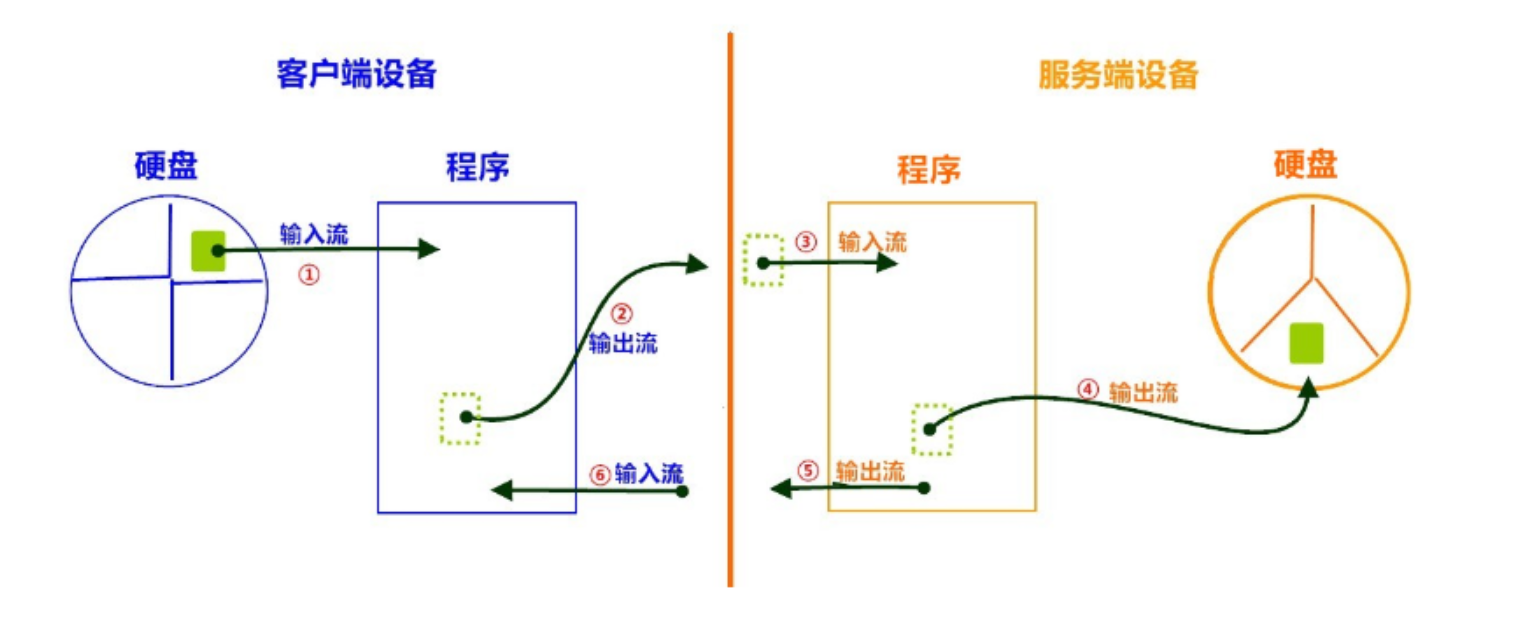
我自己的原文哦~ https://blog.51cto.com/whaosoft/12320861
一、pytorch开发基础相关
首先 PyTorch 的安装可以根据官方文档进行操作:(根据自己cuda版本不同 安装版本也不太一样啊 自己注意)
https://pytorch.org/
pip install torch torchvision1. PyTorch 基础
PyTorch 是数值计算方面其中一个最流行的库,同时也是机器学习研究方面最广泛使用的框架。在很多方面,它和 NumPy 都非常相似,但是它可以在不需要代码做多大改变的情况下,在 CPUs,GPUs,TPUs 上实现计算,以及非常容易实现分布式计算的操作。PyTorch 的其中一个最重要的特征就是自动微分。它可以让需要采用梯度下降算法进行训练的机器学习算法的实现更加方便,可以更高效的自动计算函数的梯度。我们的目标是提供更好的 PyTorch 介绍以及讨论使用 PyTorch 的一些最佳实践。
对于 PyTorch 第一个需要学习的就是张量(Tensors)的概念,张量就是多维数组,它和 numpy 的数组非常相似,但多了一些函数功能。
一个张量可以存储一个标量数值、一个数组、一个矩阵:
import torch
# 标量数值
a = torch.tensor(3)
print(a) # tensor(3)
# 数组
b = torch.tensor([1, 2])
print(b) # tensor([1, 2])
# 矩阵
c = torch.zeros([2, 2])
print(c) # tensor([[0., 0.], [0., 0.]])
# 任意维度的张量
d = torch.rand([2, 2, 2])张量还可以高效的执行代数的运算。机器学习应用中最常见的运算就是矩阵乘法。例如希望将两个随机矩阵进行相乘,维度分别是 和 ,这个运算可以通过矩阵相乘运算实现(@):
import torch
x = torch.randn([3, 5])
y = torch.randn([5, 4])
z = x @ y
print(z)对于向量相加,如下所示:
z = x + y将张量转换为 numpy 数组,可以调用 numpy() 方法:
print(z.numpy())当然,反过来 numpy 数组转换为张量是可以的:
x = torch.tensor(np.random.normal([3, 5]))自动微分
PyTorch 中相比 numpy 最大优点就是可以实现自动微分,这对于优化神经网络参数的应用非常有帮助。下面通过一个例子来帮助理解这个优点。
假设现在有一个复合函数:g(u(x)) ,为了计算 g 对 x 的导数,这里可以采用链式法则,即
而 PyTorch 可以自动实现这个求导的过程。
为了在 PyTorch 中计算导数,首先要创建一个张量,并设置其 requires_grad = True ,然后利用张量运算来定义函数,这里假设 u 是一个二次方的函数,而 g 是一个简单的线性函数,代码如下所示:
x = torch.tensor(1.0, requires_grad=True)
def u(x):
return x * x
def g(u):
return -u在这个例子中,复合函数就是 ,所以导数是 ,如果 x=1 ,那么可以得到 -2 。
在 PyTorch 中调用梯度函数:
dgdx = torch.autograd.grad(g(u(x)), x)[0]
print(dgdx) # tensor(-2.)拟合曲线
为了展示自动微分有多么强大,这里介绍另一个例子。
首先假设我们有一些服从一个曲线(也就是函数 )的样本,然后希望基于这些样本来评估这个函数 f(x) 。我们先定义一个带参数的函数:
函数的输入是 x,然后 w 是参数,目标是找到合适的参数使得下列式子成立:
实现的一个方法可以是通过优化下面的损失函数来实现:
尽管这个问题里有一个正式的函数(即 f(x) 是一个具体的函数),但这里我们还是采用一个更加通用的方法,可以应用到任何一个可微分的函数,并采用随机梯度下降法,即通过计算 L(w) 对于每个参数 w 的梯度的平均值,然后不断从相反反向移动。
利用 PyTorch 实现的代码如下所示:
import numpy as np
import torch
# Assuming we know that the desired function is a polynomial of 2nd degree, we
# allocate a vector of size 3 to hold the coefficients and initialize it with
# random noise.
w = torch.tensor(torch.randn([3, 1]), requires_grad=True)
# We use the Adam optimizer with learning rate set to 0.1 to minimize the loss.
opt = torch.optim.Adam([w], 0.1)
def model(x):
# We define yhat to be our estimate of y.
f = torch.stack([x * x, x, torch.ones_like(x)], 1)
yhat = torch.squeeze(f @ w, 1)
return yhat
def compute_loss(y, yhat):
# The loss is defined to be the mean squared error distance between our
# estimate of y and its true value.
loss = torch.nn.functional.mse_loss(yhat, y)
return loss
def generate_data():
# Generate some training data based on the true function
x = torch.rand(100) * 20 - 10
y = 5 * x * x + 3
return x, y
def train_step():
x, y = generate_data()
yhat = model(x)
loss = compute_loss(y, yhat)
opt.zero_grad()
loss.backward()
opt.step()
for _ in range(1000):
train_step()
print(w.detach().numpy())运行上述代码,可以得到和下面相近的结果:
[4.9924135, 0.00040895029, 3.4504161]这和我们的参数非常接近。
上述只是 PyTorch 可以做的事情的冰山一角。很多问题,比如优化一个带有上百万参数的神经网络,都可以用 PyTorch 高效的用几行代码实现,PyTorch 可以跨多个设备和线程进行拓展,并且支持多个平台。
2. 将模型封装为模块
在之前的例子中,我们构建模型的方式是直接实现张量间的运算操作。但为了让代码看起来更加有组织,推荐采用 PyTorch 的 modules 模块。一个模块实际上是一个包含参数和压缩模型运算的容器。
比如,如果想实现一个线性模型 ,那么实现的代码可以如下所示:
import torch
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.a = torch.nn.Parameter(torch.rand(1))
self.b = torch.nn.Parameter(torch.rand(1))
def forward(self, x):
yhat = self.a * x + self.b
return yhat使用的例子如下所示,需要实例化声明的模型,并且像调用函数一样使用它:
x = torch.arange(100, dtype=torch.float32)
net = Net()
y = net(x)requires_grad
trueparameters()for p in net.parameters():
print(p)现在,假设是一个未知的函数 y=5x+3+n ,注意这里的 n 是表示噪音,然后希望优化模型参数来拟合这个函数,首先可以简单从这个函数进行采样,得到一些样本数据:
x = torch.arange(100, dtype=torch.float32) / 100
y = 5 * x + 3 + torch.rand(100) * 0.3和上一个例子类似,需要定义一个损失函数并优化模型的参数,如下所示:
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
for i in range(10000):
net.zero_grad()
yhat = net(x)
loss = criterion(yhat, y)
loss.backward()
optimizer.step()
print(net.a, net.b) # Should be close to 5 and 3在 PyTorch 中已经实现了很多预定义好的模块。比如 torch.nn.Linear 就是一个类似上述例子中定义的一个更加通用的线性函数,所以我们可以采用这个函数来重写我们的模型代码,如下所示:
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
yhat = self.linear(x.unsqueeze(1)).squeeze(1)
return yhat这里用到了两个函数,squeeze 和 unsqueeze ,主要是torch.nn.Linear 会对一批向量而不是数值进行操作。
同样,默认调用 parameters() 会返回其所有子模块的参数:
net = Net()
for p in net.parameters():
print(p)当然也有一些预定义的模块是作为包容其他模块的容器,最常用的就是 torch.nn.Sequential ,它的名字就暗示了它主要用于堆叠多个模块(或者网络层),例如堆叠两个线性网络层,中间是一个非线性函数 ReLU ,如下所示:
model = torch.nn.Sequential(
torch.nn.Linear(64, 32),
torch.nn.ReLU(),
torch.nn.Linear(32, 10),
)3. 广播机制的优缺点
优点
PyTorch 支持广播的元素积运算。正常情况下,当想执行类似加法和乘法操作的时候,你需要确认操作数的形状是匹配的,比如无法进行一个 [3, 2] 大小的张量和 [3, 4] 大小的张量的加法操作。
但是存在一种特殊的情况:只有单一维度的时候,PyTorch 会隐式的根据另一个操作数的维度来拓展只有单一维度的操作数张量。因此,实现 [3,2] 大小的张量和 [3,1] 大小的张量相加的操作是合法的。
如下代码展示了一个加法的例子:
import torch
a = torch.tensor([[1., 2.], [3., 4.]])
b = torch.tensor([[1.], [2.]])
# c = a + b.repeat([1, 2])
c = a + b
print(c)广播机制可以实现隐式的维度复制操作(repeat 操作),并且代码更短,内存使用上也更加高效,因为不需要存储复制的数据的结果。这个机制非常适合用于结合多个维度不同的特征的时候。
为了拼接不同维度的特征,通常的做法是先对输入张量进行维度上的复制,然后拼接后使用非线性激活函数。整个过程的代码实现如下所示:
a = torch.rand([5, 3, 5])
b = torch.rand([5, 1, 6])
linear = torch.nn.Linear(11, 10)
# concat a and b and apply nonlinearity
tiled_b = b.repeat([1, 3, 1]) # b shape: [5, 3, 6]
c = torch.cat([a, tiled_b], 2) # c shape: [5, 3, 11]
d = torch.nn.functional.relu(linear(c))
print(d.shape) # torch.Size([5, 3, 10])但实际上通过广播机制可以实现得更加高效,即 f(m(x+y)) 是等同于 f(mx+my) 的,也就是我们可以先分别做线性操作,然后通过广播机制来做隐式的拼接操作,如下所示:
a = torch.rand([5, 3, 5])
b = torch.rand([5, 1, 6])
linear1 = torch.nn.Linear(5, 10)
linear2 = torch.nn.Linear(6, 10)
pa = linear1(a) # pa shape: [5, 3, 10]
pb = linear2(b) # pb shape: [5, 1, 10]
d = torch.nn.functional.relu(pa + pb)
print(d.shape) # torch.Size([5, 3, 10])实际上这段代码非常通用,可以用于任意维度大小的张量,只要它们之间是可以实现广播机制的,如下所示:
class Merge(torch.nn.Module):
def __init__(self, in_features1, in_features2, out_features, activation=None):
super().__init__()
self.linear1 = torch.nn.Linear(in_features1, out_features)
self.linear2 = torch.nn.Linear(in_features2, out_features)
self.activation = activation
def forward(self, a, b):
pa = self.linear1(a)
pb = self.linear2(b)
c = pa + pb
if self.activation is not None:
c = self.activation(c)
return c缺点
到目前为止,我们讨论的都是广播机制的优点。但它的缺点是什么呢?原因也是出现在隐式的操作,这种做法非常不利于进行代码的调试。
这里给出一个代码例子:
a = torch.tensor([[1.], [2.]])
b = torch.tensor([1., 2.])
c = torch.sum(a + b)
print(c)所以上述代码的输出结果 c 是什么呢?你可能觉得是 6,但这是错的,正确答案是 12 。这是因为当两个张量的维度不匹配的时候,PyTorch 会自动将维度低的张量的第一个维度进行拓展,然后在进行元素之间的运算,所以这里会将b 先拓展为 [[1, 2], [1, 2]],然后 a+b 的结果应该是 [[2,3], [3, 4]] ,然后sum 操作是将所有元素求和得到结果 12。
那么避免这种结果的方法就是显式的操作,比如在这个例子中就需要指定好想要求和的维度,这样进行代码调试会更简单,代码修改后如下所示:
a = torch.tensor([[1.], [2.]])
b = torch.tensor([1., 2.])
c = torch.sum(a + b, 0)
print(c)这里得到的 c 的结果是 [5, 7],而我们基于结果的维度可以知道出现了错误。
这有个通用的做法,就是在做累加( reduction )操作或者使用 torch.squeeze 的时候总是指定好维度。
4. 使用好重载的运算符
和 NumPy 一样,PyTorch 会重载 python 的一些运算符来让 PyTorch 代码更简短和更有可读性。
例如,切片操作就是其中一个重载的运算符,可以更容易的对张量进行索引操作,如下所示:
z = x[begin:end] # z = torch.narrow(0, begin, end-begin)但需要谨慎使用这个运算符,它和其他运算符一样,也有一些副作用。正因为它是一个非常常用的运算操作,如果过度使用可以导致代码变得低效。
这里给出一个例子来展示它是如何导致代码变得低效的。这个例子中我们希望对一个矩阵手动实现行之间的累加操作:
import torch
import time
x = torch.rand([500, 10])
z = torch.zeros([10])
start = time.time()
for i in range(500):
z += x[i]
print("Took %f seconds." % (time.time() - start))上述代码的运行速度会非常慢,因为总共调用了 500 次的切片操作,这就是过度使用了。一个更好的做法是采用 torch.unbind 运算符在每次循环中将矩阵切片为一个向量的列表,如下所示:
z = torch.zeros([10])
for x_i in torch.unbind(x):
z += x_i这个改进会提高一些速度(在作者的机器上是提高了大约30%)。
但正确的做法应该是采用 torch.sum 来一步实现累加的操作:
z = torch.sum(x, dim=0)这种实现速度就非常的快(在作者的机器上提高了100%的速度)。
其他重载的算数和逻辑运算符分别是:
z = -x # z = torch.neg(x)
z = x + y # z = torch.add(x, y)
z = x - y
z = x * y # z = torch.mul(x, y)
z = x / y # z = torch.div(x, y)
z = x // y
z = x % y
z = x ** y # z = torch.pow(x, y)
z = x @ y # z = torch.matmul(x, y)
z = x > y
z = x >= y
z = x < y
z = x <= y
z = abs(x) # z = torch.abs(x)
z = x & y
z = x | y
z = x ^ y # z = torch.logical_xor(x, y)
z = ~x # z = torch.logical_not(x)
z = x == y # z = torch.eq(x, y)
z = x != y # z = torch.ne(x, y)还可以使用这些运算符的递增版本,比如 x += y 和 x **=2 都是合法的。
另外,Python 并不允许重载 and 、or 和 not 三个关键词。
5. 采用 TorchScript 优化运行时间
PyTorch 优化了维度很大的张量的运算操作。在 PyTorch 中对小张量进行太多的运算操作是非常低效的。所以有可能的话,将计算操作都重写为批次(batch)的形式,可以减少消耗和提高性能。而如果没办法自己手动实现批次的运算操作,那么可以采用 TorchScript 来提升代码的性能。
TorchScript 是一个 Python 函数的子集,但经过了 PyTorch 的验证,PyTorch 可以通过其 just in time(jtt) 编译器来自动优化 TorchScript 代码,提高性能。
下面给出一个具体的例子。在机器学习应用中非常常见的操作就是 batch gather ,也就是 output[i] = input[i, index[i]]。其代码实现如下所示:
import torch
def batch_gather(tensor, indices):
output = []
for i in range(tensor.size(0)):
output += [tensor[i][indices[i]]]
return torch.stack(output)torch.jit.script@torch.jit.script
def batch_gather_jit(tensor, indices):
output = []
for i in range(tensor.size(0)):
output += [tensor[i][indices[i]]]
return torch.stack(output)这个做法可以提高 10% 的运算速度。
但更好的做法还是手动实现批次的运算操作,下面是一个向量化实现的代码例子,提高了 100 倍的速度:
def batch_gather_vec(tensor, indices):
shape = list(tensor.shape)
flat_first = torch.reshape(
tensor, [shape[0] * shape[1]] + shape[2:])
offset = torch.reshape(
torch.arange(shape[0]).cuda() * shape[1],
[shape[0]] + [1] * (len(indices.shape) - 1))
output = flat_first[indices + offset]
return output6. 构建高效的自定义数据加载类
上一节介绍了如何写出更加高效的 PyTorch 的代码,但为了让你的代码运行更快,将数据更加高效加载到内存中也是非常重要的。幸运的是 PyTorch 提供了一个很容易加载数据的工具,即 DataLoader 。一个 DataLoader 会采用多个 workers 来同时将数据从 Dataset 类中加载,并且可以选择使用 Sampler 类来对采样数据和组成 batch 形式的数据。
如果你可以随时访问你的数据,那么使用 DataLoader 会非常简单:只需要继承 Dataset 类别并实现 __getitem__ (读取每个数据)和 __len__(返回数据集的样本数量)这两个方法。下面给出一个代码例子,如何从给定的文件夹中加载图片数据:
import glob
import os
import random
import cv2
import torch
class ImageDirectoryDataset(torch.utils.data.Dataset):
def __init__(path, pattern):
self.paths = list(glob.glob(os.path.join(path, pattern)))
def __len__(self):
return len(self.paths)
def __item__(self):
path = random.choice(paths)
return cv2.imread(path, 1)比如想将文件夹内所有的 jpeg 图片都加载,代码实现如下所示:
dataloader = torch.utils.data.DataLoader(ImageDirectoryDataset("/data/imagenet/*.jpg"), num_workers=8)
for data in dataloader:
# do something with dataworkers当你的数据都很大或者你的硬盘读写速度很快,采用DataLoader进行随机读取数据是可行的。但也可能存在一种情况,就是使用的是一个很慢的连接速度的网络文件系统,请求单个文件的速度都非常的慢,而这可能就是整个训练过程中的瓶颈。
一个更好的做法就是将数据保存为一个可以连续读取的连续文件格式。例如,当你有非常大量的图片数据,可以采用 tar 命令将其压缩为一个文件,然后用 python 来从这个压缩文件中连续的读取图片。要实现这个操作,需要用到 PyTorch 的 IterableDataset。创建一个 IterableDataset 类,只需要实现 __iter__ 方法即可。
下面给出代码实现的例子:
import tarfile
import torch
def tar_image_iterator(path):
tar = tarfile.open(self.path, "r")
for tar_info in tar:
file = tar.extractfile(tar_info)
content = file.read()
yield cv2.imdecode(content, 1)
file.close()
tar.members = []
tar.close()
class TarImageDataset(torch.utils.data.IterableDataset):
def __init__(self, path):
super().__init__()
self.path = path
def __iter__(self):
yield from tar_image_iterator(self.path)不过这个方法有一个问题,当使用 DataLoader 以及多个 workers 读取这个数据集的时候,会得到很多重复的数据:
dataloader = torch.utils.data.DataLoader(TarImageDataset("/data/imagenet.tar"), num_workers=8)
for data in dataloader:
# data contains duplicated itemsworker
tar
num_workers
tar
workerclass TarImageDataset(torch.utils.data.IterableDataset):
def __init__(self, paths):
super().__init__()
self.paths = paths
def __iter__(self):
worker_info = torch.utils.data.get_worker_info()
# For simplicity we assume num_workers is equal to number of tar files
if worker_info is None or worker_info.num_workers != len(self.paths):
raise ValueError("Number of workers doesn't match number of files.")
yield from tar_image_iterator(self.paths[worker_info.worker_id])所以使用例子如下所示:
dataloader = torch.utils.data.DataLoader(
TarImageDataset(["/data/imagenet_part1.tar", "/data/imagenet_part2.tar"]), num_workers=2)
for data in dataloader:
# do something with datatfrecordhttps://github.com/vahidk/tfrecord
7. PyTorch 的数值稳定性
当使用任意一个数值计算库,比如 NumPy 或者 PyTorch ,都需要知道一点,编写数学上正确的代码不一定会得到正确的结果,你需要确保这个计算是稳定的。
首先以一个简单的例子开始。从数学上来说,对任意的非零 x ,都可以知道式子 是成立的。但看看具体实现的时候,是不是总是正确的:
import numpy as np
x = np.float32(1)
y = np.float32(1e-50) # y would be stored as zero
z = x * y / y
print(z) # prints nannan
y
float32另一种极端情况就是 y 非常的大:
y = np.float32(1e39) # y would be stored as inf
z = x * y / y
print(z) # prints nannan
y
inf
float32
1.4013e-45 ~ 3.40282e+38下面是如何查看一种数据类型的数值范围:
print(np.nextafter(np.float32(0), np.float32(1))) # prints 1.4013e-45
print(np.finfo(np.float32).max) # print 3.40282e+38为了让计算变得稳定,需要避免过大或者过小的数值。这看起来很容易,但这类问题是很难进行调试,特别是在 PyTorch 中进行梯度下降的时候。这不仅因为需要确保在前向传播过程中的所有数值都在使用的数据类型的取值范围内,还要保证在反向传播中也做到这一点。
下面给出一个代码例子,计算一个输出向量的 softmax,一种不好的代码实现如下所示:
import torch
def unstable_softmax(logits):
exp = torch.exp(logits)
return exp / torch.sum(exp)
print(unstable_softmax(torch.tensor([1000., 0.])).numpy()) # prints [ nan, 0.]这里计算 logits 的指数数值可能会得到超出 float32 类型的取值范围,即过大或过小的数值,这里最大的 logits 数值是 ln(3.40282e+38) = 88.7,超过这个数值都会导致 nan 。
那么应该如何避免这种情况,做法很简单。因为有 ,也就是我们可以对 logits 减去一个常量,但结果保持不变,所以我们选择logits 的最大值作为这个常数,这种做法,指数函数的取值范围就会限制为 [-inf, 0] ,然后最终的结果就是 [0.0, 1.0] 的范围,代码实现如下所示:
import torch
def softmax(logits):
exp = torch.exp(logits - torch.reduce_max(logits))
return exp / torch.sum(exp)
print(softmax(torch.tensor([1000., 0.])).numpy()) # prints [ 1., 0.]接下来是一个更复杂点的例子。
假设现在有一个分类问题。我们采用 softmax 函数对输出值 logits 计算概率。接着定义采用预测值和标签的交叉熵作为损失函数。对于一个类别分布的交叉熵可以简单定义为 :
所以有一个不好的实现交叉熵的代码实现为:
def unstable_softmax_cross_entropy(labels, logits):
logits = torch.log(softmax(logits))
return -torch.sum(labels * logits)
labels = torch.tensor([0.5, 0.5])
logits = torch.tensor([1000., 0.])
xe = unstable_softmax_cross_entropy(labels, logits)
print(xe.numpy()) # prints inf在上述代码实现中,当 softmax 结果趋向于 0,其 log 输出会趋向于无穷,这就导致计算结果的不稳定性。所以可以对其进行重写,将 softmax 维度拓展并做一些归一化的操作:
def softmax_cross_entropy(labels, logits, dim=-1):
scaled_logits = logits - torch.max(logits)
normalized_logits = scaled_logits - torch.logsumexp(scaled_logits, dim)
return -torch.sum(labels * normalized_logits)
labels = torch.tensor([0.5, 0.5])
logits = torch.tensor([1000., 0.])
xe = softmax_cross_entropy(labels, logits)
print(xe.numpy()) # prints 500.0可以验证计算的梯度也是正确的:
logits.requires_grad_(True)
xe = softmax_cross_entropy(labels, logits)
g = torch.autograd.grad(xe, logits)[0]
print(g.numpy()) # prints [0.5, -0.5]这里需要再次提醒,进行梯度下降操作的时候需要额外的小心谨慎,需要确保每个网络层的函数和梯度的范围都在合法的范围内,指数函数和对数函数在不正确使用的时候都可能导致很大的问题,它们都能将非常小的数值转换为非常大的数值,或者从很大变为很小的数值。
二、预处理相关
如何使用 Taichi Kernel 来实现 PyTorch 程序中特殊的数据预处理和自定义的算子,告别手写 CUDA,用轻巧便捷的方式提升机器学习模型算法的开发效率和灵活性。
边缘填充(Padding)是机器学习中常用的预处理方法。如在对图像执行卷积操作时,用户需要对图像边缘进行填充,以保证图像输入输出前后的尺寸不变。一般来说,填充的方法有零填充或 torch.nn.functional.pad 提供的重复填充、循环填充等其他预设模式。但有时候我们想要在边缘上填充某个特殊的纹理或者模式,却并没有一个精心优化过的 PyTorch 算子能够适配这种场景。
解决方案有两个:使用 PyTorch 或者 Python 逐个操作矩阵元素;手写 C++ 或 CUDA 代码并接入PyTorch。前者的计算效率非常低,会拖累神经网络的训练速度;后者学习曲线陡峭,实操非常麻烦,开发流程冗长。
那么,有没有更好的方案呢?接下来我们将通过一个例子,带大家体验如何用 Taichi 做一个砖墙纹理的边缘填充。
🧱 用Taichi给PyTorch「添砖加瓦」!
第一步,我们在PyTorch中创建一个如下图所示的「砖块」。为了更好地观察填充的规律,我们给这块「砖」填充上了渐变的颜色:
![]()
填充的基本单元
第二步,我们想要在x轴上错位重复这个「砖」,也就是如下所示的效果:

由于PyTorch中没有为这样的填充提供原生的算子,为了提高运算效率,需要将padding过程改写成一系列PyTorch的原生矩阵运算:
def torch_pad(arr, tile, y):
# image_pixel_to_coord
arr[:, :, 0] = image_height - 1 + ph - arr[:, :, 0]
arr[:, :, 1] -= pw
arr1 = torch.flip(arr, (2, ))
# map_coord
v = torch.floor(arr1[:, :, 1] / tile_height).to(torch.int)
u = torch.floor((arr1[:, :, 0] - v * shift_y[0]) / tile_width).to(torch.int)
uu = torch.stack((u, u), axis=2)
vv = torch.stack((v, v), axis=2)
arr2 = arr1 - uu * shift_x - vv * shift_y
# coord_to_tile_pixel
arr2[:, :, 1] = tile_height - 1 - arr2[:, :, 1]
table = torch.flip(arr2, (2, ))
table = table.view(-1, 2).to(torch.float)
inds = table.mv(y)
gathered = torch.index_select(tile.view(-1), 0, inds.to(torch.long))
return gathered
with Timer():
gathered = torch_pad(coords, tile, y)
torch.cuda.synchronize(device=device)这一系列的矩阵操作并不是特别直观,而且需要在GPU内存中保存多个中间结果矩阵。一个较为明显的缺点是显存比较小的卡上可能就跑不起来了。而如果使用Taichi,我们可以非常直接地描述这个运算:
@ti.kernel
def ti_pad(image_pixels: ti.types.ndarray(), tile: ti.types.ndarray()):
for row, col in ti.ndrange(image_height, image_width):
# image_pixel_to_coord
x1, y1 = ti.math.ivec2(col - pw, image_height - 1 - row + ph)
# map_coord
v: ti.i32 = ti.floor(y1 / tile_height)
u: ti.i32 = ti.floor((x1 - v * shift_y[0]) / tile_width)
x2, y2 = ti.math.ivec2(x1 - u * shift_x[0] - v * shift_y[0],
y1 - u * shift_x[1] - v * shift_y[1])
# coord_to_tile_pixel
x, y = ti.math.ivec2(tile_height - 1 - y2, x2)
image_pixels[row, col] = tile[x, y]
with Timer():
ti_pad(image_pixels, tile)
ti.sync()这段代码逻辑非常简单:遍历输出图片的每个像素,计算当前像素对应到输入的「砖块」图片中的位置,最后复制该位置的颜色到这个像素。虽然看起来是在逐个写入每个像素,但Taichi会将kernel的顶层for-loop编译成高度并行的GPU代码。同时,上一段代码中我们直接把两个PyTorch的Tensor传给了 Taichi 函数ti_pad ,Taichi会直接使用PyTorch分配好的内存,不会因为两个框架间的数据交互而产生额外开销。
最后,实际的运算性能是:在RTX3090 GPU上运行时,PyTorch (v1.12.1)耗费了30.392 ms[1],而Taichi版本的Kernel耗时仅0.267 ms[2],Taichi相对PyTorch的加速比超过了100倍。

*加速比会因实现细节和运行硬件略有不同
事实上,上述的 PyTorch 底层实现需要启动 58 个 CUDA Kernel,而本例中 Taichi 将全部运算编译成了 1 个 CUDA Kernel。更少的 Kernel 减少了 GPU 函数启动的开销,且相比 PyTorch 实现,Taichi 节省了大量冗余的内存操作。在 GPU 上内存操作远比运算操作开销更「昂贵」,这也是非常夸张的加速比的来源。Taichi 的设计遵循了 「Megakernel」的设计准则:使用单个大的 Kernel 去完成尽可能多的运算逻辑,这与机器学习系统设计中常见的 「算子融合优化」是一样的道理。
在数据预处理问题上,一方面 Taichi 拥有更精细的操作颗粒度,能灵活适配研究人员不同的需求,另一方面 Taichi 能达到更高的计算性能,显著提升预处理部分的运行速度。当然,预处理仅仅是机器学习训练和推理过程中的一小步,对于机器学习领域的研究人员来说,有大量时间花费在模型前向和反向的计算算子中。那么对于定制高性能 ML 算子,Taichi 有什么好办法?
案例 2:定制高性能 ML 算子
和预处理遇到的问题一样,很多时候研究员用到的算子非常新或者干脆是自己发明的,在 PyTorch 中找不到良好的支持。考虑到机器学习训练和推理计算量大、成本高昂,很多研究员不得不去学习 CUDA 并尽力调优,以提升计算效率。但 CUDA 代码编写难度大,调试困难,会拖慢模型迭代速度。
有一篇知乎文章[3]讲述了一个精彩的例子:作者开发了 RWKV 语言模型,使用了一个类似一维的深度卷积(depthwise convolution)的自定义算子。这个算子本身计算量不大,但是因为 PyTorch 中没有原生支持,跑得特别慢。为了解决计算性能的问题,作者编写 CUDA 代码并且采用循环合并、Shared Memory 等多种技巧来优化,最终性能达到了 PyTorch 实现的 20 倍性能。
参考这篇文章和发布的 CUDA 代码,我们也使用相同的优化手段实现了对应的 Taichi 版本。那么 Taichi 在这个例子中性能如何呢?请看下图:
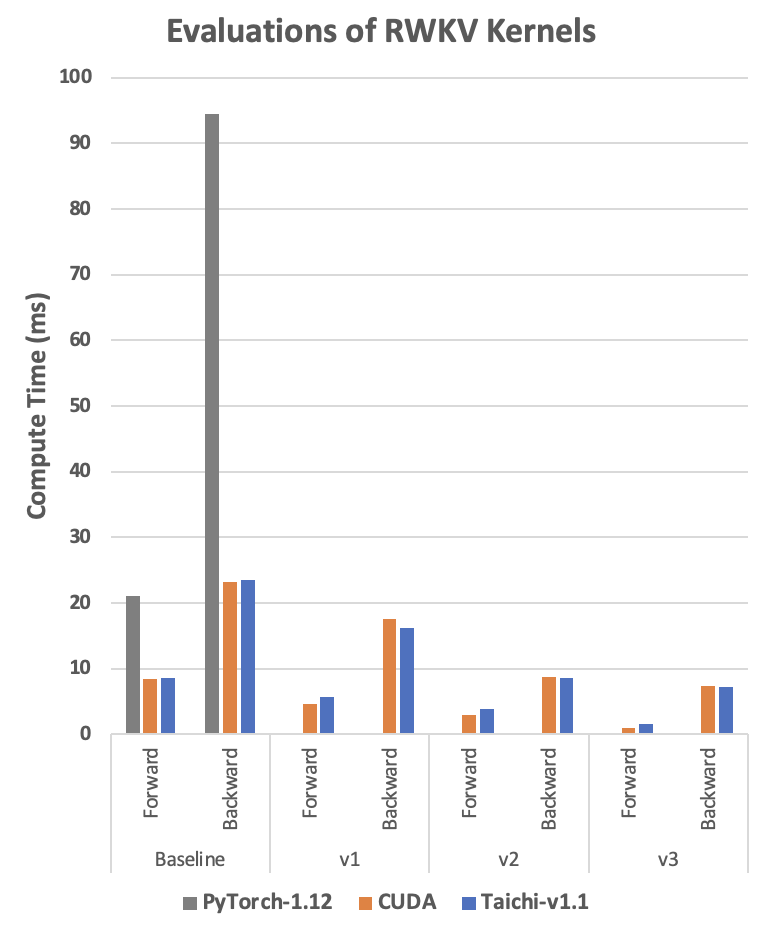
RTX3080 上的 RWKV 运算时间,单位是毫秒,越低越好。Baseline 代表代码直接实现算法,不做任何优化。v1-v3 代表不同的优化版本。CUDA 实现代码见[4], Taichi 实现代码见[5]。
我们可以看到,在使用同样的优化技术的前提下, Taichi 版本达到了非常接近 CUDA 的性能,甚至某些情况下还略快一点。这样的性能水平是如何用 Taichi 实现的呢?会有多么简单呢?
接下来我们就以 Baseline 版本为例,体验如何用 Taichi 轻松实现深度卷积算子!算子本身的运算过程很简单:遍历两个输入 Tensor w 和 k, 把它们对应位置的元素乘起来,通过一个累加循环计算出 s 并存进输出 Tensor out。
🚲 Python 实现(很慢很好懂)
def run_formula_very_slow(w, k, B, C, T, eps):
out = torch.empty((B, C, T), device='cpu')
for b in range(B):
for c in range(C):
for t in range(T):
s = eps
for u in range(t-T+1, t+1):
s += w[c][0][(T-1)-(t-u)] * k[b][c][u+T-1]
out[b][c][t] = s
return out这段代码非常直观好懂,但它运行速度如此之慢,以至于测试出来的数据都没办法把它放进上面那张图里...
🚗 PyTorch 实现(一般慢不好懂)
out = eps + F.conv1d(nn.ZeroPad2d((T-1, 0, 0, 0))(k), w.unsqueeze(1), groups=C)从上面的 Python 代码写出 PyTorch 的这一行还是非常有难度的,要对 PyTorch 的这几个算子底层的运算逻辑很熟悉才能写得出来。
🚀 Taichi 实现(很快很好懂)
@ti.kernel
def taichi_forward_v0(
out: ti.types.ndarray(field_dim=3),
w: ti.types.ndarray(field_dim=3),
k: ti.types.ndarray(field_dim=3),
eps: ti.f32):
for b, c, t in out:
s = eps
for u in range(t-T+1, t+1):
s += w[c, 0, (T-1)-(t-u)] * k[b, c, u+T-1]
out[b, c, t] = sTaichi 代码和 Python 代码几乎完全一致,而且不用考虑并行、指针偏移计算等等各种编程细节,就可以达到和 CUDA 接近的性能,在开发效率上具有很大的优势。作为对比,我们也把对应的 CUDA 版本放在后面,有兴趣的读者可以看一下。CUDA 版本的可读性差了很多。它的外层循环是隐含在线程并行的逻辑里。另外,它的指针的偏移计算比较复杂,每个元素在矩阵中的位置没办法很直观地看出来,需要做一些推演才能完全理解这段代码,当算法再复杂一些的时候就很容易写错。
__global__ void kernel_forward(const float* w, const float* k, float* x,
const float eps, const int B, const int C, const int T)
{
const int i = blockIdx.y;
const int t = threadIdx.x;
float s = eps;
const float* www = w + (i % C) * T + (T - 1) - t;
const float* kk = k + i * T;
for (int u = 0; u <= t; u++){
s += www[u] * kk[u];
}
x[i * T + t] = s;
}更重要的是,CUDA 代码需要编译环境才能运行。如果提前编译成动态库,又需要对齐 CUDA 运行时环境。环境配置、Python 接口封装等等都需要耗费精力去做。而 Taichi 代码本身就是一小段 Python 代码,可以通过 pip 安装管理,与 PyTorch 完全一致,简单了很多,其良好的可复现性,也便于机器学习开发者开源、分享代码。更好的性能、更敏捷的开发效率、更便捷的分享方式,共同构成了使用 Taichi 开发自定义 ML 算子的显著优势。
总结
虽然 PyTorch 可以高效完成机器学习中大部分的运算任务,但仍有许多算子没有实现或者运算效率无法满足需求。作为嵌在 Python 中的高性能编程语言,Taichi 易于编写、内存消耗小,计算性能接近手写 CUDA。本文展示的两个例子,正是结合 Taichi 和 PyTorch 之所长,解决了预处理算子和新算法中的算子的高性能编程问题,同时 Taichi 和 Pytorch Tensor 零开销交互的特性也省去了编写「脚手架」代码的时间,极大地提升了开发效率。希望 Taichi 可以将机器学习研究人员从繁复晦涩的高性能代码编写、验证、调优中解放出来,专注于算法本身,创造出更多有趣的东西 :-)
二、在PyTorch中创建和使用Python自定义操作符
关于如何在PyTorch中创建和使用Python自定义操作符(Custom Operators)的教程
在vllm里面看到flash attention包了一层@torch.library.custom_op装饰器(https://github.com/vllm-project/vllm/pull/7536),查阅了一下资料,发现这个是torch 2.4之后的新feature,防止打算torch compile的graph,翻译一下官方教程稍微了解一下这个用法。来源:https://pytorch.org/tutorials/advanced/python_custom_ops.html
Python Custom Operators 教程

这个教程介绍了Python自定义运算符的主题。它列出了我们将从这一教程中学习到的内容,包括如何将用Python编写的自定义运算符与PyTorch集成,以及如何使用torch.library.opcheck来测试自定义运算符。所需的先决条件是安装了PyTorch 2.4或更高版本。
PyTorch提供了大量可以在Tensor上运行的运算符(例如torch.add、torch.sum等)。但是,您可能希望在PyTorch中使用一个新的自定义运算符,可能是由第三方库编写的。本教程展示了如何封装Python函数,使它们的行为类似于PyTorch原生运算符。创建PyTorch中的自定义运算符的原因可能包括:
将任意Python函数视为不透明的可调用对象,与torch.compile相对应(即防止torch.compile跟踪进入函数)。
为任意Python函数添加训练支持。
请注意,如果您的操作可以表示为现有PyTorch运算符的组合,那么通常就不需要使用自定义运算符(例如,支持自动微分的运算应该可以直接工作)。
例子:将PIL库的crop功能封装为一个自定义运算符
假设我们在使用PIL的crop操作
import torch
from torchvision.transforms.functional import to_pil_image, pil_to_tensor
import PIL
import IPython
import matplotlib.pyplot as plt
def crop(pic, box):
img = to_pil_image(pic.cpu())
cropped_img = img.crop(box)
return pil_to_tensor(cropped_img).to(pic.device) / 255.
def display(img):
plt.imshow(img.numpy().transpose((1, 2, 0)))
img = torch.ones(3, 64, 64)
img *= torch.linspace(0, 1, steps=64) * torch.linspace(0, 1, steps=64).unsqueeze(-1)
display(img)
cropped_img = crop(img, (10, 10, 50, 50))
display(cropped_img)
crop功能无法被torch.compile有效地开箱即用处理:torch.compile在无法处理的函数上会引发"图中断"(https://pytorch.org/docs/stable/torch.compiler_faq.html#graph-breaks),而图中断会导致性能下降。以下代码通过引发错误来演示这一点(如果发生图中断,torch.compile(with fullgraph=True)会引发错误)。
@torch.compile(fullgraph=True)
def f(img):
return crop(img, (10, 10, 50, 50))
# The following raises an error. Uncomment the line to see it.
# cropped_img = f(img)为了能在torch.compile中使用crop作为黑盒操作,我们需要做两件事:
- 将该函数封装为一个PyTorch自定义运算符。
- 为该运算符添加"FakeTensor kernel"(又称"meta kernel")。给定输入Tensor的元数据(例如形状),此函数说明如何计算输出Tensor的元数据。
from typing import Sequence
# Use torch.library.custom_op to define a new custom operator.
# If your operator mutates any input Tensors, their names must be specified
# in the ``mutates_args`` argument.
@torch.library.custom_op("mylib::crop", mutates_args=())
def crop(pic: torch.Tensor, box: Sequence[int]) -> torch.Tensor:
img = to_pil_image(pic.cpu())
cropped_img = img.crop(box)
return (pil_to_tensor(cropped_img) / 255.).to(pic.device, pic.dtype)
# Use register_fake to add a ``FakeTensor`` kernel for the operator
@crop.register_fake
def _(pic, box):
channels = pic.shape[0]
x0, y0, x1, y1 = box
return pic.new_empty(channels, y1 - y0, x1 - x0)做了上述操作之后,crop现在可以在不产生图中断的情况下正常工作了。
@torch.compile(fullgraph=True)
def f(img):
return crop(img, (10, 10, 50, 50))
cropped_img = f(img)
display(img)
display(cropped_img)
为crop添加训练支持
使用torch.library.register_autograd为运算符添加训练支持。相比直接使用torch.autograd.Function,优先使用这种方式;因为autograd.Function与PyTorch运算符注册API组合使用时,可能会在与torch.compile组合时导致无声的不正确性。crop的梯度公式本质上是PIL.paste(我们把推导留作读者练习)。让我们首先将paste封装为一个自定义运算符:
@torch.library.custom_op("mylib::paste", mutates_args=())
def paste(im1: torch.Tensor, im2: torch.Tensor, coord: Sequence[int]) -> torch.Tensor:
assert im1.device == im2.device
assert im1.dtype == im2.dtype
im1_pil = to_pil_image(im1.cpu())
im2_pil = to_pil_image(im2.cpu())
PIL.Image.Image.paste(im1_pil, im2_pil, coord)
return (pil_to_tensor(im1_pil) / 255.).to(im1.device, im1.dtype)
@paste.register_fake
def _(im1, im2, coord):
assert im1.device == im2.device
assert im1.dtype == im2.dtype
return torch.empty_like(im1)现在让我们使用register_autograd来为crop指定梯度公式:
def backward(ctx, grad_output):
grad_input = grad_output.new_zeros(ctx.pic_shape)
grad_input = paste(grad_input, grad_output, ctx.coords)
return grad_input, None
def setup_context(ctx, inputs, output):
pic, box = inputs
ctx.coords = box[:2]
ctx.pic_shape = pic.shape
crop.register_autograd(backward, setup_cnotallow=setup_context)注意,backward必须是由PyTorch可理解的运算符组成,这也是我们将paste封装为自定义运算符而不直接使用PIL的paste的原因。
img = img.requires_grad_()
result = crop(img, (10, 10, 50, 50))
result.sum().backward()
display(img.grad)
这是正确的梯度,在裁剪区域内是1(白色),在未使用的区域内是0(黑色)。
测试Python自定义运算符
使用torch.library.opcheck来测试自定义运算符是否正确注册。这不会测试梯度是否在数学上正确,请单独编写测试(手动测试或使用torch.autograd.gradcheck)。要使用opcheck,请传入一组示例输入用于测试。如果你的运算符支持训练,那么示例应该包括需要计算梯度的Tensor。如果你的运算符支持多个设备,那么示例应该包括来自每个设备的Tensor。
examples = [
[torch.randn(3, 64, 64), [0, 0, 10, 10]],
[torch.randn(3, 91, 91, requires_grad=True), [10, 0, 20, 10]],
[torch.randn(3, 60, 60, dtype=torch.double), [3, 4, 32, 20]],
[torch.randn(3, 512, 512, requires_grad=True, dtype=torch.double), [3, 4, 32, 45]],
]
for example in examples:
torch.library.opcheck(crop, example)可变的Python自定义运算符
你也可以将一个会修改其输入的Python函数封装为自定义运算符。修改输入的函数很常见,因为这是许多low-level kernel编写的方式;例如,计算sin的kernel可能会修改输入,并将输出张量赋值为input.sin()。我们将使用numpy.sin来演示一个可变的Python自定义运算符的示例。
import numpy as np
@torch.library.custom_op("mylib::numpy_sin", mutates_args={"output"}, device_types="cpu")
def numpy_sin(input: torch.Tensor, output: torch.Tensor) -> None:
assert input.device == output.device
assert input.device.type == "cpu"
input_np = input.numpy()
output_np = output.numpy()
np.sin(input_np, out=output_np)由于该运算符没有返回值,因此不需要注册FakeTensor kernel(元kernel)就可以在torch.compile中正常工作。
@torch.compile(fullgraph=True)
def f(x):
out = torch.empty(3)
numpy_sin(x, out)
return out
x = torch.randn(3)
y = f(x)
assert torch.allclose(y, x.sin())这里是一次opcheck运行的结果,告诉我们确实正确注册了该kernel。如果我们忘记添加输出到mutates_args,例如,opcheck将会报错。
总结
在本教程中,我们学习了如何使用torch.library.custom_op创建一个与PyTorch子系统如torch.compile和autograd协同工作的Python自定义运算符。
本教程提供了自定义运算符的基本介绍。更多详细信息,请参阅:
- torch.library文档: https://pytorch.org/docs/stable/library.html
- 自定义运算符手册: https://pytorch.org/tutorials/advanced/custom_ops_landing_page.html#the-custom-operators-manual
三、PyTorch 2.0
先说一个小内存的部署 然后在说一下刚出的pytorch2.0 100%向后兼容,一行代码将训练提速76%
前段时间,PyTorch 团队在官方博客宣布 Pytorch 1.13 发布,包含 BetterTransformer 稳定版等多项更新。在体验新特性的同时,不少人也在期待下一个版本的推出。
出乎意料的是,这个新版本很快就来了,而且是跨越式的 2.0 版!
新版本的重要进步体现在速度和可用性,而且完全向后兼容。PyTorch 团队表示,PyTorch 2.0 是他们向 2.x 系列迈出的第一步,其稳定版预计在 2023 年 3 月初发布。
首先,PyTorch 2.0 引入了 torch.compile,这是一种编译模式,可以在不更改模型代码的情况下加速模型。在 163 个涵盖视觉、NLP 和其他领域的开源模型中,该团队发现使用 2.0 可以将训练速度提高 38-76%。

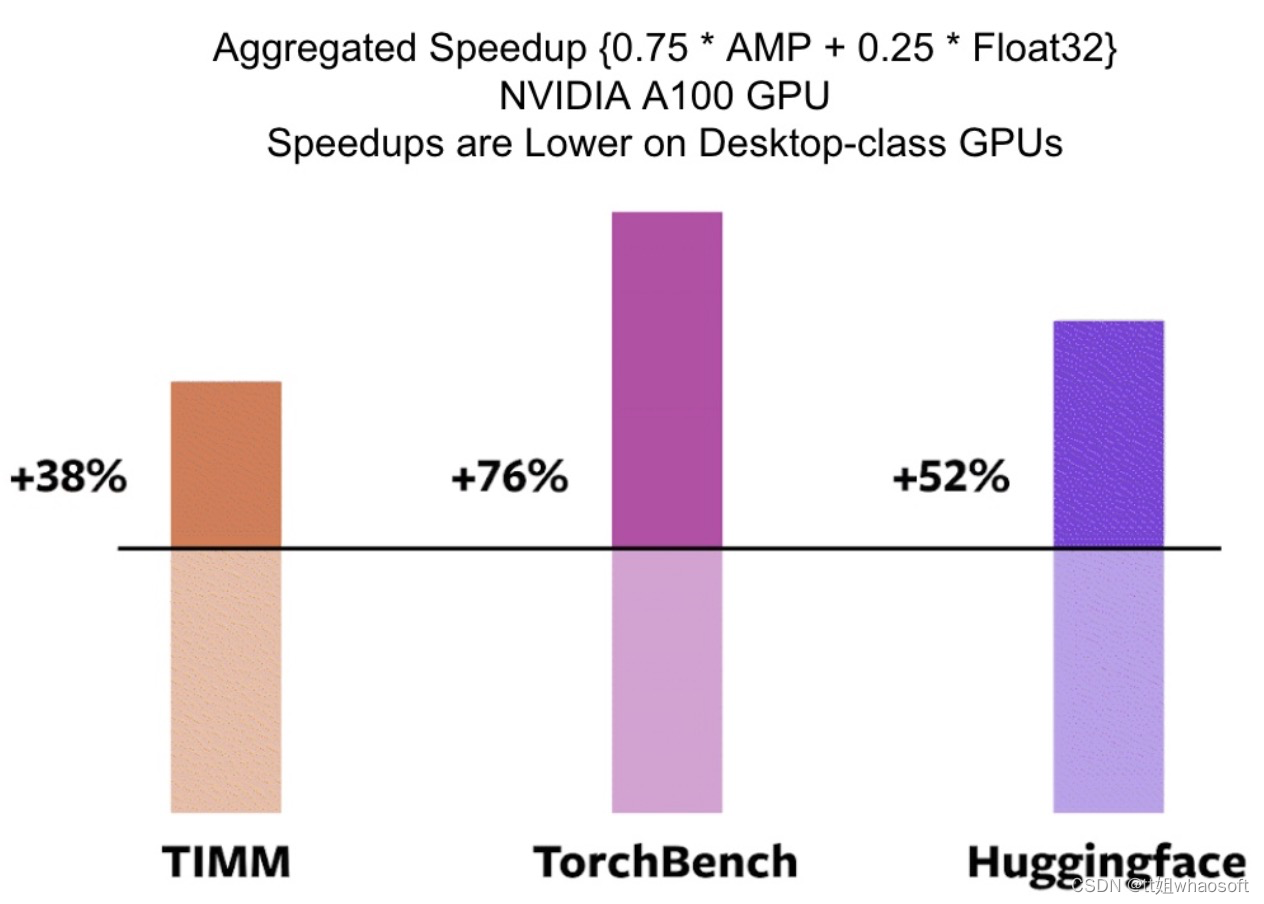
其次,PyTorch 2.0 是 100% 向后兼容的:代码库一样,API 一样,写模型的方式也一样。团队之所以称它为 2.0,是因为它有一些标志性的新特性,包括:
- TorchDynamo 可以从字节码分析生成 FX 图;
- AOTAutograd 可以以 ahead-of-time 的方式生成反向图;
- PrimTorch 引入了一个小型算子集,使后端更容易;
- TorchInductor:一个由 OpenAI Triton 支持的 DL 编译器。
PyTorch 2.0 将延续 PyTorch 一贯的优势,包括 Python 集成、命令式风格、API 简单等等。此外,PyTorch 2.0 提供了相同的 eager-mode 开发和用户体验,同时从根本上改变和增强了 PyTorch 在编译器级别的运行方式。该版本能够为「Dynamic Shapes」和分布式运行提供更快的性能和更好的支持。
在官方博客中,PyTorch团队还公布了他们对于整个2.0系列的展望:
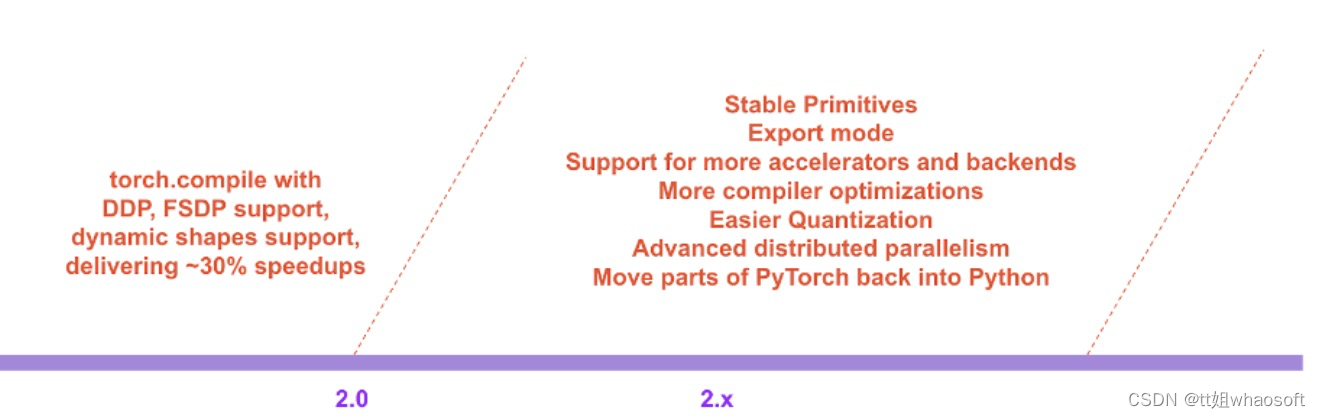
以下是详细内容。
PyTorch 2.X:速度更快、更加地 Python 化、一如既往地 dynamic
PyTorch 2.0 官宣了一个重要特性——torch.compile,这一特性将 PyTorch 的性能推向了新的高度,并将 PyTorch 的部分内容从 C++ 移回 Python。torch.compile 是一个完全附加的(可选的)特性,因此 PyTorch 2.0 是 100% 向后兼容的。
支撑 torch.compile 的技术包括研发团队新推出的 TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor。
- TorchDynamo 使用 Python Frame Evaluation Hooks 安全地捕获 PyTorch 程序,这是一项重大创新,是研究团队对快速可靠地获取图进行 5 年研发的结果;
- AOTAutograd 重载 PyTorch 的 autograd 引擎作为一个跟踪 autodiff,用于生成 ahead-of-time 向后跟踪;
- PrimTorch 将约 2000 多个 PyTorch 算子规范化为一组约 250 个原始算子的闭集,开发人员可以将其作为构建完整 PyTorch 后端的目标。这大大降低了编写 PyTorch 特性或后端的障碍;
- TorchInductor 是一种深度学习编译器,可为多个加速器和后端生成快速代码。对于 NVIDIA GPU,它使用 OpenAI Triton 作为关键构建块。
TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 是用 Python 编写的,并支持 dynamic shapes(即能够发送不同大小的张量而无需重新编译),这使得它们具备灵活、易于破解的特性,降低了开发人员和供应商的使用门槛。
为了验证这些技术,研发团队在各种机器学习领域测试了 163 个开源模型。实验精心构建了测试基准,包括各种 CV 任务(图像分类、目标检测、图像生成等)、NLP 任务(语言建模、问答、序列分类、推荐系统等)和强化学习任务,测试模型主要有 3 个来源:
- 46 个来自 HuggingFace Transformers 的模型;
- 来自 TIMM 的 61 个模型:一系列 SOTA PyTorch 图像模型;
- 来自 TorchBench 的 56 个模型:包含来自 github 的精选流行代码库。
然后研究者测量加速性能并验证这些模型的准确性。加速可能取决于数据类型,研究团队选择测量 float32 和自动混合精度 (AMP) 的加速。
在 163 个开源模型中,torch.compile 在 93% 的情况下都有效,模型在 NVIDIA A100 GPU 上的训练速度提高了 43%。在 float32 精度下,它的平均运行速度提高了 21%,而在 AMP 精度下,它的运行速度平均提高了 51%。
目前,torch.compile 还处于早期开发阶段,预计 2023 年 3 月上旬将发布第一个稳定的 2.0 版本。
TorchDynamo:快速可靠地获取图
TorchDynamo 是一种使用 Frame Evaluation API (PEP-0523 中引入的一种 CPython 特性)的新方法。研发团队采用数据驱动的方法来验证其在 Graph Capture 上的有效性,并使用 7000 多个用 PyTorch 编写的 Github 项目作为验证集。TorchScript 等方法大约在 50% 的时间里都难以获取图,而且通常开销很大;而 TorchDynamo 在 99% 的时间里都能获取图,方法正确、安全且开销可忽略不计(无需对原始代码进行任何更改)。这说明 TorchDynamo 突破了多年来模型权衡灵活性和速度的瓶颈。
TorchInductor:使用 define-by-run IR 快速生成代码
对于 PyTorch 2.0 的新编译器后端,研发团队从用户编写高性能自定义内核的方式中汲取灵感:越来越多地使用 Triton 语言。此外,研究者还想要一个编译器后端——使用与 PyTorch eager 类似的抽象,并且具有足够的通用性以支持 PyTorch 中广泛的功能。
TorchInductor 使用 pythonic define-by-run loop level IR 自动将 PyTorch 模型映射到 GPU 上生成的 Triton 代码和 CPU 上的 C++/OpenMP。TorchInductor 的 core loop level IR 仅包含约 50 个算子,并且是用 Python 实现的,易于破解和扩展。
AOTAutograd:将 Autograd 重用于 ahead-of-time 图
PyTorch 2.0 的主要特性之一是加速训练,因此 PyTorch 2.0 不仅要捕获用户级代码,还要捕获反向传播。此外,研发团队还想要复用现有的经过实践检验的 PyTorch autograd 系统。AOTAutograd 利用 PyTorch 的 torch_dispatch 可扩展机制来跟踪 Autograd 引擎,使其能够「ahead-of-time」捕获反向传递(backwards pass)。这使 TorchInductor 能够加速前向和反向传递。
PrimTorch:稳定的原始算子
为 PyTorch 编写后端具有挑战性。PyTorch 有 1200 多个算子,如果考虑每个算子的各种重载,则有 2000 多个。
在 PrimTorch 项目中,研发团队致力于定义更小且稳定的算子集,将 PyTorch 程序缩减到这样较小的算子集。目标是定义两个算子集:
- Prim ops:约有 250 个相当低级的算子。这些算子适用于编译器,需要将它们重新融合在一起以获得良好的性能;
- ATen ops:约有 750 个规范算子。这些算子适用于已经在 ATen 级别集成的后端或没有编译功能的后端(无法从较低级别的算子集(如 Prim ops)恢复性能)。
用户体验
PyTorch 2.0 引入了一个简单的函数 torch.compile,它会返回一个编译后的模型。
compiled_model *=* torch.compile(model)compiled_model 保存对模型的引用,并将 forward 函数编译为一个更优化的版本。在编译模型时,PyTorch 2.0 给了几项设置来调整它:
def torch.compile(model: Callable,
*,
mode: Optional[str] = "default",
dynamic: bool = False,
fullgraph:bool = False,
backend: Union[str, Callable] = "inductor",
# advanced backend options go here as kwargs
**kwargs
) -> torch._dynamo.NNOptimizedModule- 「mode」指定编译器在编译时应该优化的内容。
- default 是一种预设模式,它试图在不花费太长时间或使用额外内存的情况下高效编译。
- 其他模式,如 reduce-overhead,可以大大降低框架开销,但要消耗少量额外内存。max-autotune 编译很长时间,试图为你提供它所能生成的最快的代码。
- 「dynamic」模式指定是否为 Dynamic Shapes 启用代码路径。某些编译器优化不能应用于动态形状的程序。明确你想要一个带有动态形状还是静态形状的编译程序,将有助于编译器提供更好的优化代码。
- 「fullgraph」类似于 Numba 的 nopython。它将整个程序编译成一个图,或者给出一个错误提示,解释为什么它不能这样做。大多数用户不需要使用这种模式。如果你非常注重性能,那么你可以尝试使用它。
- 「backend 」指定使用哪个编译器后端。默认情况下使用 TorchInductor,但还有其他一些可用的工具。

编译体验想要在默认模式中提供最大的好处和最大的灵活性。
常见问答
1、什么是 PT 2.0?
2.0 是最新的 PyTorch 版本。PyTorch 2.0 提供相同的 eager 模式开发体验,同时通过 torch.compile 添加编译模式。这种编译模式有可能在训练和推理期间加速模型。
2、为什么是 2.0 而不是 1.14?
PyTorch 2.0 就是计划中的 1.14 。我们发布了大量新特性,我们相信这些新特性会改变用户使用 PyTorch 的方式,因此称其为 PyTorch 2.0。
3、如何安装 2.0?有什么额外要求吗?
安装最新的 nightlies:
CUDA 11.7
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117CUDA 11.6
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu116CPU
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu4、2.0 代码是否向后兼容 1.X?
是的,使用 2.0 不需要修改 PyTorch 工作流程。一行代码 model = torch.compile(model) 就可以优化模型,以使用 2.0 堆栈,并与其余 PyTorch 代码一起顺利运行。这是一个可选择项,不需要使用新的编译器。
5、默认启用 2.0 吗?
不,必须通过使用单个函数调用优化模型从而在 PyTorch 代码中显式启用 2.0。
6、如何将 PT1.X 代码迁移到 PT2.0?
代码应该按原样工作,无需任何迁移。如果想使用 2.0 中引入的新编译模式特性,那么可以从优化模型开始:
model = torch.compile(model)虽然加速主要是在训练期间观察到的,但如果你的模型运行速度比 eager 模式快,也可以将它用于推理。
import torch
def train(model, dataloader):
model = torch.compile(model)
for batch in dataloader:
run_epoch(model, batch)
def infer(model, input):
model = torch.compile(model)
return model(\*\*input)7、是否有任何不该使用 PT 2.0 的应用程序?
当前版本的 PT 2.0 仍处于实验阶段,并且处于 nightlies 版本。其中的动态形状支持还处于早期阶段,所以可以等到 2023 年 3 月稳定版发布后再使用该功能。
8、运行 PyTorch 2.0 时,代码有何不同?
开箱即用,PyTorch 2.0 与 PyTorch 1.x 相同,模型以 eager 模式运行,即 Python 的每一行都逐个执行。
在 2.0 中,如果用 model = torch.compile(model) 将模型打包,则模型在执行之前会经过 3 个步骤:
1)图获取:首先将模型重写为子图块。可由 TorchDynamo 编译的子图被「压平」,其他子图(可能包含控制流代码或其他不受支持的 Python 结构)将回退到 Eager 模式。
2)Graph lowering:所有 PyTorch 操作都被分解为特定于所选后端的组成内核。
3)图编译,内核调用其相应的低级设备专用操作。
9、2.0 目前支持哪些编译器后端?
默认和最完整的后端是 TorchInductor,但是 TorchDynamo 有一个不断增长的后端列表,可以通过调用 torchdynamo.list_backends(). 找到
10、2.0 版本的分布式训练能力如何?
Compiled 模式下的 DDP 和 FSDP ,比 FP32 中的 Eager 模式快 15%、AMP 精度快 80%。PT2.0 做了一些额外的优化,以确保 DDP 的通信 - 计算 overlap 与 Dynamo 的部分图创建良好协作。想要确保使用 static_graph=False 运行 DDP,更多细节参见:https://dev-discuss.pytorch.org/t/torchdynamo-update-9-making-ddp-work-with-torchdynamo/860
11、为什么我的代码用 2.0 的 Compiled Model 运行变慢?
性能下降最可能的原因是 graph break 太多。例如,类似模型前向 trigger 中的输出语句这样的东西会触发 graph break。详见:https://pytorch.org/docs/master/dynamo/faq.html#why-am-i-not-seeing-speedups
12、以前运行的代码在 2.0 中崩溃了,该如何调试?
参见:https ://pytorch.org/docs/master/dynamo/faq.html#why-is-my-code-crashing
参考链接:https://pytorch.org/get-started/pytorch-2.0/
四、Pytorch Debug
在使用Pytorch时你或多或少会遇到各种bug
CrossEntropyLoss和NLLLoss
最常见的错误是损失函数和输出激活函数之间的不匹配。nn.CrossEntropyLossPyTorch中的损失模块执行两个操作:nn.LogSoftmax和nn.NLLLoss。
因此nn.CrossEntropyLossPyTorch的输入应该是最后一个线性层的输出。不要在nn.CrossEntropyLossPyTorch之前应用Softmax。 否则将对Softmax输出计算log-softmax,将会降低模型精度。
如果使用nn.NLLLoss模块,则需要自己应用log-softmax。nn.NLLLoss需要对数概率,而不是普通概率。因此确保应用nn.LogSoftmaxor nn.functional.log_softmax,而不是nn.Softmax。
Softmax的计算维度
注意Softmax的计算维度。通常是输出张量的最后一个维度,例如nn.Softmax(dim=-1)。如果混淆了维度,模型最终会得到随机预测。
类别数据与嵌入操作
对于类别数据,常见的做法是进行数值编码。但对于深度学习而言,这并不是一个很好的操作,数值会带来大小关系,且会丢失很多信息。因此对于类别数据建议使用one-hot或Embedding操作,对于nn.Embedding模块,你需要设置的参数包括:
-
num_embeddings:数据类别的数量 -
embedding_dim:每个类别的嵌入维度 -
padding_idx:填充符号的索引
嵌入特征向量从随机初始化,不要用 Kaiming、Xavier初始化方法。因为标准差为1,初始化、激活函数等被设计为输入标准差为 1。nn.Embedding模块的示例用法:
import torch
import torch.nn as nn
# Create 5 embedding vectors each with 32 features
embedding = nn.Embedding(num_embeddings=5,
embedding_dim=32)
# Example integer input
input_tensor = torch.LongTensor([[0, 4], [2, 3], [0, 1]])
# Get embeddings
embed_vectors = embedding(input_tensor)
print("Input shape:", input_tensor.shape)
print("Output shape:", embed_vectors.shape)
print("Example features:\n", embed_vectors[:,:,:2])nn.LSTM 中 数据维度
默认情况下,PyTorch的nn.LSTM模块假定输入维度为[seq_len, batch_size, input_size],所以确保不要混淆序列长度和批大小的次数。如果混淆LSTM仍然可以正常运行,但会给出错误的结果。
维度不匹配
如果Pytorch执行矩阵乘法,并两个矩阵出现维度不匹配,PyTorch会报错并抛出错误。但是也存在PyTorch不会抛出错误的情况,此时未对齐的维度具有相同的大小。建议使用多个不同的批量大小测试您的代码,以防止维度不对齐。
训练和评估模式
在PyTorch中,神经网络有两种模式:train和train。您可以使用model.eval()和model.train()对模型时进行切换。不同的模式决定是否使用dropout,以及如何处理Batch Normalization。常见的错误是在eval后忘记将模型设置回train模式,确定模型在预测阶段为eval模式。
参数继承
PyTorch支持nn.Modules,一个模块可以包含另一个模块,另一个模块又可以包含一个模块,依此类推。
当调用.parameters()时,PyTorch会查找该模块内的所有模块,并将它们的参数添加到最高级别模块的参数中。
但是PyTorch不会检测列表、字典或类似结构中模块的参数。如果有一个模块列表,请确保将它们放入一个nn.ModuleList或nn.Sequential对象中。
参数初始化
正确初始化模型的参数非常重要。用标准正态分布初始化参数不是好的选择,推荐的方法有Kaiming或Xavier。
zero_grad()
请记住在执行loss.backward()之前调用optimizer.zero_grad()。如果在执行反向传播之前没有重置所有参数的梯度,梯度将被添加到上一批的梯度中。
指标计算逻辑
在怀疑自己或模型之前,请经常检查您的指标计算逻辑计算两次或更多次。像准确性这样的指标很容易计算,但在代码中添加错误也很容易。例如,检查您是否对批次维度进行了平均,而不是意外对类维度或任何其他维度进行平均。
设备不匹配
如果使用GPU可能会看到一个错误,例如:
Runtime Error: Input type (torch.FloatTensor) dand weigh type (torch.cuda.FloatTensor) should be on the same device.
此错误表示输入数据在CPU上,而权重在GPU上。确保所有数据都在同一设备上。这通常是GPU,因为它支持训练和测试加速。
nn.Sequential和nn.ModuleList
如果模型有很多层,推荐将它们汇总为一个nn.Sequential或nn.ModuleList对象。在前向传递中,只需要调用sequential,或者遍历模块列表。
class MLP(nn.Module):
def __init__(self, input_dims=64, hidden_dims=[128,256], output_dims=10):
super().__init__()
hidden_dims = [input_dims] + hidden_dims
layers = []
for idx in range(len(hidden_dims)-1):
layers += [
nn.Linear(hidden_dims[i], hidden_dims[i+1]),
nn.ReLU(inplace=True)
]
self.layers = nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)参数重复计算
在深度神经网络中,通常会有重复添加到模型中的块。如果这些块需要比更复杂的前向函数,建议在单独的模块中实现它们。例如,一个 ResNet 由多个具有残差连接的ResNet块组成。ResNet模块应用一个小型神经网络,并将输出添加回输入。最好在单独的类中实现这种动态,以保持主模型类小而清晰。
输入相同的维度
如果您有多个具有相同输入的线性层或卷积,则可以将它们堆叠在一起以提高效率。假设我们有:
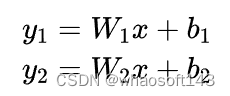
虽然可以通过两个线性层来实现它,但您可以通过将两层堆叠为一层来获得完全相同的神经网络。单层效率更高,因为这代表单个矩阵运算,而不是GPU的两个矩阵运算,因此我们可以并行化计算。
x = torch.randn(2, 10)
# Implementation of separate layers:
y1_layer = nn.Linear(10, 20)
y2_layer = nn.Linear(10, 30)
y1 = y1_layer(x)
y2 = y2_layer(x)
# Implementation of a stacked layer:
y_layer = nn.Linear(10, 50)
y = y_layer(x)
y1, y2 = y[:,:20], y[:,20:50]使用带logits的损失函数
分类损失函数(例如二元交叉熵)在PyTorch中有两个版本:nn.BCELoss和nn.BCEWithLogitsLoss,建议和推荐的做法是使用后者。这因为它在数值上更稳定,并在您的模型预测非常错误时防止出现任何不稳定性。
如果您不使用logit损失函数,则当模型预测不正确的非常高或非常低的值时,您可能会遇到问题。
五、 常用代码段
PyTorch常用代码段合集,涵盖基本配置、张量处理、模型定义与操作、数据处理、模型训练与测试等5个方面,还给出了多个值得注意的Tips,内容非常全面。
PyTorch最好的资料是官方文档。本文是PyTorch常用代码段,在参考资料[1](张皓:PyTorch Cookbook)的基础上做了一些修补,方便使用时查阅。
基本配置导入包和版本查询
import torch
import torch.nn as nn
import torchvision
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print(torch.cuda.get_device_name(0))可复现性
在硬件设备(CPU、GPU)不同时,完全的可复现性无法保证,即使随机种子相同。但是,在同一个设备上,应该保证可复现性。具体做法是,在程序开始的时候固定torch的随机种子,同时也把numpy的随机种子固定。
np.random.seed(0)
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False显卡设置
如果只需要一张显卡
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')如果需要指定多张显卡,比如0,1号显卡。
import osos.environ['CUDA_VISIBLE_DEVICES'] = '0,1'也可以在命令行运行代码时设置显卡:
CUDA_VISIBLE_DEVICES=0,1 python train.py清除显存
torch.cuda.empty_cache()也可以使用在命令行重置GPU的指令
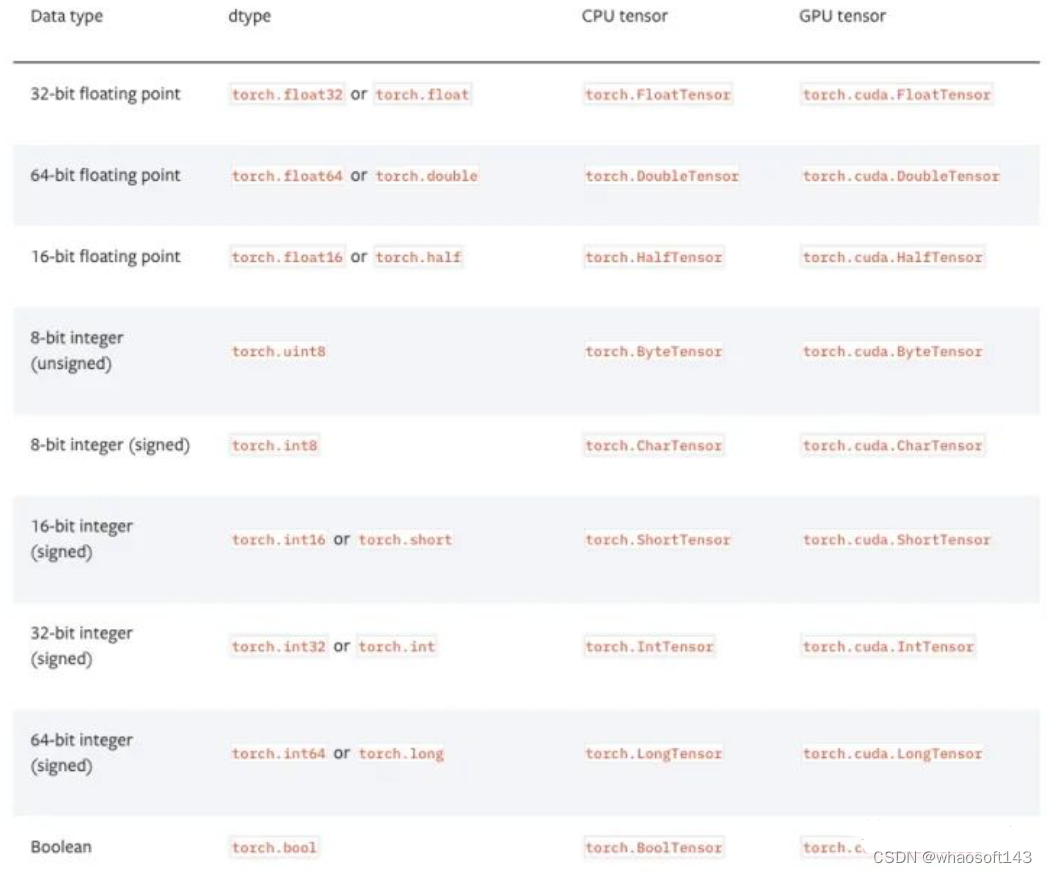
nvidia-smi --gpu-reset -i [gpu_id]张量(Tensor)处理张量的数据类型
PyTorch有9种CPU张量类型和9种GPU张量类型。
张量基本信息
tensor = torch.randn(3,4,5)print(tensor.type()) # 数据类型print(tensor.size()) # 张量的shape,是个元组print(tensor.dim()) # 维度的数量命名张量
张量命名是一个非常有用的方法,这样可以方便地使用维度的名字来做索引或其他操作,大大提高了可读性、易用性,防止出错。
# 在PyTorch 1.3之前,需要使用注释
# Tensor[N, C, H, W]
images = torch.randn(32, 3, 56, 56)
images.sum(dim=1)
images.select(dim=1, index=0)
# PyTorch 1.3之后
NCHW = [‘N’, ‘C’, ‘H’, ‘W’]
images = torch.randn(32, 3, 56, 56, names=NCHW)
images.sum('C')
images.select('C', index=0)
# 也可以这么设置
tensor = torch.rand(3,4,1,2,names=('C', 'N', 'H', 'W'))
# 使用align_to可以对维度方便地排序
tensor = tensor.align_to('N', 'C', 'H', 'W')数据类型转换
# 设置默认类型,pytorch中的FloatTensor远远快于DoubleTensor
torch.set_default_tensor_type(torch.FloatTensor)
# 类型转换
tensor = tensor.cuda()
tensor = tensor.cpu()
tensor = tensor.float()
tensor = tensor.long()torch.Tensor与np.ndarray转换
除了CharTensor,其他所有CPU上的张量都支持转换为numpy格式然后再转换回来。
ndarray = tensor.cpu().numpy()
tensor = torch.from_numpy(ndarray).float()
tensor = torch.from_numpy(ndarray.copy()).float() # If ndarray has negative stride.Torch.tensor与PIL.Image转换
# pytorch中的张量默认采用[N, C, H, W]的顺序,并且数据范围在[0,1],需要进行转置和规范化
# torch.Tensor -> PIL.Image
image = PIL.Image.fromarray(torch.clamp(tensor*255, min=0, max=255).byte().permute(1,2,0).cpu().numpy())
image = torchvision.transforms.functional.to_pil_image(tensor) # Equivalently way
# PIL.Image -> torch.Tensor
path = r'./figure.jpg'
tensor = torch.from_numpy(np.asarray(PIL.Image.open(path))).permute(2,0,1).float() / 255
tensor = torchvision.transforms.functional.to_tensor(PIL.Image.open(path)) # Equivalently waynp.ndarray与PIL.Image的转换
image = PIL.Image.fromarray(ndarray.astype(np.uint8))
ndarray = np.asarray(PIL.Image.open(path))从只包含一个元素的张量中提取值
value = torch.rand(1).item()张量形变
# 在将卷积层输入全连接层的情况下通常需要对张量做形变处理,
# 相比torch.view,torch.reshape可以自动处理输入张量不连续的情况
tensor = torch.rand(2,3,4)
shape = (6, 4)
tensor = torch.reshape(tensor, shape)打乱顺序
tensor = tensor[torch.randperm(tensor.size(0))] # 打乱第一个维度水平翻转
# pytorch不支持tensor[::-1]这样的负步长操作,水平翻转可以通过张量索引实现
# 假设张量的维度为[N, D, H, W].
tensor = tensor[:,:,:,torch.arange(tensor.size(3) - 1, -1, -1).long()]复制张量
# Operation | New/Shared memory | Still in computation graph |tensor.clone() # | New | Yes |tensor.detach() # | Shared | No |tensor.detach.clone()() # | New | No |张量拼接
'''
注意torch.cat和torch.stack的区别在于torch.cat沿着给定的维度拼接,
而torch.stack会新增一维。例如当参数是3个10x5的张量,torch.cat的结果是30x5的张量,
而torch.stack的结果是3x10x5的张量。
'''
tensor = torch.cat(list_of_tensors, dim=0)
tensor = torch.stack(list_of_tensors, dim=0)将整数标签转为one-hot编码
# pytorch的标记默认从0开始
tensor = torch.tensor([0, 2, 1, 3])
N = tensor.size(0)
num_classes = 4
one_hot = torch.zeros(N, num_classes).long()
one_hot.scatter_(dim=1, index=torch.unsqueeze(tensor, dim=1), src=torch.ones(N, num_classes).long())得到非零元素
torch.nonzero(tensor) # index of non-zero elements
torch.nonzero(tensor==0) # index of zero elements
torch.nonzero(tensor).size(0) # number of non-zero elements
torch.nonzero(tensor == 0).size(0) # number of zero elements判断两个张量相等
torch.allclose(tensor1, tensor2) # float tensor
torch.equal(tensor1, tensor2) # int tensor张量扩展
# Expand tensor of shape 64*512 to shape 64*512*7*7.
tensor = torch.rand(64,512)
torch.reshape(tensor, (64, 512, 1, 1)).expand(64, 512, 7, 7)矩阵乘法
# Matrix multiplcation: (m*n) * (n*p) * -> (m*p).
result = torch.mm(tensor1, tensor2)
# Batch matrix multiplication: (b*m*n) * (b*n*p) -> (b*m*p)
result = torch.bmm(tensor1, tensor2)
# Element-wise multiplication.
result = tensor1 * tensor2计算两组数据之间的两两欧式距离
利用广播机制
dist = torch.sqrt(torch.sum((X1[:,None,:] - X2) ** 2, dim=2))模型定义和操作一个简单两层卷积网络的示例
# convolutional neural network (2 convolutional layers)
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
model = ConvNet(num_classes).to(device)卷积层的计算和展示可以用这个网站辅助。
双线性汇合(bilinear pooling)
X = torch.reshape(N, D, H * W) # Assume X has shape N*D*H*W
X = torch.bmm(X, torch.transpose(X, 1, 2)) / (H * W) # Bilinear pooling
assert X.size() == (N, D, D)
X = torch.reshape(X, (N, D * D))
X = torch.sign(X) * torch.sqrt(torch.abs(X) + 1e-5) # Signed-sqrt normalization
X = torch.nn.functional.normalize(X) # L2 normalization多卡同步 BN(Batch normalization)
当使用 torch.nn.DataParallel 将代码运行在多张 GPU 卡上时,PyTorch 的 BN 层默认操作是各卡上数据独立地计算均值和标准差,同步 BN 使用所有卡上的数据一起计算 BN 层的均值和标准差,缓解了当批量大小(batch size)比较小时对均值和标准差估计不准的情况,是在目标检测等任务中一个有效的提升性能的技巧。
sync_bn = torch.nn.SyncBatchNorm(num_features,
eps=1e-05,
momentum=0.1,
affine=True,
track_running_stats=True)将已有网络的所有BN层改为同步BN层
def convertBNtoSyncBN(module, process_group=None):
'''Recursively replace all BN layers to SyncBN layer.
Args:
module[torch.nn.Module]. Network
'''
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
sync_bn = torch.nn.SyncBatchNorm(module.num_features, module.eps, module.momentum,
module.affine, module.track_running_stats, process_group)
sync_bn.running_mean = module.running_mean
sync_bn.running_var = module.running_var
if module.affine:
sync_bn.weight = module.weight.clone().detach()
sync_bn.bias = module.bias.clone().detach()
return sync_bn
else:
for name, child_module in module.named_children():
setattr(module, name) = convert_syncbn_model(child_module, process_group=process_group))
return module类似 BN 滑动平均
如果要实现类似 BN 滑动平均的操作,在 forward 函数中要使用原地(inplace)操作给滑动平均赋值。
class BN(torch.nn.Module)
def __init__(self):
...
self.register_buffer('running_mean', torch.zeros(num_features))
def forward(self, X):
...
self.running_mean += momentum * (current - self.running_mean)计算模型整体参数量
num_parameters = sum(torch.numel(parameter) for parameter in model.parameters())查看网络中的参数
可以通过model.state_dict()或者model.named_parameters()函数查看现在的全部可训练参数(包括通过继承得到的父类中的参数)
params = list(model.named_parameters())
(name, param) = params[28]
print(name)
print(param.grad)
print('-------------------------------------------------')
(name2, param2) = params[29]
print(name2)
print(param2.grad)
print('----------------------------------------------------')
(name1, param1) = params[30]
print(name1)
print(param1.grad)模型可视化(使用pytorchviz)
szagoruyko/pytorchvizgithub.com类似 Keras 的 model.summary() 输出模型信息,使用pytorch-summary
sksq96/pytorch-summarygithub.com模型权重初始化
注意 model.modules() 和 model.children() 的区别:model.modules() 会迭代地遍历模型的所有子层,而 model.children() 只会遍历模型下的一层。
# Common practise for initialization.
for layer in model.modules():
if isinstance(layer, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(layer.weight, mode='fan_out',
nonlinearity='relu')
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.BatchNorm2d):
torch.nn.init.constant_(layer.weight, val=1.0)
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.Linear):
torch.nn.init.xavier_normal_(layer.weight)
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
# Initialization with given tensor.
layer.weight = torch.nn.Parameter(tensor)提取模型中的某一层
modules()会返回模型中所有模块的迭代器,它能够访问到最内层,比如self.layer1.conv1这个模块,还有一个与它们相对应的是name_children()属性以及named_modules(),这两个不仅会返回模块的迭代器,还会返回网络层的名字。
# 取模型中的前两层
new_model = nn.Sequential(*list(model.children())[:2]
# 如果希望提取出模型中的所有卷积层,可以像下面这样操作:
for layer in model.named_modules():
if isinstance(layer[1],nn.Conv2d):
conv_model.add_module(layer[0],layer[1])部分层使用预训练模型
注意如果保存的模型是 torch.nn.DataParallel,则当前的模型也需要是
model.load_state_dict(torch.load('model.pth'), strict=False)将在 GPU 保存的模型加载到 CPU
model.load_state_dict(torch.load('model.pth', map_location='cpu'))导入另一个模型的相同部分到新的模型
模型导入参数时,如果两个模型结构不一致,则直接导入参数会报错。用下面方法可以把另一个模型的相同的部分导入到新的模型中。
# model_new代表新的模型
# model_saved代表其他模型,比如用torch.load导入的已保存的模型
model_new_dict = model_new.state_dict()
model_common_dict = {k:v for k, v in model_saved.items() if k in model_new_dict.keys()}
model_new_dict.update(model_common_dict)
model_new.load_state_dict(model_new_dict)数据处理计算数据集的均值和标准差
import os
import cv2
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
def compute_mean_and_std(dataset):
# 输入PyTorch的dataset,输出均值和标准差
mean_r = 0
mean_g = 0
mean_b = 0
for img, _ in dataset:
img = np.asarray(img) # change PIL Image to numpy array
mean_b += np.mean(img[:, :, 0])
mean_g += np.mean(img[:, :, 1])
mean_r += np.mean(img[:, :, 2])
mean_b /= len(dataset)
mean_g /= len(dataset)
mean_r /= len(dataset)
diff_r = 0
diff_g = 0
diff_b = 0
N = 0
for img, _ in dataset:
img = np.asarray(img)
diff_b += np.sum(np.power(img[:, :, 0] - mean_b, 2))
diff_g += np.sum(np.power(img[:, :, 1] - mean_g, 2))
diff_r += np.sum(np.power(img[:, :, 2] - mean_r, 2))
N += np.prod(img[:, :, 0].shape)
std_b = np.sqrt(diff_b / N)
std_g = np.sqrt(diff_g / N)
std_r = np.sqrt(diff_r / N)
mean = (mean_b.item() / 255.0, mean_g.item() / 255.0, mean_r.item() / 255.0)
std = (std_b.item() / 255.0, std_g.item() / 255.0, std_r.item() / 255.0)
return mean, std得到视频数据基本信息
import cv2
video = cv2.VideoCapture(mp4_path)
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = int(video.get(cv2.CAP_PROP_FPS))
video.release()TSN 每段(segment)采样一帧视频
K = self._num_segments
if is_train:
if num_frames > K:
# Random index for each segment.
frame_indices = torch.randint(
high=num_frames // K, size=(K,), dtype=torch.long)
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.randint(
high=num_frames, size=(K - num_frames,), dtype=torch.long)
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), frame_indices)))[0]
else:
if num_frames > K:
# Middle index for each segment.
frame_indices = num_frames / K // 2
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), torch.arange(K - num_frames))))[0]
assert frame_indices.size() == (K,)
return [frame_indices[i] for i in range(K)]常用训练和验证数据预处理
其中 ToTensor 操作会将 PIL.Image 或形状为 H×W×D,数值范围为 [0, 255] 的 np.ndarray 转换为形状为 D×H×W,数值范围为 [0.0, 1.0] 的 torch.Tensor。
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(size=224,
scale=(0.08, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])
val_transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])模型训练和测试分类模型训练代码
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i ,(images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch: [{}/{}], Step: [{}/{}], Loss: {}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))分类模型测试代码
# Test the model
model.eval() # eval mode(batch norm uses moving mean/variance
#instead of mini-batch mean/variance)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test accuracy of the model on the 10000 test images: {} %'
.format(100 * correct / total))自定义loss
继承torch.nn.Module类写自己的loss。
class MyLoss(torch.nn.Moudle):
def __init__(self):
super(MyLoss, self).__init__()
def forward(self, x, y):
loss = torch.mean((x - y) ** 2)
return loss标签平滑(label smoothing)
写一个label_smoothing.py的文件,然后在训练代码里引用,用LSR代替交叉熵损失即可。label_smoothing.py内容如下:
import torch
import torch.nn as nn
class LSR(nn.Module):
def __init__(self, e=0.1, reduction='mean'):
super().__init__()
self.log_softmax = nn.LogSoftmax(dim=1)
self.e = e
self.reduction = reduction
def _one_hot(self, labels, classes, value=1):
"""
Convert labels to one hot vectors
Args:
labels: torch tensor in format [label1, label2, label3, ...]
classes: int, number of classes
value: label value in one hot vector, default to 1
Returns:
return one hot format labels in shape [batchsize, classes]
"""
one_hot = torch.zeros(labels.size(0), classes)
#labels and value_added size must match
labels = labels.view(labels.size(0), -1)
value_added = torch.Tensor(labels.size(0), 1).fill_(value)
value_added = value_added.to(labels.device)
one_hot = one_hot.to(labels.device)
one_hot.scatter_add_(1, labels, value_added)
return one_hot
def _smooth_label(self, target, length, smooth_factor):
"""convert targets to one-hot format, and smooth
them.
Args:
target: target in form with [label1, label2, label_batchsize]
length: length of one-hot format(number of classes)
smooth_factor: smooth factor for label smooth
Returns:
smoothed labels in one hot format
"""
one_hot = self._one_hot(target, length, value=1 - smooth_factor)
one_hot += smooth_factor / (length - 1)
return one_hot.to(target.device)
def forward(self, x, target):
if x.size(0) != target.size(0):
raise ValueError('Expected input batchsize ({}) to match target batch_size({})'
.format(x.size(0), target.size(0)))
if x.dim() < 2:
raise ValueError('Expected input tensor to have least 2 dimensions(got {})'
.format(x.size(0)))
if x.dim() != 2:
raise ValueError('Only 2 dimension tensor are implemented, (got {})'
.format(x.size()))
smoothed_target = self._smooth_label(target, x.size(1), self.e)
x = self.log_softmax(x)
loss = torch.sum(- x * smoothed_target, dim=1)
if self.reduction == 'none':
return loss
elif self.reduction == 'sum':
return torch.sum(loss)
elif self.reduction == 'mean':
return torch.mean(loss)
else:
raise ValueError('unrecognized option, expect reduction to be one of none, mean, sum')或者直接在训练文件里做label smoothing
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
N = labels.size(0)
# C is the number of classes.
smoothed_labels = torch.full(size=(N, C), fill_value=0.1 / (C - 1)).cuda()
smoothed_labels.scatter_(dim=1, index=torch.unsqueeze(labels, dim=1), value=0.9)
score = model(images)
log_prob = torch.nn.functional.log_softmax(score, dim=1)
loss = -torch.sum(log_prob * smoothed_labels) / N
optimizer.zero_grad()
loss.backward()
optimizer.step()Mixup训练
beta_distribution = torch.distributions.beta.Beta(alpha, alpha)
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
# Mixup images and labels.
lambda_ = beta_distribution.sample([]).item()
index = torch.randperm(images.size(0)).cuda()
mixed_images = lambda_ * images + (1 - lambda_) * images[index, :]
label_a, label_b = labels, labels[index]
# Mixup loss.
scores = model(mixed_images)
loss = (lambda_ * loss_function(scores, label_a)
+ (1 - lambda_) * loss_function(scores, label_b))
optimizer.zero_grad()
loss.backward()
optimizer.step()L1 正则化
l1_regularization = torch.nn.L1Loss(reduction='sum')
loss = ... # Standard cross-entropy loss
for param in model.parameters():
loss += torch.sum(torch.abs(param))
loss.backward()不对偏置项进行权重衰减(weight decay)
pytorch里的weight decay相当于l2正则
bias_list = (param for name, param in model.named_parameters() if name[-4:] == 'bias')
others_list = (param for name, param in model.named_parameters() if name[-4:] != 'bias')
parameters = [{'parameters': bias_list, 'weight_decay': 0},
{'parameters': others_list}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)梯度裁剪(gradient clipping)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=20)得到当前学习率
# If there is one global learning rate (which is the common case).
lr = next(iter(optimizer.param_groups))['lr']
# If there are multiple learning rates for different layers.
all_lr = []
for param_group in optimizer.param_groups:
all_lr.append(param_group['lr'])另一种方法,在一个batch训练代码里,当前的lr是optimizer.param_groups[0]['lr']
学习率衰减
# Reduce learning rate when validation accuarcy plateau.
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=5, verbose=True)
for t in range(0, 80):
train(...)
val(...)
scheduler.step(val_acc)
# Cosine annealing learning rate.
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=80)
# Reduce learning rate by 10 at given epochs.
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50, 70], gamma=0.1)
for t in range(0, 80):
scheduler.step()
train(...)
val(...)
# Learning rate warmup by 10 epochs.
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda t: t / 10)
for t in range(0, 10):
scheduler.step()
train(...)
val(...)优化器链式更新
从1.4版本开始,torch.optim.lr_scheduler 支持链式更新(chaining),即用户可以定义两个 schedulers,并交替在训练中使用。
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ExponentialLR, StepLR
model = [torch.nn.Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = StepLR(optimizer, step_size=3, gamma=0.1)
for epoch in range(4):
print(epoch, scheduler2.get_last_lr()[0])
optimizer.step()
scheduler1.step()
scheduler2.step()模型训练可视化
PyTorch可以使用tensorboard来可视化训练过程。安装和运行TensorBoard。
pip install tensorboard
tensorboard --logdir=runs使用SummaryWriter类来收集和可视化相应的数据,放了方便查看,可以使用不同的文件夹,比如'Loss/train'和'Loss/test'。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)保存与加载断点
注意为了能够恢复训练,我们需要同时保存模型和优化器的状态,以及当前的训练轮数。
start_epoch = 0
# Load checkpoint.
if resume: # resume为参数,第一次训练时设为0,中断再训练时设为1
model_path = os.path.join('model', 'best_checkpoint.pth.tar')
assert os.path.isfile(model_path)
checkpoint = torch.load(model_path)
best_acc = checkpoint['best_acc']
start_epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
print('Load checkpoint at epoch {}.'.format(start_epoch))
print('Best accuracy so far {}.'.format(best_acc))
# Train the model
for epoch in range(start_epoch, num_epochs):
...
# Test the model
...
# save checkpoint
is_best = current_acc > best_acc
best_acc = max(current_acc, best_acc)
checkpoint = {
'best_acc': best_acc,
'epoch': epoch + 1,
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
}
model_path = os.path.join('model', 'checkpoint.pth.tar')
best_model_path = os.path.join('model', 'best_checkpoint.pth.tar')
torch.save(checkpoint, model_path)
if is_best:
shutil.copy(model_path, best_model_path)提取 ImageNet 预训练模型某层的卷积特征
# VGG-16 relu5-3 feature.
model = torchvision.models.vgg16(pretrained=True).features[:-1]
# VGG-16 pool5 feature.
model = torchvision.models.vgg16(pretrained=True).features
# VGG-16 fc7 feature.
model = torchvision.models.vgg16(pretrained=True)
model.classifier = torch.nn.Sequential(*list(model.classifier.children())[:-3])
# ResNet GAP feature.
model = torchvision.models.resnet18(pretrained=True)
model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1]))
with torch.no_grad():
model.eval()
conv_representation = model(image)提取 ImageNet 预训练模型多层的卷积特征
class FeatureExtractor(torch.nn.Module):
"""Helper class to extract several convolution features from the given
pre-trained model.
Attributes:
_model, torch.nn.Module.
_layers_to_extract, list<str> or set<str>
Example:
>>> model = torchvision.models.resnet152(pretrained=True)
>>> model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1]))
>>> conv_representation = FeatureExtractor(
pretrained_model=model,
layers_to_extract={'layer1', 'layer2', 'layer3', 'layer4'})(image)
"""
def __init__(self, pretrained_model, layers_to_extract):
torch.nn.Module.__init__(self)
self._model = pretrained_model
self._model.eval()
self._layers_to_extract = set(layers_to_extract)
def forward(self, x):
with torch.no_grad():
conv_representation = []
for name, layer in self._model.named_children():
x = layer(x)
if name in self._layers_to_extract:
conv_representation.append(x)
return conv_representation微调全连接层
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Linear(512, 100) # Replace the last fc layer
optimizer = torch.optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9, weight_decay=1e-4)以较大学习率微调全连接层,较小学习率微调卷积层
model = torchvision.models.resnet18(pretrained=True)
finetuned_parameters = list(map(id, model.fc.parameters()))
conv_parameters = (p for p in model.parameters() if id(p) not in finetuned_parameters)
parameters = [{'params': conv_parameters, 'lr': 1e-3},
{'params': model.fc.parameters()}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)其他注意事项
- 不要使用太大的线性层。因为nn.Linear(m,n)使用的是的内存,线性层太大很容易超出现有显存。
- 不要在太长的序列上使用RNN。因为RNN反向传播使用的是BPTT算法,其需要的内存和输入序列的长度呈线性关系。
- model(x) 前用 model.train() 和 model.eval() 切换网络状态。
- 不需要计算梯度的代码块用 with torch.no_grad() 包含起来。
- model.eval() 和 torch.no_grad() 的区别在于,model.eval() 是将网络切换为测试状态,例如 BN 和dropout在训练和测试阶段使用不同的计算方法。torch.no_grad() 是关闭 PyTorch 张量的自动求导机制,以减少存储使用和加速计算,得到的结果无法进行 loss.backward()。
- model.zero_grad()会把整个模型的参数的梯度都归零, 而optimizer.zero_grad()只会把传入其中的参数的梯度归零.
- torch.nn.CrossEntropyLoss 的输入不需要经过 Softmax。torch.nn.CrossEntropyLoss 等价于 torch.nn.functional.log_softmax + torch.nn.NLLLoss。
- loss.backward() 前用 optimizer.zero_grad() 清除累积梯度。
- torch.utils.data.DataLoader 中尽量设置 pin_memory=True,对特别小的数据集如 MNIST 设置 pin_memory=False 反而更快一些。num_workers 的设置需要在实验中找到最快的取值。
- 用 del 及时删除不用的中间变量,节约 GPU 存储。使用 inplace 操作可节约 GPU 存储,如:
x = torch.nn.functional.relu(x, inplace=True)减少 CPU 和 GPU 之间的数据传输。例如如果你想知道一个 epoch 中每个 mini-batch 的 loss 和准确率,先将它们累积在 GPU 中等一个 epoch 结束之后一起传输回 CPU 会比每个 mini-batch 都进行一次 GPU 到 CPU 的传输更快。使用半精度浮点数 half() 会有一定的速度提升,具体效率依赖于 GPU 型号。需要小心数值精度过低带来的稳定性问题。时常使用 assert tensor.size() == (N, D, H, W) 作为调试手段,确保张量维度和你设想中一致。除了标记 y 外,尽量少使用一维张量,使用 n*1 的二维张量代替,可以避免一些意想不到的一维张量计算结果。统计代码各部分耗时:
with torch.autograd.profiler.profile(enabled=True, use_cuda=False) as profile:
...print(profile)# 或者在命令行运行python -m torch.utils.bottleneck main.py使用TorchSnooper来调试PyTorch代码,程序在执行的时候,就会自动 print 出来每一行的执行结果的 tensor 的形状、数据类型、设备、是否需要梯度的信息。
# pip install torchsnooper
import torchsnooper# 对于函数,使用修饰器@torchsnooper.snoop()
# 如果不是函数,使用 with 语句来激活 TorchSnooper,把训练的那个循环装进 with 语句中去。
with torchsnooper.snoop():
原本的代码https://github.com/zasdfgbnm/TorchSnoopergithub.com模型可解释性,使用captum库:https://captum.ai/captum.ai
参考资料
- 张皓:PyTorch Cookbook,https://zhuanlan.zhihu.com/p/59205847?
- PyTorch官方文档和示例
- https://pytorch.org/docs/stable/notes/faq.html
- https://github.com/szagoruyko/pytorchviz
- https://github.com/sksq96/pytorch-summary等
六、 改动一行代码,PyTorch训练三倍提速
近日,深度学习领域知名研究者、Lightning AI 的首席人工智能教育者 Sebastian Raschka 在 CVPR 2023 上发表了主题演讲「Scaling PyTorch Model Training With Minimal Code Changes」。
为了能与更多人分享研究成果,Sebastian Raschka 将演讲整理成一篇文章。文章探讨了如何在最小代码更改的情况下扩展 PyTorch 模型训练,并表明重点是利用混合精度(mixed-precision)方法和多 GPU 训练模式,而不是低级机器优化。
文章使用视觉 Transformer(ViT)作为基础模型,ViT 模型在一个基本数据集上从头开始,经过约 60 分钟的训练,在测试集上取得了 62% 的准确率。

GitHub 地址:https://github.com/rasbt/cvpr2023
以下是文章原文:
构建基准
在接下来的部分中,Sebastian 将探讨如何在不进行大量代码重构的情况下改善训练时间和准确率。
想要注意的是,模型和数据集的详细信息并不是这里的主要关注点(它们只是为了尽可能简单,以便读者可以在自己的机器上复现,而不需要下载和安装太多的依赖)。所有在这里分享的示例都可以在 GitHub 找到,读者可以探索和重用完整的代码。

脚本 00_pytorch-vit-random-init.py 的输出。
不要从头开始训练
现如今,从头开始训练文本或图像的深度学习模型通常是低效的。我们通常会利用预训练模型,并对模型进行微调,以节省时间和计算资源,同时获得更好的建模效果。
如果考虑上面使用的相同 ViT 架构,在另一个数据集(ImageNet)上进行预训练,并对其进行微调,就可以在更短的时间内实现更好的预测性能:20 分钟(3 个训练 epoch)内达到 95% 的测试准确率。

00_pytorch-vit-random-init.py 和 01_pytorch-vit.py 的对比。
提升计算性能
我们可以看到,相对于从零开始训练,微调可以大大提升模型性能。下面的柱状图总结了这一点。

00_pytorch-vit-random-init.py 和 01_pytorch-vit.py 的对比柱状图。
当然,模型效果可能因数据集或任务的不同而有所差异。但对于许多文本和图像任务来说,从一个在通用公共数据集上预训练的模型开始是值得的。
接下来的部分将探索各种技巧,以加快训练时间,同时又不牺牲预测准确性。
开源库 Fabric
在 PyTorch 中以最小代码更改来高效扩展训练的一种方法是使用开源 Fabric 库,它可以看作是 PyTorch 的一个轻量级包装库 / 接口。通过 pip 安装。
pip install lightning下面探索的所有技术也可以在纯 PyTorch 中实现。Fabric 的目标是使这一过程更加便利。
在探索「加速代码的高级技术」之前,先介绍一下将 Fabric 集成到 PyTorch 代码中需要进行的小改动。一旦完成这些改动,只需要改变一行代码,就可以轻松地使用高级 PyTorch 功能。
PyTorch 代码和修改后使用 Fabric 的代码之间的区别是微小的,只涉及到一些细微的修改,如下面的代码所示:

普通 PyTorch 代码(左)和使用 Fabric 的 PyTorch 代码
总结一下上图,就可以得到普通的 PyTorch 代码转换为 PyTorch+Fabric 的三个步骤:
- 导入 Fabric 并实例化一个 Fabric 对象。
- 使用 Fabric 设置模型、优化器和 data loader。
- 损失函数使用 fabric.backward (),而不是 loss.backward ()。

这些微小的改动提供了一种利用 PyTorch 高级特性的途径,而无需对现有代码进行进一步重构。
深入探讨下面的「高级特性」之前,要确保模型的训练运行时间、预测性能与之前相同。

01_pytorch-vit.py 和 03_fabric-vit.py 的比较结果。
正如前面柱状图中所看到的,训练运行时间、准确率与之前完全相同,正如预期的那样。其中,任何波动都可以归因于随机性。
在前面的部分中,我们使用 Fabric 修改了 PyTorch 代码。为什么要费这么大的劲呢?接下来将尝试高级技术,比如混合精度和分布式训练,只需更改一行代码,把下面的代码
fabric = Fabric(accelerator="cuda")改为
fabric = Fabric(accelerator="cuda", precisinotallow="bf16-mixed")
04_fabric-vit-mixed-precision.py 脚本的比较结果。脚本地址:https://github.com/rasbt/cvpr2023/blob/main/04_fabric-vit-mixed-precision.py
通过混合精度训练,我们将训练时间从 18 分钟左右缩短到 6 分钟,同时保持相同的预测性能。这种训练时间的缩短只需在实例化 Fabric 对象时添加参数「precisinotallow="bf16-mixed"」即可实现。
理解混合精度机制
混合精度训练实质上使用了 16 位和 32 位精度,以确保不会损失准确性。16 位表示中的计算梯度比 32 位格式快得多,并且还节省了大量内存。这种策略在内存或计算受限的情况下非常有益。
之所以称为「混合」而不是「低」精度训练,是因为不是将所有参数和操作转换为 16 位浮点数。相反,在训练过程中 32 位和 16 位操作之间切换,因此称为「混合」精度。
如下图所示,混合精度训练涉及步骤如下:
- 将权重转换为较低精度(FP16)以加快计算速度;
- 计算梯度;
- 将梯度转换回较高精度(FP32)以保持数值稳定性;
- 使用缩放后的梯度更新原始权重。
这种方法在保持神经网络准确性和稳定性的同时,实现了高效的训练。

更详细的步骤如下:
- 将权重转换为 FP16:在这一步中,神经网络的权重(或参数)初始时用 FP32 格式表示,将其转换为较低精度的 FP16 格式。这样可以减少内存占用,并且由于 FP16 操作所需的内存较少,可以更快地被硬件处理。
- 计算梯度:使用较低精度的 FP16 权重进行神经网络的前向传播和反向传播。这一步计算损失函数相对于网络权重的梯度(偏导数),这些梯度用于在优化过程中更新权重。
- 将梯度转换回 FP32:在计算得到 FP16 格式的梯度后,将其转换回较高精度的 FP32 格式。这种转换对于保持数值稳定性非常重要,避免使用较低精度算术时可能出现的梯度消失或梯度爆炸等问题。
- 乘学习率并更新权重:以 FP32 格式表示的梯度乘以学习率将用于更新权重(标量值,用于确定优化过程中的步长)。
步骤 4 中的乘积用于更新原始的 FP32 神经网络权重。学习率有助于控制优化过程的收敛性,对于实现良好的性能非常重要。
Brain Float 16
前面谈到了「float 16-bit」精度训练。需要注意的是,在之前的代码中,指定了 precisinotallow="bf16-mixed",而不是 precisinotallow="16-mixed"。这两个都是有效的选项。
在这里,"bf16-mixed" 中的「bf16」表示 Brain Floating Point(bfloat16)。谷歌开发了这种格式,用于机器学习和深度学习应用,尤其是在张量处理单元(TPU)中。Bfloat16 相比传统的 float16 格式扩展了动态范围,但牺牲了一定的精度。

扩展的动态范围使得 bfloat16 能够表示非常大和非常小的数字,使其更适用于深度学习应用中可能遇到的数值范围。然而,较低的精度可能会影响某些计算的准确性,或在某些情况下导致舍入误差。但在大多数深度学习应用中,这种降低的精度对建模性能的影响很小。
虽然 bfloat16 最初是为 TPU 开发的,但从 NVIDIA Ampere 架构的 A100 Tensor Core GPU 开始,已经有几种 NVIDIA GPU 开始支持 bfloat16。
我们可以使用下面的代码检查 GPU 是否支持 bfloat16:
>>> torch.cuda.is_bf16_supported()
True如果你的 GPU 不支持 bfloat16,可以将 precisinotallow="bf16-mixed" 更改为 precisinotallow="16-mixed"。
多 GPU 训练和完全分片数据并行
接下来要尝试修改多 GPU 训练。如果我们有多个 GPU 可供使用,这会带来好处,因为它可以让我们的模型训练速度更快。
这里介绍一种更先进的技术 — 完全分片数据并行(Fully Sharded Data Parallelism (FSDP)),它同时利用了数据并行性和张量并行性。

在 Fabric 中,我们可以通过下面的方式利用 FSDP 添加设备数量和多 GPU 训练策略:
fabric = Fabric(
accelerator="cuda", precisinotallow="bf16-mixed",
devices=4, strategy="FSDP" # new!
)
06_fabric-vit-mixed-fsdp.py 脚本的输出。
现在使用 4 个 GPU,我们的代码运行时间大约为 2 分钟,是之前仅使用混合精度训练时的近 3 倍。
理解数据并行和张量并行
在数据并行中,小批量数据被分割,并且每个 GPU 上都有模型的副本。这个过程通过多个 GPU 的并行工作来加速模型的训练速度。

如下简要概述了数据并行的工作原理:
- 同一个模型被复制到所有的 GPU 上。
- 每个 GPU 分别接收不同的输入数据子集(不同的小批量数据)。
- 所有的 GPU 独立地对模型进行前向传播和反向传播,计算各自的局部梯度。
- 收集并对所有 GPU 的梯度求平均值。
- 平均梯度被用于更新模型的参数。
每个 GPU 都在并行地处理不同的数据子集,通过梯度的平均化和参数的更新,整个模型的训练过程得以加速。
这种方法的主要优势是速度。由于每个 GPU 同时处理不同的小批量数据,模型可以在更短的时间内处理更多的数据。这可以显著减少训练模型所需的时间,特别是在处理大型数据集时。
然而,数据并行也有一些限制。最重要的是,每个 GPU 必须具有完整的模型和参数副本。这限制了可以训练的模型大小,因为模型必须适应单个 GPU 的内存。这对于现代的 ViTs 或 LLMs 来说这是不可行的。
与数据并行不同,张量并行将模型本身划分到多个 GPU 上。并且在数据并行中,每个 GPU 都需要适 应整个模型,这在训练较大的模型时可能成为一个限制。而张量并行允许训练那些对单个 GPU 而言可能过大的模型,通过将模型分解并分布到多个设备上进行训练。

张量并行是如何工作的呢?想象一下矩阵乘法,有两种方式可以进行分布计算 —— 按行或按列。为了简单起见,考虑按列进行分布计算。例如,我们可以将一个大型矩阵乘法操作分解为多个独立的计算,每个计算可以在不同的 GPU 上进行,如下图所示。然后将结果连接起来以获取结果,这有效地分摊了计算负载。

原文链接:https://magazine.sebastianraschka.com/p/accelerating-pytorch-model-training
七、 从0开始用 PyTorch 构建完整的 NeRF
笔者通过整理分析了NeRF论文和相关参考代码,将为读者朋友讲述利用PyTorch框架,从0到1简单复现一个NeRF(神经辐射场)的实现细节和过程。
在解释代码之前,首先对NeRF(神经辐射场)的原理与含义进行简单回顾。而NeRF论文中是这样解释NeRF算法流程的:
“我们提出了一个当前最优的方法,应用于复杂场景下合成新视图的任务,具体的实现原理是使用一个稀疏的输入视图集合,然后不断优化底层的连续体素场景函数。我们的算法,使用一个全连接(非卷积)的深度网络,表示一个场景,这个深度网络的输入是一个单独的5D坐标(空间位置(x,y,z)和视图方向(xita,sigma)),其对应的输出则是体素密度和视图关联的辐射向量。我们通过查询沿着相机射线的5D坐标合成新的场景视图,以及通过使用经典的体素渲染技术将输出颜色和密度投射到图像中。因为体素渲染具有天然的可变性,所以优化我们的表示方法所需的唯一输入就是一组已知相机位姿的图像。我们介绍如何高效优化神经辐射场照度,以渲染具有复杂几何形状和外观的逼真新颖视图,并展示了由于之前神经渲染和视图合成工作的结果。”
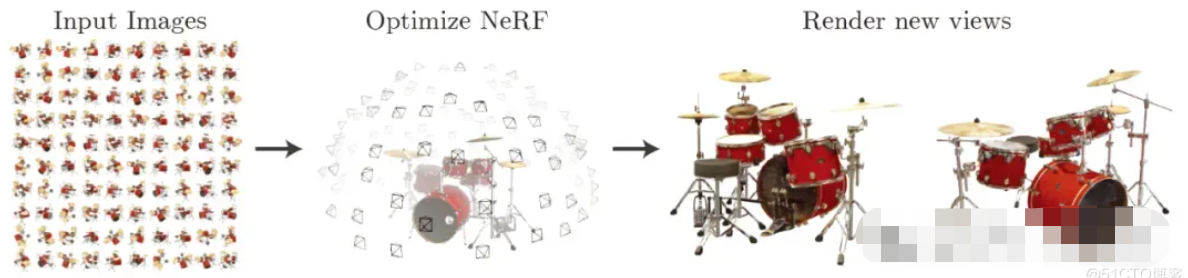
▲图1|NeRF实现流程©️【深蓝AI】
基于前文的原理,本节开始讲述具体的代码实现。首先,导入算法需要的Python库文件。
import os
from typing import Optional,Tuple,List,Union,Callable
import numpy as np
import torch
from torch import nn
import matplotlib.pyplot as plt
from mpl\_toolkits.mplot3d import axes3d
from tqdm import trange
# 设置GPU还是CPU设备
device = torch.device\('cuda' if torch.cuda.is\_available\(\) else 'cpu'\)1 输入
根据相关论文中的介绍可知,NeRF的输入是一个包含空间位置坐标与视图方向的5D坐标。然而,在PyTorch构建NeRF过程中使用的数据集只是一般的3D到2D图像数据集,包含拍摄相机的内参:位姿和焦距。因此在后面的操作中,我们会把输入数据集转为算法模型需要的输入形式。
在这一流程中使用乐高推土机图像作为简单NeRF算法的数据集,如图2所示:(具体的数据链接请在文末查看)
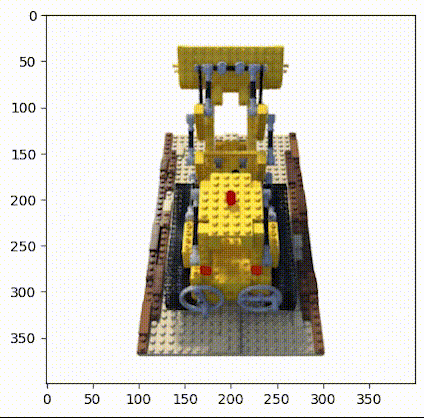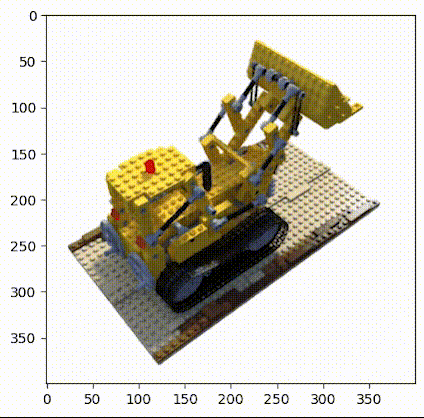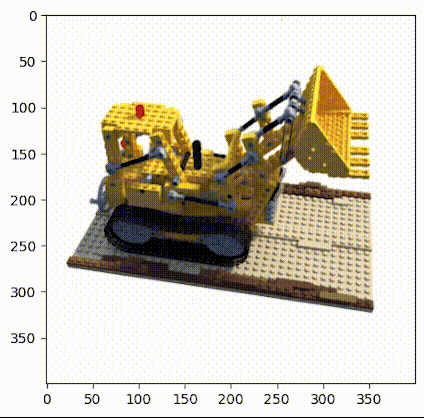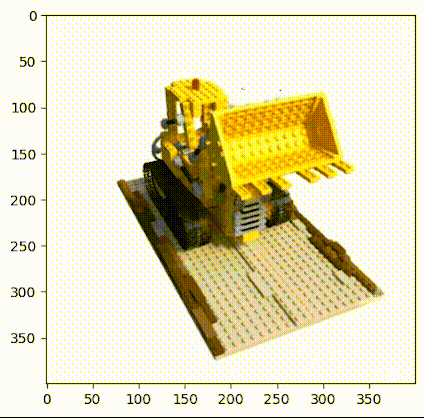
▲图2|乐高推土机数据集©️【深蓝AI】
这项工作中使用的小型乐高数据集由 106 幅乐高推土机的图像组成,并配有位姿数据和常用焦距数值。与其他数据集一样,这里保留前 100 张图像用于训练,并保留一张测试图像用于验证,具体的加载数据操作如下:
data = np.load\('tiny\_nerf\_data.npz'\) # 加载数据集
images = data\['images'\] # 图像数据
poses = data\['poses'\] # 位姿数据
focal = data\['focal'\] # 焦距数值
print\(f'Images shape: \{images.shape\}'\)
print\(f'Poses shape: \{poses.shape\}'\)
print\(f'Focal length: \{focal\}'\)
height, width = images.shape\[1:3\]
near, far = 2., 6.
n\_training = 100 # 训练数据数量
testimg\_idx = 101 # 测试数据下标
testimg, testpose = images\[testimg\_idx\], poses\[testimg\_idx\]
plt.imshow\(testimg\)
print\('Pose'\)
print\(testpose\)2 数据处理
回顾NeRF相关论文, 本次代码实现需要的输入是一个单独的5D坐标 (空间位置 和视图方向 , sigma ))。因此, 我们需要针对上面使用的小型乐高数据做一个处理操作。
一般而言,为了收集这些特点输入数据,算法中需要对输入图像进行反渲染操作。具体来讲就是通过每个像素点在三维空间中绘制投影线,并从中提取样本。
要从图像以外的三维空间采样输入数据点,首先就得从乐高照片集中获取每台相机的初始位姿,然后通过一些矢量数学运算,将这些4x4姿态矩阵转换成「表示原点的三维坐标和表示方向的三维矢量」——这两类信息最终会结合起来描述一个矢量,该矢量用以表征拍摄照片时相机的指向。
下列代码则正是通过绘制箭头来描述这一操作,箭头表示每一帧图像的原点和方向:
# 方向数据
dirs = np.stack\(\[np.sum\(\[0, 0, -1\] \* pose\[:3, :3\], axis=-1\) for pose in poses\]\)
# 原点数据
origins = poses\[:, :3, -1\]
# 绘图的设置
ax = plt.figure\(figsize=\(12, 8\)\).add\_subplot\(projectinotallow='3d'\)
\_ = ax.quiver\(
origins\[..., 0\].flatten\(\),
origins\[..., 1\].flatten\(\),
origins\[..., 2\].flatten\(\),
dirs\[..., 0\].flatten\(\),
dirs\[..., 1\].flatten\(\),
dirs\[..., 2\].flatten\(\), length=0.5, normalize=True\)
ax.set\_xlabel\('X'\)
ax.set\_ylabel\('Y'\)
ax.set\_zlabel\('z'\)
plt.show\(\)最终绘制出来的箭头结果如下图所示:
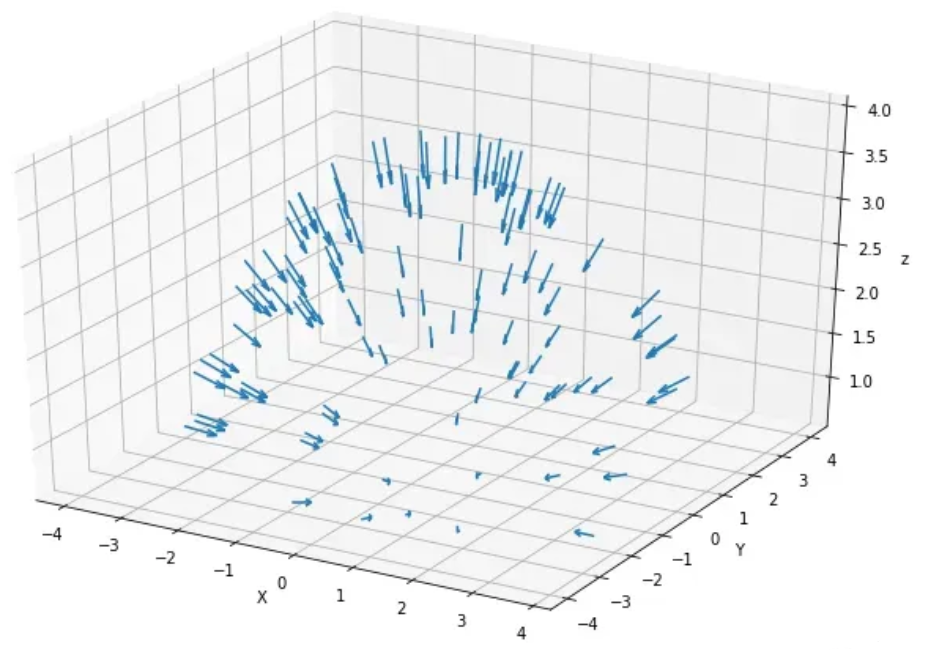
▲图3|采样点相机拍摄指向©️【深蓝AI】
当有了这些相机位姿数据之后,我们就可以沿着图像的每个像素找到投影线,而每条投影线都是由其原点(x,y,z)和方向联合定义。其中每个像素的原点可能相同,但方向一般是不同的。这些方向射线都略微偏离中心,因此不会存在两条平行方向线,如下图所示:
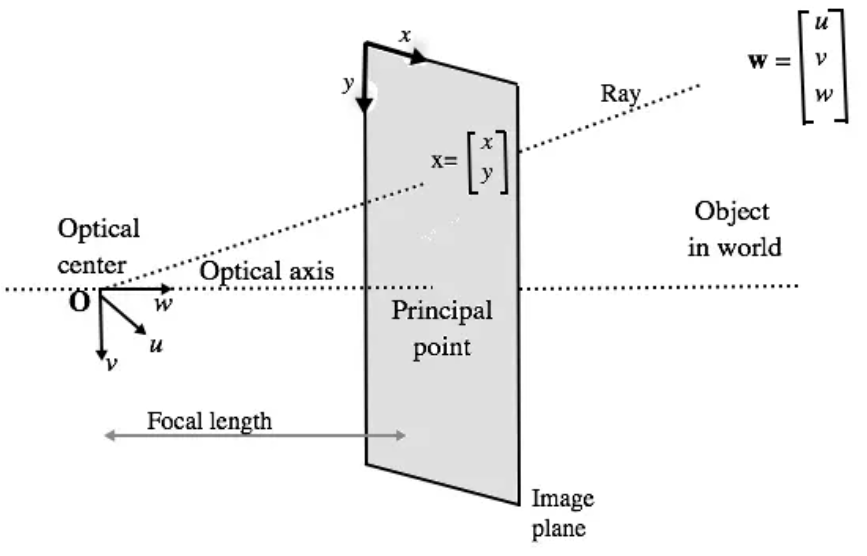
▲图4|相机内参示意图©️【深蓝AI】编译
根据图4所述的原理,我们就可以确定每条射线的方向和原点,相关代码如下:
def get\_rays\(
height: int, # 图像高度
width: int, # 图像宽带
focal\_length: float, # 焦距
c2w: torch.Tensor
\) -> Tuple\[torch.Tensor, torch.Tensor\]:
"""
通过每个像素和相机原点,找到射线的原点和方向。
"""
# 应用针孔相机模型收集每个像素的方向
i, j = torch.meshgrid\(
torch.arange\(width, dtype=torch.float32\).to\(c2w\),
torch.arange\(height, dtype=torch.float32\).to\(c2w\),
indexing='ij'\)
i, j = i.transpose\(-1, -2\), j.transpose\(-1, -2\)
# 方向数据
directions = torch.stack\(\[\(i - width \* .5\) / focal\_length,
-\(j - height \* .5\) / focal\_length,
-torch.ones\_like\(i\)
\], dim=-1\)
# 用相机位姿求出方向
rays\_d = torch.sum\(directions\[..., None, :\] \* c2w\[:3, :3\], dim=-1\)
# 默认所有射线原点相同
rays\_o = c2w\[:3, -1\].expand\(rays\_d.shape\)
return rays\_o, rays\_d得到每个像素对应的射线的方向数据和原点数据之后,就能够获得了NeRF算法中需要的五维数据输入,下面将这些数据调整为算法输入的格式:
# 转为PyTorch的tensor
images = torch.from\_numpy\(data\['images'\]\[:n\_training\]\).to\(device\)
poses = torch.from\_numpy\(data\['poses'\]\).to\(device\)
focal = torch.from\_numpy\(data\['focal'\]\).to\(device\)
testimg = torch.from\_numpy\(data\['images'\]\[testimg\_idx\]\).to\(device\)
testpose = torch.from\_numpy\(data\['poses'\]\[testimg\_idx\]\).to\(device\)
# 针对每个图像获取射线
height, width = images.shape\[1:3\]
with torch.no\_grad\(\):
ray\_origin, ray\_direction = get\_rays\(height, width, focal, testpose\)
print\('Ray Origin'\)
print\(ray\_origin.shape\)
print\(ray\_origin\[height // 2, width // 2, :\]\)
print\(''\)
print\('Ray Direction'\)
print\(ray\_direction.shape\)
print\(ray\_direction\[height // 2, width // 2, :\]\)
print\(''\)2.1 分层采样
当算法输入模块有了NeRF算法需要的输入数据,也就是包含原点和方向向量组合的线条时,就可以在线条上进行采样。这一过程是采用从粗到细的采样策略,即分层采样策略。
具体来说,分层采样就是将光线分成均匀分布的小块,接着在每个小块内随机抽样。其中扰动的设置决定了是均匀取样的,还是直接简单使用分区中心作为采样点。具体操作代码如下所示:
# 采样函数定义
def sample\_stratified\(
rays\_o: torch.Tensor, # 射线原点
rays\_d: torch.Tensor, # 射线方向
near: float,
far: float,
n\_samples: int, # 采样数量
perturb: Optional\[bool\] = True, # 扰动设置
inverse\_depth: bool = False # 反向深度
\) -> Tuple\[torch.Tensor, torch.Tensor\]:
"""
从规则的bin中沿着射线进行采样。
"""
# 沿着射线抓取采样点
t\_vals = torch.linspace\(0., 1., n\_samples, device=rays\_o.device\)
if not inverse\_depth:
# 由远到近线性采样
z\_vals = near \* \(1.-t\_vals\) + far \* \(t\_vals\)
else:
# 在反向深度中线性采样
z\_vals = 1./\(1./near \* \(1.-t\_vals\) + 1./far \* \(t\_vals\)\)
# 沿着射线从bins中统一采样
if perturb:
mids = .5 \* \(z\_vals\[1:\] + z\_vals\[:-1\]\)
upper = torch.concat\(\[mids, z\_vals\[-1:\]\], dim=-1\)
lower = torch.concat\(\[z\_vals\[:1\], mids\], dim=-1\)
t\_rand = torch.rand\(\[n\_samples\], device=z\_vals.device\)
z\_vals = lower + \(upper - lower\) \* t\_rand
z\_vals = z\_vals.expand\(list\(rays\_o.shape\[:-1\]\) + \[n\_samples\]\)
# 应用相应的缩放参数
pts = rays\_o\[..., None, :\] + rays\_d\[..., None, :\] \* z\_vals\[..., :, None\]
return pts, z\_vals接着就到了对这些采样点做可视化分析的步骤。如图5中所述,未受扰动的蓝 色点是bin的“中心“,而红点对应扰动点的采样。请注意,红点与上方的蓝点略有偏移,但所有点都在远近采样设定值之间。具体代码如下:
y\_vals = torch.zeros\_like\(z\_vals\)
# 调用采样策略函数
\_, z\_vals\_unperturbed = sample\_stratified\(rays\_o, rays\_d, near, far, n\_samples,
perturb=False, inverse\_depth=inverse\_depth\)
# 绘图相关
plt.plot\(z\_vals\_unperturbed\[0\].cpu\(\).numpy\(\), 1 + y\_vals\[0\].cpu\(\).numpy\(\), 'b-o'\)
plt.plot\(z\_vals\[0\].cpu\(\).numpy\(\), y\_vals\[0\].cpu\(\).numpy\(\), 'r-o'\)
plt.ylim\(\[-1, 2\]\)
plt.title\('Stratified Sampling \(blue\) with Perturbation \(red\)'\)
ax = plt.gca\(\)
ax.axes.yaxis.set\_visible\(False\)
plt.grid\(True\)
▲图5|采样结果示意图
3 位置编码
与Transformer一样,NeRF也使用了位置编码器。因此NeRF就需要借助位置编码器将输入映射到更高的频率空间,以弥补神经网络在学习低频函数时的偏差。
这一环节将会为位置编码器建立一个简单的 torch.nn.Module 模块,相同的编码器可同时用于对输入样本和视图方向的编码操作。注意,这些输入被指定了不同的参数。代码如下所示:
# 位置编码类
class PositionalEncoder\(nn.Module\):
"""
对输入点,做sine或者consine位置编码。
"""
def \_\_init\_\_\(
self,
d\_input: int,
n\_freqs: int,
log\_space: bool = False
\):
super\(\).\_\_init\_\_\(\)
self.d\_input = d\_input
self.n\_freqs = n\_freqs
self.log\_space = log\_space
self.d\_output = d\_input \* \(1 + 2 \* self.n\_freqs\)
self.embed\_fns = \[lambda x: x\]
# 定义线性或者log尺度的频率
if self.log\_space:
freq\_bands = 2.\*\*torch.linspace\(0., self.n\_freqs - 1, self.n\_freqs\)
else:
freq\_bands = torch.linspace\(2.\*\*0., 2.\*\*\(self.n\_freqs - 1\), self.n\_freqs\)
# 替换sin和cos
for freq in freq\_bands:
self.embed\_fns.append\(lambda x, freq=freq: torch.sin\(x \* freq\)\)
self.embed\_fns.append\(lambda x, freq=freq: torch.cos\(x \* freq\)\)
def forward\(
self,
x
\) -> torch.Tensor:
"""
实际使用位置编码的函数。
"""
return torch.concat\(\[fn\(x\) for fn in self.embed\_fns\], dim=-1\)4 NeRF模型
在此,定义一个NeRF 模型——主要由线性层模块列表构成,而列表中进一步包含非线性激活函数和残差连接。该模型有一个可选的视图方向输入,如果在实例化时提供具体的方向信息,那么会改变模型结构。
(本实现基于原始论文NeRF:Representing Scenes as Neural Radiance Fields for View Synthesis 的第3节,并使用相同的默认设置)
具体代码如下所示:
# 定义NeRF模型
class NeRF\(nn.Module\):
"""
神经辐射场模块。
"""
def \_\_init\_\_\(
self,
d\_input: int = 3,
n\_layers: int = 8,
d\_filter: int = 256,
skip: Tuple\[int\] = \(4,\),
d\_viewdirs: Optional\[int\] = None
\):
super\(\).\_\_init\_\_\(\)
self.d\_input = d\_input # 输入
self.skip = skip # 残差连接
self.act = nn.functional.relu # 激活函数
self.d\_viewdirs = d\_viewdirs # 视图方向
# 创建模型的层结构
self.layers = nn.ModuleList\(
\[nn.Linear\(self.d\_input, d\_filter\)\] +
\[nn.Linear\(d\_filter + self.d\_input, d\_filter\) if i in skip \\
else nn.Linear\(d\_filter, d\_filter\) for i in range\(n\_layers - 1\)\]
\)
# Bottleneck 层
if self.d\_viewdirs is not None:
# 如果使用视图方向,分离alpha和RGB
self.alpha\_out = nn.Linear\(d\_filter, 1\)
self.rgb\_filters = nn.Linear\(d\_filter, d\_filter\)
self.branch = nn.Linear\(d\_filter + self.d\_viewdirs, d\_filter // 2\)
self.output = nn.Linear\(d\_filter // 2, 3\)
else:
# 如果不使用试图方向,则简单输出
self.output = nn.Linear\(d\_filter, 4\)
def forward\(
self,
x: torch.Tensor,
viewdirs: Optional\[torch.Tensor\] = None
\) -> torch.Tensor:
r"""
带有视图方向的前向传播
"""
# 判断是否设置视图方向
if self.d\_viewdirs is None and viewdirs is not None:
raise ValueError\('Cannot input x\_direction if d\_viewdirs was not given.'\)
# 运行bottleneck层之前的网络层
x\_input = x
for i, layer in enumerate\(self.layers\):
x = self.act\(layer\(x\)\)
if i in self.skip:
x = torch.cat\(\[x, x\_input\], dim=-1\)
# 运行 bottleneck
if self.d\_viewdirs is not None:
# Split alpha from network output
alpha = self.alpha\_out\(x\)
# 结果传入到rgb过滤器
x = self.rgb\_filters\(x\)
x = torch.concat\(\[x, viewdirs\], dim=-1\)
x = self.act\(self.branch\(x\)\)
x = self.output\(x\)
# 拼接alpha一起作为输出
x = torch.concat\(\[x, alpha\], dim=-1\)
else:
# 不拼接,简单输出
x = self.output\(x\)
return x5 体积渲染
上面得到NeRF模型的输出结果之后,仍需将NeRF的输出转换成图像。也就是通过渲染模块对每个像素沿光线方向的所有样本进行加权求和,从而得到该像素的估计颜色值,此外每个RGB样本都会根据其Alpha值进行加权。其中Alpha值越高,表明采样区域不透明的可能性越大,因此沿射线方向越远的点越有可能被遮挡,累加乘积可确保更远处的点受到抑制。具体代码如下:
# 体积渲染
def cumprod\_exclusive\(
tensor: torch.Tensor
\) -> torch.Tensor:
"""
\(Courtesy of https://github.com/krrish94/nerf-pytorch\)
和tf.math.cumprod\(..., exclusive=True\)功能类似
参数:
tensor \(torch.Tensor\): Tensor whose cumprod \(cumulative product, see \`torch.cumprod\`\) along dim=-1
is to be computed.
返回值:
cumprod \(torch.Tensor\): cumprod of Tensor along dim=-1, mimiciking the functionality of
tf.math.cumprod\(..., exclusive=True\) \(see \`tf.math.cumprod\` for details\).
"""
# 首先计算规则的cunprod
cumprod = torch.cumprod\(tensor, -1\)
cumprod = torch.roll\(cumprod, 1, -1\)
# 用1替换首个元素
cumprod\[..., 0\] = 1.
return cumprod
# 输出到图像的函数
def raw2outputs\(
raw: torch.Tensor,
z\_vals: torch.Tensor,
rays\_d: torch.Tensor,
raw\_noise\_std: float = 0.0,
white\_bkgd: bool = False
\) -> Tuple\[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor\]:
"""
将NeRF的输出转换为RGB输出。
"""
# 沿着\`z\_vals\`轴元素之间的差值.
dists = z\_vals\[..., 1:\] - z\_vals\[..., :-1\]
dists = torch.cat\(\[dists, 1e10 \* torch.ones\_like\(dists\[..., :1\]\)\], dim=-1\)
# 将每个距离乘以相应方向射线的法线,转换为现实世界中的距离(考虑非单位方向)。
dists = dists \* torch.norm\(rays\_d\[..., None, :\], dim=-1\)
# 为模型预测密度添加噪音。可用于在训练过程中对网络进行正则化(防止出现浮点伪影)。
noise = 0.
if raw\_noise\_std > 0.:
noise = torch.randn\(raw\[..., 3\].shape\) \* raw\_noise\_std
# Predict density of each sample along each ray. Higher values imply
# higher likelihood of being absorbed at this point. \[n\_rays, n\_samples\]
alpha = 1.0 - torch.exp\(-nn.functional.relu\(raw\[..., 3\] + noise\) \* dists\)
# 预测每条射线上每个样本的密度。数值越大,表示该点被吸收的可能性越大。\[n\_ 射线,n\_样本]
weights = alpha \* cumprod\_exclusive\(1. - alpha + 1e-10\)
# 计算RGB图的权重。
rgb = torch.sigmoid\(raw\[..., :3\]\) # \[n\_rays, n\_samples, 3\]
rgb\_map = torch.sum\(weights\[..., None\] \* rgb, dim=-2\) # \[n\_rays, 3\]
# 估计预测距离的深度图。
depth\_map = torch.sum\(weights \* z\_vals, dim=-1\)
# 稀疏图
disp\_map = 1. / torch.max\(1e-10 \* torch.ones\_like\(depth\_map\),
depth\_map / torch.sum\(weights, -1\)\)
# 沿着每条射线加权。
acc\_map = torch.sum\(weights, dim=-1\)
# 要合成到白色背景上,请使用累积的 alpha 贴图。
if white\_bkgd:
rgb\_map = rgb\_map + \(1. - acc\_map\[..., None\]\)
return rgb\_map, depth\_map, acc\_map, weights6 分层体积采样
事实上,三维空间中的遮挡物非常稀疏,因此大多数点对渲染图像的贡献不大。所以,对积分有贡献的区域进行超采样会有更好的效果。这里,笔者对第一组样本应用基于归一化的权重来创建整个光线的概率密度函数,然后对该密度函数应用反变换采样来收集第二组样本。具体代码如下:
# 采样概率密度函数
def sample\_pdf\(
bins: torch.Tensor,
weights: torch.Tensor,
n\_samples: int,
perturb: bool = False
\) -> torch.Tensor:
"""
应用反向转换采样到一组加权点。
"""
# 正则化权重得到概率密度函数。
pdf = \(weights + 1e-5\) / torch.sum\(weights + 1e-5, -1, keepdims=True\) # \[n\_rays, weights.shape\[-1\]\]
# 将概率密度函数转为累计分布函数。
cdf = torch.cumsum\(pdf, dim=-1\) # \[n\_rays, weights.shape\[-1\]\]
cdf = torch.concat\(\[torch.zeros\_like\(cdf\[..., :1\]\), cdf\], dim=-1\) # \[n\_rays, weights.shape\[-1\] + 1\]
# 从累计分布函数中提取样本位置。perturb == 0 时为线性。
if not perturb:
u = torch.linspace\(0., 1., n\_samples, device=cdf.device\)
u = u.expand\(list\(cdf.shape\[:-1\]\) + \[n\_samples\]\) # \[n\_rays, n\_samples\]
else:
u = torch.rand\(list\(cdf.shape\[:-1\]\) + \[n\_samples\], device=cdf.device\) # \[n\_rays, n\_samples\]
# 沿累计分布函数找出 u 值所在的索引。
u = u.contiguous\(\) # 返回具有相同值的连续张量。
inds = torch.searchsorted\(cdf, u, right=True\) # \[n\_rays, n\_samples\]
# 夹住超出范围的索引。
below = torch.clamp\(inds - 1, min=0\)
above = torch.clamp\(inds, max=cdf.shape\[-1\] - 1\)
inds\_g = torch.stack\(\[below, above\], dim=-1\) # \[n\_rays, n\_samples, 2\]
# 从累计分布函数和相应的 bin 中心取样。
matched\_shape = list\(inds\_g.shape\[:-1\]\) + \[cdf.shape\[-1\]\]
cdf\_g = torch.gather\(cdf.unsqueeze\(-2\).expand\(matched\_shape\), dim=-1,
index=inds\_g\)
bins\_g = torch.gather\(bins.unsqueeze\(-2\).expand\(matched\_shape\), dim=-1,
index=inds\_g\)
# 将样本转换为射线长度。
denom = \(cdf\_g\[..., 1\] - cdf\_g\[..., 0\]\)
denom = torch.where\(denom \< 1e-5, torch.ones\_like\(denom\), denom\)
t = \(u - cdf\_g\[..., 0\]\) / denom
samples = bins\_g\[..., 0\] + t \* \(bins\_g\[..., 1\] - bins\_g\[..., 0\]\)
return samples # \[n\_rays, n\_samples\]7 整体的前向传播流程
此时应将上面所有内容整合在一起,通过模型计算一次前向传递。
由于潜在的内存问题,前向传递以“块“为单位进行计算,然后汇总到一个批次中。梯度传播是在整个批次处理完毕后进行的,因此有“块“和“批次“之分。对于内存紧张环境来说,分块处理尤为重要,因为该环境下提供的资源比原始论文中引用的资源更为有限。具体代码如下所示:
def get\_chunks\(
inputs: torch.Tensor,
chunksize: int = 2\*\*15
\) -> List\[torch.Tensor\]:
"""
输入分块。
"""
return \[inputs\[i:i + chunksize\] for i in range\(0, inputs.shape\[0\], chunksize\)\]
def prepare\_chunks\(
points: torch.Tensor,
encoding\_function: Callable\[\[torch.Tensor\], torch.Tensor\],
chunksize: int = 2\*\*15
\) -> List\[torch.Tensor\]:
"""
对点进行编码和分块,为 NeRF 模型做好准备。
"""
points = points.reshape\(\(-1, 3\)\)
points = encoding\_function\(points\)
points = get\_chunks\(points, chunksize=chunksize\)
return points
def prepare\_viewdirs\_chunks\(
points: torch.Tensor,
rays\_d: torch.Tensor,
encoding\_function: Callable\[\[torch.Tensor\], torch.Tensor\],
chunksize: int = 2\*\*15
\) -> List\[torch.Tensor\]:
r"""
对视图方向进行编码和分块,为 NeRF 模型做好准备。
"""
viewdirs = rays\_d / torch.norm\(rays\_d, dim=-1, keepdim=True\)
viewdirs = viewdirs\[:, None, ...\].expand\(points.shape\).reshape\(\(-1, 3\)\)
viewdirs = encoding\_function\(viewdirs\)
viewdirs = get\_chunks\(viewdirs, chunksize=chunksize\)
return viewdirs
def nerf\_forward\(
rays\_o: torch.Tensor,
rays\_d: torch.Tensor,
near: float,
far: float,
encoding\_fn: Callable\[\[torch.Tensor\], torch.Tensor\],
coarse\_model: nn.Module,
kwargs\_sample\_stratified: dict = None,
n\_samples\_hierarchical: int = 0,
kwargs\_sample\_hierarchical: dict = None,
fine\_model = None,
viewdirs\_encoding\_fn: Optional\[Callable\[\[torch.Tensor\], torch.Tensor\]\] = None,
chunksize: int = 2\*\*15
\) -> Tuple\[torch.Tensor, torch.Tensor, torch.Tensor, dict\]:
"""
计算一次前向传播
"""
# 设置参数
if kwargs\_sample\_stratified is None:
kwargs\_sample\_stratified = \{\}
if kwargs\_sample\_hierarchical is None:
kwargs\_sample\_hierarchical = \{\}
# 沿着每条射线的样本查询点。
query\_points, z\_vals = sample\_stratified\(
rays\_o, rays\_d, near, far, \*\*kwargs\_sample\_stratified\)
# 准备批次。
batches = prepare\_chunks\(query\_points, encoding\_fn, chunksize=chunksize\)
if viewdirs\_encoding\_fn is not None:
batches\_viewdirs = prepare\_viewdirs\_chunks\(query\_points, rays\_d,
viewdirs\_encoding\_fn,
chunksize=chunksize\)
else:
batches\_viewdirs = \[None\] \* len\(batches\)
# 稀疏模型流程。
predictions = \[\]
for batch, batch\_viewdirs in zip\(batches, batches\_viewdirs\):
predictions.append\(coarse\_model\(batch, viewdirs=batch\_viewdirs\)\)
raw = torch.cat\(predictions, dim=0\)
raw = raw.reshape\(list\(query\_points.shape\[:2\]\) + \[raw.shape\[-1\]\]\)
# 执行可微分体积渲染,重新合成 RGB 图像。
rgb\_map, depth\_map, acc\_map, weights = raw2outputs\(raw, z\_vals, rays\_d\)
outputs = \{
'z\_vals\_stratified': z\_vals
\}
if n\_samples\_hierarchical > 0:
# Save previous outputs to return.
rgb\_map\_0, depth\_map\_0, acc\_map\_0 = rgb\_map, depth\_map, acc\_map
# 对精细查询点进行分层抽样。
query\_points, z\_vals\_combined, z\_hierarch = sample\_hierarchical\(
rays\_o, rays\_d, z\_vals, weights, n\_samples\_hierarchical,
\*\*kwargs\_sample\_hierarchical\)
# 像以前一样准备输入。
batches = prepare\_chunks\(query\_points, encoding\_fn, chunksize=chunksize\)
if viewdirs\_encoding\_fn is not None:
batches\_viewdirs = prepare\_viewdirs\_chunks\(query\_points, rays\_d,
viewdirs\_encoding\_fn,
chunksize=chunksize\)
else:
batches\_viewdirs = \[None\] \* len\(batches\)
# 通过精细模型向前传递新样本。
fine\_model = fine\_model if fine\_model is not None else coarse\_model
predictions = \[\]
for batch, batch\_viewdirs in zip\(batches, batches\_viewdirs\):
predictions.append\(fine\_model\(batch, viewdirs=batch\_viewdirs\)\)
raw = torch.cat\(predictions, dim=0\)
raw = raw.reshape\(list\(query\_points.shape\[:2\]\) + \[raw.shape\[-1\]\]\)
# 执行可微分体积渲染,重新合成 RGB 图像。
rgb\_map, depth\_map, acc\_map, weights = raw2outputs\(raw, z\_vals\_combined, rays\_d\)
# 存储输出
outputs\['z\_vals\_hierarchical'\] = z\_hierarch
outputs\['rgb\_map\_0'\] = rgb\_map\_0
outputs\['depth\_map\_0'\] = depth\_map\_0
outputs\['acc\_map\_0'\] = acc\_map\_0
# 存储输出
outputs\['rgb\_map'\] = rgb\_map
outputs\['depth\_map'\] = depth\_map
outputs\['acc\_map'\] = acc\_map
outputs\['weights'\] = weights
return outputs到这一步骤,就几乎拥有了训练模型所需的一切模块。现在为一个简单的训练过程做一些设置,创建超参数和辅助函数,然后来训练模型。
7.1 超参数
所有用于训练的超参数都在此设置,默认值取自原始论文中数据,除非计算上有限制。在计算受限情况下,本次讨论采用的都是合理的默认值。
# 编码器
d\_input = 3 # 输入维度
n\_freqs = 10 # 输入到编码函数中的样本点数量
log\_space = True # 如果设置,频率按对数空间缩放
use\_viewdirs = True # 如果设置,则使用视图方向作为输入
n\_freqs\_views = 4 # 视图编码功能的数量
# 采样策略
n\_samples = 64 # 每条射线的空间样本数
perturb = True # 如果设置,则对采样位置应用噪声
inverse\_depth = False # 如果设置,则按反深度线性采样点
# 模型
d\_filter = 128 # 线性层滤波器的尺寸
n\_layers = 2 # bottleneck层数量
skip = \[\] # 应用输入残差的层级
use\_fine\_model = True # 如果设置,则创建一个精细模型
d\_filter\_fine = 128 # 精细网络线性层滤波器的尺寸
n\_layers\_fine = 6 # 精细网络瓶颈层数
# 分层采样
n\_samples\_hierarchical = 64 # 每条射线的样本数
perturb\_hierarchical = False # 如果设置,则对采样位置应用噪声
# 优化器
lr = 5e-4 # 学习率
# 训练
n\_iters = 10000
batch\_size = 2\*\*14 # 每个梯度步长的射线数量(2 的幂次)
one\_image\_per\_step = True # 每个梯度步骤一个图像(禁用批处理)
chunksize = 2\*\*14 # 根据需要进行修改,以适应 GPU 内存
center\_crop = True # 裁剪图像的中心部分(每幅图像裁剪一次)
center\_crop\_iters = 50 # 经过这么多epoch后,停止裁剪中心
display\_rate = 25 # 每 X 个epoch显示一次测试输出
# 早停
warmup\_iters = 100 # 热身阶段的迭代次数
warmup\_min\_fitness = 10.0 # 在热身\_iters 处继续训练的最小 PSNR 值
n\_restarts = 10 # 训练停滞时重新开始的次数
# 捆绑了各种函数的参数,以便一次性传递。
kwargs\_sample\_stratified = \{
'n\_samples': n\_samples,
'perturb': perturb,
'inverse\_depth': inverse\_depth
\}
kwargs\_sample\_hierarchical = \{
'perturb': perturb
\}7.2 训练类和函数
这一环节会创建一些用于训练的辅助函数。NeRF很容易出现局部最小值,在这种情况下,训练很快就会停滞并产生空白输出。必要时,会利用EarlyStopping重新启动训练。
# 绘制采样函数
def plot\_samples\(
z\_vals: torch.Tensor,
z\_hierarch: Optional\[torch.Tensor\] = None,
ax: Optional\[np.ndarray\] = None\):
r"""
绘制分层样本和(可选)分级样本。
"""
y\_vals = 1 + np.zeros\_like\(z\_vals\)
if ax is None:
ax = plt.subplot\(\)
ax.plot\(z\_vals, y\_vals, 'b-o'\)
if z\_hierarch is not None:
y\_hierarch = np.zeros\_like\(z\_hierarch\)
ax.plot\(z\_hierarch, y\_hierarch, 'r-o'\)
ax.set\_ylim\(\[-1, 2\]\)
ax.set\_title\('Stratified Samples \(blue\) and Hierarchical Samples \(red\)'\)
ax.axes.yaxis.set\_visible\(False\)
ax.grid\(True\)
return ax
def crop\_center\(
img: torch.Tensor,
frac: float = 0.5
\) -> torch.Tensor:
r"""
从图像中裁剪中心方形。
"""
h\_offset = round\(img.shape\[0\] \* \(frac / 2\)\)
w\_offset = round\(img.shape\[1\] \* \(frac / 2\)\)
return img\[h\_offset:-h\_offset, w\_offset:-w\_offset\]
class EarlyStopping:
r"""
基于适配标准的早期停止辅助器
"""
def \_\_init\_\_\(
self,
patience: int = 30,
margin: float = 1e-4
\):
self.best\_fitness = 0.0
self.best\_iter = 0
self.margin = margin
self.patience = patience or float\('inf'\) # 在epoch停止提高后等待的停止时间
def \_\_call\_\_\(
self,
iter: int,
fitness: float
\):
r"""
检查是否符合停止标准。
"""
if \(fitness - self.best\_fitness\) > self.margin:
self.best\_iter = iter
self.best\_fitness = fitness
delta = iter - self.best\_iter
stop = delta >= self.patience # 超过耐性则停止训练
return stop
def init\_models\(\):
r"""
为 NeRF 训练初始化模型、编码器和优化器。
"""
# 编码器
encoder = PositionalEncoder\(d\_input, n\_freqs, log\_space=log\_space\)
encode = lambda x: encoder\(x\)
# 视图方向编码
if use\_viewdirs:
encoder\_viewdirs = PositionalEncoder\(d\_input, n\_freqs\_views,
log\_space=log\_space\)
encode\_viewdirs = lambda x: encoder\_viewdirs\(x\)
d\_viewdirs = encoder\_viewdirs.d\_output
else:
encode\_viewdirs = None
d\_viewdirs = None
# 模型
model = NeRF\(encoder.d\_output, n\_layers=n\_layers, d\_filter=d\_filter, skip=skip,
d\_viewdirs=d\_viewdirs\)
model.to\(device\)
model\_params = list\(model.parameters\(\)\)
if use\_fine\_model:
fine\_model = NeRF\(encoder.d\_output, n\_layers=n\_layers, d\_filter=d\_filter, skip=skip,
d\_viewdirs=d\_viewdirs\)
fine\_model.to\(device\)
model\_params = model\_params + list\(fine\_model.parameters\(\)\)
else:
fine\_model = None
# 优化器
optimizer = torch.optim.Adam\(model\_params, lr=lr\)
# 早停
warmup\_stopper = EarlyStopping\(patience=50\)
return model, fine\_model, encode, encode\_viewdirs, optimizer, warmup\_stopper7.3 训练循环
下面就是具体的训练循环过程函数:
def train\(\):
r"""
启动 NeRF 训练。
"""
# 对所有图像进行射线洗牌。
if not one\_image\_per\_step:
height, width = images.shape\[1:3\]
all\_rays = torch.stack\(\[torch.stack\(get\_rays\(height, width, focal, p\), 0\)
for p in poses\[:n\_training\]\], 0\)
rays\_rgb = torch.cat\(\[all\_rays, images\[:, None\]\], 1\)
rays\_rgb = torch.permute\(rays\_rgb, \[0, 2, 3, 1, 4\]\)
rays\_rgb = rays\_rgb.reshape\(\[-1, 3, 3\]\)
rays\_rgb = rays\_rgb.type\(torch.float32\)
rays\_rgb = rays\_rgb\[torch.randperm\(rays\_rgb.shape\[0\]\)\]
i\_batch = 0
train\_psnrs = \[\]
val\_psnrs = \[\]
iternums = \[\]
for i in trange\(n\_iters\):
model.train\(\)
if one\_image\_per\_step:
# 随机选择一张图片作为目标。
target\_img\_idx = np.random.randint\(images.shape\[0\]\)
target\_img = images\[target\_img\_idx\].to\(device\)
if center\_crop and i \< center\_crop\_iters:
target\_img = crop\_center\(target\_img\)
height, width = target\_img.shape\[:2\]
target\_pose = poses\[target\_img\_idx\].to\(device\)
rays\_o, rays\_d = get\_rays\(height, width, focal, target\_pose\)
rays\_o = rays\_o.reshape\(\[-1, 3\]\)
rays\_d = rays\_d.reshape\(\[-1, 3\]\)
else:
# 在所有图像上随机显示。
batch = rays\_rgb\[i\_batch:i\_batch + batch\_size\]
batch = torch.transpose\(batch, 0, 1\)
rays\_o, rays\_d, target\_img = batch
height, width = target\_img.shape\[:2\]
i\_batch += batch\_size
# 一个epoch后洗牌
if i\_batch >= rays\_rgb.shape\[0\]:
rays\_rgb = rays\_rgb\[torch.randperm\(rays\_rgb.shape\[0\]\)\]
i\_batch = 0
target\_img = target\_img.reshape\(\[-1, 3\]\)
# 运行 TinyNeRF 的一次迭代,得到渲染后的 RGB 图像。
outputs = nerf\_forward\(rays\_o, rays\_d,
near, far, encode, model,
kwargs\_sample\_stratified=kwargs\_sample\_stratified,
n\_samples\_hierarchical=n\_samples\_hierarchical,
kwargs\_sample\_hierarchical=kwargs\_sample\_hierarchical,
fine\_model=fine\_model,
viewdirs\_encoding\_fn=encode\_viewdirs,
chunksize=chunksize\)
# 检查任何数字问题。
for k, v in outputs.items\(\):
if torch.isnan\(v\).any\(\):
print\(f"\! \[Numerical Alert\] \{k\} contains NaN."\)
if torch.isinf\(v\).any\(\):
print\(f"\! \[Numerical Alert\] \{k\} contains Inf."\)
# 反向传播
rgb\_predicted = outputs\['rgb\_map'\]
loss = torch.nn.functional.mse\_loss\(rgb\_predicted, target\_img\)
loss.backward\(\)
optimizer.step\(\)
optimizer.zero\_grad\(\)
psnr = -10. \* torch.log10\(loss\)
train\_psnrs.append\(psnr.item\(\)\)
# 以给定的显示速率评估测试值。
if i \% display\_rate == 0:
model.eval\(\)
height, width = testimg.shape\[:2\]
rays\_o, rays\_d = get\_rays\(height, width, focal, testpose\)
rays\_o = rays\_o.reshape\(\[-1, 3\]\)
rays\_d = rays\_d.reshape\(\[-1, 3\]\)
outputs = nerf\_forward\(rays\_o, rays\_d,
near, far, encode, model,
kwargs\_sample\_stratified=kwargs\_sample\_stratified,
n\_samples\_hierarchical=n\_samples\_hierarchical,
kwargs\_sample\_hierarchical=kwargs\_sample\_hierarchical,
fine\_model=fine\_model,
viewdirs\_encoding\_fn=encode\_viewdirs,
chunksize=chunksize\)
rgb\_predicted = outputs\['rgb\_map'\]
loss = torch.nn.functional.mse\_loss\(rgb\_predicted, testimg.reshape\(-1, 3\)\)
print\("Loss:", loss.item\(\)\)
val\_psnr = -10. \* torch.log10\(loss\)
val\_psnrs.append\(val\_psnr.item\(\)\)
iternums.append\(i\)
# 绘制输出示例
fig, ax = plt.subplots\(1, 4, figsize=\(24,4\), gridspec\_kw=\{'width\_ratios': \[1, 1, 1, 3\]\}\)
ax\[0\].imshow\(rgb\_predicted.reshape\(\[height, width, 3\]\).detach\(\).cpu\(\).numpy\(\)\)
ax\[0\].set\_title\(f'Iteration: \{i\}'\)
ax\[1\].imshow\(testimg.detach\(\).cpu\(\).numpy\(\)\)
ax\[1\].set\_title\(f'Target'\)
ax\[2\].plot\(range\(0, i + 1\), train\_psnrs, 'r'\)
ax\[2\].plot\(iternums, val\_psnrs, 'b'\)
ax\[2\].set\_title\('PSNR \(train=red, val=blue'\)
z\_vals\_strat = outputs\['z\_vals\_stratified'\].view\(\(-1, n\_samples\)\)
z\_sample\_strat = z\_vals\_strat\[z\_vals\_strat.shape\[0\] // 2\].detach\(\).cpu\(\).numpy\(\)
if 'z\_vals\_hierarchical' in outputs:
z\_vals\_hierarch = outputs\['z\_vals\_hierarchical'\].view\(\(-1, n\_samples\_hierarchical\)\)
z\_sample\_hierarch = z\_vals\_hierarch\[z\_vals\_hierarch.shape\[0\] // 2\].detach\(\).cpu\(\).numpy\(\)
else:
z\_sample\_hierarch = None
\_ = plot\_samples\(z\_sample\_strat, z\_sample\_hierarch, ax=ax\[3\]\)
ax\[3\].margins\(0\)
plt.show\(\)
# 检查 PSNR 是否存在问题,如果发现问题,则停止运行。
if i == warmup\_iters - 1:
if val\_psnr \< warmup\_min\_fitness:
print\(f'Val PSNR \{val\_psnr\} below warmup\_min\_fitness \{warmup\_min\_fitness\}. Stopping...'\)
return False, train\_psnrs, val\_psnrs
elif i \< warmup\_iters:
if warmup\_stopper is not None and warmup\_stopper\(i, psnr\):
print\(f'Train PSNR flatlined at \{psnr\} for \{warmup\_stopper.patience\} iters. Stopping...'\)
return False, train\_psnrs, val\_psnrs
return True, train\_psnrs, val\_psnrs最终的结果如下图所示:
▲图6|运行结果示意图
引用:
[1]https://www.matthewtancik.com/nerf
[2]http://cseweb.ucsd.edu/~viscomp/projects/LF/papers/ECCV20/nerf/tiny_nerf_data.npz
[3]https://towardsdatascience.com/its-nerf-from-nothing-build-a-vanilla-nerf-with-pytorch-7846e4c45666
[4]https://medium.com/@rparikshat1998/nerf-from-scratch-fe21c08b145d