你有没有尝试过使用人工智能生成图像?
如果你尝试过,你就会知道,一张好的图像的关键在于一个详细具体的提示。
我不擅长这种详细的视觉提示,所以我依赖大型语言模型来生成详细的提示,然后使用这些提示来生成出色的图像。以下是我能够生成的一些提示和图像的例子:
Prompt: Create a stunning aerial view of Bengaluru, India with the city name written in bold, golden font across the top of the image, with the city skyline and Nandi Hills visible in the background.

Prompt: Design an image of the iconic Vidhana Soudha building in Bengaluru, India, with the city name written in a modern, sans-serif font at the bottom of the image, in a sleek and minimalist style.

为了实现这些结果,我们使用了Flux.1-schnell模型进行图像生成,以及Llamma 3.1 - 8B - Instruct模型来生成提示。这两个模型都托管在一台配备了MIG(多实例 GPU)的单卡 H100 机器上。
这篇博客不是图像生成教程,我们以前已经分享过 Flux 的教程了。这次,我们的目标是创建一个可扩展、安全、全球可访问(且价格合理)的 GenAI 架构。同时,你还将在本文中了解,如何在同一块 H100 GPU 上同时运行 Flux 和 Llamma3 两个模型。
现在中国很多企业都在做大语言模型,就我们接触过的一些公司来讲,哪怕是一些小公司都在利用开源的模型定制自己内部使用的文生图和视频 AI 工具。
想象一下,一个全球化的平台需要为用户快速定制生成图像,或者一个内容平台需要跨地区提供用 AI 生成的文本。
对于开发者来说,想实现这样的架构存在许多挑战。例如:
- GPU 昂贵的价格
- GenAI 工具是尖端技术,每个工具都有特定的配置要求
- 安全地将后端服务器与GenAI服务器连接
- 将全球分布的用户路由到最近的服务器等
这次分享应该能给你提供一个参考和启发,逐一解决这些问题。
架构设计
实现方案
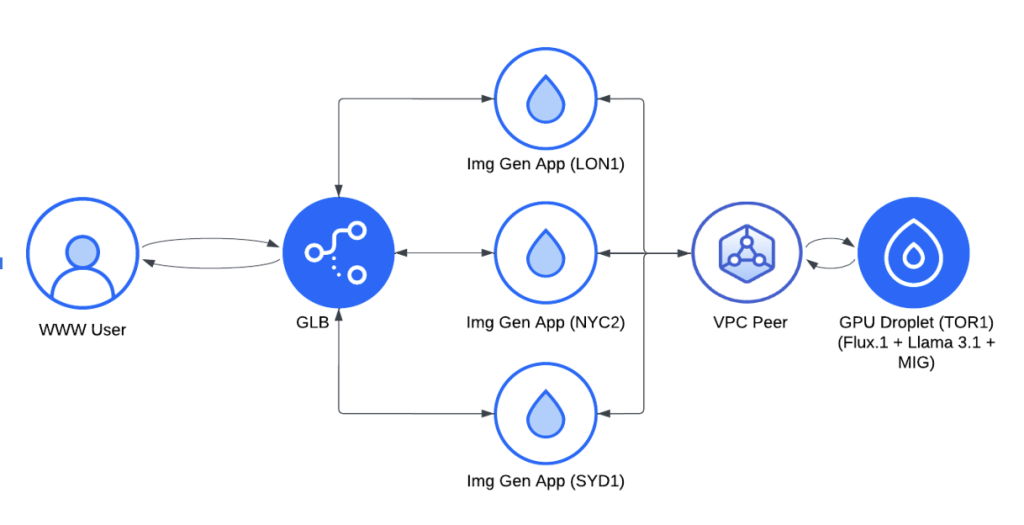
为了实现这一目标,我们设计了一个基于 DigitalOcean 云基础设施的分布式架构。后面我们会解释为什么会选择 DigitalOcean 服务器。以下是这个架构的具体工作原理:
- 我们首先使用全球负载均衡器(GLB)来管理来自不同地区的请求,确保所有用户都能体验到最小的延迟。
- 我们在关键地区(伦敦、纽约和悉尼)部署了轻量级的图像生成应用,每个应用都有自己的缓存,并且可以根据需要连接到 GPU 资源。这些应用通过 VPC 对等连接(有免费的1200 GiB的数据传输流量)安全地通信,将复杂的任务回传到多伦多的 H100 GPU Droplet 服务器上,这些服务器负责处理提Prompt和图像生成的核心任务。
组件详解
在这个架构中,有两个重要的组件 ,一个是轻量级图像生成应用,另一个是 MIG GPU 组件,我们需要解释一下这两个组件。
轻量级图像生成应用
图像生成应用是一个简单的 Python Flask 应用,主要包含三个部分:
1、位置检测模块:这个模块通过浏览器向服务器发送一个虚拟请求,以确定用户的地理位置(城市和国家),并识别哪个服务器区域正在处理该请求。这些信息会显示给用户,并帮助优化提示和图像生成的过程。
2、提示下拉模块:确定用户位置后,应用首先检查缓存中是否有与该位置相关的预存提示。如果找到合适的提示,它们会立即显示在下拉菜单中,供用户选择用于图像生成。如果没有缓存的提示,应用会向大型语言模型(LLM)发送请求生成新的提示,这些提示会被缓存起来以供将来使用,并填充到下拉菜单中供用户选择。
3、生成图像模块:当用户选择一个提示后,应用首先检查是否有从该特定提示生成的图像已缓存。如果有缓存的图像,会直接从磁盘加载,确保更快的响应时间。如果没有缓存的图像,应用会调用 API 生成新的图像,并将其缓存以供未来的请求使用,最后展示给用户。
MIG GPU 组件
MIG(多实例 GPU)是 NVIDIA GPU(如 H100)官方提供的一项功能,它允许将单个物理 GPU 划分为多个独立的实例。每个实例称为一个 MIG 片段,具有独立的计算、内存和带宽资源。
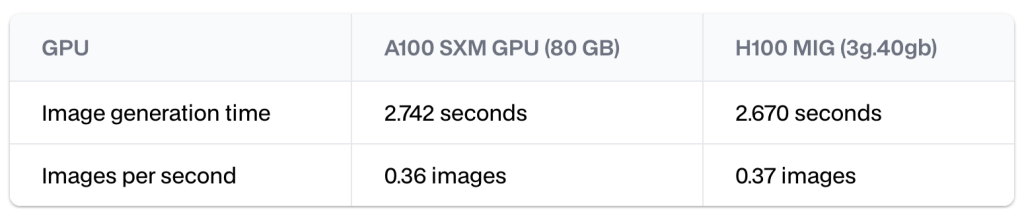
例如,我们可以为每个 H100 GPU 获得两个 H100 MIG 模型,每个模型的计算能力约为完整 GPU 的一半。在一项基准测试中,每个实例通常能在仅需 A100 GPU 80%成本的情况下提供相同甚至超过 A100 GPU 的性能。
这种设计不仅优化了 GPU 的利用率,还使我们能够在同一个 GPU 上并行部署图像生成和提示生成模型。
多实例 GPU (MIG) 如何工作
MIG 是 NVIDIA 在 Ampere 架构中引入的一项技术,同时也支持 Hopper 和 Blackwell 架构。MIG 可以将单个 GPU 划分为多个小的 GPU 实例,每个实例都可以独立运行一个模型服务器。
MIG 的组成
MIG 实例是由 GPU 的物理计算和内存切片组装而成的:
- 7 个计算切片:这些切片均匀划分了芯片上的流式多处理器(SMs)。H100 GPU 拥有 140 个 SMs,这些 SMs 被均匀分配到 7 个切片中,每个切片包含 20 个 SMs。此外,H100 GPU 还有 7 个 NVDEC 和 JPEG 图像解码器,每个切片分配一个。
- 8 个内存切片:这些切片均匀划分了芯片上的显存(VRAM)。每个内存切片有 10 GB 的 VRAM 和 GPU 总内存带宽的八分之一。
7 个计算切片看起来可能有些奇怪,但这并不是因为预留了一部分计算资源用于开销,而是因为 H100 GPU 恰好有 140 个 SMs,这些 SMs 被均匀分成 7 个切片,每个切片包含 20 个 SMs。
实现该架构
在这里我们要开始做一个演示,基于 DigitalOcean 的 GPU Droplet 服务器。DigitalOcean的 H100 GPU 在2024 年底之前仅需 2.5 美元/月/GPU,从成本上来讲非常合算。而且 DigitalOcean 也已经推出了裸金属 GPU 服务器,以供对性能要求更苛刻的 AI 工作任务,比如大型模型的训练和 GenAI 应用。
在进行 Demo 之前,你需要做以下准备:
- DigitalOcean 账户:你需要有一个DigitalOcean 账户,新用户可以获得 200 美元的免费额度,如果你正在做服务器选型,可以用这些额度来做充分的测试。(具体服务器价格可参考官方文档)
- 基本知识:你需要了解 GPU、云网络、VPC(虚拟私有云)和负载均衡的基本概念。
- 基本技能:熟悉 Bash、Docker 和 Python。
- HuggingFace 访问权限:
- 已获得对 Image Generation with Flux.1 模型的访问权限。
- 已获得对 Llama 3.1-8b-Instruct 模型的访问权限。
- vLLM 库:vLLM 是一个快速且易于使用的大型语言模型(LLM)推理和服务库。
Step-by-Step Setup
1. 创建 GPU Droplet
首先,在 DigitalOcean 上创建一个带有单个 H100 GPU 的 GPU Droplet,并选择预装了机器学习开发所需的操作系统镜像。
2. 启用 MIG 模式
GPU Droplet 启动并运行后,启用 MIG(多实例 GPU)模式。MIG 可以将 GPU 划分为多个独立的 GPU 实例,每个实例都是相互隔离的,这对于并行运行不同模型非常重要。
sudo nvidia-smi -i 0 -mig 13. 选择 MIG 配置文件并创建实例
启用 MIG 后,选择一个符合你模型需求的配置文件。
nvidia-smi mig -lgip # 列出所有配置文件例如,创建两个 MIG 实例,每个实例提供 40GB 内存,这应该足够运行两个模型。
sudo nvidia-smi mig -cgi 9,9 -C查看所有 MIG 实例 ID:
nvidia-smi -L4. 在每个 MIG 实例上设置 Docker 容器
对于每个 MIG 实例,运行一个单独的 Docker 容器,分别用于图像生成和提示生成模型。
部署 Flux.1-schnell 用于图像生成
我们使用 metatonic 的图像和代码来部署 Flux.1 的 Docker 镜像。
# 克隆仓库
git clone https://github.com/matatonic/openedai-images-flux
cd openedai-images-flux
# 复制配置文件
cp config.default.json config/config.json
# 运行 Docker 镜像
sudo docker run -d \
-e HUGGING_FACE_HUB_TOKEN="<HF_READ_TOKEN>" \
--runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=<MIG_INSTANCE_ID> \
-v ./config:/app/config \
-v ./models:/app/models \
-v ./lora:/app/lora \
-v ./models/hf_home:/root/.cache/huggingface \
-p 5005:5005 \
ghcr.io/matatonic/openedai-images-flux使用 vLLM 部署 Llama 3.1 用于提示生成
下载并运行用于提示生成模型的 Docker 容器。
sudo docker run -d --runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=<MIG_INSTANCE_ID> \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HUGGING_FACE_HUB_TOKEN="<HF_READ_TOKEN>" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model meta-llama/Meta-Llama-3.1-8B-Instruct5. 模型访问和通信
每个容器通过指定的端口访问,允许图像生成应用实例连接并发送请求到图像生成模型(Flux.1-schnell)或提示生成模型(Llama 3.1)。MIG 分区确保两个模型高效并发运行,互不干扰。
6. 设置区域应用实例
在伦敦、纽约和悉尼等区域位置设置轻量级应用实例,以本地处理用户请求,缓存频繁访问的提示和图像,加快响应速度。
- 通过 DigitalOcean 控制台的 Droplets 部分在某个区域创建 Droplet。
- SSH 登录并设置代码。为了加快速度,我已经创建了一个容器,只需要确保有 DigitalOcean 容器注册表的访问权限并拉取镜像。
# 登录到 Docker 注册表
sudo docker login registry.digitalocean.com
# 拉取容器
sudo docker pull registry.digitalocean.com/<cr_name>/city-image-generator:v2- 创建快照并将 Droplet 部署到其他区域。
# 运行容器
sudo docker run -d -p 80:80 registry.digitalocean.com/<cr_name>/city-image-generator:v2- 在其他区域创建其他 Droplet 并运行容器。
7. 设置 VPC Peering
VPC Peering 确保区域应用实例与多伦多的 GPU 服务器之间通过私有网络进行安全、低延迟的通信。
- 进入 DigitalOcean 控制台的 Networking 部分。
- 查看每个区域的默认 VPC(例如伦敦、纽约、悉尼和多伦多)。
- 使用 VPC Peering 功能建立多伦多 VPC 与其他区域 VPC 的连接。
- 使用简单的网络工具(如
ping或curl)验证连接。
8. 设置全局负载均衡器 (GLB)
全局负载均衡器 (GLB) 将用户请求分发到最近的区域应用实例,优化延迟并提升用户体验。
- 进入 DigitalOcean 控制台的 Networking 部分的 Load Balancers 部分。
- 创建一个新的全局负载均衡器。
- 将区域应用实例添加为后端目标。
- 配置健康检查、超时和其他高级设置。
- 创建负载均衡器。
写在最后
这个示例适用于探索分布式 GenAI 解决方案的企业和开发者,例如生成个性化内容的广告平台、社交平台、电商平台,或服务于全球受众的 AI 内容平台。通过利用 DigitalOcean 的产品,我们展示了如何在部署前沿 AI 服务时平衡可扩展性、安全性和成本效益。
如果你需要了解 DigitalOcean 的 GPU Droplet或裸金属 GPU 服务器,可与 DigitalOcean 中国区独家战略合作伙伴卓普云联系。
如果需要了解更多关于 AI、云架构的开发,可关注我们的博客。