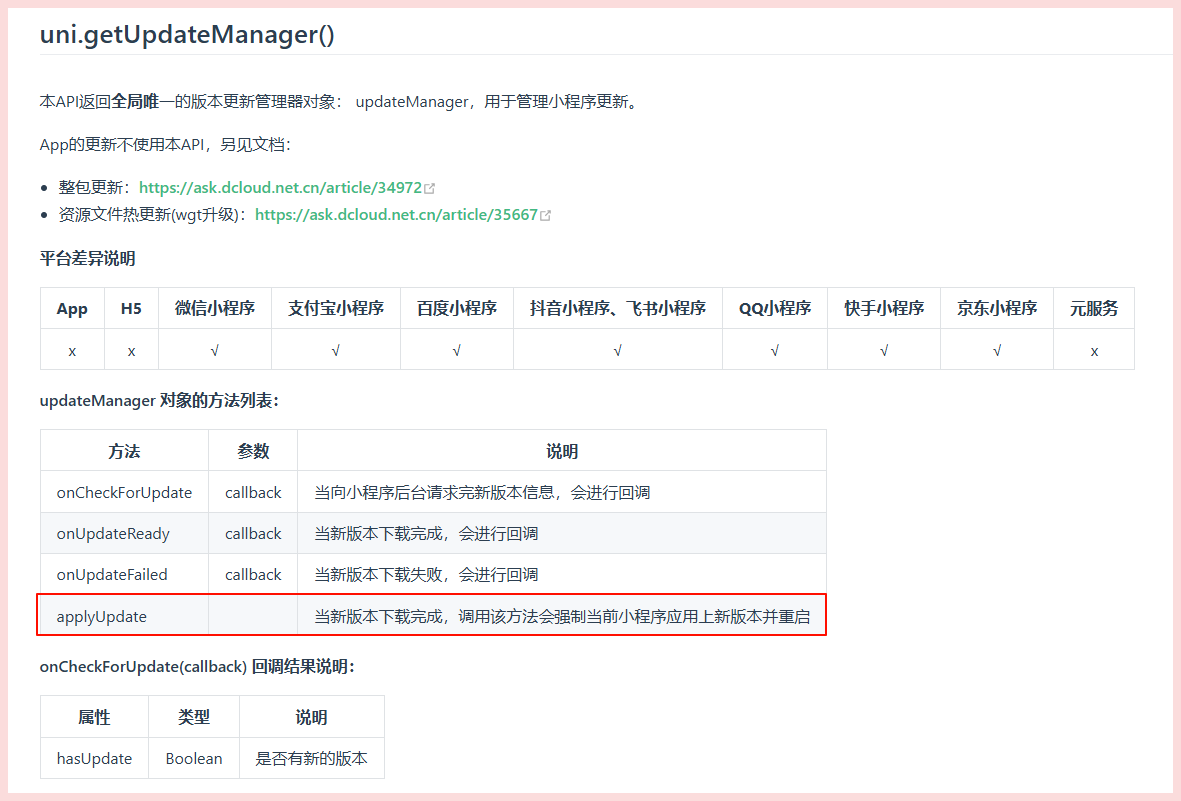
今天在看pytorch源码,遇到的问题,记录一下 。
source:/lib/python3.10/site-packages/torch/amp/grad_scaler.py
torch._amp_update_scale_(
_scale,
_growth_tracker,
found_inf_combined,
self._growth_factor,
self._backoff_factor,
self._growth_interval,
)
这段python代码是如何调用底层的cpp代码的
Tensor& _amp_update_scale_cuda_(Tensor& current_scale,
Tensor& growth_tracker,
const Tensor& found_inf,
double growth_factor,
double backoff_factor,
int64_t growth_interval) {
TORCH_CHECK(growth_tracker.is_cuda(), "growth_tracker must be a CUDA tensor.");
TORCH_CHECK(current_scale.is_cuda(), "current_scale must be a CUDA tensor.");
TORCH_CHECK(found_inf.is_cuda(), "found_inf must be a CUDA tensor.");
// 核函数调用
amp_update_scale_cuda_kernel<<<1, 1, 0, at::cuda::getCurrentCUDAStream()>>>(
current_scale.mutable_data_ptr<float>(),
growth_tracker.mutable_data_ptr<int>(),
found_inf.const_data_ptr<float>(),
growth_factor,
backoff_factor,
growth_interval);
C10_CUDA_KERNEL_LAUNCH_CHECK();
return current_scale;
}
source: https://github.com/pytorch/pytorch/blob/0431d47eaaaceadab0c0f2400e186c02ef66d96c/aten/src/ATen/native/cuda/AmpKernels.cu#L222
在 PyTorch 框架中,Python 和底层 C++/CUDA 实现之间通过 PyTorch ATen 底层 API 和 PyBind11来完成。torch._amp_update_scale_ 是一个 Python 函数,它实际上通过 PyTorch 的 C++扩展机制 调用底层 C++ 实现(_amp_update_scale_cuda_)。以下是调用流程的完整解读:
1. Python 调用 C++ 的机制
torch._amp_update_scale_ 是一个绑定在 PyTorch ATen C++核心函数上的 Python 接口。其调用流程如下:
-
Python 调用
torch._amp_update_scale_函数:- Python 参数
_scale,_growth_tracker, 和found_inf_combined是torch.Tensor对象。 - 这些对象在 Python 中使用,但底层通过
PyObject引用 C++ 的at::Tensor对象(ATen 核心张量)。
- Python 参数
-
通过绑定跳转到 C++ 函数
_amp_update_scale_cuda_:torch._amp_update_scale_被注册到一个 dispatcher(分发器),它会根据运行设备(CPU 或 GPU)选择合适的后端实现。- 在 GPU 上运行时,分发器会调用底层 CUDA 实现
_amp_update_scale_cuda_。
2. Python 到 C++ 的具体流程
-
ATen 和 PyTorch 的 Operator 注册系统:
PyTorch 使用torch::RegisterOperators注册 C++ 函数_amp_update_scale_cuda_,并将其绑定到 Python 的torch._amp_update_scale_。注册流程示例:
TORCH_LIBRARY_IMPL(aten, CUDA, m) { m.impl("_amp_update_scale_", &_amp_update_scale_cuda_); }TORCH_LIBRARY_IMPL用于将 CUDA 实现_amp_update_scale_cuda_注册到 ATen。- Python 代码调用
torch._amp_update_scale_时,会被自动映射到 C++ 实现_amp_update_scale_cuda_。
-
Python 的 Tensor 转换为 C++ 的 at::Tensor:
当torch._amp_update_scale_被调用时,Python 中的Tensor对象通过 PyBind11 自动转换为对应的at::Tensor对象。例如:torch._amp_update_scale_( _scale, # Python Tensor -> at::Tensor _growth_tracker, # Python Tensor -> at::Tensor found_inf_combined, # Python Tensor -> at::Tensor self._growth_factor, # Python float -> C++ double self._backoff_factor, # Python float -> C++ double self._growth_interval # Python int -> C++ int64_t ) -
调用 C++ 函数
_amp_update_scale_cuda_:- 参数从 Python 传递到
_amp_update_scale_cuda_,对应current_scale,growth_tracker,found_inf等。 - 在 C++ 中,
_amp_update_scale_cuda_函数会调用底层 CUDA 核心函数amp_update_scale_cuda_kernel,执行缩放更新逻辑。
- 参数从 Python 传递到
3. C++ 到 CUDA 核心函数的调用流程
在 _amp_update_scale_cuda_ 中,C++ 调用 CUDA 核心代码的主要流程是:
-
参数检查:
使用TORCH_CHECK确保current_scale,growth_tracker, 和found_inf都是 CUDA 张量:TORCH_CHECK(growth_tracker.is_cuda(), "growth_tracker must be a CUDA tensor."); TORCH_CHECK(current_scale.is_cuda(), "current_scale must be a CUDA tensor."); TORCH_CHECK(found_inf.is_cuda(), "found_inf must be a CUDA tensor."); -
启动 CUDA 核函数:
使用 CUDA 的核函数调用机制<<<...>>>启动 CUDA 内核函数:amp_update_scale_cuda_kernel<<<1, 1, 0, at::cuda::getCurrentCUDAStream()>>>( current_scale.mutable_data_ptr<float>(), // 当前缩放因子的指针 growth_tracker.mutable_data_ptr<int>(), // 成功步数计数器的指针 found_inf.const_data_ptr<float>(), // 梯度溢出的标志 growth_factor, // 增长因子 backoff_factor, // 回退因子 growth_interval // 增长间隔 );调用过程:
- CUDA 核函数
amp_update_scale_cuda_kernel被调度到当前 GPU 的流(at::cuda::getCurrentCUDAStream())。 - 各个张量(如
current_scale,growth_tracker)通过.data_ptr<T>()方法获取指针,传递给 CUDA 核函数。
- CUDA 核函数
-
CUDA 核函数执行:
核函数amp_update_scale_cuda_kernel在 GPU 上执行,完成缩放因子的动态调整。逻辑详见问题中的 CUDA 实现。 -
内核启动检查:
启动内核后,通过C10_CUDA_KERNEL_LAUNCH_CHECK()检查 CUDA 内核是否成功运行。C10_CUDA_KERNEL_LAUNCH_CHECK();
4. 总结调用链路
完整调用链如下:
-
Python 层:
torch._amp_update_scale_( _scale, _growth_tracker, found_inf_combined, self._growth_factor, self._backoff_factor, self._growth_interval )- Python 张量(
torch.Tensor)通过 PyBind11 转换为 C++ 张量(at::Tensor)。
- Python 张量(
-
C++ 层:
Tensor& _amp_update_scale_cuda_( Tensor& current_scale, Tensor& growth_tracker, const Tensor& found_inf, double growth_factor, double backoff_factor, int64_t growth_interval ) { // 调用 CUDA 核函数 amp_update_scale_cuda_kernel<<<1, 1, 0, at::cuda::getCurrentCUDAStream()>>>( current_scale.mutable_data_ptr<float>(), growth_tracker.mutable_data_ptr<int>(), found_inf.const_data_ptr<float>(), growth_factor, backoff_factor, growth_interval ); C10_CUDA_KERNEL_LAUNCH_CHECK(); return current_scale; } -
CUDA 层:
// amp_update_scale_cuda_kernel is launched with a single thread to compute the new scale.
// The scale factor is maintained and updated on the GPU to avoid synchronization.
__global__ void amp_update_scale_cuda_kernel(float* current_scale,
int* growth_tracker,
const float* found_inf,
double growth_factor,
double backoff_factor,
int growth_interval)
{
// 核函数逻辑:根据是否溢出动态调整 current_scale 和 growth_tracker
if (*found_inf) {
*current_scale = (*current_scale)*backoff_factor;
*growth_tracker = 0;
} else {
// Entering this branch means we just carried out a successful step,
// so growth_tracker is incremented before comparing to growth_interval.
auto successful = (*growth_tracker) + 1;
if (successful == growth_interval) {
auto new_scale = static_cast<float>((*current_scale)*growth_factor);
// Do not grow the scale past fp32 bounds to inf.
if (isfinite_ensure_cuda_math(new_scale)) {
*current_scale = new_scale;
}
*growth_tracker = 0;
} else {
*growth_tracker = successful;
}
}
}
5. 补充说明
这种从 Python 到 C++ 再到 CUDA 的调用链是 PyTorch 的通用设计模式:
- Python API 层:提供高层易用接口。
- C++ ATen 层:实现设备无关的核心逻辑。
- CUDA 内核层:实现高性能的设备特定操作。
后记
2025年1月2日15点22分于上海, 在GPT4o大模型辅助下完成。