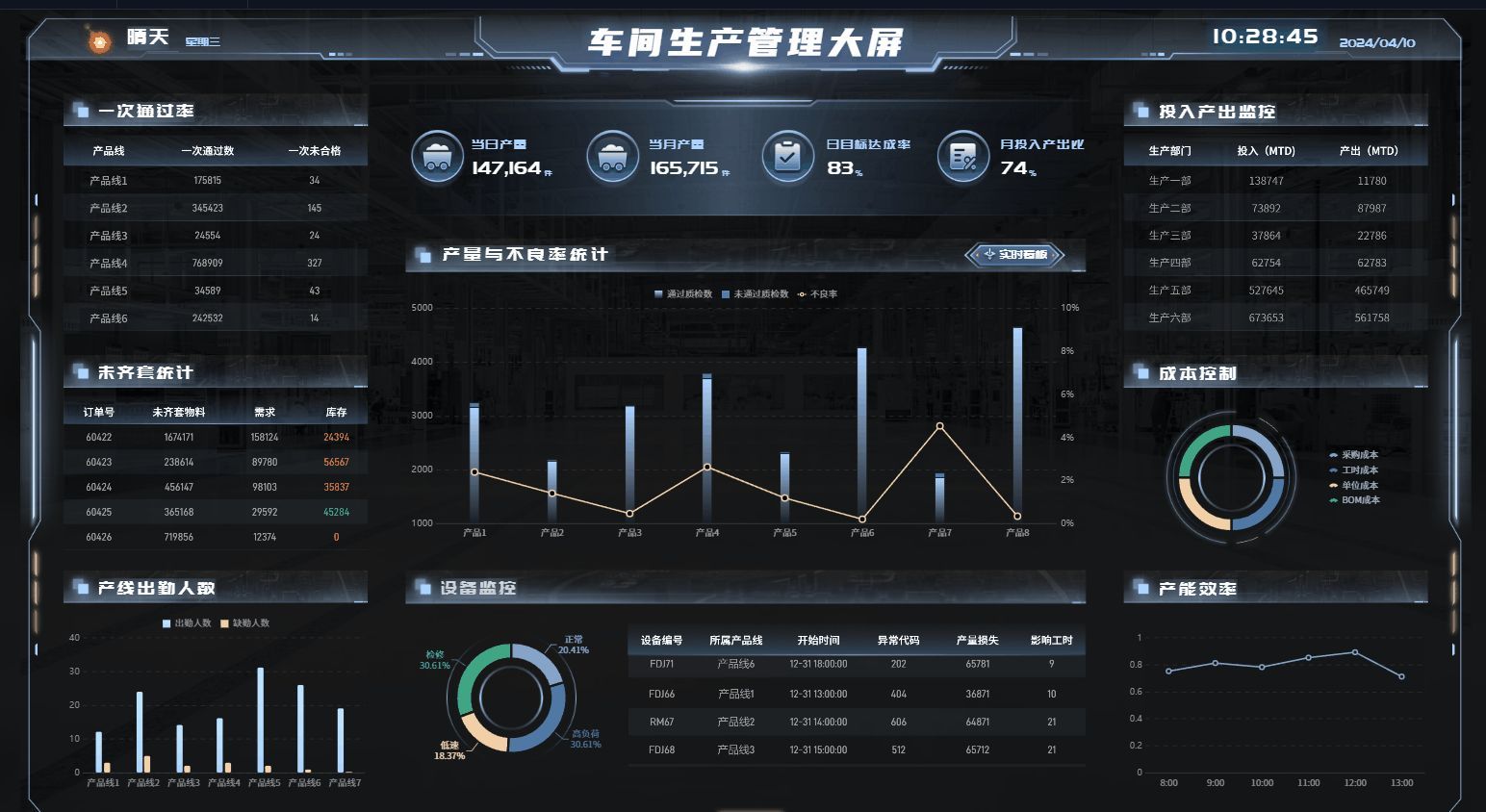
- 作者: Mohamed Elnoor, Kasun Weerakoon, Gershom Seneviratne, Ruiqi Xian, Tianrui Guan, Mohamed Khalid M Jaffar, Vignesh Rajagopal, and Dinesh Manocha
- 单位:马里兰大学学院公园分校
- 原文链接:VLM-GroNav: Robot Navigation Using Physically Grounded Vision-Language Models in Outdoor Environments (https://arxiv.org/pdf/2409.20445)
- 视频演示:https://gamma.umd.edu/researchdirections/crowdmultiagent/vlm-gronav/
主要贡献
- 物理信息融合:论文提出将视觉语言模型(VLMs)与基于本体感受的感知相结合的导航方法,显著提高了地形可通行性估计的准确性和可靠性。
- 动态更新:通过上下文学习将VLMs的语义理解与本体感受数据相结合,实现了基于机器人实时物理交互的可通行性估计的动态更新。
- 全局和局部规划器:利用VLMs进行的高层次全局规划器和实时自适应局部规划器,能够在复杂或未知环境中动态调整路径。
- 实验验证:在多种真实世界户外环境中进行了广泛的实验验证,显示出比现有方法高达50%的导航成功率提升。
研究背景
研究问题

论文主要解决的问题是如何在户外环境中实现自主机器人的导航,特别是处理不同地形的可通行性条件。
研究难点
该问题的研究难点包括:
- 自然地形的多变性和复杂性,
- 地形物理特性(如可变形性和滑动性)的可预测性差,
- 传统导航方法在复杂环境中的不足,
- 以及现有数据集在处理多样化地形上的局限性。
相关工作
该问题的研究相关工作有:
- 依赖视觉传感器的传统导航方法,
- 触觉和本体感知在机器人操作中的应用,
- 以及将基础模型、大型语言模型(LLMs)和视觉语言模型(VLMs)集成到机器人导航中的进展。
研究方法
论文提出了VLM-GroNav,一种结合视觉语言模型(VLMs)和本体感知的新型导航方法,用于解决户外环境中的机器人导航问题。

可通行性估计
使用本体感知传感器估计地形可通行性。对于腿式机器人,通过关节施加的力量计算机器人腿部的沉降量,作为地形可变形性的直接测量。对于轮式机器人,通过比较轮式里程计和LiDAR里程计的测量值来评估地形的滑动性。
- 对于腿式机器人: S sinkage = ∑ i = 1 n f joint , i 2 S_{\text{sinkage}} = \sum_{i=1}^{n} f_{\text{joint}, i}^{2} Ssinkage=i=1∑nfjoint,i2其中, f joint , i f_ {\text{joint}, i} fjoint,i是第i个关节施加的力量,n是关节总数。可通行性指标 τ \tau τ的计算公式为: τ sinkage = Γ ⋅ S sinkage − S min S max S min \tau_{\text{sinkage}} = \Gamma \cdot \frac{S_{\text{sinkage}} - S_{\text{min}}}{S_{\text{max}}S_{\text{min}}} τsinkage=Γ⋅SmaxSminSsinkage−Smin其中, S min S_{\min} Smin 对应于最不易变形的地形(如混凝土), S max S_{\max} Smax对应于最易变形的地形(如松散沙子)。
- 对于轮式机器人: τ s l i p = β 1 ( Δ d l i d a r − Δ d o d o m ) + β 2 ( Δ θ l i d a r − Δ θ o d o m ) \tau_{slip} = \beta_{1}(\Delta d_{lidar} - \Delta d_{odom}) + \beta_{2}(\Delta\theta_{lidar} - \Delta\theta_{odom}) τslip=β1(Δdlidar−Δdodom)+β2(Δθlidar−Δθodom)其中, Δ d \Delta d Δd 和 Δ θ \Delta\theta Δθ分别表示从LiDAR里程计和轮式里程计获得的距离和方向变化, β 1 \beta_{1} β1 和 β 2 \beta_{2} β2是权重因子。
Physically Grounded 推理模块
结合视觉和本体感知数据,连续更新地形可通行性估计和导航策略。利用VLMs处理视觉输入(航空影像和前置摄像头视图),并整合机器人本地传感器的实时反馈。
- 初始时,自主堆栈查询大型VLMs,根据航空影像和天气数据对地形类型进行分类。
- 在导航过程中,机器人捕获5m x 5m的前置摄像头和航空影像块,时间移位可通行性指标以匹配视觉输入。
- 构建示例池 E pool \mathcal{E}_\text{pool} Epool,包括航空影像、前置摄像头视图、对齐的可通行性指标和地形类别。
- 使用上下文学习来细化地形可通行性和导航成本估计。VLMs使用示例和文本提示来估计地形的可通行性:
τ estimate = VLM ( T prompt , E pool ) \tau_{\text{estimate}} = \text{VLM}(\mathcal{T}_{\text{prompt}},\mathcal{E}_{\text{pool}}) τestimate=VLM(Tprompt,Epool)
高层全局规划器
使用航空影像和VLMs生成引导机器人从当前位置到目标位置的最优航点集。通过在航空影像上应用视觉标记来增强VLMs识别可航行区域的能力。
- VLMs被提示带有标记图像和导航目标 T o b j e c t i v e T_{objective} Tobjective,选择最优航点序列以实现目标。
- 当可通行性估计因新的本体感知反馈而改变时,全局规划器重新查询VLMs以更新航点:
W new = VLM ( T objective , I marked , τ estimate ) \mathcal{W}_{\text{new}} = \operatorname{VLM}(\mathcal{T}_{\text{objective}},\mathcal{I}_{\text{marked}},\tau_{\text{estimate}}) Wnew=VLM(Tobjective,Imarked,τestimate) - 更新后的航点 W new W_{\text{new}} Wnew传递给局部规划器。
自适应局部规划器
通过将本体感知反馈与轻量级VLMs(具有低推理时间)集成,实时调整机器人的轨迹。使用CLIP进行零样本地形分类,识别机器人前方左侧、中间和右侧的候选前沿。
- 将前沿投影到图像帧中,并在机器人RGB相机图像中进行视觉标记,然后传递给CLIP进行零样本地形分类。
- 每个航点被分配一个地形类型 ℓ i \ell_{i} ℓi。
- 在DWA的目标函数中引入前沿成本项,优先选择朝向更具可通行性的前沿的轨迹。修改后的目标函数 G ( v , ω ) G(v,\omega) G(v,ω)为: G ( v , ω ) = J ( v , ω ) + ρ 4 ⋅ ϕ ( v , ω ) G(v,\omega) = J(v,\omega) + \rho_{4} \cdot \phi(v,\omega) G(v,ω)=J(v,ω)+ρ4⋅ϕ(v,ω)
- 前沿成本项
ϕ
(
v
,
ω
)
\phi(v,\omega)
ϕ(v,ω)的计算公式为:
ϕ
(
v
,
ω
)
=
min
p
∈
P
(
d
(
η
(
v
,
ω
)
,
p
)
⋅
τ
estimate
(
p
)
)
\phi(v,\omega) = \min\limits_{p \in P} (d(\eta(v,\omega), p) \cdot \tau_{\text{estimate}}(p))
ϕ(v,ω)=p∈Pmin(d(η(v,ω),p)⋅τestimate(p))
其中, η ( v , ω ) \eta(v,\omega) η(v,ω)表示由线速度和角速度 v v v和 ω \omega ω产生的轨迹, d ( η ( v , ω ) , p ) d(\eta(v,\omega), p) d(η(v,ω),p)是轨迹 η ( v , ω ) \eta(v,\omega) η(v,ω)终点和前沿点p之间的欧几里得距离, τ estimate ( p ) \tau_{\text{estimate}}(p) τestimate(p)是由推理模块分配给前沿p的可通行性估计。
实验设计
数据收集
使用Ghost Vision 60腿式机器人和Clearpath Husky轮式机器人进行实际环境实验。
Ghost Vision 60配备前置广角相机、OS1-32 LiDAR、GPS和Intel NUC 11系统;
Clearpath Husky配备Velodyne VLP16 LiDAR、Realsense D435i相机、GPS和笔记本电脑。
实验场景
设计了四个测试场景,包括
- 干草、泥泞草、混凝土(场景1);
- 干草、沙子、混凝土(场景2);
- 混凝土、干草、泥泞草(场景3);
- 混凝土、雪、泥泞草(场景4)。
参数配置
使用GPT-4o API进行推理和全局规划,CLIP进行基于零样本的地形分类。
结果与分析

成功率
VLM-GroNav在所有场景中均实现了最高成功率,比现有方法提高了50%。
归一化轨迹长度
VLM-GroNav在某些场景中实现了更短的轨迹长度,例如场景3中比GA-Nav和CoNVOI分别短了约0.1和0.09。
IMU能量密度
VLM-GroNav在所有场景中的IMU能量密度均低于其他方法,表明其导航更加稳定,能量使用更高效。
定性分析

VLM-GroNav在不同地形之间的过渡中表现出更好的适应性和稳定性,特别是在处理滑动和可变形地形时。
总结
论文提出的VLM-GroNav方法通过结合视觉语言模型(VLMs)和本体感知。该方法通过动态更新地形可通行性估计,实时调整全局和局部规划,显著提高了户外环境中机器人导航的成功率和稳定性。
未来的工作将包括在没有GPS的环境中进行定位的方法优化,以及进一步提高VLMs处理速度以应对动态和复杂环境。





![[Unity] Text文本首行缩进两个字符](https://i-blog.csdnimg.cn/direct/554a40aef88e4c1f8e660cfbc1462d2b.png)