目录
- Introduction
- 分类:
- 静态负采样策略
- 动态负采样策略
- 对抗负采样策略
- 重要性重加权策略
- 知识增强负采样策略
- 多种推荐场景的负采样
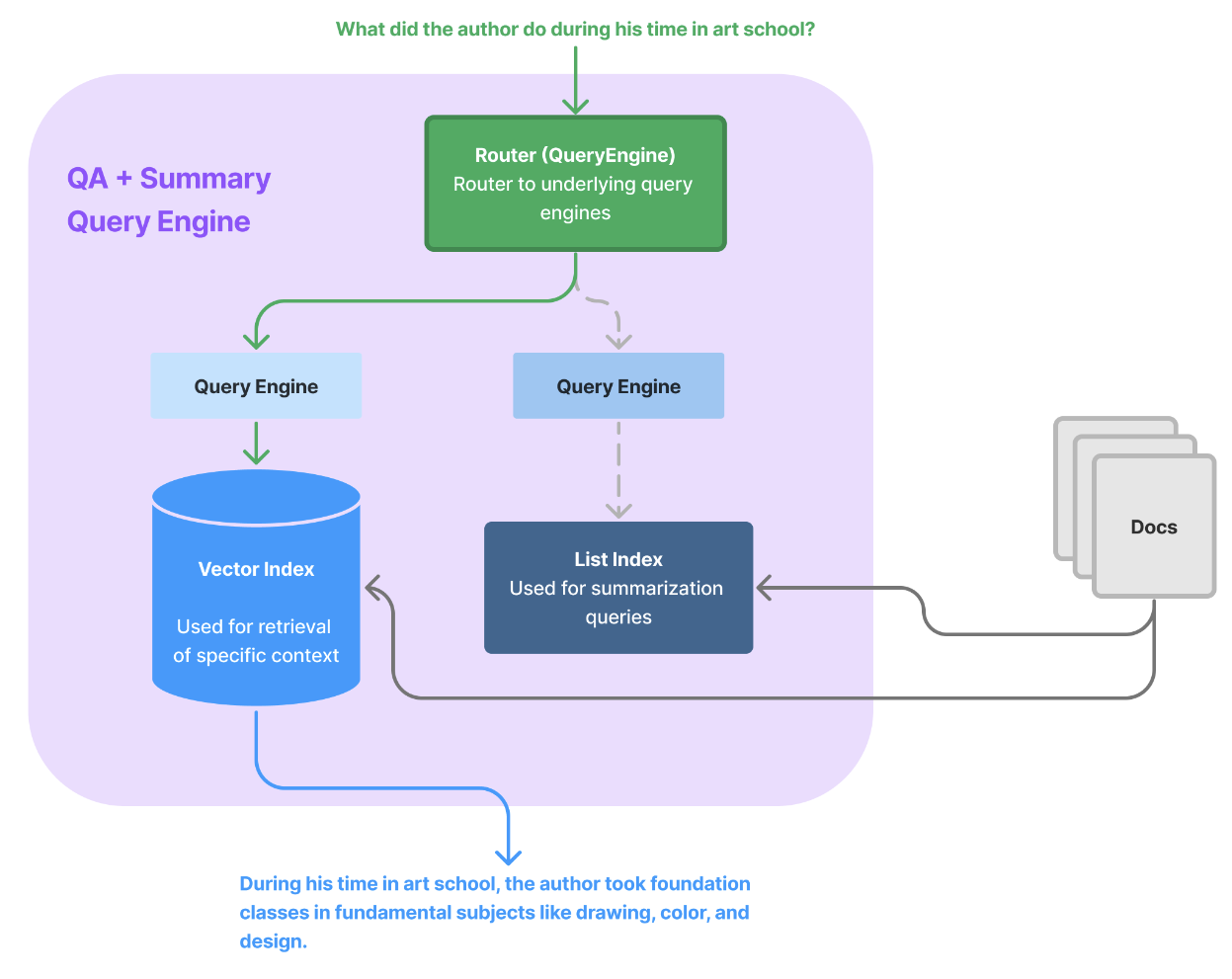
Introduction
传统的推荐算法通常关注用户的正面历史行为,而忽视了负面反馈在理解用户兴趣中的重要作用。负面采样是推荐系统中一个有前景但容易被忽视的领域,它在揭示用户行为中固有的真正负面方面发挥着关键作用。负面采样的必要性和挑战(Necessity and Challenges of Negative Sampling)。推荐系统需要处理数百万用户和item,这使得将所有数据纳入训练过程变得不切实际。用户的动态偏好和信息茧房现象限制了用户与item的互动,导致数据稀疏问题。
负面采样是推荐系统中的一个关键元素,它可以从用户未观察到的item中选择样本,以增强模型的优化。


分类:
- 静态负采样策略,其通常以静态概率采样负样本;
- 动态负采样策略,其尝试根据预先建立的采样标准动态选择负样本;
- 对抗负样本生成策略,其利用对抗学习范式来采样或生成看似合理的item作为负样本;
- 重要性重加权策略,其旨在识别每个样本的重要性,并以数据驱动的方式为它们分配不同的权重;
- 知识增强负采样策略,其专注于通过挖掘辅助知识中的隐含关联来采样负样本

静态负采样策略
-
均匀静态负采样(Uniform SNS):这种方法随机从用户未交互的item中选择负面样本。它是最简单且应用最广泛的静态负采样方法,因其简单易部署且时间效率高而被广泛使用。
-
基于流行度的静态负采样(Popularity-based SNS):这种方法选择负面样本时考虑item的流行度,即更受欢迎的item更有可能被选为负面样本。这种方法通过频次或度来反映样本的流行度,并据此进行采样。
-
预定义静态负采样(Predefined SNS):这种方法在数据集中预先定义了负面样本,这些样本是基于用户的实际行为(如跳过、点击、订购行为)来确定的。
-
非采样静态负采样(Non-sampling SNS):这种方法不进行负面采样,而是直接使用整个训练数据集中用户未观察到的项作为负面样本,以避免负面采样的敏感性问题。
这些静态负采样策略的关键在于如何根据负样本的分布来设置采样策略,通常涉及对不同样本设置不同的权重,以反映它们在数据集中的分布情况。静态负采样策略不涉及合成新的负样本,而是在学习负样本分布的基础上进行采样,使得每个样本被采样为负样本的概率在训练过程中保持不变。这些方法在不同的应用场景和数据集上有不同的表现和适用性。

动态负采样策略
- 通用动态负采样(Universal DNS):这种方法选择与用户正样本表示(或用户表示)更相关的item作为负样本。例如,一些先驱的动态负采样策略会从随机选择的item候选中选择最难的item作为负样本。这种方法旨在通过选择与当前模型状态更相关的负样本来提高模型的准确性和效率。
- 用户相似性动态负采样(User-similarity DNS):这种方法基于用户的历史行为来识别相似用户,然后根据这种相似性关联动态选择item作为负样本。它可以捕捉动态用户兴趣,并近似用户的有条件偏好状态。
- 知识感知动态负采样(Knowledge-aware DNS):这种方法动态捕捉与正面样本相关的信息丰富的样本,并选择与正面样本相关的信息item作为负样本。这些策略旨在整合特定任务的信息,以智能选择更相关和信息丰富的负面样本。
- 基于分布的动态负采样(Distribution-based DNS):这种方法分析数据集中正面和负面样本的分布模式,然后动态选择不会过度干扰训练阶段的信息丰富的负面样本。这种方法通过分析数据的固有分布来关注真实的负面样本,但增加了对空间复杂度的依赖。
- 插值动态负采样(Interpolation DNS):这种方法通过插值技术合成信息丰富的负面样本,通过注入正面样本的信息。这种方法旨在在保持信息知识的同时避免对特征空间分布的过度干扰,允许推荐系统适应变化的需求并优化正面和负面样本之间的平衡。
- 混合动态负采样(Mixed DNS):这种方法结合了多种动态负采样策略,以生成更多样化和有效的负面样本候选者。通过整合统一的负面样本和上述动态负采样策略,现有的混合负采样策略提供了一个灵活的框架,允许推荐系统根据特定任务定制不同动态负采样策略的组合,并尝试克服这些限制,实现更全面和稳健的负采样过程。
这些动态负采样策略的共同目标是提高推荐系统的性能,通过选择与用户偏好更相关的负面样本来优化模型的训练过程。每种策略都有其特定的应用场景和优势,研究者可以根据具体的推荐任务和数据特性选择合适的负采样策略。在这些方法中,通用动态负采样作为一种易于部署和通用的方法脱颖而出。然而,它依赖于用户-item匹配分数,这对准确性构成了挑战。用户相似性动态负采样优先识别用户相似性关联并捕捉用户行为相似性,同时面临用户关联依赖的挑战,尤其是对于新用户。知识感知动态负采样强调具有与正面样本相似属性的样本,以捕捉它们的内容相关性,引入了对知识的额外依赖。基于分布的动态负采样分析数据集中的固有分布,专注于真正的负面样本,但增加了对空间复杂性的依赖。插值动态负采样通过注入正面信息平衡正面和负面样本,但面临过度平滑问题,忽略了关键样本。混合动态负采样通过结合多种策略表现出显著的灵活性,但复杂的超参数调整和大量的计算成本为这些策略带来了新的挑战。

对抗负采样策略
- 生成性对抗负采样(Generative Adversarial Negative Sampling, GAN-based Sampling):这类方法通过生成对抗网络(GAN)来生成负样本。在这种设置中,生成器(Generator)尝试产生能够迷惑判别器(Discriminator)的负样本,而判别器则尝试区分正样本和由生成器产生的负样本。这种方法可以产生更多样化和信息丰富的负样本,从而提高模型的泛化能力。例如,文章中提到的PURE和GANRec就是这类方法的代表。
- 采样性对抗负采样(Sampled Adversarial Negative Sampling):这类方法不是生成新的负样本,而是从现有的候选集中采样出可能的负样本。这些样本被选中是因为它们与正样本在某些方面相似,但并不完全相同,这样可以提供更具有挑战性的负样本,促使模型学习更精细的区分能力。例如,IPGAN就是这种方法的一个例子。

重要性重加权策略
- 基于注意力的重加权(Attention-based IRW):这种策略通过注意力机制为每个样本分配不同的重要性权重。它可以根据用户的兴趣关注点灵活调整权重,使得模型能够更加关注与用户偏好更相关的样本。例如,在处理用户生成的文本评论时,可以通过注意力网络识别出评论中的关键部分,并给予这些部分更高的权重,从而提高推荐系统的准确性和个性化程度。
- 基于知识的重加权(Knowledge-based IRW):这种策略利用外部结构化知识来识别项目的重要性,并在模型优化中分配相应的权重。例如,可以利用用户的社会网络信息或项目的内容特征来确定样本的权重。这种方法特别适合处理冷启动问题,因为它可以利用额外的知识源来弥补缺乏用户历史行为数据的情况。
- 去偏重加权(Debiased IRW):这种策略旨在识别和纠正推荐系统中普遍存在的偏差(如流行度偏差、曝光偏差),并给予那些在过去被忽视的项目更高的权重,以提供更公平和多样化的推荐。例如,通过识别不同类别项目在推荐结果中的代表性不足,可以调整这些项目的权重,使得推荐系统能够更加均衡地展示各类项目。
这些重加权策略的共同目标是提高推荐系统的性能,通过为不同的样本分配适当的权重来平衡训练数据的分布,从而提高模型的准确性和鲁棒性。通过这种方式,推荐系统能够更好地理解和预测用户的偏好,提供更符合用户期望的推荐结果。

知识增强负采样策略
-
通用知识增强负采样(General Knowledge-enhanced Negative Sampling):这类方法通过利用用户和item的**辅助信息(例如用户的社交背景、item的异构知识)**来选择负样本。这些信息可以帮助模型更好地理解用户偏好和物品特性,从而选择更相关的负样本。例如,可以利用用户评分、浏览历史、购买行为等数据来增强负采样过程,使其能够捕捉到用户的真实不喜欢或不感兴趣的东西。这种方法不依赖于特定的知识图谱结构,而是广泛地利用各种可用的辅助信息来提高负采样的质量。
-
基于知识图谱的负采样(KG-based Negative Sampling):这类方法专门利用知识图谱中的结构化信息来选择负样本。知识图谱提供了实体(如用户、item)之间的关系,这些关系可以被用来识别和选择高质量的负样本。例如,KGPolicy模型就是一个利用知识图谱的辅助信息和强化学习方法来寻找高质量负样本的模型。KGPolicy通过设计的探索操作,从用户项正例探索,选择两个顺序邻居(例如,一个KG实体和一个item)访问,这样的两跳路径可以捕捉到知识感知负例。这种方法有效地学习了用多跳探索路径得到高质量的负例,并在抽样有效性和知识条目使用方面展现了优势 。
这两种策略都旨在通过引入额外的知识来提高负采样的质量,从而提高推荐系统的性能。通用知识增强负采样更注重利用各种辅助信息,而基于知识图谱的负采样则专注于利用知识图谱中的结构化信息。通过这些方法,可以更准确地模拟用户的真实偏好,提高推荐系统的效果和准确性。

多种推荐场景的负采样
- 协同过滤推荐(Collaborative Filtering Recommendation):这是推荐系统中最常见的场景之一,它基于用户的历史行为和相似用户的行为来推荐项目。在负采样中,这通常涉及到从用户未交互的项目中选择负样本。
- 图推荐(Graph-based Recommendation):在这个场景中,推荐系统利用用户和项目之间的图结构信息来进行推荐。负采样策略可能会考虑图结构信息,以选择与用户正样本更相关的负样本。
- 序列推荐(Sequential Recommendation):序列推荐关注用户随时间变化的行为序列,例如用户观看视频的顺序。负采样在这个场景中可能涉及到选择那些不太可能出现在用户序列中的项目作为负样本。
- 多模态推荐(Multi-modal Recommendation):多模态推荐系统处理包含多种类型数据(如文本、图像、音频)的项目。负采样策略需要能够处理和理解这些不同模态的数据,以选择相关的负样本。
- 多行为推荐(Multi-behavior Recommendation):在这个场景中,推荐系统需要考虑用户对项目的多种行为(如点击、购买、评分)。负采样策略需要能够区分这些不同的行为,并选择能够代表用户不喜欢的项目的负样本。
- 跨域推荐(Cross-domain Recommendation):跨域推荐系统旨在将一个领域的知识迁移到另一个领域,以解决新领域中的冷启动问题。负采样在这个场景中可能涉及到选择能够代表新领域用户不喜欢的项目的负样本。
这些场景涵盖了推荐系统的多种应用,从传统的协同过滤到更复杂的多模态和跨域推荐,展示了推荐系统在不同领域的广泛适用性和重要性。负采样在这些场景中扮演着关键角色,帮助模型更好地学习和预测用户的偏好。