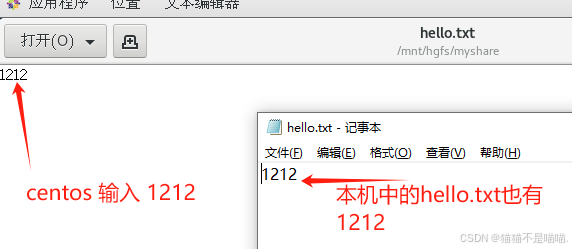
目录
1.XML介绍
1.1.XML概述
1.1.1.什么是XML
1.1.2.XML的作用
1.1.3.XML与HTML的比较
1.1.4.XML和properties(属性文件)比较
1.1.5.W3C组织
1.2.XML语法概述
1.2.1.XML文档展示
1.2.2.XML文档的组成部分
1.3.XML文档声明
1.3.1.什么是XML文档声明
1.3.2.XML文档声明结构
1.4.XML元素
1.4.1.XML元素的格式
1.4.2.XML文档的根元素
1.4.3.元素中的空白
1.4.4.元素命名规范
1.4.5.元素属性
1.4.6.注释
1.4.7.转义字符
1.4.8.CDATA段
2.XML解析
2.1.操作XML文档概述
2.1.1.如何操作XML文档
2.1.2.XML解析技术
2.2.DOM4J
2.2.1.DOM4J概述
2.2.1.1.DOM4J是什么
2.2.1.2.DOM4J中的类结构
2.2.1.3.DOM4J获取Document对象
2.2.1.4.DOM4J保存Document对象
2.2.1.5.DOM4J创建Document对象
2.2.2.Document操作
2.2.2.1.遍历students.xml
2.2.3.XPath
2.2.3.1.什么是XPath
2.2.3.2.DOM4J对XPath的支持
1.XML介绍
1.1.XML概述
1.1.1.什么是XML
XML全称Extensible Markup Language,意思是可扩展的标记语言,它是 SGML(标准通用标记语言)的一个子集
1.1.2.XML的作用
-
XML是程序的配置文件
-
可以在不同语言之间交换数据
-
作为小型数据库存储数据
1.1.3.XML与HTML的比较
-
HTML的元素是固定的,而XML可以自定义元素
-
HTML用浏览器来解析执行,XML的解析器通常需要自己来写(因为元素是自定义的)
-
HTML只能用来表示网页,而XML的使用场景更多
1.1.4.XML和properties(属性文件)比较
-
properties只能存储平面信息,而XML可以存储结构化信息
-
解析properties只需要使用Properties类就可以了,而解析XML文件是很复杂的
1.1.5.W3C组织
W3C是万维网联盟(World Wide Web Consortium)英文的缩写,它成立于1994年10月,以开放论坛的方式来促进开发互通技术(包括规格、指南、软件和工具),开发网络的全部潜能。万维网联盟(W3C)从1994年成立以来,已发布了90多份Web技术规范,领导着Web技术向前发展
W3C认为自身不是官方组织,因此将它正式发布的规范称为推荐(建议)标准,意思是进一步标准化的建议,但是由于组织自身的权威性往往成为事实上的标准
1.2.XML语法概述
1.2.1.XML文档展示
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<students>
<student number="1001">
<name>zhangSan</name>
<age>23</age>
<sex>male</sex>
</student>
<student number="1002">
<name>liSi</name>
<age>32</age>
<sex>female</sex>
</student>
<student number="1003">
<name>wangWu</name>
<age>55</age>
<sex>male</sex>
</student>
</students>1.2.2.XML文档的组成部分
-
XML文档声明
-
XML处理指令
-
XML元素
-
XML特殊字符和CDATA区 [![CADATA <<<<>>>>>> ]]
-
XML注释 <!--- -->
1.3.XML文档声明
1.3.1.什么是XML文档声明
可以看作是XML文档的说明
最简单的xml文档声明:<?xml version="1.0"?>
1.3.2.XML文档声明结构
-
version属性:用于说明当前xml文档的版本,因为都是在用1.0,所以这个属性值大家都写1.0,version属性是必须的
-
encoding属性:用于说明当前xml文档使用的字符编码集,xml解析器会使用这个编码来解析xml文档。encoding属性是可选的,默认为UTF-8。注意,如果当前xml文档使用的字符编码集是gb2312,而encoding属性的值为UTF-8,那么一定会出错的
-
standalone属性:用于说明当前xml文档是否为独立文档,如果该属性值为yes,表示当前xml文档是独立的,如果为no表示当前xml文档不是独立的,即依赖外部的约束文件,默认是yes
-
没有xml文档声明的xml文档,不是格式良好的xml文档
-
xml文档声明必须从xml文档的1行1列开始
1.4.XML元素
1.4.1.XML元素的格式
XML元素包含开始标签、元素体(内容)、结束标签。例如:<hello>大家好</hello>
空元素只有开始标签,没有元素体和结束标签,但空元素一定要闭合。例如:<hello/>
XML元素可以包含子元素或文本数据。例如:hello,a元素的元素体内容是b元素,而b元素的元素体内容是文本数据hello
XML元素可以嵌套,但必须是合法嵌套。<b>hello</b>就是错误的嵌套
1.4.2.XML文档的根元素
格式良好的XML文档必须有且仅有一个根元素
student1.xml
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<students>
<student number="1001">
<name>zhangSan</name>
<age>23</age>
<sex>male</sex>
</student>
<student number="1002">
<name>liSi</name>
<age>32</age>
<sex>female</sex>
</student>
</students>student2.xml
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<student number="1001">
<name>zhangSan</name>
<age>23</age>
<sex>male</sex>
</student>
<student number="1002">
<name>liSi</name>
<age>32</age>
<sex>female</sex>
</student>student1.xml是格式良好的xml文档,只有一个根元素,即students元素
student2.xml不是格式良好的xml文档,有两个根元素,即两个student根元素
1.4.3.元素中的空白
XML元素的元素体可以包含文本数据和子元素
a.xml
<a><b>hello</b></a>b.xml
<a>
<b>
hello
</b>
</a>a.xml中,<a>元素只有一个子元素,即<b>元素。<b>元素只有一个文本数据,即hello
b.xml中,<a>元素中第一部分为换行缩进,第二部分为<b>元素,第三部分为换行。b元素的文本数据为换行、缩进、hello、换行、缩进
其中换行和缩进都是空白,这些空白是为了增强xml文档的可读性。但xml解析器可能会因为空白出现错误的解读,这说明在将来编写解析xml程序时,一定要小心空白!!!
1.4.4.元素命名规范
XML元素名可以包含字母、数字以及一些其他可见字符,但必须遵循下面的一些规范:
-
区分大小写:<a>和<A>是两个元素
-
不能以数字开头:<1a>是错误的命名
-
最好不要以xml开头:<xml>、<Xml>、<XML>
-
不能包含空格
1.4.5.元素属性
-
属性由属性名与属性值构成,中间用等号连接
-
属性值必须使用引号括起来,单引号或双引号都可以
-
定义属性必须遵循与标签名相同的命名规范
-
属性必须定义在元素的开始标签中
-
一个元素中不能包含相同的属性名
1.4.6.注释
-
注释以<!--开头,以-->结束
-
注释中不能包含--
1.4.7.转义字符
因为在xml文档中有些字符是特殊的,不能使用它们作为文本数据。例如:不能使用“<”或“>”等字符作为文本数据,所以需要使用转义字符来表示
例如<a><a></a>,你可能会说,其中第二个<a>是a元素的文本内容,而不是一个元素的开始标签,但xml解析器是不会明白你的意思的。把<a><a></a>修饰为<a><a></a>,这就OK了

转义字符都是以“&”开头,以“;”结束。这与后面我们学习的实体是相同的
1.4.8.CDATA段
当大量的转义字符出现在xml文档中时,会使xml文档的可读性大幅度降低。这时如果使用CDATA段就会好一些
在CDATA段出现的“<”、“>”、“””、“’”、“&”,都无需使用转义字符。这可以提高xml文档的可读性
<a><![CDATA[<a>]]></a>在CDATA段中不能包含“]]>”,即CDATA段的结束定界符
2.XML解析
2.1.操作XML文档概述
2.1.1.如何操作XML文档
XML文档也是数据的一种,对数据的操作也不外乎是“增删改查”。也被大家称之为“CRUD”
2.1.2.XML解析技术
XML解析方式分为两种:DOM(Document Object Model)和SAX(Simple API for XML)。这两种方式不是针对Java语言来解析XML的技术,而是跨语言的解析方式。例如DOM也在JavaScript中存在
DOM是W3C组织提供的解析XML文档的标准接口,而SAX是社区讨论的产物,是一种事实上的标准
DOM和SAX只是定义了一些接口,以及某些接口的缺省实现,而这个缺省实现只是用空方法来实现接口。一个应用程序如果需要DOM或SAX来访问XML文档,还需要一个实现了DOM或SAX的解析器,也就是说这个解析器需要实现DOM或SAX中定义的接口。提供DOM或SAX中定义的功能
2.2.DOM4J
2.2.1.DOM4J概述
2.2.1.1.DOM4J是什么
DOM4J是针对Java开发人员专门提供的XML文档解析规范,它不同于DOM,但与DOM相似。DOM4J针对Java开发人员而设计,所以对于Java开发人员来说,使用DOM4J要比使用DOM更加方便
DOM4J对DOM和SAX提供了支持,使用DOM4J可以把org.dom4j.document转换成org.w3c.Document,DOM4J也支持基于SAX的事件驱动处理模式
使用者需要注意,DOM4J解析的结果是org.dom4j.Document,而不是org.w3c.Document。DOM4J与DOM一样,只是一组规范(接口与抽象类组成),底层必须要有DOM4J解析器的实现来支持
DOM4J使用JAXP来查找SAX解析器,然后把XML文档解析为org.dom4j.Document对象。它还支持使用org.w3c.Document来转换为org.dom4j.Docment对象
2.2.1.2.DOM4J中的类结构
在DOM4J中,也有Node、Document、Element等接口,结构上与DOM中的接口比较相似。但还是有很多的区别:

在DOM4J中,所有XML组成部分都是一个Node,其中Branch表示可以包含子节点的节点,例如Document和Element都是可以有子节点的,它们都是Branch的子接口
Attribute是属性节点,CharacterData是文本节点,文本节点有三个子接口,分别是CDATA、Text、Comment
2.2.1.3.DOM4J获取Document对象
使用DOM4J来加载XML文档,需要先获取SAXReader对象,然后通过SAXReader对象的read()方法来加载XML文档:
SAXReader reader = new SAXReader();
Document doc = reader.read("src/students.xml");2.2.1.4.DOM4J保存Document对象
保存Document对象需要使用XMLWriter对象的write()方法来完成,在创建XMLWriter时还可以为其指定XML文档的格式(缩进字符串以及是否换行),这需要使用OutputFormat来指定
doc.addDocType("students", "", "students.dtd");
OutputFormat format = new OutputFormat("\t", true);
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileWriter(xmlName), format);
writer.write(doc);
writer.close();2.2.1.5.DOM4J创建Document对象
DocumentHelper类有很多的createXXX()方法,用来创建Node对象
Document doc = DocumentHelper.createDocument();2.2.2.Document操作
2.2.2.1.遍历students.xml
涉及的相关方法:
Element getRootElement():Document的方法,用来获取根元素
List elements():Element的方法,用来获取所有孩子元素
String attributeValue(String name):Element的方法,用来获取指定名字的属性值
Element element(String name):Element的方法,用来获取第一个指定名字的子元素
String elementText(String name):Element的方法,用来获取第一个指定名字的子元素的文本内容
分析步骤:
1.获取Document对象
2.获取root元素
3.获取root所有子元素
4.遍历每个student元素
-
打印student元素number属性
-
打印student元素的name子元素内容
-
打印student元素的age子元素内容
-
打印student元素的sex子元素内容
2.2.3.XPath
2.2.3.1.什么是XPath
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言
2.2.3.2.DOM4J对XPath的支持
在DOM4J中,Node接口中的三个方法最为常用
-
List selectNodes(String xpathExpression):在当前节点中查找满足XPath表达式的所有子节点;
-
Node selectSingleNode(String xpathExpression):在当前节点中查找满足XPath表达式的第一个子节点;
-
String valueOf(String xpathExpression):在当前节点中查找满足XPath表达式的第一个子节点的文本内容;
Document doc = reader.read(new FileInputStream("person.xml"));
Element root = doc.getRootElement();
List<Element> eList = root.selectNodes("/persons");
List<Element> eList1 = root.selectNodes("/persons/person/name");
List<Element> eList2 = root.selectNodes("//age");
List<Element> eList3 = root.selectNodes("//person/age");
List<Element> eList4 = root.selectNodes("/*/*/address");
List<Element> eList5 = root.selectNodes("//*");
List<Element> eList6 = root.selectNodes("/persons/person[1]");
List<Element> eList7 = root.selectNodes("/persons/person[last()]");
List<Element> eList8 = root.selectNodes("//@id");
List<Element> eList9 = root.selectNodes("//person[@id]");
List<Element> eList10 = root.selectNodes("//person[@*]");
List<Element> eList11 = root.selectNodes("//*[not(@*)]");
List<Element> eList12 = root.selectNodes("//person[@id='person1']");