Mybatis-plus-扩展功能
一:代码生成器
AutoGenerator 是 MyBatis-Plus 的代码生成器,通过 AutoGenerator 可以快速生成 Entity、Mapper、Mapper XML、Service、Controller 等各个模块的代码,极大的提升了开发效率。
功能的演示:
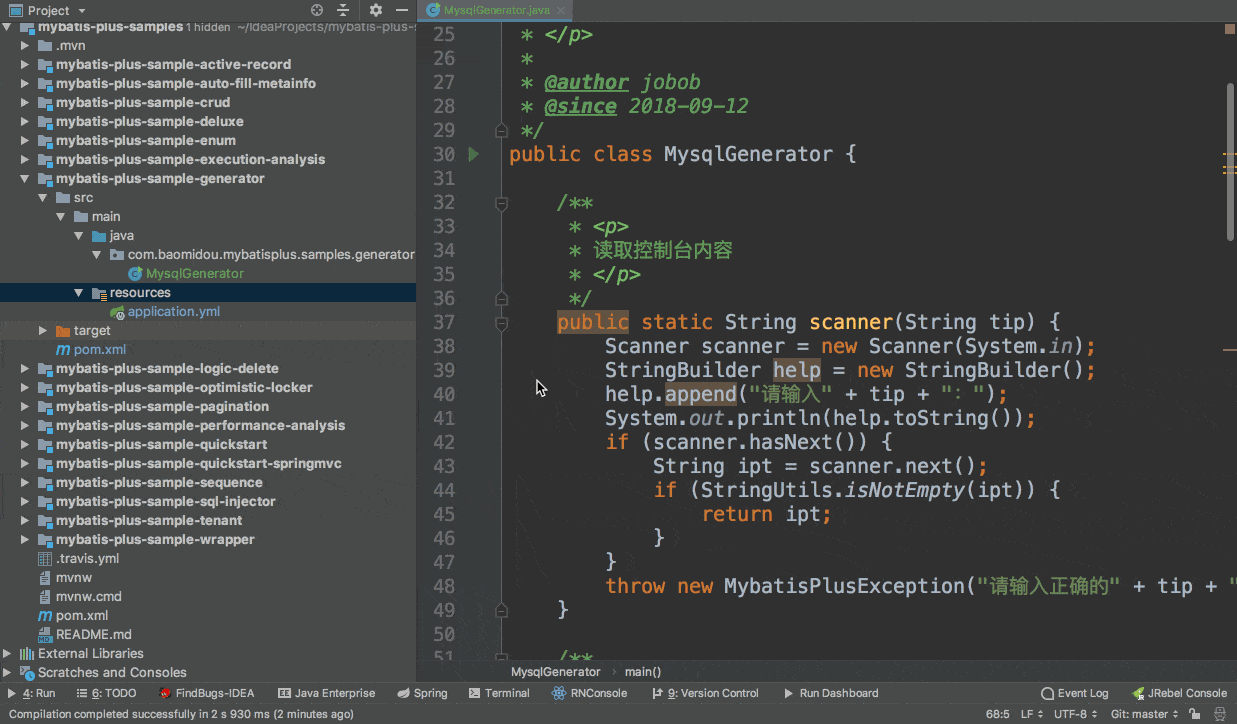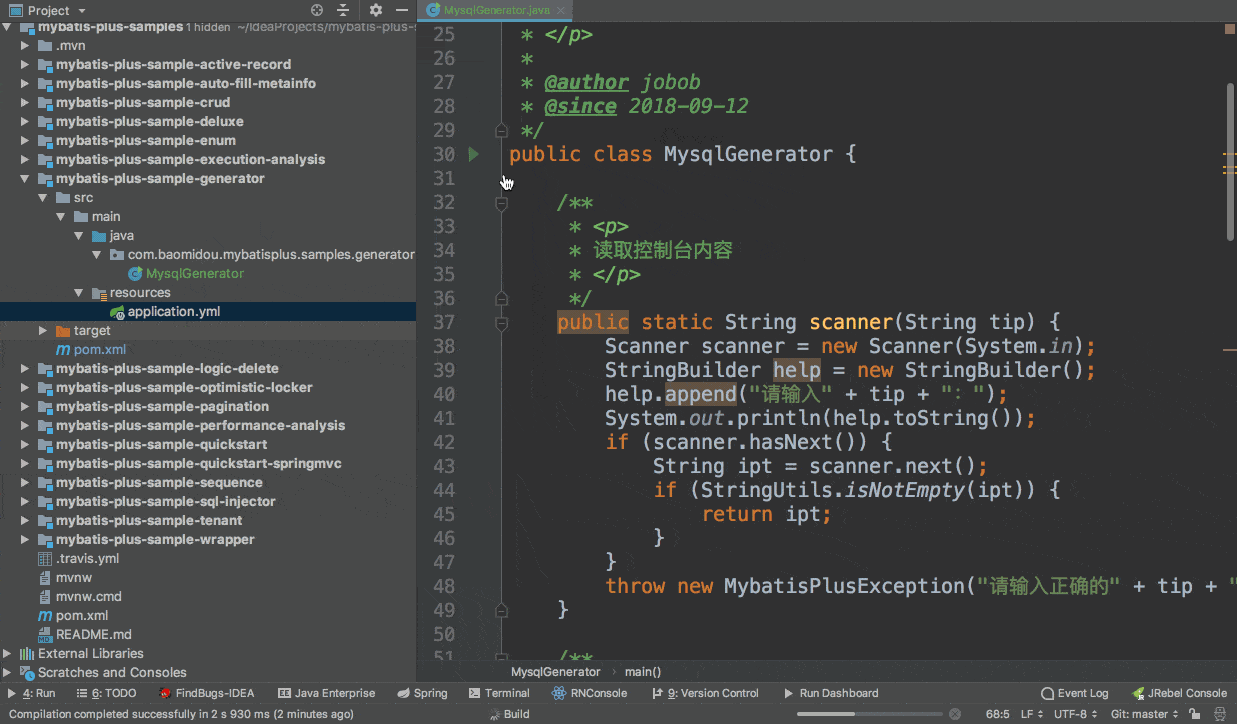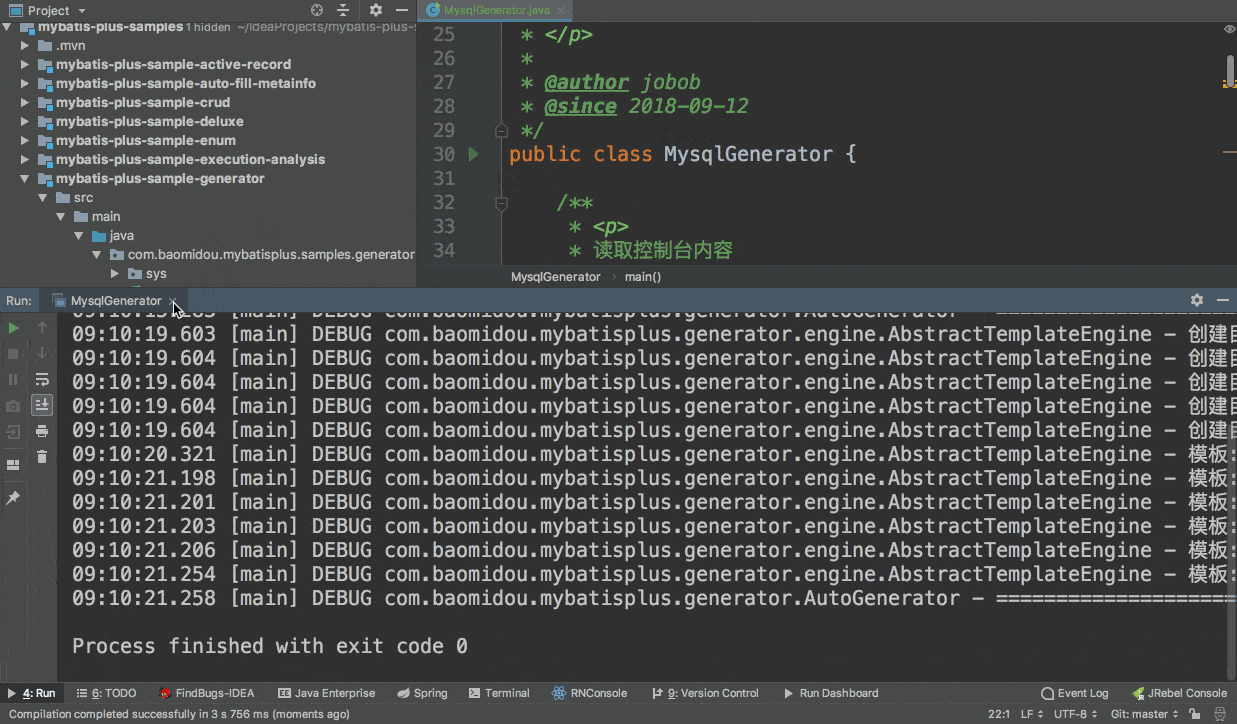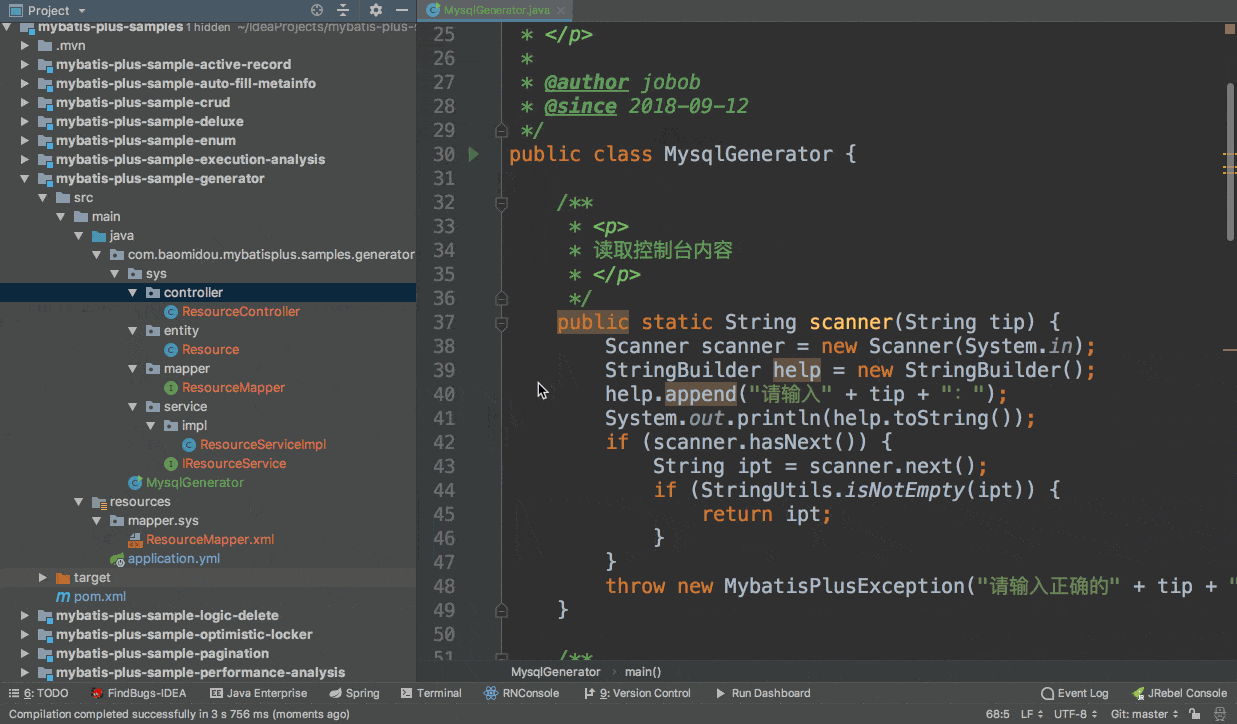
我们安装这个mybatisplus插件:

安装成功后会在idea上方多出来一个其他的菜单选项:

我们选上面那个是连接数据库:

下面就是代码生成器:



这样填好直接生成就行了;
二:静态工具

案例:

在我们查询用户id时是在userservice中,如果我们还要去查询用户的所有地址呢,我们就要去注入addressservice,我们在查询地址的时候如果要查询用户信息又要注入userservice,这样就会造成循环依赖,我们就可以使用Db静态工具来指定要查询的类的字节码就行:
@Override
public UserVO queryandAddress(Long id) {
User user = userMapper.selectById(id);
UserVO userVO = BeanUtil.copyProperties(user, UserVO.class);
List<Address> list = Db.lambdaQuery(Address.class)
.eq(Address::getUserId, id)
.list();
if (CollUtil.isEmpty(list)){
List<AddressVO> addressVOS = BeanUtil.copyToList(list, AddressVO.class);
userVO.setAddressVOS(addressVOS);
}
return userVO;
}
我们这里使用的Db静态类的lambda查询,指定类,就会去查询指定类对应的数据库表,然后就是和之前一样设置条件,最后表明要返回的类型是list;
然后我们要将address集合转成addressvo的集合就需要使用BeanUtil的copyToList方法,可以使用CollUtil的isEmpty判断集合是否为空;
第二个功能:
@Override
public List<UserVO> querysandAddress(List<Long> ids) {
List<User> users = listByIds(ids);
if (CollUtil.isEmpty(users)){
return Collections.emptyList();
}
List<UserVO> userVOS = BeanUtil.copyToList(users, UserVO.class);
//将用户的id获取从列表中获取出来变成一个用户id的集合
List<Long> userIds = users.stream().map(User::getId).collect(Collectors.toList());
List<Address> list = Db.lambdaQuery(Address.class)
.in(Address::getUserId, userIds)
.list();
List<AddressVO> addressVOS = BeanUtil.copyToList(list, AddressVO.class);
//将集合中的元素根据属性值的不同进行分组,得到的是一个map,map的键是分组的不同属性值,map的值是每个组的集合
Map<Long, List<AddressVO>> map=new HashMap<>();
if (CollUtil.isEmpty(addressVOS)){
map = addressVOS.stream().
collect(Collectors.groupingBy(AddressVO::getUserId));
}
for (UserVO userVO : userVOS) {
userVO.setAddressVOS(map.get(userVO.getId()));
}
return userVOS;
}
代码解释:首先直接使用service中继承的方法listbyIds,传入一个id集合,获取的是用户集合,然后我们判断这个集合是否为空,为空就直接返回空集合:conllections.emptylist;然后我们直接将user这个集合拷贝成vo集合,然后因为我们传入的用户id有的存在,有点可能不存在,但是我们获取的user集合中的id都是存在的,所以我们就去将user集合中的每个user的id属性抽取出来单独称为一个集合:List userIds = users.stream().map(User::getId).collect(Collectors.toList());通过stream流来将其抽取出来,然后我们在根据这个获取的用户id去查询地址,然而我们并没有注入,我们直接使用db静态方法,使用方法lambdaQuery来进行处理,因为是集合我们不能使用eq所以我们使用in,然后获取到的是一个集合,我们直接将集合拷贝成vo集合,然后因为我们之后要为每个uservo设置一个地址集合,而我们获取的地址集合是所有的user的,所以我们要进行分组,我们可以使用stream流的方式进行分组: map = addressVOS.stream().
collect(Collectors.groupingBy(AddressVO::getUserId));这里groupby就是以什么为标准进行分组,获得一个map,map的键就是分组的依据,这里就是userid,map的值就是每个用户对应的地址集合;然后我们遍历uservo,将地址赋值给uservo就行了;
三:逻辑删除

比如我们在购物的时候,删除订单,订单的数据并没有被删除,而是被逻辑删除了;

配置了逻辑删除对应的字段名之后,之前的sql语句的执行都会去根据逻辑删除的字段去执行,比如删除就变成了把字段名的值改变一下,查询只会查询没有被逻辑删除的;

四:枚举处理器

在我们定义状态时通常会用数字来表示不同的状态,这样的话我们编写起来很不方便,所以我们引入了枚举类,直接将原来的状态的类型改为枚举的类型,然而我们数据库的类型还是数字的类型,那么我们就需要枚举处理器了,将枚举类中表示值的属性加上注解:


先定义一个枚举类;
package com.itheima.mp.enums;
import com.baomidou.mybatisplus.annotation.EnumValue;
import lombok.Getter;
@Getter
public enum UserStatus {
NORMAL(1, "正常"),
FREEZE(2, "冻结")
;
private final int value;
private final String desc;
UserStatus(int value, String desc) {
this.value = value;
this.desc = desc;
}
}
然后加上注解:
@EnumValue
private final int value;
private final String desc;
最后加上配置:
configuration:
default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler
然后如果我们想要返回给前端的值不是枚举的名字,我们就需要加上jsonvalue注解:
五:json类型处理器

就是我们将一些值存入数据库中时,数据库中的值是json的,我们之前都是使用字符串传的,当然这样json格式的我们一般使用对象,而我们使用对象的话,存入数据库中时又需要将对象转成json格式的,比较麻烦,我们可以配置json处理器,这样我们就可以将我们java中的对象转成json格式的字符串;
@TableField(typeHandler = JacksonTypeHandler.class)
private UserInfo info;
@TableName(autoResultMap = true)
public class User {
进行这两个配置:一个在属性上加上json处理器,一个在类名上加上自动转换注解;
六:分页插件
1:基本实现方式
使用分页插件的步骤:
1:首先是配置分页插件:
@Configuration
public class MybatisConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
// 初始化核心插件
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 添加分页插件
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
定义一个配置类,里面声明一个bean,bean里初始化一个拦截器,相当于在使用mp的时候就会检查有没有配置这些插件,首先初始化核心插件,然后再去添加分页插件;
2:然后就能使用分页插件的相关api进行分页操作了
@Test
void testPageQuery() {
Page<User> page = Page.of(1, 10);
page.addOrder(new OrderItem("balance",true));//新版:page.addOrder(OrderItem.desc("balance"));
Page<User> p = iUserService.page(page);
List<User> records = p.getRecords();
System.out.println(records);
System.out.println(p.getTotal());
}
这里pageof设置分页参数,然后addorder是添加排序条件,true是升序,false是降序
然后就可以调用service中的page方法传入page对象,就获得了分页查询的结果,然后就能通过方法来获取结果
2:通用分页实体

定义一个实体类,专门设置一个pagequery来接收分页查询的条件:
@Data
@ApiModel(description = "分页查询实体")
public class PageQuery {
@ApiModelProperty("页码")
private Long pageNo;
@ApiModelProperty("页码")
private Long pageSize;
@ApiModelProperty("排序字段")
private String sortBy;
@ApiModelProperty("是否升序")
private Boolean isAsc;
}
然后我们可以在一些实体类的请求实体类中继承pagequery,这样就能用请求实体类做分页查询的请求实体类:
@Data
@ApiModel(description = "用户查询条件实体")
public class UserQuery extends PageQuery {
@ApiModelProperty("用户名关键字")
private String name;
@ApiModelProperty("用户状态:1-正常,2-冻结")
private Integer status;
@ApiModelProperty("余额最小值")
private Integer minBalance;
@ApiModelProperty("余额最大值")
private Integer maxBalance;
}
再定义一个DTO来接收分页查询的返回值:
package com.itheima.mp.domain.dto;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.util.List;
@Data
@ApiModel(description = "分页结果")
public class PageDTO<T> {
@ApiModelProperty("总条数")
private Long total;
@ApiModelProperty("总页数")
private Long pages;
@ApiModelProperty("集合")
private List<T> list;
}
使用泛型来表示可以接受不同类型的分页结果;
service中的实现:
@Override
public PageDTO<User> pageSelect(UserQuery userQuery) {
Page<User> page = Page.of(userQuery.getPageNo(), userQuery.getPageSize());
page.addOrder(new OrderItem(userQuery.getSortBy(), userQuery.getIsAsc()));
Page<User> page1 = lambdaQuery()
.like(userQuery.getName() != null, User::getUsername, userQuery.getName())
.eq(userQuery.getStatus() != null, User::getStatus, userQuery.getStatus())
.page(page);
return new PageDTO<User>(page1.getTotal(),page1.getPages(),page1.getRecords());
}

我们将分页条件封装成page对象的代码逻辑有点冗余,可以单独提出来,这样更加通用;
然后我们将page结果转成pageDTO也是,可以提出封装起来;
public <T> Page<T> toMpPage(OrderItem... items) {
Page<T> page = Page.of(pageNo, pageSize);
if (StrUtil.isNotBlank(sortBy)) {
page.addOrder(new OrderItem(sortBy, isAsc));
} else if (items != null) {
page.addOrder(items);
}
return page;
}
封装page结果返回,接受的是默认排序的参数,可变参数:。。。;
T> Page toMpPage(OrderItem… items) {
Page page = Page.of(pageNo, pageSize);
if (StrUtil.isNotBlank(sortBy)) {
page.addOrder(new OrderItem(sortBy, isAsc));
} else if (items != null) {
page.addOrder(items);
}
return page;
}
> 封装page结果返回,接受的是默认排序的参数,可变参数:。。。;