目录
1.多表查询
1.1 外键
1.2 链接查询
2.MySQL函数
内置函数简介
数值函数
字符串函数
时间日期函数
条件判断操作
开窗函数
1.多表查询
本质:把多个表通过主外键关联关系链接(join)合并成一个大表,在去单表查询操作
1.1 外键
外键概念: 在从表(多方)创建一个字段,引用主表(一方)的主键,对应的这个字段就是外键。
外键特点:
1:从表外键的值是对主表主键的引用。
2:从表外键类型,必须与主表主键类型一致。

外键约束:
==注意: 只有innodb存储引擎支持外键约束和事务!!!==

外键约束添加和删除
建表时添加外键约束: ... CONSTRAINT [外键约束名] FOREIGN KEY (外键名) REFERENCES 主表名 (主表主键)
建表后添加外键约束:alter table 从表名 add CONSTRAINT [外键约束名] FOREIGN KEY (外键名) REFERENCES 主表名 (主表主键)
删除外键约束: alter table 从表名 drop FOREIGN KEY 外键约束名;
# 创建数据库并使用它
create database if not exists ai_db2;
use ai_db2;
# 创建分类表
drop table if exists category1;
CREATE TABLE category1
(
cid VARCHAR(32) PRIMARY KEY, # 分类id
cname VARCHAR(100) # 分类名称
);
# 查看存储引擎
show create table category1;
# 商品表
drop table if exists products1;
CREATE TABLE products1
(
pid VARCHAR(32) PRIMARY KEY,
pname VARCHAR(40),
price DOUBLE,
category_id VARCHAR(32),
-- 建表时添加外键约束: CONSTRAINT [外键约束名] FOREIGN KEY (外键名) REFERENCES 主表名 (主表主键)
CONSTRAINT FOREIGN KEY (category_id) REFERENCES category1 (cid)
);
# 查看存储引擎
show create table products1;
-- 删除外键约束
-- alter table 从表名 drop FOREIGN KEY 外键约束名;
alter table products1 drop FOREIGN KEY products1_ibfk_1;
-- 建表后添加外键约束
-- alter table 从表名 add CONSTRAINT [外键约束名] FOREIGN KEY (外键名) REFERENCES 主表名 (主表主键)
alter table products1 add CONSTRAINT wj FOREIGN KEY (category_id) REFERENCES category1 (cid) ;查看依赖图

外键约束的特点
外键约束关键字: foreign key
外键约束语法: [CONSTRAINT 约束名] FOREIGN KEY (外键字段) REFERENCES 主表名(主键字段);
外键约束作用:
限制从表插入数据: 从表插入数据的时候如果外键值是主表主键中不存在的,就插入失败
限制主表删除数据: 主表删除数据的时候如果主键值已经被从表外键的引用,就删除失败
外键约束好处: 保证数据的准确性和完整性
1.2 链接查询

数据准备
# 使用库
use ai_db2;
# 建测试表
CREATE TABLE products
(
id INT PRIMARY KEY AUTO_INCREMENT, -- 商品ID
name VARCHAR(24) NOT NULL, -- 商品名称
price DECIMAL(10, 2) NOT NULL, -- 商品价格
score DECIMAL(5, 2), -- 商品评分,可以为空
is_self VARCHAR(8), -- 是否自营
category_id INT -- 商品类别ID
);
CREATE TABLE category
(
id INT PRIMARY KEY AUTO_INCREMENT, -- 商品类别ID
name VARCHAR(24) NOT NULL -- 类别名称
);
# 添加测试数据
INSERT INTO category
VALUES (1, '手机'),
(2, '电脑'),
(3, '美妆'),
(4, '家居');
INSERT INTO products
VALUES (1, '华为Mate50', 5499.00, 9.70, '自营', 1),
(2, '荣耀80', 2399.00, 9.50, '自营', 1),
(3, '荣耀80', 2199.00, 9.30, '非自营', 1),
(4, '红米note 11', 999.00, 9.00, '非自营', 1),
(5, '联想小新14', 4199.00, 9.20, '自营', 2),
(6, '惠普战66', 4499.90, 9.30, '自营', 2),
(7, '苹果Air13', 6198.00, 9.10, '非自营', 2),
(8, '华为MateBook14', 5599.00, 9.30, '非自营', 2),
(9, '兰蔻小黑瓶', 1100.00, 9.60, '自营', 3),
(10, '雅诗兰黛粉底液', 920.00, 9.40, '自营', 3),
(11, '阿玛尼红管405', 350.00, NULL, '非自营', 3),
(12, '迪奥996', 330.00, 9.70, '非自营', 3),
(13, '百草味紫皮腰果',9,NULL,NULL,NULL);交叉连接
交叉连接关键字: cross join
显式交叉连接格式: select * from 左表 cross join 右表;
隐式交叉连接格式: select * from 左表,右表;
注意: 交叉连接了解即可,因为它本质就是一个错误,又叫笛卡尔积(两个表记录数的乘积)
注意: 左表和右表没有特殊含义,只是在前面是左表,在后面的是右表
-- 1.交叉连接(笛卡尔积): 是一个错误!!!工作中慎用!!!
# 关键字: cross join
# 隐式交叉连接格式: select 字段名 from 左表,右表;
SELECT *
FROM
products,
category;
# 显式交叉连接格式: select 字段名 from 左表 cross join右表;
SELECT *
FROM
products
CROSS JOIN category;内连接(常用)
内连接关键字: inner join ... on
显式内连接格式: select * from 左表 inner join 右表 on 关联条件;
隐式内连接格式: select * from 左表 , 右表 where 关联条件;
注意: 左表和右表没有特殊含义,只是在前面是左表,在后面的是右表
-- 2.内连接: 两个表的交集
# 关键字: inner join on
# 隐式内连接格式: select 字段名 from 左表,右表 where 条件;
SELECT
c.id cid,
c.name cname,
p.id pid,
p.name pname
FROM
products p,
category c
WHERE
p.category_id = c.id;
# 显式内连接格式: select 字段名 from 左表 cross join右表;
SELECT
c.id cid,
c.name cname,
p.id pid,
p.name pname
FROM
products p
INNER JOIN category c ON p.category_id = c.id;左外连接
内连接关键字: left outer join ... on
左外连接格式: select * from 左表 left outer join 右表 on 关联条件;
注意: 左表和右表没有特殊含义,只是在前面是左表,在后面的是右表
右外连接
内连接关键字: right outer join ... on
左外连接格式: select * from 左表 right outer join 右表 on 关联条件;
注意: 左表和右表没有特殊含义,只是在前面是左表,在后面的是右表
-- 3.外连接
-- 为了方便演示插入一条数据
INSERT INTO
products(name, price, category_id)
VALUES
('百草味紫皮腰果', 9, 5);
-- 需求: 分别使用左右连接查询每个分类下的所有商品,即使没有商品的分类要展示
-- 分析: 必须以分类表为主
-- 左外连接: left outer join
SELECT
c.id cid,
c.name cname,
p.id pid,
p.name pname
FROM
category c
LEFT OUTER JOIN products p ON p.category_id = c.id;
-- 右外连接: right outer join
SELECT
c.id cid,
c.name cname,
p.id pid,
p.name pname
FROM
products p
RIGHT OUTER JOIN category c ON p.category_id = c.id;全外连接
注意: mysql中没有full outer join on这个关键字,所以不能用它来完成全外连接!
所以只能先查询左外连接和右外连接的结果,然后用union或者union all来实现!!!
union : 默认去重
union all: 不去重
-- 全外连接
# union : 默认去重
SELECT *
FROM
products p
LEFT JOIN category c ON p.category_id = c.id
UNION
SELECT *
FROM
products p
RIGHT JOIN category c ON p.category_id = c.id;
# union all: 不去重
SELECT *
FROM
products p
LEFT JOIN category c ON p.category_id = c.id
UNION ALL
SELECT *
FROM
products p
RIGHT JOIN category c ON p.category_id = c.id;自连接查询
解释: 两个表进行关联时,如果左表和右边是同一张表,这就是自关联。
注意: 自连接必须起别名!
-- 自连接查询
-- 查询'江苏省'下所有城市
SELECT
shi.id,
shi.title,
sheng.id,
sheng.title
FROM
areas sheng
JOIN areas shi ON shi.pid = sheng.id
WHERE
sheng.title = '江苏省';
-- 查询'宿迁市'下所有的区县
SELECT
quxian.id,
quxian.title,
shi.id,
shi.title
FROM
areas shi
JOIN areas quxian ON quxian.pid = shi.id
WHERE
shi.title = '宿迁市';
-- 查询'安徽省'下所有的市,以及市下面的区县信息
SELECT
quxian.id,
quxian.title,
shi.id,
shi.title,
sheng.id,
sheng.title
FROM
areas sheng
JOIN areas shi ON shi.pid = sheng.id
JOIN areas quxian ON quxian.pid = shi.id
WHERE
sheng.title = '江苏省';
-- 自连接的妙用
-- 需求1: 求每个月和上月的差额
SELECT
c.month,
c.revenue,
c.revenue-u.revenue as diff
FROM
sales c
JOIN sales u ON c.month = u.month + 1;
-- 需求2: 求截止到当月累计销售额
SELECT
c.month,
SUM(u.revenue)
FROM
sales c
JOIN sales u ON c.month >= u.month
GROUP BY
c.month;子查询
子查询:在一个 SELECT 语句中,嵌入了另外一个 SELECT 语句,那么被嵌入的 SELECT 语句称之为子查询语句,外部那个SELECT 语句则称为主查询。
作用: 子查询是辅助主查询的。
子查询的结果充当主查询的条件
子查询的结果充当主查询的数据源(临时表)
子查询的结果充当主查询的查询字段
-- 子查询
-- 1.子查询作为条件使用
-- 需求: 求商品价格大于平均价的商品信息
SELECT *
FROM
products
WHERE
price > (SELECT AVG(price) FROM products);
-- 需求: 求商品价格最高的商品信息(考虑并列情况)
select *
from products
where price = (select max(price) from products);
-- 查询'河北省'下所有城市
select * from areas where pid = (select id from areas where title = '河北省');
-- 查询'邯郸市'下所有区县
select * from areas where pid = (select id from areas where title = '邯郸市');
-- 注意:子查询作为表使用必须加括号,同时起别名!!!
-- 需求: 查询'电脑'分类中商品的平均价格,要求结果中包含分类名称
# 思路1: 先合并商品表和分类表,再分组聚合
select c.name,avg(p.price)
from products p JOIN category c ON c.id = p.category_id
group by c.name having c.name = '电脑';
# 思路2: 子查询作为表使用,调优角度: join之前能提前过滤就提前过滤
select c.name,avg(p.price)
from products p JOIN (select * from category where name = '电脑') c ON c.id = p.category_id
group by c.name ;
-- 需求: 查询各个分类中商品的平均价格,要求结果中包含分类名称
# 思路1: 先合并商品表和分类表,再分组聚合
select c.name,avg(p.price)
from products p JOIN category c ON c.id = p.category_id
group by c.name ;
# 思路2: 直接查询商品表中各个分类平均价格,先不考虑名称,最后再去连接查询
select c.name,avg_price
from (select category_id,avg(price) as avg_price from products group by category_id) t
join category c on t.category_id = c.id;
-- 需求: 计算每个学生的分数和整体平均分的差值
-- 1.既作为字段又作为表
select
id,
name,
gender,
score,
avg_score,
score-avg_score as diff
from students s
join (select round(avg(score),2) as avg_score from students) t;
-- 2.直接作为字段用
select
id,
name,
gender,
score,
(select round(avg(score),2) as avg_score from students) avg_score,
score-(select round(avg(score),2) as avg_score from students) as diff
from students;2.MySQL函数
内置函数简介
在MySQL中有很多内置函数,除了之前学习的聚合函数之外,还有很多其他内置函数:数值函数、字符串函数、时间日期函数、流程控制函数、加解密函数、开窗函数等。
问题:内置函数该如何学习? 熟悉常用的内置函数,其他用到再查帮助文档 官网文档:MySQL :: MySQL 8.0 Reference Manual :: 14 Functions and Operators 在mysql命令行或DataGrip软件中通过 HELP '函数名' 查看指定函数的帮助文档 示例: help ‘count’;
数值函数
数值函数分类: 小数位数处理 ROUND、FORMAT、TRUNCATE、FLOOR、CEIL 求余数、求幂、随机数 MOD、POW、RAND
字符串函数
字符串函数分类: 大小写转换、反转 LOWER、UPPER 字符串反转、拼接、局部替换 REPEAT、CONCAT、CONCAT_WS、REPLACE 字符串截取,字符串的字符个数以及存储长度 SUBSTR、SUBSTRING、LEFT、RIGHT 字符串长度 CHAR_LENGTH、LENGTH
时间日期函数
时间日期函数分类: 获取当前时间的函数,比如当前的年月日 NOW、CURRENT_DATE、CURRENT_TIME 计算时间差的函数,比如两个日期之间相差多少天,一个日期90天后是几月几号 DATE_ADD、DATE_SUB、DATEDIFF、TIMESTAMPDIFF 获取年月日的函数,从一个时间中提取具体的年份、月份等 YEAR、MONTH、DAY、HOUR、MINUTE、SECOND、WEEKDAY 时间转换的函数,比如将2021-10-05转换为时间戳 字符串和时间的转换: DATE_FORMAT、STR_TO_DATE 时间戳和时间的转换: UNIX_TIMESTAMP、FROM_UNIXTIME 时间戳(数字):某个时间距离UTC时区的1970-01-01 00:00:00 过去了多久(通常以秒或毫妙为单位)。 比如:东八区的2023-06-01 17:20:44距离UTC时区的1970-01-01 00:00:00 已经过去了 1685611244 秒
条件判断操作
case
when 条件1 then 值1
when 条件2 then 值2
....
else 值n
end
IF(条件, 值1, 值2):条件成立,IF的结果就是值1,否则结果就是值2
==注意:CASE...END中只有两种条件选择时,可以使用IF函数替代=
-- CASE WHEN基本使用
-- 示例1
-- 需求:查询所有学生的成绩信息,并将学生的成绩分成5个等级,查询结果中需要有一个学生的成绩等级列,
-- 成绩等级如下:
-- 优秀:90分及以上
-- 良好:80-90,包含80
-- 中等:70-80,包含70
-- 及格:60-70,包含60
-- 不及格:60分以下
-- 查询结果字段:
-- name(姓名)、course(科目)、score(成绩)、grade(成绩等级)
-- 数据准备
CREATE TABLE `tb_score` (
`name` varchar(24) NOT NULL,
`course` varchar(24) NOT NULL,
`score` decimal(5,2) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `tb_score` VALUES ('张三','语文',81.00),('张三','数学',75.00),('李四','语文',76.00),
('李四','数学',90.00),('王五','语文',81.00),('王五','数学',100.00);
-- 查询结果
SELECT *,
CASE
WHEN score >= 90 THEN '优秀'
WHEN score >= 80 THEN '良好'
WHEN score >= 70 THEN '中等'
WHEN score >= 60 THEN '及格'
ELSE '不及格'
END AS grade
FROM
tb_score;
-- 分组条件计数
-- 示例1:统计不同科目中,成绩在90分以上(包含90)和90分以下的人数各有多少
-- 查询结果字段:
-- course(科目)、gte_90(该科目90分以上是学生人数)、lt_90(该科目90分以下的学生人数)
# 方式1
SELECT
course,
COUNT(
CASE WHEN score >= 90 THEN 1 ELSE NULL END
) AS gte_90,
COUNT(
CASE WHEN score < 90 THEN 1 ELSE NULL END
) AS lt_90
FROM
tb_score
GROUP BY
course;
# 方式2
SELECT
course,
sum(
CASE WHEN score >= 90 THEN 1 ELSE 0 END
) AS gte_90,
sum(
CASE WHEN score < 90 THEN 1 ELSE 0 END
) AS lt_90
FROM
tb_score
GROUP BY
course;开窗函数
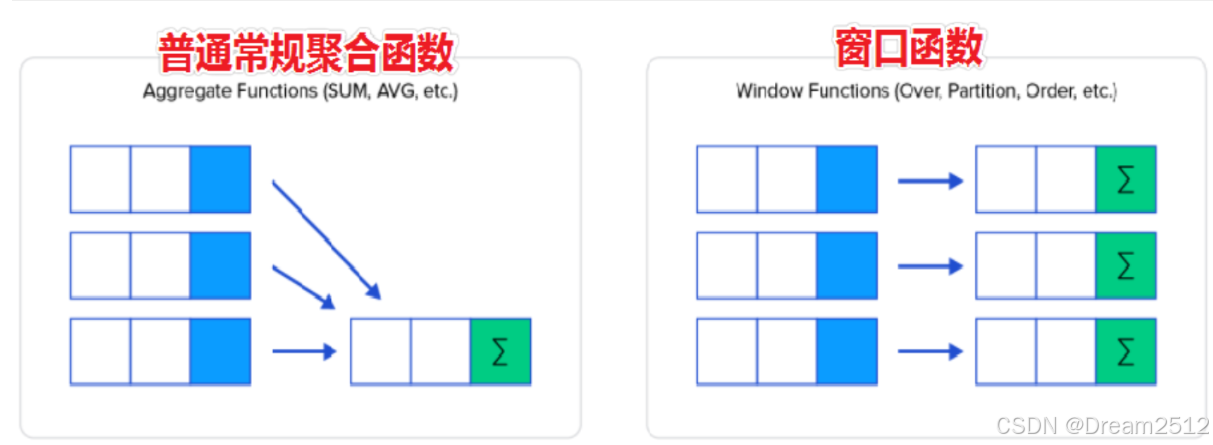
==作用:查询每一行数据时,使用指定的窗口函数对每行关联的一组数据进行处理。==
基本语法:<ranking function> OVER (ORDER BY 列名, ...) OVER(...)的作用就是设置每一行数据关联的一组数据范围,OVER()时,每行关联的数据范围都是整张表的数据。 <window function>表示使用的窗口函数,窗口函数可以使用之前已经学过的聚合函数,比如COUNT、SUM、AVG、MAX、MIN等,也可以ROW_NUMBER、RANK、DENSE_RANK等,后面会依次介绍。
常用排序函数:
RANK():产生的排名序号 ,有并列的情况出现时序号不连续 DENSE_RANK() :产生的排序序号是连续的,有并列的情况出现时序号会重复 ROW_NUMBER() :返回连续唯一的行号,排名序号不会重复
# ----------------------------------- 1. 窗口函数简介 -----------------------------------
-- 窗口函数是 MySQL8.0 以后加入的功能,之前需要通过定义临时变量和大量的子查询才能完成的工作,使用窗口函数实现起来更加简洁高效
-- 窗口函数的作用是在处理每行数据时,针对每一行关联的一组数据进行处理。
-- 基础语法:<window function> OVER(...)
-- <window function> 表示使用的窗口函数,窗口函数可以使用之前已经学过的聚合函数,比如COUNT()、SUM()、AVG()等,也可以是其他函数,比如 ranking 排序函数等,后面的课程中会介绍
-- OVER(...)的作用就是设置每行数据关联的窗口数据范围,OVER()时,每行关联的数据范围都是整张表的数据。
-- 典型应用场景1:计算每个值和整体平均值的差值
-- 示例1
# 需求:计算每个学生的 Score 分数和所有学生整体平均分的差值。
# 查询结果字段:
# ID、Name、Gender、Score、AVG_Score(学生整体平均分)、difference(每位学生分数和整体平均分的差值)
SELECT *,
AVG(score) OVER () AS avg_score,
score - AVG(score) OVER () AS diff
FROM
students;
# ----------------------------------- 3. PARTITION BY分区 -----------------------------------
-- 基本语法:<window function> OVER(PARTITION BY 列名, ...)
-- PARTITION BY 列名, ...的作用是按照指定的列对整张表的数据进行分区
-- 分区之后,在处理每行数据时,<window function>是作用在该行数据关联的分区上,不再是整张表上
-- 应用示例
-- 示例1
-- 需求:计算每个学生的 Score 分数和同性别学生平均分的差值
-- 查询结果字段:
-- ID、Name、Gender、Score、Avg(同性别学生的平均分)、difference(每位学生分数和同性别学生平均分的差值)
SELECT *,
AVG(score) OVER (PARTITION BY gender) AS gender_score,
score - AVG(score) OVER (PARTITION BY gender) AS diff
FROM
students;
-- 补充:PARTITION BY 和 GROUP BY的区别
-- 使用场景不同
-- PARTITION BY用在窗口函数中,结果是:一进一出
-- GROUP BY用在分组聚合中,结果是:多进一出
# ----------------------------------- 4. 排名函数 -----------------------------------
-- 基本语法:<ranking function> OVER (ORDER BY 列名, ...)
-- OVER() 中可以指定 ORDER BY 按照指定列对每一行关联的分区数据进行排序,然后使用排序函数对分区内的每行数据产生一个排名序号
-- 排名函数
-- RANK():产生的排名序号 ,有并列的情况出现时序号不连续
-- DENSE_RANK() :产生的排序序号是连续的,有并列的情况出现时序号会重复
-- ROW_NUMBER() :返回连续唯一的行号,排名序号不会重复
-- PARTITION BY和排序函数配合
-- 示例1:
-- 需求:按照不同科目,对学生的分数从高到低进行排名(要求:连续可重复)
-- 查询结果字段:
-- name、course、score、dense_rank(排名序号)
SELECT *,
DENSE_RANK() OVER (PARTITION BY course ORDER BY score DESC) as dr
FROM
tb_score;
-- 典型应用:获取指定排名的数据
-- 示例2
-- 需求:获取每个科目,排名第二的学生信息
-- 查询结果字段:
-- name、course、score
SELECT *
FROM
(SELECT *,
DENSE_RANK() OVER (PARTITION BY course ORDER BY score DESC) AS dr
FROM
tb_score) t
WHERE
dr = 2;
-- CTE(公用表表达式)
-- CTE(公用表表达式):Common Table Expresssion,类似于子查询,相当于一张临时表,可以在 CTE 结果的基础上,进行进一步的查询操作。
-- 基础语法
/*
WITH tmp1 AS (
-- 查询语句
), tmp2 AS (
-- 查询语句
), tmp3 AS (
-- 查询语句
)
SELECT
字段名
FROM 表名;
*/
-- 示例1
-- 需求:获取每个科目,排名第二的学生信息
-- 查询结果字段:
-- name、course、score
WITH
temp AS (SELECT *,
DENSE_RANK() OVER (PARTITION BY course ORDER BY score DESC) AS dr
FROM
tb_score
)
SELECT *
FROM
temp
WHERE
dr = 2;