文章目录
- 4. 用户行为数据采集模块
- 4.3 日志采集Flume
- 4.3.1 Kafka的三个架构
- 4.3.1.1 source
- 4.3.1.2 channel
- 4.3.1.3 sink
- 4.3.1.4 kafka source
- 4.3.1.5 kafka sink
- 4.3.1.6 kafka channel
- 4.3.1.6.1 第一个结构
- 4.3.1.6.2 第二个结构
- 4.3.1.6.3 第三个结构
4. 用户行为数据采集模块
4.3 日志采集Flume
4.3.1 Kafka的三个架构
4.3.1.1 source
taildir source:可以读取文件的数据,实时的读取文件的数据,并且支持断点续传
avro source :是在Flume之间互相传输的一般配合avro sink,经常使用在Flume做成拓扑结构的时候
nc source :接收网络端口的
exec source:可以读取文件的数据,实时的读取文件的数据,并且不支持断点续传,一般没有人用
spooling source :支持断点续传,监控的不是文件,监控的是文件夹
kafka source :下面有详细的说明
4.3.1.2 channel
file channe : 比较慢,基于磁盘的,但是优点是数据不容易丢,虽然慢,但有个优化,加一个索引机制
memory channel: 比较快,基于内存的,但是缺点是数据容易丢
kafka channel: 下面有详细的说明
4.3.1.3 sink
hdfs sink:这个是经常使用
kafka sink : 下面有详细的说明
avro sink:一般配合avro source
flume官网https://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#
4.3.1.4 kafka source
 Kafka Source is an Apache Kafka consumer that reads messages from Kafka topics. If you have multiple Kafka sources running, you can configure them with the same Consumer Group so each will read a unique set of partitions for the topics. This currently supports Kafka server releases 0.10.1.0 or higher. Testing was done up to 2.0.1 that was the highest avilable version at the time of the release.
Kafka Source is an Apache Kafka consumer that reads messages from Kafka topics. If you have multiple Kafka sources running, you can configure them with the same Consumer Group so each will read a unique set of partitions for the topics. This currently supports Kafka server releases 0.10.1.0 or higher. Testing was done up to 2.0.1 that was the highest avilable version at the time of the release.
意思就是说kafka source从kafka topics里面读数据,kafka source就是kafka的消费者
4.3.1.5 kafka sink
 This is a Flume Sink implementation that can publish data to a Kafka topic. One of the objective is to integrate Flume with Kafka so that pull based processing systems can process the data coming through various Flume sources.
This is a Flume Sink implementation that can publish data to a Kafka topic. One of the objective is to integrate Flume with Kafka so that pull based processing systems can process the data coming through various Flume sources.
This currently supports Kafka server releases 0.10.1.0 or higher. Testing was done up to 2.0.1 that was the highest avilable version at the time of the release.
Required properties are marked in bold font.
意思就是说kafka source往kafka topics里面写数据,kafka source就是kafka的生产者
4.3.1.6 kafka channel
kafka有消峰解耦的功能

The events are stored in a Kafka cluster (must be installed separately). Kafka provides high availability and replication, so in case an agent or a kafka broker crashes, the events are immediately available to other sinks
The Kafka channel can be used for multiple scenarios:
1.With Flume source and sink - it provides a reliable and highly available channel for events
2.With Flume source and interceptor but no sink - it allows writing Flume events into a Kafka topic, for use by other apps
3.With Flume sink, but no source - it is a low-latency, fault tolerant way to send events from Kafka to Flume sinks such as HDFS, HBase or Solr
This currently supports Kafka server releases 0.10.1.0 or higher. Testing was done up to 2.0.1 that was the highest avilable version at the time of the release.
The configuration parameters are organized as such:
1.Configuration values related to the channel generically are applied at the channel config level, eg: a1.channel.k1.type =
2.Configuration values related to Kafka or how the Channel operates are prefixed with “kafka.”, (this are analgous to CommonClient Configs) eg: a1.channels.k1.kafka.topic and a1.channels.k1.kafka.bootstrap.servers. This is not dissimilar to how the hdfs sink operates
3. Properties specific to the producer/consumer are prefixed by kafka.producer or kafka.consumer
4.Where possible, the Kafka paramter names are used, eg: bootstrap.servers and acks
This version of flume is backwards-compatible with previous versions, however deprecated properties are indicated in the table below and a warning message is logged on startup when they are present in the configuration file.
Required properties are in bold.
Flume 会将数据封装成Event的形式,header+body,如果Flume要想使用Kafka Channel,则必须独立安装一个Kafka集群,Kafka支持高可用和副本,Kafka有以下三种结构。
4.3.1.6.1 第一个结构
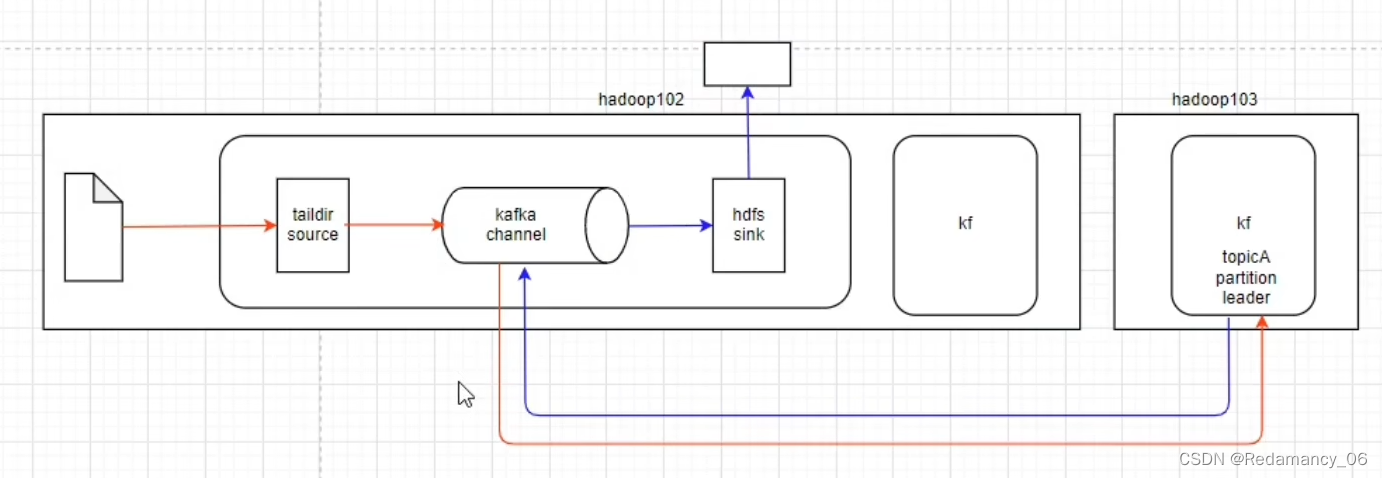
结合Flume source和sink来使用
由taildir source读取数据,发送给kafka channel,因为是kafka channel,因此将数据存储到kafka的topic里面,hdfs sink从kafka channel里面读数据,发现是kafka channel,则从kafka当中要读的数据读出来,发送给hdfs sink
4.3.1.6.2 第二个结构
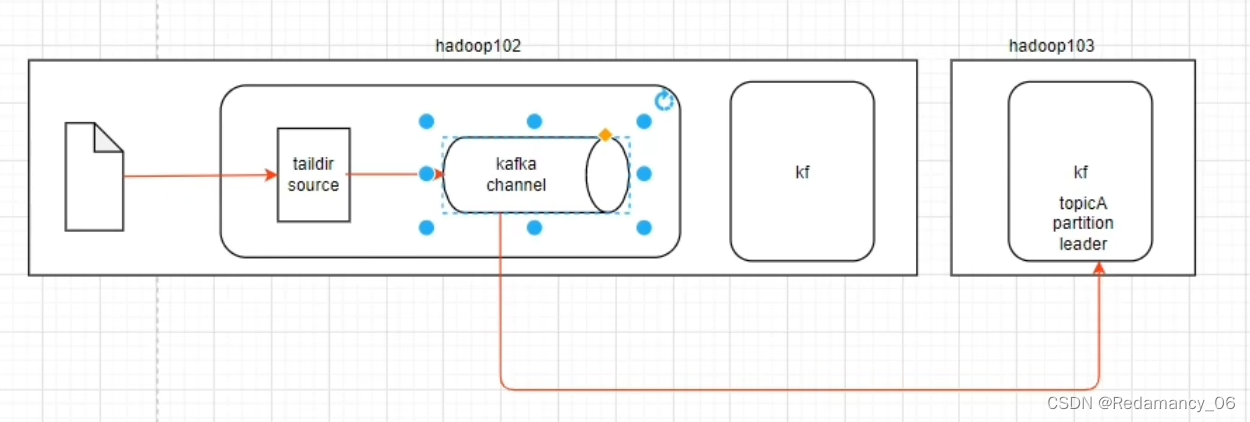 结合source和拦截器来使用,没有sink
结合source和拦截器来使用,没有sink
由taildir source读取数据,发送给kafka channel,因为是kafka channel,因此将数据存储到kafka的topic里面
4.3.1.6.3 第三个结构
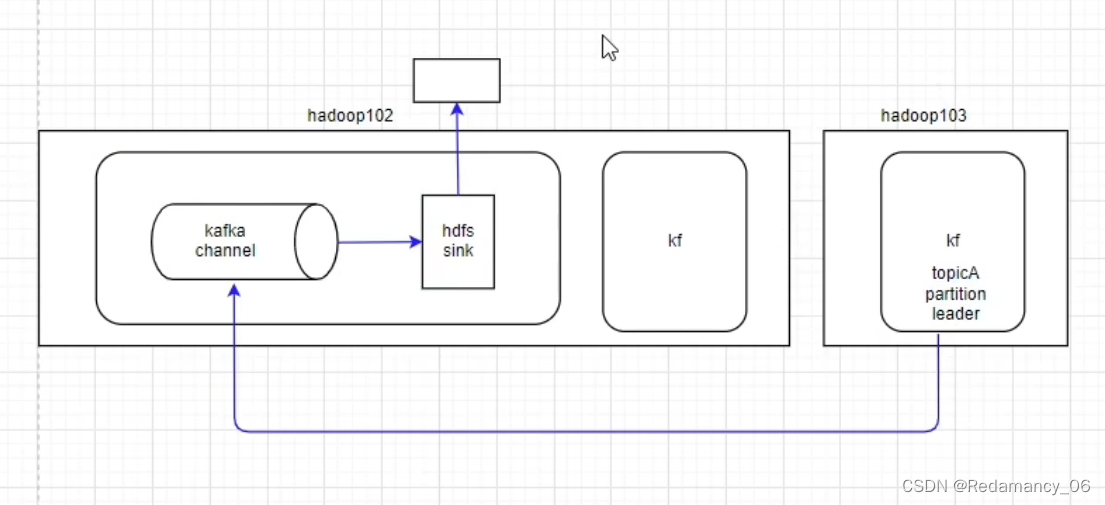 结合Flume sink,没有source
结合Flume sink,没有source
hdfs sink从kafka channel里面读数据,发现是kafka channel,则从kafka当中要读的数据读出来,发送给hdfs sink
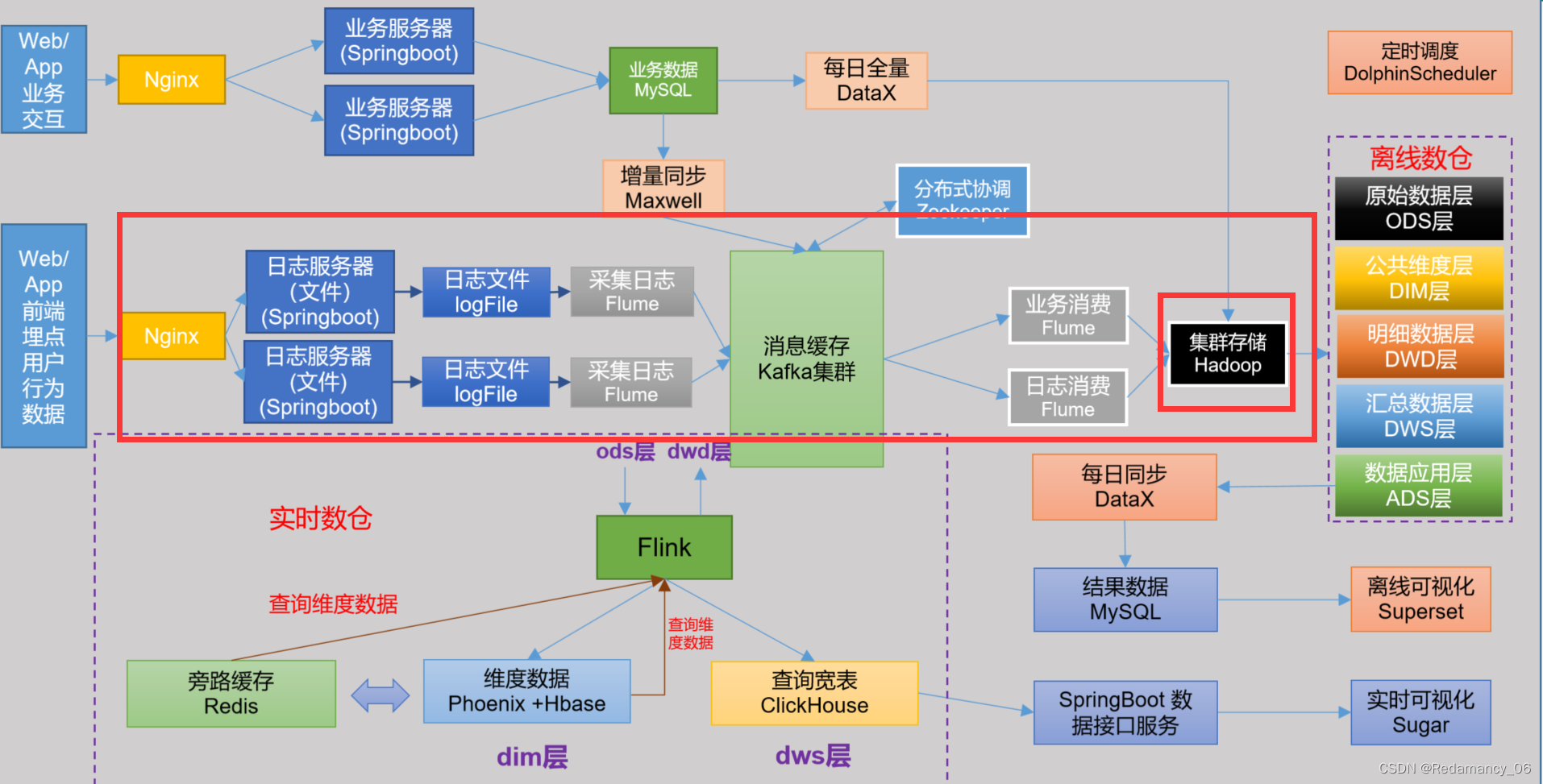
由于需要将数据上传到hadoop集群上,因此第一个架构符合我们的需要,但是从官网上可以看到,数据以FlumeEvent的格式发送到kafka,FlumeEvent的格式是head+body,从source发送到channel的数据是FlumeEvent。离线数仓要的数据只有body,实时的也是只要body,因此head的数据就多存了。如果把parseAsFlumeEvent的参数设置为false,那存到kafka 里面只有一个body,离线和实时也只要body的数据,因此刚刚好,但是第一个框架还有一个拦截器,拦截器和header一起使用,因此不能将header取消,也就是说parseAsFlumeEvent不能设置为false,使用第二个框架比较好性能也好,也满足我们的需求

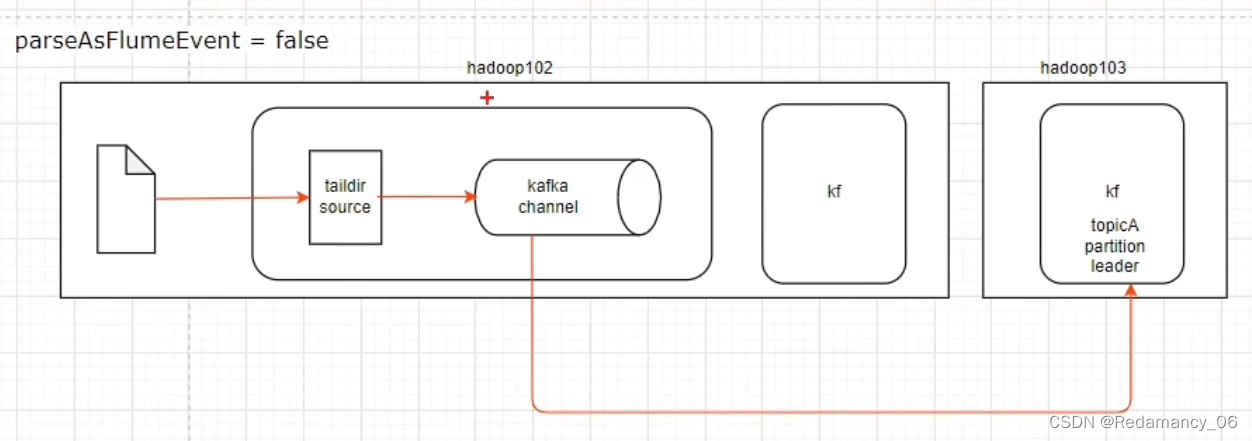
| parseAsFlumeEvent | true | Expecting Avro datums with FlumeEvent schema in the channel. This should be true if Flume source is writing to the channel and false if other producers are writing into the topic that the channel is using. Flume source messages to Kafka can be parsed outside of Flume by using org.apache.flume.source.avro.AvroFlumeEvent provided by the flume-ng-sdk artifact |