拓扑排序精讲
117. 软件构建
题目描述
某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的内容,这意味着如果文件 A 依赖于文件 B,则必须在处理文件 A 之前处理文件 B (0 <= A, B <= N - 1)。请编写一个算法,用于确定文件处理的顺序。
输入描述
第一行输入两个正整数 N, M。表示 N 个文件之间拥有 M 条依赖关系。
后续 M 行,每行两个正整数 S 和 T,表示 T 文件依赖于 S 文件。
输出描述
输出共一行,如果能处理成功,则输出文件顺序,用空格隔开。
如果不能成功处理(相互依赖),则输出 -1。
输入示例
5 4 0 1 0 2 1 3 2 4输出示例
0 1 2 3 4提示信息
文件依赖关系如下:
所以,文件处理的顺序除了示例中的顺序,还存在
0 2 4 1 3
0 2 1 3 4
等等合法的顺序。
数据范围:
0 <= N <= 10 ^ 5
1 <= M <= 10 ^ 9
每行末尾无空格。
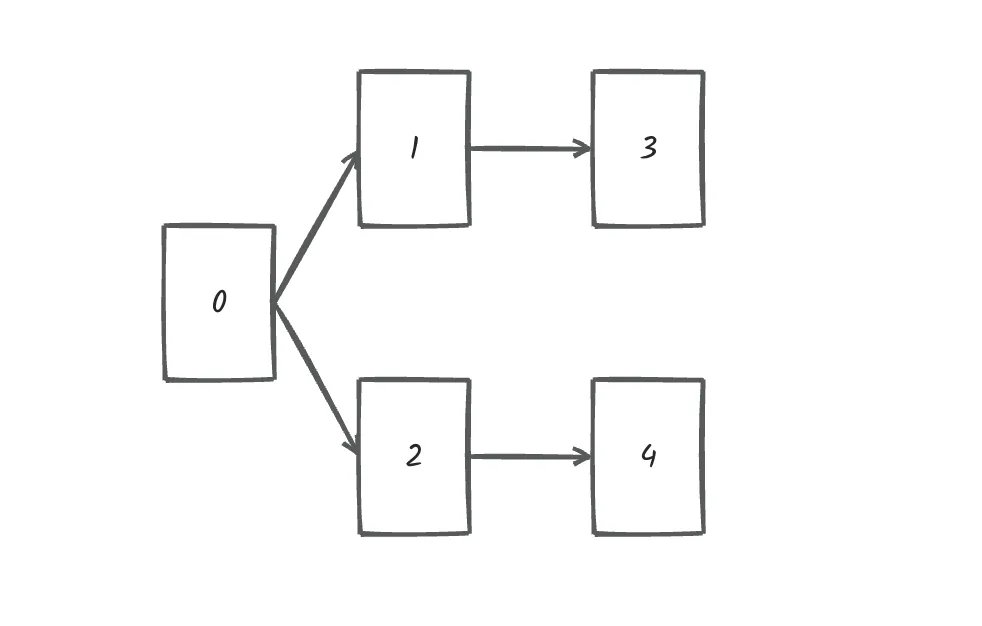
概括来说,给出一个 有向图,把这个有向图转成线性的排序 就叫拓扑排序。
当然拓扑排序也要检测这个有向图 是否有环,即存在循环依赖的情况,因为这种情况是不能做线性排序的。
所以拓扑排序也是图论中判断有向无环图的常用方法。
其实只要能在把 有向无环图 进行线性排序 的算法 都可以叫做 拓扑排序。
实现拓扑排序的算法有两种:卡恩算法(BFS)和DFS。
出发节点:当我们做拓扑排序的时候,应该优先找 入度为 0 的节点,只有入度为0,它才是出发节点。
拓扑排序的过程,其实就两步:
- 找到入度为0 的节点,加入结果集
- 将该节点从图中移除
循环以上两步,直到 所有节点都在图中被移除了。
模拟过程
用本题的示例来模拟这一过程:
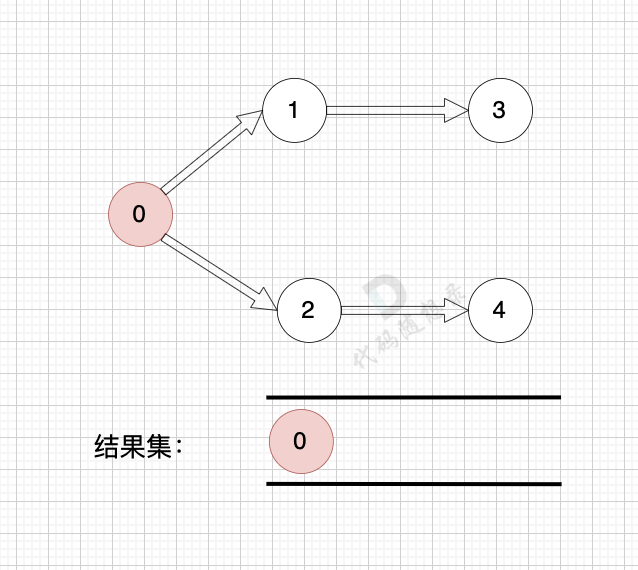
1、找到入度为0 的节点,加入结果集
2、将该节点从图中移除
1、找到入度为0 的节点,加入结果集
这里大家会发现,节点1 和 节点2 入度都为0, 选哪个呢?
选哪个都行,所以这也是为什么拓扑排序的结果是不唯一的。
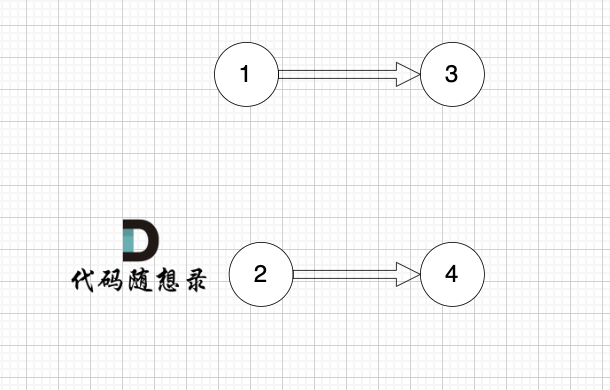
2、将该节点从图中移除
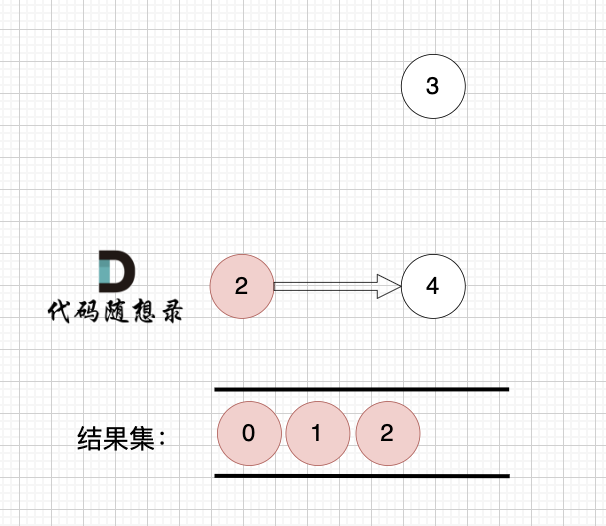
1、找到入度为0 的节点,加入结果集
节点2 和 节点3 入度都为0,选哪个都行,这里选节点2
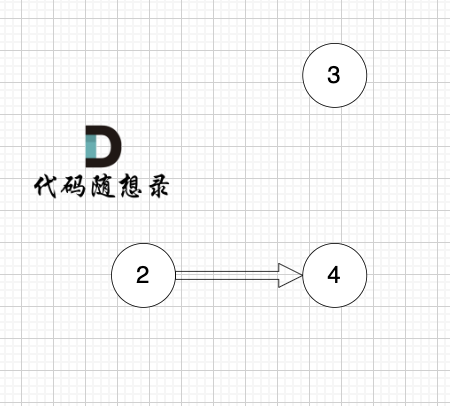
2、将该节点从图中移除
后面的过程一样的,节点3 和 节点4,入度都为0,选哪个都行。
最后结果集为: 0 1 2 3 4 。当然结果不唯一的
有环的情况
只有一个结果,因为接下来找不到一个入度为0的节点了
模拟运行结果
假设输入如下:
4 6 0 1 1 2 2 3 3 4 4 5
首先读取
m=4和n=6,初始化inDegree和umap。读取依赖关系:
0 -> 1:inDegree[1]++,umap[0].push_back(1)1 -> 2:inDegree[2]++,umap[1].push_back(2)2 -> 3:inDegree[3]++,umap[2].push_back(3)3 -> 4:inDegree[4]++,umap[3].push_back(4)4 -> 5:inDegree[5]++,umap[4].push_back(5)初始化队列,入度为0的节点是
0,将其加入队列。拓扑排序:
cur = 0,result.push_back(0),处理0指向的文件1,inDegree[1]--,inDegree[1] == 0,将1加入队列。cur = 1,result.push_back(1),处理1指向的文件2,inDegree[2]--,inDegree[2] == 0,将2加入队列。cur = 2,result.push_back(2),处理2指向的文件3,inDegree[3]--,inDegree[3] == 0,将3加入队列。cur = 3,result.push_back(3),处理3指向的文件4,inDegree[4]--,inDegree[4] == 0,将4加入队列。cur = 4,result.push_back(4),处理4指向的文件5,inDegree[5]--,inDegree[5] == 0,将5加入队列。cur = 5,result.push_back(5),处理5指向的文件,没有文件。最终结果集
result为[0, 1, 2, 3, 4, 5],大小为6,等于文件数n。输出结果:
0 1 2 3 4 5


代码
思想简单,但是代码却不简单。
1.初始化的时候,就把每个节点的入度 和 每个节点的依赖关系做统计。
2.找入度为0 的节点,需要用一个队列放存放。
3.开始从队列里遍历入度为0 的节点,将其放入结果集。
4.将 该节点作为出发点所连接的节点的 入度 减一(类似把节点移除出图,但不是真移除)
#include<iostream>
#include<vector>
#include<queue>
#include<unordered_map>
using namespace std;
int main()
{
int m,n,s,t;//依赖关系数,文件数0到n-1,具体文件的依赖关系st
cin>>n>>m;
vector<int>inDegree(n,0);//每个节点的入度关系
vector<int>result;//结果
unordered_map<int,vector<int>>umap;//记录文件依赖关系
while(m--)
{
cin>>s>>t;
inDegree[t]++;//因为t依赖s,所以t的入度关系自增
umap[s].push_back(t);//记录s指向的文件
}
queue<int>que;//存放入度为0的节点
for(int i=0;i<n;i++)
{
if(inDegree[i]==0)que.push(i);
}
while(que.size())
{
int cur=que.front();
que.pop();
result.push_back(cur);//结果集记录入度为0的节点,先入先出
vector<int>files=umap[cur];//获取当前文件及其指向文件
if(files.size())
{
for(int i=0;i<files.size();i++)//遍历所有指向的文件。
{
inDegree[files[i]]--;// cur的指向的文件入度-1
if(inDegree[files[i]]==0)que.push(files[i]);//只要入度为0,就饿可以加入队列中
}
}
}
if(result.size()==n)//如果结果集的大小等于文件数 n,说明所有文件都能正确排序。
{
for(int i=0;i<n-1;i++)
cout<<result[i]<<" ";
cout<<result[n-1];
}
else cout<<-1<<endl;
}dijkstra(朴素版)精讲
47. 参加科学大会(第六期模拟笔试)
题目描述
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。
小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。
小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
输入描述
第一行包含两个正整数,第一个正整数 N 表示一共有 N 个公共汽车站,第二个正整数 M 表示有 M 条公路。
接下来为 M 行,每行包括三个整数,S、E 和 V,代表了从 S 车站可以单向直达 E 车站,并且需要花费 V 单位的时间。
输出描述
输出一个整数,代表小明从起点到终点所花费的最小时间。
输入示例
7 9 1 2 1 1 3 4 2 3 2 2 4 5 3 4 2 4 5 3 2 6 4 5 7 4 6 7 9输出示例
12提示信息
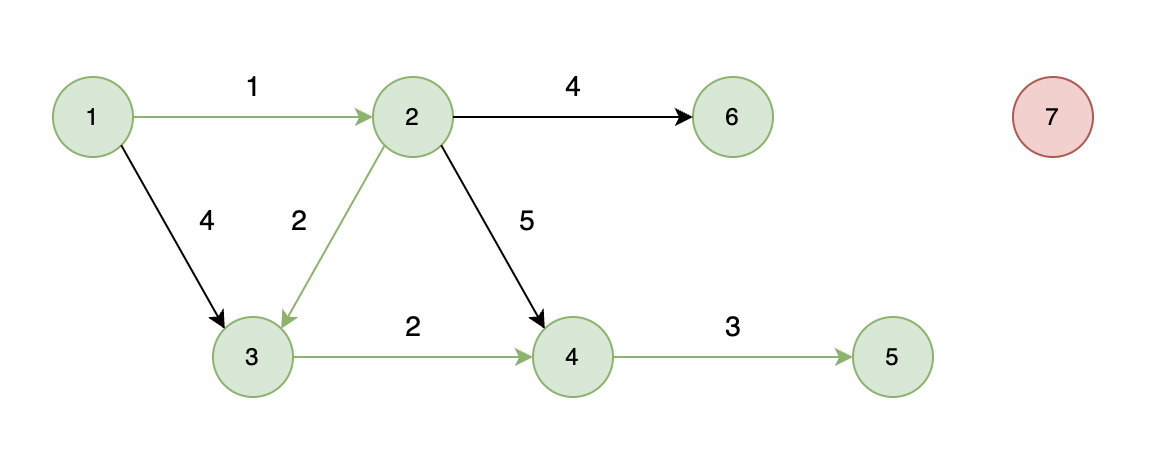
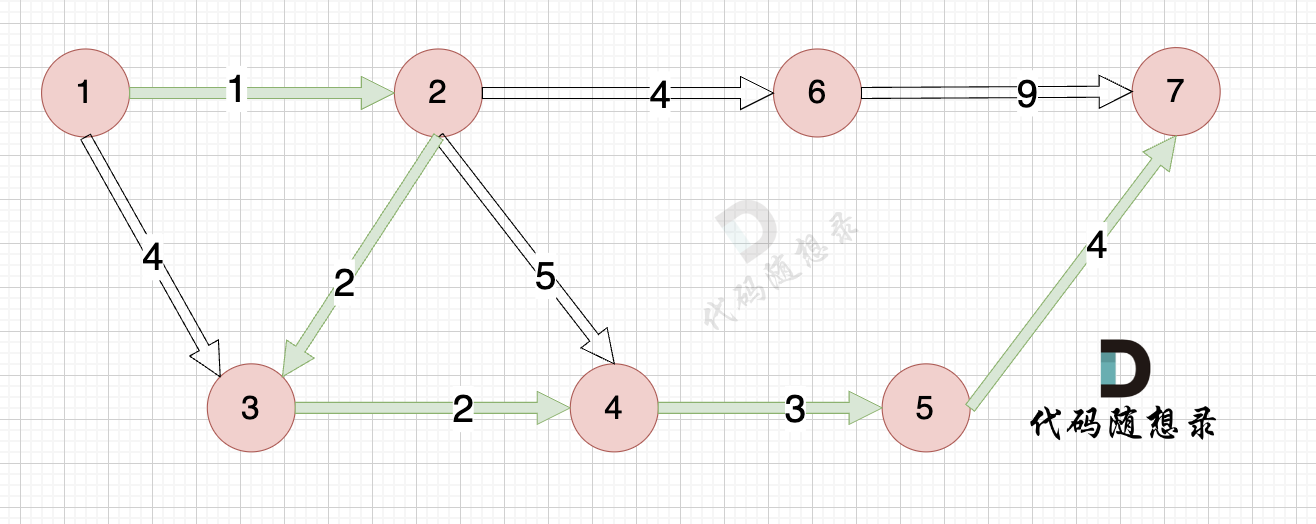
能够到达的情况:
如下图所示,起始车站为 1 号车站,终点车站为 7 号车站,绿色路线为最短的路线,路线总长度为 12,则输出 12。
不能到达的情况:
如下图所示,当从起始车站不能到达终点车站时,则输出 -1。
数据范围:
1 <= N <= 500;
1 <= M <= 5000;

最短路是图论中的经典问题即:给出一个有向图,一个起点,一个终点,问起点到终点的最短路径。
dijkstra算法:在有权图(权值非负数)中求从起点到其他节点的最短路径算法。
需要注意两点:
- dijkstra 算法可以同时求 起点到所有节点的最短路径
- 权值不能为负数
dijkstra 算法 同样是贪心的思路,不断寻找距离 源点最近的没有访问过的节点。
这里我也给出 dijkstra三部曲:
- 第一步,选源点到哪个节点近且该节点未被访问过
- 第二步,该最近节点被标记访问过
- 第三步,更新非访问节点到源点的距离(即更新minDist数组)(注意这里的mindist记录的是离源点的距离!!!)
和prim算法很像。
模拟过程
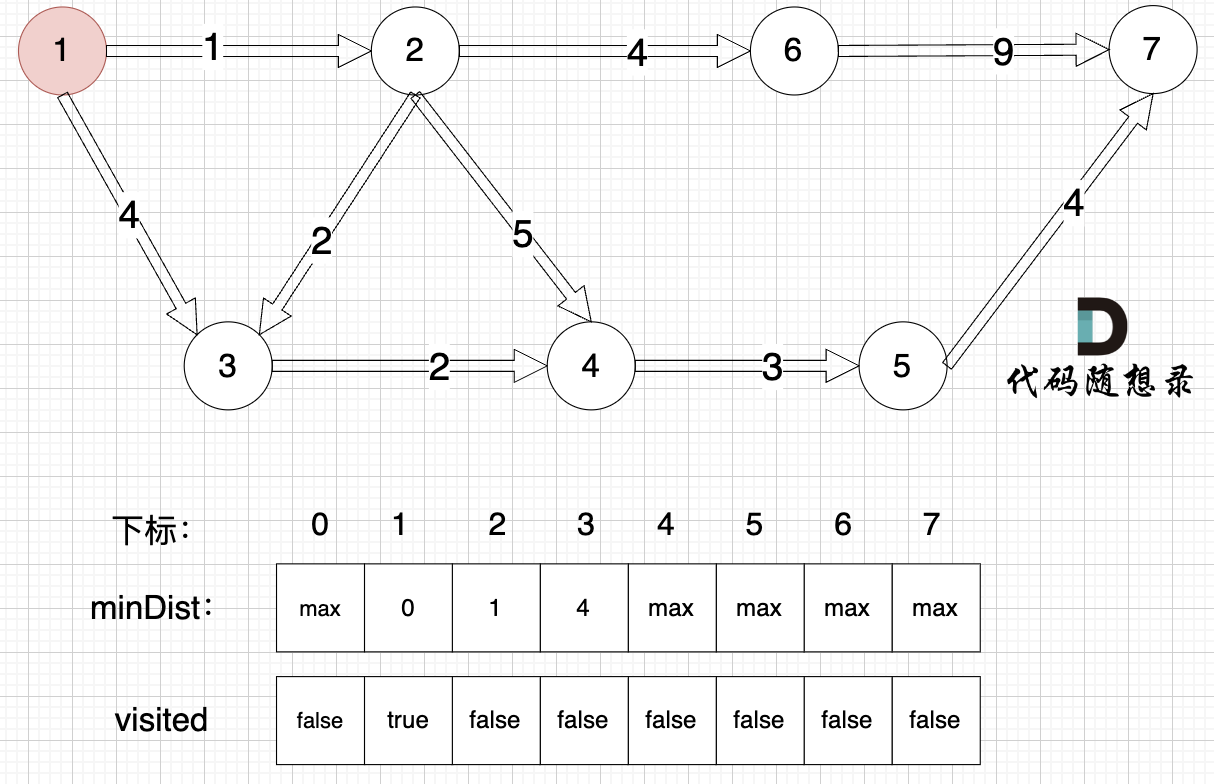
1-2-3-4-6-5-7
更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
- 源点到节点2的最短距离为1,小于原minDist[2]的数值max,更新minDist[2] = 1
- 源点到节点3的最短距离为4,小于原minDist[3]的数值max,更新minDist[3] = 4
以此类推,到第7节点时
节点7加入,但节点7到节点7的距离为0,所以 不用更新minDist数组
最后我们要求起点(节点1) 到终点 (节点7)的距离。
再来回顾一下minDist数组的含义:记录 每一个节点距离源点的最小距离。
那么起到(节点1)到终点(节点7)的最短距离就是 minDist[7] ,按上面举例讲解来说,minDist[7] = 12,节点1 到节点7的最短路径为 12。
路径如图:

代码例子4 4 1 2 1 1 3 4 2 3 1 3 4 1
首先读取
n=4和m=4,初始化邻接矩阵grid。读取边并填充邻接矩阵:
- 边
(1, 2, 1),grid[1][2] = 1- 边
(1, 3, 4),grid[1][3] = 4- 边
(2, 3, 1),grid[2][3] = 1- 边
(3, 4, 1),grid[3][4] = 1初始化
minDist和visited。运行 Dijkstra 算法:
- 第一次迭代:选择节点1,更新
minDist为[0, 1, 4, INT_MAX]。- 第二次迭代:选择节点2,更新
minDist为[0, 1, 2, INT_MAX]。- 第三次迭代:选择节点3,更新
minDist为[0, 1, 2, 3]。- 第四次迭代:选择节点4,
minDist保持不变。最终输出:
3
代码
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {
int n,m,p1,p2,val;//公共汽车站数量,公路数量,某站到某站及其所花时间
cin>>n>>m;
//声明一个大小为 (n + 1) x (n + 1) 的二维向量 grid,用于存储图的邻接矩阵。初始值为 INT_MAX,表示不存在的边或非常大的权值。
vector<vector<int>>grid(n+1,vector<int>(n+1,INT_MAX));
for(int i=0;i<m;i++)
{
cin>>p1>>p2>>val;
grid[p1][p2]=val;
}
int start=1;int end=n;
//存储从源点到每个节点的最短距离
vector<int>minDist(n+1,INT_MAX);
//记录顶点是否被访问过
vector<bool>visited(n+1,false);
minDist[start]=0;//起始点到自身的距离为0
for(int i=1;i<=n;i++)//遍历所有节点
{
int minval=INT_MAX;
int cur=1;
//第一步,选距离源点最近且未被访问过的节点
for(int j=1;j<=n;j++)
{
if(!visited[j]&&minDist[j]<minval)
{
minval=minDist[j];
cur=j;
}
}
//第二步,标记当前节点为已被访问
visited[cur]=true;
//第三步,更新非访问节点到源点的距离(更新mindist数组)
for(int k=1;k<=n;k++)
{
if(!visited[k]&&grid[cur][k]!=INT_MAX&&minDist[cur]+grid[cur][k]<minDist[k])
{
minDist[k]=minDist[cur]+grid[cur][k];
}
}
}
if(minDist[end]==INT_MAX)cout<<-1<<endl;//表示不能到达终点
else
cout<<minDist[end]<<endl;//最后一个节点有更新的值,就是最短路径的结果
}
和prim算法的区别
prim是求 非访问节点到最小生成树的最小距离,而 dijkstra是求 非访问节点到源点的最小距离。
prim 更新 minDist数组的写法:
for (int j = 1; j <= v; j++) { if (!isInTree[j] && grid[cur][j] < minDist[j]) { minDist[j] = grid[cur][j]; } }因为 minDist表示 节点到最小生成树的最小距离,所以 新节点cur的加入,只需要 使用 grid[cur][j] ,grid[cur][j] 就表示 cur 加入生成树后,生成树到 节点j 的距离。
dijkstra 更新 minDist数组的写法:
for (int v = 1; v <= n; v++) { if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) { minDist[v] = minDist[cur] + grid[cur][v]; } }因为 minDist表示 节点到源点的最小距离,所以 新节点 cur 的加入,需要使用 源点到cur的距离 (minDist[cur]) + cur 到 节点 v 的距离 (grid[cur][v]),才是 源点到节点v的距离。


















