一、基础背景
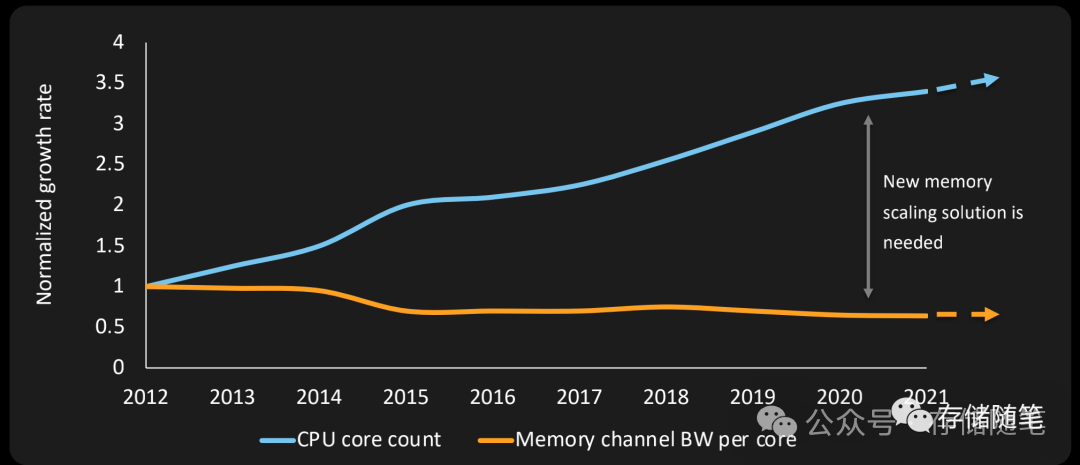
传统的冯·诺依曼架构虽然广泛应用于各类计算系统,但其分离的数据存储与处理单元导致了数据传输瓶颈,特别是在处理内存密集型任务时,CPU或GPU需要频繁地从内存中读取数据进行运算,然后再将结果写回内存,这一过程涉及大量的数据传输和较高的延迟,成为制约系统性能提升的关键瓶颈。
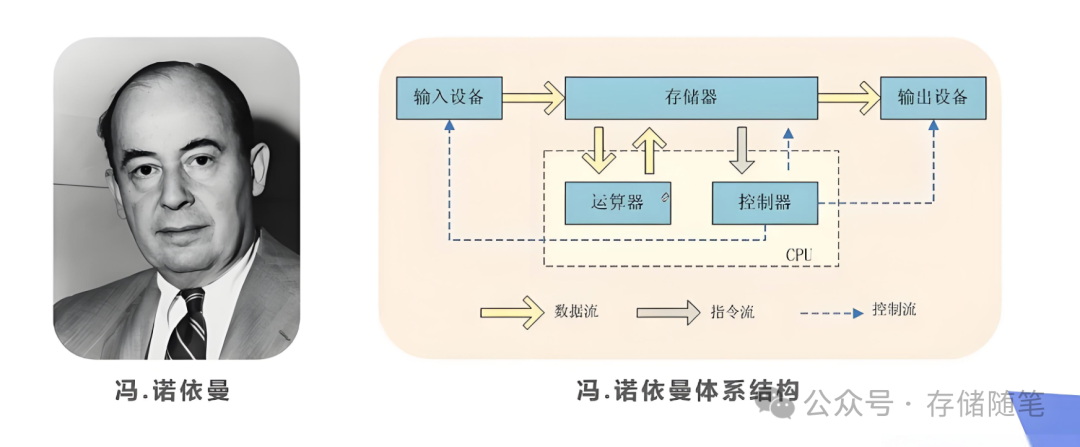
冯·诺依曼架构中目前有一个很严重的问题叫做内存墙(Memory Wall),处理器速度(尤其是CPU)相对于主内存(如DRAM)访问速度的增长差距所造成的性能瓶颈现象。随着处理器性能不断提升,其处理数据的速度远超主内存的读写速度,导致处理器经常处于等待数据从内存加载到缓存或从缓存写回内存的状态,这种等待时间占用了大量原本可用于计算的时间,限制了整个系统的性能表现。简而言之,内存墙就是指处理器与内存之间的带宽和延迟不匹配导致的性能障碍。
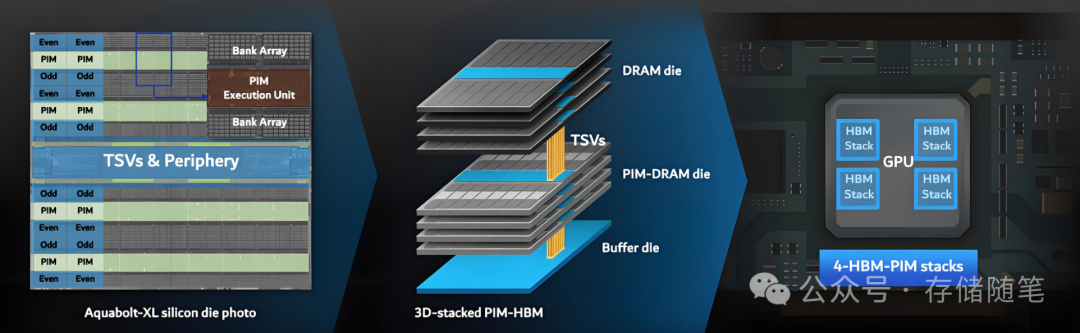
PIM(Processing-in-Memory)技术则是为解决内存墙问题而提出的一种计算范式。它将计算功能直接集成到内存模块内部或非常靠近内存的位置,使得数据处理能够在数据驻留的地方进行,而非在传统架构中先将数据从内存取出、经过较慢的总线传送到处理器、进行计算后再返回内存。

PIM的核心思想是“数据在哪里,计算就在哪里”。通过在内存芯片内部或紧邻内存的位置添加计算单元,可以大幅度减少甚至消除频繁的数据搬运过程。数据不再需要经过内存控制器、总线和各级缓存,而是直接在内存内部完成计算操作。这样,就消除了因数据传输产生的延迟和带宽压力,显著降低了处理器等待数据的时间。

超大规模人工智能(AI)系统,以ChatGPT等为代表,凭借其仿人问答、对话、甚至创作音乐和编写计算机程序等能力,震撼全球。然而,在这神奇表象的背后,实则需要庞大的内存密集型数据计算支撑。
此外,CXL诞生的基础是为了解决CPU内存和附加设备内存的互联,实现资源共享,得到最大的性能提升。随着数据大规模超算、AI、5G、云技术、边缘计算、自动驾驶等蓬勃发展,未来的数据存在指数级的增长且要求实时计算。
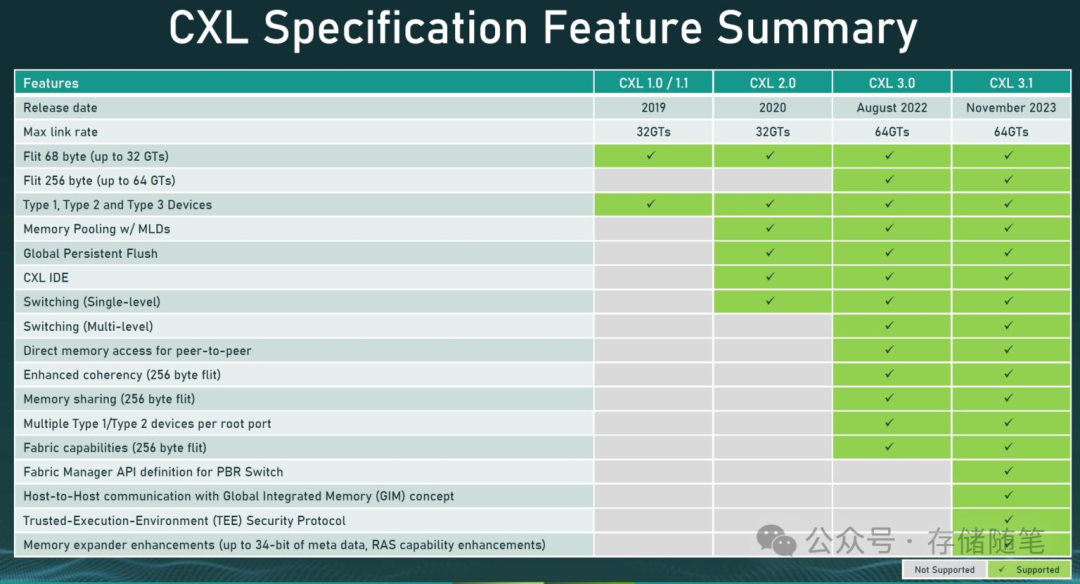
从2019年的CXL 1.0,CXL协议目前已经发展了CXL 3.1。服务器目前正面临着内存性能挑战,而CXL部署提供了短期和长期的解决方案。从CXL 1.1开始,AI云服务器可以从内存扩展中受益,CXL 3.0为GPU、DPU、FPGA和ASIC等加速器提供直接访问内存池的权限。云服务提供商和超大规模企业将对由CXL 2.0发起的内存池和可组合服务器表现出浓厚的兴趣。同时,数据库服务器将利用运行更大的内存数据库以加快分析速度的能力。

数据中心工作负载变得越来越复杂,需要越来越多的计算能力和内存来处理不断增长的数据量。内存是一种非常昂贵的资源,2022年占服务器价值的平均比例约为30%,预计到2025年将超过40%。为了解决这些问题,已经提出了新型内存处理器接口,旨在优化资源的使用和加速数据中心工作负载的执行。在这种动态背景下,CXL已经崛起并获得了业界的广泛支持。
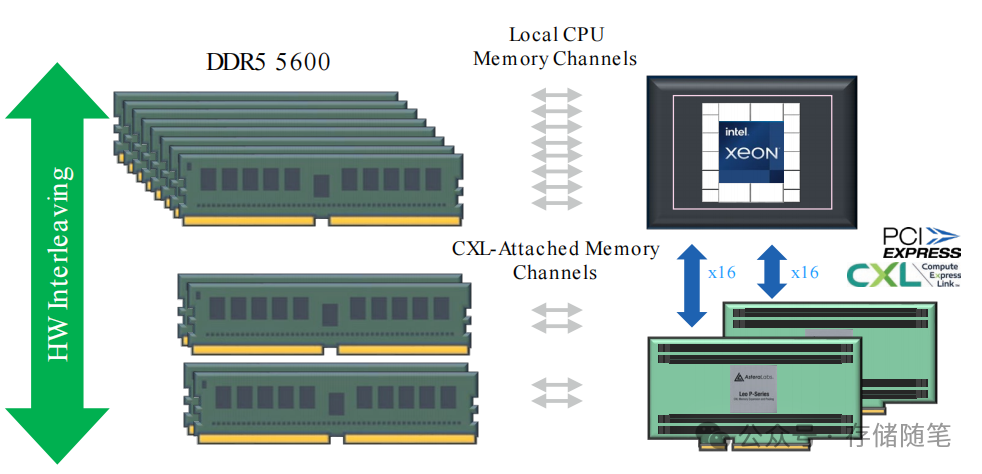
通过使用CXL(Compute Express Link)技术来突破内存墙。CXL通过提供一个高速、低延迟的互连标准,使得服务器能够外接更多的内存资源,而不局限于主板上的物理插槽。这样,服务器内存的带宽(数据传输速度)和容量得以显著提升,理论上可以达到现有配置的1.5倍,从而更好地满足高性能计算和大数据处理的需求。
二、CXL-PNM原理分析
既然,PIM近内存计算与CXL都有助于打破内存墙,那么,二者结合,又会发生什么?
CXL-PNM是一种类似于PIM(Processing In Memory)的技术,它通过在内存半导体中集成算术功能,使计算功能靠近数据存储位置。这种设计减少了数据在内存和处理器之间移动的距离,从而显著降低了延迟并减少了能量消耗。然而,对于现代机器学习应用而言,它们不仅需要处理内存密集型操作,还涉及到计算密集型任务。
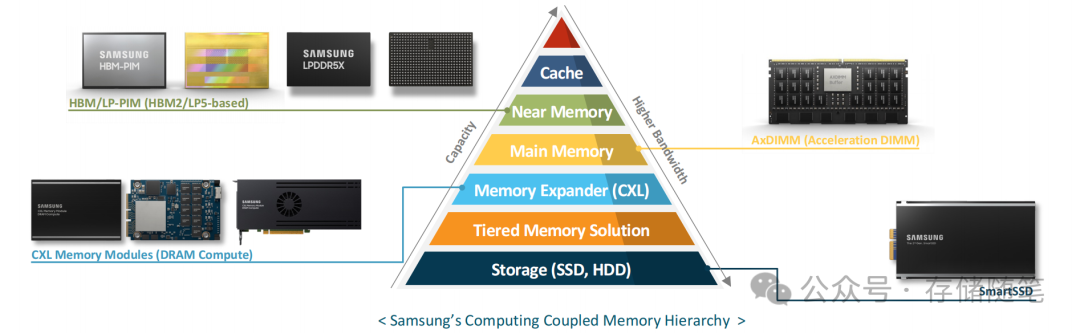
近期,在OCP峰会上,三星与Hynix均展示了CXL+PNM(Processing Near Memory)的解决方案,三星的解决方案叫做CMM-DC,Hynix的解决方案叫做CMM-Ax。

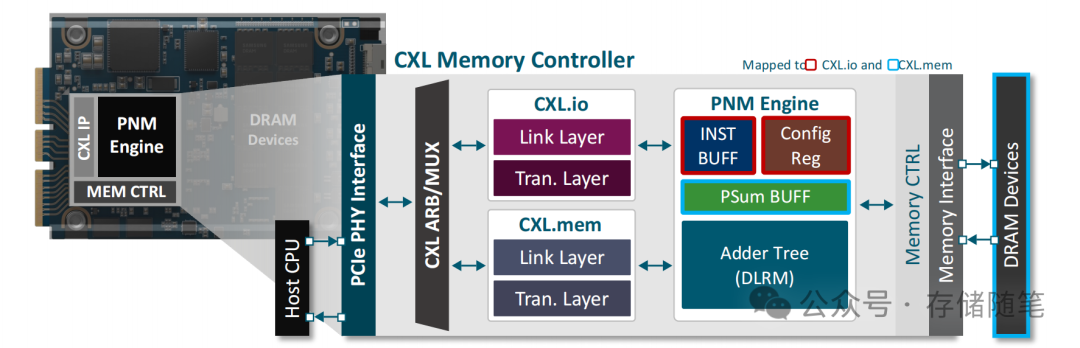
三星的CMM-DC是一种近内存处理解决方案,它通过将计算能力放置在靠近内存的位置来提高数据处理效率。

CMM-DC 在 CXL IP 和内存控制器之间放置了一个加速器 IP(PNM Engine),这个加速器专门设计用于处理内存密集型任务。
-
PNM Engine的作用:在数据存储位置附近执行计算任务,从而减少数据在内存与CPU之间传输的延迟。通过在内存附近执行计算,PNM Engine 可以显著提高数据密集型任务的处理效率,尤其是对于那些需要频繁访问内存的应用场景,如机器学习推理、数据库查询等。
-
CMM-DC 控制器的设计:CMM-DC控制器的设计将PNM Engine IP放置在CXL IP和内存控制器之间。这种设计使得PNM Engine可以直接与内存交互,并通过CXL IP与外部计算资源进行通信。
-
CXL.io 的连接:CXL.io协议是CXL标准的一部分,主要用于数据传输和通信。在CMM-DC解决方案中,通过CXL.io连接,加速器的控制器可以管理CMM-DC内部的各种功能块,如内存控制器、PNM Engine等,确保它们之间的通信顺畅无阻,并且能够协同工作以实现最佳性能。
三、CXL.io/PCIe 通信开销分析
CXL.io 和 PCIe 是两种用于高速互连的标准,它们被广泛应用于现代计算系统中,用于连接不同类型的设备,如CPU、内存、存储和加速器等。然而,在实际应用中,CXL.io 和 PCIe 的通信会带来一定的开销,特别是在延迟和处理器使用方面。
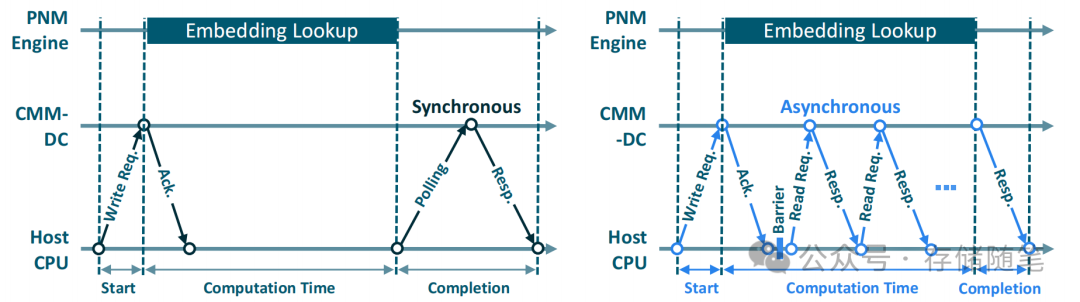
CXL.io/PCIe 的通信开销
-
延迟开销:CXL.io 和 PCIe 在进行设备间通信时会产生显著的延迟开销。这种延迟主要来自于协议栈的处理时间以及操作系统(OS)进行上下文切换(context switch)时产生的软件开销。
-
处理器使用率:除了延迟外,CXL.io 和 PCIe 的通信还会占用处理器资源,尤其是在进行启动/完成状态检查时需要频繁轮询(polling)的情况下。
轮询开销
-
轮询机制:为了检查某个任务是否开始或完成,系统通常会采用轮询的方式。然而,在CXL.io 和 PCIe 的环境中,轮询操作本身就需要耗费大约2~3微秒的时间。这在高频次的轮询操作中尤其明显,会对整体系统的性能产生负面影响。
-
轮询的影响:频繁的轮询不仅增加了处理器的负担,还可能导致其他关键任务得不到及时处理,从而影响系统的整体响应时间和吞吐量。
协议栈开销
-
协议栈处理时间:相较于CXL.mem(主要用于内存一致性通信),CXL.io 和 PCIe 在协议栈层面的处理时间更长。这意味着数据在传输过程中需要经过更多的处理步骤,从而增加了延迟。
-
上下文切换开销:当涉及到特权I/O设备(privileged I/O devices)的通信时,操作系统需要进行上下文切换来管理这些设备的通信。这种上下文切换会导致额外的软件开销,进而影响整体性能。
与 CXL.mem 的对比
-
CXL.mem 优势:CXL.mem 主要用于提供内存一致性通信,它在协议栈中的处理时间较短,因此延迟相对较低。CXL.mem 更适用于需要频繁访问内存且对延迟敏感的应用场景。
-
CXL.io/PCIe 适用场景:尽管 CXL.io 和 PCIe 在某些情况下会产生较大的开销,但在需要高速数据传输的应用中依然具有优势。例如,在数据传输量较大且对延迟要求相对宽松的场景下,CXL.io 和 PCIe 可以提供足够的带宽支持。
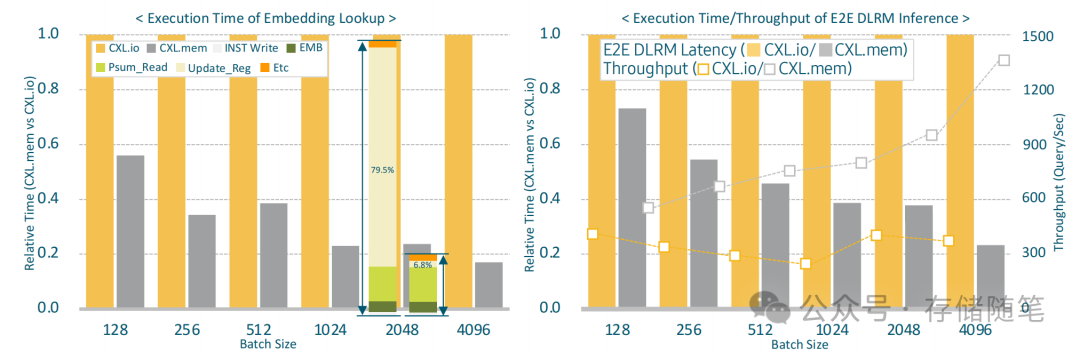
CXL.io 和 PCIe 在提供高速互连的同时,确实会在延迟和处理器使用方面产生一定的开销。这些开销主要来源于协议栈处理时间以及操作系统进行上下文切换时产生的软件开销。在需要频繁轮询的状态检查场景中,这种开销尤为显著。
与之相比,CXL.mem 在延迟方面表现更优,适用于需要低延迟内存访问的应用。CXL.mem 技术在 ML 推理中的应用,特别是在 DLRM 场景下,通过减少启动/完成检查的延迟,并优化数据传输过程,显著提高了推理任务的吞吐量和响应速度。这种技术的优势在于它能够更有效地管理内存一致性通信,并通过合理的任务分配,使得系统能够更好地利用计算资源。