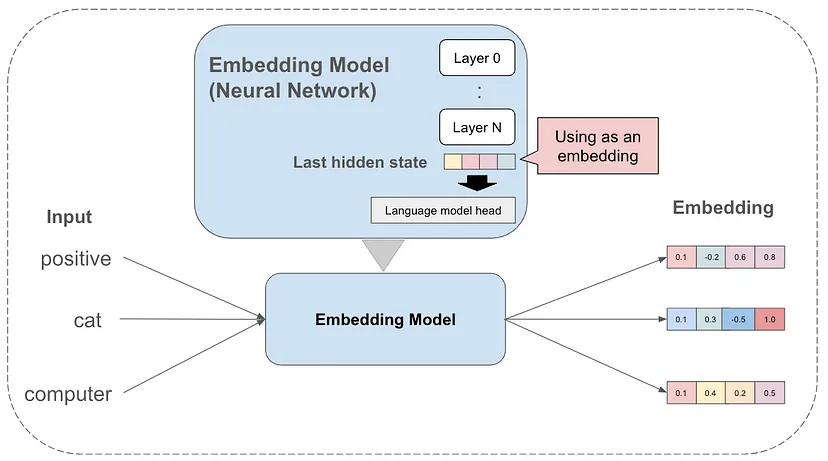
在深入探讨 MoE 作为嵌入模型的工作原理之前,先来回顾一下嵌入(embeddings)的相关知识。在深度学习模型中,嵌入是输入数据的内部表示,蕴含语义和浓缩的数据信息。通常,我们会提取神经网络的最后隐藏状态作为嵌入。一般而言,基于编码器的模型在提取嵌入方面表现出色,因为它们能够通过双向注意力捕捉语义,而仅解码器模型常使用因果注意力,只能与前一个单词令牌交互,无法像编码器 - 解码器模型那样捕获丰富的语义(如上下文信息)。
以往人们普遍认为解码器模型不能用于嵌入提取,但研究发现 MoE 中的路由权重为解码器嵌入提供了补充信息。MoE 每层的路由权重反映了对输入令牌的推理选择,包含了隐藏状态嵌入可能丢失的输入语义信息。从数学公式上看,如公式 (g) 为 softmax 函数,(H) 表示隐藏状态,我们通过连接所有 MoE 层的路由权重来避免丢失模型的推理选择。
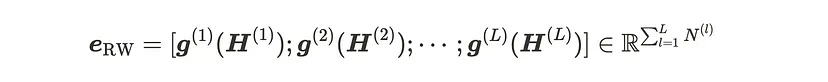
为了充分利用路由权重和解码器嵌入,研究者提出了 MoE 嵌入(MoEE)方法以形成更全面的嵌入表示。MoEE 主要有两种类型:
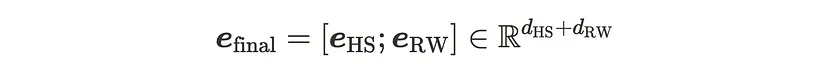
- 基于连接的组合(MoEE(concat)):此方法较为简单,直接将路由权重和解码器嵌入进行连接,如公式所示。它能够保留每个路由权重捕获的独特信息,同时使下游任务能够利用组合后的表示。
- 加权和集成(MoEE(sum)):该方法对由路由权重和隐藏状态(HS)嵌入计算出的相似度分数进行加权求和,记为 MoEE(sum)。其中,(\alpha) 是一个超参数,用于控制路由权重的贡献。在计算每对的相似度分数后,还需计算其与真实相似度之间的等级相关性(如 Spearman 等级相关性)。这种方法适用于比较两个句子的任务,如语义文本相似度任务。

在实际应用中,MoEE(concat) 较为易用。并且,研究者还利用 PromptEOL 技术来增强 MoEE。PromptEOL 技术通过提示特定模板来约束大语言模型预测下一个令牌中的语义信息,如在嵌入任务中使用的特定提示。从性能表现来看,MoEE 结合 PromptEOL 能够比有监督和自监督方法取得更好的效果。虽然其在排行榜上并非最新的最优结果,但它的价值在于无需进一步训练就能在嵌入任务中获得不错的结果。

二、MoEE 与 BERTopic 的实践应用
在这部分,我们将展示如何从预训练的 MoE 大语言模型中提取嵌入,并结合 BERTopic 使用 20 - news - group 数据集进行主题聚类。
(一)环境准备
我们采用 Python 3.10 的 conda 环境,在 Ubuntu 20.04 系统上进行实验,显卡配置为 cuda 12.4,16 GB VRAM。需要注意的是,下载模型权重可能需要 32 GB 内存。具体的环境搭建命令如下:
conda create -n moee python=3.10 -y
conda activate moee
pip install transformers torch bitsandbytes bertopic accelerate
由于 MoE 模型通常需要较高的 VRAM,我们需要使用 bitsandbytes 这个量化包来节省 VRAM 内存。同时,还需克隆官方 GitHub 仓库:
git clone https://github.com/tianyi-lab/MoE-Embedding.git
(二)利用 MoEE 进行主题聚类
这里我们以 OLMoE - 1B - 7B 模型为例,它在 16 GB VRAM 上运行推理较为可行。首先加载模型:
kwargs = {
"base_model": 'allenai/OLMoE-1B-7B-0924',
"normalized": False,
"torch_dtype": torch.bfloat16,
"mode": "embedding",
"pooling_method": "mean",
"attn_implementation": "sdpa",
"attn": "bbcc"
}
config = {
'embed_method': 'prompteol',
'emb_info': 'MoEE'
}
embedding_model = MOEE(model_name_or_path='allenai/OLMoE-1B-7B-0924', **kwargs)
接着,计算 20 - news - group 数据集的嵌入并传递给 BERTopic:
from sklearn.datasets import fetch_20newsgroups
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
dataset = MyDataset(docs)
dataloader = DataLoader(dataset=dataset, batch_size=8)
embeddings = None
for batch in tqdm(dataloader):
with torch.no_grad():
embedding = embedding_model.encode(batch, **config)
if embeddings is None:
embeddings = embedding[0]
else:
embeddings = np.vstack((embeddings, embedding[0]))
torch.cuda.empty_cache()
在计算嵌入时,我们使用 torch.utils.data.DataLoader 作为迭代器,并对每个批次的文档进行编码。需要注意的是,传递给 BERTopic 的嵌入必须是 np.asarray 类型。
如果要使用自己的 MoE 模型,需要实现从每个 MoE 层获取路由权重的功能,而对于隐藏状态嵌入,则可以利用 HuggingFace 变压器函数,在推理时只需传递 output_hidden_states=True 参数即可。
完成嵌入计算后,就可以运行主题建模了:
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine')
hdbscan_model = HDBSCAN(min_cluster_size=15, metric='euclidean', cluster_selection_method='eom', prediction_data=True)
vectorizer_model = CountVectorizer(stop_words="english")
ctfidf_model = ClassTfidfTransformer()
representation_model = KeyBERTInspired()
topic_model = BERTopic(
embedding_model=embedding_model,
umap_model=umap_model,
hdbscan_model=hdbscan_model,
vectorizer_model=vectorizer_model,
ctfidf_model=ctfidf_model,
representation_model=representation_model
)
topics, probs = topic_model.fit_transform(docs, embeddings)
通过默认设置,我们得到了 42 个主题,从随机抽取的样本来看,能够很好地捕捉语义。同时,通过主题聚类可视化,我们可以清晰地看到不同主题之间的关联,如红色圆圈标记的主题 0 与计算机相关,其附近的主题也与机械相关词汇(如图形、数字、打印机等)有关。

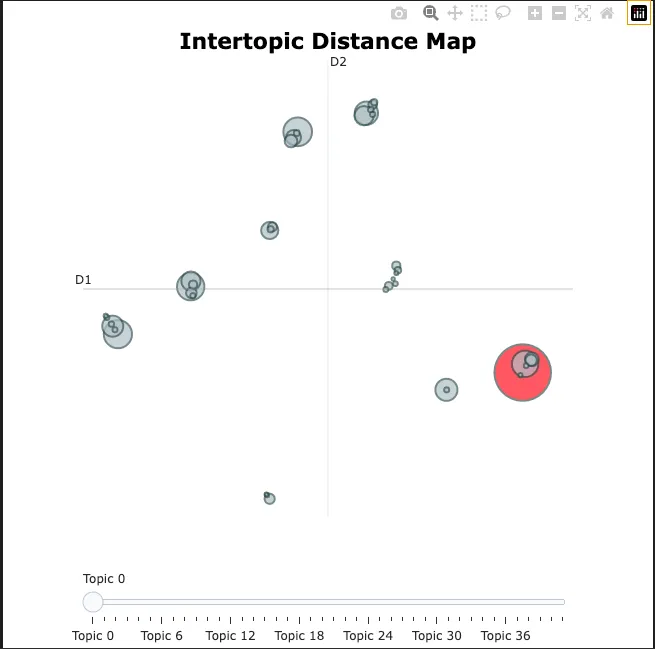
这种方法表明,我们无需额外训练就能获得不错的嵌入效果。尽管与当前最优的有监督模型相比,在质量上还有提升空间,但这一研究成果无疑为无训练的嵌入提取方法的进一步改进迈出了重要一步。
以上就是今天的全部内容,如果您对人工智能技术感兴趣,欢迎关注我们的公众号,获取更多精彩内容!
[参考文献]
[1] Ziyue Li, Tianyi Zhou, YOUR MIXTURE - OF - EXPERTS LLM IS SECRETLY AN EMBEDDING MODEL FOR FREE (2024), Arxiv
[2] Omar S., et.al., Mixture of Experts Explained (2023), Hugging Face
[3] William Fedus, Barret Zoph., et.al., Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (2021), Arxiv
[4] Ting Jiang, et.al., Scaling Sentence Embeddings with Large Language Models (2023), Arxiv
本文由mdnice多平台发布



















