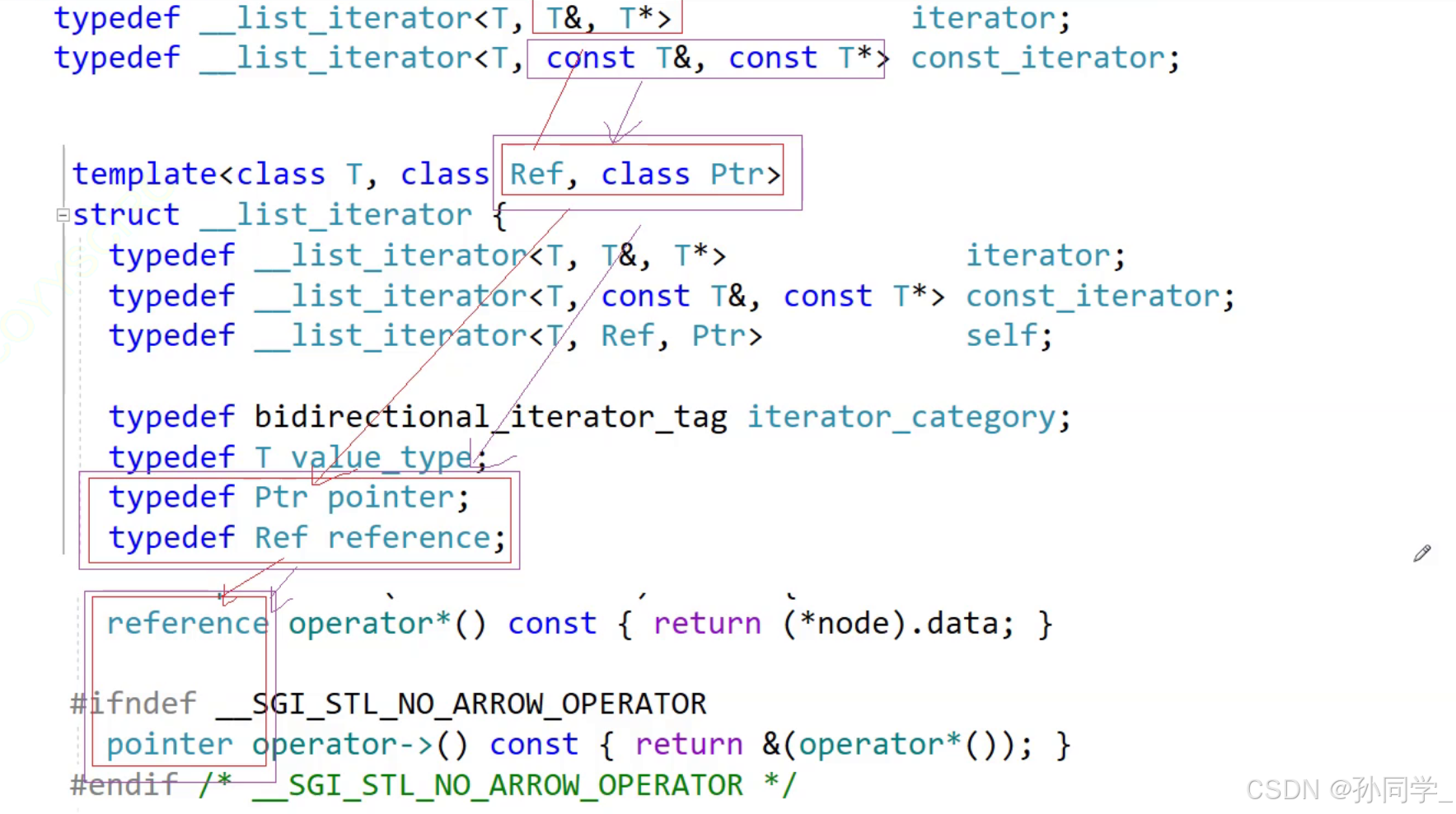
决策树的生成与剪枝
- 决策树的生成
- 生成决策树的过程
- 决策树的生成算法
- 决策树的剪枝
- 决策树的损失函数
- 决策树的剪枝算法
- 代码
决策树的生成
生成决策树的过程
为了方便分析描述,我们对上节课中的训练样本进行编号,每个样本加一个ID值,如图所示:

从根结点开始生成决策树,先将上述训练样本(1-9)全部放在根节点中。
然后选择信息增益或信息增益比最大的特征向下分裂,按照所选特征取值的不同将训练样本分发到不同的子结点中。
例如所选特征有3个取值,则分裂出3个子结点,然后在子结点中重复上述过程,直到所有特征的信息增益(比)很小或者没有特征可选为止,完成决策树的构建,如下图所示:

图中的决策树共有2个内部结点和3个叶子结点,每个结点旁边的编号代表训练样本的 ID 值。内部结点代表样本的特征,叶子结点代表样本的预测类别,我们将叶子节点中训练样本占比最大的类作为决策树的预测标记。
在使用构建好的决策树在测试数据上分类时,只需要从根节点开始依次测试内部结点代表的特征即可得到测试样本的预测分类。
决策树的生成算法
下面我们先来总结一下 ID3分类决策树的生成算法:
输入:训练数据集 D 、特征集合 A 的信息增益阈值 ;输出:决策树 T
-
若 D 中的训练样本属于同一类,则 T 为单结点树,返回 D 中任意样本的类别。
-
若 A 中的特征为空,则 T 为单结点树,返回 D 中数量最多的类别。
-
使用信息增益在 A 中进行特征选择,若所选特征 A_i 的信息增益小于设定的阈值,则 T 为单结点树,返回 D 中数量最多的类别。
-
否则根据 A_i 的每一个取值,将 D 分成若干子集 D_i,将 D_i 中数量最多的类作为标记值,构建子结点,返回 T。
-
以 D_i 为训练集,{A - A_i} 为特征集,递归地调用上述步骤,得到子树 T_i,返回 T。
使用 C4.5 算法进行决策树的生成只需要将信息增益改成信息增益比即可。
决策树的剪枝
决策树的损失函数
决策树的叶子节点越多,模型越复杂。决策树的损失函数考虑了模型复杂度,我们可以通过优化其损失函数来对决策树进行剪枝。决策树的损失函数计算过程如下:
-
计算叶子结点 t 的样本类别经验熵

对于叶子结点 t 来说,其样本类别的经验熵越小, t 中训练样本的分类误差就越小。当叶子结点 t 中的训练样本为同一类别时,经验熵为零,分类误差为零。 -
计算决策树 T 在所有训练样本上的损失之和 C(T)

对于叶子结点 t 中的每一个训练样本,其类别标记都是随机变量 Y 的一个取值,这个取值的不确定性用信息熵来衡量,且可以用经验熵来估计。由上文可知,经验熵在一定程度上可以反映决策树在该样本上的预测损失,累加所有叶子结点上的训练样本损失即上图中的计算公式。 -
计算考虑模型复杂度的的决策树损失函数

决策树的叶子结点个数表示模型的复杂度,通过最小化上面的损失函数,一方面可以减少模型在训练样本上的预测误差,另一方面可以控制模型的复杂度,保证模型的泛化能力。
决策树的剪枝算法
-
计算决策树中每个结点的样本类别经验熵:

如上图所示,对于本课示例中的决策树,需要计算 5 个结点的经验熵。 -
遍历非叶子结点,剪枝相当于去除其子结点,自身变为叶子结点:

对于图中的非叶子结点(有工作?),剪枝后变为叶子结点,并通过多数表决的方法确定其类别标记。
以上就是这节课的所有内容了,实际上还有一种决策树算法:分类与回归树(classification and regression tree,简称 CART),它既可以用于分类也可以用于回归,同样包含了特征选择、决策树的生成与剪枝算法。
关于 CART 算法的内容,我们将在最后一章 XGBoost 中进行学习,下面请你来做一道关于信息增益比的题目,顺便回顾一下前面所学的知识
代码
## 1. 创建数据集
import pandas as pd
data = [['yes', 'no', '青年', '同意贷款'],
['yes', 'no', '青年', '同意贷款'],
['yes', 'yes', '中年', '同意贷款'],
['no', 'no', '中年', '不同意贷款'],
['no', 'no', '青年', '不同意贷款'],
['no', 'no', '青年', '不同意贷款'],
['no', 'no', '中年', '不同意贷款'],
['no', 'no', '中年', '不同意贷款'],
['no', 'yes', '中年', '同意贷款']]
# 转为 dataframe 格式
df = pd.DataFrame(data)
# 设置列名
df.columns = ['有房?', '有工作?', '年龄', '类别']
## 2. 经验熵的实现
from math import log2
from collections import Counter
def H(y):
'''
y: 随机变量 y 的一组观测值,例如:[1,1,0,0,0]
'''
# 随机变量 y 取值的概率估计值
probs = [n/len(y) for n in Counter(y).values()]
# 经验熵:根据概率值计算信息量的数学期望
return sum([-p*log2(p) for p in probs])
## 3. 经验条件熵的实现
def cond_H(a):
'''
a: 根据某个特征的取值分组后的 y 的观测值,例如:
[[1,1,1,0],
[0,0,1,1]]
每一行表示特征 A=a_i 对应的样本子集
'''
# 计算样本总数
sample_num = sum([len(y) for y in a])
# 返回条件概率分布的熵对特征的数学期望
return sum([(len(y)/sample_num)*H(y) for y in a])
## 4. 特征选择函数
def feature_select(df,feats,label):
'''
df:训练集数据,dataframe 类型
feats:候选特征集
label:df 中的样本标记名,字符串类型
'''
# 最佳的特征与对应的信息增益比
best_feat,gainR_max = None,-1
# 遍历每个特征
for feat in feats:
# 按照特征的取值对样本进行分组,并取分组后的样本标记数组
group = df.groupby(feat)[label].apply(lambda x:x.tolist()).tolist()
# 计算该特征的信息增益:经验熵-经验条件熵
gain = H(df[label].values) - cond_H(group)
# 计算该特征的信息增益比
gainR = gain / H(df[feat].values)
# 更新最大信息增益比和对应的特征
if gainR > gainR_max:
best_feat,gainR_max = feat,gainR
return best_feat,gainR_max
## 5. 决策树的生成函数
import pickle
def creat_tree(df,feats,label):
'''
df:训练集数据,dataframe 类型
feats:候选特征集,字符串列表
label:df 中的样本标记名,字符串类型
'''
# 当前候选的特征列表
feat_list = feats.copy()
# 若当前训练数据的样本标记值只有一种
if df[label].nunique()==1:
# 将数据中的任意样本标记返回,这里取第一个样本的标记值
return df[label].values[0]
# 若候选的特征列表为空时
if len(feat_list)==0:
# 返回当前数据样本标记中的众数,各类样本标记持平时取第一个
return df[label].mode()[0]
# 在候选特征集中进行特征选择
feat,gain = feature_select(df,feat_list,label)
# 若选择的特征信息增益太小,小于阈值 0.1
if gain<0.1:
# 返回当前数据样本标记中的众数
return df[label].mode()[0]
# 根据所选特征构建决策树,使用字典存储
tree = {feat:{}}
# 根据特征取值对训练样本进行分组
g = df.groupby(feat)
# 用过的特征要移除
feat_list.remove(feat)
# 遍历特征的每个取值 i
for i in g.groups:
# 获取分组数据,使用剩下的候选特征集创建子树
tree[feat][i] = creat_tree(g.get_group(i),feat_list,label)
# 存储决策树
pickle.dump(tree,open('tree.model','wb'))
return tree
# 6. 决策树的预测函数
def predict(tree,feats,x):
'''
tree:决策树,字典结构
feats:特征集合,字符串列表
x:测试样本特征向量,与 feats 对应
'''
# 获取决策树的根结点:对应样本特征
root = next(iter(tree))
# 获取该特征在测试样本 x 中的索引
i = feats.index(root)
# 遍历根结点分裂出的每条边:对应特征取值
for edge in tree[root]:
# 若测试样本的特征取值=当前边代表的特征取值
if x[i]==edge:
# 获取当前边指向的子结点
child = tree[root][edge]
# 若子结点是字典结构,说明是一颗子树
if type(child)==dict:
# 将测试样本划分到子树中,继续预测
return predict(child,feats,x)
# 否则子结点就是叶子节点
else:
# 返回叶子节点代表的样本预测值
return child
## 7. 在样例数据上测试
# 获取特征名列表
feats = list(df.columns[:-1])
# 获取标记名
label = df.columns[-1]
# 创建决策树(此处使用信息增益比进行特征选择)
T = creat_tree(df,feats,label)
# 计算训练集上的预测结果
preds = [predict(T,feats,x) for x in df[feats].values]
# 计算准确率
acc = sum([int(i) for i in (df[label].values==preds)])/len(preds)
# 输出决策树和准确率
print(T,acc)












![[面试题]--索引用了什么数据结构?有什么特点?](https://i-blog.csdnimg.cn/direct/97e24e97a4ac47e8a7936cdf1d5ceec4.gif#pic_center)