一、相关实际问题
- 内核是如何管理内存的
- 如何查看内核使用的内存信息
- 服务器上一条ESTABLISH状态的空连接需要消耗多少内存
- 机器上出现了3万多个TIME_WAIT,内存开销会不会很大
二、Linux内核如何管理内存
内核针对自己的应用场景,使用了一种叫做SLAB/SLUB的内存管理机制。这种管理机制通过四个步骤把物理内存条管理起来,供内核申请和分配内核对象。
1)node划分
早期的计算机中,内存控制器还没有整合到CPU,所有的内存访问都需要经过北桥芯片组来完成,即内存控制器集成在北桥中。CPU访存需要通过前端总线连接到北桥芯片,然后北桥芯片连接到内存,这样的架构被称为UMA(一致性内存访问)。总线模型保证了所有的内存访问都是一致的(即每个处理器共享相同的内存地址空间)。在UMA架构下,CPU和内存之间的通信全部都要通过前端总线,而提高性能的方式就是不断提高CPU、前端总线和内存的工作频率。当前架构的变化,已经不用南北桥的架构了。现代架构使用高速总线(如PCI Express)和互连技术(如Intel的QuickPath Interconnect或AMD的Infinity Fabric)来替代南北桥的功能,提高数据传输效率。
而随着物理条件的限制,CPU朝着高频率的方向发展遇到了天花板,性能的提升开始供提高主频转向增加CPU数量(多核、多CPU)。**而越来越多的 CPU 对前端总线的争用,使前端总线成为了瓶颈。为了消除 UMA 架构的瓶颈,NUMA(非一致性内存访问)架构诞生了。**在NUMA架构下,**每个CPU会有自己的独立的内存控制器,并且独立连接到一部分内存(直连的这部分内存称为本地内存),组成一个node,不同node之间通过QPI(Quick Path Interconnect)进行通信访问远程内存。**如下图所示:

在 NUMA 架构下,内存的访问出现了本地和远程的区别:访问远程内存的延时会明显高于访问本地内存。
系统 boot 的时候,硬件会把 NUMA 信息发送给 os,如果系统支持 NUMA ,会发生以下几件事:
- 获取 NUMA 配置信息
- 将 processors(不是 cores) 分成很多 nodes,一般是一个 processor 一个 node。
- 将 processor 附近的 memory 分配给它。
- 计算node 间通信的cost(距离)。
Linux 识别到 NUMA 架构后,每个进程、线程都会继承一个 numa policy,定义了可以使用那些CPU(甚至是那些 core),哪些内存可以使用,以及 policy 的强制程度,即是优先还是强制性只允许。每个 thread 被分配到了一个”优先” 的 node 上面运行,thread 可以在其他地方运行(如果 policy 允许的话),但是 os 会尝试让他在优先地 node 上面去运行。默认的内存分配方案是:优先从本地分配内存。如果本地内存不足,优先淘汰本地内存中无用的内存。使内存页尽可能地和调用线程处在同一个 node。
只是优先从本地分配内存,进程同样可以访问到其他内存条。因为在计算机系统中,物理内存地址是由内存管理单元(Memory Management Unit,MMU)管理的,它会把CPU发出的地址请求转换为实际的物理内存地址。即使系统中有多个内存条(也就是说,有多个物理内存块),MMU也会把它们看作是一个连续的地址空间进行管理。
当系统启动时,BIOS或者UEFI会检测所有的硬件设备,包括内存条。每个内存条的大小和位置信息会被记录在一个叫做内存映射(Memory Map)的数据结构中。这个内存映射会被传递给操作系统。
在操作系统启动时,它会读取这个内存映射,然后建立起自己的物理内存管理数据结构,如页帧数组。操作系统会把每个物理内存页的地址和状态(比如是否被使用,被哪个进程使用)记录在struct page的一个实例中。页帧数组中的每个元素对应物理内存中的一个页,页帧数组的索引直接映射到物理内存地址。
在多个内存条的情况下,页帧数组会涵盖所有的内存条。即使内存条在物理上是分离的,但在页帧数组中它们看起来是连续的。当一个物理页面被分配给一个进程时,操作系统会在页表中创建一个页表项,将虚拟地址映射到这个物理页面的地址。
以上是硬件层面上的NUMA(hardware view),而作为软件层面的Linux,则对NUMA的概念进行了抽象。即便硬件上是一整块连续内存的UMA,Linux也可将其划分为若干的node(所有node其实是个软件上的概念)。同样,即便硬件上是物理内存不连续的NUMA,Linux也可将其视作UMA(software view)。
所以,在Linux系统中,你可以基于一个UMA的平台测试NUMA上的应用特性。从另一个角度,UMA就是只有一个node的特殊NUMA,所以两者可以统一用NUMA模型表示。
2)zone划分
NUMA模型中,物理内存被划分为几个节点(node),一个node对应一个内存簇bank,即每个内存簇认为是一个节点。
首先,内存被划分为结点,每个节点关联到系统中的一个处理器。接着各个节点又被划分为内存管理区域,一个管理区域通过struct zone_struct描述,其被定义为zone_t,用以表示内存的某个范围。主要分为以下几种类型的内存管理区域:
- ZONE_DMA:地址段最低的一块内存区域(物理内存起始的16M),供IO设备DMA访问。
- 一些使用 DMA 的外设并没有像 CPU 那样的 32 位地址总线,比如只有 16 位总线,就只能访问 64 KB 的空间,24 位总线就只能访问 16 MB 的空间,如果给 DMA 分配的内存地址超出了这个范围,设备就没法(寻址)访问了。也应该成为ZONE_DMA24
- ZONE_DMA32:到了 64 位系统,外设的寻址能力增强,因此又加入了一个 ZONE_DMA32,空间大小为 16MB 到 4GB
- ZONE_NORMAL:可直接映射到内核的普通内存域(16M-896M),在X86-64架构下,DMA和DMA32之外的内存全部在NORMAL的zone里管理
- ZONE_HIGHMEM:高端内存,内核不能直接使用(896M-4G),动态映射到内核空间3G+896M-4G的位置。即要访问的物理地址空间大于虚拟地址空间,不能直接建立映射的场景。适用于32位CPU系统,64位的CPU系统虚拟地址空间足够大,直接映射即可,所以都是NORMAL。
- 对于现在64位的系统。ZONE_HIGHMEM已经没有了,增加了ZONE_MOABLE区域。
32位系统内存映射图:

64位:大致如下:可能内核版本不同。有些划分有一点差别

每个zone下都包含了许许多多个Page(页面),在Linux下一个页面的大小一般是4KB(处理器架构决定的,操作系统编译的时候固定下来)。
可以使用zoneinfo命令查看机器上zone的划分,也可以看到每个zone下所管理的页面有多少。cat /proc/zoneinfo
3)基于伙伴系统管理空闲页面
伙伴系统中的伙伴指的是两个内存块、大小相同、地址连续,同属于一个大块区域
每个zone下面都有很多的页面,Linux使用伙伴系统对这些页面进行高效的管理。在内核中,表示zone的数据结构是struct zone。其下面的一个数组free_area管理了绝大部分可用的空闲页面。
#define MAX_ORDER 11
struct zone{
free_area free_area[MAX_ORDER];
......
}
free_area是一个包含11个元素的数组。每一个元素分别代表不同大小(4KB、8KB、16KB、32KB…)的空闲可分配的连续内存链表。
即每一个元素都代表一种大小的内存块,数组的索引表示了内存块包含的页框数量。例如,free_area[0]中存放的是单独的空闲页框(4KB),free_area[1]中存放的是包含两个页框的空闲内存块(8KB),等等。这种方式可以方便地查找和分配满足特定大小需求的内存块

每个free_area元素都有一个或多个链表:
- MIGRATE_UNMOVABLE:表示不可移动的pages,例如内核数据结构的pages。
- MIGRATE_RECLAIMABLE:表示可回收的pages,例如系统中的缓存,当内存紧张时可以回收其内存。
- MIGRATE_MOVABLE:表示可移动的pages,例如用户进程的pages。当需要大块连续的内存空间,或者进行内存碎片整理时,可以移动这类page。
- MIGRATE_PCPTYPES:表示特殊用途的pages,一般用于不可移动和可回收page的临时备份。
- MIGRATE_HIGHATOMIC:表示高优先级的分配请求,这种类型的page只有在内存非常紧张时才会被使用。
链表中的每一个元素都是一个空闲内存块。这些内存块在物理内存中是连续的,也就是说,它们包含的页框在物理内存中是紧邻的。这样,当内核需要分配一个连续的内存区域时,可以直接从这些链表中查找和分配。但要注意,虽然这些内存块在物理内存中是连续的,但在虚拟内存中可能并不连续。因为虚拟地址到物理地址的映射是通过页表完成的,不同的页框可以被映射到虚拟内存中的任意位置(不一定在相邻的页表项)。
free_area数组里的链表元素存储了一个叫struct page的结构体。struct page是内核用来描述物理内存页的主要数据结构。
每个物理页在内核中都有一个对应的struct page实例。这个结构体包含了许多用于页管理的字段,如用于链接空闲页的链表节点字段等。内核可以通过这个结构体找到对应的物理页。为了映射物理内存和struct page实例,Linux内核使用了一种叫做mem_map的数组。这个数组的每个元素都是一个struct page实例,整个数组的顺序与物理内存页的顺序相同。因此,内核可以通过简单的指针运算在物理地址和对应的struct page实例之间进行转换。
通过cat /proc/pagetypeinfo可以看到当前系统中伙伴系统各个尺寸的可用连续内存块数量。
内核提供分配器函数alloc_pages到上面的多个链表中寻找可用连续页面。
struct page * alloc_pages(gfp_t gfp_mask, unsigned int order)
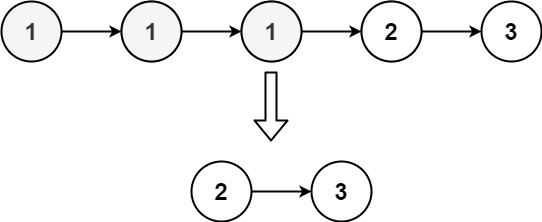
假如要申请8KB(连续两个页框的内存),**在基于伙伴系统的内存分配中,有可能需要将大块内存拆分成两个小伙伴。在释放中,可能会将两个小伙伴合并,在此组成更大块的连续内存。**具体的工作步骤:
- 先到free_area[1],即8KB的链表中查询
- 如果无可用,则到free_area[2],即16KB的链表中查询
- 如果找到了则将其拆分成两个小伙伴,使用掉其中一个
- 将另一个小伙伴放置到8KB的链表中
4、slab分配器
到目前介绍的内存分配都是以页面4KB为单位的。而内核代码经常需要在运行时分配和释放小块的内存区域。如果每次都使用普通的页分配器(即每次分配至少一个页的内存)来完成,可能会浪费大量内存。为了更高效地分配小块内存,内核在伙伴系统之上又引入了一个专用的内存分配器slab(或叫slub)
这个分配器最大的特点就是一个slab内只分配特定大小、甚至是特定的对象,当一个对象释放内存后,另一个同类对象可以直接使用这块内存。通过这样的方式极大地降低了碎片发生的概率。
在SLAB分配器中,当内核需要频繁创建和销毁某种类型的对象时(比如文件描述符、进程描述符等),它会创建一个kmem_cache,并根据需要的对象大小进行初始化。每个kmem_cache都包含一些预分配的内存块(SLABs),这些内存块的大小都与需要的对象大小相匹配。当内核代码需要分配一个新的对象时,可以直接从对应的kmem_cache中取出一个预先分配的内存块,而不需要每次都去进行页分配。同样,当一个对象被释放时,它的内存块可以被直接归还到kmem_cache中,以便再次使用。
struct kmem_cache {
struct kmem_cache_node **node;
......
}
struct kmem_cache_node {
struct list_head slabs_partial;
struct list_head slabs_full;
struct list_head slabs_free;
}
**一个kmem_cache可以有多个kmem_cache_node,每个kmem_cache_node代表该kmem_cache在一个特定的NUMA节点上的状态。**NUMA是一种针对多处理器系统的内存架构,其主要思想是将物理内存划分为多个节点,每个处理器可以直接访问所有的内存,但访问不同节点的内存的延迟和带宽可能会有所不同。因此,在NUMA系统中,内存的分配策略可能会影响到程序的性能。为了在NUMA系统中更高效地管理内存,Linux内核引入了kmem_cache_node。在每个kmem_cache中,每个NUMA节点都有一个对应的kmem_cache_node。这个kmem_cache_node包含了该节点上的空闲对象列表,以及其他一些与该节点相关的信息。当从kmem_cache中分配或释放对象时,内核会优先考虑当前CPU对应的NUMA节点,这样可以提高内存访问的性能。
每个kmem_cache_node中都有满、半满、空三个链表。每个链表节点都对应一个slab,一个slab由一个或多个内页也组成。
每一个slab内都保存的是同等大小的对象。
当cache中内存不够时,会调用基于伙伴系统的分配器请求整页连续内存的分配。

内核中会有很多个kmem_cache存在,它们是在Linux初始化或者是运行的过程中分配出来的。其中有的是通用的,有的是专用的。

从图中可以看到socket_alloc内核对象都存在TCP的专用kmem_cache中。通过查看/proc/slabinfo可以查看所有的kmem_cahce。
并不是所有的对象都会使用SLAB分配器进行分配。SLAB分配器是针对频繁分配和释放的小型对象设计的,比如内核中的各种数据结构(例如,文件描述符、信号量、进程描述符等)。对于这些对象,SLAB分配器可以显著提高分配效率,减少内存碎片,并提高缓存利用率。然而,对于大型对象(比如用户请求的大块内存),或者不常用的对象(即分配和释放不频繁的对象),直接使用页分配器(Page Allocator)或者伙伴系统(Buddy System)进行分配通常更为高效。页分配器可以处理任何大小的内存请求,但对于小型对象,可能会造成内存的浪费。
此外,用户空间的内存分配(例如,通过malloc()或者new进行的分配)通常不直接使用SLAB分配器。用户空间的内存分配通常由C库(例如,glibc)提供的内存分配器处理,这个分配器使用系统调用(例如,brk()或者mmap())从内核获取或释放内存。
Linux还提供了一个特别方便的命令slabtop来按照内存从大到小进行排列,可以用来分析slab内存开销。
此外slab管理器组件提供了若干接口函数方便使用:
- kmem_cache_create:创建一个基于slab的内核对象管理器。
- kmem_cache_alloc:快速为某个对象申请内存。
- kmem_cache_free:将对象占用的内存归还给slab分配器
5)小结
内核使用内存的方式:
- 把所有内存条和CPU换分成node
- 把每一个node划分成zone
- 每个zone下都用伙伴系统管理空闲页面
- 内核提供slab分配器为自己专用
前三步是基础模块,为应用程序分配内存时的请求调页组件页能够用到,但是第四步就是内核给自己专用的了。
三、TCP连接相关内核对象
TCP连接建立的过程中,每申请一个内核对象也都需要到相应的缓存里申请一块内存。
1)socket函数直接创建
int __sock_create(struct net *net, int family, ...)
{
struct socket *sock;
// 分配socket对象
sock = sock_alloc();
// 调用协议族的创建函数创建sock对象
err = pf->create(net, sock, protocol, kern);
}
1. sock_inode_cache对象申请
在sock_alloc函数中,申请了一个struct socket_alloc的内核对象。socket_alloc内核对象将socket和inode信息关联了起来。
struct socket_alloc {
struct socket socket;
struct inode vfs_inode;
}
在sock_alloc的实现逻辑中,最后就调用了kmem_cache_alloc从sock_inode_cache中申请了一个struct socket_alloc对象。
static struct inode *sock_alloc_inode(struct super_block *sb)
{
struct socket_alloc *ei;
struct socket_wq *wq;
ei = kmem_cache_alloc(sock_inode_cachep, GFP_KERNEL);
if(!ei)
return NULL;
wq = kmalloc(sizeof(*wq), GFP_KERNEL);
}
sock_inode_cache是专门用来存储struct socket_alloc的slab缓存,它是在init_inodecache中通过kmem_cache("sock_inode_cache", sizeof(struct socket_alloc), ...)初始化的。
另外还可以看到通过kmalloc申请了一个socket_wq,这是个用来记录在socket上等待事件的等待项。
2. tcp对象申请
对于IPv4来说,inet协议族对应的create函数是inet_create,因此__sock_create中对pf->create的调用会执行到inet_create中去。
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern)
{
......
// 这个answer_prot其实就是tcp_prot
answer_prot = answer->prot;
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot);
}
struct sock *sk_alloc(...)
{
sturct sock *sk;
sk = sk_prot_alloc(prot, priority | __GFP_ZERO, family);
}
static struct sock *sk_prot_alloc(struct proto *prot, ...)
{
slab = prot->slab;
if(slab != null) {
sk = kmem_cache_alloc(slab, priority & ~__GFP_ZERO);
}
在这个函数中,将会到TCP这个slab缓存中使用kmem_cache_alloc从slab中申请一个struct sock内核对象出来。TCP这个slab缓存是在协议栈初始化的时候在inet_init中使用kmem_cache_create(prot->name, prot->obj_size, ...)(这里prot是一个tcp_prot)初始化好的一个名为TCP、大小为sizeof(struct tcp_sock)的kmem_cache,并把它记到tcp_prot->slab的字段下。
struct proto tcp_prot = {
.name = "TCP",
......
.obj_size = sizeof(struct tcp_sock),
}
需要记住的是,在TCP slab缓存中实际存放的是struct tcp_sock对象,是struct sock的扩展,由于tcp_sock、inet_connection_sock、inet_sock、sock是逐层嵌套的关系,所以tcp_sock是可以当作sock来使用的。
3. dentry和flip对象申请
回到socket系统调用的入口处,除了sock_create以外,还调用了一个sock_map_fd
SYSCALL_DEFINE(socket, int, family, int, type, int, protocol)
{
sock_create(family, type, protocol, &sock);
sock_map_fd(sock, flags & (0_CLOEXEC | ONONBLOCK);
}
以此为入口将完成struct dentry的和struct file申请。
struct dentry {
......
struct dentry *d_parent;
struct qstr d_name;
struct inode *d_inode;
unsigned char d_iname[DNAME_INLINE_LEN];
......
}
内核初始化的时候创建好了一个dentry slab和flip slab缓存,所有的struct dentry对象和struct file对象都将由它们进行分配。
static int sock_map_fd(struct socket *sock, int flags)
{
struct file *newfile;
int fd = get_unused_fd_flags(flags);
......
// 1.申请dentry、file内核对象
newfile = sock_alloc_file(sock, flags, NULL);
if(likely(!IS_ERR(newfile))) {
// 2.关联到socket及进程
fd_install(fd, newfile);
return fd;
}
}
struct file *sock_alloc_file(struct socket *sock, int flags, const char *dname)
{
// 申请dentry
path.dentry = d_alloc_pseudo(sock_mnt->mnt_sb, &name);
// 申请flip
file = alloc_file(&path, FMOD_READ | FMODE_WRITE, &socket_file_ops);
......
}
**在sock_alloc_file中完成内核对象的申请,其中会去进行struct dentry和struct file两个内核对象的申请。**dentry对象的申请最终同样是是调用到了kmem_cache_alloc函数(对应的slab缓存dentry在内核初始化时的dcache_init中创建的),而file对象的申请最终是调用了kmem_cache_zalloc函数进行分配(对应的slab缓存flip是在内核初始化时的files_init中创建的)
kmem_cache_alloc()和kmem_cache_zalloc()都是用于从指定的kmem_cache中分配对象的函数。它们的主要区别在于,kmem_cache_zalloc()在分配内存后,会自动将内存区域初始化为0。
具体来说:
- kmem_cache_alloc():从指定的kmem_cache分配一个对象的内存空间。返回的内存空间中的内容是不确定的,也就是说,它可能包含任何数据。调用者需要自己对内存进行初始化。
- kmem_cache_zalloc():从指定的kmem_cache分配一个对象的内存空间,并自动将整个内存区域初始化为0。这意味着调用者可以直接使用返回的内存,无需再进行初始化。
在一些情况下,使用kmem_cache_zalloc()可能更方便,因为它可以确保内存区域的内容被初始化为0。然而,如果你知道你会立即覆盖整个内存区域的内容,那么使用kmem_cache_alloc()可能会更高效,因为它避免了不必要的内存初始化。
4. 小结
调用链:
- SYSCALL_DEFINE3
- sock_create
- __sock_create
- sock_alloc => => sock_alloc_inode:申请socket_alloc和socket_wq
- inet_create
- sk_alloc => sk_prot_alloc:申请tcp_sock
- __sock_create
- sock_map_fd
- sock_alloc_file
- d_alloc_pseudo => __d_alloc:申请dentry
- alloc_file => get_empty_flip:申请file
- sock_alloc_file
- sock_create
socket系统调用完毕之后,在内核中就申请了配套的一组内核对象。这些内核对象并不是鼓励地存在,而是互相保留着和其他内存对象的关联关系。

所有网络相关的操作,包括数据接收和发送等都以这些数据结构为基础来进行的。
2)服务端socket创建
除了直接创建socket意外,服务端还可以通过accept函数在接受连接请求时完成相关内核对象的创建。
SYSCALL_DEFINE(accept4, int, fd, struct sockaddr __user *, upeerp_sockaddr, int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
// 根据fd查找到监听的socket
sock = sockfd_lookup_light(...);
// 申请并初始化新的socket
newsock = sock_alloc();
newsock->type = sock->type;
newsock->ops = sock->ops;
// 申请新的file对象,并设置到新的socket上
newfile = sock_alloc_file(newsock, ...);
// 接受连接
err = sock->ops->accept(sock, newsock, sock->file->f_flags);
// 将新文件添加到当前进程的打开文件列表
fd_install(newfd, newfile);
}
可以看到socket_alloc、file、dentry对象的分配都是相同的方式,唯一的区别是tcp_sock对象是在第三次握手的时候创建的,所以这里在接收连接的时候直接从全连接队列拿出request_sock的sock成员就可以了,无需再单独申请。
四、问题解答
1、内核是如何管理内存的:内核采用SLAB的方式来管理内存,总共分为四部
- 把所有的内存条和CPU进行分组,组成node
- 把每一个node划分成多个zone
- 每个zone下都用伙伴系统来管理空闲页面
- 提供slab分配器来管理各种内核对象
- 前三步时基础模块,为应用程序分配内存时的请求调页组件也能够用到,而第四步是内核专用的。每个slab缓存都是用来存储固定大小,甚至是特定的一种内核对象。这样当一个对象释放内存后,另一个同类对象可以直接使用这块内存,几乎没有任何碎片。极大地提高了分配效率,同时降低了碎片率。
2、如何查看内核使用的内存信息
- 通过/proc/slabinfo可以看到所有的kmem_cache。
- 更方便的是slatop命令,它从大到小按照占用内存进行排列。
3、服务器上一条ESTABLISH状态的空连接需要消耗多少内存:假设连接上绝大部分时间都是空闲的,也就是假设没有发送缓存区和接收缓存区的开销,那么一个socket大约需要如下几个内核对象
- struct socket_alloc:大约0.62KB, slab缓存名是sock_inode_cache
- struct tcp_sock:大约1.94KB,slab缓存名是tcp
- struct dentry:大约0.19KB,slab缓存名是dentry
- struct file:大约为0.25KB,slab缓存名是flip
- 加上slab多少会存在一点碎片无法使用,这组内核对象的大小大约是3.3KB左右。所以即使一万条连接也只需要占用33MB的内存
- 至于CPU开销,没有数据包的接收和处理是不需要消耗CPU的。长连接上在没有数据传输的情况下,只有极少量的保护包传输,CPU开销可以忽略不计
4、机器上出现了3万多个TIME_WAIT,内存开销会不会很大
- 从内存的角度来考虑,一条TIME_WAIT状态的连接仅仅是0.4KB左右的内存而已
- 从端口的角度来考虑,占用的端口只是针对特定服务器来说是占用了,只要下次连接的服务端不一样(IP或者端口不一样),那么这个端口仍然可以用来发起TCP连接
- 只有在连接同一个server的时候端口占用才能算得上是问题。如果想解决这个问题可以考虑使用tcp_max_tw_buckets来限制TIME_WAIT连接总数,或者打开tcp_tw_recycle、tcp_tw_reuse来快速回收端口,或者干脆使用长连接代替频繁的短连接。