一.磁盘
1.磁盘物理结构
盘片
磁盘可以有多个磁片,每个磁片有两个盘面,每个盘面都对应一个磁头,都可以存储数据。

磁道 扇区
磁道是指在盘面上,由磁头读写的数据环形轨道。每个磁道都是由一圈圈的圆形区域组成,数据在这些区域内以磁性方式存储。
磁道由多个扇区组成,扇区是数据的最小存储单位。一个扇区大小一般为512字节。
每条磁道扇区个数相同,不同磁道的扇区大小也一样,但面积不一样,导致密度不同。

柱面
在多个盘片上,相同位置的磁道组成一个柱面。
例如,第一盘片的第一个磁道、第二盘片的第一个磁道,依此类推,构成一个“柱”。

2.磁盘存储结构
磁盘的基本单位不是字节,而是扇区。每个扇区的大小为512字节,扇区是数据的最小存储单位。
系统在写入数据时是按照从柱面到柱面的方式(从最外面的开始),当上一个柱面写满数据后才移动磁头到下一个柱面,而且是从柱面的第一个磁头的第一个扇区开始写入,从而使磁盘性能最优。
磁盘有多个磁片,一个磁片有两个盘面,每个盘面有多个磁道,每条磁道有多个扇区,每个扇区有512字节。
磁盘容量=磁头数(盘面数)*磁道数*每道的扇区数*512字节
如何找对应的扇区呢?
找到一个扇区大概流程如下:
1.首先找在哪一个面上。
2.再找在哪一个磁道(柱面)
3.再找在在哪一个扇区上.
这种叫做CHS 寻址方式
- C(Cylinder):柱面号
- H(Head):磁头号
- S(Sector):扇区号
注意:柱面号和磁头号下标从0开始,而扇区号从1开始。
3.磁盘逻辑结构
多个扇区组成磁道,我们把磁道剪开,把扇区看成数组元素,磁道就是一维数组。
半径相同的磁道构成柱面,我们把柱面剪开,就可以看成二维数组。
多个柱面构成磁盘,再剪开,就相当于三维数组。
本质上无论是三维还是二维数组都可以看成一维数组,我们就可以把磁盘抽象为下标从0开始的一维数组。
在一维数组中找对应扇区的方式叫做LBA寻址
- LBA 使用一个线性地址序列,从 0 开始编号,直接表示数据块的位置。这种方式比传统的 CHS(Cylinder-Head-Sector)寻址更为直观和简单。
CHS转LBA
本质上就是将三维数组转化为一维数组,找对应下标。
一个柱面上的扇区数=磁头数*一条磁道的扇区数
LBA=柱面号C*一个柱面上扇区数+磁头数H*一条磁道的扇区数+扇区数S-1
eg.CHS 地址 (C = 5, H = 2, S = 10)
LBA转CHS
柱面号C=LBA//一个柱面上的扇区数
磁头号H=(LBA%一个柱面上的扇区数)//一条磁道的扇区数
扇区号S=LBA%一条磁道的扇区数+1
//取整
二.文件系统
在文件系统中是如何存储文件的呢?

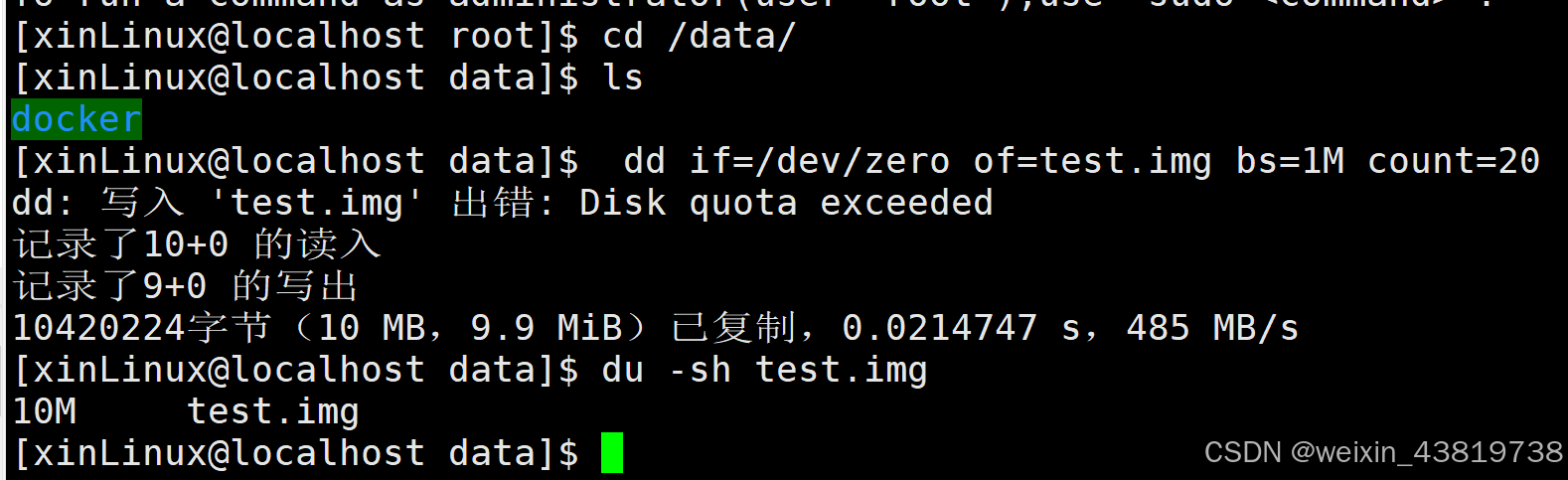
1.磁盘有500G的内存,先把500G分区,内存大小可能不一样,但加起来是500G。
2.再把一个区进行分组,管理好一个组,就相当于管好了一个区,其他区也这样管理,就管理好了整个磁盘。
Block group

inode Table
inode Table是存储inode的数据结构,相当于一个数组,里面存储的元素是inode,inode大小一般为128或者256字节。

什么是inode?
inode里面是整个小组的文件属性,包含i结点编号,文件的权限 创建时间 大小,以及blocks[NUM](用来找对应的文件内容)
struct inode { uint32_t i_mode; // 文件类型和权限 uint32_t i_uid; // 文件拥有者的用户ID uint32_t i_gid; // 文件拥有者的组ID uint32_t i_size; // 文件大小(字节) uint32_t i_atime; // 最后访问时间(Access time) uint32_t i_mtime; // 最后修改时间(Modification time) uint32_t i_ctime; // 最后状态更改时间(Change time) uint32_t i_links_count; // 硬链接计数 uint32_t i_blocks; // 文件占用的数据块数 uint32_t i_flags; // 文件标志(如只读等) uint32_t i_block[15]; // 指向数据块的指针(直接、间接、双间接、三级间接) };

Data Blocks
在这里面存储的就是文件的内容,我们知道一个扇区的大小为512字节,但系统在进行io交互的时候一般以一个块的大小进行,一个块的大小一般为4KB,相当于8个扇区。
Data Blocks里面就有很多块来存储文件内容。

inode Bitmap
我们怎么知道inode Table里面哪里存了数据,哪里没存呢?
inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用.
0000 0000 0001 就表示inode Table第一个位置存有文件属性。
我们知道进行io操作时,是以块为单位的。所以当我要修改bit位时,最少把一块4kb的内容读入内存中再修改,最后重新写入磁盘当中。
Block Bitmap
和inode Bitmap同理,记录Data Block的存储情况。
块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。
当我们新建一个文件时,系统进行的操作?
1.先在inode Bitmap中找bit位为0,并置为1.
2.在inode Table中找对应的数据块,并填入文件的属性。
3.如果文件大小小于4kb,只需要申请一块数据块,在Block Bitmap 找0置1.
4.在Data Block中找对应数据库并写入文件内容。
5.最后把文件在Data Block的位置(块号),填入inode中的blocks[NUM]中,建立映射关系。
Group Descriptor Table
GDT,Group Descriptor Table:块组描述符,它作用是对整个组进行管理。
记录还有多少个inode,还有多少个数据块。
每个组描述符存储以下关键信息:
- 块组编号:标识当前块组的索引。
- 起始数据块:该块组中数据块的起始位置。
- 起始 inode:该块组中 inode 的起始位置。这是 inode 表的开始地址,文件系统使用这个信息来访问和管理该块组中的 inode。
- 块和 inode 的计数:记录该块组中总的数据块数和 inode 数。
- 空闲数据块计数:当前块组中可用的数据块数。
- 空闲 inode 计数:当前块组中可用的 inode 数。
- 已分配数据块位图:指向一个位图,表示哪些数据块已被分配。
- 已分配 inode 位图:指向一个位图,表示哪些 inode 已被分配。
Super Block
它作用是对整个区进行管理。
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:整个区的bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
超级块提供整个区的文件系统信息,而组描述符表则为每个块组提供局部的管理信息。
超级块(Super Block)不是每个group里面都有,有多个分别在不同的组里面。不同组里面的超级块是一样的。
确保一个超级块有问题,可以用其它超级块来修复。增强数据安全性。
1.inode block是如何分配的呢?
在一个区中inode block都是唯一的,但每个组中都有inode Bitmap Block Bitmap,group0怎么知道group1有没有把inode=1分配出去呢?
其实在Group Descriptor Table中会记录起始 inode和起始 block。
inode的值是根据在位图中的位置和起始inode的值确定的。
比如说在inode Bitmap中第1个bit位的0置为1,起始inode=10000.分配的inode的值为10001
block分配同理。

2.inode block是如何映射的
我们知道inode映射block是靠一个数组int blocks[15]。里面存储的就是block的块号,但里面只有15个块号,最多找到60KB大小的文件内容。很显然这不对,那到底怎么找到全部的block呢?
unsigned long i_block[15]; // 数据块指针(12个直接、1个单级、1个双级、1个三级间接) 直接指针:直接指向文件数据块的地址,通常有几个(例如,12个直接指针)。 间接指针: 单级间接指针:指向一个数据块,该数据块包含其他数据块的指针。 双级间接指针:指向一个数据块,该数据块指向另一个间接块,间接块中又包含数据块的指针。 三级间接指针:类似于双级间接指针,进一步扩展了指针的深度。其实blocks前12个元素是直接存对应block的块号,
第13个是单级间接指针,指向一个数据块,该数据块包含其他数据块的块号,一个数据块4KB,一个块号1int,就可以存1024个块号。
第14个是双级间接指针,指向一个数据块,该数据块指向另一个间接块,间接块中又包含数据块的块号。双级间接指针 指向的数据块可以存1024*1024个块号。
...三级间接指针 指向的数据块可以存1024*1024*1024个块号。
使用指针可以实现动态扩展,可以让inode结构大小一致,简化了文件系统的管理,查看文件属性时更高效。
3.系统是如何找到目标文件的inode
我们知道任何文件都是有路径的。
要找到目标文件就要先找到它的上级目录。为什么?
因为目录本质也是文件,也有属性和内容,自然也有inode 和对应的block,而目录的数据块中就有文件/目录 的文件名和对应的inode
eg./home/user/dir1/document.txt
1.根目录的 inode 是固定的,系统会先读取根目录的 inode ./
2.找到 / 的inode映射到对应的block里面有子目录名和对应inode ./hmoe
3.再读取home目录的inode
4.找到 home 的inode映射到对应的block里面有子目录名和对应inode ./hmoe/user
5.继续重复读取目录inode,在block找目标目录的inode 直到找到目标文件
每次访问一个文件都要从/开始找吗?
是的,但是当访问某个目录时,操作系统会缓存该目录下的文件和子目录的信息。这样,如果后续访问相同的目录,就可以直接从缓存中获取信息,而无需再次访问磁盘。
三.软硬链接
1.创建软硬链接
1.硬链接
ln test.c test_link.c //创建硬链接
[wws@hcss-ecs-178e link]$ > test.c
[wws@hcss-ecs-178e link]$ ll
total 0
-rw-rw-r-- 1 wws wws 0 Oct 20 13:30 test.c
[wws@hcss-ecs-178e link]$ ln test.c test_link.c
[wws@hcss-ecs-178e link]$ ll
total 0
-rw-rw-r-- 2 wws wws 0 Oct 20 13:30 test.c
-rw-rw-r-- 2 wws wws 0 Oct 20 13:30 test_link.c
[wws@hcss-ecs-178e link]$ ll -i
total 0
789286 -rw-rw-r-- 2 wws wws 0 Oct 20 13:30 test.c
789286 -rw-rw-r-- 2 wws wws 0 Oct 20 13:30 test_link.cll -i 显示每个文件的 inode 号码。
看上面代码,我们可以看出两个细节。
1.用目标文件test.c创建的硬链接文件test_link.c的inode一样。
2.-rw-rw-r-- 1 wws wws 0 Oct 20 13:30 test.c
中间的数字1变为了2。代表什么意思?
789286 -rw-rw-r-- 2 wws wws 0 Oct 20 13:30 test.c
789286 -rw-rw-r-- 2 wws wws 0 Oct 20 13:30 test_link.c
1.硬链接文件inode和目标文件相同,说明它们实际上是同一个文件。只不过inode映射了两个文件名
2.789286 -rw-rw-r-- 2 wws wws 0 Oct 20 13:30 test.c中间的数字2表示有多少个硬链接指向该文件,本身算一个,再加上test_link.c硬链接,再加1。当把test.c test_link.c删除任意一个,链接数2->1。
[wws@hcss-ecs-178e link]$ ll total 0 -rw-rw-r-- 2 wws wws 0 Oct 20 13:30 test.c -rw-rw-r-- 2 wws wws 0 Oct 20 13:30 test_link.c [wws@hcss-ecs-178e link]$ rm test_link.c [wws@hcss-ecs-178e link]$ ll total 0 -rw-rw-r-- 1 wws wws 0 Oct 20 13:30 test.c采用引用计数的方式,只有当链接数0时,文件才会被删除。
2.软链接
ln -s test.c test_sl.c //-s 创建软链接
1.软链接文件inode和目标文件不同,说明软链接文件是一个独立的文件。
2.软链接文件和硬链接文件内容不同的是,硬链接与目标文件内容完全相同,因为它们指向同一个数据块,而软链接则是指向目标文件路径的引用。不管是软连接还是硬链接他们输出的结果和目标文件都是一样的。
硬链接就像拷贝,目标文件被删对硬链接文件没有影响。而软链接就像引用,目标文件被删这个引用就变得无效,无法访问。
2.软硬链接有什么作用
1.硬链接作用
1.对文件备份。我们找到硬链接文件的inode是独立的,而指向的block数据块和目标文件是同一个,只有当引用计数 链接数==0时,inode 以及对应的block才会被删除。
2.创建. ..硬链接目录快速定位不同目录
[wws@hcss-ecs-178e ~]$ mkdir empty [wws@hcss-ecs-178e ~]$ ll total 16 drwxrwxr-x 2 wws wws 4096 Oct 20 14:17 empty drwxrwxr-x 2 wws wws 4096 Oct 20 13:51 link -rw-rw-r-- 1 wws wws 63 Oct 12 14:30 makefile drwxrwxr-x 2 wws wws 4096 Oct 17 19:14 myshell新建的空目录的链接数为什么是2?
[wws@hcss-ecs-178e ~]$ ll -i total 16 789140 drwxrwxr-x 2 wws wws 4096 Oct 20 14:17 empty 789130 drwxrwxr-x 2 wws wws 4096 Oct 20 13:51 link 656101 -rw-rw-r-- 1 wws wws 63 Oct 12 14:30 makefile 789314 drwxrwxr-x 2 wws wws 4096 Oct 17 19:14 myshell [wws@hcss-ecs-178e ~]$ cd empty [wws@hcss-ecs-178e empty]$ ll -al -i total 8 789140 drwxrwxr-x 2 wws wws 4096 Oct 20 14:17 . 655895 drwxr-xr-x 12 wws wws 4096 Oct 20 14:17 ..其实在空目录中还有两个隐藏目录. .. empty目录下的. 目录就是empty的硬链接目录。
如果再在empty目录下再创建一个目录,那么新建目录的..目录也是empty的硬链接目录。
wws@hcss-ecs-178e empty]$ mkdir empty1 [wws@hcss-ecs-178e empty]$ cd .. [wws@hcss-ecs-178e ~]$ ll -i total 16 789140 drwxrwxr-x 3 wws wws 4096 Oct 20 14:23 empty
2.软链接作用
1.方便访问文件
如果有一个在深层目录的文件,可以对它创建软链接来简化路径,快速定位
ln -s /path/to/very/deep/directory/test.c test-soft.link2.指向目录
软连接可以指向目录,这在管理文件和目录时非常有用。例如,可以创建指向常用目录的软连接,使其更容易访问:
ln -s /home/user/documents/ my_docs
注意:
1.硬链接只能在同一个文件系统中创建。因为硬链接依赖于文件系统的inode结构。每个文件在文件系统中都有一个唯一的inode,硬链接直接引用该inode。
因此,如果尝试在不同的文件系统之间创建硬链接,系统会返回错误,因为不同的文件系统有各自独立的inode管理。2.硬链接不指向目录:通常不能创建指向目录的硬链接(为了避免循环引用)。
eg. ./dir1/dir2/dir3/hard->dir2 hard是dir2的软连接,这样dir2和hard就会形成一个环。
目录中的隐藏文件. ..除外,. ..是文件系统为每个目录自动管理的特殊链接,确保目录的完整性和正确性。
四.动静态库
1.静态库
1.创建静态库
1.首先准备.c文件里面是编写的源代码
2.使用编译器将源代码编译成目标文件.o
gcc -c file1.c # 生成 file1.o gcc -c file2.c # 生成 file2.o3.创建静态库
ar rcs libmylibrary.a file1.o file2.or插入文件 c创建库 s生成索引
lib库的前缀 .a后缀
2.链接静态库
头文件:例如
my_library.h,其中声明了库中的函数和数据结构。静态库:例如
libmylibrary.a,这是编译后的静态库文件。源文件:例如
main.c,你要编译和链接的主程序。
编译器和链接器会默认在特定的路径下查找头文件和库文件。
默认头文件查找路径:
/usr/include:主要的系统头文件目录,包含标准库和系统相关的头文件。/usr/local/include:用于存放本地安装的软件包的头文件,适合自定义库。默认库文件查找路径
/usr/lib:主要的库文件目录,包含标准库文件(如libc.a和libm.a)。/usr/local/lib:用于存放本地安装的软件包的库文件,适合自定义库。
1.我们可以把头文件 静态库放在系统的默认查找路径下,要用-l选项指明静态库名称
gcc main.c -lmylibrary -o my_program-l
功能:指定要链接的库的名称。
用法:链接时只需提供库名,而不需要前缀
lib和后缀.a或.so。
2.不放在默认路径下,我们可以给系统指定路径下找
假设你有一个名为
my_library.a的静态库,位于/opt/mylibs,以及一个头文件
my_library.h,位于/opt/myheaders,可以这样编译和链接:gcc -I/opt/myheaders -L/opt/mylibs main.c -lmylibrary -o my_program
-I选项功能:指定包含头文件的目录。
用法:通常用于编译阶段,帮助编译器找到源文件中使用的头文件。
-L选项功能:指定链接器搜索库文件的目录。
用法:在链接阶段使用,告诉链接器在指定目录中查找库文件。
2.动态库
1.创建动态库
1.首先准备.c文件里面是编写的源代码
2.使用编译器将源代码编译成目标文件.o
gcc -c -fPIC mathlib.c -o mathlib.o-fPIC选项,这表示生成位置无关的代码,
这类代码的特点是能够在内存中的任何地址加载并执行,非常适合用于创建动态链接库,因为动态库可以在多个程序中共享,并且在运行时可以被装载到任何地址。
3.创建动态库
-shared选项创建动态链接库gcc -shared -o libmathlib.so mathlib.o
2.链接动态库
链接动态库和链接静态库一样,可以把头文件和库放在系统的默认路径下或者 -I -L 给编译器指明特定路径,再用-l指明库名。
3.运行时找到动态库
动态库和静态库不同的是,静态库在编译完时 在库中用到的代码已经加载到程序当中,不再需要库了,即使删除静态库也不影响以后运行。但动态库在运行时才会被加载,所以程序在运行时仍需要找到动态库。
怎么才能让系统在运行时找到动态库?
1.使用
LD_LIBRARY_PATH环境变量:
LD_LIBRARY_PATH环境变量用于指定动态库的搜索路径。可以在终端中临时设置,export LD_LIBRARY_PATH=/path/to/your/library:$LD_LIBRARY_PATH或者在配置文件中(/.bashrc)写入 永久设置。
echo "export LD_LIBRARY_PATH=/path/to/your/library:$LD_LIBRARY_PATH" >> ~/.bashrc source ~/.bashrc //立即生效2.拷贝到系统的默认路径下 并更新 ldconfig
将动态库放在系统标准路径下,可以将其复制到
/usr/local/lib或/usr/lib目录,然后运行ldconfig。sudo cp /path/to/your/library/libmylibrary.so /usr/local/lib/ sudo ldconfig3.可以在系统的默认路径下创建软链接 并更新 ldconfig
sudo ln -s /path/to/your/library/libmylibrary.so /usr/local/lib/libmylibrary.so sudo ldconfig
注意:如果同时存在静态库和动态库文件,gcc g++会优先加载动态库。也可以在编译时加上-static选项指定静态库。
gcc main.c -L. -lmystatic -static -o my_program_static