📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


❀ 融入模糊规则的宽度神经网络结构
- 论文概述
- 创新点及贡献
- 算法流程讲解
- 核心代码复现
- main.py文件
- FBLS.py文件
- 使用方法
- 测试结果
- 示例:使用公开数据集进行本地训练
- 准备数据
- 定义数据转换(预处理)
- 下载并加载训练数据集
- 下载并加载测试数据集
- 将每张图片展平并检查加载的数据
- 将每张图片展平
- 将整个训练集展平
- 将整个测试集展平
- 将数据转换为DataFrame并保存为CSV文件
- 数据输入模型进行训练
- 实验结果
- 环境配置
论文概述
今天来给大家讲解一篇发表在中科院一区顶级期刊上《IEEE Transactions on Cybernetics》的有关于目前人工智能计算机视觉新方向(宽度学习)的文章。作者在这篇文章中基于宽度神经网络提出了一种改进的新模型,融入了模糊规则来提高模型对特殊特征的分辨能力。由于模糊规则的复杂性,本博客用了比较多的博客来讲述,如果大家觉得太难,可以直接下载附件代码先跑起来,从代码入手再回来看数学公式会更直接一点。
该论文的作者团队介绍了一种创新的神经模糊模型,即模糊宽度学习系统(简称BLS),这一系统是通过将Takagi-Sugeno(TS)模糊逻辑融入BLS架构中而创建的。在模糊BLS中,传统的BLS特征节点被一系列TS模糊子系统所取代,这些子系统各自负责处理输入数据。不同于直接将各个模糊子系统生成的模糊规则输出简单汇总为一个结果,模糊BLS选择将它们全部传输至一个增强层,进行更深层次的非线性处理,以此来保持输入数据的特性。最终,模糊子系统的去模糊化输出与增强层的输出相结合,共同决定了模型的输出结果。模糊子系统前件部分所使用的高斯隶属函数的中心以及模糊规则的数量,均通过k-means聚类方法来确定。在模糊BLS中,需要计算的参数主要包括连接增强层输出与模型输出的权重,以及模糊子系统后件部分多项式的随机初始化系数,这些参数都可以通过直接求解的方法得到。因此,模糊BLS依然保持了BLS在处理速度上的优势。
该模糊BLS通过一些流行的回归和分类基准进行评估,并与一些最先进的非模糊和神经模糊方法进行比较。结果表明,模糊BLS在性能上优于其他模型。此外,模糊BLS在模糊规则数量和训练时间方面也优于神经模糊模型,在一定程度上缓解了规则爆炸的问题。
本文所涉及的所有资源的获取方式:这里
创新点及贡献
为了建立一个名为模糊BLS的新神经模糊模型,他们用Takagi-Sugeno(TS)模糊子系统代替BLS左部的特征节点。模糊BLS的显著特征与其他神经模糊方法不同,其创新点如下。
模糊BLS构建于一组一阶TS模糊子系统之上,每个子系统均负责处理输入数据。该系统的独特之处在于,所有模糊子系统均参与构建模糊BLS的最终输出,从而充分利用了这种“集体智慧”架构的优势。
我们采用k均值算法对输入数据进行聚类,并据此为每个模糊子系统确定模糊规则的数量以及前件部分高斯隶属函数的中心。得益于k均值算法的特性,每个模糊子系统都能从训练数据中提取出不同的中心,确保产生多样化的结果,从而尽可能全面地捕捉输入数据的信息。
在模糊BLS中,模糊规则产生的输出并不会被立即汇总。相反,所有模糊子系统生成的中间值会被整合成一个向量,并直接传递给增强节点进行非线性转换。随后,结合增强层的输出以及模糊子系统的去模糊化输出,共同生成模型的最终输出。
模糊BLS的参数设定包括连接增强层输出到最终输出层的权重,以及每个模糊子系统中模糊规则后件部分的系数。这些参数可以通过高效的伪逆计算快速得出,从而确保模糊BLS在保持BLS快速计算特性的同时,也能实现精确的输出。
算法流程讲解
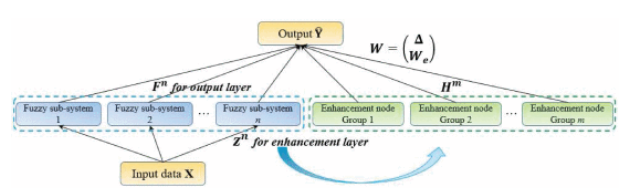
模糊广义学习系统(FBLS)基于随机向量功能链接神经网络和伪逆理论的架构。该设计使系统能够快速且渐进地学习,并且在无需重新训练的情况下重新建模。FBLS模型如图3所示,包含输入层、模糊子系统层、增强节点复合层和输出层。在复合层中,使用模糊规则从输入数据生成多个模糊子系统。这些模糊子系统随后被增强为增强节点,每个节点具有不同的随机权重。通过将所有特征和增强节点连接到输出层来计算输出。
模糊广义学习系统的主要概念是将输入数据映射到一组模糊规则中,然后利用BLS算法学习和优化这些规则的权重和参数。这些模糊规则由模糊集及其对应的隶属函数组成,这些函数描述了输入和输出之间的模糊关系。通过采用模糊逻辑推理,系统可以基于输入数据的模糊表示进行预测和分类。
FBLS是一种结合了随机向量功能链接神经网络和伪逆理论的神经网络模型。该设计允许系统快速学习和适应,无需重新训练。如图3所示,该模型由输入层、模糊子系统层、增强层和输出层组成。在模糊子系统层,使用模糊规则从输入数据生成多个模糊子系统。这些模糊子系统随后使用随机权重转换为增强节点。通过将所有模糊子系统和增强节点连接到输出层来计算输出。





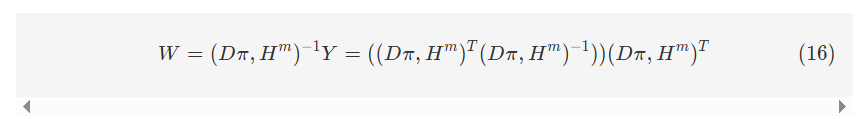
核心代码复现
本人在复现时用三个文件来完成本次项目,分别是main.py文件作为顶层文件调用所有函数和方法;utils.py文件作为工具文件,封装了一些所需要用到的方法;FBLS.py文件中实现了Fuzzy规则和BLS结合的新型宽度神经网络模型——FBLS,下面我们将分别给出他们的伪代码来进一步帮大家理解。
main.py文件
开始
|
|---> 导入 numpy 和 scipy.io 中的 loadmat 和 savemat 函数
|---> 导入 random 和 FBLS 模块中的 bls_train 函数
|
|---> 定义主函数 main():
| |
| |---> 从 MATLAB 文件 'wbc.mat' 中加载数据
| | data = loadmat('wbc.mat')
| | train_x = data['train_x']
| | train_y = data['train_y']
| | test_x = data['test_x']
| | test_y = data['test_y']
| |
| |---> 转换测试集
| | n = 随机生成一个置换数组,长度为 test_x.shape[0]
| | 使用置换数组 n 的前 140 行来更新 test_x 和 test_y,并将它们转换为 np.float64 类型
| | train_y 和 test_y 转换为二元标签 (-1, +1)
| |
| |---> 初始化常数和变量
| | C = 2 ** -30
| | s = 0.8
| | best = 0.72
| | result = 空列表
| |
| | NumRule = 2
| | NumFuzz = 6
| | NumEnhan = 20
| |
| |---> 设置随机种子为 1,生成 Alpha 和 WeightEnhan
| | Alpha = 空列表
| | 对于 i 从 0 到 NumFuzz-1:
| | 生成大小为 (train_x.shape[1], NumRule) 的随机数组 alpha
| | 将 alpha 添加到 Alpha
| |
| | 生成大小为 (NumFuzz * NumRule + 1, NumEnhan) 的随机数组 WeightEnhan
| |
| |---> 打印模糊规则数、模糊系统数和增强器数
| | 打印字符串 'Fuzzy rule No.= {NumRule}, Fuzzy system No. ={NumFuzz}, Enhan. No. = {NumEnhan}'
| |
| |---> 调用 bls_train 函数进行模型训练和测试
| | 调用 bls_train(train_x, train_y, test_x, test_y, Alpha, WeightEnhan, s, C, NumRule, NumFuzz)
| | 返回 NetoutTest, Training_time, Testing_time, TrainingAccuracy, TestingAccuracy
| |
| |---> 计算总时间,并将结果保存到 result 列表中
| | total_time = Training_time + Testing_time
| | 将 [NumRule, NumFuzz, NumEnhan, TrainingAccuracy, TestingAccuracy] 添加到 result 列表
| |
| |---> 如果 TestingAccuracy 比 best 大,则更新 best,并将结果保存到 'optimal.mat' 文件中
| | 如果 best < TestingAccuracy:
| | 更新 best 为 TestingAccuracy
| | 将 {'TrainingAccuracy': TrainingAccuracy, 'TestingAccuracy': TestingAccuracy,
| | 'NumRule': NumRule, 'NumFuzz': NumFuzz, 'NumEnhan': NumEnhan, 'time': total_time}
| | 保存到 'optimal.mat'
| |
| |---> 将 result 列表保存到 'result.mat' 文件中
| | 将 {'result': np.array(result)} 保存到 'result.mat'
| |
| |---> 打印字符串 'Results saved!'
|
|---> 如果运行在主模块下:
| 调用主函数 main()
|
结束
在main.py文件中,我们将FBLS模型封装在bls_train函数中,加载好数据集之后输入模型中进行训练,并编写代码对输出的结果进行测试,打印出评价指标。
FBLS.py文件
开始
|
| 返回 2 / (1 + exp(-2 * x)) - 1
|
|---> 函数 result_tra(output):
| 返回 argmax(output, axis=1)
|
|---> 函数 bls_train(train_x, train_y, test_x, test_y, Alpha, WeightEnhan, s, C, NumRule, NumFuzz):
| |
| |---> std = 1
| |---> 记录开始时间
| |
| |---> 设置 H1 为 train_x
| |---> 初始化 y 为大小 (train_x.shape[0], NumFuzz * NumRule) 的零矩阵
| |---> 初始化 CENTER 为一个空列表
| |---> 初始化 ps 为一个空列表
| |
| |---> 循环 i 从 0 到 NumFuzz-1:
| | |
| | |---> 设置 b1 为 Alpha[i]
| | |---> 初始化 t_y 为大小 (train_x.shape[0], NumRule) 的零矩阵
| | |---> 使用 NumRule 个聚类对 train_x 进行 KMeans 聚类,并将中心设置为聚类中心
| | |
| | |---> 循环 j 从 0 到 train_x.shape[0]-1:
| | | |
| | | |---> 计算 MF 为 exp(-sum((train_x[j, :] - center) ** 2) / std)
| | | |---> 将 MF 归一化
| | | |---> 设置 t_y[j, :] 为 MF * (train_x[j, :].dot(b1))
| | |
| | |---> 将 center 添加到 CENTER
| | |---> 初始化 scaler 为范围 (0, 1) 的 MinMaxScaler
| | |---> 使用 scaler 对 t_y 进行拟合和变换,并将结果设置为 T1
| | |---> 将 scaler 添加到 ps
| | |---> 设置 y[:, NumRule * i:NumRule * (i + 1)] 为 T1
| |
| |---> 将 y 与一个全为 0.1 的列连接起来形成 H2
| |---> 计算 T2 为 H2 dot WeightEnhan
| |---> 设置 l2 为 s / max(T2)
| |---> 对 T2 乘以 l2 应用 tansig
| |---> 将 y 与 T2 连接起来形成 T3
| |
| |---> 计算 beta 为 inverse(T3.T dot T3 + eye(T3.shape[1]) * C) dot T3.T dot train_y
| |---> 记录训练时间
| |---> 打印 'Training has been finished!' 和训练时间
| |---> 计算 NetoutTrain 为 T3 dot beta
| |
| |---> 设置 yy 为 result_tra(NetoutTrain)
| |---> 设置 train_yy 为 result_tra(train_y)
| |---> 计算 TrainingAccuracy 为 mean(yy == train_yy)
| |---> 打印训练准确率
| |
| |---> 记录开始时间
| |
| |---> 设置 HH1 为 test_x
| |---> 初始化 yy1 为大小 (test_x.shape[0], NumFuzz * NumRule) 的零矩阵
| |
| |---> 循环 i 从 0 到 NumFuzz-1:
| | |
| | |---> 设置 b1 为 Alpha[i]
| | |---> 初始化 t_y 为大小 (test_x.shape[0], NumRule) 的零矩阵
| | |---> 设置 center 为 CENTER[i]
| | |
| | |---> 循环 j 从 0 到 test_x.shape[0]-1:
| | | |
| | | |---> 计算 MF 为 exp(-sum((test_x[j, :] - center) ** 2) / std)
| | | |---> 将 MF 归一化
| | | |---> 设置 t_y[j, :] 为 MF * (test_x[j, :].dot(b1))
| | |
| | |---> 设置 scaler 为 ps[i]
| | |---> 使用 scaler 变换 t_y 并将结果设置为 TT1
| | |---> 设置 yy1[:, NumRule * i:NumRule * (i + 1)] 为 TT1
| |
| |---> 将 yy1 与一个全为 0.1 的列连接起来形成 HH2
| |---> 对 HH2 dot WeightEnhan 乘以 l2 应用 tansig
| |---> 将 yy1 与 TT2 连接起来形成 TT3
| |
| |---> 计算 NetoutTest 为 TT3 dot beta
| |---> 设置 y 为 result_tra(NetoutTest)
| |---> 设置 test_yy 为 result_tra(test_y)
| |---> 计算 TestingAccuracy 为 mean(y == test_yy)
| |---> 记录测试时间
| |---> 打印 'Testing has been finished!' 和测试时间
| |---> 打印测试准确率
| |
| |---> 返回 NetoutTest, Training_time, Testing_time, TrainingAccuracy, TestingAccuracy
|
结束
在FBLS.py文件中,我们完整地复现了FBLS模型的代码,依照上面提到的算法流程一比一实现了FBLS从输入数据到输出测试结果的过程。
使用方法
在FBLS.py文件中我们已经封装好了结果,因此我们可以直接在main.py文件中调用我们想要的数据集并进行训练。
首先,我们需要把本地的数据集放入到当前目录中然后修改数据集名称为大家本地的数据集名称,或者给出它的绝对路径:data=loadmat(‘文件名的绝对路径’)
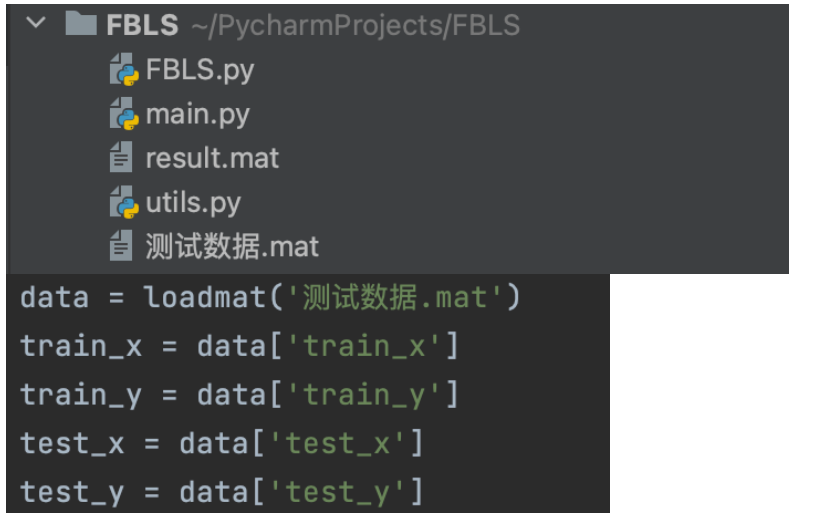
这里我们的数据集中有四个变量:train_x,train_y,test_x,test_y,分别存储的训练集的数据、标签和测试集的数据、标签,标签采用独热编码。
然后在这里,我们可以修改模型的超参数(模糊规则数、模糊节点数和增强层数量)来使我们的模型拟合到最优结果

接下来就可以得到我们输出的结果啦,训练精度、测试精度、训练时间、测试时间都会被打印出来,大家如果想多使用一些评价指标,也可以自行添加需要的指标,具体方法可以参考我之前的博客。
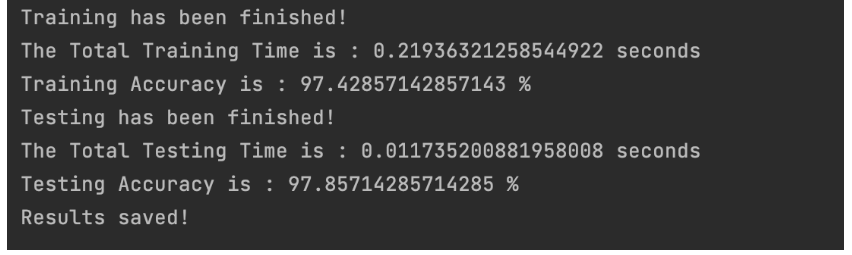
测试结果
在一次训练测试结束后,我们可以看到最后的结果,训练精度和测试精度都可以达到97%。
我们可以修改一下超参数,让 NumRule = 10,NumFuzz = 20,NumEnhan = 100
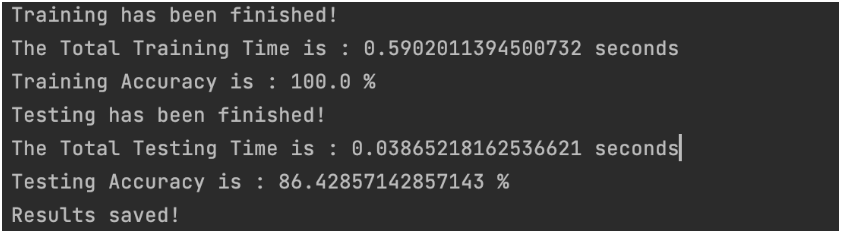
可以看到现在模型训练精度虽然达到了100%,但是测试精度出现了下降,这就说明我们参数调的太大让模型出现了过拟合现象,具体的调参大家可以根据自己的数据集来调整。
示例:使用公开数据集进行本地训练
有了复现代码之后,大家肯定很感兴趣我们应该怎么利用这个复现好的模型来在公开数据集上进行本地训练呢,这样才能推进我们的研究。这里我就以MNIST数据集为例教大家如何利用这份代码来进行在公开数据集上的训练
准备数据
首先我们需要将想要用到的数据集导入到本地环境中,
import ssl import torch from torchvision import datasets, transforms from torch.utils.data import DataLoader import pandas as pd
ssl._create_default_https_context = ssl._create_unverified_context
定义数据转换(预处理)
transform = transforms.Compose([ transforms.Resize((10, 10)), transforms.ToTensor(), # 转换为Tensor # transforms.Normalize((0.1307,), (0.3081,)) # 归一化 ])
下载并加载训练数据集
train_dataset = datasets.MNIST(root=‘./data’, train=True, download=True, transform=transform) train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
下载并加载测试数据集
test_dataset = datasets.MNIST(root=‘./data’, train=False, download=True, transform=transform) test_loader = DataLoader(dataset=test_dataset, batch_size=1000, shuffle=False)
现在很多公开数据集都提供了第三方库的内置接口,如上面的代码,我们可以很方便地直接使用代码将数据导入到本地环境中。这份MNIST公开数据集中包含70000张首先数字签名的图片,其中60000张被用作训练集,10000张被用作测试集。这里为了适应我们的模型,我们需要对图像数据做一些处理,我们将图像调整为10*10的大小,并将其按照像素点进行展平,将展平后的像素点作为每一个样本的特征,也就是说我们最后会得到训练数据格式为(60000,100),测试数据格式为(10000,100)的数据集用于实验。
将每张图片展平并检查加载的数据
examples = enumerate(train_loader) batch_idx, (example_data, example_targets) = next(examples)
将每张图片展平
flat_example_data = example_data.view(example_data.size(0), -1)
print(flat_example_data.shape) # 应该输出 (64, 784) print(example_targets.shape) # 应该输出 (64,)
将整个训练集展平
all_flat_train_data = [] all_train_targets = []
for batch_idx, (data, targets) in enumerate(train_loader): flat_data = data.view(data.size(0), -1) all_flat_train_data.append(flat_data) all_train_targets.append(targets)
all_flat_train_data = torch.cat(all_flat_train_data) all_train_targets = torch.cat(all_train_targets)
print(all_flat_train_data.shape) print(all_train_targets.shape) # 应该输出 (60000,)
将整个测试集展平
all_flat_test_data = [] all_test_targets = []
for batch_idx, (data, targets) in enumerate(test_loader): flat_data = data.view(data.size(0), -1) all_flat_test_data.append(flat_data) all_test_targets.append(targets)
all_flat_test_data = torch.cat(all_flat_test_data) all_test_targets = torch.cat(all_test_targets)
print(all_flat_test_data.shape) print(all_test_targets.shape) # 应该输出 (10000,)
将数据转换为DataFrame并保存为CSV文件
train_df = pd.DataFrame(all_flat_train_data.numpy()) train_df[‘label’] = all_train_targets.numpy() train_df.to_csv(‘mnist_train_flattened.csv’, index=False)
test_df = pd.DataFrame(all_flat_test_data.numpy()) test_df[‘label’] = all_test_targets.numpy() test_df.to_csv(‘mnist_test_flattened.csv’, index=False)
print(“数据已成功保存到CSV文件中。”)
数据输入模型进行训练
接下来我们可以选择多种方式将数据输入到模型中进行训练,我这里选择的是先将处理好的数据保存到csv文件中,然后输入的时候将其读出来导入环境中。 保存:
将数据转换为DataFrame并保存为CSV文件 train_df = pd.DataFrame(all_flat_train_data.numpy()) train_df[‘label’] = all_train_targets.numpy() train_df.to_csv(‘mnist_train_flattened.csv’, index=False) test_df = pd.DataFrame(all_flat_test_data.numpy()) test_df[‘label’] = all_test_targets.numpy() test_df.to_csv(‘mnist_test_flattened.csv’, index=False)
导入:
train_data = pd.read_csv(‘mnist_train_flattened.csv’) test_data = pd.read_csv(‘mnist_test_flattened.csv’) train_x = train_data.drop(‘label’, axis=1).values train_y = convert_onehot(train_data[‘label’].values).astype(int) test_x = test_data.drop(‘label’, axis=1).values test_y = convert_onehot(test_data[‘label’].values).astype(int)
接下来的步骤就如跟上述使用测试数据的逻辑一样
实验结果
接下来我们来看看使用FBLS进行MNIST数据集分类的效果,本次我主要测试了随着各个节点数的上升,FBLS的效果会有什么变化,结果如下图:
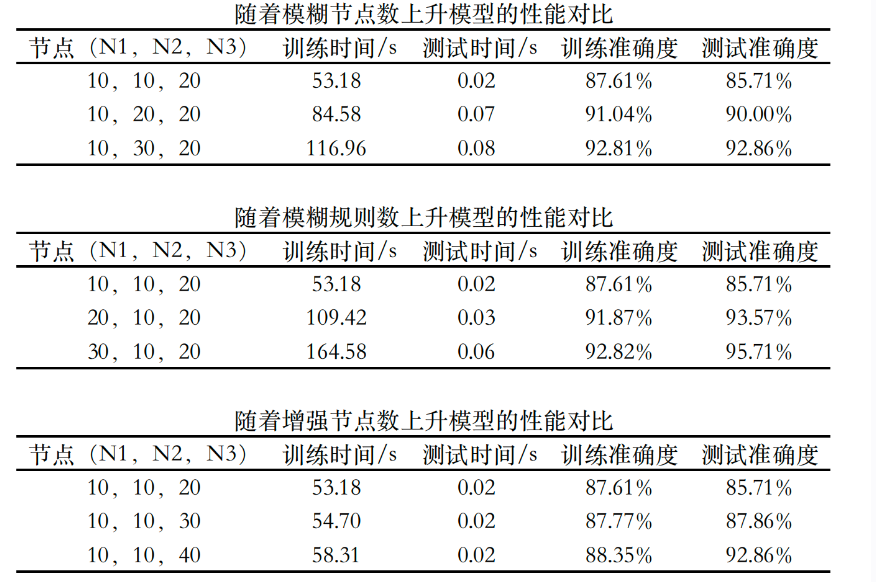
模型的分类准确率基本在90%左右,可以看到固定其他变量不变,模糊节点数、模糊规则数和增强节点数的增加都会带来模型性能的提升,但相应的训练时间也会一定程度的增加。
需要注意的是上表可以看作是对FBLS三个关键性参数的敏感性测试,FBLS的参数调节比较粗略,其分类最优值其实可以达到更优,目前我手调能达到的值已经到了97%,大家也可以多多尝试更广泛的参数看看是否可以收敛的更好,对MNIST数据集进行实验的代码我也一并放在了附件代码中,大家可以下载下来好好研究。
环境配置
- 本次使用的python版本最好为python3.8及以上- 使用的库函数包括numpy、scipy、sklearn和random
成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
“每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。”
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里