背景需求:
2023区级大课题《运用Python优化3-6岁幼儿学习活动材料的实践研究》需要做阶段资料
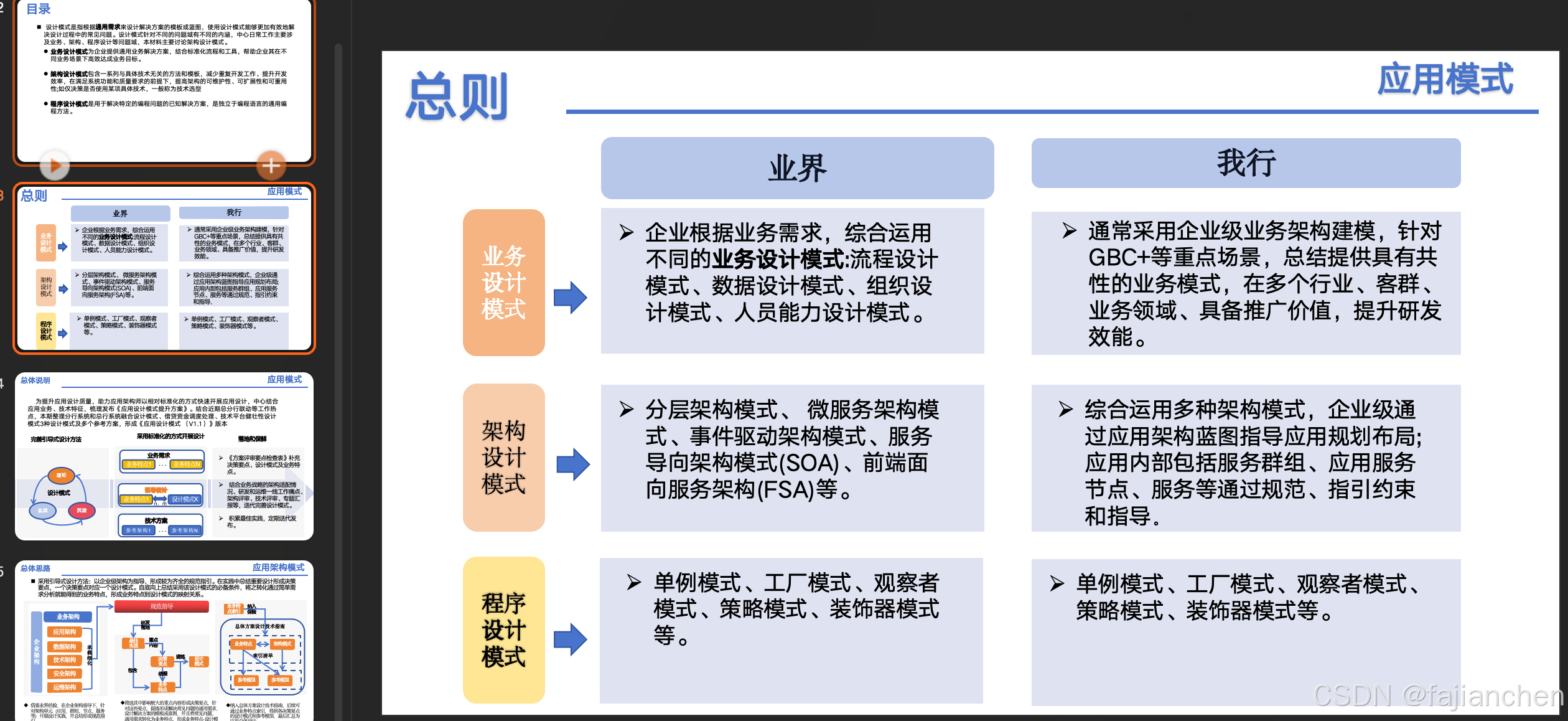
本来应该2024年6月就提交电子稿和打印稿。可是python学具的教学实验实在太多了,不断生成,我忙着做教学,都没有精力去整理。
2025年1月3日,是2024区级大课题阶段资料上交的时期,科研主任让我必须上交存档了。
于是我花了一周终于把资料贴好了(成果太多了,都不知道用那份好),提交电子稿。同时需要打印成纸稿。

存在问题:
1.需要打印的每个Word文件都在单独的文件夹里,每次打印都需要打开一个文件夹,然后打开Word,再打印,打印时要选择参数(双面打印等)

2.最后还需要把打印出来的纸稿按照顺序排列。调整正反面。这需要核对目录。也耗费时间。
解决思路
写的已经很累了,不想在打印整理上费脑子。我想做成一个PDF合并打印。直接就获取整理好顺序的纸稿。
1、把单个Word转成pdf
2、把所有pdf按照顺序合并在一个pdf内
解决方式:
1、Word都是doc文件,需要转成docx。
2、每个文件夹里的docx有1个(课题文档),或多个(一些参考资料),但只有1个docx是需要的









因此,需要将doc转docx,我希望只读取二级文件夹里我需要的那个docx。(实际最后,一级文件里所有的doc都转成docx了。不是只转换二级文件夹里的docx。)


给docx文件前面写上序号01,确保PDF也能排序(后来发现一些参考文件的doc也转pdf了,所以必须写上01序号,才能让这些PDF排列在前面,便于选择前11个pdf合并)


3、确保每个DOCX都是双数页(,这样PDF合并后,每个word的标题还是都能在奇数页上。来不及写代码了,我都是手动添加换页符)
(1)所有DOCX打开,

(2)如果是单数页,再最后一页手动按一个换页符。CTrl+Enter


(3)如果是双数页,就关闭

这样就能确保合并打印时,每个有标题的页面都在奇数页上



代码展示:
这是上学期的代码 03 第一学期,读取前11个pdf合并

import os
from docx import Document
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
from PyPDF2 import PdfFileMerger, PdfFileReader
import time
from docx2pdf import convert
import comtypes.client
# 初始化 Word 应用程序
word = comtypes.client.CreateObject('Word.Application')
word.Visible = False
# 指定包含 DOC 文件的文件夹路径
path=r"D:\课题"
m="3"
n="一"
input_folder =path+fr"\0{m} 第{n}学期"
# input_folder =path+r"04 第二学期"
# 遍历输入文件夹中的所有文件和子文件夹
for root, dirs, files in os.walk(input_folder):
for file in files:
if file.endswith('.doc'):
doc_file = os.path.join(root, file)
docx_file = os.path.join(root, f"{os.path.splitext(file)[0]}.docx")
# 打开 DOC 文件并保存为 DOCX 文件
doc = word.Documents.Open(doc_file)
doc.SaveAs(docx_file, FileFormat=16) # FileFormat=16 表示 DOCX 格式
doc.Close()
print(f"Converted {doc_file} to {docx_file}")
# 关闭 Word 应用程序
word.Quit()
import os
import time
from docx2pdf import convert
# 指定包含 DOCX 文件的文件夹路径
# input_folder = r"D:\课题\03 第一学期"
# 指定输出 PDF 文件的文件夹路径
output_folder = input_folder+r"\12 PDF合集"
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
# 遍历输入文件夹中的所有文件和子文件夹
for root, dirs, files in os.walk(input_folder):
docx_files = [file for file in files if file.endswith('.docx')]
if docx_files:
for docx_file in docx_files:
docx_file_path = os.path.join(root, docx_file)
pdf_file_name = f"{os.path.splitext(docx_file)[0]}.pdf"
pdf_file_path = os.path.join(output_folder, pdf_file_name)
convert(docx_file_path, pdf_file_path)
print(f"Converted {docx_file_path} to {pdf_file_path}")
time.sleep(3) # 给转换一些时间间隔,避免过快导致失败
# 最后把PDF合并
import os,time
from PyPDF2 import PdfMerger, PdfFileReader
# 创建一个PdfMerger对象
merger = PdfMerger()
# 获取输出文件夹中的所有PDF文件
pdf_files = [f for f in os.listdir(output_folder) if f.endswith('.pdf')]
# 遍历所有的PDF文件并合并()
for filename in pdf_files[:11]:
pdf_path = os.path.join(output_folder, filename)
with open(pdf_path, 'rb') as pdf_file:
pdf_reader = PdfFileReader(pdf_file)
merger.append(pdf_reader)
# 保存合并后的PDF文件
output_path = os.path.join(input_folder,f"0{m} 第{n}学期合并打印.pdf")
merger.write(output_path)
merger.close()
print("PDF文件合并完成!")
import shutil
shutil.rmtree(output_folder)
合并后我发现,除了我需要的二级文件夹里的docx,在一级文件夹里的docx(与二级文件夹同级,红色部分文件)也被PDF了。



所以我给每个需要的docx文件进行编号(01-11)只提取有序号的前11个PDF文件合并(文件名的数字首字排在前面,字母首字排中间,汉字首字最后)




(第一个学期的所有PDF,只提取有序号的前11个pdf合并)

提取前11个pdf合并(就是有数字序号的11个)

最后效果

--------------题外话---------------
我发现括号排在数字前面,但是合并前11个文档时,并没有这个括号首字的文件。
那么数字、字母、汉字和符号怎么排序呢?

以下这篇文章提到了一些排法。
https://www.zhihu.com/question/20227012/answer/2584107682![]() https://www.zhihu.com/question/20227012/answer/2584107682
https://www.zhihu.com/question/20227012/answer/2584107682
符号首字的确在数字首字前面。但是为什么最后没有被算成第一个PDF文件?

后续再研究看看怎么回事
--------------------------------------------------------------------------------------------
(第二学期的所有PDF,提取有序号的前10个pdf合并,没有申请书了。所以少一个)


提取前10个PDF合并(有数字序号的)


打印情况
桌面文件

第一学期PDF

108页。正反54张(01的申请书不用打印,实际打印86张)


第二学期PDF102页。正反51张


打印和作品展示:
彩色双面打印机(不用翻页真的好方便)






 拖了很久的任务终于完成了,大大松口气!(* ̄︶ ̄)
拖了很久的任务终于完成了,大大松口气!(* ̄︶ ̄)