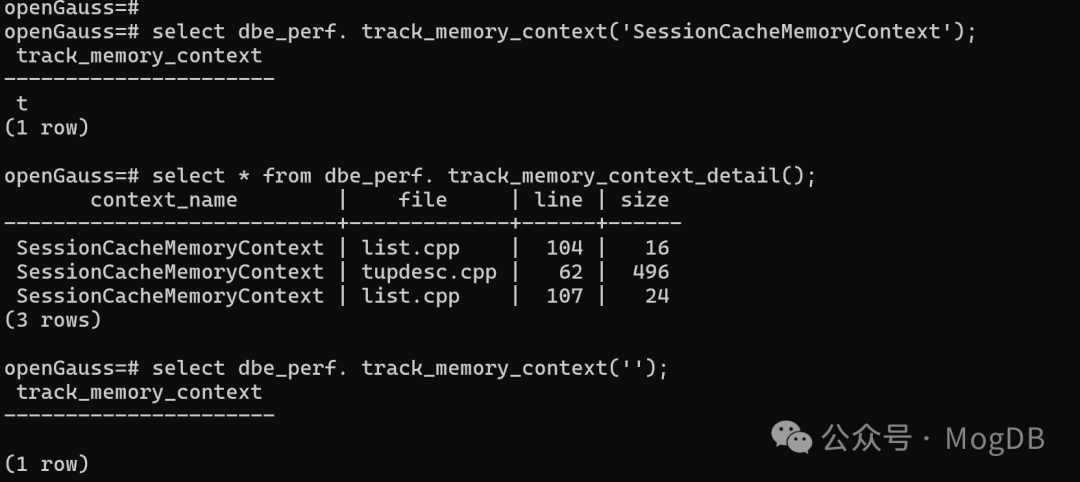
两种代码模式
核心代码模式
核心代码模式:就是给你一个函数框架,你需要实现函数逻辑,这种模式一般称之为。
目前大部分刷题平台和技术面试/笔试场景都是核心代码模式。
比如力扣第一题两数之和,就是给出 twoSum 函数的框架如下,然后要求给出具体实现
class Solution
// 即后台会自动输入数组 nums 和目标值 target,你需要实现算法逻辑,最后计算返回一个数组。
public int[] twoSum(int[] nums, int target) {
}
}
ACM 模式
简单来说,ACM 模式就是预先不提供函数框架,代码提交到后台后,系统会把每个测试用例(字符串)用标准输入传给你的程序,然后对比你程序的标准输出和预期输出是否相同,以此判断你的代码是否正确。
对于 ACM 模式,一个技巧就是要对代码分层,把对字符串输入的处理逻辑和真正的算法逻辑分开,类似这样:
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 主要负责接收处理输入的数据,构建输入的用例
int[] nums;
int target;
int N = scanner.nextInt();
...
// 调用算法逻辑进行求解
System.out.println(twoSum(nums, target));
}
public static int[] twoSum(int[] nums, int target) {
// 转化为核心代码模式,在这里写算法逻辑
}
}
常见错误
- 编译错误(Compile Error)
- 代码无法通过编译,这种错误一般是语法错误,比如拼写错误、缺少分号等。一般网页上手搓代码容易出现这种错误
- 运行错误(Runtime Error)
- 代码可以编译通过,但是在运行时出现了数组越界、空指针异常等错误。这种错误一般是由于边界条件处理不当,你需要留意边界条件、特殊测试用例(也叫做 Corner case,比如输入为空等情况)。
- 答案错误(Wrong Answer)
- 代码可以编译通过,也可以运行,但是某些测试用返回的结果和正确答案不一致。这种错误一般是因为你的算法有问题,需要你根据出错的用例反思,甚至可能整个思路都错了,需要你推倒重来。
- 超时(Time Limit Exceeded,常简称为 TLE)
- 力扣预定义的测试用例中,越靠后的用例数据规模就越大。如果你的算法的时间复杂度太高,在运行这些大规模的测试用例时就容易超过系统规定的时间限制,导致超时错误。如果你卡在大规模的测试用例,一般就能说明你的算法结果是正确的,因为前面的小规模测试用例都通过了,只不过是时间复杂度太高,需要优化。可能的错误有:
- 是否有冗余计算,是否有更高效的解法思路来降低时间复杂度。
- 是否有编码错误,比如边界控制出错,错误地传值传引用导致无意义的数据拷贝等。
- 笔试中,一般是按照通过的测试用例数量来计分的。所以如果你实在是想不出最优解法通过所有用例,提交一个暴力解,过几个用例捞点分,也是一种聪明的策略。
- 内存超限(Memory Limit Exceeded,常简称为 MLE)
- 和超时错误类似,内存超限一般是算法的空间复杂度太高,在运行大数据规模的测试用例时,占用的内存超过了系统规定的内存限制。想要解决这个问题,你需要检查以下几点:
- 是否有申请了多余的空间,是否有更高效的解法思路来降低空间复杂度。
- 是否在递归函数中错误地使用了传值参数导致无意义的数据拷贝。
- 和超时错误类似,内存超限一般是算法的空间复杂度太高,在运行大数据规模的测试用例时,占用的内存超过了系统规定的内存限制。想要解决这个问题,你需要检查以下几点:
数组
我们在说「数组」的时候有多种不同的语境,因为不同的编程语言提供的数组类型和 API 是不一样的,所以开头先统一一下说辞:可以把「数组」分为两大类,一类是「静态数组」,一类是「动态数组」。
- 「静态数组」就是一块连续的内存空间,我们可以通过索引来访问这块内存空间中的元素,这才是数组的原始形态。
- 「动态数组」是编程语言为了方便我们使用,在静态数组的基础上帮我们添加了一些常用的 API,比如 push, insert, remove 等等方法,这些 API 可以让我们更方便地操作数组元素,不用自己去写代码实现这些操作。
有了动态数组,后面讲到的队列、栈、哈希表等复杂数据结构都会依赖它进行实现。
静态数组
静态数组在创建的时候就要确定数组的元素类型和元素数量。只有在 C++、Java、Golang 这类语言中才提供了创建静态数组的方式,类似 Python、JavaScript 这类语言并没有提供静态数组的定义方式。
静态数组的用法比较原始,实际软件开发中很少用到,写算法题也没必要用,我们一般直接用动态数组。
定义一个静态数组的方法如下:
// 定义一个大小为 10 的静态数组
int arr[10];
// 用 memset 函数把数组的值初始化为 0
memset(arr, 0, sizeof(arr));
// 使用索引赋值
arr[0] = 1;
// 使用索引取值
int a = arr[0];
用 memset 将数组元素初始化为 0 是 C/CPP 的特有操作。
因为在 C/CPP 中,申请静态数组的语句(即 int arr[10] )只是请操作系统在内存中开辟了一块连续的内存空间,你也不知道这块空间是谁使用过的二手内存,你也不知道里面存了什么奇奇怪怪的东西。所以一般我们会用 memset 函数把这块内存空间的值初始化一下再使用。
其他比如 Java Golang ,静态数组创建出来后会自动帮你把元素值都初始化为 0,所以不需要再显式进行初始化。
动态数组
动态数组底层还是静态数组,只是自动帮我们进行数组空间的扩缩容,并把增删查改操作进行了封装,让我们使用起来更方便而已。
因此,动态数组也不能解决静态数组在中间增删元素时效率差的问题。数组随机访问的超能力源于数组连续的内存空间,而连续的内存空间就不可避免地面对数据搬移和扩缩容的问题。
// java 中创建动态数组不用显式指定数组大小,它会根据实际存储的元素数量自动扩缩容
// ArrayList 很熟悉了,即可重复的集合,底层是静态数组
ArrayList<Integer> arr = new ArrayList<>();
for (int i = 0; i < 10; i++) {
// 在末尾追加元素,时间复杂度 O(1)
arr.add(i);
}
// 在中间插入元素,时间复杂度 O(N)
// 在索引 2 的位置插入元素 666
arr.add(2, 666);
// 在头部插入元素,时间复杂度 O(N)
arr.add(0, -1);
// 删除末尾元素,时间复杂度 O(1)
arr.remove(arr.size() - 1);
// 删除中间元素,时间复杂度 O(N)
// 删除索引 2 的元素
arr.remove(2);
// 根据索引查询元素,时间复杂度 O(1)
int a = arr.get(0);
// 根据索引修改元素,时间复杂度 O(1)
arr.set(0, 100);
// 根据元素值查找索引,时间复杂度 O(N)
int index = arr.indexOf(666);
实现动态数组
手写实现动态数组有这几个关键点:
- 自动扩缩容
- 在实际使用动态数组时,缩容也是重要的优化手段。比方说一个动态数组开辟了能够存储 1000 个元素的连续内存空间,但是实际只存了 10 个元素,那就有 990 个空间是空闲的。为了避免资源浪费,我们其实可以适当缩小存储空间,这就是缩容。扩容和缩容采用的门限值可以自定义,例如:
- 当数组元素个数达到底层静态数组的容量上限时,扩容为原来的 2 倍;
- 当数组元素个数缩减到底层静态数组的容量的 1/4 时,缩容为原来的 1/2。
- 在实际使用动态数组时,缩容也是重要的优化手段。比方说一个动态数组开辟了能够存储 1000 个元素的连续内存空间,但是实际只存了 10 个元素,那就有 990 个空间是空闲的。为了避免资源浪费,我们其实可以适当缩小存储空间,这就是缩容。扩容和缩容采用的门限值可以自定义,例如:
- 索引越界的检查
- 自然的,在删/改/查中,都有一件共同要做的事:检查下标是否越界,因此,可以将检查下标越界这个行为,再次提取出作为一个公共方法。
增很特殊,由于增是可以放到任意一个位置的,因此不应检查其下标是否越界
- 自然的,在删/改/查中,都有一件共同要做的事:检查下标是否越界,因此,可以将检查下标越界这个行为,再次提取出作为一个公共方法。
public E remove(int index) {
// 检查索引越界
checkElementIndex(index);
...
}
- 删除元素谨防内存泄漏
- 单从算法的角度,其实并不需要关心被删掉的元素应该如何处理,但是具体到代码实现,我们需要注意可能出现的内存泄漏。给出的代码实现中,删除元素时,我都会把被删除的元素置为 null,
// 删最后一个元素
public E removeLast() {
E deletedVal = data[size - 1];
// 删除最后一个元素
// 必须给最后一个元素置为 null,否则会内存泄漏
data[size - 1] = null;
size--;
return deletedVal;
}
Java 的垃圾回收机制是基于 图算法 的可达性分析,如果一个对象再也无法被访问到,那么这个对象占用的内存才会被释放;否则,垃圾回收器会认为这个对象还在使用中,就不会释放这个对象占用的内存。
如果你不执行 data[size - 1] = null 这行代码,那么 data[size - 1] 这个引用就会一直存在,你可以通过 data[size - 1] 访问这个对象,所以这个对象被认为是可达的,它的内存就一直不会被释放,进而造成内存泄漏。
单/双链表
虚拟头尾结点的使用
- 一般来说,单链表设置虚拟头结点即可,虚拟尾结点用处不大(删改时要找到倒数第二个元素,由于没有双向指针,仍然要遍历)
- 双链表可同时设置虚拟头尾结点
- 设置虚拟结点有两层意思
- 1)创建一个空的虚拟结点
- 2)该结点用不删除,相应的引用恒指向这个空结点,如下图,同时设置了虚拟头尾结点,这两个结点恒为空,且相应的应用恒指向虚拟头尾结点

虚拟头尾结点的原理很简单,就是在创建双链表时就创建一个虚拟头节点和一个虚拟尾节点,无论双链表是否为空,这两个节点都存在。这样就不会出现空指针的问题,可以避免很多边界情况的处理。
// 举例来说,假设虚拟头尾节点分别是 dummyHead 和 dummyTail,那么一条空的双链表长这样:
dummyHead <-> dummyTail
// 如果你添加 1,2,3 几个元素,那么链表长这样:
dummyHead <-> 1 <-> 2 <-> 3 <-> dummyTail
没有虚拟头尾结点时,要把在头部插入元素、在尾部插入元素和在中间插入元素几种情况分开讨论
有了头尾虚拟节点后,无论链表是否为空,都只需要考虑在中间插入元素的情况就可以了,这样代码会简洁很多。
当然,虚拟头结点会多占用一点内存空间,但是比起给你解决的麻烦,这点空间消耗是划算的。
实现(带头结点)(带头尾引用)的单链表
- 带头结点的意思是,在创建链表之时便顺带创建一个空的结点,此即为头结点。
// 单链表作为一个类->其中包含结点类->结点类中存储值以及下一个结点,逻辑闭环
public class SinglyLinkedList<E> {
// 内部静态类:结点类,注意与单链表类区分
private static class Node<E> {
E val;
Node<E> next;
// 结点类的构造方法
Node(E val) {
this.val = val;
this.next = null;
}
}
// 虚拟头结点
private Node<E> head;
// 该尾结点指向实际尾结点,因为单链表中虚拟尾结点没用
private Node<E> tail;
private int size;
// 单链表类的构造方法,该链表带有虚拟头结点,因此初始化时将头结点置空
public SinglyLinkedList() {
this.head = new Node<>(null);
this.tail = head;
this.size = 0;
}
addFirst
- 注意单链表中无需虚拟尾结点,因此前面定义单链表时,尾结点是实际的尾结点,因此:
- 头引用不用动永远指向空头结点
- 尾引用视情况改变指向
- 且在该方法中,tail 引用只需要在链表为空时插入才要移动,其余情况不动。(因为该方法只在链头即空头结点之后插入)
public void addFirst(E e) {
Node<E> newNode = new Node<>(e);
// 防止断链
newNode.next = head.next;
// 由于是在链头(空头结点之后添加),因此用空头结点指向新结点
head.next = newNode;
// 如果是链表此时为空(只包含空头结点,则将尾指针指向新添加的结点)
if (size == 0) {
tail = newNode;
}
size++;
}


addLast
这个好理解
public void addLast(E e) {
Node<E> newNode = new Node<>(e);
tail.next = newNode;
tail = newNode;
size++;
}
add
add 方法接收传入的值和下标,将结点插入指定位置。
- 判断越界
- 判断是否在链尾插入,直接调 addLast 即可
- 都不是则开始遍历插入
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size) {
addLast(element);
return;
}
Node<E> prev = head;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
Node<E> newNode = new Node<>(element);
newNode.next = prev.next;
prev.next = newNode;
size++;
}
removeLast
移除最后一个元素首先要找到最后一个元素,
但只找到最后一个元素是不够的,还需找到倒数第二个元素,1)将其 next 引用置空 2)tail 引用指向倒数第二个元素
public E removeLast() {
if (isEmpty()) {
throw new NoSuchElementException();
}
Node<E> prev = head;
while (prev.next != tail) {
prev = prev.next;
}
E val = tail.val;
prev.next = null;
tail = prev;
size--;
return val;
}
实现(带虚拟头尾结点)的双链表
- 双链表中,设置虚拟尾结点很有意义
public class DoublyLinkedList<E> {
// 虚拟头尾节点
final private Node<E> head, tail;
private int size;
// 双链表节点
private static class Node<E> {
E val;
Node<E> next;
Node<E> prev;
Node(E val) {
this.val = val;
}
}
// 构造函数初始化虚拟头尾节点
public DoublyLinkedList() {
this.head = new Node<>(null);
this.tail = new Node<>(null);
head.next = tail;
tail.prev = head;
this.size = 0;
}
addFirst
- 与单链表的 addFirst 有两个不同,修改时需要考虑进去:
- 双链表带有 prev 指针
- 双链表带有虚拟尾结点
public void addFirst(E e) {
Node<E> x = new Node<>(e);
// head <-> temp
x.next = head.next;
x.prev = head;
head.next.prev = x;
head.next = x;
// head <-> x <-> temp
size++;
}

栈和队列
事实上,栈和队列本质上只是被限制了的元素进出顺序的数组/链表。
假设我们要实现的是链栈/链队,都可以用之前的双向链表调用特定 API 即可。
这里我们使用 Java 的容器 LinkedList 实现链栈:
// 用链表作为底层数据结构实现栈
public class LinkedStack<E> {
private final LinkedList<E> list = new LinkedList<>();
// 向栈顶加入元素,时间复杂度 O(1)
public void push(E e) {
list.addLast(e);
}
// 从栈顶弹出元素,时间复杂度 O(1)
public E pop() {
return list.removeLast();
}
环形数组
环形数组的提出:假设要用数组实现队列(队尾入队,队头出队),但在数组的头部改动元素复杂度是 O(n),如何优化成 O(1)?
一句话:环形数组技巧利用求模(余数)运算,将普通数组变成逻辑上的环形数组,可以让我们用 O(1) 的时间在数组头部增删元素。
- 核心原理:
- 环形数组维护了两个指针 start 和 end,start 指向第一个有效元素的索引,end 指向最后一个有效元素的下一个位置索引。这样,当我们在数组头部添加或删除元素时,只需要移动 start 索引,而在数组尾部添加或删除元素时,只需要移动 end 索引。
- 当 start, end 移动超出数组边界(< 0 或 >= arr.length)时,我们可以通过求模运算 % 让它们转一圈到数组头部或尾部继续工作,这样就实现了环形数组的效果
- 开闭区间
- 理论上,可以随机设计区间的开闭,但一般设计为左闭右开区间是最方便处理的,即 [start, end) 区间包含数组元素。因为这样初始化 start = end = 0 时区间 [0, 0) 中没有元素,但只要让 end 向右移动(扩大)一位,区间 [0, 1) 就包含一个元素 0 了。
- 如果设置为两端都开的区间,那么让 end 向右移动一位后开区间 (0, 1) 仍然没有元素;
- 如果设置为两端都闭的区间,那么初始区间 [0, 0] 就已经包含了一个元素。这两种情况都会给边界处理带来不必要的麻烦,如果你非要使用的话,需要在代码中做一些特殊处理。
- 什么时候用环形数组
- 如果要使用数组实现的队列(特别是双端队列)时,为了保证入队出队都是 O(1),就要使用环形数组。
哈希表
- 为什么我们常说,哈希表的增删查改效率都是 O(1)
- 因为哈希表底层就是操作一个数组,其主要的时间复杂度来自于哈希函数计算索引和哈希冲突。只要保证哈希函数的复杂度在 O(1),且合理解决哈希冲突的问题,那么增删查改的复杂度就都是 O(1)。
- 哈希表的遍历顺序为什么会变化?
- 因为哈希表在达到负载因子时会扩容,这个扩容过程会导致哈希表底层的数组容量变化,哈希函数计算出来的索引也会变化,所以哈希表的遍历顺序也会变化。
- 为什么不建议在 for 循环中增/删哈希表的 key
- 原因和上面相同,还是扩缩容导致的哈希值变化。遍历哈希表的 key,本质就是遍历哈希表底层的 table 数组,如果一边遍历一边增删元素,如果遍历到一半,插入/删除操作触发了扩缩容,整个 table 数组都变了,那么遍历就乱套了。
扩缩容导致 key 顺序变化是哈希表的特有行为,但即便排除这个因素,任何其他数据结构,也都不建议在遍历的过程中同时进行增删,否则很容易导致非预期的行为。
- 原因和上面相同,还是扩缩容导致的哈希值变化。遍历哈希表的 key,本质就是遍历哈希表底层的 table 数组,如果一边遍历一边增删元素,如果遍历到一半,插入/删除操作触发了扩缩容,整个 table 数组都变了,那么遍历就乱套了。
- 为啥一定要用不可变类型作为哈希表的 key?
- 因为哈希表的主要操作都依赖于哈希函数计算出来的索引,如果 key 的哈希值会变化,会导致键值对意外丢失,产生严重的 bug。
哈希函数的构造
谈及构造一个函数,首先要确定输入,再确定函数,最后能得到输出。
哈希函数输入
以 HashMap 为例,其 Key 只能为引用类型,即使传入 int 等基本类型,也会通过自动装箱转化为 Integer 等包装类型。
核心原因是,HashMap 会调用 hashcode 方法,将对象的引用转化为一个独一无二的数值。
因此,哈希函数的输入,即 key ,一般要求为引用类型,即 String/Integer 等。
哈希函数的构造
任意 Java 对象都会有一个 int hashCode() 方法,在实现自定义的类时,如果不重写这个方法,那么它的默认返回值可以认为是该对象的内存地址。一个对象的内存地址显然是全局唯一的一个整数。
所以我们只要调用 key 的 hashCode() 方法就相当于把 key 转化成了一个整数,且这个整数是全局唯一的。
保证索引合法
hashCode 方法返回的是 int 类型,首先一个问题就是,这个 int 值可能是负数,而数组的索引是非负整数。
那么你肯定想这样写代码,把这个值转化成非负数:
int h = key.hashCode();
if (h < 0) h = -h;
但这样有问题,int 类型可以表示的最小值是【 -2^3 而最大值是 2^31 - 1。所以如果 h = -2^31,那么 -h = 2^31 就会超出 int 类型的最大值,这叫做整型溢出,编译器会报错,甚至产生不可预知的结果。
为什么 int 的最小值是 -2^31,而最大值是 2^31 - 1?这涉及计算机补码编码的原理,简单说,int 就是 32 个二进制位,其中最高位(最左边那位)是符号位,符号位是 0 时表示正数,是 1 时表示负数。
现在的问题是,我想保证 h 非负,但又不能用负号直接取反。那么一个简单直接的办法是利用这种补码编码的原理,直接把最高位的符号位变成 0,就可以保证 h 是非负数了:
哈希冲突的解决办法
如果两个不同的 key 通过哈希函数得到了相同的索引,这种情况就叫做「哈希冲突」。
哈希冲突不可能避免,只能在算法层面妥善处理出现哈希冲突的情况。
因为这个 hash 函数相当于是把一个无穷大的空间映射到了一个有限的索引空间,所以必然会有不同的 key 映射到同一个索引上。
哈希冲突的两种常见的解决方法,一种是拉链法,另一种是线性探查法(也经常被叫做开放寻址法)。
名字听起来高大上,说白了就是纵向延伸和横向延伸两种思路嘛: