MapReduce是一种分布式计算框架,用于处理大规模数据集。其核心思想是“分而治之”,通过Map阶段将任务分解为多个简单任务并行处理,然后在Reduce阶段汇总结果。MapReduce编程模型包括Map和Reduce两个阶段,数据来源和结果存储通常在HDFS中。MapReduce编程实例中,以词频统计为例,通过Map阶段处理输入数据生成中间结果,Reduce阶段合并这些结果得到最终统计。实现步骤包括准备数据文件、创建Maven项目、添加依赖、创建日志属性文件、编写Mapper和Reducer类,以及运行驱动器类来启动作业。通过这一系列步骤,可以实现高效的大规模数据处理。

6.1 初探MapReduce
news2026/2/12 9:27:13
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2260024.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

Scripted Pipeline语法简单使用
一、JenkinsFile 语法参数 env_tools
环境工具变量的定义设置位置: “Manage Jenkins”-> “Tools”
stage(env tools) {node(test){ //定义maven java环境def mvnHome tool MAVEN_HOME_CentOS//引用环境变量,配置PATH变量env.PATH &qu…

前端退出对话框也就是点击右上角的叉,显示灰色界面,已经解决
文章目录 遇到一个前端bug,点击生成邀请码 打开对话框 然后我再点击叉号,退出对话框,虽然退出了对话框,但是显示灰色界面。如下图: 导致界面就会失效,点击任何地方都没有反应。 发现是如下代码的问题&am…
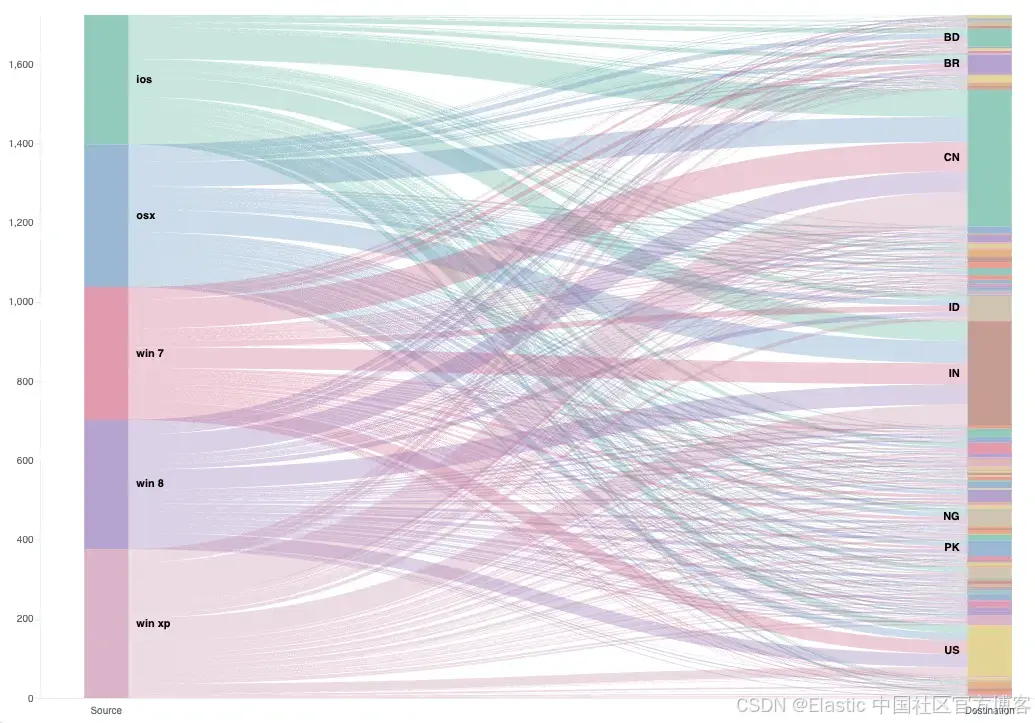
在 Kibana 中为 Vega Sankey 可视化添加过滤功能
作者:来自 Elastic Tim Bosman 及 Miloš Mandić 有兴趣在 Kibana 中为 Vega 可视化添加交互式过滤器吗?了解如何利用 “kibanaAddFilter” 函数轻松创建动态且响应迅速的 Sankey 可视化。 在这篇博客中,我们将了解如何启用 Vega Sankey 可视…

【实验】【H3CNE邓方鸣】交换机端口安全实验+2024.12.11
实验来源:邓方鸣交换机端口安全实验 软件下载: 华三虚拟实验室: 华三虚拟实验室下载 wireshark:wireshark SecureCRT v8.7 版本: CRT下载分享与破解 文章目录 dot1x 开启802.1X身份验证 开启802.1X身份验证,需要在系统视图和接口视…

qt 封装 调用 dll
这个目录下 ,第一个收藏的这个 ,可以用,
但是有几个地方要注意
第一.需要将dll的头文件添加到qt的文件夹里面 第二,需要在pro文件里面添加动态库路径
第三,如果调用dll失败,那么大概需要将dll文件放在e…



队列+宽搜_429. N 叉树的层序遍历_二叉树最大宽度
429. N 叉树的层序遍历 定义一个队列q,将一层的节点入队,并记录节点个数。根据节点的个数,出队列,并将其孩子入队列。出完队列,队列当前剩余节点的个数就是下次出队列的次数。直到队列为空 /*
// Definition for a Nod…

深度剖析 ToF 技术:原理、优劣、数据纠错与工业应用全解析
1 引言
飞行时间(Time-of-Flight,简称ToF)技术是一种先进的三维成像技术,其工作机制与三维激光扫描技术有着相似之处。ToF技术的主要优势在于其能够一次性捕获整个场景的深度信息,而不是通过逐点扫描的方式来获取&…

嵌入式硬件-- 元器件焊接
1.锡膏的使用
锡膏要保存在冰箱里。
焊接排线端子;138度的低温锡(锡膏),
第一次使用,直接拿东西挑一点涂在引脚上,不知道多少合适,加热台加热到260左右,放在上面观察锡融化&#…

一区向量加权算法优化INFO-CNN-SVM卷积神经网络结合支持向量机多特征分类预测
一区向量加权算法优化INFO-CNN-SVM卷积神经网络结合支持向量机多特征分类预测 目录 一区向量加权算法优化INFO-CNN-SVM卷积神经网络结合支持向量机多特征分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述
1.Matlab实现INFO-CNN-SVM向量加权算法优化卷积神经网络结…

给新ubuntu电脑配置远程控制环境和c++版本的opencv环境
目录 改用户密码安装ssh sever安装net-tools配置vscode安装vim配置C opencv1. 安装g, cmake, make2.安装opencv依赖库3.下载opencv源文件(1)方法一:官网下载(2)方法二:GitHub下载方式: 4. Cmake…

(3)spring security - 认识PasswordEncoder
目录 1.简介1.1.简单了解认证流程 2.密码验证3.PasswordEncoder的内置实现4.小结 目标: 简单了解认证的流程简单认识spring security中的Password Encoder
1.简介 还是以这幅图为基础,认识Password Encoder到底是什么?
1.1.简单了解认证流程…

29.在Vue 3中使用OpenLayers读取WKB数据并显示图形
在Web开发中,地理信息系统(GIS)应用越来越重要,尤其是在地图展示和空间数据分析的场景中。OpenLayers作为一个强大的开源JavaScript库,为开发者提供了丰富的地图展示和空间数据处理能力。在本篇文章中,我将…

LLM大语言模型私有化部署-OpenEuler22.03SP3上容器化部署Dify与Qwen2.5
背景
Dify 是一款开源的大语言模型(LLM) 应用开发平台。其直观的界面结合了 AI 工作流、 RAG 管道、 Agent 、模型管理、可观测性功能等,让您可以快速从原型到生产。相比 LangChain 这类有着锤子、钉子的工具箱开发库, Dify 提供了更接近生产需要的完整…

革新3D高保真数字人生成:无需深度摄像头,普通手机视频即可创建逼真面部动画
在数字化内容创作领域,特别是虚拟人物和增强现实(AR)应用中,高质量的3D数字人生成正变得越来越重要。然而,传统方法依赖于昂贵的深度摄像头和复杂的设备设置,这不仅增加了成本,也限制了其灵活性和易用性。为了解决这些问题,并降低进入门槛,一款基于MetaHuman的插件应运…

【前端 Uniapp】使用Vant打造Uniapp项目(避坑版)
一、基本介绍
Uniapp 是基于 Vue.js 的开发框架,通过一套代码可以同时发布到多个平台的应用框架。而 Vant 是针对移动端 Vue.js 的组件库。通过这样的组合,我们可以快速构建出一个跨平台的移动应用。Vant 已经支持多种小程序和 H5 平台,也对…

【记录】Django解决与VUE跨域问题
1 梗概 这里记录Django与VUE的跨域问题解决方法,主要修改内容是在 Django 中。当然其他的前端项目 Django 也可以这样处理。 2 安装辅助包
pip install django-cors-headers3 配置 settings.py INSTALLED_APPS [ # ... corsheaders, # ... ] 为了响应…

【AI知识】激活函数介绍(sigmoid Tanh Relu)+ 梯度爆炸 / 消失及解决办法
激活函数: 使用激活函数的原因: 神经网络中每一层的输入输出都是一个线性求和的过程,下一层的输出只是承接了上一层输入函数的线性变换,如果没有激活函数,无论构造的神经网络多么复杂,有多少层,…

驱动开发-入门【1】
1.内核下载地址
Linux内核源码的官方网站为https://www.kernel.org/,可以在该网站下载最新的Linux内核源码。进入该网站之后如下图所示: 从上图可以看到多个版本的内核分支,分别为主线版本(mainline)、稳定版本&#…