提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、功能说明
- 二、使用步骤
- 1.controller
- 2.工具类 DocumentUtil
- 导出样式
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、功能说明
将要导出的文件已动态方式进行下载

二、使用步骤
1.controller
代码如下(示例):
@ApiOperation("导出维权word模板")
@GetMapping("/export/{id}")
public ResponseEntity<byte[]> exportWord(@PathVariable("id") Long id) throws IOException {
// 获取 SupervisionDocument 对象
SupervisionDocument supervisionDocument = service.getById(id);
// 创建并填充数据模型
HashMap<String, Object> dataMap = new HashMap<>();
//将base64的内容进行解码
String s = new String(Base64.getDecoder().decode(supervisionDocument.getSupervisionOrderText()));
dataMap.put("content", s);
//编号判断如果获取为空则默认空格
dataMap.put("number", supervisionDocument.getSupervisionOrderNumber());
//整改时限
dataMap.put("time", new SimpleDateFormat("yyyy年MM月dd日").format(supervisionDocument.getRectificationDeadline()));
//录入时间
dataMap.put("entryTime", new SimpleDateFormat("yyyy年MM月dd日").format(supervisionDocument.getCreatedAt()));
//录入单位
dataMap.put("entryUnit", supervisionDocument.getEntryUnit());
//被堵办单位
dataMap.put("supervisedUnit", supervisionDocument.getSupervisedUnit());
//获取附件
dataMap.put("attachment", splitUrl(supervisionDocument.getAttachments()));
if (supervisionDocument.getDocumentType().equals("1")) {
// 生成文档的字节流
ByteArrayOutputStream outputStream = DocumentUtil.generateDocAsStream(
"word/提示函.docx",
dataMap
);
// 设置文件下载的文件名
String fileName = "提示函_" + id + ".docx";
// 设置响应头确保文件下载
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_OCTET_STREAM);
headers.setContentDispositionFormData("attachment", new String(fileName.getBytes("UTF-8"), "ISO-8859-1"));
// 返回文件流内容作为响应体
return new ResponseEntity<>(outputStream.toByteArray(), headers, HttpStatus.OK);
}
2.工具类 DocumentUtil
代码如下(示例):
package com.ruoyi.common.core.utils;
import com.deepoove.poi.XWPFTemplate;
import com.openhtmltopdf.pdfboxout.PdfRendererBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.ByteArrayOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Map;
/**
* 文档处理工具类。
* <p>
* 提供生成Word和PDF文档的方法。
* </p>
* @author Administrator
*/
public class DocumentUtil {
private static final Logger logger = LoggerFactory.getLogger(DocumentUtil.class);
/**
* 生成Word文档
*
* @param templatePath 模板文件路径
* @param outputPath 输出文件路径
* @param data 数据模型
* @throws IOException 如果文档生成失败
*/
public static void generateDoc(String templatePath, String outputPath, Map<String, Object> data) throws IOException {
logger.info("开始生成Word文档,模板路径:{},输出路径:{}", templatePath, outputPath);
if (Files.exists(Paths.get(outputPath))) {
throw new IOException("文件已存在:" + outputPath);
}
XWPFTemplate template = XWPFTemplate.compile(templatePath);
try {
template.render(data);
try (FileOutputStream out = new FileOutputStream(outputPath)) {
template.write(out);
}
} catch (Exception e) {
logger.error("生成Word文档时发生错误", e);
throw new IOException("生成Word文档时发生错误:" + e.getMessage(), e);
} finally {
template.close();
}
logger.info("Word文档生成成功,输出路径:{}", outputPath);
}
/**
* 生成Word文档并返回文件流
*
* @param templatePath 模板文件路径
* @param data 数据模型
* @return 文件流
* @throws IOException 如果文档生成失败
*/
public static ByteArrayOutputStream generateDocAsStream(String templatePath, Map<String, Object> data) throws IOException {
// 从 classpath 中读取模板文件流
try (InputStream templateStream = DocumentUtil.class.getClassLoader().getResourceAsStream(templatePath)) {
if (templateStream == null) {
throw new IOException("模板文件未找到:" + templatePath);
}
// 创建 XWPFTemplate 实例并渲染数据
XWPFTemplate template = XWPFTemplate.compile(templateStream);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
try {
template.render(data); // 将数据渲染到模板
template.write(outputStream); // 将模板内容写入输出流
} catch (Exception e) {
logger.error("生成Word文档时发生错误", e);
throw new IOException("生成Word文档时发生错误:" + e.getMessage(), e);
} finally {
template.close();
}
logger.info("Word文档生成成功");
return outputStream;
}
}
/**
* 生成PDF文件
*
* @param htmlContent HTML内容
* @param outputPath 输出文件路径
* @throws IOException 如果PDF生成失败
*/
public static void generatePdf(String htmlContent, String outputPath) throws IOException {
logger.info("开始生成PDF文件,输出路径:{}", outputPath);
if (Files.exists(Paths.get(outputPath))) {
throw new IOException("文件已存在:" + outputPath);
}
try (ByteArrayOutputStream os = new ByteArrayOutputStream()) {
PdfRendererBuilder builder = new PdfRendererBuilder();
builder.useFastMode();
builder.withHtmlContent(htmlContent, null);
builder.toStream(os);
builder.run();
try (FileOutputStream fos = new FileOutputStream(outputPath)) {
fos.write(os.toByteArray());
}
} catch (Exception e) {
logger.error("生成PDF文件时发生错误", e);
throw new IOException("生成PDF文件时发生错误:" + e.getMessage(), e);
}
logger.info("PDF文件生成成功,输出路径:{}", outputPath);
}
/**
* 生成PDF文件并返回文件流
*
* @param htmlContent HTML内容
* @return 文件流
* @throws IOException 如果PDF生成失败
*/
/**
* 生成PDF文件并返回文件流
*
* @param htmlContent HTML内容
* @return 文件流
* @throws IOException 如果PDF生成失败
*/
public static ByteArrayOutputStream generatePdfAsStream(String htmlContent) throws IOException {
logger.info("开始生成PDF文件");
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
try {
PdfRendererBuilder builder = new PdfRendererBuilder();
builder.useFastMode();
// 设置中文字体路径
String fontPath = DocumentUtil.class.getClassLoader().getResource("SimSun.ttf").toExternalForm();
// 嵌入中文字体
builder.useFont(() -> DocumentUtil.class.getClassLoader().getResourceAsStream("SimSun.ttf"), "SimSun");
// 在HTML中使用该字体
htmlContent = htmlContent.replace("<head>", "<head>\n<style>@font-face { font-family: 'SimSun'; src: url('" + fontPath + "'); }</style>");
htmlContent = htmlContent.replace(" ", " ");
htmlContent = htmlContent.replace("“", "“");
htmlContent = htmlContent.replace("”", "”");
// 去除html body 里的字体样式 只去除body里的
htmlContent = htmlContent.replace("<body>", "<body style=\"font-family: 'SimSun', Arial, sans-serif;\">");
htmlContent = cleanHtmlBodyFonts(htmlContent);
builder.withHtmlContent(htmlContent, null);
builder.toStream(outputStream);
builder.run();
} catch (Exception e) {
logger.error("生成PDF文件时发生错误", e);
throw new IOException("生成PDF文件时发生错误:" + e.getMessage(), e);
}
logger.info("PDF文件生成成功");
return outputStream;
}
/**
* 生成包含复杂内容的PDF文件
*
* @param outputPath 输出文件路径
* @throws IOException 如果PDF生成失败
*/
public static void generateComplexPdf(String outputPath) throws IOException {
String htmlContent = "<!DOCTYPE html>\n" +
"<html lang=\"en\">\n" +
"<head>\n" +
" <meta charset=\"UTF-8\" />\n" +
" <style>\n" + " body {\n" +
" font-family: 'SimSun', Arial, sans-serif;\n" +
" }" +
" h1 {\n" +
" color: #333;\n" +
" }\n" +
" p {\n" +
" font-size: 14px;\n" +
" line-height: 1.5;\n" +
" }\n" +
" table {\n" +
" width: 100%;\n" +
" border-collapse: collapse;\n" +
" }\n" +
" table, th, td {\n" +
" border: 1px solid black;\n" +
" }\n" +
" th, td {\n" +
" padding: 8px;\n" +
" text-align: left;\n" +
" }\n" +
" img {\n" +
" width: 100px;\n" +
" height: auto;\n" +
" }\n" +
" </style>\n" +
" <title>Complex PDF Example</title>\n" +
"</head>\n" +
"<body>\n" +
" <h1>PDF生成示例</h1>\n" +
" <p>这是一个包含不同内容的PDF示例。</p>\n" +
" <h2>表格</h>\n" +
" <table>\n" +
" <tr>\n" +
" <th>名称</th>\n" +
" <th>年龄</th>\n" +
" <th>城市</th>\n" +
" </tr>\n" +
" <tr>\n" +
" <td>张三</td>\n" +
" <td>30</td>\n" +
" <td>北京</td>\n" +
" </tr>\n" +
" <tr>\n" +
" <td>李四</td>\n" +
" <td>25</td>\n" +
" <td>上海</td>\n" +
" </tr>\n" +
" </table>\n" +
" <h2>图像</h2>\n" +
" <img src=\"https://via.placeholder.com/100\" alt=\"示例图像\" />\n" +
"</body>\n" +
"</html>";
generatePdf(htmlContent, outputPath);
}
/**
* 生成包含复杂内容的PDF文件并返回文件流
*
* @return 文件流
* @throws IOException 如果PDF生成失败
*/
public static ByteArrayOutputStream generateComplexPdfAsStream() throws IOException {
String htmlContent = "<!DOCTYPE html>\n" +
"<html lang=\"en\">\n" +
"<head>\n" +
" <meta charset=\"UTF-8\" />\n" +
" <style>\n" + " body {\n" +
" font-family: 'SimSun', Arial, sans-serif;\n" +
" }" +
" h1 {\n" +
" color: #333;\n" +
" }\n" +
" p {\n" +
" font-size: 14px;\n" +
" line-height: 1.5;\n" +
" }\n" +
" table {\n" +
" width: 100%;\n" +
" border-collapse: collapse;\n" +
" }\n" +
" table, th, td {\n" +
" border: 1px solid black;\n" +
" }\n" +
" th, td {\n" +
" padding: 8px;\n" +
" text-align: left;\n" +
" }\n" +
" img {\n" +
" width: 100px;\n" +
" height: auto;\n" +
" }\n" +
" </style>\n" +
" <title>Complex PDF Example</title>\n" +
"</head>\n" +
"<body>\n" +
" <h1>PDF生成示例</h1>\n" +
" <p>这是一个包含不同内容的PDF示例。</p>\n" +
" <h2>表格</h2>\n" +
" <table>\n" +
" <tr>\n" +
" <th>名称</th>\n" +
" <th>年龄</th>\n" +
" <th>城市</th>\n" +
" </tr>\n" +
" <tr>\n" +
" <td>张三</td>\n" +
" <td>30</td>\n" +
" <td>北京</td>\n" +
" </tr>\n" +
" <tr>\n" +
" <td>李四</td>\n" +
" <td>25</td>\n" +
" <td>上海</td>\n" +
" </tr>\n" +
" </table>\n" +
" <h2>图像</h2>\n" +
" <img src=\"https://via.placeholder.com/100\" alt=\"示例图像\" />\n" +
"</body>\n" +
"</html>";
return generatePdfAsStream(htmlContent);
}
public static String cleanHtmlBodyFonts(String htmlContent) {
// 清除内联样式中的字体相关属性
String cleaned = htmlContent.replaceAll(
"font-family:\\s*[^;\"']+;?", "" // 清除 font-family
).replaceAll(
"style=\"\\s*\"", "" // 清除空的style属性
).replaceAll(
"<body[^>]*>", "<body style=\"font-family: 'SimSun', Arial, sans-serif;\">" // 替换body标签
);
// 清除仿宋_GB2312等特定字体类
cleaned = cleaned.replaceAll(
"font-family:\\s*[仿宋楷体]+((_GB2312)|(_GBK))?[^;\"']*;?", ""
);
return cleaned;
}
}
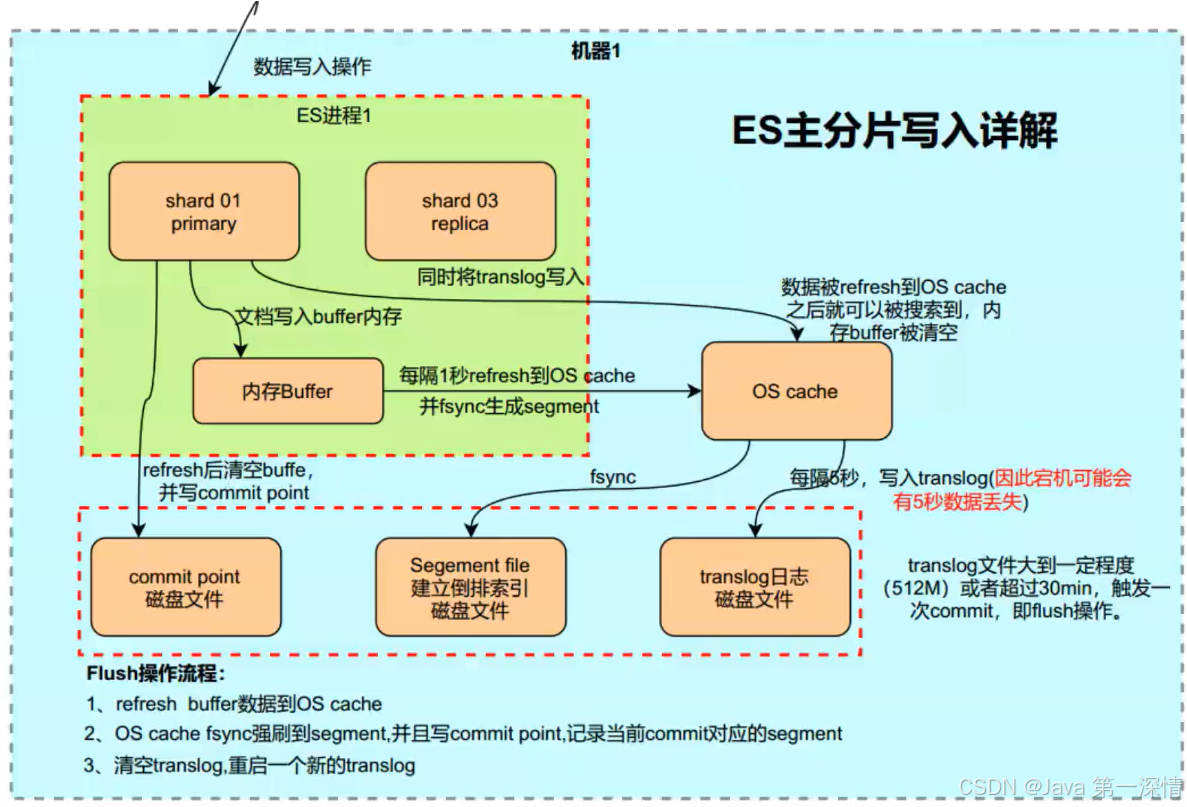
该处使用的url网络请求的数据。
导出样式