目录
一、磁盘简介
(一)、认知磁盘
(1)结构
(2)物理设备的命名规则
(二)、磁盘分区方式
MBR分区
MBR分区类型
扩展
GPT格式
lsblk命令
使用fdisk管理分区
使用gdisk管理分区
拓展
格式化
blkid命令
挂载
umount命令
特殊挂载
挂载大文件
查看磁盘空间使用量
df命令
du命令
RAID
RAID0
RAID1
RAID5
RAID10 (主流)
mdadm命令
基本分区
开机自动挂载
LVM逻辑卷
交换分区
一、磁盘简介
(一)、认知磁盘
(1)结构


(2)物理设备的命名规则
(二)、磁盘分区方式
分区的目的:文件分类,将一块硬盘分成几个小块。用来根据使用存放不同的文件。
MBR分区
MBR分区类型
扩展
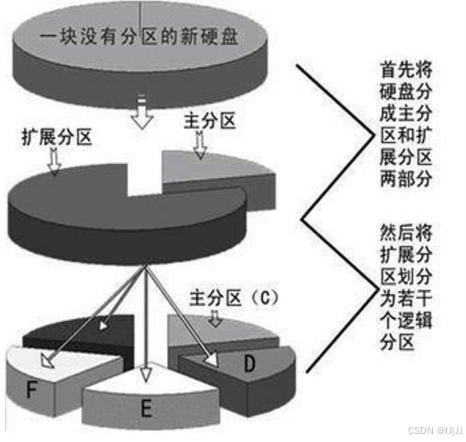
mpt-主分区表-有分区信息,一个分区要有16字节来记录分区,主分区表被划分为4块
3个主分区-能真实使用,最后一个分区--扩展分区-里面又有逻辑分区
一共分区不能超过16个,一块的大小不能高于2tb
cat /proc/partitions 查看系统识别的分区表
lsof -i /dev/sdb1 磁盘吞吐
以上都是磁盘分区的查看
GPT格式
分区命令:gdisk(parted---rhel6)
一共可以分128个主分区
GPT大于小于2TB都可以。最大超过目前硬件可以支撑的硬盘大小。
GPT格式分区就不存在扩展分区、逻辑分区的概念。
#注意:从MBR转到GPT,或从GPT转换到MBR会导致数据全部丢失!因为转换格式要格式化硬盘。
lsblk命令
使用fdisk管理分区
使用gdisk管理分区
拓展
设置完后wq保存,然后udevadm 等同步分区表(系统识别)
gdisk --gpt分区,fdisk里也可以设置gpt分区,parted mkpart primary --分区
格式化
blkid命令
挂载
umount命令
特殊挂载
挂载大文件
查看磁盘空间使用量
df命令
du命令
RAID
RAID0
RAID1
RAID5
RAID10 (主流)
mdadm命令
基本分区
首先给关机状态的虚拟机添加磁盘
这里在添加硬盘时多添加几块,方便后续练习实验;
[root@localhost ~]# lsblk #查看磁盘设备。当硬盘已经被添加,但是还没有格式化没有挂载的时候,使用lsblk查看硬盘信息;
NAME: 设备的名称
MAJ:MIN 主设备号:次设备号
RM: 设备是否可移动。0表示不可移动设备,1表示制度设备。
TYPE: 设备的类型。常见的类型包括disk(硬盘)、part(分区)、rom(制度存储设备)等。
1、fdisk
MBR 14个分区(4个主分区,扩展分区,逻辑分区)
[root@localhost ~]# fdisk -l /dev/sdb #查看磁盘分区信息
[root@localhost ~]# fdisk /dev/sdb #开始分区
m:查看帮助
n:新建分区
w:保存退出
p:打印分区信息
parteprobe /dev/sdb #更新磁盘分区表,手动让内核更新分区表。不需要重启;
lsblk #查看磁盘设备
如果在创建三个主分区后需要一个以上的分区,那么就需要在第二步的时候选择创建扩展分区,然后在扩展分区的基础上创建逻辑分区,这样就可以满足创建更多分区的需求;
MBR与GPT分区格式转换的方法:
[root@lnmt ~]# parted -s /dev/sdb malabel gpt #将/dev/sdb(MBR)格式转化成为(GPT)格式
[root@lnmt ~]# parted -s /dev/sdb malabel msdos #将/dev/sdb(GPT)格式转化成(MBR)格式
2、gdisk创建分区
[root@lnmt ~]# yum -y install gdisk #安装分区工具
[root@lnmt ~]# gdisk -l /dev/sdb #查看磁盘分区信息
[root@lnmt ~]# gdisk /dev/sdb #开始分区
[root@lnmt ~]# partprobe /dev/sdb #刷新分区表
3、创建文件系统(格式化)
[root@lnmt ~]# mkfs.ext4 /dev/sdb1 #格式化成ext4格式的文件系统
[root@lnmt ~]# mkfs.xfs /dev/sdb2 #格式化成xfs格式的文件系统
4、挂载mount使用
[root@lnmt ~]# mkdir /mnt/disk1 #创建挂载目录
[root@lnmt ~]# mount /dev/sdb1 /mnt/disk1/ #挂载
5、查看磁盘挂载与磁盘使用空间
-T 打印文件系统类型
-h 人性化显示,磁盘空间大小
6、取消挂载
[root@lnmt ~]# umount /mnt/disk1 #卸载硬盘
[root@lnmt ~]# umount -l /mnt/disk1 #强制卸载硬盘,即使目录有资源被进程占用,也可以卸载
[root@lnmt ~]# fuser 挂载点 #查找占用文件的进程pid然后杀死,再进行卸载
开机自动挂载
1、/etc/fstab文件实现开机的时候自动挂载
[root@lnmt ~]# blkid /dev/sdb1 #查看uuid和文件系统类型
/dev/sdb1: UUID="5be2ae51-a819-47e0-aeb6-eb75dcd0b6f4" TYPE="ext4"
[root@lnmt ~]# vim /etc/fstab
UUID=5be2ae51-a819-47e0-aeb6-eb75dcd0b6f4 /mnt/disk1 ext4 defaults 0 0
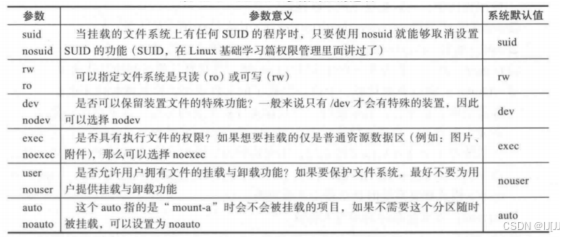
参数解释:
第一列:挂载设备
(1)/dev/sdb1
(2)UUID=设备的uuid RHEL6/7的默认写法,同一台机器内唯一的一个设备标识
第二列:挂载点
第三列:文件系统类型
第四列:文件系统属性
第五列:是否对文件系统进行磁带备份:0 #不备份
第六列:是否检查文件系统:0 #不检查
[root@lnmt ~]# mount -a #自动挂载
2、/etc/rc.d/rc.local开机自动挂载
这个配置文件会在用户登陆之前读取,这个文件中写入了什么命令,在每次系统启动时都会执行一次。也就是说,如果有任何需要在系统启动时运行的工作,则只需写入 /etc/rc.d/rc.local 配置文件即可;
[root@lnmt ~]# vim /etc/rc.d/rc.local
mount /dev/sdb1 /mnt/disk1/
[root@lnmt ~]# chmod +x /etc/rc.d/rc.local #添加执行权限
[root@lnmt ~]# reboot
LVM逻辑卷
1、LVM管理
LVM概念:LVM是Linux环境中对磁盘分区进行管理的一种机制,是建立在硬盘和分区之上,文件系统之下的一个逻辑层,可提高磁盘分区管理的灵活性。
LVM的特点
#传统分区的缺点:
传统的文件系统是基于分区的,一个文件系统对应一个分区。这种方式比较直观,但不宜改变。当一个分区空间已满时,无法对其扩充,只能采用重新分区/建立文件系统,非常麻烦;或把分区中的数据移到另一个更大的分区中。
#当采用LVM时:
1,将硬盘的多个分区由LVM统一为卷组管理,可以方便的加入或移走分区以扩大或减小卷组的可用容量,充分利用硬盘空间;
2,当硬盘空间不足而加入新的硬盘时,不必将数据从原硬盘迁到新硬盘,而只需把新的分区加入卷组并扩充逻辑卷即可。
3,文件系统建立在LVM上,可以跨分区,方便使用;
#使用LVM主要是方便管理、增加了系统的扩展性。可以跨分区,多个硬盘组合。
2、创建LVM
首先准备添加3块磁盘:可以是/dev/sdb这种没有分区的也可以是/dev/sdb这种已经分区了的
注意:如果没有pv命令,安装 #yum -y install lvm2
[root@localhost ~]# pvcreate /dev/sdb #创建pv
[root@localhost ~]# pvs / pvscan / pvdisplay #三种查看pv的方法
以上是第一步,创建物理卷;
[root@localhost ~]# vgcreate vg1 /dev/sdb #创建卷组,这里还可以-s来指定创建分区的PE大小
[root@localhost ~]# vgs / vgscan / vgdisplay #查看卷组
第二步:创建卷组;
[root@localhost ~]# lvcreate -L 2G -n lv1 vg1 #创建lv
[root@localhost ~]# lvcreate -l 200 -n lv2 vg1 #采用PE的方式创建一个lv
[root@localhost ~]# lvcreate -l free PE -n lv2 vg1 #PE的另一种写法
[root@localhost ~]# lvs / lvscan / lvdisplay #查看lv的三种命令
第三步:创建lv,这里我用了三种命令创建了三个lv;
-L:指定lv的大小;
-n:给创建的lv起一个名字;
-l 200 :指定PE数量来制定lv大小;
3、制作文件系统并挂载
[root@localhost ~]# mkfs.xfs /dev/vg1/lv1 #制作xfs的文件系统
[root@localhost ~]# mkfs.ext4 /dev/vg1/lv2 #制作ext4的文件系统
[root@localhost ~]# mkdir /mnt/lv{1..2} #创建挂载点
[root@localhost ~]# mount /dev/vg1/lv1 /mnt/lv1 #挂载
[root@localhost ~]# mount /dev/mapper/vg1-lv2 /mnt/lv2 #挂载的另一种写法
挂载以后:df -hT #查看磁盘挂载信息
不过此时只是临时挂载,要想永久挂载就需要前文提到的修改系统文件以达到开机自己挂载,在这我也就不再多赘述了;
4、LVM逻辑卷扩容
4.1、VG管理
如果lv所在的vg有空间直接对lv扩容就可以了!
扩大VG vgextend
[root@localhost ~]# pvcreate /dev/sdc #创建新的物理卷
[root@localhost ~]# vgextend vg1 /dev/sdc #vg1卷组名,将/dev/sdc扩展到vg1中
扩大LV lvextend
[root@localhost ~]# lvextend -L 5G /dev/vg1/lv1 #这是指将lv1扩容到5G
[root@localhost ~]# lvextend -L +3G /dev/vg1/lv1 #这是指在原有基础上加3G
[root@localhost ~]# lvectend -l +200 /dev/vg1/lv1 #PE写法,在原有的基础上加200个PE
FS(file system)文件系统扩容
这里介绍xfs和ext4两种文件系统的扩容;
[root@localhost ~]# xfs_growfs /dev/vg1/lv1 #xfs文件系统扩容
[root@localhost ~]# resize2fs /dev/vg1/lv1 #ext4文件系统扩容
5、LVM逻辑卷缩容
重要提示:在进行任何磁盘操作前,请务必备份重要数据。操作错误可能导致数据丢失;
备份数据:再开始缩小逻辑卷之前,首先备份其中所有的数据,以防止数据丢失。
卸载逻辑卷:如果逻辑卷包含操作系统的根目录或者已挂载的其他重要目录,需要再进入单用户模式下或使用Live CD环境下卸载该逻辑卷。这是因为无法在线缩小当前正在使用的逻辑卷。
卸载文件系统:在缩小逻辑卷之前,确保已卸载文件系统。如果是ext2/ext3/ext4文件系统,可以使用 “umount /mnt/vg/lv”
检查文件系统:在缩小逻辑卷之前,最好使用文件系统检查工具检查文件系统是否有错误。对于ext2/ext3/ext4文件系统可以运行:“e2fsck -f /de/vg/lv”
缩小逻辑卷:使用lvresize命令来缩小逻辑卷。例如缩小到10G,可以运行:
lvresize --resizefs --size 10G /dev/vg/lv
重新挂载逻辑卷
验证操作:确认文件系统和逻辑卷已成功缩小到所需大小
请注意,缩小逻辑卷涉及风险,如果操作不当可能导致数据丢失。因此,再进行此操作之前,无比备份所有重要数据,并谨慎操作。如果你对这些步骤不确定或不熟悉,建议寻求专业人士的帮助。
交换分区
交换分区管理Swap--也叫虚拟内存
作用:提升内存的容量,防止OOM(Out of Memory)
现象是当内存不够的时候内核会随即杀死进程,它认为占用内存多的进程。(内核会先删除占用内存多的进程)
swap分区大小的设置规则:
再Linux系统,我们可以参照Redhat公司为RHEL5、RHEL6推荐的SWAP空间的大小划分原则,在你没有其他特别需求时,可以作为很好的参考依据。
内存小于4GB,推荐不少于2GB的swap空间;
内存4GB~16GB,推荐不少于4GB的swap空间;
内存16GB~64GB,推荐不少于8GB的swap空间;
内存64GB~256GB,推荐不少于16GB的swap空间;
1、查看当前的交换分区
[root@localhost ~]# free -m #查看内存
[root@localhost ~]# swapon -s #查看交换分区信息
2、增加交换分区
增加交换分区,可以是基本分区,LVM,File;
基本分区制作交换分区
[root@localhost ~]# fdisk /dev/sdd #分一个主分区出来
[root@localhost ~]# partbrobe /dev/sdd #刷新分区表
[root@localhost ~]# mkswap /dev/sdd1 #初始化
[root@localhost ~]# blkid /dev/sdd #查看UUID
[root@localhost ~]# vim/det/fstab #制作开机自动挂载
[root@localhost ~]# swapon -a #激活swap分区
[root@localhost ~]# swapoff /dev/sdd #关闭swap分区
file制作
[root@localhost ~]# dd if=/dev/zero of=/swap.img bs=1M count=2000
[root@localhost ~]# mkswap /swap.img #初始化
[root@localhost ~]# vim /etc/fstab #设置开机自动挂载
[root@localhost ~]# chmod 600 /swap.img #交换分区权限设置为600,默认为644权限不安全
[root@localhost ~]# swapon -a #激活
[root@localhost ~]# swapon -s #查看交换分区信息