强化训练
强化学习的训练与一般的深度学习不太一样。需要有一个环境,对智能体的动作,给予一个奖励并进行状态转移。用于训练的数据,是在训练的过程中产生的。
这里以一个小车上坡的强化学习作为例子,相关文档在下方
https://sagemaker-examples.readthedocs.io/en/latest/reinforcement_learning/rl_mountain_car_coach_gymEnv/rl_mountain_car_coach_gymEnv.html
在对应文件在reinforcement_learning\rl_mountain_car_coach_gymEnv 目录下。这里实际运行时的时候。需要将reinforcement_learning\common目录也移动到rl_mountain_car_coach_gymEnv目录下
训练介绍
该训练模拟了一辆动力不足的汽车的任务是攀登陡峭的山峰,只有到达右侧山顶才能成功。小车无法一脚油门直接开到山顶,但是左侧还有另一座山,可以利用它获得动力,将汽车开到山顶。
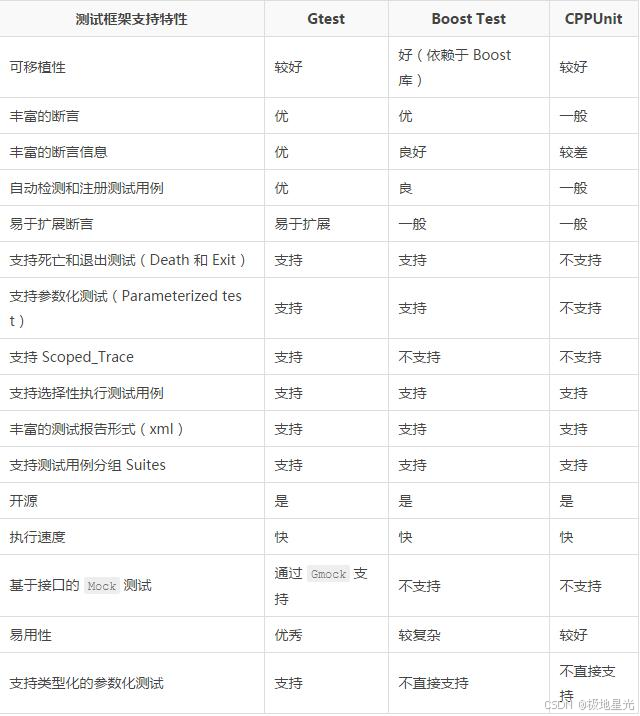
例子中几个关键的概念如下
环境(Env):Open AI Gym里的MountainCarContinuous-v0
动作(Action):让小车向左/向右移动和什么都不做
状态(State):小车在水平位置的坐标,以及当前的速度
奖励(Reward):当到达右侧山顶时获得100分,每执行一步扣1分
下图演示了小车到达山顶的过程

Tips:
这里需要注意一点,git上的这个例子,需要先将rl_mountain_car_coach_gymEnv目录下的commom文件删除,然后将该目录同级的common库复制到rl_mountain_car_coach_gymEnv目录下。

复制完后的rl_mountain_car_coach_gymEnv 如下

使用Sagemaker进行强化学习的时候,可以使用Docker在JupyterNotebook的实例上进行本地的训练。等到调试完成后可以再改到SageMaker上进行训练。
一些关键的概念
Coach(教练)
项目中的Coach是一个高级框架或工具包,旨在简化强化学习任务的开发和实验过程。它提供了许多预定义的算法、环境接口以及用于训练和评估智能体的组件。Coach具有灵活性,可以适应不同类型的任务和算法。它负责整个强化学习训练流程的管理和协调。
Agent(智能体)
Agent是指在强化学习任务中执行动作的实体。智能体在一个环境中观察状态,并基于其策略选择动作来与环境进行交互。Agent的目标是通过与环境的交互,学习如何最大化累积奖励或达到特定的目标。Agent的行为通常由一个或多个学习算法来控制,例如Q-learning、Policy Gradient等。
rl_coach库
这个例子中使用了gym.openai的库,可以用来提供这个小车例子的环境。同时还使用了rl_coach库,提供了一个模块化的框架,其中包含了一系列预定义的强化学习组件和算法,如深度 Q 网络(DQN)、策略梯度、行动者-评论家(Actor-Critic)等.
CheckPoint(检查点)
例子还使用了CheckPoint(检查点)用来进行预测。检查点的作用是当训练特别大的时候,可以用来保留部分训练的结果。以便下一次训练的时候,可以直接从检查点继续,避免重新开始训练。可以简单的理解为训练过程的存档。
例子解析
由于这个例子使用的环境是gym.openai例子的环境,所以并不需要自己去编写关于环境的逻辑。
并且训练的过程也是透明的,不需要自己去迭代参数以及指定参数的输入输出类型
Sagemaker的强化学习主要是通过RLEstimator进行的,相关文档可以查看 https://sagemaker.readthedocs.io/en/stable/frameworks/rl/sagemaker.rl.html
特别需要注意的是,这个Estimator支持的强化学习框架只有mxnet和tensorflow

classsagemaker.rl.estimator.RLEstimator(entry_point, toolkit=None, toolkit_version=None, framework=None, source_dir=None, hyperparameters=None, image_uri=None, metric_definitions=None, **kwargs)创作不易,如果觉得这篇文章对你有所帮助,可以动动小手,点个赞哈,ღ( ´・ᴗ・` )比心