大模型WebUI:Gradio全解系列8——Additional Features:补充特性(上)
- 前言
- 本篇摘要
- 8. Additional Features:补充特性
- 8.1 队列
- 8.1.1 使用方法
- 8.1.2 配置队列演示
- 8.2 输入输出流
- 8.2.1 输出流
- 1. 生成器yield
- 2. 流媒体
- 8.2.2 输入流
- 1. 流事件
- 2. 图像滤镜
- 8.2.3 统一的输入输出流
- 8.2.4 跟踪过去的输入或输出
- 8.3 提示及进度条
- 8.3.1 提示
- 8.3.2 进度条
- 8.4 批处理函数
- 8.4.1 Interface与Blocks演示
- 8.4.2 diffusers库与批处理
- 参考文献
前言
本系列文章主要介绍WEB界面工具Gradio。Gradio是Hugging Face发布的简易webui开发框架,它基于FastAPI和svelte,便于部署人工智能模型,是当前热门的非常易于开发和展示机器学习大语言模型LLM及扩散模型DM的UI框架。本系列文章分为前置概念和实战演练两部分。前置概念先介绍Gradio的详细技术架构、历史、应用场景、与其他框架Gradio/NiceGui/StreamLit/Dash/PyWebIO的区别,然后详细介绍了大模型及数据的资源网站Hugging Face,包括三种资源models/datasets/spaces、六类开源库transformers/diffusers/datasets/PEFT/accelerate/optimum实战。实战演练部分先讲解了多种不同的安装、运行和部署方式,安装包括Linux/Win/Mac三类系统安装,运行包括普通方式和热重载方式,部署包括本地部署、HuggingFace托管、FastAPI挂载和Gradio-Lite浏览器集成;然后按照先整体再细节的逻辑,讲解Gradio的多种高级特性:三种Gradio Clients(python/javascript/curl)、Gradio Tools、Gradio的模块架构和环境变量等,方便读者对Gradio整体把握;最后深入细节,也是本系列文章的核心,先实践基础功能Interface、Blocks和Additional Features,再详解高级功能Chatbots、Data Science And Plots和Streaming。本系列文章注解详细,代码均可运行并附有大量运行截图,方便读者理解,Gradio一定会成为每个技术人员实现奇思妙想的最称手工具。
本系列文章目录如下:
- 《Gradio全解系列1——Gradio简介》
- 《Gradio全解系列1——Gradio的安装与运行》
- 《Gradio全解系列2——Gradio的3+1种部署方式实践》
- 《Gradio全解系列2——浏览器集成Gradio-Lite》
- 《Gradio全解系列3——Gradio Client:python客户端》
- 《Gradio全解系列3——Gradio Client:javascript客户端》
- 《Gradio全解系列3——Gradio Client:curl客户端》
- 《Gradio全解系列4——Gradio Tools:将Gradio用于LLM Agents》
- 《Gradio全解系列5——Gradio库的模块架构和环境变量》
- 《Gradio全解系列6——Interface:高级抽象界面类(上)》
- 《Gradio全解系列6——Interface:高级抽象界面类(下)》
- 《Gradio全解系列7——Blocks:底层区块类(上)》
- 《Gradio全解系列7——Blocks:底层区块类(下)》
- 《Gradio全解系列8——Additional Features:补充特性(上)》
- 《Gradio全解系列8——Additional Features:补充特性(下)》
- 《Gradio全解系列9——Chatbots:聊天机器人(上)》
- 《Gradio全解系列9——Chatbots:聊天机器人(下)》
- 《Gradio全解系列10——Data Science And Plots:数据科学与绘图》
- 《Gradio全解系列11——Streaming:数据流(上)》
- 《Gradio全解系列11——Streaming:数据流(下)》
本篇摘要
本篇介绍Gradio的其它附加功能,这些功能辅助Interface/Blocks实现更绚丽效果和更多功能。本章附加功能主要包括队列、输入输出流、提示及进度条、批处理函数、安全访问文件和资源清理,下面逐一讲述。
8. Additional Features:补充特性
本篇介绍Gradio的其它附加功能,这些功能辅助Interface/Blocks实现更绚丽效果和更多功能。本章附加功能主要包括队列、输入输出流、提示及进度条、批处理函数、安全访问文件和资源清理,下面逐一讲述。
8.1 队列
每个Gradio程序提供了一个内置的队列系统,可以处理数千个并发用户。由于许多事件监听器可能涉及繁重的处理任务,Gradio 会自动为每个事件监听器创建一个队列来处理后端的事件,因此每个事件监听器都会自动拥有一个队列来处理传入的事件。
8.1.1 使用方法
如果函数推理时间较长(比如目标检测),或者应用程序处理流量过大,则需要使用queue方法进行排队。queue方法使用websockets,可以防止网络超时,通过启用队列,可以控制用户在队列中的位置。
队列使用方式如下:
demo = gr.Interface(...).queue()
demo.launch()
#或
with gr.Blocks() as demo:
#...
demo.queue()
demo.launch()
以Blocks为例,演示如下:
with gr.Blocks() as demo:
button = gr.Button(label="Generate Image")
button.click(fn=image_generator, inputs=gr.Textbox(), outputs=gr.Image())
demo.queue(max_size=10)
demo.launch()
8.1.2 配置队列演示
每个事件监听器默认都有自己的队列,一次处理一个请求,但可以通过事件监听器的两个参数进行配置:
- concurrency_limit:设置事件监听器的最大并发执行数。默认情况下限制为 1,除非在 Blocks.queue() 中的参数default_concurrency_limit另行配置。你也可以将其设置为None以表示无限制(即无限数量的并发执行);
- concurrency_id:允许事件监听器通过分配相同的ID来共享队列。当使用共享队列管理多个事件监听器时,使用concurrency_id指定队列,例如如果你的设置中只有2个GPU,但多个函数需要访问GPU访问,此时可以为所有这些函数创建一个共享队列。
两个参数的设置示例如下:
import gradio as gr
with gr.Blocks() as demo:
prompt = gr.Textbox()
image = gr.Image()
generate_btn_1 = gr.Button("Generate Image via model 1")
generate_btn_2 = gr.Button("Generate Image via model 2")
generate_btn_3 = gr.Button("Generate Image via model 3")
generate_btn_1.click(image_gen_1, prompt, image, concurrency_limit=2, concurrency_id="gpu_queue")
generate_btn_2.click(image_gen_2, prompt, image, concurrency_id="gpu_queue")
generate_btn_3.click(image_gen_3, prompt, image, concurrency_id="gpu_queue")
在这个例子中,所有三个事件监听器共享一个标识为 “gpu_queue” 的队列。该队列最多可以同时处理 2 个并发请求,额外的请求将被排队,直到有可用的槽位。这些配置易于Gradio管理队列行为。注意事项:
- 要确保事件监听器的并发无限制,可以将 concurrency_limit设置为None,这在用户函数调用外部 API(该API自行处理请求的速率限制)时非常有用。
- 所有队列的默认并发限制可以使用Blocks.queue()中的default_concurrency_limit参数全局设置。
8.2 输入输出流
对于图像、音频、视频等文件,需要用流进行操作,本节通过讲述输出流、输入流、统一的输入输出流以及跟踪流等,让大家掌握如何处理多媒体文件。
8.2.1 输出流
在某些情况下,我们需要流式输出一系列结果,而不是一次性显示单个输出。例如,某个图像生成模型希望显示每一步生成的图像,直到最终图像生成;或者某个聊天机器人,它逐词流式输出响应,而不是一次性返回所有内容。在这种情况下,可以向Gradio提供一个生成器函数。
1. 生成器yield
在Python中创建生成器非常简单:通常yield语句会放在某种循环中,该函数不是返回单个值,而是生成一系列值。可以像提供常规函数一样向Gradio提供生成器。
例如,以下是一个模拟的图像生成模型,它在输出图像之前生成若干步噪声,使用gr.Interface类进行演示:
import gradio as gr
import numpy as np
import time
def fake_diffusion(steps):
rng = np.random.default_rng()
for i in range(steps):
time.sleep(1)
image = rng.random(size=(600, 600, 3))
yield image
image = np.ones((1000,1000,3), np.uint8)
image[:] = [255, 124, 0]
yield image
demo = gr.Interface(fake_diffusion,
inputs=gr.Slider(1, 10, 3, step=1),
outputs="image")
demo.launch()
运行截图如下:

请注意,我们在迭代器中添加了 time.sleep(1),它在步骤之间创建一个人为的暂停,这样就能够观察到迭代器的每一步。但在真实的图像生成模型中,这可能是不必要的。
Gradio同样可以处理输入流,例如,每当用户在文本框中输入一个字母时,图像生成模型都会重新运行。这在关于构建响应式界面的中有更详细的介绍,请参考Interface章节中关于实时Interface的讲解。
2. 流媒体
Gradio可以直接从生成器函数中流式输出音频和视频,这让用户几乎在函数生成音频或视频的同时就能听到或看到。实现流式媒体只需执行以下操作:
- 在 gr.Audio 或 gr.Video 输出组件中设置 streaming=True,图像自动转换为 base64 格式;
- 编写一个 Python 生成器,生成下一个音频或视频的“chunk”块;
- 设置 autoplay=True,以便媒体自动开始播放。
对于音频,下一个“块”可以是 .mp3 或 .wav 文件,也可以是音频的字节序列。对于视频,下一个“块”必须是 .mp4 文件或使用 h.264 编解码器且扩展名为 .ts 的文件。为了确保流畅播放,请确保每个块的长度一致且大于 1 秒。
我们将通过一些简单的示例来说明这些要点,以音频为例:
import gradio as gr
from time import sleep
def keep_repeating(audio_file):
for _ in range(10):
sleep(0.5)
yield audio_file
gr.Interface(keep_repeating,
gr.Audio(sources=["microphone"], type="filepath"),
gr.Audio(streaming=True, autoplay=True)
).launch()
运行后点击submit,输出与输入同步播放,截图如下:

同样也可以视频为例,只需将gr.Audio替换为gr.Video即可:gr.Video(sources=["webcam"], format="mp4"),设置也一样,不再重复。关于流的端到端演示请参考后续的数据流章节。
8.2.2 输入流
在上一小节中,我们介绍了如何从事件处理程序中流式输出一系列结果。Gradio还可以将用户摄像头中的图像或麦克风中的音频块流式输入到事件处理程序中,这可以用于创建实时对象检测应用程序或使用Gradio构建对话式聊天应用。
1. 流事件
目前,gr.Image 和 gr.Audio 组件支持通过 stream 事件实现输入流。比如创建一个最简单的流式应用程序,直接返回未修改的网络摄像头流:
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
input_img = gr.Image(label="Input", sources="webcam")
with gr.Column():
output_img = gr.Image(label="Output")
input_img.stream(lambda s: s, input_img, output_img, time_limit=15, stream_every=0.1, concurrency_limit=30)
if __name__ == "__main__":
demo.launch()
运行截图如下:

可以自己运行看一下效果。当用户开始录制时,stream 事件会被触发。底层逻辑是网络摄像头每 0.1 秒拍摄一张照片并将其发送到服务器,然后服务器会返回该图像。
stream 事件有两个独特的关键字参数:
- time_limit:这是 Gradio 服务器处理事件的时间限制。多媒体流本质上是无限制的,因此设置时间限制非常重要,以防止一个用户长期占用 Gradio 队列。时间限制仅计算处理流所花费的时间,不包括在队列中等待的时间。输入图像底部显示的橙色条表示剩余时间。当时间限制到期时,用户将自动重新加入队列。
- stream_every:这是流捕获输入并将其发送到服务器的频率(以秒为单位)。对于图像检测或处理等演示,设置较小的值可以实现“real-time”实时效果。对于语音转录等演示,较高的值更有用,因为可以使转录算法可以更好地理解上下文。
2. 图像滤镜
本节创建一个图像滤镜演示,用户可以选择多种应用于网络摄像头输入流的滤镜,滤镜种类包括边缘检测滤镜、卡通滤镜,或者简单地垂直翻转流滤镜。代码如下:
import gradio as gr
import numpy as np
import cv2
def transform_cv2(frame, transform):
if transform == "cartoon":
# prepare color
img_color = cv2.pyrDown(cv2.pyrDown(frame))
for _ in range(6):
img_color = cv2.bilateralFilter(img_color, 9, 9, 7)
img_color = cv2.pyrUp(cv2.pyrUp(img_color))
# prepare edges
img_edges = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
img_edges = cv2.adaptiveThreshold(
cv2.medianBlur(img_edges, 7),
255,
cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY,
9,
2,
)
img_edges = cv2.cvtColor(img_edges, cv2.COLOR_GRAY2RGB)
# combine color and edges
img = cv2.bitwise_and(img_color, img_edges)
return img
elif transform == "edges":
# perform edge detection
img = cv2.cvtColor(cv2.Canny(frame, 100, 200), cv2.COLOR_GRAY2BGR)
return img
else:
return np.flipud(frame)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
transform = gr.Dropdown(choices=["cartoon", "edges", "flip"],
value="flip", label="Transformation")
input_img = gr.Image(sources=["webcam"], type="numpy")
with gr.Column():
output_img = gr.Image(streaming=True)
dep = input_img.stream(transform_cv2, [input_img, transform], [output_img],
time_limit=30, stream_every=0.1, concurrency_limit=30)
demo.launch()
运行后选择边缘检测滤镜,截图如下:
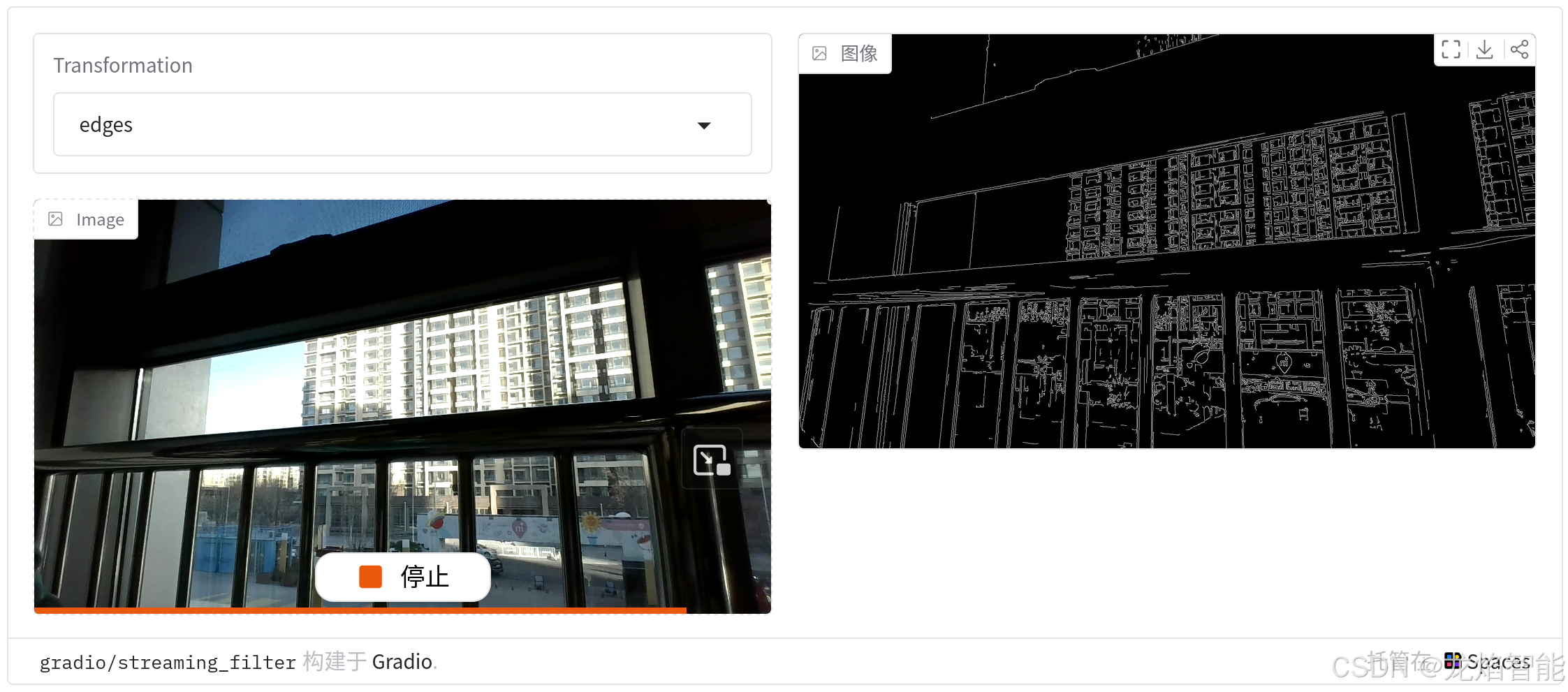
需要注意的是:
- 当更改滤镜值时,它会立即在输出流中生效。这是流事件与其他 Gradio 事件的一个重要区别:在处理流的过程中,可以更改流相关的输入值并立即生效。
- 我们将图像输出组件的 streaming 参数设置为True,这样可以让服务器自动将输出图像转换为 base64 格式,这是一种适合流高效传输的格式。
8.2.3 统一的输入输出流
对于一些图像流式传输演示(如上面的示例),我们不需要分别显示输入和输出组件,只显示修改后的输出流,应用程序看起来会更简洁。
我们可以通过将输入图像组件指定为流事件的输出来实现这一点,省略重复代码,另外加入一些CSS格式,核心代码如下:
css=""".my-group {max-width: 500px !important; max-height: 500px !important;}
.my-column {display: flex !important; justify-content: center !important; align-items: center !important};"""
with gr.Blocks(css=css) as demo:
with gr.Column(elem_classes=["my-column"]):
with gr.Group(elem_classes=["my-group"]):
transform = gr.Dropdown(choices=["cartoon", "edges", "flip"],
value="flip", label="Transformation")
input_img = gr.Image(sources=["webcam"], type="numpy", streaming=True)
input_img.stream(transform_cv2, [input_img, transform], [input_img], time_limit=30, stream_every=0.1)
demo.launch()
运行截图如下:

8.2.4 跟踪过去的输入或输出
通常流式函数应该是无状态的,它应该接受当前输入并返回相应的输出。然而在某些情况下,可能希望跟踪过去的输入或输出。例如可能希望在缓冲区保留前 k 个输入,以提高音频转录演示的准确性。可以使用 Gradio 的 gr.State()组件来实现这一点,示例如下:
def transcribe_handler(current_audio, state, transcript):
next_text = transcribe(current_audio, history=state)
state.append(current_audio)
# 保留前3个输入
state = state[-3:]
return state, transcript + next_text
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
mic = gr.Audio(sources="microphone")
state = gr.State(value=[])
with gr.Column():
transcript = gr.Textbox(label="Transcript")
mic.stream(transcribe_handler, [mic, state, transcript], [state, transcript],
time_limit=10, stream_every=1)
demo.launch()
8.3 提示及进度条
当程序运行出现状况时,如何告知用户,以及让用户知道等待时间,这就用到提示和进度条。
8.3.1 提示
提示组件分为三类:gr.Error()、 gr.Warning() 和gr.Info() 。我们希望向用户显示提示错误信息,为此可以在函数中抛出 gr.Error(“自定义消息”) ,这时函数停止执行并向用户显示错误信息。
我们还可以通过在函数中单独使用 gr.Warning(“自定义消息”) 或 gr.Info(“自定义消息”) 来立即显示模态框,同时继续执行函数。gr.Info() 和 gr.Warning() 之间的唯一区别是提示框的颜色。演示如下:
import gradio as gr
from functools import partial
with gr.Blocks() as demo:
with gr.Row():
duration = gr.Number(label="Duration", info="Set to -1 for infinite", value=10, minimum=-1)
with gr.Row():
error = gr.Button("Error")
info = gr.Button("Info")
warning = gr.Button("Warning")
def display_message(type, msg, duration):
duration = None if duration < 0 else duration
if type == "error":
raise gr.Error(msg, duration=duration)
elif type == "info":
gr.Info(msg, duration=duration)
elif type == "warning":
gr.Warning(msg, duration=duration)
error.click(partial(display_message, "error", "ERROR 💥"), [duration])
info.click(partial(display_message, "info", "INFO ℹ️"), [duration])
warning.click(partial(display_message, "warning", "WARNING ⚠️"), [duration])
运行结果如下:

提示:请注意gr.Error()是一个必须引发的异常,而gr.Warning()和gr.Info()可以让函数继续运行。
8.3.2 进度条
Gradio 支持创建自定义进度条,可以自定义和控制进度更新,以便向用户展示。要启用此功能,只需在方法中添加一个参数,该参数的默认值为 gr.Progress 实例;然后通过直接调用此实例并传入一个介于 0 和 1 之间的浮点数来更新进度,或者使用 Progress 实例的 tqdm() 方法来跟踪可迭代对象的进度,演示如下:
import gradio as gr
import time
def slowly_reverse(word, progress=gr.Progress()):
progress(0, desc="Starting")
time.sleep(1)
progress(0.05)
new_string = ""
for letter in progress.tqdm(word, desc="Reversing"):
time.sleep(0.25)
new_string = letter + new_string
return new_string
demo = gr.Interface(slowly_reverse, gr.Text(), gr.Text())
demo.launch()
运行截图如下:

如果使用 tqdm 库,甚至可以通过将gr.Progress()的参数track_tqdm设置为True,自动从任意函数中已存在的 tqdm.tqdm 报告进度更新!
8.4 批处理函数
Gradio 支持传入批处理函数,批处理函数是指接收输入列表并返回预测列表的函数。使用批处理函数的优势在于:如果启用了队列,Gradio服务器将传入的请求进行自动批处理和并行处理,从而可能加快演示执行速度。
8.4.1 Interface与Blocks演示
例如,下面演示是一个批处理函数,它接收两个输入列表(一个单词列表和一个整数列表),并返回一个修剪后的单词列表作为输出:
import gradio as gr
import time
def trim_words(words, lens):
trimmed_words = []
time.sleep(5)
for w, l in zip(words, lens):
trimmed_words.append(w[:int(l)])
return [trimmed_words]
以下是 Gradio 代码示例(注意 batch=True 和 max_batch_size=16),使用gr.Interface:
gr.Interface(fn=image_classifier, inputs="image", outputs="label")
demo = gr.Interface(
fn=trim_words,
inputs=["textbox", "number"],
outputs=["label"],
batch=True,
max_batch_size=16
)
demo.launch()
运行界面如下:

使用gr.Blocks:
with gr.Blocks() as demo:
with gr.Row():
word = gr.Textbox(label="word")
leng = gr.Number(label="leng")
output = gr.Textbox(label="Output")
with gr.Row():
run = gr.Button()
event = run.click(trim_words, [word, leng], output, batch=True, max_batch_size=16)
demo.launch()

在上面的示例中,可以并行处理 16 个请求(总推理时间为 5 秒),而不是每个请求单独处理(总推理时间为 80 秒)。
8.4.2 diffusers库与批处理
Hugging Face 的库 transformers 和 diffusers 中许多模型与 Gradio 的批处理模式可以非常自然地配合使用,比如下面是一个使用 diffusers 批量生成图像的示例演示:
import torch
from diffusers import DiffusionPipeline # type: ignore
import gradio as gr
generator = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
# move to GPU if available
if torch.cuda.is_available():
generator = generator.to("cuda")
def generate(prompts):
images = generator(list(prompts)).images # type: ignore
return [images]
demo = gr.Interface(generate,
"textbox",
"image",
batch=True,
max_batch_size=4 # Set the batch size based on your CPU/GPU memory
)
if __name__ == "__main__":
demo.launch()
此处由于版本问题和引入库torch,可能出现错误提示,我们主要从代码理解批处理的使用方法即可,是否运行成功不必强求。
参考文献
- Gradio - guides - Additional Features



















