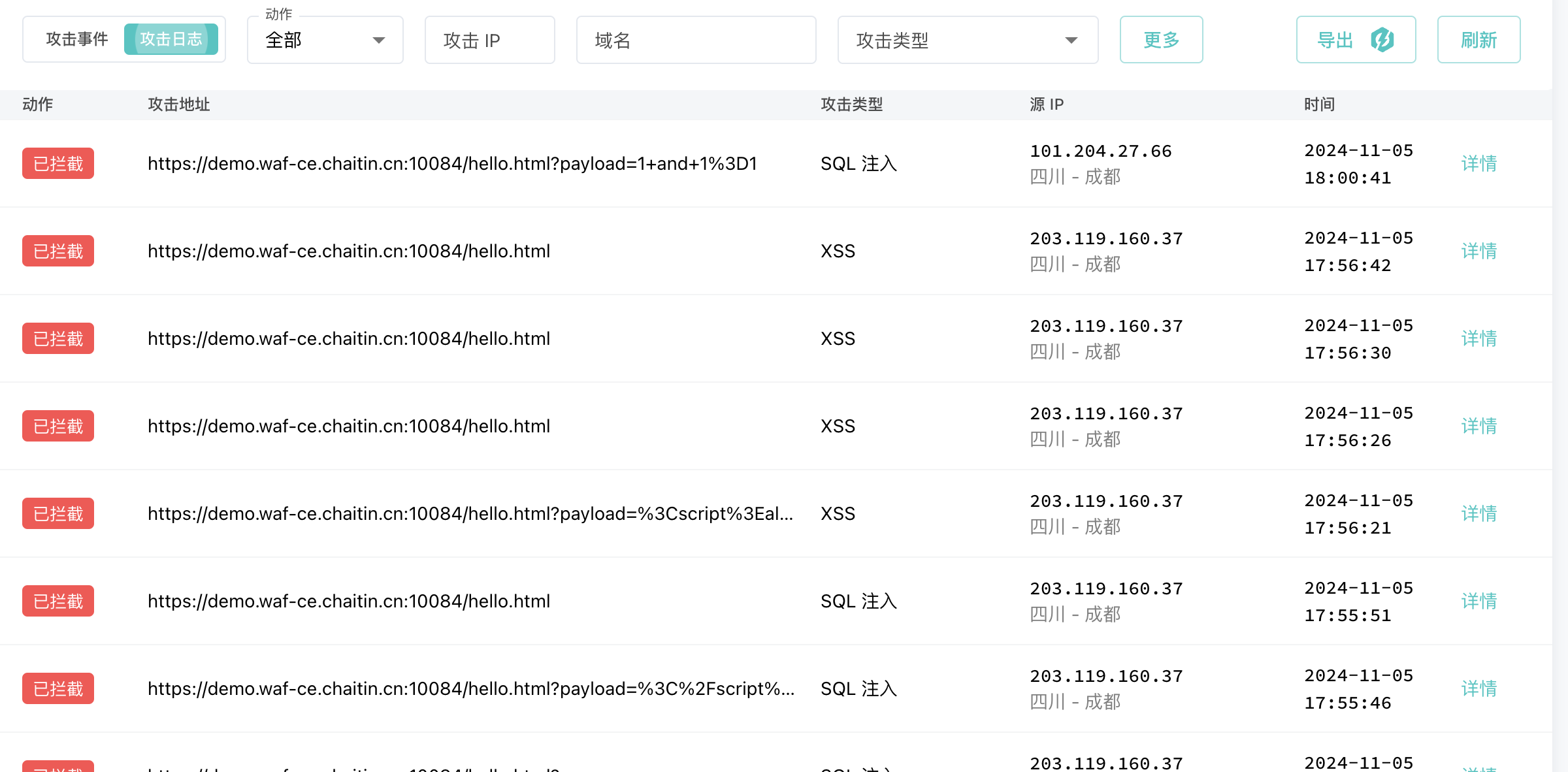
一、概述
扩散式生成模型相较于GAN网络的对抗式生成模型,有更高的精度,也更符合人类的视觉和审美罗技,且风格化能力更强。现行的所有Diffusion模型都是基于2020年的论文DDPM来实现的。
GAN网络通过使生成器(Generator)生成的模型尽可能的逼近真实图片
来实现以假乱真的效果。而相较于GAN,Diffusion的生成模式略有不同。Diffusion包含两个步骤:①前向扩散(为模型添加噪声);②反向扩散(由噪声生成图像)。这两个过程互为反向运算,通过学习,模型能更好的从初始的高斯噪声中拟合出合适的图像。与其说Diffusion是在学习如何画画,倒不如说它是在学习如何为图像去噪。
二、前向扩散

前向扩散可以概述为向原始图片 不断添加高斯噪声,让它最终变为随机噪声
的过程,其公式可以表述为
的递归公式:
其中,是一个值很小的超参数,
是一个0-1的高斯噪声,并且可以将其推倒为:
其中,,
同样是一个0-1的高斯噪声。
三、反向扩散

反向扩散可以理解为前向扩散的逆操作,这一功能在实际计算中通过预测噪声来实现,并通过这个预测噪声逐步将随机噪声
还原成原始图像
。其公式可以表述为递归公式:
其中,为噪声估计函数(用于估计真实噪声
,
是模型的训练参数),
表示预测噪声和真实噪声之间的误差(
)。可见Diffusion模型的训练主要是训练噪声估计模型
,并使用它来估计真实噪声
。
四、训练过程
损失函数使用MSE表示为:
模型的实际预测步骤可以分为以下5步:

五、生成图片
通过章节四中的训练,可以得到估计噪声,然后使用反向扩散公式不断迭代得到最终图像
。
六、噪声预测模型
由于噪声和原始图片处在同一维度中,故可以使用AutoEncoder模型直接进行预测。原论文中直接使用了一个U-Net作为噪音预测模型

七、代码实现
PyTorch版