“AI 的 iPhone 时刻到来了”。非算法岗位的研发同学’被迫’学习 AI,产品岗位的同学希望了解 AI。但是,很多自媒体文章要么太严谨、科学,让非科班出身的同学读不懂;要么,写成了科幻文章,很多结论都没有充分的逻辑支撑,是‘滑坡推理’的产物。这篇文章从底层讲起,却不引入太多概念,特别是数学概念,让所有人都能对大模型的核心概念、核心问题建立认知。文章末尾也为需要严肃全面地学习深度学习的人给出了建议。
关于以 ChatGPT 为代表的大语言模型(LLM),相关介绍文章、视频已经很多。算法部分,约定俗成地,还是先来一段贯口。当前我们说的 LLM,一般代指以 ChatGPT 为代表的基于 Generative Pre-trained Transformer 架构的自然语言处理神经网络模型。顾名思义,它是个以预训练技术为核心的模型,是个生成模型。同时它是Transformer这个编码-解码模型的解码部分。
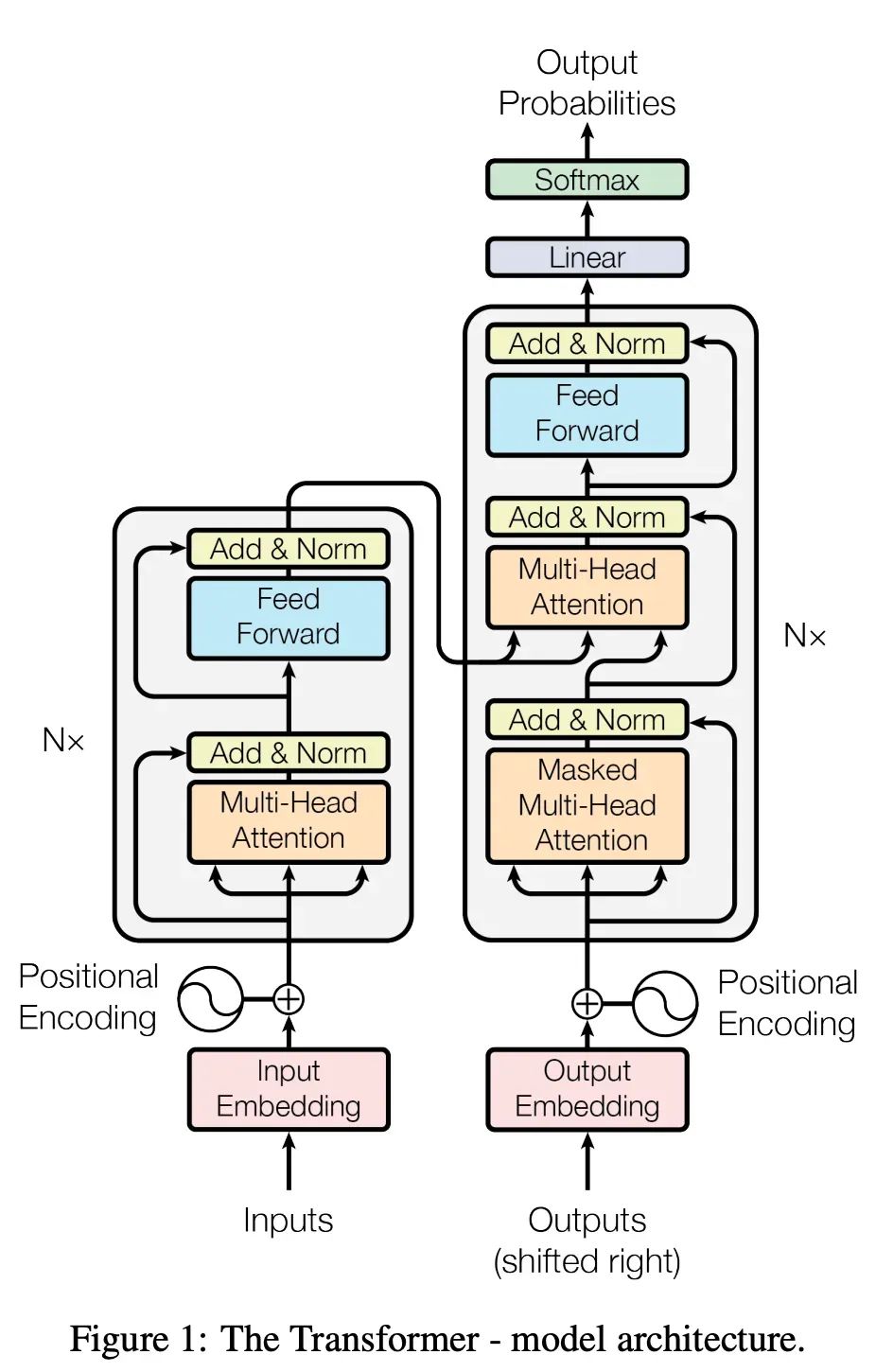
不管你能不能看懂,它就是这张图的右边部分。到了这里,非基础研究、应用研究的同学就开始在听天书了。读这篇文章的这一部分,大家是为了’学到‘知识,而不是为了’被懂算法的同学咬文嚼字扣细节给自己听,被秀一脸,留下自己一脸茫然‘。大家的目标是‘学习’为首,‘准确’为辅。那我就用不嗑细节的‘人话’跟大家讲一讲,什么是自然语言处理大模型。虽然,这些内容就仅仅是’毕业生面试应用研究岗位必须完全答对‘的档次,但是,‘知之为知之,不知为不知,是知也’,大家如果不懂,是应该看一看的。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
1 编解码与表示学习
什么是自编码器(autoencoder,encoder-decoder model)?通俗地说,用拍摄设备,录制视频,录制成了 mp4 文件,就是采集并且 encode;你的手机视频播放器播放这个视频,就是 decode 视频并且播放。做 encode-decode 的模型,就是编码-解码模型。很明显,编码模型和解码模型是两个模型,但是,他们是配对使用的。你不能编码出一个.avi 文件,然后用只支持.mp4 的解码器去解码。
在深度学习领域里,下面这个就是最简单的编码-解码模型示意图。f 函数是编码器,把输入 x 变成某个叫做 h 的东西,g 是解码函数,把编码出来的东西,解码成输出 r。
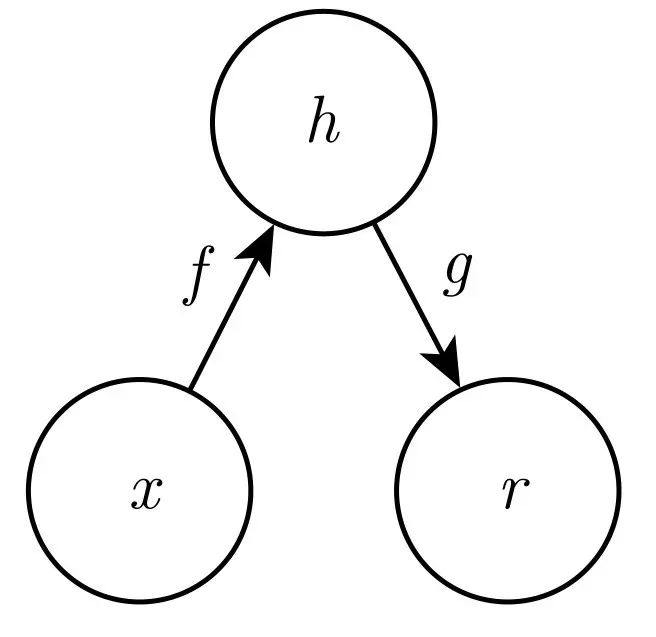
那么,最简单的编码器,就是什么都不干:f(x)=x,h=x,r=g(f(x))=h。输入‘Tom chase Jerry’,输出就是‘Tom chase Jerry’。显然,这样的字编码器不需要训练,并且,也没有任何用处。
如果,输入‘Tom chase Jerry’,输出是‘汤姆追逐杰瑞’,那么这个自编码器就完成了机器翻译的任务。我们人类可以做翻译,实际流程上,也跟这个差不多。那么,我们人类是怎么做到的呢?我们并不是以‘做翻译’为唯一的目标去学习语言的,我们会学习‘单词’、‘语法’、‘语言所表达的常识’这些语言之下最基础的‘特征’的‘表示’。当我们学会了被表达的事物和它在不同语言中的表示之后,我们就能做翻译这件事情了。我们仔细审视一下这个过程,我们至少做了两件事情:
1 ) 学会被各种语言所表示的‘东西’,这里我们称之为世界知识 (world knowledge),它包括事实性知识 (factual knowledge) 和常识 (commonsense)。其中包括,学会至少两门语言里表达世界知识的单词和语法。
2)学会按别人的要求去执行翻译这个任务。
那么,这两件事情的第一件,就是 GPT 的第二个单词,Pre-train(预训练)。我们就是要去学到‘Tom chase Jerry’这句话和其他无数句话在被拆解成世界性知识之后的‘表示’。
Transformer 就是一个专门用于自然语言处理的编码-解码器架构。编码器-解码器可以有很多不同的架构细节,就能得到不同的自编码架构,Transformer 是此刻看起来效果最好的,能很好地学到自然语言背后的特征,并且有足够大的模型容量。所谓模型容量,是指,有一些模型参数过多,就反而学不到特征,或者无法训练了,无法用于表示特别复杂的东西。
2 GPT
GPT 全称 Generative Pre-trained Transformer,前面讲了编解码,算是讲了一点点 Transformer,也讲了预训练、Pre-trained。那么,Generative 从何讲起?
我接着说人话。前面讲到了,编码器-解码器是两个不同的模型,就像你看视频,你的手机上并不需要视频录制、编辑软件,只需要一个解码-播放器一样。训练两个模型太麻烦,我们希望就围绕一个模型做研究,做训练。我们能不能不做编码,就围绕解码模型来达到一些目的呢?答案当然是可以的。
打个不严谨的比方。我现在想找人帮我画一幅肖像画。其实我并不懂怎么画画。于是,我请人给我画。我并不能从画工技艺、艺术审美方面去评判他画得好不好。但是,我是有能力去判断我请的人画出来的画是不是令我满意的。此时,我就是一个 decode-only 的模型。你会说,“你这个 decode-only 的模型必须要有一个懂 encode 的画师才能工作啊“。是的,我不懂画画。确实需要一个画师。
但是,你记得吗,OpenAI 训练 GPT3 的模型,就是给它海量的数据,让它去训练。那么,画师不教导我绘画技巧,只是不停的给我画肖像,并且,给我看肖像是否满意,我指出哪些地方不满意,他做出修改。这个事情干了一千万次,我是不是至少能学到_‘当给我一幅没画好的我的肖像画,我知道应该怎么接着画下一笔‘_?我不是从拆解好的理论体系里去学习的,我并不能叫出各种会画技法的名字,但是,我就是会做上面这件事情了。
相当于,我听到“GPT 是一个预训练模”,我就知道下一个字一定是“型”字一样。而因为我只擅长接着前面做好的事情完成接下来的事情,所以,我会‘生成’这个工作方式,同时,我也只会‘生成’这个工作方式。这就是 Generative 的意思。
总结一下,Generative 是被训练出来的模型的工作的方式,Transformer 是这个模型的架构,Pre-trained 是形容 Transformer 的,就是说训练这个模型,预训练是不可或缺的核心步骤。
3 巨量参数
有一个很重要的点,被训练完成的我,是如何知道没画完的肖像画的下一笔是应该怎么画的?就相当于你听到“今天天气很”之后,你是怎么知道下一个词是什么的?显然,你是靠猜测的。什么东西来支撑你的猜测?是你被训练了一百万次的经验。这些经验构成了什么?这些经验被你潜意识地总结成了一些规律。有一些规律确定性很高,有一些规律确定性很低。“今天天气很”后面接的字,确定性很低,“GPT 是一个预训练模”后面接的字确定性很高。
那么,你实际上就是学到了一个概率模型,这个概率模型其实是无数个场景的概率分布组合而成的概率模型。预测“今天天气很”的下一个词,是一个概率分布。“GPT 是一个预训练模”的下一个词是另一个概率分布。所以,从头学习机器学习、深度学习,就会知道,所有机器学习、深度学习模型都是概率模型,统计学是核心工具。
GPT3 的 paper讲,OpenAI 做的 GPT3 有 1750 亿参数。不管 paper 怎么说,实际上是如何做到的。你只是自己想象一下,想要记住足够全面的‘世界知识’,是不是至少要有足够大的’模型体积(模型容量)',即足够多的参数?更深入的研究还在继续进行,此刻,按照 GPT3 的 paper 来说,当参数量达到 1750 亿的时候,模型就能记住这个世界的‘世界知识’所需要的所有‘特征’的‘表示’了。每个参数用 16 位的浮点数保存,体积是 320GBytes。这个世界的‘世界知识’,被这 320G 的数据表示了。
我们在对话聊天的时候,如果说了一些自己觉得是常识,对方却不懂的时候,是不是对话就较难进行下去了?所以,为什么我们的模型需要这么多参数?因为它需要‘什么都懂’。如果我说我用 32M 规模的数据就记住了这个世界的常识,你是不是会觉得‘这显然不可能’?
4 GPT3 不等于 ChatGPT
前面已经讲了 Generative、Pre-trained、Transformer 这些概念。我们接着讲 ChatGPT。首先,GPT3 不等于 ChatGPT,GPT3 这个预训练模型,是 ChatGPT 的基础。回顾我们最开始讲的‘人如何学会翻译’至少需要两个步骤,第一步就是训练一个 GPT3 的预训练模型。有了这个模型之后,我们还要接着做一些训练,才能完成 ChatGPT。
我们首先来回顾一下 GPT1、GPT2。
GPT1 的 paper名字叫做,Improving Language Understanding by Generative Pre-Training,通过生成式预训练提升模型对语言的理解能力,这就是我们前面讲过的东西。但是,它还没达到很好的效果。我们想在 decoder-only 的模型里学到‘用语言呈现的世界知识’的’深层表示’,初步证明这个方向有前途。
GPT2 的 paper名字叫做,Language Models are Unsupervised Multitask Learners。在这篇文章里,找到了让 GPT1 这个‘思想方法’达到很好的效果的技术手段,通过自监督学习。怎么个自监督法呢?就是我们手里有很多书籍、文章,我们通过给模型书籍的前 n 个字儿,让它猜测第 n+1 个字儿是什么,我们手里有正确的第 n+1 个字儿,让模型去不断纠正自己。模型为了达到更准确猜中第 n+1 个字儿的目标,就被迫‘学到’了潜在的‘世界知识’的表示。就像我们学到了语言的语法,记住了单词,掌握了世界的常识。实际上,我们交给模型的任务,都是‘猜下一个词’。但是计算‘56+21=’也是猜下一个词。
所以,又可以把猜下一个词分解为很多种猜词任务,数学计算就是其中一种。最后,证明了 GPT2 效果还不错。多说一句,上面这么搞,怎么就是自监督了呢?是否是‘有监督’学习,本身这个概念比较模糊,并不是一个科学的定义,只是大家习惯这么叫而已。我们约定俗成,把‘训练数据是经过精巧地设计,并且准备过程对人力成本较高’的训练,叫做有监督训练,否则就是无监督。我们只是把前人努力写的书做了一个调整给到模型,按照这个约定,应该属于无监督学习。但是,好像,我们又其实是在用人类努力的成果在训练它。所以,有人就开始称这种情况为‘自监督学习’。
接着,你就会想,深度学习是一门科学啊,怎么能对概念的定义搞得这么模糊不严谨?对,你说得没错,深度学习,在玩数学的人眼里,就是充满了不严谨,处在鄙视链的底端。但是,你挡不住深度学习应用的效果好呀。深度学习就是这么一系列‘不严谨’,充满了‘我不知道为什么,但是这么做效果就好’的方法。科学家们在努力地解释它为什么效果好,但是,这些研究远远追不上,找到‘效果更好,但是并不理解为什么效果好’的方法的步伐。对你自己的认知亦是如此,你有自我认知,那么,你的自我认知是怎么来的?“我是谁,我从哪里来,我要到哪里去?”
GPT3 的 paper名字叫做,Language Models are Few-Shot Learners。意思就是,在 GPT2 的思路的指导下,我们通过把参数增加到 1750 亿,真地学到了‘世界知识’!学到了这些潜在的‘表示/特征’之后,我们只需要再让模型学一个任务的少量几个 case,模型就能学进一步学到我们给的几个 case 里的潜在的’特征’,即这几个 case 所表达的规律和逻辑。
但是,GPT3 掌握了知识,但是,它还不会干活呀。比如,你给它输入“给我写一段简介”,模型理解你确实说了“给我写一段简介”,但是,它此刻可以生成很多东西。比如生成一个“要简介限制在 120 个字以内”。它是个生成模型,把你说的话续写下去,也是一种生成啊!所以,我们还得教一个理解了我们的话模型,按照我们想要的方式去生成结果。就像,我们在进行一场对话。所以,就是 ChatGPT,chat+GPT。我们要进行聊天,本质上,就是让模型‘要能听懂我们的指令’。所以,OpenAI 接着又有一篇重磅论文Training language models to follow instructions with human feedback,它在 OpenAI 的官网上,是另一个名字Aligning language models to follow instructions。
顾名思义,就是要通过一些‘问题-回答’对的训练数据,让模型能在收到“给我写一段简介”这样的指令性的输入的时候,真地去按照指令的要求去生成接下来的东西。OpenAI 的标题里出现了一个词’Alignling(对齐)',你可以不管它。但是,理解了这个词,你才理解了‘制定对齐/指令微调’的核心技术。有兴趣,你可以接着看这个自然段,也可以不看,直接跳到下下一个自然段。
‘指令对齐’,就让掌握了知识的模型能按照我们想要的方式去生成更多的词了。达到这个效果的方法,讲起来,很硬核。为了说人话,我就打个比方。现在,我们有一个房间,里面有几百本书就像垃圾一样堆砌在一起。这就是预训练已经把隐藏特征学到了。我们应该怎么去整理这些书籍呢?这个问题,取决于,我们后续要如何使用这些书籍。我们可以按门类,去排列书籍,每一类书籍一个书架。也可以按照书名去排列书籍,所有书籍分别根据书名被放在按 A-Z 排列的的书架里。
所以,对齐,就是根据我们的目的,去整理模型学到了的知识。那么,为什么我们不用整理、重构之类的词,而用对齐呢?因为,我们知道模型学到了知识,但是,我们能看到这些表示,就是 1750 亿个参数,但是,人类看不懂它。就像,人类能看到自己的脑袋,但是脑袋里的神经元是如何联合在一起工作的,看不懂。
更具体的,‘1+1=2’这个知识,你知道它存储在你大脑里的具体哪个神经元上么?你当然不能。所以,我们没有细粒度的手段去整理书籍。有一个比较粗力度的手段,就是:按照我的需求,大概地把一些数据强行抓住首尾两本书,把它们压齐。你整理书籍,可以一本一本放。但是你没法去拿其中一本的时候,你当然可以从一对儿书的两端,用力压,被按照我们想要的方式挤压之后,书自己就变得更整齐了,对齐到了我们想要的结构。
我再打个比方,社会共识、常识,本身也是‘对齐’得来的。‘婚姻应该是自由恋爱的结果’,这个常识,不是从来如此的。是理性主义崛起之后,紧接着浪漫主义在 1900 年左右崛起,在 20 世纪才出现的。浪漫主义借由‘罗密欧与朱丽叶’之类的文艺作品广泛传播、得到认可,进而才把我们的常识‘对齐’成了这么一个结果。说得更远一点,习惯了中国文化的人在美国必然会被‘文化冲突’所困扰,也是因为,中国和美国其实都通过媒体把自己的常识对齐成了不同的‘形状’。‘对齐’无时无刻不在这个世界里发生。
实际上,模型每次只能生成一个词儿,那么,把问题和回答都当成字符串连接起来,结构是:输入[问题里所有的词][回答的前n个词儿],生成回答的第 N+1 个词儿。如果进行第二轮对话。输入就变成了:输入[第一个问题里所有的词][第一个回答的所有词][第二个问题的所有词][第二个问题的回答的前n个词],输出[第二个回答的第 N+1 个词]。至于模型如何知道哪一段是问题,哪一段是问题,这里不展开描述。
实际上,ChatGPT 的训练过程,可以看下面这张图,我不做解释,能不能看懂,随缘(进一步阅读另一篇比较说人话的文章,看这里):
至此,你知道了 GPT3 是 ChatGPT 这个‘技惊四座’的模型的基础。
5 RLHF-强化学习
我们都知道,ChatGPT 至少经历了预训练、指令对齐、你可以理解为,一个大学生上一门课,指令对齐就是老师在课堂上给我们上课。但是,我们学习不能总是耗着一个老师一直给我们讲啊,成本太高了。就是说,积累大量指令对齐的 QA(问题-回答)训练数据,成本很高。后续更大量的学习,还得学生自己在脱离老师的强帮助,自行学习。一则效果更好,二则成本更低。
所以,我们用完成了指令对齐的模型,针对大量问题作出回答。并且,每个问题都给出 10 个回答。由人类去标注,所有回答里,哪些回答更好。用这个标注的 QA 对去接着‘对齐’模型,让模型把知识对齐到更符合我们的要求。这个时候,人类需要做的,就仅仅是提问题+标注,之前是要给出问题且给出答案。成本降低了一些,速度也变快了一些。这里,强化学习实际上是训练一个奖励模型(reward model)作为新的老师,来对模型的回答进行‘批改’,让模型愈发把知识‘对齐’到我们想要的样子。
上面简单的强化学习讲解,其实有一个很严重的问题。如果对于同一个 Q,老师一会儿说 A1 好,一会儿说 A2 好,就变成了学生的脑子在来回拉扯。所以,强化学习,在细节上,还有更多不同的细节。为了讲人话,我这里略过这些细节。
6 LoRA 与 instruction fine-tuning
大模型太大,训练成本太高,人们总在寻找更低成本近似的方法。最近 LoRA 也是跟 CV(计算机图像)领域的 Stable Diffusion 一起大火。这里也用人话讲一下 LoRA fine-tuning(不讲 Stable Diffusion)。为了讲清楚,会有一点点不讲人话的时候。
LoRA paper的标题是 LoRA: Low-Rank Adaptation of Large Language Models。其实,这个方法,属于‘迁移学习’这个领域。LoRA 达到的效果是:在有一个已经训练好的大模型之后,再训练一个依赖于大模型的小模型,组合在一起工作,达到用较低的成本实现对大模型的微调。结果稍稍裂化于对大模型进行了微调,但是微调成本更低。低在哪儿呢?接下来就得先讲明白 LoRA 是如何工作的。
什么是 low rank?低排名?low rank 是个数学概念,rank 是指矩阵的秩,low rank Adaptation 就是说,用秩较低的矩阵替代之前秩较高的矩阵。我还是稍微说一下什么是矩阵的秩,因为会被多次用到。
我们有一个 3x4 的矩阵如下:
[1,2,3,4]
[2,4,6,8]
[3,6,8,12]
显然,要存储它,我们需要用到 12 个数字。但是,这个我特别构造的矩阵是有一个特点的,第二行可以由[1,2,3,4]乘以 2 得到,第三行可以由[1,2,3,4]乘以 3 得到。那么,实际上,我就可以用[1,2,3,4]里的 4 个数字,加上 1、2、3 这 3 个系数,总共 7 个数字就可以表示这个矩阵。我需要的数字数量从 12 个降低到了 7 个。原始矩阵叫做 W,分解之后变成了需要的数字更少的两个矩阵 B 和 A,公式就是 W=B 乘以 A,记为 W=BA。
在我这个例子中,是无损失地进行了分解。数学上,有办法进行精度有损的分解,W 可以转化为更少的数字构成 B 和 A。这就是说人话版本的矩阵的秩分解。
这里,我们补充介绍一下深度网络里的参数是怎么组织的:
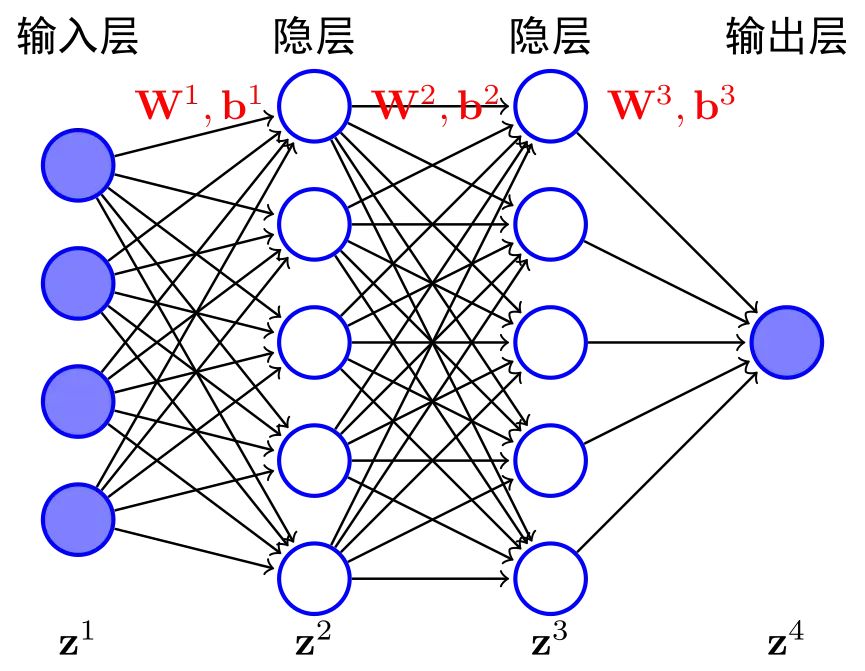
在这个图中,我们看到了一个网状结构。其中‘O 单向箭头指向 P’的意思就是‘O 参与计算,得到 P’。我们就看到了 z1、z2、z3 很多层,z1 这一层是一个 W1 矩阵和 B1 这个偏置向量。z1、z2、z3,越往右,就越深,就是深度网络。所谓参数,就是这些密密麻麻、层层叠叠的计算网络里的数字。这个图只是一个示意,真实的网络结构,各有各的不同。以及,必须在每个网络节点上选择合适的激活函数,后面不会用到,这里不做展开。好了,我们接着讲 LoRA。
理解了低秩分解,LoRA 的 paper 的意思就是:
假设我们的模型深度为 l(layer 的首字母),每一层的参数为矩阵 W。并且,我们之前就已经训练好了一个模型,这个模型的参数冻结住,永远不改变了,记为 W0。那么,我们训练模型就是在不断改变下面这个公式的 ΔW 这个模型参数变更的增量。
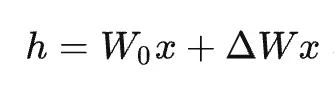
这个增量可以通过低秩分解,分解为:
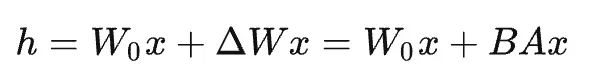
训练主要过程依然和其他所有 fine-tuning 一样,只是多了一个细节:把训练后的参数变更保存到了 BA 中,而不是直接更新到 W0 里去。
这里,稍微讲解一下训练一个 Transformer 模型需要的显存量。根据这篇文章的计算,训练每 2 个字节大小个 16 位浮点数表示的参数,需要 20 个字节的显存。那么,常见的 70 亿参数的模型,大小是 14GBytes,需要的显存至少是 140GBytes,如果要提高并行度,就需要更多显存。当前比较强的A100 显卡,单卡有 40G 显存和 80G 显存两个版本,单卡无法进行训练,必须要多卡同时进行。因为如果显存不够的话,是根本无法开始训练的。显存容量,决定了模型能不能开始训练。GPU 算力,决定了要训练多久。
那么,我们可以得到以下几个结论:
1)模型训练好之后,做线上推理服务,计算量,并没有减少,反而可能有所微微增加。
2)低秩矩阵的大小是可以调整的,可以是非常小。低秩矩阵越小,丢失的精度越多。
3)训练过程,两个核心成本是显存使用和 GPU 运算量。LoRA 方法下,低秩矩阵 BA 是可训练参数。显存的使用,等于 1 倍模型参数的体积加上 10 倍可训练参数的体积。GPU 计算量可以根据可训练参数的数量决定,如果我们把 BA 设定得比较小,训练量可以比全参数模型训练降低成千上万倍。
4)微调后的模型和原始模型的参数不能相差过大,不然用一个低秩矩阵 BA 所替代的 ΔW 会丢失大量精度,推理效果特别差。
5)LoRA 是一种模型训练的思想方法。它可以适配到很多类型的模型上。GPT 模型,或者 Stable Diffusion 的模型,都可以。训练时节省的显存量,要根据具体模型结构来计算。
这些特性,说一个更具体的 case。stable diffusion 是一个开源的结合了 Transformer 的文字生成图片的 CV(计算机视觉)模型。它的参数量是 1.2 亿多,大小 469M。假设,如果没有 LoRA 的方法,可能就需要至少 4G 的显存。家庭游戏显卡显存一般在 8G 左右,因为显存不够,训练的并行度很低,即使是民用 GPU 也可能在闲等,在同一张显卡上,都需要更长的训练时间。LoRA 让显存需求降低到 1G 左右,并行度提高了 8 倍。训练的总结算量还降低上百倍。训练成本大大降低。。同时,训练出来的 LoRA 小模型,体积就 32M 左右,社区里就流行起了把自己 fine-tune 出来的 stable diffusion 下的 LoRA 模型互相传播。
回顾一下 LoRA 与 GPT,我们可以说,LoRA 方式的 fine tuning 的对于 GPT 的价值,并不太大。只有在很小的场景,有 LoRA 的发挥空间。
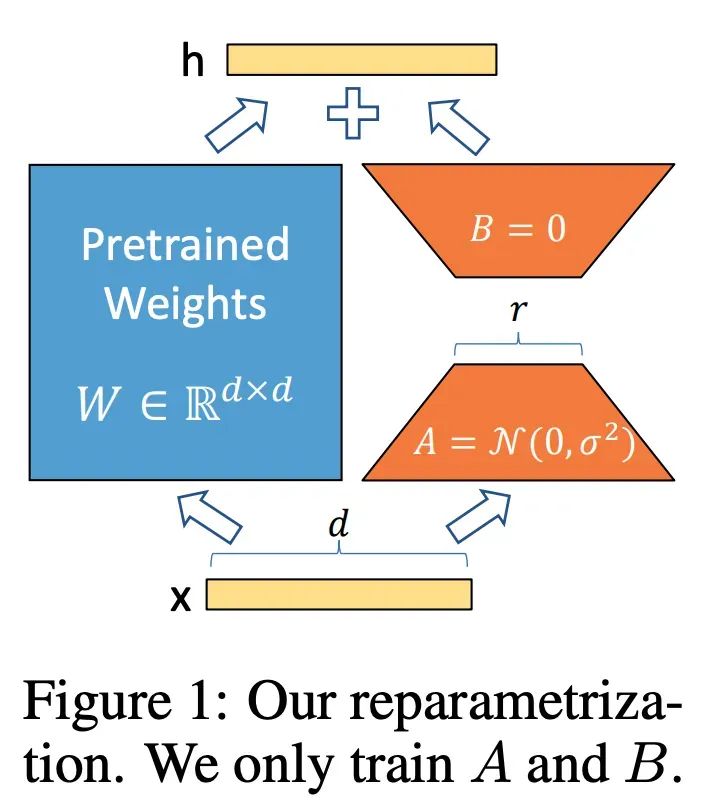
现在,你应该能理解 LoRA 论文原文中的这种图了。注意,这里,LoRA 是对原深度神经网络的每一层都设计了对应 BA 矩阵。
综上,如果我们手里已经有一个强大的模型,我们仅仅像微调它的表现,而不是想要教会它很多新的东西,使用 LoRA 方法,成本是很低的。比如,文生图的时候,我们不调整生成出来的图片的框架、构图,我们只想调整图片的风格(真实系、漫画风)。或者,我们让一个强大的模型去做一些简单的任务,把简单的任务做得特别好,也可以用 LoRA。
7 常见的开源类 GPT3 模型
Meta 开源的LLaMA是现在市面上预训练做得最好的开源的架构类似 GPT3 的模型。它提供了 70 亿、130 亿、650 亿 3 个参数规格的模型。特别说明一下,它只做了预训练。它支持多种语言。英文效果最佳,中文和其他语言的效果一样,比英语差一些。
Vicuna-7b 是用 70k 指令对 LLaMA 进行了指令微调,它微调的 70 亿参数的 LLaMA 版本。是当前开源的做完了指令微调的模型里,效果最好的。
chatglm-6b是清华大学清华认知工程实验室基于自己设计的预训练模型架构General Language Model微调而来的聊天模型。参数规模是 62 亿。GLM 模型是基于 Transformer 架构,更像 Transformer 的 Encoder 部份-BERT。预训练用了 1T token 的中英文语料。没说具体用了多少语料进行指令微调。中文聊天的效果,是开源模型里最好的。但是 GLM 模型架构天花板有没有 GPT3 那么高,需要有人去研究,清华大学没有对外公开。glm 预训练模型有一个 130 亿的版本,没有对外开源。
bloom-176b是参数最多的开源预训练模型,模型架构和 GPT3 很相似,是学术界很多人一起窜起来的一个预训练模型。它只做了预训练,做 QA 任务,效果较差。
alpaca-lora-7b是依附在 LLaMA-7b 上的模型。这个模型效果一般,但是它开源了 52k 条挺有价值的指令微调训练数据,它是用了一个用 ChatGPT 作为老师来生成更多训练数据的方法(paper 的名字是:SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions)来训练的模型。同时,alpaca 是一个 LoRA 方法下的模型。self-instruct 这个思路,非常有趣,其实大家都会自然而然有这种想法:既然有了 ChatGPT 这个效果特别好的模型,为什么我不直接只搜集指令问题,然后用 ChatGPT 给我生成指令 QA 里的 Answer,并且生成更多类似的 QA 对呢?这个想法是很好的,我们也在用。但是,文章里也说了,会出现‘对某些垂直领域的问题过拟合,对其他领域的问题欠拟合’的问题,这里不展开细节。