Java 中的 Map 集合及其子类详解:HashMap 和 TreeMap
在 Java 编程中,Map 是一种用于存储键值对的集合结构。Java 提供了多种 Map 实现类,其中最常用的是 HashMap 和 TreeMap。
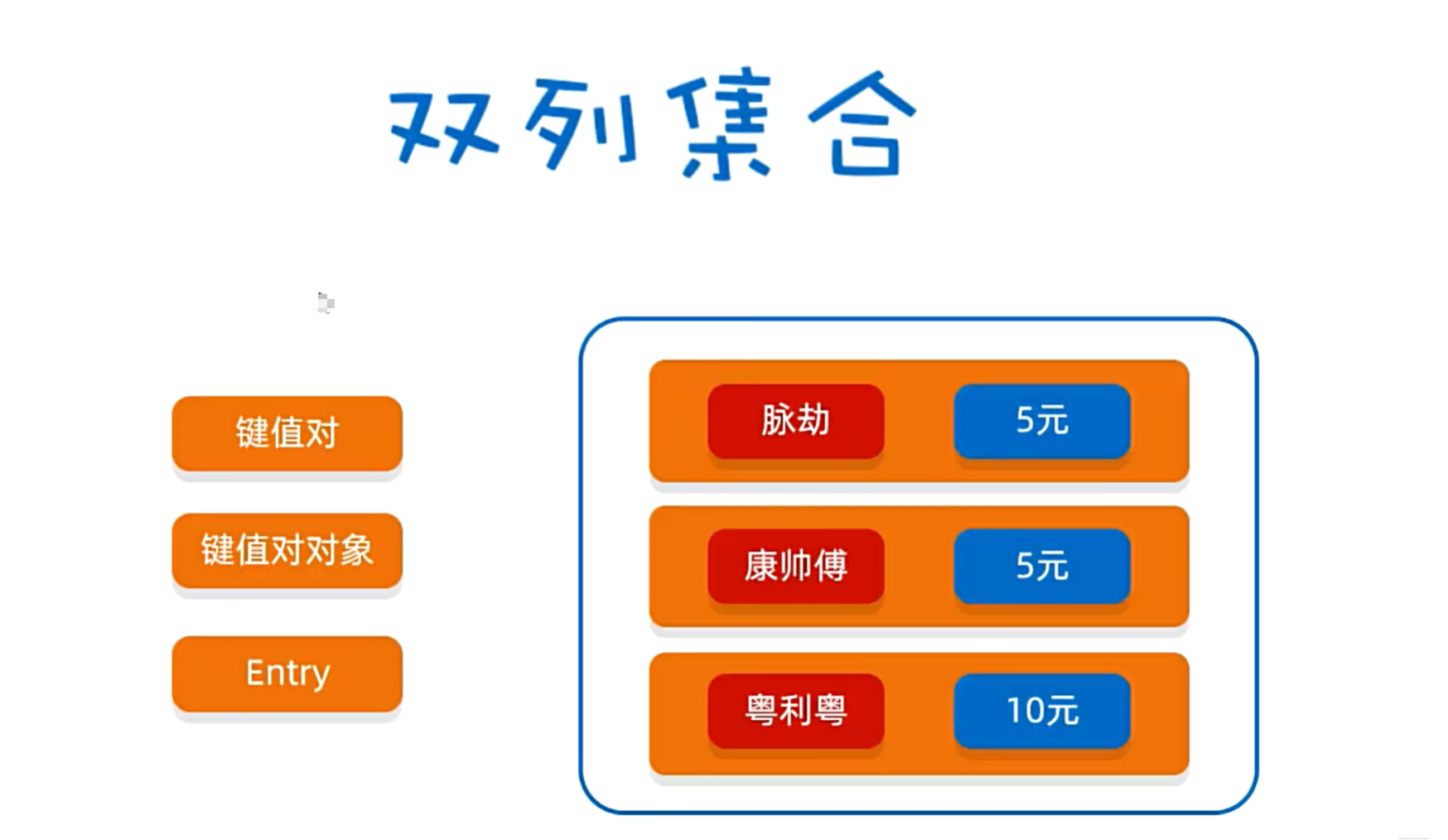
双列集合
在Java中,双列集合(也称为映射集合或字典)主要由Map接口及其实现类(如HashMap和TreeMap)构成。双列集合的特点是通过键(Key)来唯一标识对应的值(Value),形成键值对的关系。

1. 定义和特性
双列集合的核心特性如下:
- 键唯一性:每个键在集合中都是唯一的,不能重复。
- 值可以重复:不同的键可以对应相同的值。
- 高效查找:通过键查找值的时间复杂度通常为O(1)(在
HashMap中)。
2. 主要实现类
- HashMap:基于哈希表实现的
Map接口,允许null键和null值,查找速度快,适合大多数情况。 - TreeMap:基于红黑树实现的
Map接口,按键的自然顺序或指定的比较器排序,不允许null键,查找速度较慢但有序。
3. 基本操作
以下是Map接口的一些常用方法:
| 方法名称 | 说明 |
|---|---|
V put(K key, V value) | 添加元素 |
V remove(Object key) | 根据键删除键值对元素 |
void clear() | 移除所有的键值对元素 |
boolean containsKey(Object key) | 判断集合是否包含指定的键 |
boolean containsValue(Object value) | 判断集合是否包含指定的值 |
boolean isEmpty() | 判断集合是否为空 |
int size() | 集合的长度,即中键值对的个数 |
4. 应用场景
双列集合广泛应用于需要快速查找和存储关系的数据场景,例如:
- 统计词频:使用单词作为键,出现次数作为值。
- 缓存系统:存储数据和其对应的过期时间。
- 配置参数:键为配置名,值为配置的具体内容。
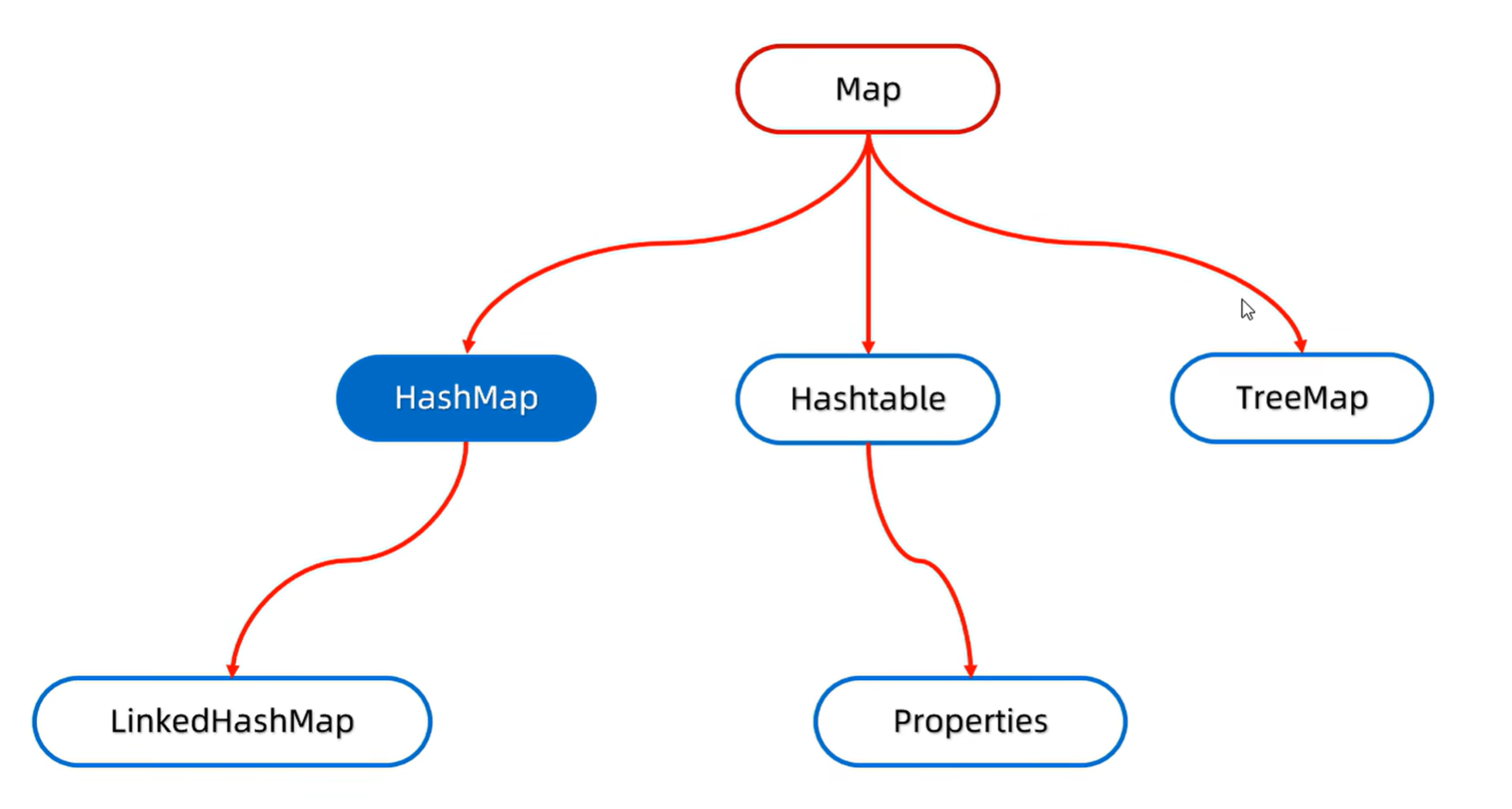
1. Map 集合概述
1.1 Map 的基本概念
Map 是一个接口,表示存储键值对的数据结构。键的唯一性保证了查找、插入、删除的效率,值可以重复。常见的实现类有 HashMap 和 TreeMap。
interface Map<K,V> // K: 键类型, V: 值类型

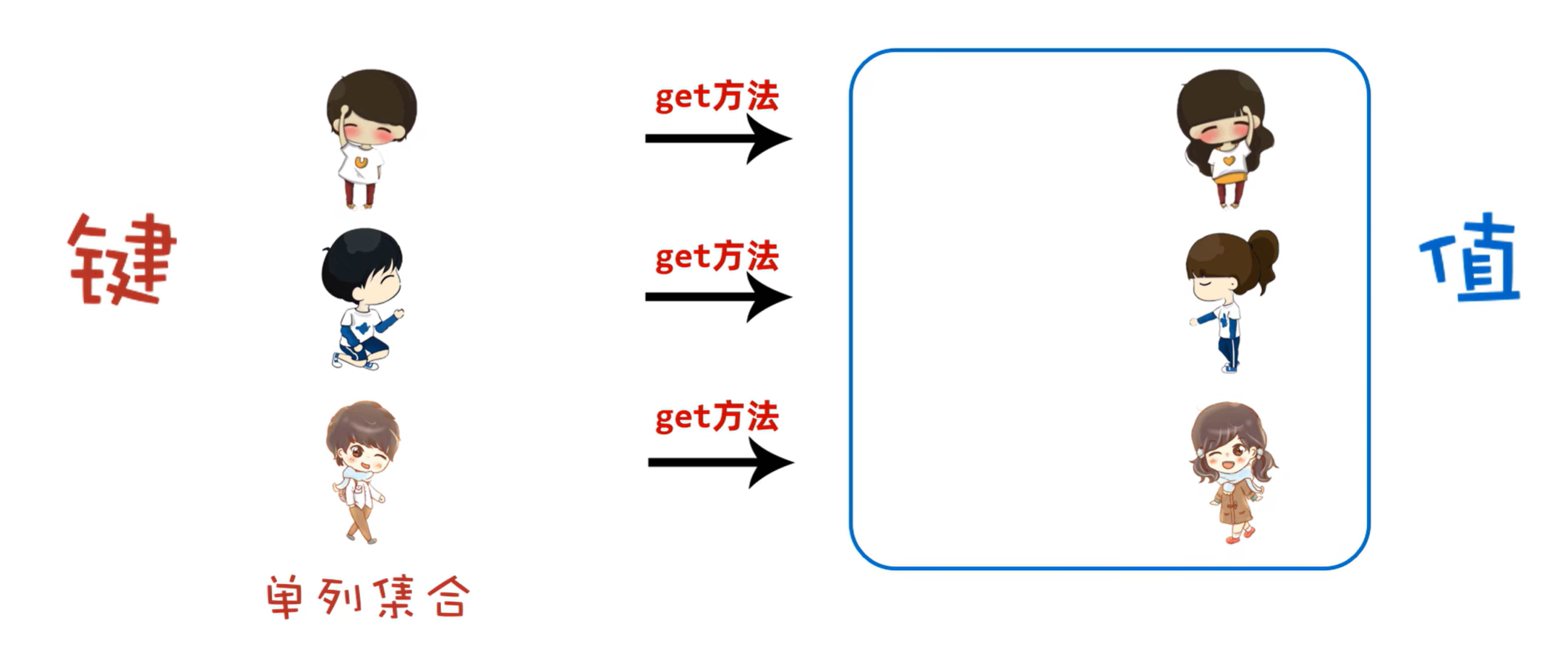
1.2 Map接口的特性
- 键值对存储:每个元素由一个键和一个值组成,键用于索引,值是与键相关的数据。
- 键唯一性:
Map中每个键都是唯一的,不能有重复键。如果使用相同的键插入新值,则原有值将被替换。 - 无序性:
Map的元素通常是无序的,尤其是HashMap和LinkedHashMap。某些实现(如TreeMap)会根据键的自然顺序或指定的比较器进行排序。 - 允许空值:大多数
Map实现允许一个null键和多个null值。
1.3 Map集合的三种遍历方式
在Java中,Map集合的遍历可以通过多种方式进行,每种方式都有其特点和适用场景。以下是对Map集合的三种主要遍历方式的详细介绍。
1. 使用 keySet() 方法遍历
keySet() 方法返回一个包含所有键的集合,我们可以通过这个集合来遍历 Map 中的每一个键,并根据键获取相应的值。
示例代码:
import java.util.HashMap;
import java.util.Map;
public class KeySetTraversal {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("Apple", 1);
map.put("Banana", 2);
map.put("Orange", 3);
// 使用 keySet() 遍历
for (String key : map.keySet()) {
Integer value = map.get(key);
System.out.println("Key: " + key + ", Value: " + value);
}
}
}
2. 使用 entrySet() 方法遍历
entrySet() 方法返回一个包含所有键值对的集合,可以通过 Map.Entry 接口来同时获取键和值。这种方式更加高效,因为可以避免通过 get() 方法访问值。
示例代码:
import java.util.HashMap;
import java.util.Map;
public class EntrySetTraversal {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("Apple", 1);
map.put("Banana", 2);
map.put("Orange", 3);
// 使用 entrySet() 遍历
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("Key: " + key + ", Value: " + value);
}
}
}
3. 使用 Java 8 的 forEach 方法
Java 8引入的 forEach 方法可以用来遍历 Map,这是一个非常方便和简洁的方式,尤其适合于流式编程。
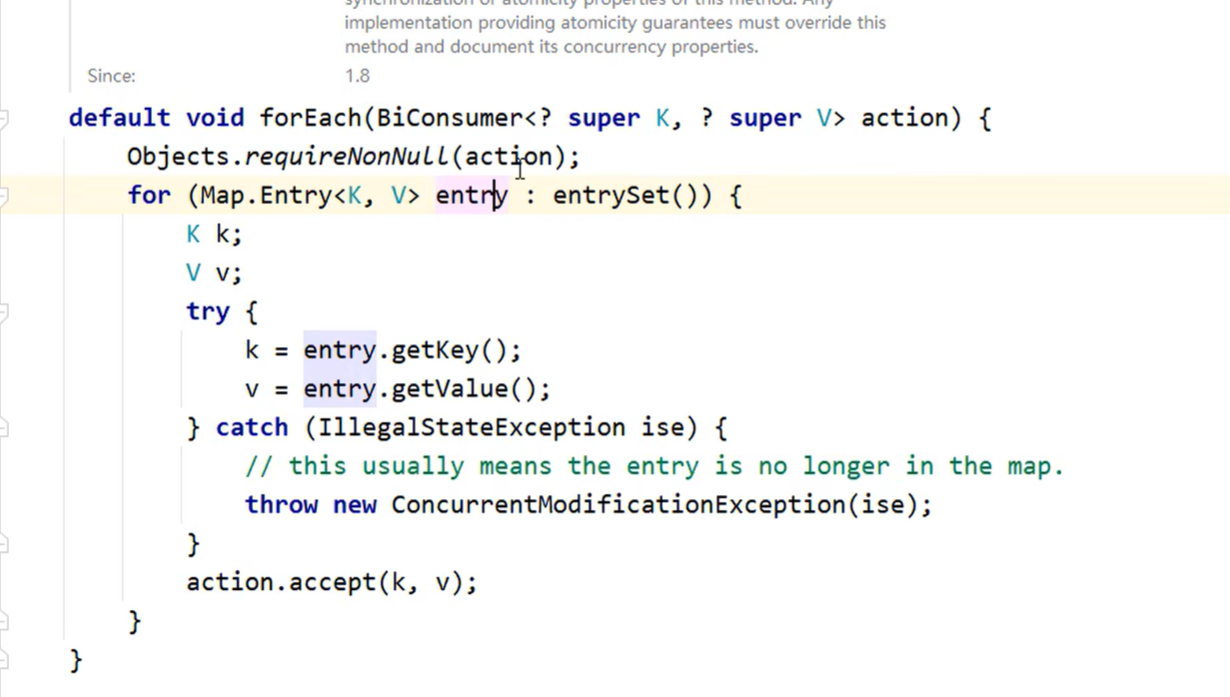
示例代码:
import java.util.HashMap;
import java.util.Map;
public class ForEachTraversal {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("Apple", 1);
map.put("Banana", 2);
map.put("Orange", 3);
// 使用 forEach() 遍历
map.forEach((key, value) -> {
System.out.println("Key: " + key + ", Value: " + value);
});
}
}
2. HashMap
2.1 概述
HashMap是Map接口的一个重要实现类,基于哈希表(Hash Table)实现。它提供了快速的查找、插入和删除操作,是在单线程环境中使用的理想选择。

2.2 特性
- 存储结构:使用数组和链表(或红黑树)相结合来存储键值对。
- 时间复杂度:在平均情况下,
HashMap的插入、删除和查找操作的时间复杂度为O(1)。 - 不保证顺序:
HashMap不保证元素的顺序,因此在遍历时,返回的顺序可能与插入顺序不同。 - 允许null键和null值:
HashMap可以有一个null键和多个null值。
2.3 线程安全
HashMap 不是线程安全的,多个线程并发访问时可能导致数据不一致。可以使用 Collections.synchronizedMap() 方法来创建一个线程安全的 HashMap,或者使用 ConcurrentHashMap 来替代它。
2.4 使用场景
适合于频繁插入、删除操作且对元素顺序没有要求的场景。常见的使用场景包括缓存、数据库结果集的处理等。
2.5 性能
在适当的负载因子下,HashMap 的性能非常优秀,但在高并发情况下可能会出现性能下降的问题,因为它在扩容时会影响所有线程的性能。
2.6 底层原理
- HashMap底层是哈希表结构的
- 依赖nashCode方法和equals方法保证键的唯一
- 如果键存储的是自定义对象,需要重写hashCode:和equals方法,如果值存储自定义对象,不需要重写hashCode和equals方法

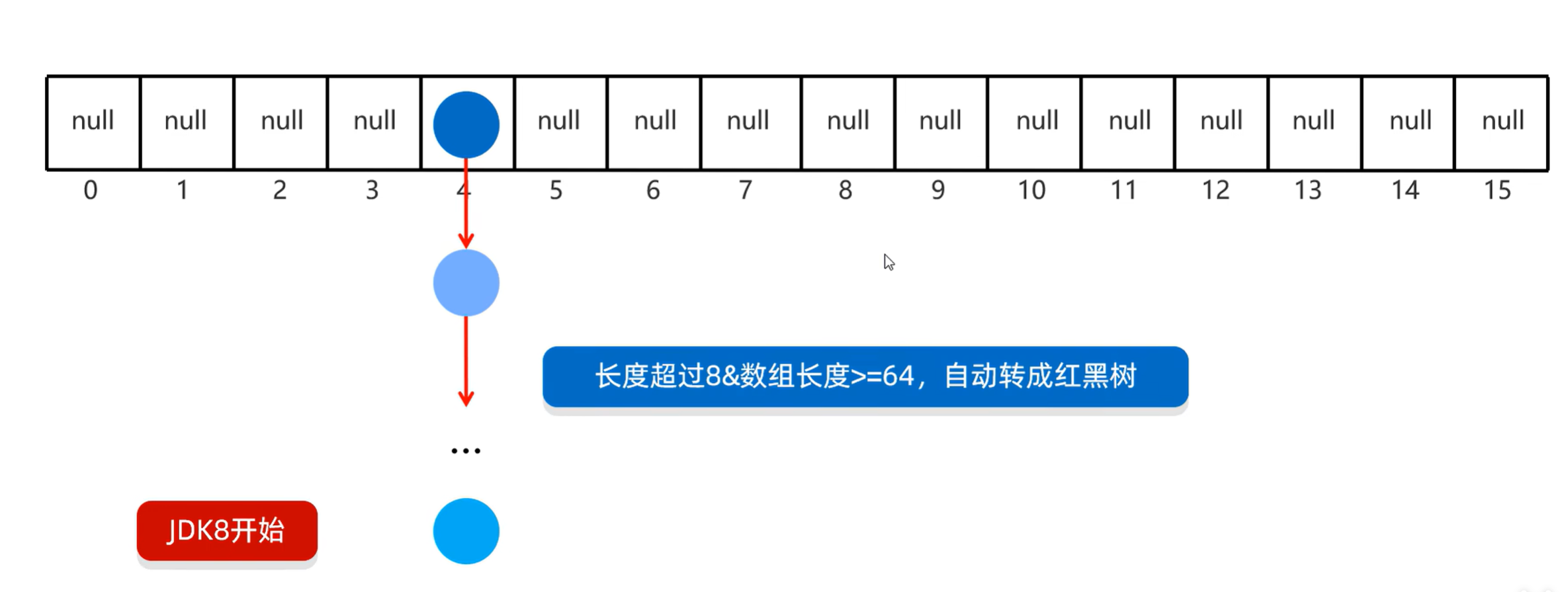
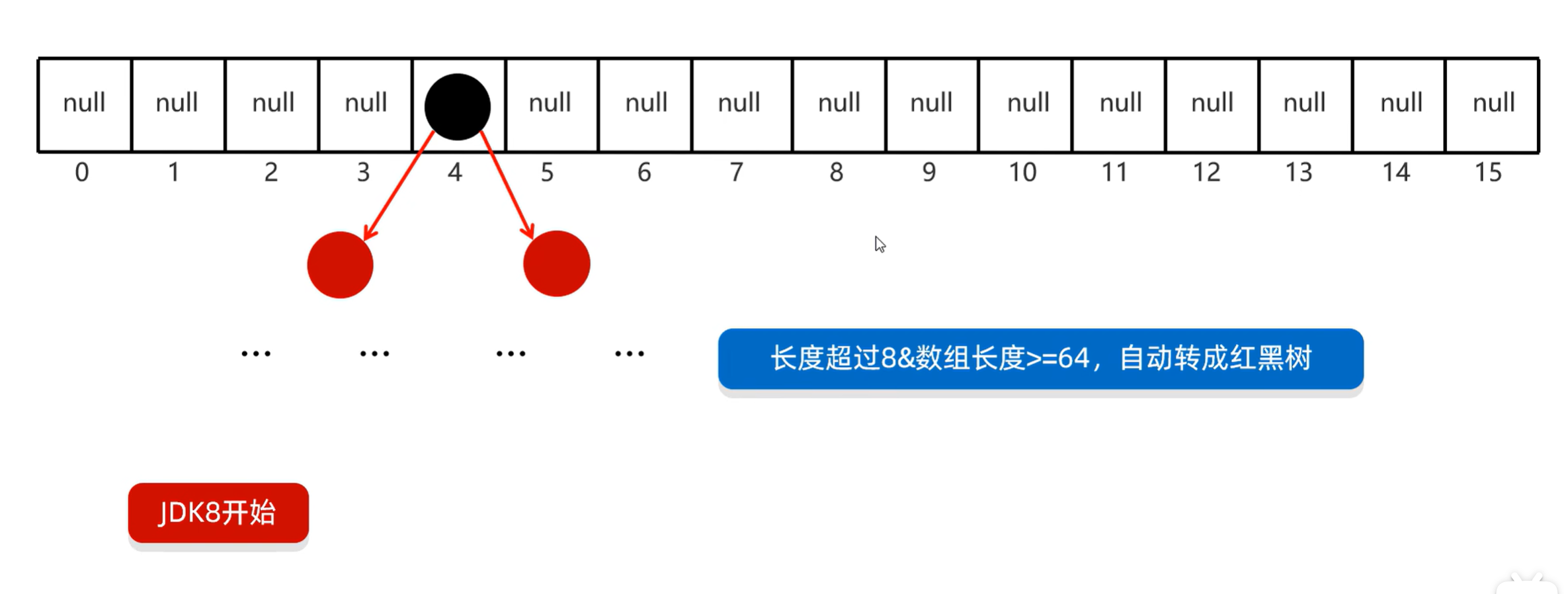
2.6 示例代码
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("苹果", 10);
map.put("香蕉", 20);
map.put("橘子", 30);
System.out.println("香蕉的数量: " + map.get("香蕉"));
map.remove("苹果");
System.out.println("水果数量: " + map.size());
}
}
注意事项
- 并发问题:
HashMap在多线程环境中不安全,如果多个线程同时访问一个HashMap并至少一个线程在结构上进行修改,必须使用ConcurrentHashMap替代。 - 负载因子:可以在创建
HashMap时指定初始容量和负载因子,以优化性能。例如,HashMap<String, Integer> map = new HashMap<>(16, 0.75f);。
3. LinkedHashMap
3.1 概述
LinkedHashMap是HashMap的子类,具有HashMap的特性,同时维护元素的插入顺序。它在插入时使用双向链表来保持顺序。

3.2 特性
- 存储结构:使用哈希表和双向链表来存储键值对。
- 时间复杂度:与
HashMap相同,插入、删除和查找的平均时间复杂度为O(1)。 - 保持插入顺序:遍历
LinkedHashMap时,返回的顺序是根据元素的插入顺序。 - 允许null键和null值:与
HashMap相同,可以有一个null键和多个null值。
3.3 线程安全
LinkedHashMap 也不是线程安全的,可以使用 Collections.synchronizedMap() 或 ConcurrentHashMap 来确保线程安全。
3.4 使用场景
适合需要保持插入顺序的场景,如实现最近最少使用(LRU)缓存、保持插入顺序的结果集等。
3.5 示例代码
import java.util.LinkedHashMap;
public class LinkedHashMapExample {
public static void main(String[] args) {
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
map.put("苹果", 10);
map.put("香蕉", 20);
map.put("橘子", 30);
for (String key : map.keySet()) {
System.out.println(key + ": " + map.get(key));
}
}
}
4. TreeMap
4.1 概述
TreeMap是基于红黑树实现的Map接口的一个实现类,提供了有序的键值对存储。
4.2 特性
- 存储结构:使用红黑树存储键值对,保证键的有序性。
- 时间复杂度:插入、删除和查找的时间复杂度为O(log n)。
- 自然顺序或自定义顺序:可以根据键的自然顺序(Comparable)或指定的比较器(Comparator)进行排序。
- 不允许null键:
TreeMap不允许null键,但允许多个null值。
4.3 线程安全
TreeMap 也不是线程安全的,建议在多线程环境中使用 ConcurrentSkipListMap 或通过 Collections.synchronizedMap() 来实现线程安全。
4.4 使用场景
适合需要按键排序的场景,如实现有序字典、范围查找等。
4.5 示例代码
import java.util.TreeMap;
public class TreeMapExample {
public static void main(String[] args) {
TreeMap<String, Integer> map = new TreeMap<>();
map.put("苹果", 10);
map.put("香蕉", 20);
map.put("橘子", 30);
for (String key : map.keySet()) {
System.out.println(key + ": " + map.get(key));
}
}
}
5. 线程安全问题的综合比较
| 特性 | HashMap | LinkedHashMap | TreeMap |
|---|---|---|---|
| 线程安全 | 否 | 否 | 否 |
| 插入顺序 | 无序 | 有序 | 有序 |
| 查找复杂度 | O(1) | O(1) | O(log n) |
| 可存储空值 | 是 | 是 | 否(键不能为null) |
6. 选择合适的Map实现类
选择适当的 Map 实现类,取决于具体需求:
- 若需要快速的查找性能且不关心元素顺序,选择
HashMap。 - 若需要保持元素插入顺序,选择
LinkedHashMap。 - 若需要按键的自然顺序或自定义顺序访问元素,选择
TreeMap。
在多线程环境下,考虑使用 ConcurrentHashMap、ConcurrentSkipListMap,或者在每个 Map 访问上加锁,以确保线程安全。
7. 总结
在Java中,Map接口提供了强大的功能用于存储和操作键值对数据。HashMap、LinkedHashMap和TreeMap各自具有不同的特性和适用场景:
HashMap:快速存取,无序,适合性能要求高的场景。LinkedHashMap:保持插入顺序,适合需要顺序访问的场景。TreeMap:有序存储,适合需要排序和范围查询的场景。
访问元素,选择TreeMap。
在多线程环境下,考虑使用 ConcurrentHashMap、ConcurrentSkipListMap,或者在每个 Map 访问上加锁,以确保线程安全。
7. 总结
在Java中,Map接口提供了强大的功能用于存储和操作键值对数据。HashMap、LinkedHashMap和TreeMap各自具有不同的特性和适用场景:
HashMap:快速存取,无序,适合性能要求高的场景。LinkedHashMap:保持插入顺序,适合需要顺序访问的场景。TreeMap:有序存储,适合需要排序和范围查询的场景。