声明:非广告,纯用户体验
1. CogVideoX
CogVideoX 是智谱 AI 推出的一款极具创新性与突破性的视频生成产品。它在技术层面展现出诸多卓越特性,例如其采用的 Diffusion + Transformer(DiT)架构奠定了强大的生成能力基础,而自主研发的 3D VAE 三维变分自编码器结构不仅能将原始视频数据大幅压缩至仅 2% 的大小,有效降低训练成本与难度,还结合 3D RoPE 位置编码模块显著提升在时间维度上捕捉帧间关系的能力,让生成的视频在时间流转上更加自然流畅。
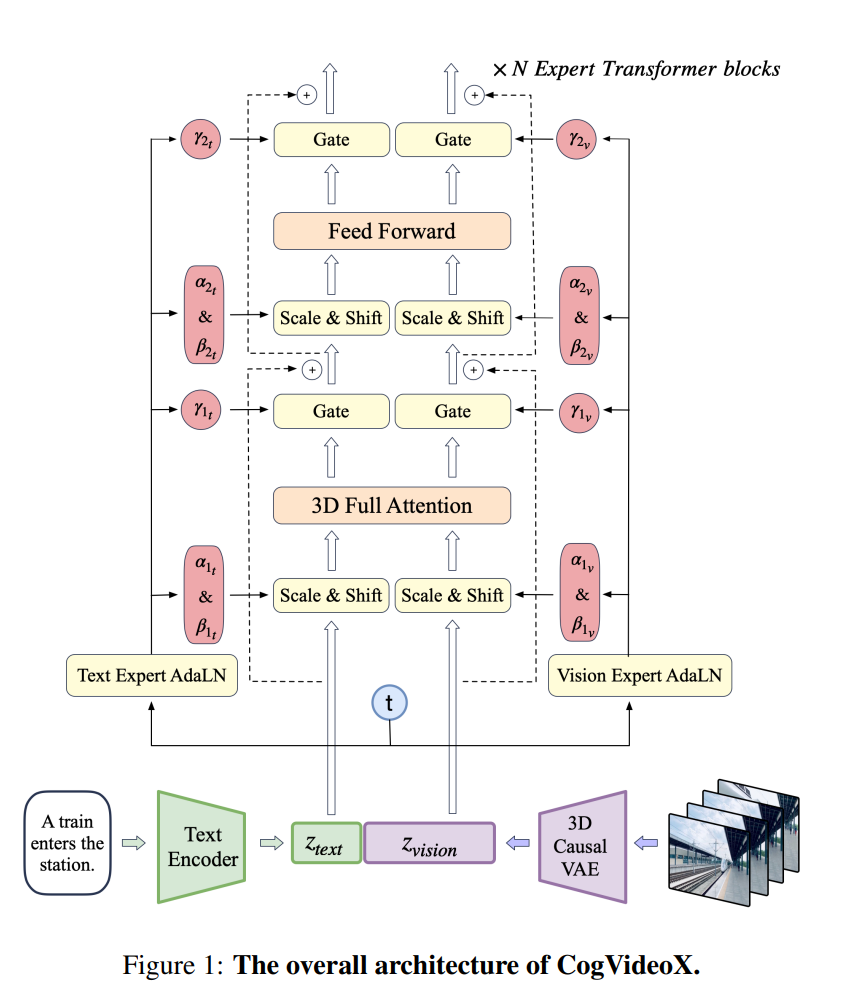
其专家 Transformer 架构摒弃传统 cross attention 模块,在输入阶段巧妙地将文本 embedding 和视频 embedding 连接,借助 expert adaptive layernorm 弥补文本与视频模态间的差异,同时采用 3D 全注意力机制与 3D RoPE 位置编码模块,全方位强化视觉与语义信息的对齐效果,极大提升对复杂提示词的理解与呈现能力,能够创作出内容连贯性极佳、镜头调度丰富且人物表演细腻的视频。
![]()
在性能表现方面,它能够生成 10 秒时长、4K 分辨率、60 帧的超高清视频,且支持任意尺寸,无论是宽屏还是常规比例都能精准呈现,同一指令或图片可一次性生成 4 个视频,极大地丰富了创作的多样性与效率。
此外CogVideoX 涵盖了多个重要领域,在内容创作方面助力专业创作者和普通爱好者高效产出各类创意视频,无论是广告、剧情短片还是娱乐短视频;在教育教学中可生动地将知识转化为可视化的教学视频,增强教学效果与吸引力;在商业广告领域能根据品牌需求快速打造个性化的宣传视频,提升广告投放的影响力
同时借助其强大的文本、图像、视频分析能力,快速准确地过滤违规信息,保障平台内容安全;在多模态搜索引擎里利用图像与视频理解能力优化搜索结果呈现;在智能宠物监控场景下通过视频分析与动作识别技术协助主人远程照看宠物。
智谱 AI 还积极推动其开源进程,如 CogVideoX v1.5 - 5B、CogVideoX v1.5 - 5B - I2V 已在 GitHub 开源,并且其模型已在智谱清言的多端应用上线,用户可通过 “清影” 功能免费体验其从文本或图像生成视频的精彩服务,为广大用户和开发者开启了一扇通往高效、智能视频创作的全新大门,对推动视频生成技术在众多领域的应用与发展有着极为深远的意义。
接下来演示一下怎么通过丹摩平台使用 CogVideoX 来生成视频
2. 创建实例
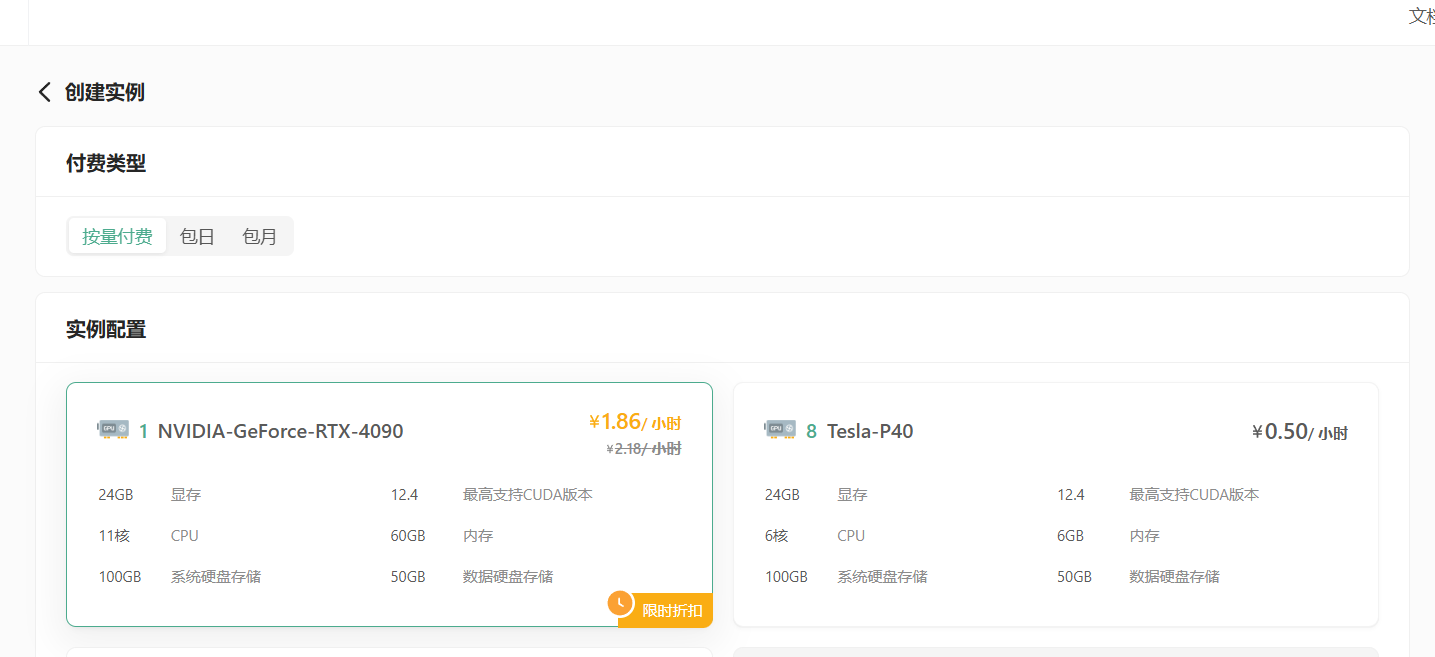
首先登录丹摩平台,进入创建页面后,首先在实例配置中选择付费类型,一般短期需求的话可以选择按量付费或者包日,我们这里做个演示就直接选择按量付费了,长期需求可以选择包月套餐;其次选择单卡或多卡启动,然后选择需求的 GPU 型号
以下是以下配置的介绍:
| 显卡 | 显存-GB | 内存-GB/卡 | CPU-核心/卡 | 存储 | 简介 |
| RTX 4090 | 24 | 60 | 11 | 100G系统盘 | 性价比配置,推荐入门用户选择,适合模型推理场景 |
| RTX 4090 | 24 | 124 | 15 | 100G系统盘 | 性价比配置,推荐入门用户与专业用户选择,适合模型推理场景 |
| H800 SXM | 80 | 252 | 27 | 100G系统盘 | 顶级配置,推荐专业用户选择,适合模型训练与模型推理场景 |
| H800 PCle | 80 | 124 | 21 | 100G系统盘 | 顶级配置,推荐专业用户选择,适合模型训练与模型推理场景 |
| L40S | 48 | 124 | 21 | 100G系统盘 | 专业级配置,推荐专业用户选择,适合模型训练与模型推理场景 |
| P40 | 24 | 12 | 6 | 100G系统盘 | 性价比配置,推荐入门用户选择,适合模型推理场景 |
由于 CogVideoX 在 FP-16 精度下的推理至少需 18GB 显存,微调则需要 40GB 显存,这里创建实例比较推荐的选择:按量付费-- GPU 数量 1(表示单卡启动,最高可支持 8 卡组合启动,处理速度也会大大提升)--NVIDIA-GeForc-RTX-4090,该配置为 60GB 内存,24GB 的显存。
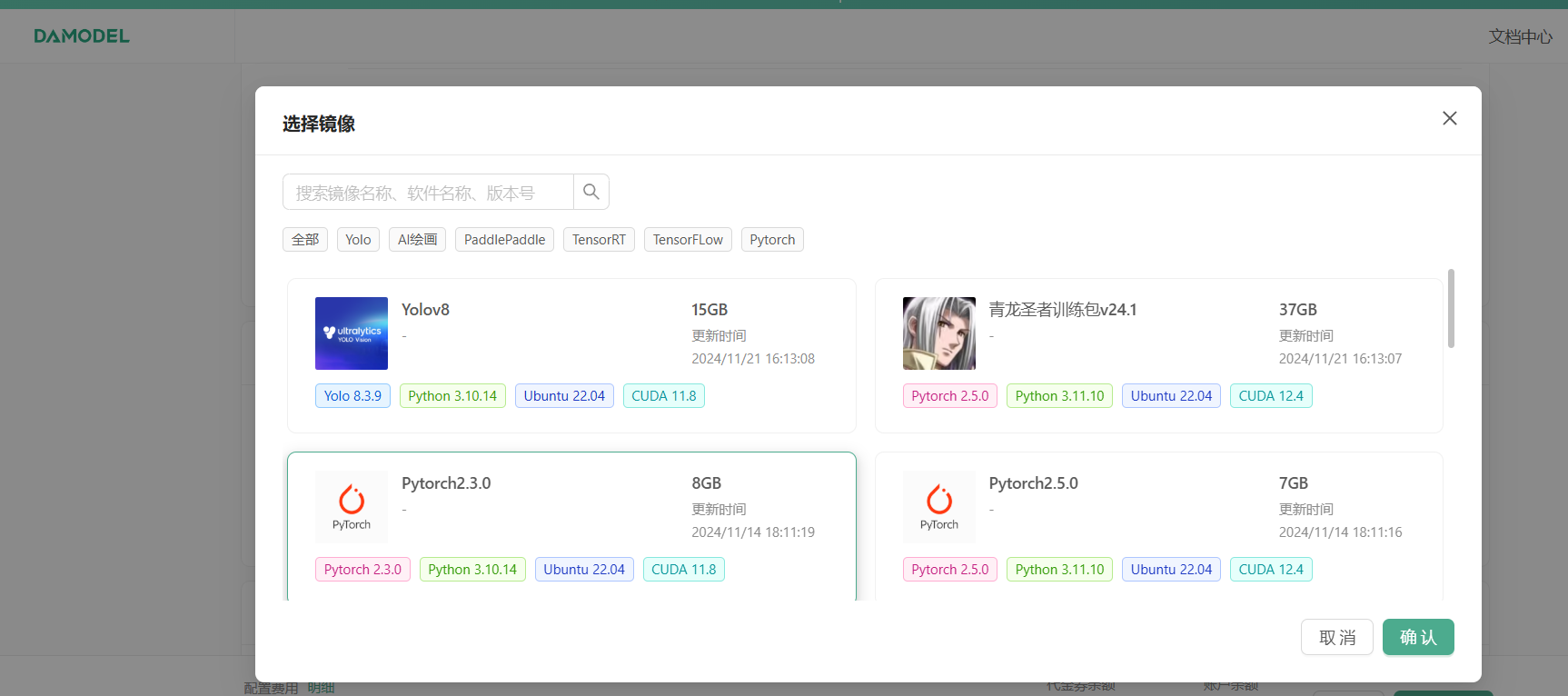
接下来,配置数据硬盘的大小,每个实例默认附带了 50GB 的数据硬盘,首次创建可以就选择默认大小 50GB,也是足够用的,可以看到,平台提供了一些基础镜像供快速启动,第一次创建可以选择基础镜像,如果后续有保存镜像,可以在我的镜像中选择保存好的镜像启动,镜像选择 PyTorch2.3.0、Ubuntu-22.04,CUDA12.1 镜像。
接下来创建密钥,密钥名称自定义,首次创建实例需要创建密钥对,后续创建可以沿用已经创建的密钥对,点击确认之后生成的密钥就会下载到本地
创建之后就可以选择刚刚创建好的密钥对,然后点击立即创建,稍等片刻就会创建成功
平台还提供了在线访问实例的 JupyterLab 入口,JupyterLab 是一个交互式的开发环境,具有灵活而强大的用户界面。用户可以使用它编写 notebook、操作终端、编辑 markdown 文本、打开交互模式、查看 csv 文件及图片等。
3. 配置环境和依赖
官方代码仓库为:GitHub - THUDM/CogVideo: text and image to video generation: CogVideoX (2024) and CogVideo (ICLR 2023)
基于官方代码仓库的配置方法推荐您阅读:国产版Sora复现——智谱AI开源CogVideoX-2b 本地部署复现实践教程-CSDN博客
进入 JupyterLab 后,打开终端,首先拉取 CogVideo 代码的仓库
wget http://file.s3/damodel-openfile/CogVideoX/CogVideo-main.tar
下载完成后解压缩CogVideo-main.tar
tar -xf CogVideo-main.tar
其次,进入 CogVideo-main 文件夹,输入安装对应依赖:
cd CogVideo-main/
pip install -r requirements.txt4. 模型与配置文件
除了配置代码文件和项目依赖,还需要上传 CogVideoX 模型文件和对应的配置文件。
官方模型仓库: https://huggingface.co/THUDM/CogVideoX-2b/tree/main
仓库地址
平台已经预置了 CogVideoX 模型,直接执行以下命令进行下载:
cd /root/workspace
wget http://file.s3/damodel-openfile/CogVideoX/CogVideoX-2b.tar解压之后点进 CogVideoX-2b 文件,类似于一下内容
5. 开始运行
5.1. 调试
进入 CogVideo-main文件夹,首先需要创建一个 test.py 文件,test.py 代码内容如下,主要使用diffusers库中的 CogVideoXPipeline模型,加载了一个预训练的 CogVideo 模型,然后根据一个详细的文本描述(prompt),生成对应视频:
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
# prompt里写自定义想要生成的视频内容
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."
pipe = CogVideoXPipeline.from_pretrained(
"/root/workspace/CogVideoX-2b", # 这里填CogVideo模型存放的位置,此处是放在了数据盘中
torch_dtype=torch.float16
).to("cuda")
# 参数do_classifier_free_guidance设置为True可以启用无分类器指导,增强生成内容一致性和多样性
# num_videos_per_prompt控制每个prompt想要生成的视频数量
# max_sequence_length控制输入序列的最大长度
prompt_embeds, _ = pipe.encode_prompt(
prompt=prompt,
do_classifier_free_guidance=True,
num_videos_per_prompt=1,
max_sequence_length=226,
device="cuda",
dtype=torch.float16,
)
video = pipe(
num_inference_steps=50,
guidance_scale=6,
prompt_embeds=prompt_embeds,
).frames[0]
export_to_video(video, "output.mp4", fps=8)运行test.py文件,运行成功后,可以在当前文件夹中找到对应 prompt 生成的 output.mp4 视频

5.2. webUI
模型官方也提供了 webUIDemo,进入CogVideo-main文件夹,运行gradio_demo.py文件:
cd /root/workspace/CogVideo-main
python gradio_demo.py
- 模型官方提供了 webUIDemo。进入 CogVideo - main 文件夹,运行 gradio_demo.py 文件:cd /root/workspace/CogVideo - main,python gradio_demo.py
- 运行后访问路径是本地 url : http://0.0.0.0:7870。此时需通过丹摩平台提供的端口映射能力,把内网端口映射到公网。
- 进入 GPU 云实例页面,点击操作 - 更多 - 访问控制,点击添加端口,添加 7870 端口,添加成功后,通过访问链接即可访问到刚刚启动的 gradio 页面。