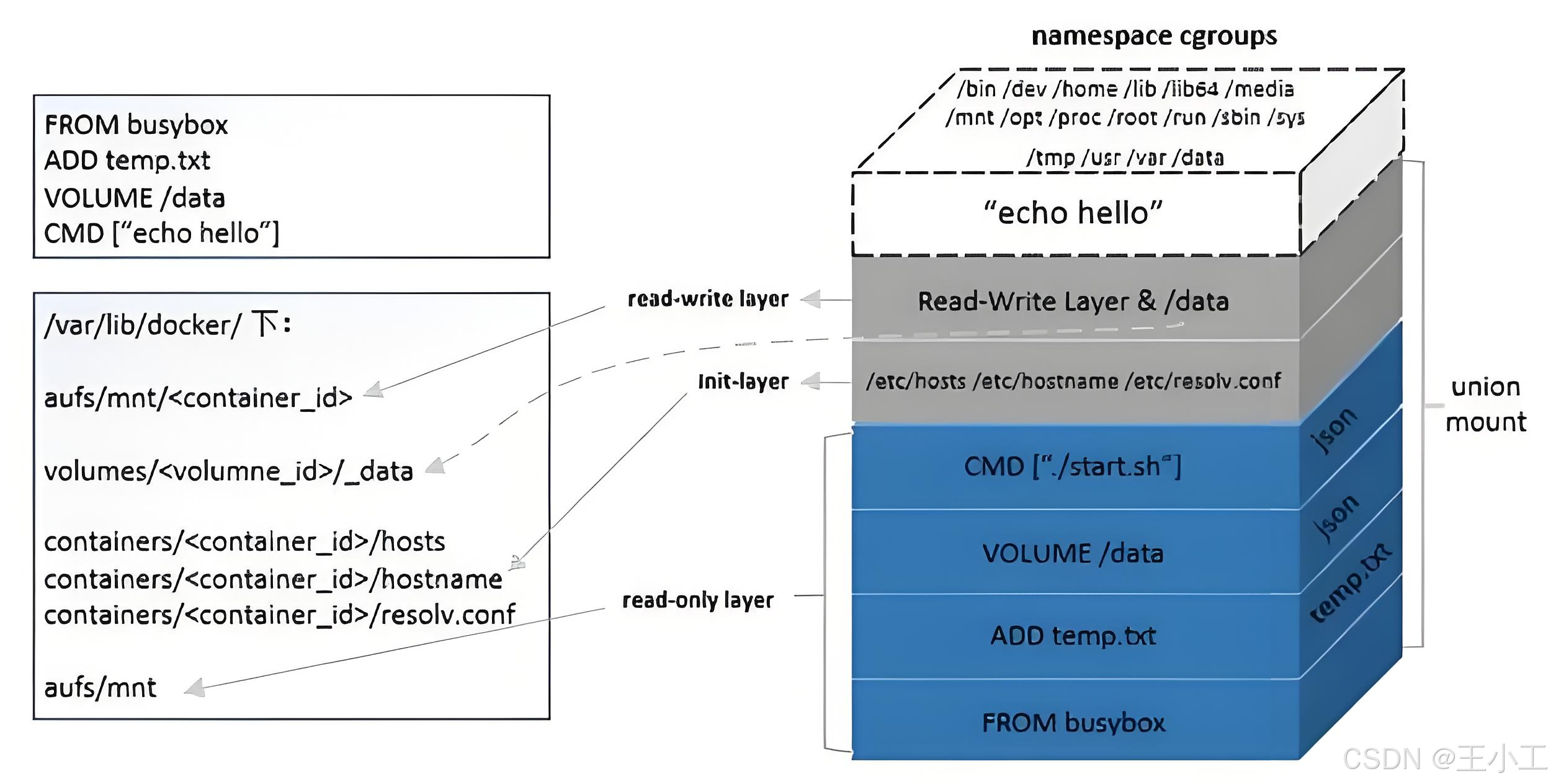
流程:
1. 连接链接获取页面内容(html文件);
2. 过滤获取需要信息(正则) [可能重复步骤1,2] ;
3. 存储文件到本地。
import urllib. request as request
import urllib. error as error
import requests
headers = {
'Connection' : 'keep-alive' ,
'Accept-Language' : 'zh-CN,zh;q=0.9' ,
'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8' ,
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' ,
}
def getHtml ( url) :
try :
req = request. Request( url)
webpage = request. urlopen( req)
html = webpage. read( )
return html
except error. URLError as e:
print ( str ( e. code) + '\t' + e. reason)
return None
def getXMLText ( url) :
try :
response = requests. get( url)
response. raise_for_status( )
response. encoding = "utf-8"
return response. text
except :
return None
def getHtmlWithHead ( url) :
req = request. Request( url, headers)
webpage = request. urlopen( req)
html = webpage. read( )
return html
def main ( ) :
url = input ( '输入网址: ' )
print ( getHtml( url) )
print ( getXMLText( url) )
if __name__ == '__main__' :
main( )
python用于爬虫的库: urllib, requests
urllib.request 用于打开和读取URL, (request.urlopen)
urllib.error 用于处理前面request引起的异常, (:403 Forbidden)
urllib.parse 用于解析URL,
urlopen(url, data=None, timeout=<object object at 0x000001D4652FE140>, *, cafile=None, capath=None, cadefault=False, context=None)。
1 . from bs4 import BeautifulSoup as bs:
soup = bs( html, 'html.parser' )
info = soup. find_all( 'div' , attrs= { 'class' : 'add' } )
info = soup. select( 'p' )
2 . import re
title = re. compile ( r'<h2>(.*?)</h2>' ) . search( str ( info) )
3 . str 字符操作
author = str ( info) . replace( '<p>' , '' ) . replace( '</p>' , '' ) . rstrip( )
import os
import time
dir = 'D:\\Python\\Data\\'
path = 'D:\\Python\\Data\\text.txt'
1 . create dir
isExists = os. path. exists( dir )
if not isExists:
os. mkdir( path)
2 . write: 'w' , 'wb'
file = open ( path, 'w' , encoding= 'utf-8' )
file . write( 'content' )
file . close( )
3 . read: 'r' , 'rb'
file = open ( path, 'rb' )