Transforming Words into Motion: A Guide to Video Generation with AMD GPU — ROCm Blogs

发布日期: 2024年4月24日
作者: Douglas Jia
本博客介绍了通过增强稳定扩散模型在文本到视频生成方面的进展,并展示了使用阿里巴巴的ModelScopeT2V模型在AMD GPU上生成视频的过程。
介绍
人工智能在各类内容生成中实现了重大转变,包括文本、图像和音频领域。虽然在图像生成方面通过扩散模型取得了显著进展,但由于训练的复杂性,视频生成在目前仍然是一项具有挑战性的任务。尽管在文本到图像合成方面已有明显进步,但缺乏公开可用的视频生成代码库阻碍了进一步的研究。为了解决这一问题,ModelScopeT2V引入了一种简单而有效的视频生成方法,利用潜在扩散模型和多帧训练策略。实验结果显示了该模型的优越性能,使其成为未来视频合成研究的有价值基线。

ModelScopeT2V模型架构
来源: ModelScope文本到视频技术报告
基于模型架构可以看出,该模型与经典的稳定扩散模型的主要区别在于,它将具有F帧的视频转换为具有F元素的张量(每个元素代表视频中的一个图像/帧)。每个图像/帧将像在稳定扩散中那样经过扩散和去噪过程。但是,等等,这一框架如何捕捉视频的本质:像素之间的时空关系?这就是时空块的作用。时空块在捕捉潜在空间中的复杂时空依赖关系方面是不可或缺的,从而提高了视频合成的质量。为了达到这一目标,我们利用时空卷积和注意力机制的能力,有效地捕捉这些复杂的依赖关系。
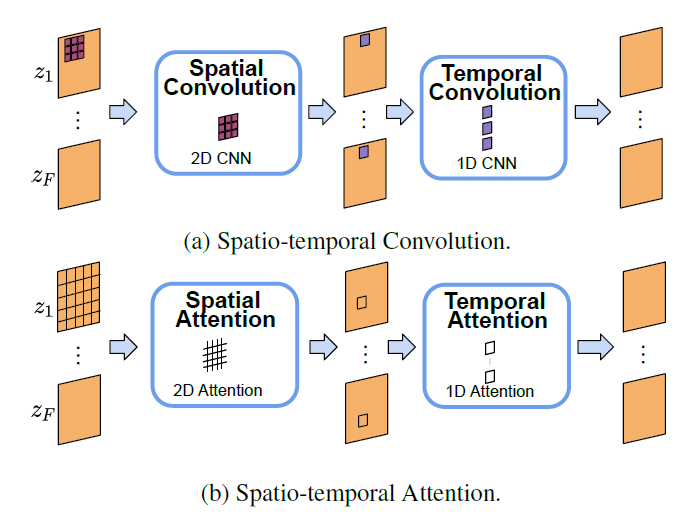
时空块处理流程图
来源: ModelScope文本到视频技术报告
该块利用时空卷积和注意力机制的结合,分析视频帧之间的相关性。时空卷积跨越空间和时间维度,而时空注意力则专注于视频帧内的特定区域和时间步骤。这一整合使模型能够掌握复杂的时空模式并生成高质量的视频。每个时空块由反复的空间和时间卷积以及空间和时间注意力操作组成。具体而言,这些操作分别重复(2,4,2,2)次,以在性能和计算效率之间取得平衡。此外,模型使用了两种类型的空间注意力:用于跨模态交互的交叉注意力模块(关注文本提示)和用于视觉特征空间建模的自注意力模块。两个时间注意力模块均为自注意力模块。这一概要旨在提供对文本到视频生成的直观理解。欲深入了解,我们建议参考ModelScope团队的原始技术报告。
实现
我们在搭载AMD GPU的PyTorch ROCm 6.0 docker容器中运行推理(查看支持的操作系统和AMD硬件列表)。
首先,在Linux shell中使用以下代码pull并运行docker容器:
docker run -it --ipc=host --network=host --device=/dev/kfd --device=/dev/dri \
--group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--name=t2v-pytorch rocm/pytorch:rocm6.0_ubuntu20.04_py3.9_pytorch_2.1.1 /bin/bash
然后在docker容器中运行以下代码来安装所需的Python包:
pip install diffusers transformers accelerate opencv-python
现在,我们已经准备好使用Hugging Face的`diffusers` API在Python中生成有趣的视频了。
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import export_to_video
# 默认为: DDIMScheduler
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b")
pipe.to('cuda')
# 生成视频
generator = torch.Generator(device="cuda").manual_seed(1234)
prompt = "A monkey is riding a horse around a lake"
video_frames = pipe(prompt, generator=generator, num_inference_steps=50, num_frames=20).frames
export_to_video(video_frames[0], "/var/lib/jenkins/example.mp4")
Loading pipeline components...: 100%|█████████████| 5/5 [00:00<00:00, 8.45it/s] 100%|███████████████████████████████████████████| 50/50 [00:31<00:00, 1.58it/s] '/var/lib/jenkins/example.mp4'
你可以在这个博客的GitHub仓库中的`videos`文件夹中找到所有生成的视频。
基于稳定扩散的模型,包括当前的这个模型,包含不同的组件,例如调度器、文本编码器、分词器、UNet和变分自动编码器。这些组件是模块化的,使我们能够用同类型的其他组件替换。例如,我们可以用更大的模型如OpenCLIP替换基于CLIPTextModel的文本编码器,以改进提示理解。在当前的博客中,我们将向您展示如何测试`diffusers`包中实现的不同调度器的效果。
调度器是负责在管道内组织整个去噪过程的组件。这包括确定去噪步骤的数量、过程是随机还是确定性的,以及使用哪种算法找到去噪样本。调度器在平衡去噪速度和质量方面起着至关重要的作用,通常需要复杂的算法来优化这种权衡。由于定量测量不同调度器效果的固有困难,通常的做法是试验各种选择,以确定哪一个最适合特定扩散管道的需求。你可以在`videos`文件夹中找到生成的视频并比较调度器的效果。
# DPMSolverMultistepScheduler
pipe1 = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b")
pipe1.scheduler = DPMSolverMultistepScheduler.from_config(pipe1.scheduler.config)
pipe1.to("cuda")
#LMSDiscreteScheduler
pipe2 = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b")
pipe2.scheduler = LMSDiscreteScheduler.from_config(pipe2.scheduler.config)
pipe2.to("cuda")
#PNDMScheduler
pipe3 = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b")
pipe3.scheduler = PNDMScheduler.from_config(pipe3.scheduler.config)
pipe3.to("cuda")
video_frames = pipe1(prompt, generator=generator, num_inference_steps=50, num_frames=20).frames
export_to_video(video_frames[0], "/var/lib/jenkins/example1.mp4")
video_frames = pipe2(prompt, generator=generator, num_inference_steps=50, num_frames=20).frames
export_to_video(video_frames[0], "/var/lib/jenkins/example2.mp4")
video_frames = pipe3(prompt, generator=generator, num_inference_steps=50, num_frames=20).frames
export_to_video(video_frames[0], "/var/lib/jenkins/example3.mp4")
Loading pipeline components...: 100%|█████████████| 5/5 [00:00<00:00, 8.24it/s] Loading pipeline components...: 100%|█████████████| 5/5 [00:00<00:00, 8.45it/s] Loading pipeline components...: 100%|█████████████| 5/5 [00:00<00:00, 8.92it/s] 100%|███████████████████████████████████████████| 50/50 [00:30<00:00, 1.66it/s] 100%|███████████████████████████████████████████| 50/50 [00:30<00:00, 1.65it/s] 100%|███████████████████████████████████████████| 50/50 [00:31<00:00, 1.57it/s] '/var/lib/jenkins/example3.mp4'
在接下来的部分中,我们考察了模型在集成训练数据中的先验知识的能力,例如“时代广场”和“梵高风格”。在查看生成的视频后,很明显,模型有效地将这些提示中的关键元素进行了整合,生成了反映指定特征的视频。
# 生成 prompt = "A Robot is dancing in the Times Square" video_frames = pipe(prompt, generator=generator, num_inference_steps=50, num_frames=20).frames export_to_video(video_frames[0], "/var/lib/jenkins/example_ts.mp4") prompt = "A cartoon of a dog dancing in Van Gogh style" video_frames = pipe(prompt, generator=generator, num_inference_steps=50, num_frames=20).frames export_to_video(video_frames[0], "/var/lib/jenkins/example_vs.mp4")
100%|███████████████████████████████████████████| 50/50 [00:31<00:00, 1.59it/s] 100%|███████████████████████████████████████████| 50/50 [00:31<00:00, 1.58it/s] '/var/lib/jenkins/example_vs.mp4'
如果你希望视频中有更高质量的图像,可以考虑增加`num_inference_steps`。对于更长的视频,可以调整`num_frames`。根据你的需求自由地调整这些参数,前提是你没有遇到内存问题。
致谢
我们向ModelScope Text-to-Video 技术报告的作者们致以诚挚的感谢。他们对生成式人工智能社区的宝贵贡献使得本篇博客成为可能。



![[0342].第12节:加载与存储指令及算数指令](https://i-blog.csdnimg.cn/blog_migrate/f2cc4d4eea0f4272b3d442b7af02a4d2.png)