题1.从尾到头打印链表
题目:输入一个链表的头结点,从尾到头反过来打印出每个节点的值。链表的定义如下:
struct ListNode
{
int mValue;
ListNode *mNext;
ListNode *mPrev;
};1.1 方法一:栈
思路:要反过来打印,首先需要遍历,那么从先遍历的节点后打印,典型的后进先出,符合栈的结构。
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
struct ListNode
{
int mValue;
ListNode *mNext;
};
void reverselist(ListNode *pHead)
{
if (pHead == nullptr)
{
return;
}
stack<ListNode *> reversenodes; // 创建一个栈容器
ListNode *node = pHead;
while (node != nullptr) // 遍历链表
{
reversenodes.push(node); // 将其放入栈容器中
node = node->mNext;
}
while (!reversenodes.empty()) // 循环从栈取出节点
{
node = reversenodes.top();
cout << node->mValue << endl;
reversenodes.pop();
}
}
// 添加到链表的尾部
struct ListNode *AddToTail(ListNode *pHead, int value)
{
ListNode *pNew = new ListNode(); // 创建了一个子节点
pNew->mValue = value;
pNew->mNext = nullptr; // 因为是向尾部节点插入值,所以其下一个节点一定是空
if (pHead == nullptr) // 如果头结点为空,则当前节点为头结点
{
pHead = pNew;
}
else // 如果头结点不为空
{
ListNode *pnode = pHead; // 则先取出链表的头结点
while (pnode->mNext != nullptr) // 如果当前节点有子节点,则说明不是最后一个节点
{
pnode = pnode->mNext;
}
pnode->mNext = pNew; // 找到了最后的节点,将此时要添加的节点放到链表的尾部
}
return pHead;
}
int main()
{
ListNode *Head = nullptr;
Head = AddToTail(Head, 1);
Head = AddToTail(Head, 2);
Head = AddToTail(Head, 3);
reverselist(Head);
return 0;
}
1.2 方法二:递归
思想:递归从本质上将就是一个栈的结构,后进先出,所以我们可以当输出一个节点时候,先输入其下一个节点,然后再输出当前节点。
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
struct ListNode
{
int mValue;
ListNode *mNext;
};
void recursionlist(ListNode *pHead)
{
if(pHead == nullptr)//注意递归的返回条件
{
return;
}
if(pHead->mNext != nullptr)//如果当前节点还有子节点,则递归先打印子节点的值
{
recursionlist(pHead->mNext);
}
cout<<pHead->mValue<<endl;
}
// 添加到链表的尾部
struct ListNode *AddToTail(ListNode *pHead, int value)
{
ListNode *pNew = new ListNode(); // 创建了一个子节点
pNew->mValue = value;
pNew->mNext = nullptr; // 因为是向尾部节点插入值,所以其下一个节点一定是空
if (pHead == nullptr) // 如果头结点为空,则当前节点为头结点
{
pHead = pNew;
}
else // 如果头结点不为空
{
ListNode *pnode = pHead; // 则先取出链表的头结点
while (pnode->mNext != nullptr) // 如果当前节点有子节点,则说明不是最后一个节点
{
pnode = pnode->mNext;
}
pnode->mNext = pNew; // 找到了最后的节点,将此时要添加的节点放到链表的尾部
}
return pHead;
}
int main()
{
ListNode *Head = nullptr;
Head = AddToTail(Head, 2);
Head = AddToTail(Head, 3);
Head = AddToTail(Head, 4);
recursionlist(Head);
return 0;
}
题2:两数相加
题目:给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
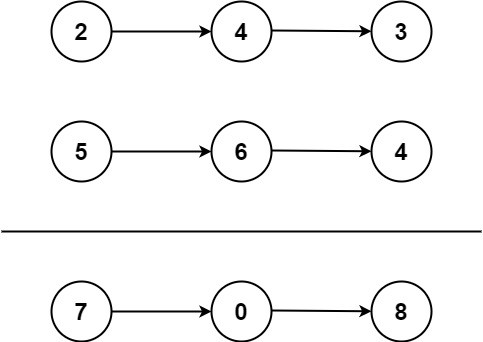
输入:l1 = [2,4,3], l2 = [5,6,4] 输出:[7,0,8] 解释:342 + 465 = 807.
难度:中等
思路:
我们知道其数字为逆序,那么两个链表的相同位置可以直接相加,如果相同位置相加值大于10,则代表要在下一位相加的时候,加1进位。
需要注意的点是:当两个链表都遍历完成,但是进位标志仍然为1,代表我们需要再创建一个节点用于进位。例如:链表1为999,链表二为1,两个相加,当访问完链表1的第三个位置时,循环退出,此时我们的结果为000并且进位标志不为0,因此我们要再创建一个节点存储1的结果,然后将其输出变为0001
代码一
struct ListNode
{
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
class Solution
{
public:
ListNode *addTwoNumbers(ListNode *l1, ListNode *l2)
{
if (l1 == nullptr) // 如果第一个链表为空,则返回第二个链表
{
return l2;
}
if (l2 == nullptr) // 如果第二个链表为空,则返回第一个链表
{
return l1;
}
ListNode *returnlistPhead = nullptr; // 先创建返回链表的头节点链表
ListNode *returnlistptail = nullptr; // 先创建返回链表的头节点链表
int carry = 0; // 代表进位
while (l1 != nullptr || l2 != nullptr)
{
ListNode *node = new ListNode();
if (l1 != nullptr && l2 != nullptr)
{
if (carry + l1->val + l2->val < 10) // 如果两位相加不超过10,则不需要进位
{
node->val = carry + l1->val + l2->val;
carry = 0; // 重置进位,代表当前位数不需要进位
}
else
{
node->val = carry + l1->val + l2->val - 10; // 如果两位相加超过10,则需要进位
carry = 1; // 代表当前位数需要进位
}
l1 = l1->next;
l2 = l2->next;
}
else if (l1 == nullptr) // 此时l2不为空
{
if (carry + l2->val < 10) // 如果两位相加不超过10,则不需要进位
{
node->val = carry + l2->val;
carry = 0; // 重置进位,代表当前位数不需要进位
}
else
{
node->val = carry + l2->val - 10; // 如果两位相加超过10,则需要进位
carry = 1; // 代表当前位数需要进位
}
l2 = l2->next;
}
else if (l2 == nullptr) // 此时l1不为空
{
if (carry + l1->val < 10) // 如果两位相加不超过10,则不需要进位
{
node->val = carry + l1->val;
carry = 0; // 重置进位,代表当前位数不需要进位
}
else
{
node->val = carry + l1->val - 10; // 如果两位相加超过10,则需要进位
carry = 1; // 代表当前位数需要进位
}
l1 = l1->next;
}
// 插入链表中
if (returnlistPhead == nullptr) // 如果返回的链表第一个元素为空
{
returnlistPhead = returnlistptail = node;
returnlistptail->next = nullptr;
}
else
{
returnlistptail->next = node;
returnlistptail = returnlistptail->next;
}
}
if(carry == 1)//当我们每次使用进位后都会将carry重置为0,而此时代表链表一和链表二都遍历完毕,但是还有一次进位没使用,所以要多加一位
//例如链表1为999,链表2为 1,此时必须多创建一个节点,用以进位
{
ListNode *node = new ListNode(1, nullptr);
returnlistptail->next = node;
}
return returnlistPhead;
}
};代码二:
此处主要是将上面的代码简化。
struct ListNode
{
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
class Solution
{
public:
ListNode *addTwoNumbers(ListNode *l1, ListNode *l2)
{
if (l1 == nullptr) // 如果第一个链表为空,则返回第二个链表
{
return l2;
}
if (l2 == nullptr) // 如果第二个链表为空,则返回第一个链表
{
return l1;
}
ListNode *prevreturnPhead = new ListNode(-1,nullptr); // 先创建返回链表的头节点链表的前一个节点
ListNode *prevreturntail = prevreturnPhead;
int carry = 0; // 代表进位
while (l1 || l2 || carry)
{
int sum = 0;
if (l1)
{
sum += l1->val;
l1 = l1->next;
}
if (l2)
{
sum += l2->val;
l2 = l2->next;
}
sum += carry;
prevreturntail->next = new ListNode((sum % 10),nullptr);
prevreturntail = prevreturntail->next;
carry = sum /10;
}
return prevreturnPhead->next;
}
};题3:删除链表的倒数第n个节点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
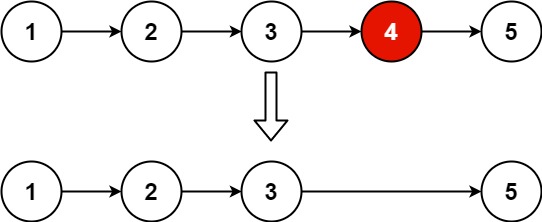
输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
难度:中等
3.1方法一:递归
使用cur标志位找到倒数要删除的节点,如果是要删除的节点,则将当前节点的next指针指向下一个节点的next指针,如果不是要删除的节点,则指针保持不变。
注意在递归调用中指针名称相同,但其代表的含义是不同的。
class Solution
{
public:
int cur = 0;
ListNode *removeNthFromEnd(ListNode *head, int n)
{
if (!head)
return NULL;
head->next = removeNthFromEnd(head->next, n);
cur++;
if (n == cur)
return head->next;
return head;
}
};3.2 方法二:栈
在对链表进行操作时,一种常用的技巧是添加一个哑节点(dummy node),它的 next 指针指向链表的头节点。这样一来,我们就不需要对头节点进行特殊的判断了。
第一步:添加一个哑节点(dummy node),它的 next 指针指向链表的头节点。
第二步:将其循环放入栈中。
第三步:找到要删除的元素的上一个元素,即栈顶元素。
第四步:重置要删除的元素的上一个元素的next指针为删除元素的next指针。
第五步:返回哑节点的next指针,即为链表的头结点。
struct ListNode
{
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
class Solution
{
public:
int cur = 0;
ListNode *removeNthFromEnd(ListNode *head, int n)
{
if (head == nullptr || n <= 0)
{
return nullptr;
}
ListNode *dummynode = new ListNode(0, head);//添加一个哑节点(dummy node),它的 next 指针指向链表的头节点。这样一来,我们就不需要对头节点进行特殊的判断了
ListNode *dummynode2 = dummynode;
stack<ListNode *> stacklists;
while (dummynode2 != nullptr)
{
stacklists.push(dummynode2);
dummynode2 = dummynode2->next;
}
while (n != 0 && !stacklists.empty())
{
n--;
stacklists.pop();
}
ListNode *prevnode = stacklists.top();//要删除节点的上一个节点
prevnode->next = prevnode->next->next;
ListNode *returnhead = dummynode->next;
return returnhead;
}
};题4:两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。

示例 1:
输入:head = [1,2,3,4] 输出:[2,1,4,3]
思路:
第一步:创建哑结点 dummy,令 dummy.next = head。令 temp 表示当前到达的节点,初始时 temp = dummy。每次需要交换 temp 后面的两个节点。
如果 temp 的后面没有节点或者只有一个节点,则没有更多的节点需要交换,因此结束交换。否则,获得 temp 后面的两个节点 node1 和 node2,通过更新节点的指针关系实现两两交换节点。
第二步:交换之前的节点关系是 temp -> node1 -> node2,交换之后的节点关系要变成 temp -> node2 -> node1
temp.next = node2
node1.next = node2.next
node2.next = node1
完成上述操作之后,节点关系即变成 temp -> node2 -> node1。
第三步:再令 temp = node1,对链表中的其余节点进行两两交换,直到全部节点都被两两交换。
两两交换链表中的节点之后,新的链表的头节点是 dummyHead.next,返回新的链表的头节点即可。
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
struct ListNode
{
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
class Solution
{
public:
ListNode *swapPairs(ListNode *head)
{
if (head == nullptr || head->next == nullptr)
{
return head;
}
ListNode *dummy = new ListNode(0, head);//创建一个哑节点,因为除了链表首两个节点交换,其他节点交换会有三个节点的指针发生变化。
//所以为了不特殊处理头节点,创建了哑节点。
ListNode *temp = dummy;
while (temp->next != nullptr && temp->next->next != nullptr)//当哑结点的下一个元素和下两个元素都不为空的时候,才发生交换
//
{
ListNode *one = temp->next;//第一个节点
ListNode *two = temp->next->next;//第二个节点
temp->next = two;
one->next = two->next;
two->next = one;
temp = one;
}
ListNode *retrunhead= dummy->next;
delete dummy;
return retrunhead;
}
};
题5:删除排序链表中重复的元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。

示例 1:
输入:head = [1,1,2] 输出:[1,2]
思路:
本题可以用快慢指针的方法,将慢指针指向第一个节点,快指针指向第二个节点,如果第一个节点的值等于第二个节点的值,则删除当前节点,并移动快指针到下一个值,如果慢指针和快指针指向的值不相等,则慢指针和快指针都向前移动一次,直到遍历完链表。
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
struct ListNode
{
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
class Solution
{
public:
ListNode *deleteDuplicates(ListNode *head)
{
if (head == nullptr || head->next == nullptr)//如果链表中没有元素或者只有一个元素则直接返回
{
return head;
}
ListNode *slow = head;
ListNode *fast = head->next;
while (fast != nullptr)
{
if (slow->val == fast->val)//如果慢指针的值等于快指针的值,则删除当前节点,慢指针的下一个节点指向要删除节点的下一个节点
{
slow->next = fast->next;
fast = fast->next;//更新快指针为要删除节点的下一个节点
}
else //如果慢指针的值不等于快指针的值,则移动慢指针的值到下一位,移动快指针的值也到下一位
{
slow =slow->next;
fast = fast->next;
}
}
return head;
}
};