我自己的原文哦~ https://blog.51cto.com/whaosoft/12286744
#自动驾驶的技术发展路线
端到端自动驾驶
- Recent Advancements in End-to-End Autonomous Driving using Deep Learning: A Survey
- End-to-end Autonomous Driving: Challenges and Frontiers
在线高精地图
- HDMapNet:基于语义分割的在线局部高精地图构建 (ICRA2022)
- VectorMapNet:基于自回归方式的端到端矢量化地图构建(ICML2023)
- MapTR : 基于固定数目点的矢量化地图构建 (ICLR2023)
- MapTRv2:一种在线矢量化高清地图构建的端到端框架
- PivotNet:基于动态枢纽点的矢量化地图构建 (ICCV2023)
- BeMapNet:基于贝塞尔曲线的矢量化地图构建 (CVPR2023)
- LATR: 无显式BEV 特征的3D车道线检测 (ICCV2023)
- TopoNet: 基于图的驾驶场景拓扑推理
- TopoMLP: 先检测后推理(拓扑推理 strong pipeline)
- LaneGAP:连续性在线车道图构建
- Neural Map Prior: 神经地图先验辅助在线建图 (CVPR2023)
- MapEX:现有地图先验显著提升在线建图性能
大模型与自动驾驶
- CLIP:Learning Transferable Visual Models From Natural Language Supervision
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
- MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
- InstructGPT:Training language models to follow instructions with human feedback
- ADAPT: Action-aware Driving Caption Transformer
- BEVGPT:Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning
- DriveGPT4:Interpretable End-to-end Autonomous Driving via Large Language Model
- Drive Like a Human Rethinking Autonomous Driving with Large Language Models
- Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
- HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving
- LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving
- Planning-oriented Autonomous Driving
- WEDGE A multi-weather autonomous driving dataset built from generative vision-language models
Nerf与自动驾驶
- NeRF: Neural Radiance Field in 3D Vision, A Comprehensive Review
- Neural Volume Rendering: NeRF And Beyond
- MobileNeRF:移动端实时渲染,Nerf导出Mesh(CVPR2023)
- Co-SLAM:实时视觉定位和NeRF建图(CVPR2023)
- Neuralangelo:当前最好的NeRF表面重建方法(CVPR2023)
- MARS:首个开源自动驾驶NeRF仿真工具(CICAI2023)
- UniOcc:NeRF和3D占用网络(AD2023 Challenge)
- Unisim:自动驾驶场景的传感器模拟(CVPR2023)
Occupancy占用网络
- Grid-Centric Traffic Scenario Perception for Autonomous Driving: A Comprehensive Review
BEV感知
- Vision-Centric BEV Perception: A Survey
- Vision-RADAR fusion for Robotics BEV Detections: A Survey
- Surround-View Vision-based 3D Detection for Autonomous Driving: A Survey
- Delving into the Devils of Bird’s-eye-view Perception: A Review, Evaluation and Recipe
多模态融合
针对Lidar、Radar、视觉等数据方案进行融合感知;
- A Survey on Deep Domain Adaptation for LiDAR Perception
- Automatic Target Recognition on Synthetic Aperture Radar Imagery:A Survey
- Deep Multi-modal Object Detection and Semantic Segmentation for Autonomous Driving:Datasets, Methods, and Challenges
- MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving:A Review
- Multi-Modal 3D Object Detection in Autonomous Driving:A Survey
- Multi-modal Sensor Fusion for Auto Driving Perception:A Survey
- Multi-Sensor 3D Object Box Refinement for Autonomous Driving
- Multi-View Fusion of Sensor Data for Improved Perception and Prediction in Autonomous Driving
3D检测
对基于单目图像、双目图像、点云数据、多模态数据的3D检测方法进行了梳理;
- 3D Object Detection for Autonomous Driving:A Review and New Outlooks
- 3D Object Detection from Images for Autonomous Driving A Survey
- A Survey of Robust LiDAR-based 3D Object Detection Methods for autonomous driving
- A Survey on 3D Object Detection Methods for Autonomous Driving Applications
- Deep Learning for 3D Point Cloud Understanding:A Survey
- Multi-Modal 3D Object Detection in Autonomous Driving:a survey
- Survey and Systematization of 3D Object Detection Models and Methods
目标检测综述
主要涉及通用目标检测任务、检测任务中的数据不均衡问题、伪装目标检测、自动驾驶领域检测任务、anchor-based、anchor-free、one-stage、two-stage方案等;
- A Survey of Deep Learning for Low-Shot Object Detection
- A Survey of Deep Learning-based Object Detection
- Camouflaged Object Detection and Tracking:A Survey
- Deep Learning for Generic Object Detection:A Survey
- Imbalance Problems in Object Detection:A survey
- Object Detection in 20 Years:A Survey
- Object Detection in Autonomous Vehicles:Status and Open Challenges
- Recent Advances in Deep Learning for Object Detection
目标检测数据增强与不均衡问题
主要涉及目标检测任务中的数据增强、小目标检测、小样本学习、autoargument等工作;
- A survey on Image Data Augmentation for Deep Learning
- Augmentation for small object detection
- Bag of Freebies for Training Object Detection Neural Networks
- Generalizing from a Few Examples:A Survey on Few-Shot
- Learning Data Augmentation Strategies for Object Detection
分割综述
主要对实时图像分割、视频分割、实例分割、弱监督/无监督分割、点云分割等方案展开讨论;
- A Review of Point Cloud Semantic Segmentation
- A SURVEY ON DEEP LEARNING METHODS FOR SEMANTIC IMAGE SEGMENTATION IN REAL-TIME
- A SURVEY ON DEEP LEARNING METHODS FOR SEMANTIC
- A Survey on Deep Learning Technique for Video Segmentation
- A Survey on Instance Segmentation State of the art
- A Survey on Label-efficient Deep Segmentation-Bridging the Gap between Weak Supervision and Dense Prediction
- A Technical Survey and Evaluation of Traditional Point Cloud Clustering for LiDAR Panoptic Segmentation
- Evolution of Image Segmentation using Deep Convolutional Neural Network A Survey
- On Efficient Real-Time Semantic Segmentation
- Unsupervised Domain Adaptation for Semantic Image Segmentation-a Comprehensive Survey
多任务学习
对检测+分割+关键点+车道线联合任务训练方法进行了汇总;
- Cascade R-CNN
- Deep Multi-Task Learning for Joint Localization, Perception, and Prediction
- Mask R-CNN
- Mask Scoring R-CNN
- Multi-Task Multi-Sensor Fusion for 3D Object Detection
- MultiTask-CenterNet
- OmniDet
- YOLOP
- YOLO-Pose
目标跟踪
对单目标和多目标跟踪、滤波和端到端方法进行了汇总;
- Camouflaged Object Detection and Tracking:A Survey
- Deep Learning for UAV-based Object Detection and Tracking:A Survey
- Deep Learning on Monocular Object Pose Detection and Tracking:A Comprehensive Overview
- Detection, Recognition, and Tracking:A Survey
- Infrastructure-Based Object Detection and Tracking for Cooperative Driving Automation:A Survey
- Recent Advances in Embedding Methods for Multi-Object Tracking:A Survey
- Single Object Tracking:A Survey of Methods, Datasets, and Evaluation Metrics
- Visual Object Tracking with Discriminative Filters and Siamese Networks:A Survey and Outlook
深度估计
针对单目、双目深度估计方法进行了汇总,对户外常见问题与精度损失展开了讨论;
- A Survey on Deep Learning Techniques for Stereo-based Depth Estimation
- Deep Learning based Monocular Depth Prediction:Datasets, Methods and Applications
- Monocular Depth Estimation Based On Deep Learning:An Overview
- Monocular Depth Estimation:A Survey
- Outdoor Monocular Depth Estimation:A Research Review
- Towards Real-Time Monocular Depth Estimation for Robotics:A Survey
关键点检测
人体关键点检测方法汇总,对车辆关键点检测具有一定参考价值;
- 2D Human Pose Estimation:A Survey
- A survey of top-down approaches for human pose estimation
- Efficient Annotation and Learning for 3D Hand Pose Estimation:A Survey
- Recent Advances in Monocular 2D and 3D Human Pose Estimation:A Deep Learning Perspective
Transformer综述
视觉transformer、轻量级transformer方法汇总;
- A Survey of Visual Transformers
- A Survey on Visual Transformer
- Efficient Transformers:A Survey
车道线检测
对2D/3D车道线检测方法进行了汇总,基于分类、检测、分割、曲线拟合等;
2D车道线
- A Keypoint-based Global Association Network for Lane Detection
- CLRNet:Cross Layer Refinement Network for Lane Detection
- End-to-End Deep Learning of Lane Detection and Path Prediction for Real-Time Autonomous Driving
- End-to-end Lane Detection through Differentiable Least-Squares Fitting
- Keep your Eyes on the Lane:Real-time Attention-guided Lane Detection
- LaneNet:Real-Time Lane Detection Networks for Autonomous Driving
- Towards End-to-End Lane Detection:an Instance Segmentation Approach
- Ultra Fast Structure-aware Deep Lane Detection
3D车道线
- 3D-LaneNet+:Anchor Free Lane Detection using a Semi-Local Representation
- Deep Multi-Sensor Lane Detection
- FusionLane:Multi-Sensor Fusion for Lane Marking Semantic Segmentation Using Deep Neural Networks
- Gen-LaneNet:A Generalized and Scalable Approach for 3D Lane Detection
- ONCE-3DLanes:Building Monocular 3D Lane Detection
- 3D-LaneNet:End-to-End 3D Multiple Lane Detection
SLAM综述
定位与建图方案汇总;
- A Survey on Active Simultaneous Localization and Mapping-State of the Art and New Frontiers
- The Revisiting Problem in Simultaneous Localization and Mapping-A Survey on Visual Loop Closure Detection
- From SLAM to Situational Awareness-Challenges
- Simultaneous Localization and Mapping Related Datasets-A Comprehensive Survey
模型量化
- A Survey on Deep Neural Network CompressionChallenges, Overview, and Solutions
- Pruning and Quantization for Deep Neural Network Acceleration A Survey
#自动驾驶仿真框架&模拟器汇总
好多年以来自动驾驶仿真基本上采用传统的仿真软件,很多年车企都完成了工具和方法闭环,不过应用范围仅限于主动安全功能,对于高阶/L3/L4/NOP/NOA功能应用较少。
最近几年的自动驾驶仿真出现了世界模型/强化学习/NeRF/扩散模型/LLM/Agent等新型技术,越来越多的供应商开始基于这些新技术、逐渐摆脱传统仿真软件,开发新兴的自动驾驶仿真框架&模拟器,为仿真带来了新的机遇。
本文汇总了传统仿真软件、新型仿真框架,以及仿真平台、光学仿真、仿真引擎,可作为学习、研究、开发的参考资料。
1.仿真引擎
Unity
Unity是由Unity Technologies开发的跨平台 游戏引擎,于 2005 年 6 月在Apple 全球开发者大会上作为Mac OS X游戏引擎首次宣布并发布。此后该引擎逐渐扩展到支持各种桌面、移动、控制台和虚拟现实平台。Unity在iOS和Android移动游戏开发中特别受欢迎,被认为对于初学者开发人员来说易于使用,并且在独立游戏开发中很受欢迎。该引擎可用于创建三维(3D)和二维(2D)游戏,以及交互式模拟和其他体验。
Unity 主页:https://unity.com/cn
Unity Doc:https://docs.unity.com/
Unity API:https://docs.unity3d.com/ScriptReference/
Unity Man:https://docs.unity3d.com/Manual/index.html
Unity 代码:https://github.com/Unity-Technologies
Unity Wiki:https://en.wikipedia.org/wiki/Unity_(game_engine)
UnityTechnologies Wiki:https://en.wikipedia.org/wiki/Unity_Technologies
UnrealEngine
Unreal Engine ( UE ) 是由Epic Games开发的一系列 3D 计算机图形游戏引擎,首次亮相于 1998 年的第一人称射击游戏Unreal。它最初是为PC第一人称射击游戏开发的,后来被用于各种类型的游戏,并被其他行业采用,尤其是电影和电视行业。虚幻引擎采用C++编写,具有高度可移植性,支持广泛的桌面、移动、控制台和虚拟现实平台。
最新一代虚幻引擎 5 于 2022 年 4 月推出。其源代码可在GitHub上获取,商业使用基于版税模式授予,Epic 收取收入超过 100 万美元的 5%,游戏免收这一费用发布在Epic Games Store上。\Epic 在引擎中加入了 Quixel 等被收购公司的功能,这被认为得益于《堡垒之夜》的收入。2014年,虚幻引擎被吉尼斯世界纪录评为全球“最成功的视频游戏引擎”
UnrealEngine 主页:https://www.unrealengine.com
UnrealEngine 代码:https://github.com/folgerwang/UnrealEngine
UnrealEngine 代码:https://github.com/20tab/UnrealEnginePython
UnrealEngine Wiki:https://en.wikipedia.org/wiki/Unreal_Engine
EpicGames:https://en.wikipedia.org/wiki/Epic_Games
Cognata
Cognata 主页:https://www.cognata.com/
Cognata 介绍:https://www.cognata.com/simulation/
Cognata 介绍:https://www.cognata.com/autonomous-vehicles/
OptiX
Nvidia OptiX(OptiX 应用加速引擎)是一种光线追踪 API,于 2009 年左右首次开,计算通==过CUDA引入的低级或高级API卸载到GPU。CUDA仅适用于Nvidia的图形产品。
Nvidia OptiX 是Nvidia GameWorks的一部分。OptiX 是一个高级或算法API,这意味着它旨在封装光线追踪所属的整个算法,而不仅仅是光线追踪本身。这是为了让 OptiX 引擎能够以极大的灵活性执行更大的算法,而无需应用程序端进行更改。
OptiX 主页:https://developer.nvidia.com/rtx/ray-tracing/optix
OptiX 下载:https://developer.nvidia.com/designworks/optix/download
OptiX Wiki:https://en.wikipedia.org/wiki/OptiX
2.仿真软件
VTD
VTD 是世界上使用最广泛的开放平台,用于创建、配置和动画化用于 ADAS 和自动驾驶车辆的训练、测试和验证的虚拟环境和场景。VTD 为第三方组件提供开放接口,并为第三方模块提供带有 API 的插件概念。其主要特点是在车辆控制、感知、驾驶员培训、人工智能系统训练数据生成和车辆测试台方面的各种应用。
VTD在传感器仿真、复杂场景创建、车辆和行人建模以及车辆动力学方面具有强大的能力。
VTD 主页:https://hexagon.com/products/virtual-test-drive
VTD ASAM:https://www.asam.net/members/product-directory/detail/virtual-test-drive-vtd/
VTD 华为云八爪鱼:https://support.huaweicloud.com/usermanual-octopus/octopus-03-0011.html
CARLA
CARLA 是一个用于自动驾驶研究的开源模拟器。CARLA 的开发是为了支持自动驾驶系统的开发、培训和验证。除了开源代码和协议之外,CARLA 还提供为此目的创建的开放数字资产(城市布局、建筑物、车辆),并且可以自由使用。该仿真平台支持灵活的传感器套件和环境条件规范。

CARLA 主页:https://carla.org//
CARLA 代码:https://github.com/carla-simulator/carla
CARLA 文档:https://carla.readthedocs.io/en/latest/start_introduction/
CARLA 文档:https://carla.readthedocs.io/en/latest/
CARLA 论文:https://arxiv.org/abs/1711.03938
CarSim
CarSim是专门针对车辆动力学的仿真软件,CarSim模型在计算机上运行的速度比实时快3-6倍,可以仿真车辆对驾驶员,路面及空气动力学输入的响应,主要用来预测和仿真汽车整车的操纵稳定性、制动性、平顺性、动力性和经济性,同时被广泛地应用于现代汽车控制系统的开发。CarSim可以方便灵活的定义试验环境和试验过程,详细的定义整车各系统的特性参数和特性文件。

CarSim 主页:https://www.carsim.com/
CarSim 主页:https://www.carsim.com/products/carsim/index.php
CarSim 介绍:https://www.carsim.com/products/carsim/
CarSim 介绍:https://www.carsim.com/downloads/pdf/CarSim_Introduction.pdf
CarSim 文档:https://carsim.readthedocs.io/en/latest/
BikeSim
BikeSim 提供最准确、详细且高效的方法来模拟两轮和三轮车辆的性能。经过二十多年的实际验证,BikeSim 已成为分析摩托车动力学、开发主动控制器、计算整体系统性能和设计下一代主动安全系统的普遍首选工具。

BikeSim 主页:https://www.carsim.com/products/bikesim/index.php
TruckSim
Trucksim是汽车动力学模型仿真软件,可以和Simulink连接实现整车控制,TruckSim的优点是动力学模型搭建过程简单,参数化配置整车参数,可将动力学模型搭建的较为科学,缺点是不够灵活,没有基于电机的新能源车辆动力学仿真模型。
TruckSim 主页:https://www.carsim.com/products/trucksim/index.php
TruckSim 介绍:https://www.carsim.com/users/pdf/release_notes/trucksim/TruckSim2024_New_Features.pdf
TruckSim 介绍:
SuspensionSim
SuspensionSim 模拟应用于悬架系统的准静态运动学和合规性 (K&C) 测试。SuspensionSim 在几个方面与车辆模拟产品 BikeSim、CarSim 和 TruckSim 有所不同。SuspensionSim 没有使用具有特定多体模型的预定义参数程序,而是使用基于用户数据集构建模型的多体求解器程序
SuspensionSim 主页:https://www.carsim.com/products/suspensionsim/index.php
SuspensionSim 介绍:https://www.carsim.com/downloads/pdf/SuspensionSim_Handout_Letter.pdf
VehicleSim
Mechanical Simulation Corporation 生产和分销软件工具,用于模拟和分析机动车辆响应转向、制动、油门、道路和空气动力学输入的动态行为。VS SDK 是一个软件开发工具包。这意味着它包含以尽可能少的配置来处理项目所需的所有工具、库、文档和示例项目。
VehicleSim 主页:https://www.carsim.com/products/supporting/vehiclesim/vs_api.php
VehicleSim SDK:https://www.carsim.com/users/vs_sdk/index.php
CarMaker
仿真解决方案 CarMaker 专为在所有开发阶段(MIL、SIL、HIL、VIL)的汽车和轻型车辆的开发和无缝测试而设计。开放式集成和测试平台允许为无人驾驶、ADAS、动力总成和车辆动力学等应用领域实施虚拟测试场景。借助高分辨率 3D 可视化工具 MovieNX,可提供照片级的真实画质。各种支持的标准和接口也保证了与现有工具环境的顺利集成。


CarMaker 主页:https://ipg-automotive.com/cn/products-solutions/software/carmaker/
CarMaker 教程:https://ipg-automotive.com/en/know-how/multimedia/online-tutorials/
CarMaker 与 Simulink 配合使用:https://www.mathworks.com/products/connections/product_detail/carmaker.html
TruckMaker
TruckMaker 仿真解决方案专门针对卡车、工程车辆、公共汽车、中型卡车、重型卡车和特种车辆等重型车辆的开发和测试要求量身定制。TruckMaker 可以在虚拟世界中对真实世界的测试场景进行准确建模,并提高开发过程的敏捷性。根据汽车系统工程方法,使用 TruckMaker 进行虚拟车辆测试可以在现实场景中对整个车辆的整个系统进行无缝开发、校准、测试和验证。
TruckMaker 主页:https://ipg-automotive.com/cn/products-solutions/software/truckmaker/
MotorcycleMaker
虚拟试驾有助于应对当今车辆开发的挑战。MotorcycleMaker 专门针对开发和测试摩托车、电动自行车或踏板车等机动两轮车的要求。MotorcycleMaker 能够在虚拟世界中对真实测试场景进行准确建模,并提高开发流程的敏捷性。根据汽车系统工程方法,MotorcycleMaker 的虚拟试驾可以在现实场景中实现整个车辆的整个系统的无缝开发、校准、测试和验证。
MotorcycleMaker 主页:https://ipg-automotive.com/en/products-solutions/software/motorcyclemaker/
AirSim
AirSim(航空信息学和机器人模拟)是一款开源跨平台模拟器,适用于无人机、汽车等地面车辆和各种其他物体,建立在Epic Games专有的虚幻引擎 4之上,作为人工智能研究平台。它由微软开发,可用于试验自动驾驶汽车的深度学习、计算机视觉和强化学习算法。这允许测试自主解决方案,而不必担心现实世界的损坏。
AirSim 提供约 12 公里的道路和 20 个城市街区以及API,以便以独立于平台的方式检索数据和控制车辆。API 可通过多种编程语言访问,包括C++、C#、Python和Java。AirSim 支持带有驱动轮和飞行控制器(例如 PX4)的硬件在环,以实现物理和视觉上的真实模拟。该平台还支持常见的机器人平台,例如机器人操作系统(ROS)。它被开发为一个虚幻插件,可以放入任何虚幻环境中。Unity插件的实验版本也已发布。

AirSim 主页:https://www.unrealengine.com/
AirSim 介绍:https://microsoft.github.io/AirSim/
AirSim 文档:https://amov-wiki.readthedocs.io/zh-cn/latest/docs/AirSim%E4%BB%BF%E7%9C%9F.html
AirSim 代码:https://github.com/microsoft/AirSim
AirSim Wiki:https://en.wikipedia.org/wiki/AirSim
PreScan
Simcenter Prescan 是一个基于物理的仿真平台,用于涉及自动化的行业,用于开发基于雷达、激光雷达、摄像头、超声波传感器和 GPS 等传感器技术的高级驾驶辅助系统 (ADAS) 和自动驾驶系统 (ADS) 。
Simcenter Prescan 还用于测试车辆对车辆 (V2V) 和车辆对基础设施 (V2I) 通信应用。Simcenter Prescan 可以访问经过验证的传感器模型和材料物理响应,作为一系列有意义的保真度级别的一部分。此外,还包括准确的车辆动力学模型,并且可以轻松填充交通。Simcenter Prescan 有助于将被测系统集成到仿真环路中,并可以将其大规模部署到集群或云中,为验证提供必要的覆盖范围。
Simcenter Prescan 提供了一个编辑器来定义场景以及一个运行时环境来执行场景。
PreScan 主页:https://plm.sw.siemens.com/en-US/simcenter/autonomous-vehicle-solutions/prescan/
PreScan Mathworks:https://www.mathworks.com/products/connections/product_detail/prescan.html
Constellation
NVIDIA Omniverse 是一个模块化开发平台,用于构建 3D 工作流程、工具、应用程序和服务。基于Pixar的通用场景描述(OpenUSD)、NVIDIA RTX 和NVIDIA AI技术,开发人员使用 Omniverse 为工业数字化和感知 AI 应用构建实时 3D 模拟解决方案。
Constellation 主页:https://developer.nvidia.com/omniverse
Constellation 代码:https://github.com/NVIDIA-Omniverse
Constellation Python API:https://docs.omniverse.nvidia.com/isaacsim/latest/reference_python_api.html
Constellation Doc:https://docs.omniverse.nvidia.com/
Constellation Guide:https://docs.omniverse.nvidia.com/dev-guide/latest/index.html
LGSVL


LGSVL 主页:https://www.svlsimulator.com/
LGSVL 代码:https://github.com/lgsvl/simulator
LGSVL文档:https://www.svlsimulator.com/docs/
LGSVL 论文:https://arxiv.org/abs/2005.03778
Omniverse
NVIDIA Omniverse 是一个模块化开发平台,用于构建 3D 工作流程、工具、应用程序和服务。基于 Pixar的通用场景描述(OpenUSD)、NVIDIA RTX 和NVIDIA AI技术,开发人员使用 Omniverse 为工业数字化和感知 AI 应用构建实时 3D 模拟解决方案。
Omniverse 主页:https://developer.nvidia.com/omniverse
Omniverse 代码:https://github.com/NVIDIA-Omniverse
Panosim
PanoSim是由国内一家创业公司联合吉大、北航等高校资源开发的一款智能驾驶汽车仿真软件平台。软件以智能驾驶汽车全栈仿真为开发目标,具有完整的场景模型、传感器模型和车辆模型,可用于智能驾驶算法的快速开发和验证。

Panosim 主页:https://www.panosim.com/
PanoSim自动驾驶仿真测试平台 介绍:https://www.zhihu.com/column/c_1510268115455426560
基于PanoSim5.0虚拟仿真平台的自主代客泊车AVP系统开发教程 介绍:
SUMMIT
SUMMIT(大规模混合交通中的城市驾驶模拟器)是一款开源模拟器,专注于为复杂的现实世界地图上不受管制的密集城市交通生成高保真交互式数据。它与 OSM 文件和 SUMO 网络形式的地图数据配合使用,生成具有复杂且现实的不受监管行为的异构交通代理群体。SUMMIT 可以使用从在线来源获取的地图数据,提供几乎无限的复杂环境来源。
SUMMIT还公开了与地图数据提供的上下文信息进行交互的接口。它还提供了一套强大的几何实用程序供外部程序使用。通过这些,SUMMIT 旨在实现感知、车辆控制和规划、端到端学习等广泛领域的应用。SUMMIT 是在非常成功的 CARLA 基础上建立的。CARLA 的更新不断合并到 SUMMIT 中,以确保 SUMMIT 的用户能够获得 CARLA 赋予的高质量工作,例如其高保真物理、渲染和传感器;、然而,应该指出的是,并非 SUMMIT 的所有组件都可以与 CARLA 的组件兼容,因为它们是针对不同的用例而设计的。

SUMMIT Doc:https://adacompnus.github.io/summit-docs/
SUMMIT 代码:https://github.com/AdaCompNUS/summit
SUMO
城市交通模拟(SUMO)是一个开源、高度可移植、微观和连续的交通模拟软件包,旨在处理大型网络。它允许进行包括行人在内的联运模拟,并附带大量用于场景创建的工具。它主要由德国航空航天中心运输系统研究所的员工开发。
SUMO 主页:https://sumo.dlr.de/docs/index.html
SUMO 主页:https://eclipse.dev/sumo/
SUMO 文档:https://sumo.dlr.de/docs/index.html
SUMO 论文:https://elib.dlr.de/127994/
SUMO 代码:https://github.com/eclipse-sumo/sumo
OpenCDA
OpenCDA 是一种集成了原型协同驾驶自动化(CDA;参见 SAE J3216)管道以及常规自动驾驶组件(例如感知、定位、规划、控制)的仿真工具。该工具集成了自动驾驶仿真(CARLA)、交通仿真(SUMO)和联合仿真(CARLA + SUMO)。
OpenCDA 基于标准自动驾驶系统 (ADS) 平台,专注于车辆、基础设施和其他道路使用者(例如行人)之间的各类数据交换和合作。OpenCDA全部采用 Python 语言。目的是使研究人员能够快速原型设计、模拟和测试 CDA 算法和功能。通过应用我们的仿真工具,用户可以方便地对其定制算法进行特定任务评估(例如目标检测精度)和管道级评估(例如交通安全)。

OpenCDA 文档:https://opencda-documentation.readthedocs.io/en/latest/index.html
OpenCDA 介绍:https://opencda-documentation.readthedocs.io/en/latest/md_files/introduction.html
OpenCDA 代码:https://github.com/ucla-mobility/OpenCDA
OpenCDA 论文:https://ieeexplore.ieee.org/document/9564825
OpenCDA 论文:https://arxiv.org/abs/2301.07325
OpenCDA-ROS
OpenCDA-ROS,它基于开源框架 OpenCDA 和机器人操作系统 (ROS) 的优势,将 ROS 的实际部署能力与 OpenCDA 成熟的 CDA 研究框架和基于仿真的评估无缝综合起来以填补上述空白。
OpenCDA-ROS 将利用 ROS 和 OpenCDA 的优势,促进仿真和现实世界中关键 CDA 功能的原型设计和部署,特别是协作感知、地图绘制和数字孪生、协作决策和运动规划以及智能基础设施服务。
OpenCDA-ROS 论文:https://ieeexplore.ieee.org/document/10192346
RoadRunner
RoadRunner 是一款交互式编辑器,可让开发者设计用于模拟和测试自动驾驶系统的 3D 场景。开发者可以通过创建特定于区域的路标和标记来自定义道路场景。可以插入标志、信号灯、护栏和道路损坏,以及树叶、建筑物和其他 3D 模型。
RoadRunner 提供用于设置和配置交叉口交通信号计时、相位和车辆路径的工具。RoadRunner 支持激光雷达点云、航空图像和 GIS 数据的可视化。开发者可以使用OpenDRIVE导入和导出道路网络。使用 RoadRunner 构建的 3D 场景可以以 FBX 、glTF、OpenFlight、OpenSceneGraph、OBJ 和 USD 格式导出。导出的场景可用于自动驾驶模拟器和游戏引擎,包括 CARLA、Vires VTD、NVIDIA DRIVE Sim、 rFpro、百度 Apollo、 Cognata、Unity和Unreal Engine。

RoadRunner 主页:https://www.mathworks.com/products/roadrunner.html
TADSim
TADSim 百科:https://baike.baidu.com/item/TAD%20Sim/63745889?fr=ge_ala
腾讯发布自动驾驶仿真平台TAD Sim 2.0:https://zhuanlan.zhihu.com/p/150694950
TADSim 论文:https://dl.acm.org/doi/10.1145/2699715
51SimOne
51World 主页:https://wdp.51aes.com/
51World 介绍:https://www.51vr.com.au/technology/city
51SimOne开源版已正式发布,助力国产自主智能驾驶仿真平台搭建:https://zhuanlan.zhihu.com/p/475293607
PTV-Vissim
PTV Vissim是由位于德国卡尔斯鲁厄的PTV Planung Transport Verkehr AG开发的微观多模态交通流仿真软件包。PTV Vissim 于 1992 年首次开发,如今已成为全球市场的领导者。
PTV-Vissim 主页:https://www.ptvgroup.com/en/products/ptv-vissim
[TV-Vissim Wiki:https://en.wikipedia.org/wiki/PTV_VISSIM
PTV-Visum
PTV Visum 是世界领先的交通规划软件。它是交通网络和交通需求、公共交通规划以及交通战略和解决方案开发的宏观模拟和宏观建模的标准。借助 PTV Visum,开发者可以创建交通模型,为长期战略规划和短期运营使用提供见解。
PTV-Visum 主页:https://www.ptvgroup.com/en/products/ptv-vissim
PTV-Flows
PTV Flows 使交通运营商能够轻松地实时监控和预测交通。通过利用机器学习、最先进的算法和自动警报,PTV Flows 使城市和道路当局能够优化其交通管理,而无需大量资源或复杂的基础设施。
因此,PTV Flows 附带 自动更新的网络地图和 来自覆盖广泛的主要提供商的浮动汽车数据 (FCD) 。该软件可以从浏览器运行,也可以通过 API 集成到现有系统中。
PTV-Flows 主页:https://www.ptvgroup.com/en/products/ptv-flows
Dyna4
DYNA4 是一个开放的模拟环境,用于汽车和商用车的虚拟试驾。物理模型包括车辆动力学、动力总成、内燃机、电动机、传感器和交通。使用 DYNA4 进行虚拟试驾有助于安全高效的功能开发和测试。PC 上的闭环仿真比实时运行速度更快,例如用于早期开发阶段(MIL、SIL),或者当 ECU 可用时可以在硬件在环系统(HIL)上执行。
DYNA4 的道路基础设施和交通 3D 环境模拟为环境感知发挥关键作用的辅助和自动驾驶提供了虚拟测试场。
Dyna4 ASAM:https://www.asam.net/members/product-directory/detail/dyna4/
Dyna4 Vector:https://www.vector.com/int/en/products/products-a-z/software/dyna4/
3.仿真框架
PGDrive
为了更好地评估和提高端到端驾驶的泛化能力,引入了一种开放式且高度可配置的驾驶模拟器,称为 PGDrive,遵循程序生成的关键特征。首先通过所提出的生成算法通过对基本路块进行采样来生成不同的道路网络。然后它们被转变为交互式训练环境,其中呈现具有真实运动学的附近车辆的交通流。

PGDrive 主页:https://www.pgdrive.com/
PGDrive 介绍:https://decisionforce.github.io/pgdrive/
PGDrive Doc:https://pgdrive.readthedocs.io/en/latest/
PGDrive 代码:https://github.com/decisionforce/pgdrive
PGDrive 论文:https://arxiv.org/abs/2012.13681
MetaDrive
MetaDrive 是一款驾驶模拟器,具有以下主要功能:
组合:它支持生成具有各种道路地图和交通设置的无限场景,用于可泛化强化学习的研究。
轻量级:易于安装和运行。它可以在标准 PC 上运行高达 +1000 FPS。
真实:准确的物理模拟和多种感官输入,包括激光雷达、RGB 图像、自上而下的语义图和第一人称视图图像。
MetaDrive 主页:https://metadriverse.github.io//metadrive/
MetaDrive 代码:https://github.com/metadriverse/metadrive
MetaDrive 论文:https://arxiv.org/abs/2109.12674
SimulationCity
SimulationCity 主页:https://www.theverge.com/2021/7/6/22565448/waymo-simulation-city-autonomous-vehicle-testing-virtual
SimulationCity 主页:https://waymo.com/blog/2021/06/SimulationCity.html
CarCraft
Waymo 模拟正在教授自动驾驶汽车宝贵的技能:https://www.engadget.com/2017-09-11-waymo-self-driving-car-simulator-intersection.html
走进 WAYMO 训练自动驾驶汽车的秘密世界:https://www.theatlantic.com/technology/archive/2017/08/inside-waymos-secret-testing-and-simulation-facilities/537648/
模拟如何将一盏闪烁的黄灯变成数千小时的体验:https://medium.com/waymo/simulation-how-one-flashing-yellow-light-turns-into-thousands-of-hours-of-experience-a7a1cb475565
UniSim
UniSim,这是一种神经传感器模拟器,它采用配备传感器的车辆捕获的单个记录日志,并将其转换为现实的闭环多传感器模拟。
UniSim 构建神经特征网格来重建场景中的静态背景和动态角色,并将它们组合在一起,以在新视点(添加或删除角色以及在新位置)模拟 LiDAR 和相机数据。为了更好地处理外推视图,结合了动态对象的可学习先验,并利用卷积网络来完成看不见的区域。实验表明 UniSim 可以在下游任务上模拟具有小域间隙的真实传感器数据。
UniSim 项目:https://waabi.ai/unisim/
UniSim 论文:https://arxiv.org/abs/2308.01898
UniSim 解读:https://zhuanlan.zhihu.com/p/636695025
MARS
提出了一种基于神经辐射场(NeRF)的自动驾驶模拟器。与现有作品相比,我们的作品具有三个显着特点:
1).实例感知:该模拟器使用独立的网络分别对前景实例和背景环境进行建模,以便可以单独控制实例的静态(例如大小和外观)和动态(例如轨迹)属性。
2).模块化:该模拟器允许在不同的现代 NeRF 相关主干、采样策略、输入模式等之间灵活切换,这种模块化设计能够促进基于 NeRF 的自动驾驶模拟的学术进步和工业部署。
3).真实:考虑到最佳模块选择,我们的模拟器设置了新的最先进的照片写实效果。

MARS 论文:https://arxiv.org/abs/2307.15058
MARS 代码:https://github.com/OPEN-AIR-SUN/mars
MARS 项目:https://open-air-sun.github.io/mars/
MARS 作者:https://sites.google.com/view/fromandto
MARS 解读:https://zhuanlan.zhihu.com/p/653536221
MagicDrive
MagicDrive,这是一种新颖的街景生成框架,提供多种 3D 几何控制,包括相机姿势、道路地图和 3D 边界框,以及通过定制编码策略实现的文本描述。此外,该设计结合了跨视图注意模块,确保多个摄像机视图之间的一致性。借助 MagicDrive,实现了高保真街景合成,可捕捉细致入微的 3D 几何形状和各种场景描述,从而增强 BEV 分割和 3D 对象检测等任务。

MagicDrive 论文:https://arxiv.org/abs/2310.02601
MagicDrive 代码:https://github.com/cure-lab/MagicDrive
MagicDrive 项目:https://gaoruiyuan.com/magicdrive/
MagicDrive 解读:https://zhuanlan.zhihu.com/p/663261335
DrivingGaussian
这是一个对动态自动驾驶场景的高效且有效的框架。对于具有移动物体的复杂场景,首先使用增量静态 3D 高斯函数顺序渐进地对整个场景的静态背景进行建模。然后,利用复合动态高斯图来处理多个移动对象,单独重建每个对象并恢复它们在场景中的准确位置和遮挡关系。
一步使用 LiDAR 先验进行高斯散射来重建具有更多细节的场景并保持全景一致性。DrivingGaussian 在驾驶场景重建方面优于现有方法,并能够实现具有高保真度和多摄像头一致性的逼真环视合成。
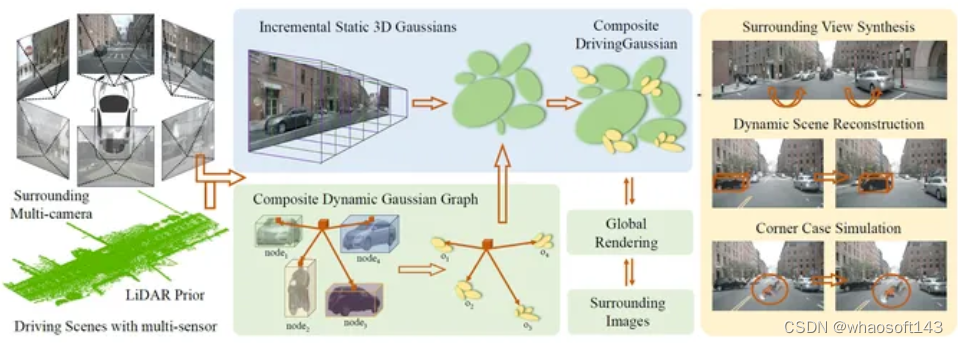
DrivingGaussian 论文:https://arxiv.org/abs/2312.07920
DrivingGaussian 项目:https://pkuvdig.github.io/DrivingGaussian/
NeuRAD
提出了 NeuRAD,这是一种针对动态 AD 数据量身定制的稳健新颖的视图合成方法。在五个流行的 AD 数据集上验证了其性能,全面实现了最先进的性能。该方法具有简单的网络设计、针对相机和激光雷达的广泛传感器建模(包括卷帘快门、光束发散和光线下降),并且适用于开箱即用的多个数据集。

NeuRAD 论文:https://arxiv.org/abs/2311.15260
NeuRAD 代码:https://github.com/georghess/NeuRAD
NeuRAD 解读:https://zhuanlan.zhihu.com/p/673873117
EmerNeRF
EmerNeRF基于NeRF,可以自监督地同时捕获野外场景的几何形状、外观、运动和语义。EmerNeRF将场景分层为静态场和动态场,在instant-NGP对三维空间进行Hash的基础上,多尺度增强动态对象的渲染精度。通过结合静态场、动态场和光流(场景流)场,EmerNeRF能够在不依赖于有监督动态对象分割或光流估计的前提下表示高度动态的场景,并实现了最先进的性能。
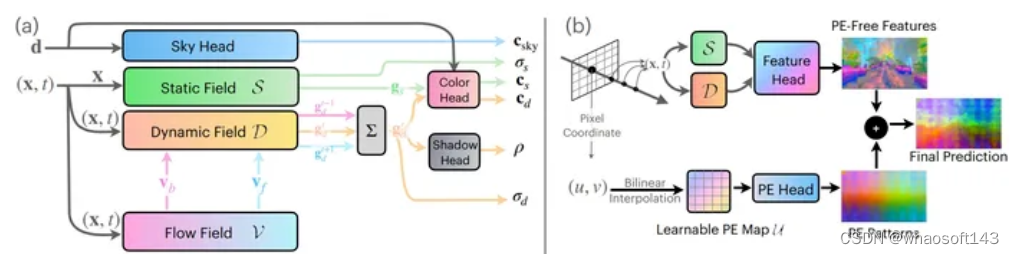
EmerNeRF 论文:EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision
EmerNeRF 项目:https://emernerf.github.io/
EmerNeRF 代码:https://github.com/NVlabs/EmerNeRF
EmerNeRF 解读:https://zhuanlan.zhihu.com/p/674024253
Panacea
Panacea,这是一种在驾驶场景中生成全景和可控视频的创新方法,能够生成无限数量的多样化、带注释的样本,这对于自动驾驶的进步至关重要。Panacea 解决了两个关键挑战:一致性和可控性。一致性确保时间和跨视图的一致性,而可控性确保生成的内容与相应注释的对齐。我们的方法集成了新颖的 4D 注意力和两阶段生成管道以保持一致性,并辅以 ControlNet 框架,通过鸟瞰图 (BEV) 布局进行细致控制。
Panacea 在 nuScenes 数据集上的广泛定性和定量评估证明了其在生成高质量多视图驾驶场景视频方面的有效性。这项工作通过有效增强用于先进 BEV 感知技术的训练数据集,显着推动了自动驾驶领域的发展。
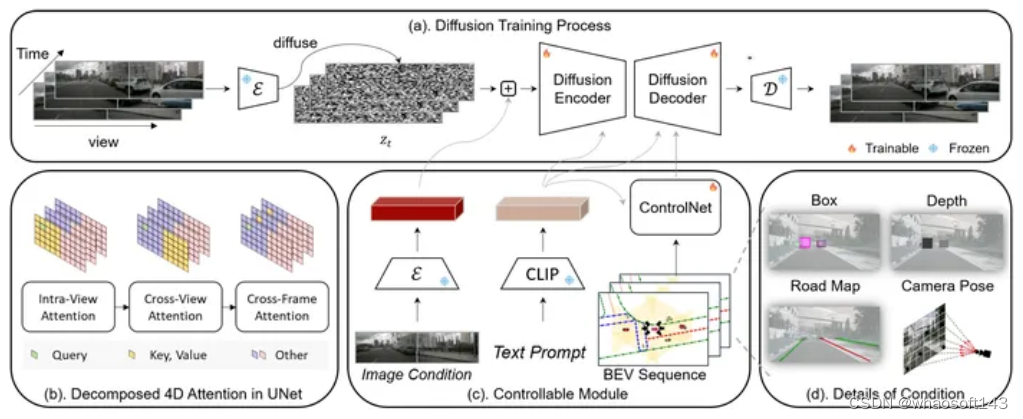
Panacea 论文:https://arxiv.org/abs/2311.16813
Panacea 解读:https://zhuanlan.zhihu.com/p/671567561
LimSim
提出了LimSim,即长期交互式多场景交通模拟器,旨在提供城市路网下的长期连续模拟能力。LimSim 可以模拟细粒度的动态场景,并专注于交通流中多辆车之间的多样化交互。本文详细介绍了LimSim的框架和特点,并通过案例研究和实验展示了其性能。

LimSim 论文:https://arxiv.org/abs/2307.06648
LimSim 解读:https://zhuanlan.zhihu.com/p/657727848
GenSim
建议通过利用大型语言模型(LLM)的基础和编码能力来自动生成丰富的模拟环境和专家演示。方法被称为 GenSim,有两种模式:目标导向生成,其中向LLM提供目标任务,法学硕士提出任务课程来解决目标任务;以及探索性生成,其中LLM从先前的任务中引导并迭代提出有助于解决更复杂任务的新颖任务。

GenSim 论文:https://arxiv.org/abs/2310.01361
GenSim 代码:https://github.com/liruiw/GenSim
GenSim 项目:https://huggingface.co/spaces/Gen-Sim/Gen-Sim
GenSim 介绍:https://zhuanlan.zhihu.com/p/661690326
UNav-Sim
UNv-Sim,是第一个整合了虚幻引擎 5 (UE5) 高效、高细节渲染的模拟器。UNV-Sim 是开源的,包括一个基于视觉的自主导航堆栈。通过支持 ROS 等标准机器人工具,UNav-Sim 使研究人员能够高效地开发和测试水下环境的算法。
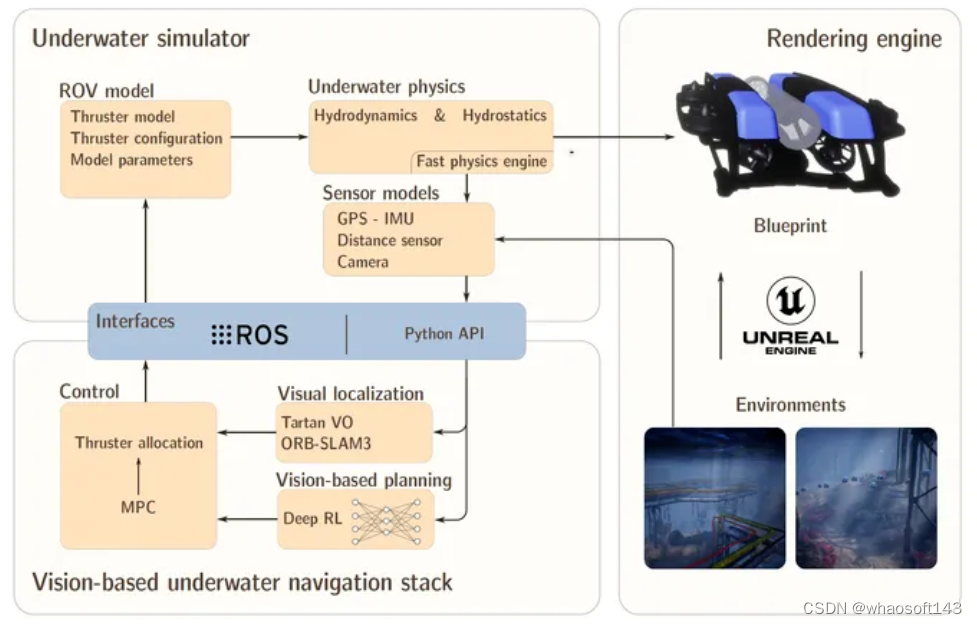
UNav-Sim 论文:https://arxiv.org/abs/2310.11927
UAV-Sim
利用神经渲染方面的最新进展来改进基于 noveview 无人机的静态和动态图像合成,特别是从高海拔处捕获显着的场景属性。最当最先进的检测模型主要针对真实数据和合成数据的混合集而不是单独的真实数据或合成数据进行优化时,可以实现相当大的性能提升。

UAV-Sim论文:https://arxiv.org/abs/2310.16255
PegasusSimulator
Pegasus Simulator,这是一个作为 NVIDIA Isaac Sim 扩展实现的模块化框架,可以在逼真的环境中实时模拟多个多旋翼飞行器,同时提供与广泛采用的PX4-Autopilot 和 ROS2 通过其模块化实施和直观的图形用户界面。

PegasusSimulator 论文:https://arxiv.org/abs/2307.05263
MTR
提出了一种简单而有效的自回归方法来模拟多智能体行为,该方法基于著名的多模态运动预测框架,称为运动变换器(MTR)[5],并应用了后处理算法。我们提交的名为 MTR+++ 的作品在 2023 年 WOSAC 的现实主义元指标上达到了 0.4697。此外,挑战后还提出了基于MTR的改进模型MTR_E,其得分为0.4911,截至2023年6月25日在WOSAC排行榜上排名第三。
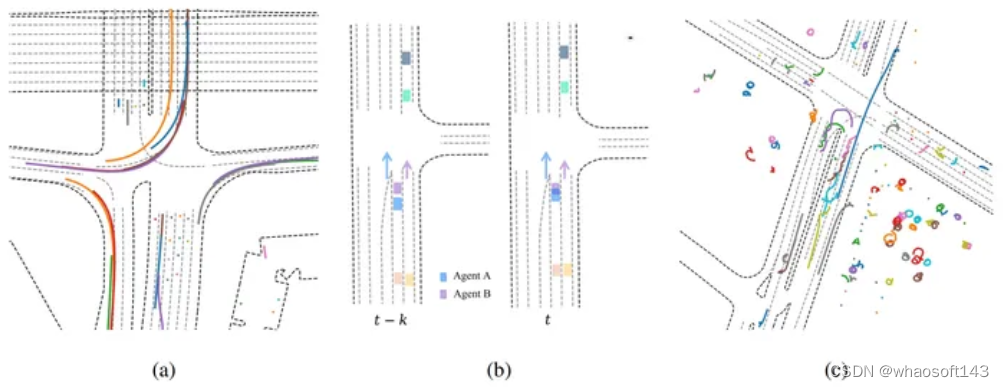
MTR 论文:https://arxiv.org/abs/2306.15914
MVTA
提出了用于代理模拟的 MultiVerse Transformer (MVTA) 有效地利用了基于Transformer的运动预测方法,并且专为代理的闭环模拟而定制。为了产生高度真实的模拟,设计了新颖的训练和采样方法,并实现了后退水平预测机制。此外,引入了一种可变长度历史聚合方法,以减轻闭环自回归执行期间可能出现的复合误差。
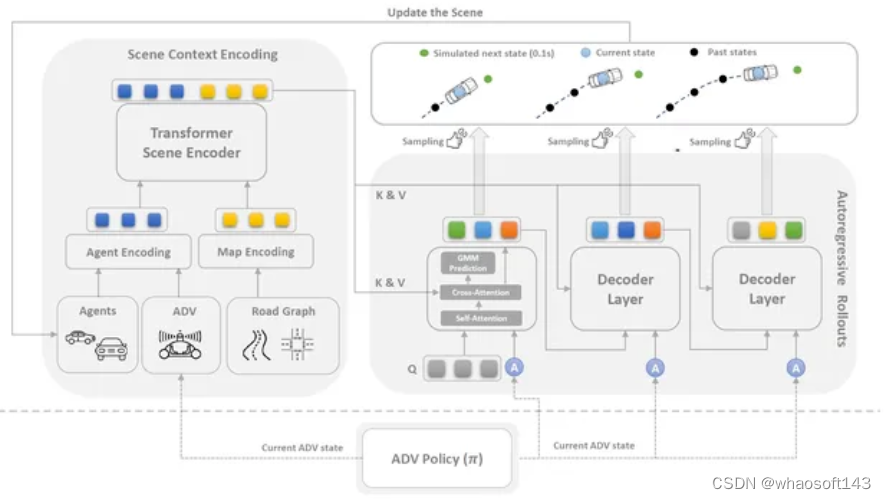
MVTA 论文:https://arxiv.org/abs/2306.11868
MVTA 项目:https://multiverse-transformer.github.io/sim-agents/
SimOnWheels
推出 Sim-on-Wheels,这是一种安全、现实的车辆在环框架,用于测试自动驾驶汽车在现实世界中安全关键场景下的性能。轮子模拟运行在现实世界中运行的自动驾驶车辆上。
它创建具有危险行为的虚拟交通参与者,并将虚拟事件无缝插入到从物理世界实时感知的图像中。处理后的图像被输入到自主系统中,使自动驾驶车辆能够对此类虚拟事件做出反应。完整的管道在实际车辆上运行并与物理世界交互,但它看到的安全关键事件是虚拟的。Sim-on-Wheels 安全、互动、真实且易于使用。这些实验证明了车轮模拟在促进高保真度和低风险的具有挑战性的现实世界场景中测试自动驾驶过程的潜力。
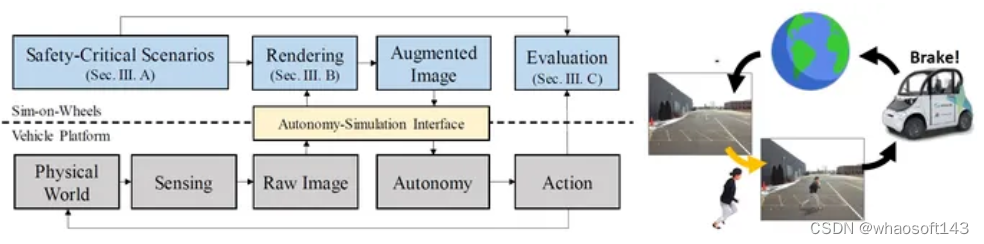
SimOnWheels 论文:https://arxiv.org/abs/2306.08807
AutoVRL
AutoVRL,这是一个基于 Bullet 物理引擎构建的开源高保真模拟器,利用 PyTorch 中的 OpenAI Gym 和 Stable Baselines3 来训练 AGV DRL 代理,以实现从模拟到真实的策略传输。
AutoVRL配备了GPS、IMU、LiDAR和摄像头的传感器实现、用于AGV控制的执行器和现实环境,并具有针对新环境和AGV模型的可扩展性。该模拟器提供对最先进的 DRL 算法的访问,利用 Python 接口进行简单的算法和环境定制以及模拟执行。
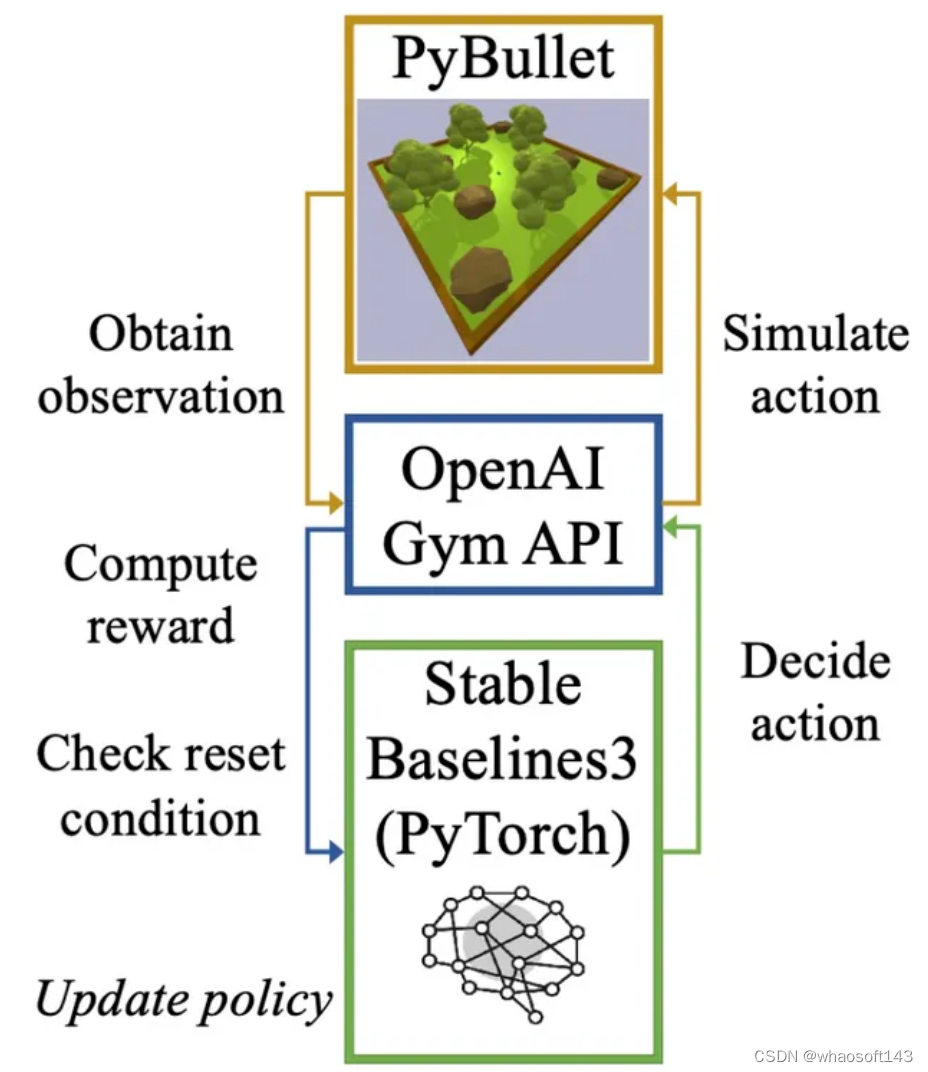
AutoVRL 论文:https://arxiv.org/abs/2304.11496
AptSim2Real
近似配对方法 AptSim2Real 利用了这样一个事实:模拟器可以生成在光照、环境和构图方面与现实世界场景大致相似的场景。我们新颖的训练策略带来了显着的定性和定量改进,与最先进的未配对图像翻译方法相比,FID 分数提高了 24%。
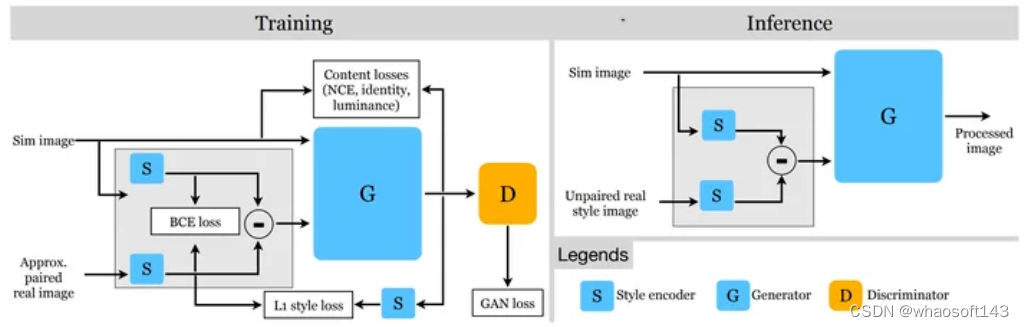
AptSim2Real 论文:https://arxiv.org/abs/2303.12704
AdaptSim
AdaptSim 项目:https://irom-lab.github.io/AdaptSim/
AdaptSim 论文:https://arxiv.org/abs/2302.04903
AdaptSim 代码:https://irom-lab.github.io/AdaptSim/
WaymoX
Waymax 是一款轻量级、多代理、基于 JAX 的模拟器,用于基于Waymo 开放运动数据集的自动驾驶研究。Waymax 旨在支持自动驾驶行为研究的各个方面 :从规划的闭环模拟和模拟代理研究到开环行为预测。对象(例如车辆、行人)被表示为边界框,而不是原始传感器输出,以便将行为研究提炼成最简单的形式。由于所有组件完全用 JAX 编写,因此 Waymax 可以轻松分发并部署在 GPU 和 TPU等硬件加速器上。

WaymoX 论文:https://arxiv.org/abs/2310.08710
WaymoX 代码:https://github.com/waymo-research/waymax
WaymoX 主页:https://waymo.com/intl/zh-cn/re
4.仿真平台
华为-Octopus
自动驾驶云服务(Octopus)是面向车企、研究所的全托管平台,在华为云上提供自动驾驶数据云服务、自动驾驶标注云服务、自动驾驶训练云服务、自动驾驶仿真云服务、配置管理服务,帮助车企以及研究所快速开发自动驾驶产品。
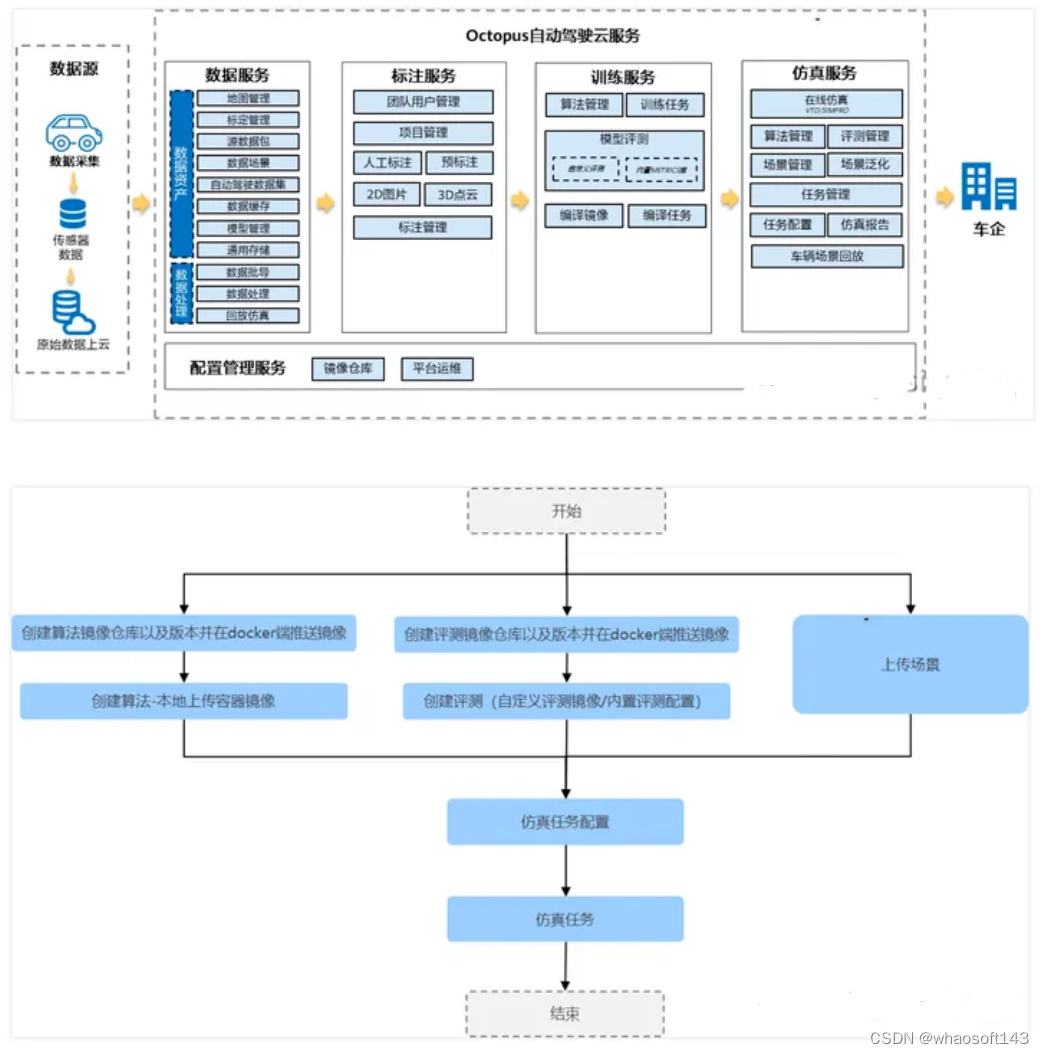
Octopus 主页:https://support.huaweicloud.com/octopus/index.html
什么是Octopus:https://support.huaweicloud.com/productdesc-octopus/octopus-01-0001.html
仿真服务简介:https://support.huaweicloud.com/usermanual-octopus/octopus-03-0009.html
百度-ApolloCloud
ApolloCloud 主页:https://apollocloud.baidu.com/
Apollo仿真平台场景编辑器:https://apollo.baidu.com/community/article/120
云仿真测试解决方案:https://apollocloud.baidu.com/solution/test
Apollo仿真平台:https://developer.apollo.auto/platform/simulation_cn.html
腾讯-TDASim

智能网联解决方案:https://cloud.tencent.com/solution/intelligent-vehicle-road-cooperation
TADSim 百科:https://baike.baidu.com/item/TAD%20Sim/63745889?fr=ge_ala
腾讯发布自动驾驶仿真平台TAD Sim 2.0:https://zhuanlan.zhihu.com/p/150694950
TADSim 论文:https://dl.acm.org/doi/10.1145/2699715
阿里-IVOCC
IVOCC:https://www.aliyun.com/product/iovcc
英伟达-DriveSim
NVIDIA DRIVE Sim 是一个端到端仿真平台,从头开始构建,可运行大规模、基于物理的多传感器仿真。它是开放的、可扩展的、模块化的,支持从概念到部署的 AV 开发和验证,提高开发人员的工作效率并加快发布时间。
DriveSim 主页:https://developer.nvidia.com/drive/simulation
DriveSim 介绍:https://www.nvidia.com/en-sg/self-driving-cars/simulation/
5.光学仿真
3DOptix
3DOptix 官网:https://www.3doptix.com/
3DOptix 主页:https://www.3doptix.com/design-simulation-software/
OpticStudio
Ansys Zemax OpticStudio 光学工作流程和设计软件主页:https://www.ansys.com/products/optics/ansys-zemax-opticstudio
LightTools
LightTools 使您能够快速创建一次尝试就能成功的照明设计,从而减少原型迭代。使用 LightTools 的智能且易于使用的工具提高您的生产效率并缩短上市时间。
LightTools 主页:https://www.synopsys.com/optical-solutions/lighttools.html
总结
其实很多ADAS企业都不太重视仿真的,重心都在回灌和道路测试,即使搭建了仿真工具链,在量产项目中的作用也很小,只是用来分析、复现问题/BUG。
面向量产项目/功能开发的传感器数据&信号仿真、车辆运动学&动力学仿真、感知&规控联合仿真、数据孪生数据挖掘的仿真还是没有完全成熟的方案,迫切需要面向WorldSim的全栈联合仿真&模拟器。如果可以把芯片硬件仿真、软件算法仿真一起搞了,那就更完美了。
#汽车行驶性能的主观评价-直线行驶特性
车辆直线行驶时的方向稳定性作为被动安全的重要组成部分,是轻松、愉快驾驶的前提条件。直道行驶所描述的车辆特性包括:车辆自身的直线行驶稳定性,车辆受外界干绕影响的敏感程度和车辆保持行驶路线所需的修正做功。
11.1 直线行驶
由路面不平度、空气运动学影响、驾驶员的干扰转向输入、驱动系统的内力和扭矩等因素所导致的干扰力会对车轮的行驶方向,进而对车辆的直线行驶运动产生影响。需要评价的内容包括:直线行驶时,车辆行车方向的变化和受侧向干扰的影响程度以及消除这些干扰所需的做功。
路面状况:均质表面、不同附着特性的平直路面,比如干燥路面、湿滑路面、冰路面、长短波纹不一的不平路面、碎石路面及其他特殊路面(波纹路面、铁饼路面等)
行驶工况:在无风或者很低的风速下,车辆以一定速度直线行驶(比如车速恒定于 80、100、150km/h、最大速度)
研发目的:车辆应该尽可能的保持自回正性能,这样方向盘上保持行驶方向的力矩和修正行驶路线的转向动作可以很小。
影响因素:
前后轮定位参数
前、后桥运动学和弹性运动学
尤其是主销后倾(主销后倾角,主销后倾拖距)
转向特性
轴荷分布
轮胎特性(车轮和轮胎尺寸、特征参数,如侧偏刚度等)
空气动力学特性
轴距
11.2 悬架干涉转向
如果松开方向盘,车辆悬架的运动会导致转向动作,使方向盘发生轻微的转动。如果握紧方向盘,那么会引起车辆的横摆运动,甚至是行驶路线的变化。需要评价的是行驶过程中松开方向盘条件下所产生的方向盘转角大小或是固定方向盘条件下的转向力矩波动。
路面状况:有较高附着性能和不同路面不平度的直路,如:带长、短波纹的不平路面、波纹路面和翘曲路面。
行驶工况:车辆以一定速度直线行驶(比如车速恒定于 80、100、150km/h、最大速度)
研发目的:即使悬架弹簧发生较大的变形,也不允许出现转向运动或者横摆运动。
影响因素:
前、后桥运动学和弹性运动学(图 11.1)
转向特性
悬架弹簧、稳定杆、阻尼的校准
轮胎特性(车轮和轮胎尺寸、特征参数,如侧偏刚度等)
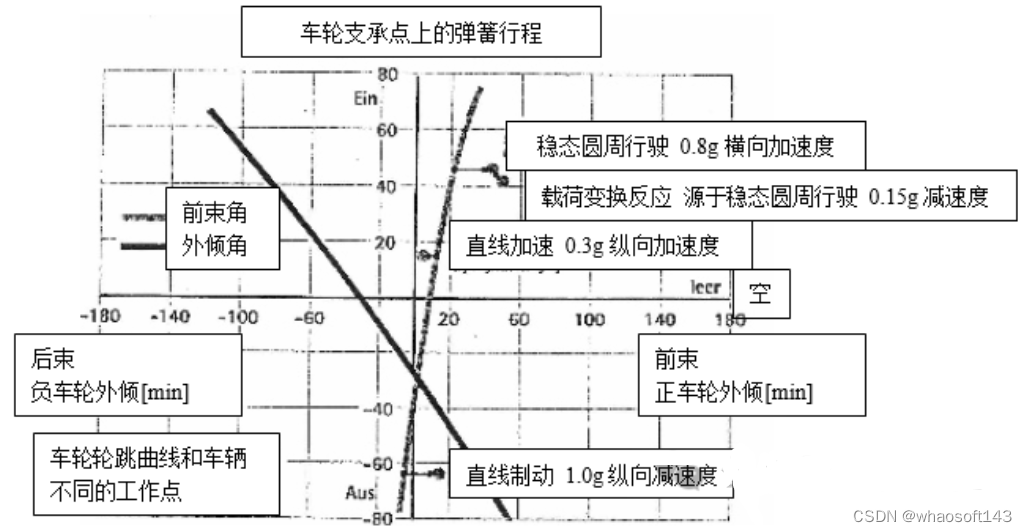
图 11.1 车轮前束和车轮外倾同悬架变形、行驶工况间的关系
11.3 侧倾转向
道路表面的不连续性,尤其是左、右车轮行驶路面间的差别(变形、建造缺陷、磨损或者沉陷)会导致车辆的侧倾运动,从而引起方向盘轻微的自转向运动。如果固定方向盘,则车辆会产生横摆运动、偏离原来的行驶路线。需要评价的是行驶过程中松开方向盘条件下所产生的方向盘转角大小或是固定方向盘条件下的转向力矩波动。
行驶工况:车辆以一定速度行驶(比如车速恒定于 80、100、150km/h、最大速度)
研发目的:即使车身发生剧烈侧倾运动,也不应该产生转向或者横摆运动。
影响因素:
前、后桥运动学和弹性运动学
横向稳定杆引起的转向运动学
悬架弹簧、稳定杆、阻尼的校准转向特性
侧倾轴线位置和悬架变形时该位置的变化
轮胎特性(车轮和轮胎尺寸、特征参数、如侧偏刚度等)

11.4 转向摆振(Lenkungspendeln)
转向摆振描述了转向—车辆系统的低频振动特性,包括频率特性、阻尼特性和衰减特性。通过下述的 3 种转向激励工况可以对转向摆振特性做出综合评价:
■ 在正弦激励下,评价转向动作是否会引起耦合的转向-侧倾运动,以及在停止激励后,振动衰减速度。
■ 在瞬时激励(Anreißen)作用下,观察方向盘是否及如何回复初始位置,如果振动衰减,那么评价超调震荡的次数和振幅。
■ 如果任方向盘自由转动,路面不平度是否会引起转向摆振现象。路面状况:高附着系数平直路面或者纵向方向不平整的路面。
行驶工况:车辆首先以恒定车速(最好能以较高的车速,如 120,150,180km/h,最高车速等)直线行驶。为了对转向摆振现象有更全面的认识,可以用下述方法转动方向盘:首先在转向盘中间位置附近施加轻微的不同频率的正弦激励,以获得转向摆振的固有频率;然后以该固有频率施加正弦转向激励并保持,转向幅度很小(比如小于+/-10 度)。当出现自激振动后,放开方向盘。
在瞬时激励作用下,保持直线行驶的车辆受到瞬时转向激励,然后迅速松手并评价其衰减特性。车辆在不平整路面上行驶时,任方向盘自由运动,观察周期性的自转向运动。
研发目的:如果松开方向盘,车辆在所有车速范围内都不允许出现转向摆振现象。如果方向盘受到瞬时激励,方向盘应该迅速、在尽可能没有超调震荡的情况下回复到初始位置。在正弦激励作用下,往复运动同样应该在激励去除后迅速衰减。在施加激励过程中,应该明显感觉到转向回正力矩的反作用。在不平路面条件下,自由转动的方向盘上不应该出现周期性的振动。
影响因素:
转向系统的弹性、转动惯量、摩擦和阻尼悬架弹簧、稳定杆、阻尼的校准
横向稳定杆引起的附加转向转向特性
空气动力学特性
前、后桥运动学和弹性运动学,特别是主销后倾角轴荷分布
轮胎特性(车轮和轮胎尺寸、特征参数,如侧偏刚度、磨损程度等)
11.5 纵向缝隙敏感性
车辆驶过纵向缝隙时,会产生转向运动或者行驶路线的偏离。需要评价的是行驶过程中松开方向盘条件下所产生的方向盘转角大小或是固定方向盘条件下的转向力矩波动,或者是行驶路线的偏离程度及抗干扰所需的转向做功。
路面状况:有高附着特性和纵向缝隙的平直路面,比如水泥路面间的缝隙、路面施工留下的接痕、路上凸起的车道标记(图 11.2)、城市道路中的铁路铁轨(图 11.3)。
行驶工况:车辆以一定的车速(比如恒定 50、80、100、150km/h)直线行驶并通过带尖角缝隙的路面。

图 11.2路上凸起的车道标记

图 11.3 纵向缝隙(铁轨)
研发目的:纵向缝隙不应该引起方向盘的转向、转向力矩的波动或者行驶路线的偏移。
影响因素:
前、后桥运动学和弹性运动学
车轮定位参数干扰力臂长度转向特性
轮胎特性(车轮和轮胎尺寸、特征参数,如侧偏刚度等)
11.6 车辙敏感性
车辙敏感性描述了车辆在有凹痕的路面上行驶或者在凹陷车辙内及其周围行驶时,车辆的方向稳定性和路面对转向的反作用。这些凹陷由路面的磨损或者重载汽车对路面的挤压形成(图 11.4)。在上述情况下,车辆会出现转向运动和行驶路线的偏移。需要评价的是行驶过程中松开方向盘条件下所产生的方向盘转角大小或是固定方向盘条件 下的转向力矩波动,或者是行驶路线的偏离程度及抗干扰所需的转向做功。

图 11.4 车辙(载重汽车)
路面状况:有高附着性和车辙的平直路面,比如载重汽车磨损路面产生的凹陷车辙或者纵向铣出的凹痕等。
行驶工况:车辆以一定的车速(比如恒定 50、80、100km/h)直线行驶,然后以极小的角度驶上车辙或者在车辙内以微小的侧向偏移行驶。
研发目的:车辙不允许引起转向运动、转向力矩波动或者行驶路线的偏移。
影响因素:
前、后桥运动学和弹性运动学
车轮定位参数转动系统弹性转向特性
干扰力臂长度
轮胎特性(车轮和轮胎尺寸、胎面轮廓、特征参数,如侧偏刚度等)
11.7 载荷变换反应控制
车辆直线行驶时,载荷变换反应也会引起转向运动和行驶路线的变化。需要评价的是行驶过程中松开方向盘条件下所产生的方向盘转角大小或是固定方向盘条件下的转向力矩波动,或者是行驶路线的偏离程度及抗干扰所需的转向做功。
路面状况:平直路面,其有着不同特性的均质表面,比如干燥路面、湿滑路面、雪地和冰路面
行驶工况:车辆初始时以恒定车速保持直线行驶,该车速可以逐步提高,比如恒定 60、80、100、150km/h,然后突然改变油门踏板位置,比如突然减小或者增大到全油门位置。
研发目的:载荷变换反应不允许引起转向运动、转向力矩波动或者行驶路线的偏移。
影响因素:
运动学和弹性运动学(尤其是驱动轴的非对称性)
轮胎外形的相同性,比如胎面锥度驱动轴的非对称性
轴间差速器的锁止特性
11.8 抗侧风特性
受侧风影响,车辆会改变行驶方向,偏离原来的行驶路线。需要评价侧风干扰的程度、干扰出现的速度以及保持车辆直线行驶所需消耗的转向做功。为了获得上诉评价,在调整车辆保持直线行驶的过程中,有时要松开方向盘,而有时要固定方向盘。
路面状况:有高附着性能的平直路面,最好是不限速、不拥堵的高速路
行驶工况:车辆在侧风作用下,或者在不同迎风角侧向风模拟装置(图11.5)的作用下, 以恒定车速(最好以较高的车速)保持直线行驶,该车速可以逐步提高(比如恒定 60、80、100、150km/h、最高车速)。
研发目的:由侧风引起的行驶方向的改变和行驶路线的偏移应该尽可能小。如果行驶轨迹和行驶方向受到干扰,那么这一干扰应该迅速衰减,这样驾驶员可以有足够的反应时间。同时为保持原先的行驶路线所需的转向做功应该尽可能小。

图 11.5侧向风模拟装置
影响因素:空气动力学特性
质心位置转向特性
悬架弹簧、稳定杆、阻尼的校准前、后桥弹性运动学
11.9 风敏感度
在车流较多的情况下会形成空气扰动和空气涡流,对车辆造成一定程度的干扰。车辆在跟随行驶、超车和被超车的情况下,评价其是否及产生何种响应(侧倾、横摆振动、侧向偏移)以及消除干扰所需消耗的转向做功。
路面状况:有高附着性的平直路面,最好是不限速、不拥堵的高速路
行驶工况:在无拥堵、长距离(至少 30km)条件下,车辆以不同的速度和不同的超车情况(超车和被超车)行驶。需要用到所有的车道。尤其要评价客车和载重车辆在不同距离下的空气涡流特性。
研发目的:空气涡流不应该引起车辆的响应。即使车辆受到干扰,消除这一干扰也应该只需消耗很少的转向做功。

图 11.6 “边缘的(abrisskante)”尾灯
影响因素:
空气运动学特性,尤其是车尾侧面截断角(Heckabrisskanten)的设计(图 11.6)
质心位置
转向特性
前、后桥弹性运动学车轮定位参数
11.10 轿车—挂车组合的摆动稳定性
车辆拖着挂车,尤其拖着房车行驶时,当车速接近所允许的最高车速时,车辆可能出现
危险的摆动现象。需要观察的是,挂车在何种车速以下才不会发生摆动现象或者摆动可以迅速被削弱。
路面状况:有高附着性能的平整路面
行驶工况:车辆以恒定车速直线行驶,该速度将逐步提高直至危险车速或者最高车速。为了对摆动现象进行评价,可以按下述方法转动方向盘:
首先在转向盘中间位置附近施加轻微的正弦转向激励,以获得挂车摆动运动的固有频率。然后以该固有频率对车辆进行激励。转动方向盘的幅度应该很小。该测试通常在很低的车速下就开始进行,然后慢慢提高车速。随着摆动运动的加剧,车辆—挂车组合逐渐接近危险速度,此时不能再提高车速。当车组以危险车速或者最高车速行驶时,其摆动激剧,即使有经验的驾驶员也无法控制车辆。
采用另一种方法的话,车辆首先调整至直线行驶,接着对方向盘施加瞬时激励,车组随后将回复到初始状态。进行该测试时,车速必须明显低于危险车速的一半。
在挂车和牵引车允许的最大载重范围内,测试采用不同的载重状态。
研发目的:即使挂车的重量和牵引车的重量没有恰当的比例关系,车组也必须安全达到法定允许的车速。该车速应该足够高,以保证其与危险车速间仍有足够的距离。
影响因素:
■挂车:总重量
质心位置
挂车的转动惯量
车桥样式及其弹性运动学弹簧和阻尼的校准
挂车钩的负载能力
牵引杆和挂车钩间的阻尼器(图11.7;采用摩擦阻尼器或者液压阻尼器通常可以将危险车速提高 20km/h)
轮胎特性(车轮和轮胎尺寸、特征参数,如侧偏刚度等)
■牵引车:总重量
轴荷分布
运动学和弹性运动学(尤其是受侧向力作用的后轮)
轮胎特性(车轮和轮胎尺寸、特征参数,如侧偏刚度等)

图 11.7 带有阻尼器的挂车离合器
#端到端自动驾驶合集
最近的端到端驱动方法可以分为两个主流:模仿学习和强化学习。强化学习(RL)是机器学习中最有趣的领域之一,其中代理通过遵循策略与环境交互。在环境的每一个状态下,它都会根据策略采取行动,从而获得奖励并过渡到新状态。RL的目标是学习使长期累积回报最大化的最优策略。在模仿学习中,专家(通常是人类)为我们提供了一组演示,而不是试图从稀疏的奖励中学习或手动指定奖励函数。然后,代理尝试通过模仿专家的决策来学习最优策略。下面为大家汇总了近三年的一些端到端工作,虽然不多,但确实是一个很值得研究的领域!
用于端到端自动驾驶多模态融合transformer
论文名称:Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
如何将互补传感器的表示集成到自动驾驶中?基于几何的传感器融合在目标检测和运动预测等感知任务中显示出巨大的前景。然而,对于实际驾驶任务,3D场景的全局上下文是关键,例如,交通灯状态的变化可以影响几何上远离该交通灯的车辆的行为。因此,单独的几何结构可能不足以有效地融合端到端驱动模型中的表示。本文证明了基于现有传感器融合方法的模拟学习策略在高密度动态代理和复杂场景的存在下表现不佳,这些场景需要全局上下文推理,例如在不受控制的交叉口处处理来自多个方向的迎面而来的交通。因此,作者提出了一种新的多模态融合transformer:TransFuser,以利用注意力来集成图像和激光雷达表示。使用CARLA城市驾驶模拟器在涉及复杂场景的城市环境中通过实验验证了论文方法的有效性。与基于几何的融合相比,本文的方法实现了最先进的驾驶性能,同时减少了76%的碰撞。
Contribution
(1) 论文证明,基于现有传感器融合方法的模仿学习策略无法处理城市驾驶中的对抗性场景,例如,十字路口的无保护转弯或来自闭塞区域的行人;(2) 提出了一种新的多模态融合transformer(TransFuser),以将3D场景的全局上下文结合到不同模态的特征提取层中;(3) 在复杂的城市环境中通过实验验证了本文的方法,包括CARLA中的对抗场景,并实现了最先进的性能;代码和经过训练的模型可在:
https://github.com/autonomousvision/transfuser
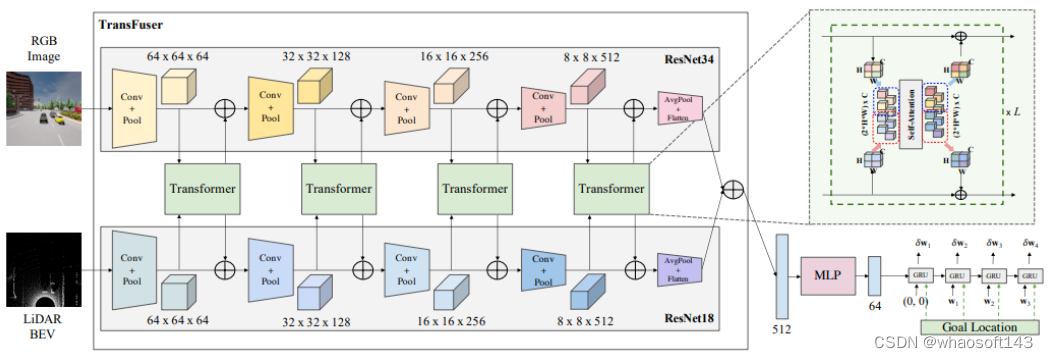
模型结构
将单视图RGB图像和LiDAR BEV表示作为多模态融合变换器(TransFuser)的输入,该transformer使用多个transformer模块来融合两种模态之间的中间特征图。该融合在整个特征提取器中以多个分辨率(64×64、32×32、16×16和8×8)应用,从而从图像和LiDAR BEV流输出512维特征向量,并通过逐元素求和进行组合。该512维特征向量构成对3D场景的全局上下文进行编码的环境的紧凑表示。然后,在将其传递到自回归航路点预测网络之前,通过MLP对其进行处理。使用一个单层GRU,然后是一个线性层,该层处于隐藏状态,并预测差异ego-vehicle路线点{δ}=,在ego-vehicle的当前坐标系中表示。
实 验
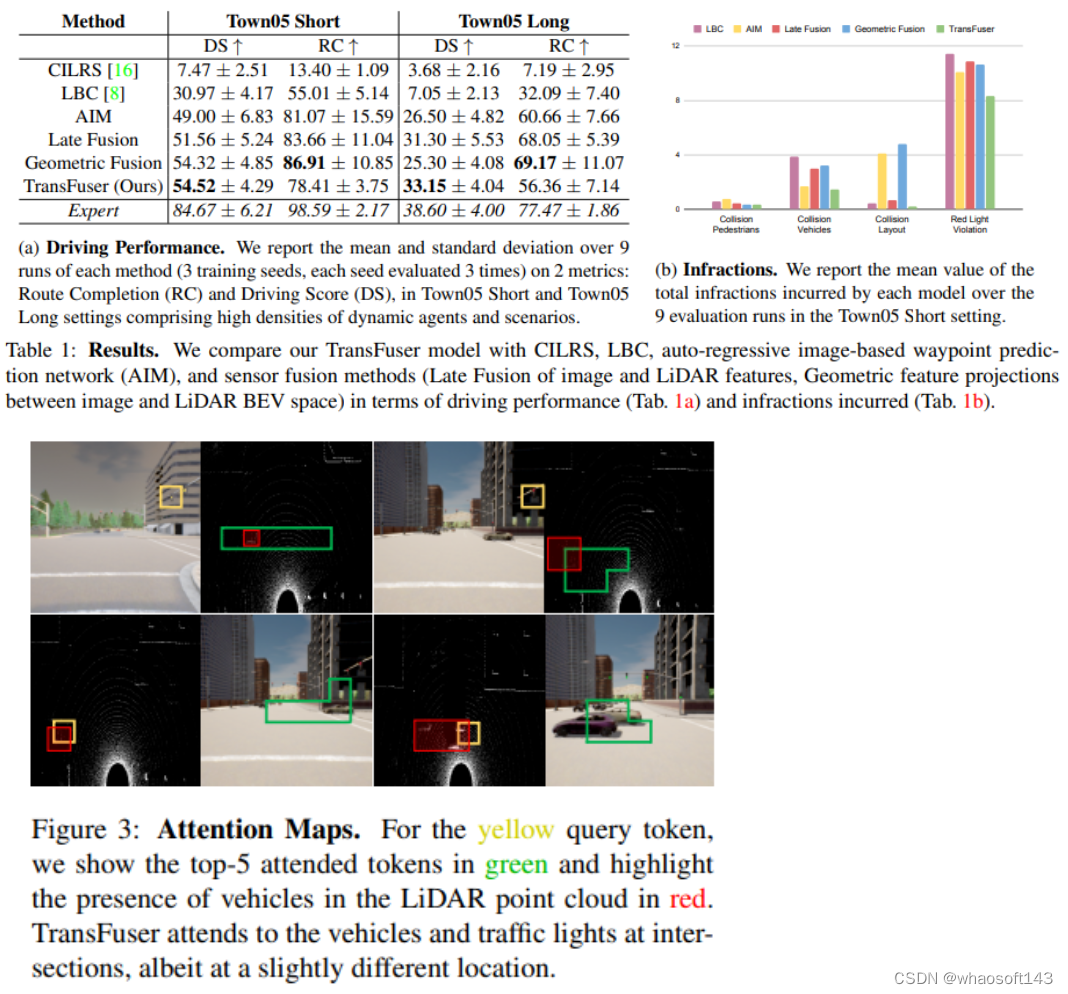
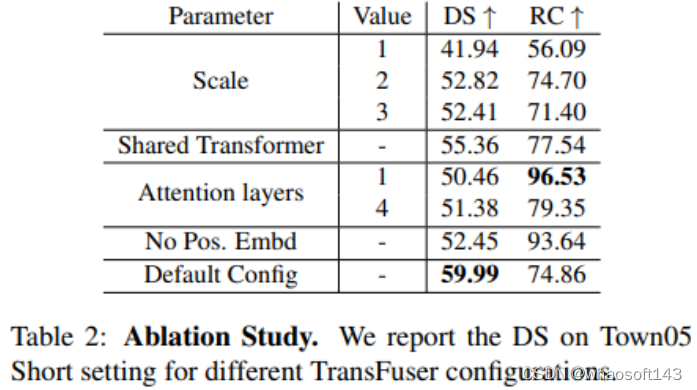
论文将本方法的驱动性能与几个基线进行比较,进行违规分析以研究不同的故障案例,可视化TransFuser的注意力图,并进行消融研究以突出我们模型不同组件的重要性。论文考虑沿一组预定义的路线在各种区域导航的任务,例如高速公路、城市地区和住宅区。路线由全球规划器提供的GPS坐标中的一系列稀疏目标位置和相应的离散导航命令(例如,跟随车道、左转/右转、改变车道)定义。论文的方法只使用稀疏的GPS位置来驾驶,每条路线由若干场景组成,在预定义位置初始化,测试代理可以处理不同类型的对抗性情况,例如避障、交叉口无保护转弯、车辆闯红灯、行人从闭塞区域出来在任意位置横穿道路,代理需要在指定的时间限制内完成路线,同时遵守交通规则并应对高密度的动态代理。
指标:(1) 路线完成(RC),完成的路线距离百分比,(2) 驾驶分数(DS),是由违规乘数加权的路线完成度,该乘数考虑了与行人、车辆和静态元素的碰撞、路线偏离、车道违规、闯红灯和行驶停止标志和(3)违规计数
论文名称:Learning to Drive by Watching YouTube Videos: Action-Conditioned Contrastive Policy Pretraining
深度视觉运动策略学习旨在将原始视觉观察映射到行动,在机器人操纵和自动驾驶等控制任务中取得了很好的结果。然而,它需要与培训环境进行大量的在线交互,这限制了它的实际应用。与流行的用于视觉识别的无监督特征学习相比,用于视觉运动控制任务的特征预训练的研究要少得多。在这项工作中,我们的目标是通过观看长达数小时的未分级YouTube视频来预处理驾驶任务的政策表示。具体来说,我们用少量标记数据训练一个逆动态模型,并使用它来预测所有YouTube视频帧的动作标签。然后开发了一种新的对比策略预训练方法,以从带有伪动作标签的视频帧中学习动作条件特征。实验表明,所得到的动作条件特征对于下游的强化学习和模仿学习任务获得了实质性的改进,优于从先前的无监督学习方法和ImageNet预处理的权重!
本文评估了各种任务的行动条件预训练的有效性,例如端到端自动驾驶中通过模仿学习(IL)和强化学习(RL)进行的策略学习,以及车道检测(LD),实验结果表明,ACO成功地学习了下游任务的可推广特征。贡献总结如下:
1.提出了一种对大量真实世界驾驶视频进行政策预训练的新范式;
2.开发了一种新的行动条件对比学习方法ACO,以学习与行动相关的特征;
3.在下游策略学习任务中的各种预训练方法的实验表明,所提出的方法产生的特征在驱动任务中获得了足够的性能增益;
主要思路

本文目的是学习视觉运动策略学习的可推广视觉特征(通过对大量未经修正的真实驾驶视频进行预训练),作者提出了一种新的对比学习算法,称为行动条件集中学习(ACO)。ACO的本质是定义了两种类型的对比对:实例对比对(ICP)和动作对比对(ACP)。单个图像的两个视图形成正ICP,而不同图像的两视图形成负ICP,只有使用ICP进行预训练才能使表示包括下游策略学习任务的不必要信息。
例如,天气和照明条件等视觉线索对形成ICP至关重要,但对自动驾驶的决策几乎没有贡献。为了将特征集中在与策略相关的属性上,我们引入了另一种类型的对比对,称为动作对比对(ACP)。正ACP由两幅不同的图像组成,显示了驾驶员行为相似的场景。例如,上图中的两个真实世界快照形成了一个正ACP,都显示了驾驶员左转时的第一个视图图像。ACO基于ICP和ACP学习表示,其中ICP侧重于学习歧视性一般视觉特征,ACP侧重于政策相关特征。上图说明了ACO的训练流程,在上面的分支中,首先对给定的图像进行两次扩充,以创建查询和关键视图并形成ICP。本文还创建了另一个基于ACP的学习流程,为了创建ACP,数据集中的每一帧都用伪动作标签进行标记。动作标签用于在不同图像之间形成ACP,并计算用于策略特征学习的ACP损失。
实 验
作者评估了两个主要策略学习任务的预训练特征:端到端驾驶中的模仿学习(IL)和强化学习(RL),还评估了一个相关的视觉识别任务:车道检测(LD)。
论文首先从YouTube上抓取驾驶视频,收集了134个视频,总长度超过120小时。这些视频涵盖了不同天气条件(晴、雨、雪等)和地区(农村和城市地区)的不同驾驶场景。我们每一秒采样一帧,得到130万帧的数据集。将YouTube驾驶数据集分成70%数据的训练集和30%数据的测试集,并在训练集上进行ACO的训练。


Learning from All Vehicles
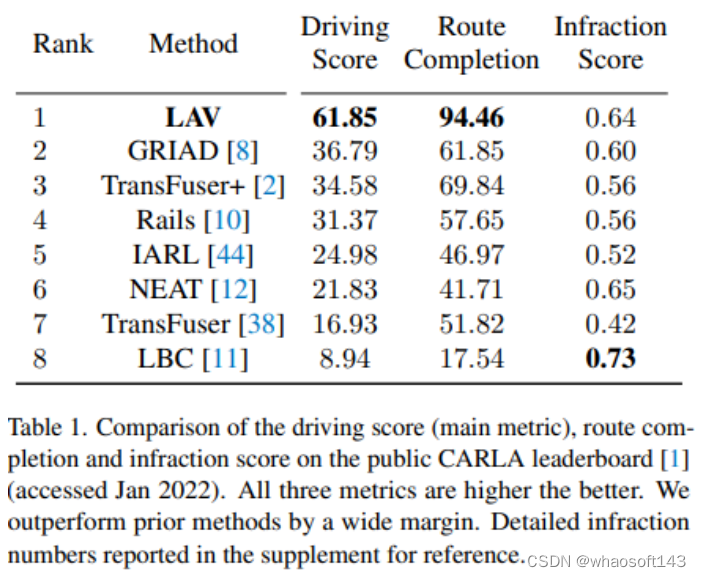
这篇论文提出了一个系统来训练驾驶政策,不仅从ego-vehicle,而且从它观察到的所有车辆收集到的经验。该系统使用其他代理的行为来创建更多样的驾驶场景,而无需收集额外数据。从其它车辆学习的主要困难是没有传感器信息,论文使用一组监督任务来学习对控制车辆的视点不变的中间表示。这不仅在训练时提供了更丰富的信号,还允许在推理过程中进行更复杂的推理。学习所有车辆的驾驶方式有助于预测测试时的行为,并避免碰撞,在闭环驾驶模拟中评估了该系统。本文的系统大大超过了公共CARLA排行榜上的所有现有方法,驾驶得分提高了25分,路线完成率提高了24分!
本文的框架,从所有车辆学习(LAV),在一个联合识别、预测和规划堆栈中处理感知和运动的部分可观测性,论文使用特权蒸馏方法将感知和行动的部分可观测性挑战解耦。LAV首先学习感知模型,该感知模型使用来自3D检测和分割任务的辅助监督来输出视点不变表示。根据定义,该辅助任务不区分自我车辆和场景中的其他车辆,因此学习视点不变表示。它处理传感器的部分可观测性,同时,LAV学习特权运动规划器。使用未来的路线点来表示运动计划,而不是预测转向和加速度,这仅适用于自车车辆。使用GT计算机视觉标签作为特权运动规划器的输入,计算机视觉标签确保视点不变,路点提供运动的不变表示。特权运动规划器预测所有附近车辆的轨迹,并推断其高级命令。最后使用特权蒸馏将两个模型结合在一个联合框架中,该最终蒸馏使用感知模型的视点不变视觉特征从所有车辆学习运动预测模型,提取的策略仅从原始传感器输入驱动。论文在CARLA驾驶模拟器中验证了方法,在提交时,在CARLA公共排行榜上排名第一,它获得61.85的驾驶分数和94.46的路线完成率。这两种方法在所有方法中都是最高的,并且大大超过了现有的最先进方法,分别将驾驶分数和路线完成率提高了25和24分。
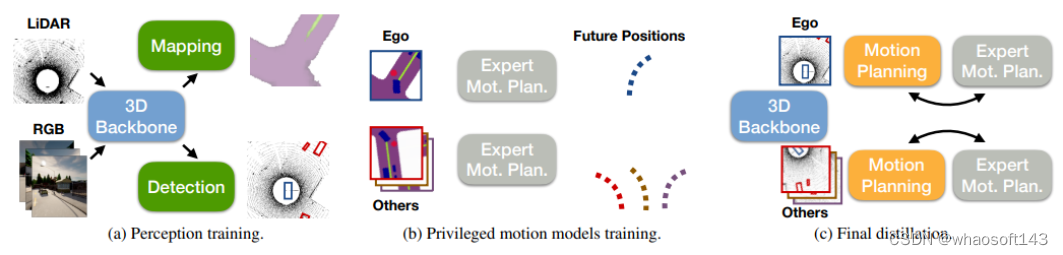
整体框架
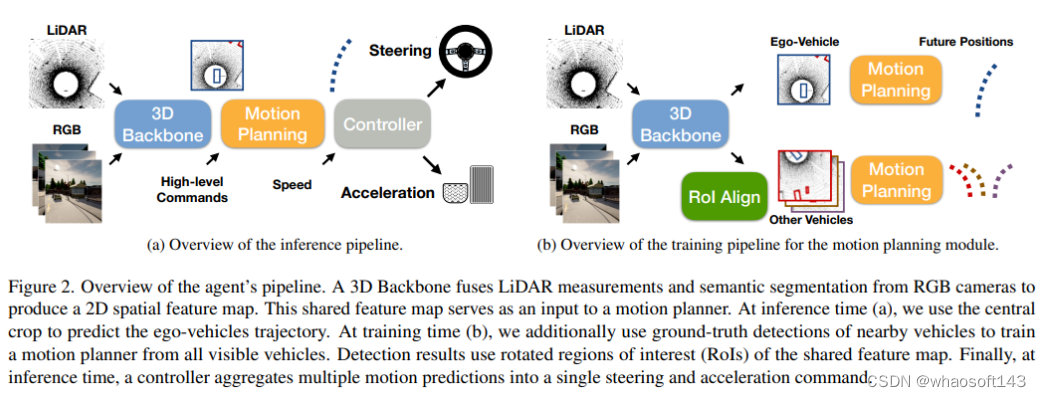
训练pipeline,(a) 使用检测和语义映射作为监督信号来训练3D感知模型。这两个任务都有助于学习视点不变的空间表示。检测还可以预测其他车辆的姿态,使用这些姿态来预测它们在推断时的未来轨迹,感知模块产生用于运动规划的车辆独立特征表示。(b) 同时训练一个GT感知的运动规划器,使用附近所有车辆的轨迹对模型进行训练,并使用它们的未来轨迹作为监督。(c) 最后,使用蒸馏将(a)和(b)中学习的模型结合起来,该模型仅使用ego-vehicles传感器输入来学习所有车辆如何以端到端的方式进行规划。
实 验


COOPERNAUT:端到端
驾驶与网络车辆的协助感知
论文名称:COOPERNAUT: End-to-End Driving with Cooperative Perception for Networked Vehicles
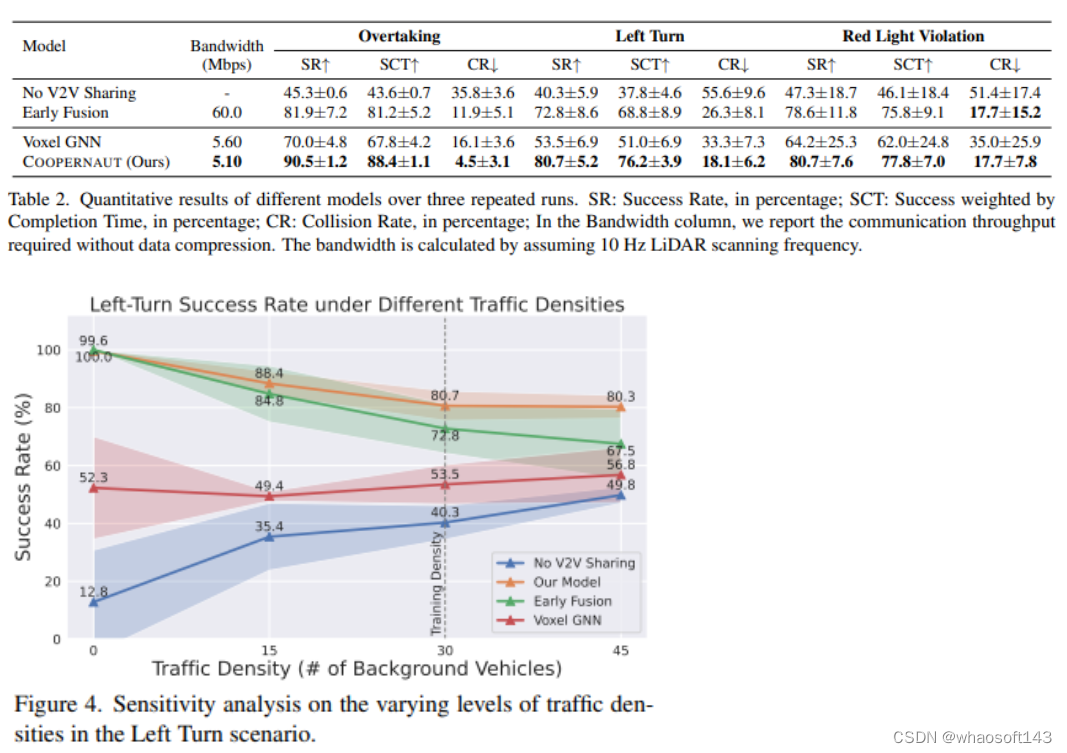
用于自动驾驶汽车的光学传感器和学习算法在过去几年中取得了巨大的进步。尽管如此,当今自动驾驶汽车的可靠性受到视线感知能力有限和数据驱动方法在处理极端情况时的脆弱性的阻碍。随着电信技术的最新发展,与车对车通信的协作感知已成为在危险或紧急情况下增强自动驾驶的一个有前途的范例。本文介绍了COOPERNAUT,这是一种端到端的学习模型,它使用跨车辆感知进行基于视觉的协作驾驶。模型将LiDAR信息编码为紧凑的基于点的表示,可以通过真实的无线信道在车辆之间作为消息传输。为了评估模型,作者开发了AUTOCASTSIM,这是一个网络增强的驾驶模拟框架,具有示例事故多发场景。在AUTOCASTSIM上的实验表明,提出的协作感知驾驶模型在这些具有挑战性的驾驶情况下比以egocentric驾驶模型平均成功率提高了40%,带宽需求比先前的V2VNet小5倍!!!

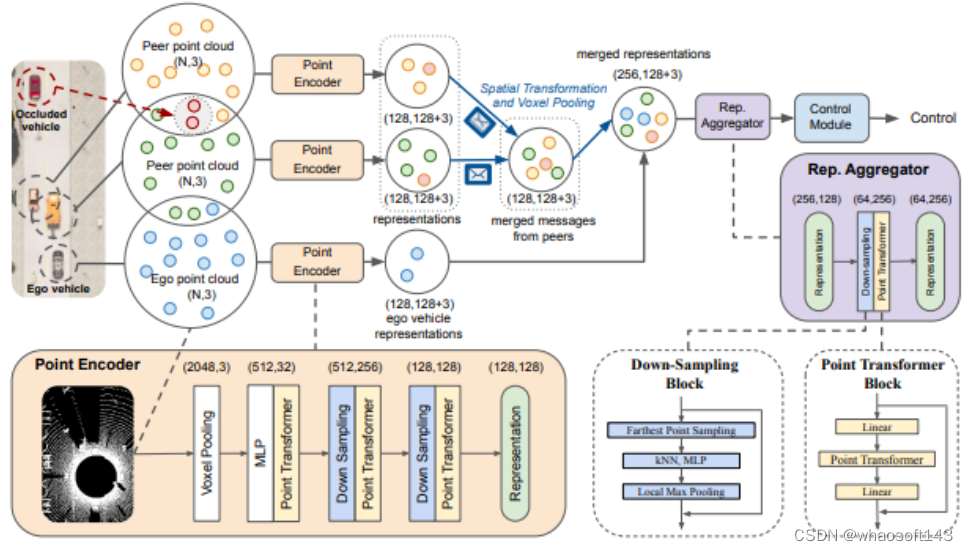
模型结构
COOPERNAUT是用于联网车辆的端到端基于视觉的驾驶模型。它包含一个用于本地提取关键信息以供共享的点编码器,一个用于合并多车辆消息的表示聚合器,以及一个用于推理联合消息的控制模块。编码器产生的每个消息具有128个关键点坐标及其相关特征,然后,信息在空间上转化为ego框架。自我载体通过体素最大池化合并传入消息并计算聚合表示。最后,聚合器合成来自ego 车辆及其所有邻居的联合表示,然后将其传递给控制模块以产生控制决策,括号中的数字表示数据维度。
实 验
论文首先讨论评估方法和实验设置,然后简要概述基线,接下来将根据基线给出本文方法的主要定量评估结果。最后,提供了进一步的分析和可视化,以了解学习的模型质量!
端到端自动驾驶的轨迹引导控制预测
一个简单但强大的基线
论文名称:Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline(NIPS2022)
当前的端到端自动驾驶方法要么基于计划的轨迹运行控制器,要么直接执行控制预测,这已经跨越了两个单独研究的研究领域。鉴于它们彼此潜在的互惠互利,本文主动探索这两个的结合。具体来说,论文的综合方法有两个分支,分别用于轨迹规划和直接控制。轨迹分支预测未来轨迹,而控制分支涉及一种新颖的多步预测方案,从而可以推断当前动作和未来状态之间的关系。这两个分支被连接,使得控制分支在每个时间步从轨迹分支接收相应的引导,然后将两个分支的输出融合以实现互补优势。使用CARLA模拟器在具有挑战性场景的闭环城市驾驶环境中评估结果,即使使用单目相机输入,所提出的方法在官方CARLA排行榜上排名第一,以大幅度超过其他具有多传感器或融合机制的复杂候选方法!
代码:https://github.com/OpenPerceptionX/TCP
利用来自两个分支的预测轨迹和控制信号,作者提出了一种基于情况的融合方案,根据实验结果和先验知识,以自集成的方式自适应地组合这两种形式,以形成最终输出。它结合了这两种形式中的最佳形式,从而进一步提高了不同场景下的性能。当在CARLA驾驶模拟器中进行验证时,TCP显示出优异的性能,论文的方法仅使用单目摄像头,驾驶成绩达到75.137分,在公共CARLA排行榜上排名第一,甚至超过了使用多个摄像头和激光雷达的现有最先进方法13.291分。本文的主要贡献包括:
1.研究了端到端自动驾驶的两种主要模式:轨迹规划和直接控制,并建议将它们结合在一个集成的学习pipelines中,这是第一次联合学习和融合这两个分支进行预测。
2.设计了具有时间模块和轨迹引导注意力的多步骤控制预测分支,以实现时间推理,为了结合两个分支的优点,作者设计了一个基于情境的方案来融合两个输出。
3.作为一个简单但强大的基线,本文的方法仅使用单目摄像头作为输入,在CARLA排行榜上实现了新的最先进水平,许多竞争对手使用了多个传感器。作者进行了充分的消融研究,以验证方法的有效性。
整体框架
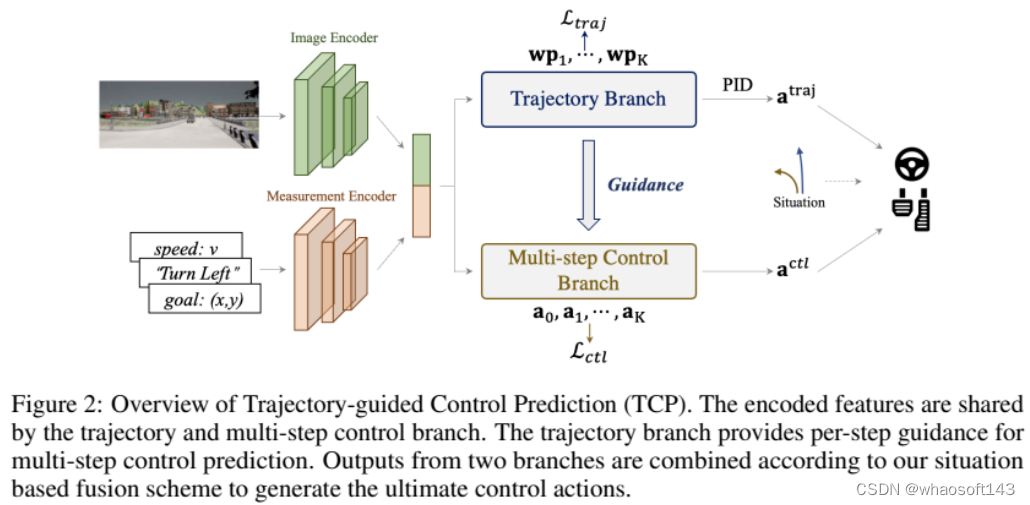
轨迹制导控制预测(TCP)概述,轨迹和多步控制分支共享编码特征。轨迹分支为多步控制预测提供每步指导,两个分支的输出根据基于情况的融合方案进行组合,以生成最终的控制动作。
概述如图2所示,整个架构由输入编码级和两个后续分支组成。输入图像i经过基于CNN的图像编码器,例如ResNet,以生成特征图F。同时,导航信息g与当前速度v连接以形成测量输入m,然后基于MLP的测量编码器将m作为其输入并输出测量特征jm。编码的特征然后由两个分支共享,用于后续的轨迹和控制预测。具体而言,控制分支是一种新颖的多步预测设计,具有轨迹分支的指导。最后,采用基于情境的融合方案来结合两种输出范式中的最佳。
实 验
为了评估我们的方法,我们使用 Kinect Azure 构建了一个真实世界数据集,并获取了 ground truth 深度。因为这种深度相机功耗较
本文的方法在CARLA驾驶模拟器中进行了验证和测试,给定由一系列稀疏导航点以及高级命令(直行、左转/右转、变道和车道跟随)定义的路线,闭环驾驶任务要求自动驾驶者朝着目的地行驶。它旨在模拟现实的交通状况,包括不同的挑战场景,如避障、穿越无信号交叉口和突然失去控制。有三个主要指标:驾驶得分、路线完成和违规得分。Route Completion是自治代理完成的路由的百分比,违规分数衡量道路沿线的违规次数,包括行人、车辆、道路布局、红灯等。驾驶分数是主要指标,是路线完成和违规分数的乘积。
数据集:使用随机天气条件下随机生成的路线,在CARLA模拟器提供的8个公共城镇中收集420K个数据。在8个城镇(Town01、Town03、Town04和Town06)中的4个城镇中训练了189K数据的TCP,以进行消融,并使用所有420K数据进行训练,以提交在线排行榜。
公共CARLA排行榜评估,本文的方法TCP和TCP Ens仅使用单目相机就分别获得了69.714和75.137的驾驶分数。
高,所以噪声会减少,深度质量也会比手机的 ToF 模块好得多。在将手机和 Azure Kinect 固定在一个联合安装座上后,将手机的 ToF 模块和超广角相机分别与Kinect深度相机进行标定。一旦标定完成,就可以将Kinect深度图重新投影到超广角相机和手机 ToF 相机进行比较。我们捕获了 4 个场景,总共 200 张快照。
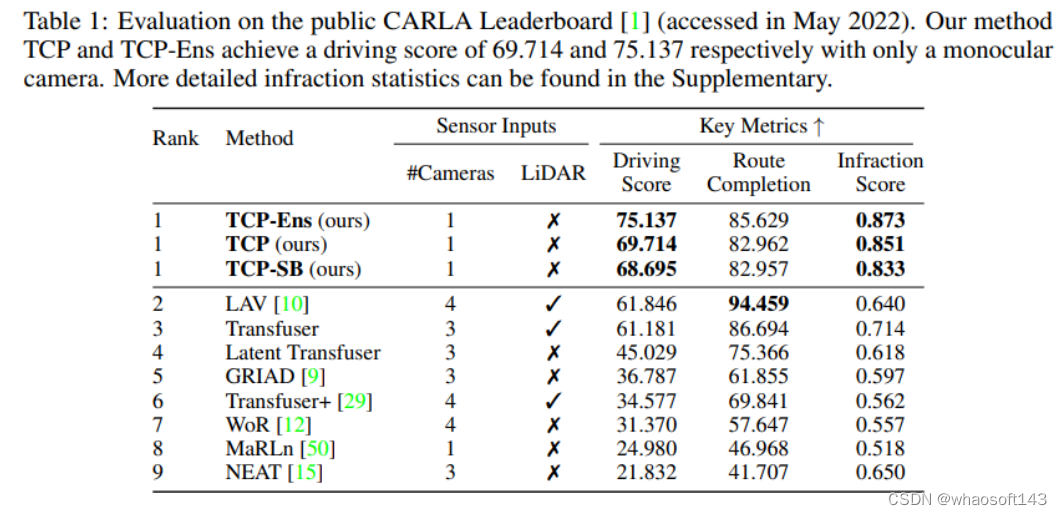
在违规频率方面,控制和仅轨迹模型之间的比较,TurnRatio是指转弯过程中发生的相应比率。
#关键技术与发展趋势
随着以ChatGPT为代表的生成式人工智能的发展,端到端自动驾驶系统得到了广泛关注,有望为通用场景的驾驶智能带来革命性突破。以全部模块神经网络化为特征的端到端系统对专家规则的依赖度低,功能的集约性与实时性强,具备智能涌现能力和跨场景应用潜力,是实现数据驱动自进化驾驶能力的重要途径。
近期,来自于清华大学的李升波等学者的论文,讨论了端到端汽车自动驾驶系统的关键技术与发展趋势。论文介绍了生成式人工智能的技术现状,总结了端到端自动驾驶的关键技术,归纳了该类自动驾驶系统的发展现状,并总结了生成式人工智能与自动驾驶融合发展的技术挑战。
论文地址:
https://aiview.cbpt.cnki.net/WKD/WebPublication/paperDigest.aspx?paperID=60ba64c1-3dee-4986-bed9-f86b98006872
下载链接:
https://kns.cnki.net/kcms/detail/detail.aspx?filename=DKJS202305001&dbname=cjfdtotal&dbcode=CJFD&v=MjMyODFTYkJmYkc0SE5MTXFvOUZaWVI2RGc4L3poWVU3enNPVDNpUXJSY3pGckNVUjdtZVplWnJGeXJsVjd2Skk=
1 生成式人工智能的技术现状
数据、算力和算法是大模型发展的支柱,其中算法是大模型的核心技术体现。现有大模型多以Transformer结构为基础,采用“预训练(Pre-training)+微调(Fine-tune)”技术进行参数学习,使之适配不同领域的具体任务,经剪枝压缩后完成最终部署。本节将围绕网络架构、预训练、微调和剪枝压缩四个方面对大模型关键技术进行介绍。
1.1 神经网络的架构设计
大模型的出现得益于深度学习浪潮中深度神经网络的发展。深层网络的学习建模能力更强,有利于模型的性能提升。
在2017年,Google提出了神经网络结构Transformer(图1),大幅提升了网络表达能力,在CV、NLP等多个领域大放异彩,Transformer现已成为大模型的基础网络结构之一。Transformer是以注意力机制为核心的编解码器结构,其主要结构为注意力、位置编码、残差连接、层归一化模块。Transformer被广泛应用于NLP、CV、RL等领域的大模型中。

图1 Transformer网络结构
1.2 预训练与微调技术
预训练是使大模型获得通用知识并加速模型在微调阶段收敛的关键步骤。根据序列建模的方式,语言模型可以分为自回归语言模型和自编码语言模型(图2)。自回归语言模型使用Transformer的解码器结构,根据前文预测下一个词,从而对序列的联合概率进行单向建模。自编码语言模型则利用Transformer的编码器结构,通过预测序列中的某个词来双向建模序列的联合概率。
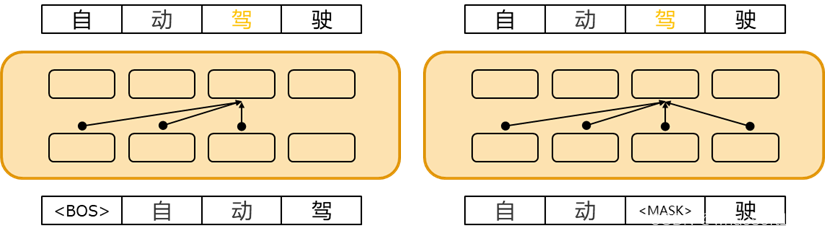
图2两类语言模型示意图
微调是指将预训练好的大模型在下游任务中进行调整,使之与具体任务更加适配。微调后的大模型与预训练大模型相比,在下游任务中性能通常大幅提升。随着模型规模不断增大,微调所有参数变得十分困难,因此近年来出现了多种高效微调方法,包括Vanilla Finetune、Prompt Tuning以及Reinforcement Learning from Human Feedback(RLHF)等方法(图3)。
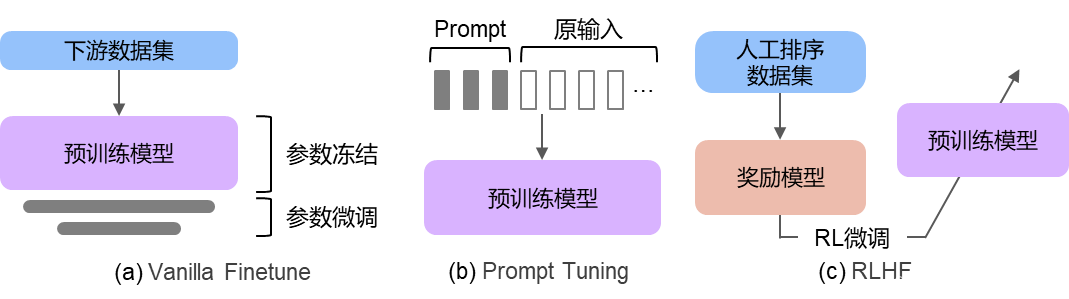
图3 三种微调方法示意图
1.3 模型的剪枝与压缩
训练好的大模型需要部署在算力和内存受限的系统上,因此需要对大模型进行剪枝和压缩,减小模型中的冗余结构和信息,使其能在受限的计算资源上进行快速推理,同时尽量减小对模型精度的影响。大模型的压缩方法主要包括模型剪枝、知识蒸馏和量化。
2 端到端自动驾驶的关键技术
人工智能技术与自动驾驶技术的融合,关键在于打通以车云协同为核心的边缘场景数据采集和自动驾驶模型训练的在线循环迭代路径。图4展示了车云协同的自动驾驶大模型开发方案:由一定规模具有网联功能的车辆进行众包数据采集,数据清洗和筛选之后上传至云控计算平台;利用云控平台的充足算力,生成海量仿真驾驶数据;融合虚实数据进行场景构建,利用自监督学习、强化学习、对抗学习等方法对自动驾驶大模型进行在线迭代优化;所学大模型经剪枝压缩后得到车规级实时模型,并通过OTA方式下载到车载芯片,完成车端驾驶策略的自进化学习。
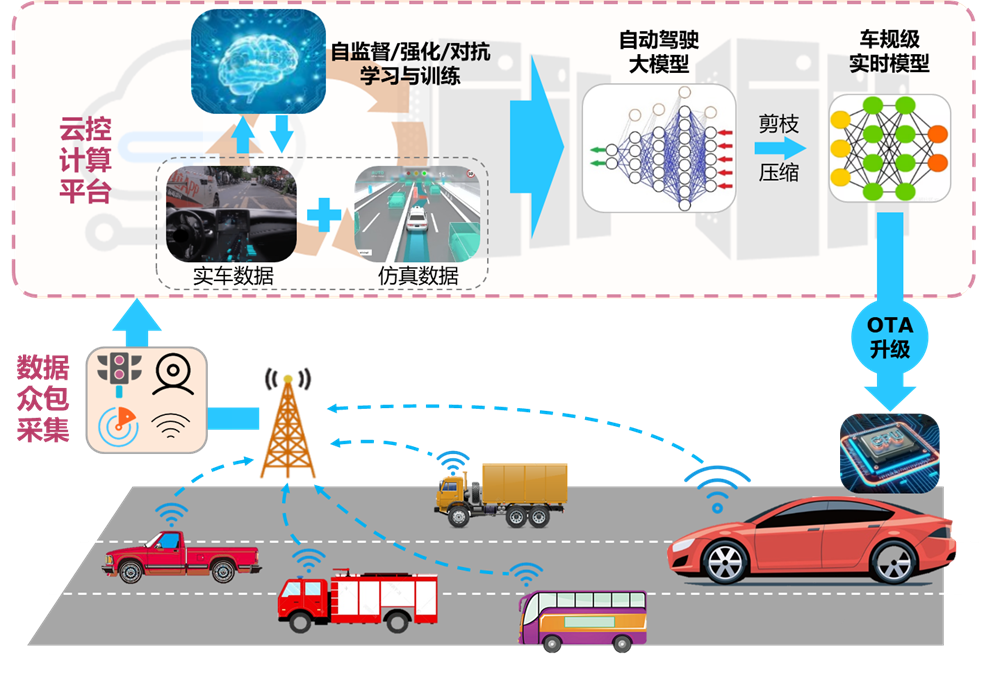
图4 车云协同的自动驾驶大模型开发方案
具体研究内容包括:(1)面向自动驾驶的大模型基础理论;(2)自动驾驶感知认知通用基础大模型;(3)自动驾驶决策控制通用基础大模型;(4)自动驾驶大数据采集生成与自动标注;(5)车云协同的基础大模型持续进化;(6)自主可控的车用集成部署工具链与平台。
3 端到端自动驾驶的技术发展趋势
随着大模型技术的不断发展,以ChatGPT为代表的大模型技术展现出令人惊叹的效果。大模型已在多项工业实践中得到初步应用中,有望成为实体经济新的增长引擎。
3.1 感知大模型
自动驾驶的感知模块利用传感器采集的数据,实时动态地生成驾驶环境的感知结果。感知大模型是提升车辆自动驾驶能力的核心驱动力之一,这些模型能识别和理解道路、交通标志、行人、车辆等信息,为自动驾驶车辆提供环境感知,继而用于车辆自主决策。
目前在自动驾驶感知方面已有相关应用,例如百度文心UFO 2.0视觉大模型、华为盘古CV以及商汤的INTERN大模型等。
鸟瞰图感知(Bird's Eye View,BEV)是当前主流感知方案之一,它将摄像头、雷达等多源传感器的感知信息转换至鸟瞰视角,并行地完成目标检测、图像分割、跟踪和预测等多项感知任务,如图5所示。典型工作如特斯拉的BEV感知,百度的UniBEV和商汤的FastBEV。
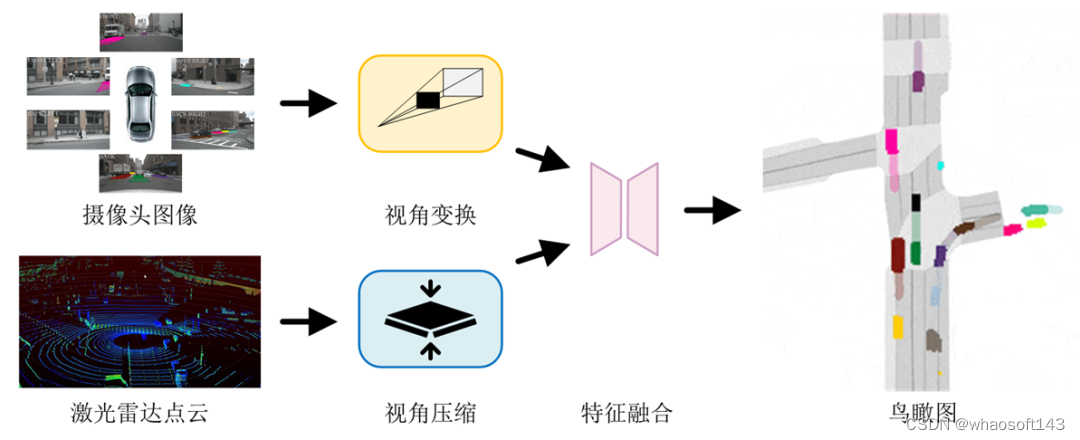
图5 鸟瞰图感知流程
3.2 预测大模型
预测是自动驾驶的关键组成部分,它主要涉及对周边交通参与者未来运动状态的预测,也称为轨迹预测。轨迹预测综合考虑道路结构、历史轨迹以及与其他交通参与者的交互关系等信息,输出一条或多条未来可能行驶的轨迹,供下游决策控制任务参考。数据驱动型的轨迹预测方法通常采用编码-解码架构,包括信息表示、场景编码和多模态解码等主要环节。代表工作包括谷歌Wayformer、清华SEPT和毫末智行DriveGPT等。
3.3 决控大模型
自主决策与运动控制是自动驾驶的核心功能,决策与控制水平的高低决定了自动驾驶汽车的智能程度。自动驾驶决控系统的技术方案主要经过了三个发展阶段:专家规则型、模仿学习型以及类脑学习型。自动驾驶决策控制大模型的目标是构建以深度学习与强化学习为代表、数据驱动与知识引导相结合的决策控制通用基础模型训练算法,为自动驾驶智能性突破提供解决方案。
目前工业界尚缺乏用于自动驾驶的决策与控制一体化大模型。由清华大学提出的集成式架构(IDC)将决策与控制整合为统一的约束型最优控制问题,利用数据驱动算法求解评价模型与策略模型,它以环境感知结果为输入,直接输出油门、制动、转向等控制指令。IDC 具有在线计算效率高、可解释性强、无需人工标注数据、可自回归地预测下一个动作等优点,为大模型应用于自动驾驶决控奠定了基础。图6为传统专家分层式和集成式决控架构示意图。

图6 两种决控架构示意图
3.4 端到端训练的自动驾驶模型
端到端的自动驾驶方案将输入的原始传感器数据直接映射输出为轨迹点或低级控制命令,与分层式架构相比,其具有简洁的方案结构与巨大的性能潜力。端到端方案的工业应用面临着数据短缺、学习效率低下和鲁棒性差等问题,尤其无法保障任何极端情况下模型输出的安全性,这将成为其应用于自动驾驶领域的最大挑战。代表工作有上海人工智能实验室的UniAD和特斯拉FSD Beta V12。
随着算力发展与大模型技术的兴起,端到端的自动驾驶将为行业带来新的突破。针对端到端方案,不断降低其技术门槛、进行可解释性研究、以及提出更多保障端到端自动驾驶安全的算法,将是未来热门的研究方向。
4 总结
以大模型为代表的生成式人工智能是智能网联汽车发展的战略前瞻方向。这需要进一步突破:适用于驾驶大数据的大模型预训练方法和学习理论;泛场景、泛对象、跨模态适用的感知认知和决策控制通用基础模型;仿真环境数据与真实场景数据结合的大规模数据采集与标注系统;车云协同的基础大模型持续进化技术与车用集成部署工具链与平台等。以上技术的攻关将打通以车云协同为核心的驾驶大数据和自动驾驶大模型算法在线循环迭代路径,推动端到端自动驾驶技术在全场景的落地应用。
#Sora会改变自动驾驶的终局吗?
这场AI热给自动驾驶带来的新课题,已然摆在眼前。
“我们团队目前最重要的工作就是复现Sora”,清华大学助理教授剑寒(化名)告诉「智车星球」,他的主要研究方向是机器人相关的计算机视觉,“不止我们,从2月16日(Sora发布当天)开始,基本所有在这个赛道的人都在转方向。”
关于原子弹,最有价值的情报就是它可以被造出来。
这句话再次被Sora印证。
不过在剑寒看来,这很正常,“科研界可能有100种前瞻方向,不可能都尝试,OpenAI出来的效果这么好,大家开始学习他的做法,这没有什么问题。就像世界上有这么多材料,尝试到用钨做灯丝呈现出了很好的效果,大家都会跟进。”
除了技术端,资本端的跟进也很迅速。
券商的朋友甚至等不及春节假期结束就找到我,询问是否能介绍相关专家交流一下Sora对自动驾驶的影响。
这场关于“大模型+自动驾驶”能否产生新的化学反应的讨论,再次因为OpenAI带来了新一轮的热度。
1 新的仿真路线
此次Sora的推出,展示出了明显优于此前生成式视觉模型的成果,这也让不少人对其在自动驾驶仿真领域的应用产生了期待。
在51Sim CEO鲍世强看来,Sora 已经展现出了多视角长时长下一致性较高的图像,场景的真实度和细节也很好。
“其实从仿真的角度看,生成式视频模型做的事和游戏引擎没有本质区别,只是一个是更可控的显式的,一个是数据驱动的隐式的。游戏引擎的一个劣势是如果要达到较强的真实感门槛较高,需要建模大量的高质量资产,优点是可控制性和可编辑性较强,世界完全受控。但 Sora的可编辑性以及可控性从目前的展示来看还不确认,我认为挑战还是比较大。” 鲍世强解释道。“
目前,合成数据主要分为三个路线——物理仿真与图形渲染路线、基于神经辐射场(NeRF、3DGaussion 等)的场景重建路线以及基于世界模型的生成路线。
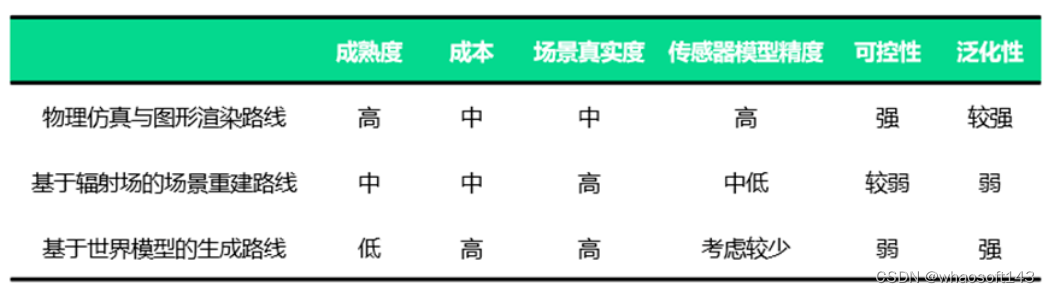
“基于世界模型的生成路线还处于发展的早期阶段,与视频创作领域不同,智驾场景落地确定性要求比较高,需要呈现出一致性和物理规律,如何可控的生成更多有价值的Corner Case 还有待深入探讨,但后续发展空间是巨大的。“ 鲍世强告诉[智车星球]。
目前,在这条垂直赛道上,国内已经有企业在做相关研究。
去年9月,极佳科技和清华大学的研究人员就推出了真实世界驱动的自动驾驶世界模型DriveDreamer。
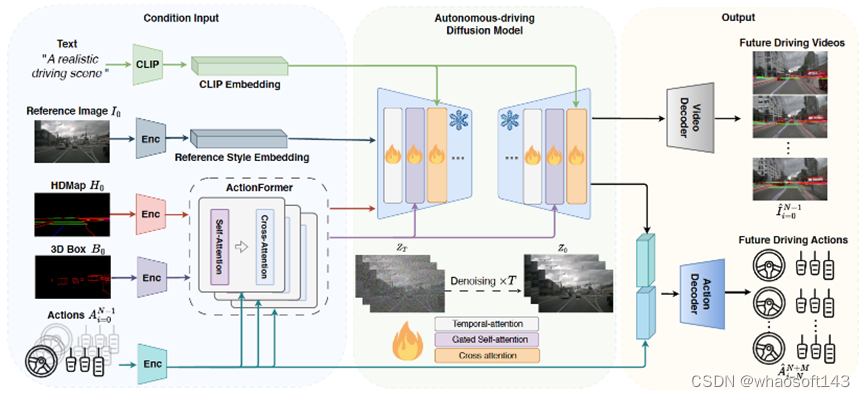
△DriveDreamer 总体结构框图
据极佳科技CEO黄冠介绍,DriveDreamer使用了数十亿图像数据预训练的 Diffusion model 作为基础模型,并利用百万张自动驾驶场景图像帧进行模型训练,在此过程中引入了数十亿可学习参数。
DriveDreamer能够生成符合交通结构化信息的视频;可以根据文本描述改变生成视频的天气、时间等;可以根据输入的驾驶动作生成不同的未来驾驶场景视频。
“现在已经有不少客户基于DriveDreamer做数据生成、闭环仿真,Sora的出现也让我们对这个方向更确定。当然,目前还有准确性、精细度等各方面的工程问题需要继续提升。” 黄冠解释道。
2 大模型“加速”自动驾驶
虽然文本视频生成大模型完全进入自动驾驶量产环节还有不少需要提升的地方,但大模型对于自动驾驶是否有加成,在业内人士看来是一个需要做质疑的讨论。
“在过去一年多的时间内,这已经是被广泛验证的事情。”长城汽车AI Lab负责人杨继峰告诉「智车星球」,“大模型在自动驾驶领域,首先被证实效果的领域是数据重建,基于此诞生了新的场景生成在仿真领域的机会;Sora无疑规模更大也更通用,但是在自动驾驶领域的落地还需要进一步探索,特别是针对空间和语音应用。然后影响到的end to end,以及最近很热的LLM-based driving agent类型的大模型算法架构。”
简单来说,就是通过增加推理能力来处理复杂场景从而提高性能,并通过极大地简化模型开发来降低成本。
自动驾驶软件的初创公司Ghost Autonomy(曾获得OpenAI创业基金500万美元投资,旨在将大规模、多模态的大语言模型引入自动驾驶领域)的模型工程师Prannay Khosla也在文章《One Model To Rule The Road?》中提到,大语言模型(LLMs,广义上被称为基础模型)正在改变自动驾驶开发的多个环节。
首先是在理解及标注数据层面,Prannay Khosla提到模型工程的核心是数据问题,即更好的数据产生更好的模型,“更好的数据”不仅仅是关于规模,还有完备性。训练集必须代表现实世界中可能遇到的每一个概念,例如,每一种车道标记类型、每一种道路配置、每一种障碍物、建筑类型等。收集所有这些数据不仅昂贵,而且还需要进行复杂的数据挖掘,从而标注相关样本以开发出完备的训练集。人类需要数十万小时来开发这些训练集,但是它们仍然不完备。
而大型模型在解决这个问题上已被证明特别有用,能够通过语言接口对复杂问题进行zero-shot泛化(即解决从未在相关数据集上训练过的新任务),以更低的代价对数据集进行整理和标注。在这种应用中,大型模型可能不用于最终产品的推理,但用于帮助训练最终交付的模型。
其次,大模型能提升可解释性。早期的自动驾驶被庞大的代码库所主导,导致在复杂场景中难以进行调试。LLMs提供了一种与神经网络中的注意力层进行交互的新途径,使得在驾驶系统内部实现提示和可解释性成为可能。同样,这里的大型模型是一个工具,帮助开发和解释在运行时部署的其他模型。
而随着LLMs显示出可以真正“理解世界”的潜力,Prannay Khosla认为这种新的理解水平可以扩展到驾驶任务,使模型无需显式训练(Explicit Training),就能安全自然地驾驭复杂场景,这为解决“长尾问题”提供了新的路径。LLMs还显示出在决策中使用大量上下文信息的能力。
最后,Prannay Khosla也提到了基于action的生成式视觉模型,例如GANs和Diffusion models,可以在线创建逼真的驾驶场景,可以用于有效的仿真。
但同样,Prannay Khosla也提到尚不完全清楚大型视觉模型是否能生成有意思的Corner Case场景。像素级仿真渲染对于构建规划器和测试道路预测模型非常有用,但对于测试和制造自动驾驶汽车所需的规模来说,计算效率可能不高。
3 自动驾驶终局在哪?
目前,视频生成方法主要分为两类:基于Transformer和基于扩散模型。
前者源于大型语言模型方案,通常是采用对下一个Token的自回归预测或对masked Token的并行解码来生成视频。
利用Transformer进行Token预测可以高效学习到视频信号的动态信息,并可以复用大语言模型领域的经验,因此,基于Transformer的方案是学习通用世界模型的一种有效途径。
扩散模型是近两年来视频生成领域的研究热点,是“文生图”的代表,相关研究成果也有不少。比如在2D扩散模型潜在空间的基础上引入时间维度,并使用视频数据进行微调,有效地将图像生成器转变为视频生成器,实现高分辨率视频合成;有基于预训练的2D扩散模型构建了级联视频扩散模型;也有基于Transformer的扩散模型改进了视频生成。
不过,基于扩散模型的方法难以在单一模型内整合多种模态。此外,基于扩散模型的方案难以拓展到更大参数,因此很难学习到通用世界的变化和运动规律。
Sora则是结合了Transformer 和 Diffusion 两个模型,在过去DALL.E和GPT的研究基础上,采用了DALL.E 3中的重述技术。因此能更好遵循用户的文本描述,并且有极强的扩展性。
再简单些,OpenAI用GPT的能力做视频文本对齐,通过将多个高分辨率视频素材进行降维处理,然后密集训练,最后就是我们熟悉的大力出奇迹。
阳光底下无新鲜事,虽然没有网络大小、用了哪些数据、具体怎么训练等细节,但从OpenAI公布的报告中,并没有“武功秘籍”般的存在,思路和方法都是大家熟悉的东西。
但AI热与明星公司OpenAI的结合,再加上关于技术本身之外的讨论,让Sora的热度来到了极高的位置,也引出了大家对自动驾驶终局的讨论。
2月18日,马斯克在科技主播 @Dr.KnowItAll 一条主题为“OpenAI 的重磅炸弹证实了特斯拉的理论”的视频下留言,表示“特斯拉已经能够用精确物理原理制作真实世界视频大约一年了”。
随后马斯克在 X 上转发了一条 2023 年的视频,内容是特斯拉自动驾驶总监 Ashok Elluswamy 向外界介绍特斯拉如何用 AI 模拟真实世界驾驶。
训练 AI 理解和生成一个真实的场景或世界,是特斯拉与Sora一致的训练思路。
过去十几年,虽然技术在不断迭代,但自动驾驶的本质依然是通过海量数据教会系统开车,即便目前在不少环节已经有大模型加入,也只是加速了过程,并没有解决自动驾驶研发过程中遇见的问题。
“但是自动驾驶从世界感知进入到通用认知以后,自动驾驶的本质很可能就会发生变化,那就是Al Agent——LLM+Memory+Tool+Planning。自动驾驶就变成了怎么教一个通用智慧体开车的问题,通过大模型的预训练去学会推理、记忆等能力和道路驾驶等通用知识,通过SFT去强化场景驾驶行为,通过RL把数据闭环变成奖励模型。这跟当前依赖海量数据和Corner Case的思路完全不同。” 杨继峰说道。
“(自动驾驶)最终可能就是一个语言模型加世界模型。”黄冠也提出了类似观点。
可以说,对于自动驾驶,Sora这次的小试牛刀,不仅展示出了相关技术在自动驾驶仿真领域的应用潜力,更是让行业看到大模型对真实世界有了理解和模拟之后,引发了对于自动驾驶发展方向的思考。
这场AI热给自动驾驶带来的新课题,已然摆在眼前。
#自动驾驶标注行业是否会被世界模型所颠覆?
1: 数据标注面临的问题(特别是基于BEV 任务)
随着基于BEV transformer 任务的兴起,随之带来的是对数据的依赖变的越来越重,基于BEV 任务的标注也变得越来越重要。目前来看无论是2D-3D的联合障碍物标注,还是基于重建点云的clip 的车道线或者Occpuancy 任务标注都还是太贵了(和2D标注任务相比,贵了很多)。当然业界里面也有很多基于大模型等的半自动化,或者自动化标注的研究。还有一方面是自动驾驶的数据采集,周期太过于漫长,还涉及到数据合规能一系列问题。比如,你想采集一个平板车跨相机的场景,或者一个车道线城市多变少,少变多的场景,就需要采集人员专项去构建这样的场景。
2: 24年会是世界模型的奇点时刻吗?
世界模型这个概念太过于大,或者说成传感器仿真。在特斯拉AI day 上第一次见识到仿真对标注的颠覆,whaosoft开发板商城aiot物联网设备

图1: 特斯拉的自动化标注效果
图二 4D 重建的效果
当时看到之后是震惊, 还是震惊!就像当成特斯拉的BEV 一样颠覆。随着越来越多的研究人员在这个方向不断发力,有很多优秀的研究呈现出来。UniSim 的自动驾驶仿真系统, 具备 重放,动态物体行为控制, 自由视角渲染等功能(这应该是每一个训练模型的同学都想拥有的) 。

还可以对lidar 进行仿真。


NeuRAD: Neural Rendering for Autonomous Driving
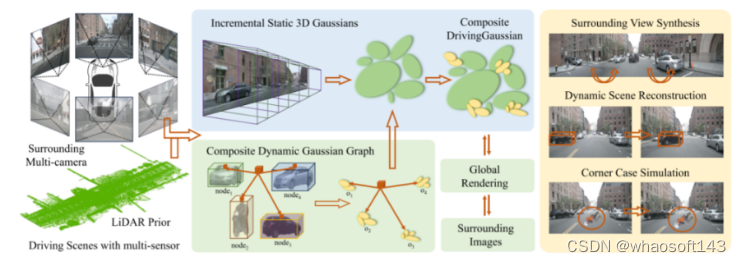
DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes 以上的方法都大多和Nerf 相关,整个pipeline 都比较重。还有另一个方向,基于扩散的研究方向。目前也取得了不错的研究。

BEVControl: Accurately Controlling Street-view Elements withMulti-perspective Consistency via BEV Sketch Layout

BEVControl: Accurately Controlling Street-view Elements withMulti-perspective Consistency via BEV Sketch Layout

< MagDriver MAGIC DRIVE : STREET VIEW GENERATION WITH DIVERSE 3D GEOMETRY CONTROL >
技术发展太快了,传感器仿真的门槛正在降低,有可能24年自动驾驶标注行业会出现一些颠覆性的产品出来!
#World Model 最新综述
在快速发展的自动驾驶领域,准确预测未来事件并评估其影响的能力对安全性和效率至关重要,对决策过程至关重要。世界模型已经成为一种变革性的方法,使自动驾驶系统能够合成和解释大量的传感器数据,从而预测潜在的未来场景并弥补信息差距。本文对自动驾驶世界模型的现状和未来进展进行了初步回顾,涵盖了它们的理论基础、实际应用以及旨在克服现有局限性的正在进行的研究工作。这项调查强调了世界模型在推进自动驾驶技术方面的重要作用,希望成为研究界的基础参考,促进快速进入和理解这一新兴领域,并激励持续的创新和探索。
简介
开发能够在复杂的现实世界场景中无缝导航的自动驾驶系统,仍然是当代技术的一个强大前沿。这一挑战不仅是技术性的,而且是哲学性的,探索将人类智能与人工构建区分开来的认知和感知的本质。这一挑战的关键在于向机器灌输人类毫不费力就能运用的直觉推理和“常识”。当前的机器学习系统,尽管有着强大的能力,但在人类轻松解决的模式识别任务中往往会出现失误,这凸显了我们在寻求真正自主系统方面的巨大差距。另一方面,人类的决策深深植根于感官感知,受到这些感知的记忆和直接观察的约束。除了感知之外,人类还拥有预测行动结果、预见潜在未来和预测感官输入变化的神奇能力,这些能力是我们与世界互动的基础。在机器中复制这种能力的努力不仅是一项工程挑战,也是弥合人类和机器智能之间认知鸿沟的一步。
为了解决这一差距,世界模型已成为一种关键的解决方案,通过模拟人类感知和决策过程,为系统提供预测和适应动态环境的能力。面对现实世界场景的复杂性和不可预测性,这种进化至关重要,传统的人工智能方法难以复制人类认知过程的深度和可变性。世界模型具有弥合人类和机器智能之间认知鸿沟的潜力,为实现更复杂的自动驾驶系统提供了一条途径,这突显了世界模型的必要性。
世界模型从20世纪70年代控制理论的概念框架到目前在人工智能研究中的突出地位,反映了技术进化和跨学科融合的显著轨迹。先驱们提出的控制理论的最初公式是基础,为动态系统管理中的计算模型集成奠定了基础。这些早期的努力有助于证明应用数学模型预测和控制复杂系统的潜力,这一原理最终将成为世界模型发展的基础。whaoの开发板商城aiot物联网设备
随着该领域的发展,神经网络的出现带来了范式的转变,使动态系统的建模具有无与伦比的深度和复杂性。这种从静态线性模型到动态非线性表示的转变促进了对环境相互作用的更深入理解,为我们今天看到的复杂世界模型奠定了基础。递归神经网络(RNN)的集成尤其具有变革性,标志着向能够进行时间数据处理的系统迈进,这对预测未来状态和实现抽象推理至关重要。
2018年,Ha和Schmidhuber正式公布了世界模型,这是一个决定性的时刻,捕捉到了人工智能研究界的集体愿望,即赋予机器一种让人想起人类意识的认知处理水平。通过利用混合密度网络(MDN)和RNN的力量,这项工作阐明了无监督学习提取和解释环境数据中固有的空间和时间模式的途径。这一突破的意义怎么强调都不为过,它表明,自主系统可以对其运行环境实现细致入微的理解,以以前无法达到的准确性预测未来的情景。
在自动驾驶领域,世界模型的引入标志着向数据驱动智能的关键转变,预测和模拟未来场景的能力成为安全和高效的基石。数据稀缺的挑战,特别是在纯电动汽车标签等专业任务中,突显了世界模型等创新解决方案的实际必要性。通过从历史数据中生成预测场景,这些模型不仅规避了数据收集和标记带来的限制,而且增强了在模拟环境中对自主系统的训练,这些模拟环境可以反映甚至超越现实世界条件的复杂性。这种方法预示着一个新时代的到来,在这个时代,自动驾驶汽车配备了反映一种直觉的预测能力,使它们能够以前所未有的复杂程度导航和应对环境。
本文深入研究了复杂的世界模型,探索了它们的基本原理、方法进步以及在自动驾驶领域的实际应用。它克服了困扰该领域的挑战,预测了未来的研究轨迹,并思考了将世界模型集成到自主系统中的更广泛影响。通过这样做,这项工作不仅希望记录这一领域的进展,还希望激发人们对人工智能和人类认知之间共生关系的更深入思考,预示着自动驾驶技术的新时代。
世界模型的发展
本节概述了世界模型的复杂架构,详细介绍了它们的关键组成部分以及在各种研究中的重要应用。这些模型被设计用于复制人类大脑的复杂认知过程,使自主系统能够以类似于人类思维的方式做出决策并了解其环境。
世界模型的架构基础
世界模型的架构旨在模仿人脑的连贯思维和决策过程,集成了几个关键组件:
1)感知模块:这个基本元素充当系统的感官输入,类似于人类的感官。它采用先进的传感器和编码器模块,如可变自动编码器(VAE)、Masked自动编码器(MAE)和离散自动编码器(DAE),将环境输入(图像、视频、文本、控制命令)处理和压缩为更易于管理的格式。该模块的有效性对于准确感知复杂动态环境至关重要,有助于详细了解模型的后续预测和决策。
2)记忆模块:与人类海马体类似,记忆模块可用于记录和管理过去、现在和预测的世界状态及其相关成本或回报。它通过回放最近的经历来支持短期和长期记忆功能,这一过程通过将过去的见解融入未来的决策来增强学习和适应。该模块综合和保留关键信息的能力对于深入了解一段时间内的环境动态至关重要。
3)控制/运动模块:该组件直接负责通过动作与环境进行交互。它评估当前状态和世界模型提供的预测,以确定旨在实现特定目标的最佳行动顺序,例如最小化成本或最大化回报。该模块的复杂性在于它能够集成感官数据、记忆和预测见解,从而做出明智的战略决策,应对现实世界场景的复杂性。
4)世界模型模块:在体系结构之前,世界模型模块执行两个主要功能:估计有关当前世界状态的任何缺失信息和预测环境的未来状态。这种双重能力使系统能够生成其周围环境的全面预测模型,考虑不确定性和动态变化。通过模拟潜在的未来场景,该模块使系统能够主动准备和调整其策略,反映人类认知中的预测性和适应性思维过程。
这些组成部分共同形成了一个强大的框架,使世界模型能够模拟类似于人类的认知过程和决策。通过集成这些模块,世界模型实现了对其环境的全面和预测性理解,这对于开发能够以前所未有的复杂度在现实世界中导航和交互的自主系统至关重要。

在高维感官输入场景中,世界模型利用潜在的动力学模型来抽象地表示观测到的信息,从而能够在潜在状态空间内进行紧凑的前向预测。由于深度学习和潜在变量模型的进步,这些潜在状态比高维数据的直接预测更具空间效率,有助于执行许多并行预测。以十字路口汽车方向的模糊性为例,这种情况象征着现实世界动力学固有的不可预测性。潜在变量是表示这些不确定结果的有力工具,为世界模型设想基于当前状态的一系列未来可能性奠定了基础。这项努力的关键在于将预测的确定性方面与现实世界现象的内在不确定性相协调,这是世界模型功效的核心平衡行为。
为了应对这一挑战,人们提出了各种策略,从通过温度变量引入不确定性到采用递归状态空间模型(RSSM)和联合嵌入预测架构(JEPA)等结构化框架。这些方法致力于微调预测的准确性和灵活性之间的平衡。此外,利用Top-k采样并从基于CNN的模型过渡到变换器架构,如变换器状态空间模型(TSSM)或时空逐片变换器(STPT),已显示出通过更好地近似现实世界的复杂性和不确定性来增强模型性能的前景。这些解决方案努力使世界模型的输出与现实世界的可能发展更紧密地联系在一起。这种一致性至关重要,因为与游戏环境相比,现实世界的影响因素范围要广得多,未来结果的随机性也更大。过度依赖最高概率的预测可能导致长期预测的重复周期。相反,预测中的过度随机性会导致荒谬的未来与现实大相径庭。
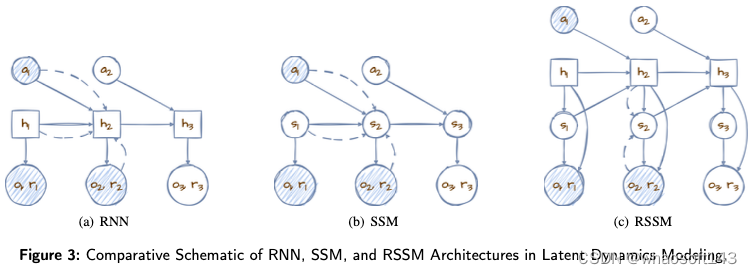
特别是RSSM和JEPA是世界模型研究中使用最广泛的核心结构:
1)递归状态空间模型(RSSM)是Dreamer世界模型系列中的一个关键模型,旨在促进纯粹在潜在空间内的前向预测。这种创新的结构使模型能够通过潜在状态空间进行预测,其中过渡模型中的随机路径和确定性路径在成功规划中发挥着关键作用。
图3展示了三个时间步长的潜在动力学模型示意图。该模型最初观察两个时间步长,然后预测第三个时间步长。在这里,随机变量(圆形)和确定性变量(方形)在模型的体系结构中相互作用——实线表示生成过程,而虚线表示推理路径。图3(a)中的初始确定性推理方法揭示了由于其固定性质,其在捕捉各种潜在未来方面的局限性。相反,考虑到其固有的不可预测性,图3(b)中的完全随机方法在跨时间步长的信息保持方面提出了挑战。
RSSM的创新之处在于它将状态战略性地分解为图3(c)中的随机和确定性分量,有效地利用了确定性元素的预测稳定性和随机元素的自适应潜力。这种混合结构确保了强大的学习和预测能力,适应了现实世界动态的不可预测性,同时保持了信息的连续性。通过将RNN的优势与状态空间模型(SSM)的灵活性相结合,RSSM为世界模型建立了一个全面的框架,增强了它们预测未来状态的能力,同时兼顾了精度和适应性。
2)联合嵌入预测体系结构(JEPA)通过关注表示空间而不是直接、详细的预测,标志着预测建模的范式转变。如图4所示,通过抽象输入(𝐱) 和目标(𝐲) 通过双编码器转换为表示(𝐬𝑥 和𝐬𝑦), 并利用潜在变量(𝐳) 对于预测,JEPA在效率和准确性方面实现了显著的飞跃。该模型擅长滤除噪声和不相关信息,专注于预测任务的本质。潜在变量的战略使用(𝐳) 管理不确定性进一步细化了模型的重点,使其能够更精确地预测抽象结果。通过优先考虑相关特征并包含预测任务的固有不确定性,JEPA不仅简化了预测过程,还确保了结果的相关性和可靠性,为复杂环境中的预测建模树立了新标准。

Broad Spectrum Applications
如表1所示,世界模型在不同的环境中展示了无与伦比的性能,尤其是在游戏中,它们的功能得到了显著展示。在雅达利100k排行榜的竞争格局中,世界车型占据主导地位,前五名中有四名由这些创新架构占据。其中,EfficientZero在基于图像的强化学习中显著提高了采样效率,利用MuZero的基本原理,在短短两小时的训练内实现了人类可比的游戏熟练度。在《我的世界》游戏中,DreamerV3标志着一个里程碑,成为自主开采钻石的首个模型,这一壮举在没有利用人工生成的数据或预定义的学习课程的情况下完成。这一成就归功于其对符号预测的新颖使用,通过使用静态符号转换,促进了模型在不同环境尺度上的适应性。相反,HarmonyDream在世界模型学习中引入了一种动态的损失缩放方法,通过规模、维度和训练动态的复杂平衡来优化多任务学习效率。DreamerV3的符号转换与HarmonyDream的动态损耗调整的协同集成有可能进一步提升世界模型的性能和多功能性。


基于图像的联合嵌入预测架构(I-JEPA)说明了一种在不依赖手工制作的数据增强的情况下学习高度语义图像表示的方法。I-JEPA使用抽象表示预测丢失的目标信息,有效地消除了不必要的像素级细节。这使模型能够学习更多的语义特征,通过对世界抽象表示的自我监督学习,实现对不完整图像的更准确分析和完成。除了图像之外,该架构还通过基于音频的联合嵌入预测架构(A-JEPA)展示了高可扩展性,在多个音频和语音分类任务上设置了最先进的性能,优于依赖外部监督预训练的模型。
在Fetch、DeepMind Control Suite和Meta world等机器人操作中,潜在探索者成就者(LEXA)通过想象力同时训练探索者和成就者,在40项机器人操作和移动任务中优于以前的无监督方法。此外,在这些任务中,L3P设计了一种新的算法来学习分散在目标空间中的潜在地标,在三种机器人操作环境中实现了学习速度和测试时间泛化的优势。谷歌团队创新性地将世界模型的概念应用于机器人导航任务,利用它们来获取周围环境的信息,并使智能代理能够预测其行为在特定环境中的后果。Pathdreamer在机器人导航中的实施利用了世界模型来增强环境意识和预测规划,通过创新地使用3D点云来表示环境,显著提高了导航成功率。此外,SafeDreamer将基于拉格朗日的方法集成到Dreamer框架中,用于安全强化学习,证明了高性能、低成本安全应用的可行性。
世界模型的快速训练能力,以DayDreamer的真实世界机器人学习效率为例,与传统方法形成鲜明对比,突显了这些模型在加速学习过程和提高性能方面的变革潜力。
虚拟场景和视频生成成为关键应用,SORA和Genie在这一领域取得了领先进展。SORA能够根据不同的提示制作连贯、高清晰度的视频,这是朝着模拟复杂世界动态迈出的重要一步。尽管SORA在物理交互模拟方面面临挑战,但其一致的3D空间表示突出了其作为基础世界模型的潜力。Genie的交互式环境生成虽然在视频质量上不如SORA先进,但引入了用户驱动的世界操纵的新维度,让我们得以一窥世界模型在创建沉浸式可控虚拟现实方面的未来应用。
这项全面的研究强调了世界模型的非凡多功能性和前沿性,说明了它们在推动游戏、机器人、虚拟环境生成等领域的创新方面的基础作用。这些模型的能力与动态适应和多领域泛化的融合预示着人工智能的新时代,在这个时代,世界模型不仅可以作为特定任务的工具,还可以作为更广泛的探索、学习和发现的平台。
自动驾驶中的世界模型
本节深入探讨了世界模型在自动驾驶领域的变革性应用,强调了它们对环境理解、动态预测和阐明运动物理原理的关键贡献。作为世界模型应用的一个新兴前沿,自动驾驶领域为利用这些先进的计算框架带来了独特的挑战和机遇。尽管人们对自动驾驶的兴趣与日俱增,但将世界模型融入自动驾驶主要围绕着场景生成、规划和控制机制展开,这些领域已经成熟,可以进行探索和创新。

驾驶场景生成
自动驾驶中的数据获取遇到了巨大的障碍,包括与数据收集和注释相关的高昂成本、法律约束和安全考虑。通过自我监督学习范式,世界模型能够从大量未标记的数据中提取有价值的见解,从而以具有成本效益的方式提高模型性能,从而提供了一个有前景的解决方案。世界模型在驾驶场景生成中的应用尤其值得注意,因为它有助于创建各种逼真的驾驶环境。这一能力大大丰富了训练数据集,使自动驾驶系统具有在罕见和复杂的驾驶场景中导航的鲁棒性。
GAIA-1代表了一种新颖的自主生成人工智能模型,能够使用视频、文本和动作输入创建逼真的驾驶视频。GAIA-1通过Wayve接受了来自英国城市的大量真实世界驾驶数据的培训,学习并理解驾驶场景中的一些真实世界规则和关键概念,包括不同类型的车辆、行人、建筑和基础设施。它可以基于几秒钟的视频输入来预测和生成后续的驾驶场景。值得注意的是,生成的未来驾驶场景与提示视频没有密切联系,而是基于GAIA-1对世界规则的理解。以自回归变换器网络为核心,GAIA-1预测以输入图像、文本和动作标记为条件的即将到来的图像标记,然后将这些预测解码回像素空间。GAIA-1可以预测多种潜在的未来,并根据提示(例如,不断变化的天气、场景、交通参与者、车辆动作)生成不同的视频或特定驾驶场景,甚至包括其训练集之外的动作和场景(例如,强行进入人行道)。这证明了它理解和推断训练集中没有的驾驶概念的能力。在现实世界中,由于这种驾驶行为的风险性,很难获得数据。驾驶场景生成允许模拟测试,丰富数据组成,增强复杂场景中的系统能力,并更好地评估现有驾驶模型。此外,GAIA-1生成连贯的动作,并有效地捕捉3D几何结构的视角影响,展示了其对上下文信息和物理规则的理解。
DriveDreamer也致力于驾驶场景生成,与GAIA-1不同之处在于它是在nuScenes数据集上训练的。它的模型输入包括高清地图和3D盒子等元素,可以更精确地控制驾驶场景的生成和更深入的理解,从而提高视频生成质量。此外,DriveDreamer可以生成未来的驾驶行为和相应的预测场景,帮助决策。
ADriver-I采用当前视频帧和历史视觉-动作对作为多模式大语言模型(MLLM)和视频潜在扩散模型(VDM)的输入。MLLM以自回归方式输出控制信号,其用作VDM预测后续视频输出的提示。通过连续的预测周期,ADriver-I在预测世界中实现了无限驱动。
从大型语言模型的成功中汲取灵感,WorldDreamer将世界建模视为一种无监督的视觉序列建模挑战。它利用STPT将注意力集中在时空窗口内的局部补丁上。这种关注促进了视觉信号的动态学习,并加速了训练过程的收敛。尽管World Dreamer是一款通用的视频生成模型,但它在生成自动驾驶视频方面表现出了非凡的性能。
除了视觉信息,驾驶场景还包括过多的关键物理数据。MUVO利用世界模型框架预测和生成驾驶场景,集成激光雷达点云和视觉输入,预测未来驾驶场景的视频、点云和3D占用网格。这种全面的方法大大提高了预测和产生结果的质量。特别地,结果3D占用网格可以直接应用于下游任务。更进一步,OccWorld和Think2Drive直接利用3D占用信息作为系统输入,预测周围环境的演变,并规划自动驾驶汽车的行动。
规划和控制
除了场景生成,世界模型还有助于在驾驶环境中进行学习、评估潜在的未来以及完善规划和控制策略。例如,基于模型的模仿学习(MILE)采用基于模型的模拟学习方法,从离线数据集中联合学习CARLA中的动力学模型和驾驶行为。MILE采用“广义推理算法”对未来驾驶环境进行理性和可视化的想象和预测,利用想象来补偿缺失的感知信息。这种能力能够规划未来的行动,允许自动驾驶汽车在没有高清地图的情况下运行。在CARLA模拟器中未经经验验证的测试场景中,MILE显著优于最先进的车型,将驾驶分数从46提高到61(相比之下,专家数据分数为88)。MILE的特点是长期和高度多样化的未来预测。MILE使用解码器对预测的未来状态进行解码,展示了在各种场景下的稳定驾驶。

SEM2在RSSM的基础上引入了语义masked世界模型,以提高端到端自动驾驶的采样效率和鲁棒性。作者认为,世界模型的潜在状态包含了太多与任务无关的信息,对采样效率和系统鲁棒性产生了不利影响。此外,由于训练数据不平衡,世界模型难以处理意外情况。为了解决这些问题,引入了签名过滤器来提取关键任务特征,并使用过滤后的特征重建语义掩码。对于数据不平衡,使用采样器来平衡数据分布。在CARLA中训练和测试后,SEM2的性能比DreamerV2有了显著提高。
考虑到大多数自动驾驶汽车通常都有多个摄像头,多视图建模也是世界模型的一个关键方面。Drive WM是第一个多视图世界模型,旨在增强端到端自动驾驶规划的安全性。Drive WM通过多视图和时间建模,联合生成多个视图的帧,然后从相邻视图预测中间视图,显著提高了多个视图之间的一致性。此外,Drive WM引入了一个简单的统一条件界面,灵活应用图像、动作、文本和其他条件,简化了条件生成过程。Drive WM在具有六个视图的nuScenes数据集上进行了训练和验证,通过对预测的候选轨迹进行采样并使用基于图像的奖励函数来选择最佳轨迹。在nuScenes数据集上,使用FID和FVD作为标准,Drive WM超过了所有其他当代方法,表明预测未来有助于自动驾驶的规划。此外,与GAIA-1一致,Drive WM在不可驾驶区域导航的能力展示了世界模型在处理领域外案例方面的理解和潜力。此外,从Alberto Elfes的开创性工作中汲取灵感,UniWorld引入了一种创新方法,利用多帧点云融合作为生成4D占用标签的基本事实。该方法考虑了来自多摄像机系统的图像中存在的时间-空间相关性。通过利用未标记的图像激光雷达对,UniWorld对世界模型进行预训练,显著增强了对环境动力学的理解。当在nuScenes数据集上进行测试时,与依赖单目预训练的方法相比,UniWorld在运动预测和语义场景完成等任务的IoU方面有了显著改进。
TrafficBots也是一种端到端的自动驾驶模型,它更加强调预测场景中个体代理的行为。TrafficBots以每个代理的目的地为条件,采用条件变分自动编码器(CVAE)来学习每个代理的不同个性,从而从BEV的角度促进行动预测。与其他方法相比,TrafficBots提供了更快的操作速度,并且可以扩展以容纳更多的代理。尽管TrafficBots的性能可能还无法与最先进的开环策略相媲美,但它展示了闭环策略在行动预测方面的潜力。
挑战和未来展望
世界模型在自动驾驶领域的进步提供了一个创新的前沿,有可能重新定义车辆的机动性。然而,这一充满希望的局面并非没有挑战。解决这些障碍和探索未来前景需要深入研究技术复杂性和更广泛的社会影响。
技术和计算挑战
1)长期可扩展内存集成:在自动驾驶领域,为世界模型注入反映人类认知过程复杂性的长期可扩展记忆仍然是一个艰巨的挑战。这些模型的有效性与其建筑基础有着内在的联系,而建筑基础目前在处理长期任务时面临着重大障碍。这些限制阻碍了模型长时间保留和有效访问信息的能力,这是在自动驾驶中遇到的复杂动态环境中导航的关键能力。当代模型正在努力解决梯度消失和灾难性遗忘等问题,这些问题严重限制了它们的长期记忆能力。尽管Transformer架构在通过自注意力机制方便访问历史数据方面取得了进步,但在处理长序列时,它们在可扩展性和速度方面遇到了障碍。以TRANSDREAMER和S4WM等研究为例的创新方法探索了旨在克服这些障碍的替代神经结构。值得注意的是,S4WM在高达500步的序列上保持高质量生成方面表现出了卓越的性能,显著超过了传统架构。然而,超过1000步后观察到的性能下降加剧了人工记忆系统和生物记忆系统能力之间的现有差距。
为了弥补这一差距,未来的研究工作可能会转向多管齐下的策略,包括增加网络容量、集成复杂的外部记忆模块以及探索迭代学习策略。这些努力不仅旨在扩展世界模型中记忆的时间范围,还旨在增强它们驾驭自动驾驶固有的复杂决策过程的能力。通过促进计算效率和内存可扩展性之间更深层次的协同作用,这些进步可以显著推动自动驾驶汽车的能力,使其能够以前所未有的精度和可靠性适应和响应现实世界驾驶环境不断变化的动态。
2)仿真到现实世界的泛化:仿真训练环境和现实世界条件的多方面性质之间的差异是自动驾驶技术发展的关键瓶颈。目前的模拟平台虽然先进,但在完美反映现实世界场景的不可预测性和可变性方面还不够。这种不一致表现为物理特性、传感器噪声和不可预见事件的发生方面的差异,严重破坏了仅在模拟环境中训练的世界模型的适用性。
开发能够从模拟到真实世界驾驶场景无缝概括的世界模型是至关重要的。这不仅需要改进模拟技术,以更准确地捕捉真实世界环境的微妙之处和不可预测性,还需要开发对模拟数据和真实世界数据之间的差异具有内在鲁棒性的模型。提高模拟的保真度,采用领域自适应技术,并利用真实世界的数据进行连续的模型细化,是实现更有效泛化的潜在途径。此外,先进的感官融合技术的集成和对新学习范式的探索,如元学习和来自不同数据源的强化学习,可以进一步使世界模型能够动态适应现实世界驾驶的复杂性。这些进步对于实现真正的自动驾驶系统至关重要,该系统能够以敏捷、准确和安全的方式应对现实世界环境带来的无数挑战。
道德和安全挑战
1)决策问责制:确保车辆自主决策框架内的问责制是最重要的伦理问题,因此必须开发具有无与伦比透明度的系统。引导自动驾驶汽车的算法固有的复杂性需要一种机制,该机制不仅有助于关键和常规场景中的决策,而且使这些系统能够阐明其决策的基本原理。这种透明度对于在最终用户、监管机构和广大公众之间建立和保持信任至关重要。
为了实现这一点,迫切需要将可解释的人工智能(XAI)原理直接集成到世界模型的开发中。XAI旨在使人工智能决策更容易被人类理解,为自动驾驶汽车所采取的行动提供清晰易懂的解释。这不仅涉及对决策过程的阐述,还涉及对影响这些决策的伦理、逻辑和实践考虑的全面描述。在自动驾驶系统中实施XAI需要一种多学科的方法,利用人工智能开发、道德、法律标准和用户体验设计的专业知识。这种合作努力对于确保自动驾驶汽车能够参与决策过程至关重要,这些决策过程不仅在技术上是合理的,而且在道德上是可辩护的和社会可接受的。
2)隐私和数据完整性:自动驾驶技术依赖于广泛的数据集进行操作和持续改进,这引起了人们对隐私和数据安全的高度关注。保护个人信息不受未经授权的访问和侵犯是一个至关重要的优先事项,需要一个强有力的数据道德处理和保护框架。
解决这些问题涉及一个多方面的战略,该战略超越了对现有隐私法规的遵守,如欧洲的《通用数据保护条例》(GDPR)。它需要建立严格的数据治理政策,规定数据的收集、处理、存储和共享。这些政策的设计应尽量减少数据暴露,并确保数据最小化原则,即只处理特定合法目的所需的数据。此外,部署先进的网络安全措施对于保护数据的完整性和机密性至关重要。这包括利用加密技术、安全数据存储解决方案和定期安全审计来识别和缓解潜在的漏洞。此外,提高用户对其数据的收集、使用和保护方式的透明度至关重要。这可以通过明确、可访问的隐私政策和机制来实现,这些政策和机制允许用户控制其个人信息,包括数据访问、更正和删除选项。
未来展望
1)连接人类直觉和人工智能精度一个开创性的视角是世界模型朝着促进自动驾驶汽车内认知协同驾驶框架的方向发展。与仅依赖预定义算法和传感器输入进行决策的传统自动驾驶系统不同,认知协同驾驶旨在将人类驾驶员细致入微、直观的决策能力与人工智能的准确性和可靠性相结合。通过利用先进的世界模型,车辆可以获得前所未有的环境意识和预测能力,反映人类的认知过程,如预期、直觉和驾驭复杂社会技术环境的能力。
这种集成使自动驾驶汽车不仅能对眼前的物理世界做出反应,还能理解和适应驾驶的社会和心理层面——解释手势、预测人类行为,并做出反映对人类规范和期望的更深入理解的决策。例如,配备认知协同驾驶功能的世界模型可以准确预测城市环境中的行人运动,在四向停车处导航社会驾驶惯例,或根据乘客的舒适度和反馈调整驾驶风格。
2)车辆与城市生态系统的协调另一个富有远见的视角涉及世界模型在将自动驾驶汽车转变为生态工程代理人方面的作用,通过有助于环境可持续性的适应性、响应性行为与城市生态系统协调。世界模型凭借其对复杂系统和动力学的深刻理解,可以使自动驾驶汽车优化路线和驾驶模式,不仅提高效率和安全性,还可以减少排放、减少拥堵和促进节能等对环境的影响。
设想一种场景,即世界模型使自动驾驶汽车车队能够根据实时环境条件、交通流量和城市基础设施状况动态调整其运营。这些车辆可以协同改变路线,以平衡整个城市的交通负荷,减少拥堵和城市热岛效应。他们可以优先考虑优化燃油效率和减少排放的路线和速度,甚至可以与智能城市基础设施对接,通过车辆到电网技术支持能源电网平衡。
结论
总之,这项调查深入研究了世界模型在自动驾驶领域的变革潜力,强调了它们通过增强预测、模拟和决策能力在推进车辆自主性方面的关键作用。尽管取得了重大进展,但长期内存集成、模拟到现实世界的泛化和道德考虑等挑战突显了在现实世界应用程序中部署这些模型的复杂性。应对这些挑战需要一种多学科的方法,将人工智能研究的进步与伦理框架和创新的计算解决方案相结合。展望未来,世界模型的发展不仅有望增强自动驾驶技术,还将重新定义我们与自动化系统的互动,这突出了跨领域持续研究和合作的必要性。当我们站在这一技术前沿的风口浪尖上时,我们必须以勤奋和远见应对道德影响和社会影响,确保自动驾驶技术的发展与更广泛的社会价值观和安全标准保持一致。
#激光雷达原理
全球汽车行业正在进行自动化变革,这将彻底改变交通运输的安全和效率水平。
戴姆勒在S级豪华车型中引入L3级自动驾驶(L3,在特定条件下自动驾驶,人类驾驶员一旦被请求就会随时接管)是自动驾驶革命的一个重大突破。其他多家汽车公司已经宣布即将推出这一功能,包括本田和宝马。使用LiDAR(光探测和测距)的3D成像是使之成为可能的关键传感技术。
在过去的8年里,LiDAR公司约50亿美元的投资的主要重点是用于乘车、卡车运输和物流的L4级自动驾驶(不需要人类司机的L4级)。由于技术、安全、监管和成本方面的考虑,实现L4/L5级自动驾驶能力已被证明比最初设想的更具挑战性。在许多情况下,这种能力的货币化的商业案例也被证明是不明确的。对于激光雷达公司来说,这是一个艰难的探索,因为时间跨度较长,而且主要的L4玩家正在开发他们的激光雷达(Waymo、Aurora、Argo)。
完全自动驾驶的目标市场:车辆的数量大大降低(<500万辆/年,而消费者的汽车使用约为1亿辆/年)。汽车原始设备制造商没有能力在完全自动驾驶市场上竞争,他们看到了在他们的汽车上增加有限的自动驾驶功能并向更大的客户群销售舒适、自由时间和安全的产品的机会。这使许多LiDAR公司转向解决L2和L3自动驾驶问题。最近宣布的公司包括法雷奥(奔驰)、Innoviz(宝马)、Luminar(沃尔沃)、Cepton(通用汽车)、Ibeo(长城汽车)和Innovusion(Nio)。与汽车一级供应商的合作关系也已经具体化(Aeye-Continental, Baraja-Veoneer, Cepton-Koito, Innoviz-Magna)。
范围和点密度(点/秒或PPS)是制约LiDAR提供的感知能力的关键性能参数。这些参数包括在足够的范围内对车道标记、交通基础设施、路面、行人、车辆和道路碎片进行探测和分类,以实现安全和舒适的自动操纵。虽然性能是至关重要的,但向消费类汽车的转移促使LiDAR公司也关注更多的 "普通 "特性,如价格、尺寸、功耗、车辆集成/造型、制造可扩展性和安全认证。
美国底特律Autosens的一个小组会议讨论了使消费类车辆能够负担得起LiDAR的价格(或痛苦)门槛。作为参考,汽车摄像头和毫米波雷达的价格分别在10-20美元和50-100美元之间,理想的是LiDAR将达到类似的价格点。这在可预见的未来是不合理的,有几个原因。首先,相机和毫米波雷达已经在消费汽车的ADAS(汽车驾驶辅助系统)方面有着几十年的技术积累和发展。其次,它们主要依赖于硅和CMOS技术,这些技术利用了消费和工业电子的规模。激光雷达没有那么成熟,它依赖于复杂的光学半导体技术(特别是激光器)。这个领域的供应链今天根本没有定位来支持这种定价。
使LiDAR的可接受门槛价格合理化的一种方法是将其与L3级自动驾驶车辆配置的价格联系起来。对于奔驰S级车来说,这个价格大约是5000美元。鉴于LiDAR使这一功能成为可能,有理由认为LiDAR可以获得500美元(或L3选项价格的10%)的价格点。随着中等价位的汽车开始提供这个配置,L3的价格将需要降低(约3000美元),而LiDAR的价格将降低到约300美元。只有当设计运行域(ODD)扩大(在速度、位置、天气等方面),并且在这个演变过程中没有发生重大安全事故时,才有可能出现广泛的客户接受。
其次,传感器集成必须在不影响消费者汽车的整体风格和情感吸引力的情况下进行。尺寸和功耗制约着传感器的集成位置和方式。传感器(尤其是LiDAR)所消耗的大部分功率被转化为热量。从效率、热管理和缩小尺寸的角度来看,尽量减少热量是有益的。
毫米波雷达传感器的体积为100-500立方厘米,消耗5-15W的功率(取决于性能)。照相机明显更小,更省电(通常在25-200立方厘米的范围内,耗电约3W)。汽车中的空间是宝贵的,随着L2级和L3级功能的发展,LiDAR需要与这些传统的传感器在空间、功率、计算资源和热管理方面进行竞争。
操作物理学、扫描方法和波长是驱动尺寸和功耗的关键因素。表1的主要结论如下。
④是最不紧凑的方法。1550nm ToF(飞行时间)操作需要高峰值功率的光纤激光器,它不像半导体二极管激光器那样紧凑。二维扫描和独立的发射/接收孔径也往往使LiDAR的体积更大。
①似乎是最紧凑的方法。FMCW/RMCW(频率/随机调制连续波)使用同调检测(将一部分发射光束与接收光束光学混合)。这允许使用与半导体光放大器集成的二极管激光器。光机械扫描发生在一个维度上(水平方向)。垂直扫描是通过可调谐激光器和类似棱镜的光学器件(没有移动部件)完成的。它还使用了一个单静止结构(通过一个光圈进行发射/接收)。
与905纳米(②)相比,1550纳米LiDAR(①和④)消耗更高的功率,但也提供更高的范围性能。较高的功率消耗是由多种因素造成的。首先,激光器被允许以更高的光功率驱动(1550纳米的眼睛安全阈值比905纳米的高得多)。其次,1550纳米的激光器效率较低,消耗更多的电功率。最后,由于温度敏感性较高,1550纳米激光器需要被冷却或温度稳定。这就消耗了电力。
LiDAR射程和PPS性能的世代改进(Innoviz和Valeo在②)增加了电力消耗。这是可以理解的,因为更高的性能需要更多的激光功率、占空比和空间频率。信号处理计算能力也会增加。在这些情况下,尺寸似乎与功耗的增加成正比。
相对于Flash LiDAR(③)提供的适度性能,它在尺寸和功耗方面是昂贵的。如果消除移动部件是一个关键的考虑因素(可靠性或集成度),那么使用电子扫描的架构就更有吸引力(③),因为它们在同等大小的情况下能提供明显更高的性能,并大大降低功耗。折衷的办法是,全局快门操作是不可能的,从而导致点云的模糊效应。
LiDAR在集成度、尺寸和功耗方面正在逐渐成熟。相对于毫米波雷达,它在尺寸和功耗方面仍然是~2-3倍大。成像相机甚至更紧凑、更省电(尺寸低10倍,功率低5倍)。
随着时间的推移,LiDAR是否会达到与这些其他传感器同等的水平?1550纳米的FMCW/RMCW LiDAR(①)一旦在硅光子学平台上实现了芯片级的二维光学扫描,就能提供与雷达同等尺寸的最佳潜力(这是目前积极研究的领域,但在实际中还不可行)。功耗不可能降低,因为基本的激光技术需要有重大的材料改进(在过去的三十年里,为了支持光纤通信,已经在这个领域进行了大量的投资,而且不太可能有巨大的改进)。功率消耗的主要部分是由激光器引起的,其中70%以上被转化为热量,需要加以管理。这反过来又对尺寸设定了一个下限。
要确保像LiDAR这样复杂的光机械传感器能够从原型到大批量生产的扩展,需要在设计的早期阶段考虑供应链和可制造性。在这方面,LiDAR公司和一级供应商(他们已经掌握了有效扩展到批量生产的流程和科学)之间的伙伴关系是非常宝贵的。
法雷奥公司设计和制造其LiDAR(SCALA系列)。在Autosens,他们提出了影响设计过程的考虑因素--技术选择、供应商、工艺简单性、成本、可靠性和可扩展性。周期时间和废品水平得到了严格的分析和验证。法雷奥的理念是推出满足当前汽车客户需求的 "适合功能 "的设计(最初可能在性能上不领先于竞争对手,但对客户来说是可靠和易于部署的),将这些设计投入批量生产,并将规模化和低成本的经验作为未来设计的性能升级的基础。迄今为止,已经生产了超过17万个汽车级LiDAR(跨越SCALA 1和2系列,SCALA 2目前是在前面讨论的奔驰S级中设计的)。SCALA 3利用这一经验,性能显著提高,将于2023年推出。法雷奥的方法与许多风险投资的LiDAR公司不同,这些公司最初往往专注于最大限度地提高性能,并假设一旦产量增加,规模和成本要求将得到解决。这是一个困难的主张。
希捷科技是一家大型的硬盘驱动器(HDD)制造商,每年生产超过1亿台。在Autosens会议上,他们介绍并演示了他们的LiDAR,这是一个1550纳米的系统,能够实现动态凹陷,120°视场,250米范围和25W的功耗。该公司首创了HAMR(热辅助磁记录),用于增加硬盘的存储容量。安装在记录头上的激光二极管被用来局部加热单个比特,以翻转磁极并协助写入过程。光学、精密机械、高速电子和扫描是关键的设计平台。硬盘制造线利用光学、机械和电子部件的精确定位(亚微米)和粘合,以及高产量的在线和最终测试。希捷公司的战略是利用其HDD产品的专利、相关技术块和制造基础设施,用于汽车LiDAR。在拥挤的LiDAR生态系统中,希捷公司可能不同于其他任何加入者。他们从现有的高产量、低成本的生产线开始,将类似复杂性的产品设计插入其中。他们可能在未来颠覆LiDAR市场。
Trioptics介绍了为汽车市场大批量制造LiDAR的一些制造设备挑战。光学、机械和电子元件的精确对准和粘合是高产量LiDAR制造的关键,同样也是在非常低的周期时间内校准和测试子组件和最终产品的能力。关键是要确保每一个子组件的设计和采购都有足够的精度水平和基准点,以便机器人自动化能够有效地发挥作用。Trioptics公司正在为LiDAR的生产建立商业化的设备,他们的主张与20年前基于光纤的通信系统的扩展类似。它催生了一个专门用于制造光电子元件的专业设备行业,包括预烧/测试、光纤对准/连接、芯片/导线粘接、密封和可靠性测试系统。
对传感器安全认证的两个关键标准的方法:ISO 26262功能安全标准和新兴的ISO 21448标准,涉及预期功能安全(SOTIF)。后者涉及一个特定的车辆功能在承诺的ODD中的表现。对于像LiDAR这样的新传感器,在不利的照明和天气条件下,将其转化为物体检测和分类(例如车辆、行人、障碍物和交通基础设施)是至关重要的。LiDAR供应商越来越关注这个新标准,尽管目前还不清楚这是否是由OEM或Tier 1承担的事情。
汽车LiDAR无疑已经到来。虽然L4自动驾驶市场还很遥远,但需要LiDAR的有限自动驾驶水平(L2和L3)提供了一个更有利可图的近期机会。设计的机会是有限的,对这些机会的竞争是残酷的。赢得这些机会将需要在性能、成本、可靠性和易于集成方面提供正确的平衡。
下文是TI关于激光雷达的介绍PPT欢迎大家关注,一起学习。
#自动驾驶热点方向
端到端自动驾驶
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
- Paper: https://arxiv.org/pdf/2312.03031.pdf
- Code: https://github.com/NVlabs/BEV-Planner
Visual Point Cloud Forecasting enables Scalable Autonomous Driving
- Paper: https://arxiv.org/pdf/2312.17655.pdf
- Code: https://github.com/OpenDriveLab/ViDAR
LLM Agent
ChatSim: Editable Scene Simulation for Autonomous Driving via LLM-Agent Collaboration
- Paper: https://arxiv.org/pdf/2402.05746.pdf
- Code: https://github.com/yifanlu0227/ChatSim
语义场景补全
Symphonize 3D Semantic Scene Completion with Contextual Instance Queries
- Paper: https://arxiv.org/pdf/2306.15670.pdf
- Code: https://github.com/hustvl/Symphonies
人工智能内容生成
Panacea: Panoramic and Controllable Video Generation for Autonomous Driving
- Paper: https://arxiv.org/pdf/2311.16813.pdf
- Code: https://github.com/wenyuqing/panacea
三维目标检测
PTT: Point-Trajectory Transformer for Efficient Temporal 3D Object Detection
- Paper: https://arxiv.org/pdf/2312.08371.pdf
- Code: https://github.com/KuanchihHuang/PTT
双目立体匹配
MoCha-Stereo: Motif Channel Attention Network for Stereo Matching
- Paper:
- Code: https://github.com/ZYangChen/MoCha-Stereo
协同感知
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
- Paper:
- Code: https://github.com/ryhnhao/RCooper
SLAM
SNI-SLAM: SemanticNeurallmplicit SLAM
- Paper: https://arxiv.org/pdf/2311.11016.pdf
Scene Flow Estimation
DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement
- Paper: https://arxiv.org/pdf/2311.17456.pdf
- Code: https://github.com/IRMVLab/DifFlow3D
Efficient Network
Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications
- Paper: https://arxiv.org/pdf/2401.06197.pdf
Segmentation
OMG-Seg: Is One Model Good Enough For All Segmentation?
- Paper: https://arxiv.org/pdf/2401.10229.pdf
- Code: https://github.com/lxtGH/OMG-Seg
#关于BEV车道线落地的点点滴滴
21年 埋下了一颗种子
看过BEV障碍物故事的同学应该清楚,我们组是在21年10月左右开始做BEV 障碍物的。那个时候不敢想着去做BEV 车道线,因为没有人力。但是我记得在12月左右的时候,我们面到了一个候选人,在面试的过程中听到他们做了差不多半年多的BEV 车道线,整个技术路线是通过高精地图来作为BEV 车道线网络的训练真值,并说效果还不错。很遗憾,那个候选人最后没有来我们这里。结合21年Telsa AI day 讲的车道线内容,一个要做BEV 车道线的种子就这样在组内埋下了。
22年 走对了第一步
整个22年,我们组内人力都是很紧张的,我记得在6,7月份的时候,我们刚好有人力去探索一下BEV 车道线。但是当时我们组只有一个同学(我们就先叫他小轩同学吧)有2个月的时间去做这件事。然后21年的那颗种子开始发芽了,我们准备先从数据下手,小轩同学还是很给力的(很有想象力,后续小轩同学也做了更多令大家惊喜的东西),差不多用了2月的时间,我们可以通过高速高精地图来提取对应的车周围的车道线数据。当时做出来的时候,我记得大家还是很激动的。

图1: 高精地图车道线 投影到图像系的效果
大家从图1上可以看出,贴合对还是有一些问题,因此小轩同学又做了系列的优化。2个月后,小轩同学去做其他任务了,现在回头看,我们的BEV 车道线探索之路,已经走对了第一步。因为在21年,22年已经逐步有很多优秀的BEV 车道线论文和代码相继开源。看到这里,你可能以为23年一定有一个完完美美的BEV 车道线落地的故事,然后理想往往都很丰满,现实却是很残酷。
23年 跌跌撞撞
由于我们BEV 障碍物已经证明BEV 这条路是可以走下去了,并且在路测也表现出了不错的效果。组内开始有了更多的资源来考虑车道线这件事,注意这里不是BEV了。为什么呢?因为在这个时候,我们面临了很大的上线压力,BEV 车道线又没有足够的经验,或者说整个组内做过2D 车道线量产的人都几乎没有。23年前半年,真的可以用跌跌撞撞来形容,我们内部激烈的讨论了很多次,最后决定形成2条线,一条线为2D 车道线: 大部分的人力在2D 车道线这条线上,重后处理,轻模型,通过2D 车道线这条线来积累车道线后处理量产经验。一条线为BEV 车道线:只有一小部分人力(其实就1-2个人力),注重BEV 车道线的模型设计, 积累模型经验。BEV 车道线的网络已经有很多了,我在这里贴2篇对我们影响比较大的论文供大家参考。《HDMapNet: An Online HD Map Construction and Evaluation Framework》 和 《MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction》
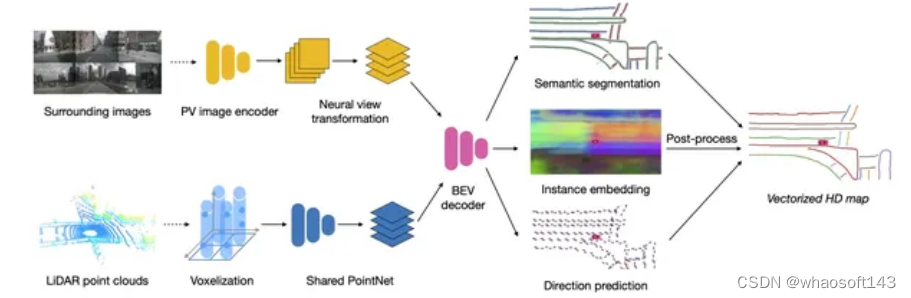
图2: HDMapNet
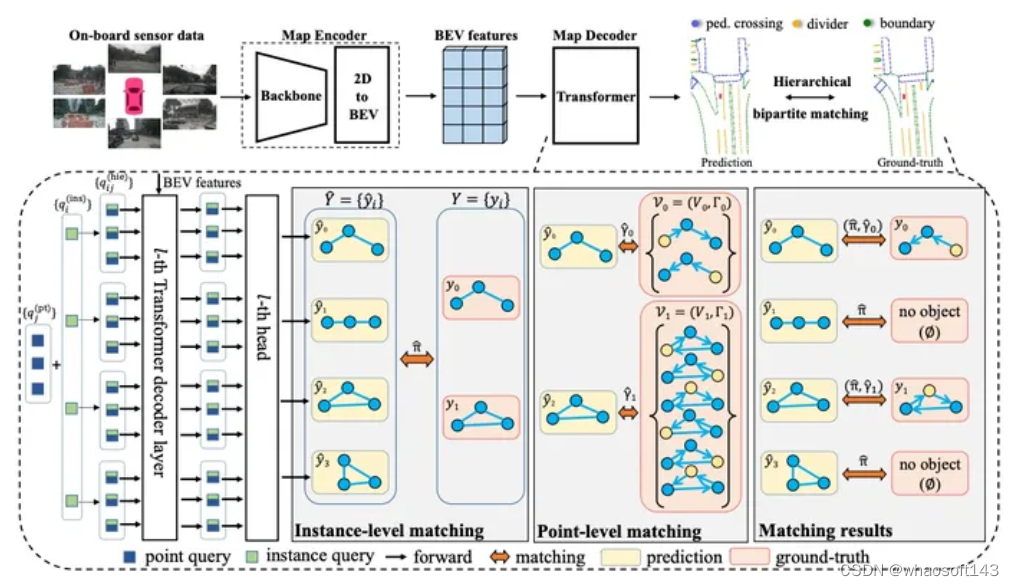
图3 MapTR
很幸运,在4,5月份的时候,我们在2D 车道线这条线积累了大量的车道线后处理量产经验,我们的BEV 车道线网络也设计出来了,在5月底,很快BEV 车道线顺利上车。在这里不得不说一下我们负责车道线后处理的大海同学,还是很给力的。然而当你觉得很顺利的时候,往往噩梦就要开始了。BEV 车道线部署后,控车效果不理想,这个时候大家陷入了自我怀疑阶段,到底是因为BEV 车道线3次样条曲线拟合的问题,还是下游参数没有适配好的问题。万幸的是,我们车上有供应商的效果,我们在路测时把供应商的车道线结果保存下来,然后在可视化工具里面在和我们的结果对比。当控车效果不好的时候,先证明我们自己的车道线质量是没有问题,这样驱动下游来适配我们的BEV车道线。一个月,整整一个月的时间,我们才稳定控车。我记得很清楚,我们还从上海跑到苏州,那天还是周六,大家在群里看到高速的控车效果都很激动。
然而一个故事往往都是一波三折的,我们只能利用高速高精地图来生产车道线数据。城市怎么办,还有那么多badcase 需要解决。这个时候重要人物终于要出现了,我们就先叫他小糖同学吧(我们数据组的大管家)。小糖同学他们利用点云重建来给我们重建出来重建clip(这个过程还是蛮痛苦,我记得那两个月是他们压力最大的时候,哈哈,当然我们和小糖同学经常相爱相杀,毕竟经常在开会时常常说又没有数据了。)。然后重建出来后怎么标注,放眼当时手里的供应商们,都没有这样的标注工具,别说什么标注经验了。又是和小糖同学他们一起,经历了漫长的1个月时间,标注工具终于和供应商打磨好了。(我们经常开玩笑说,我们这是在赋能整个自动驾驶的标注行业,这个过程是真痛苦,重建clip 加载是真慢 )。然而整个标注还是比较慢的,或者比较贵,这个时候小轩同学带着他的车道线预标注大模型闪亮登场(车道线预标注的大模型效果还是杠杠的),大家看他的眼神都在闪闪发光。这一套组合拳打下来,我们的车道线数据生产终于是磨合的差不多了。8月份的时候我们的BEV 车道线控车道线已经迭代的不错了,对于简单的高速领航功能。现在小轩同学在大模型预标注方向依旧不断的给我们带来更多的惊喜,我们和小糖同学依旧在相爱相杀中。
然而一个故事都不是这么容易结束,我们在9月份的时候,开始动手做多模态(Lidar,camera,Radar)多任务(车道线,障碍物,Occ)前融合模型,并后续支持城市领航功(NCP), 也就是所谓的重感知,轻地图的方案。基于BEV障碍物和BEV 车道线的经验前融合网络我们很快就部署上车了,应该是在9月底的时候。车道线也加了很多子任务,路面标识别,路口的拓扑等等。在这个过程中,我们对BEV 车道线的后处理进行了升级,抛弃了车道线3次样条曲线拟合,而采用点的跟踪方案,点的跟踪方案和我们的车道线模型的输出可以很好的结合在一起。这个过程也是一个痛苦的,我们连续2个月,每周开一次专项会,毕竟我们已经基于拟合的方案做的不错了,但是为了更高的上限,只能痛并快乐着。最终目前我们已经把基础的功能进行路测了。
稍微给大家解释一下图4,左边是车道线点跟踪的效果目前我们模型的感知范围只有前80米,大家可以看到车后也有一些点,这是跟踪留下的。右边是我们的建立的实时感知图,当然现在还在一个快速迭代的过程,还有很多问题正在解决中。
24年 新的开始
时刻,站在24年回看我们从21年到现在的一路成长和积累,很庆幸在21年那个点,有机会去做BEV, 也很庆幸有一群志同相合的小伙伴一路相辅相成。24年,对我们来说,有很多东西需要去追寻,前融合模型的量产上线,数据方向的发力,时序模型的探索,端到端的畅想等等。
#开环端到端自动驾驶中自车状态是你所需要的一切吗?
原标题:Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
论文链接:https://arxiv.org/abs/2312.03031
代码链接:https://github.com/NVlabs/BEV-Planner
作者单位:南京大学 NVIDIA
论文思路:
端到端自动驾驶最近作为一个有前景的研究方向浮现出来,以全栈视角为目标寻求自动化。沿这条线,许多最新的工作遵循开环评估设置在 nuScenes 上研究规划行为。本文通过进行彻底的分析并揭示更多细节中的难题,更深入地探讨了这个问题。本文最初观察到,以相对简单的驾驶场景为特征的 nuScenes 数据集,导致在整合了自车状态(ego status)的端到端模型中感知信息的利用不足,例如自车的速度。这些模型倾向于主要依赖自车状态进行未来路径规划。除了数据集的局限性之外,本文还注意到当前的指标并不能全面评估规划质量,这导致从现有基准中得出的结论可能存在偏见。为了解决这个问题,本文引入了一个新的指标来评估预测的轨迹是否遵循道路。本文进一步提出了一个简单的基线,能够在不依赖感知标注的情况下达到有竞争力的结果。鉴于现有基准和指标的局限性,本文建议学术界重新评估相关的主流研究,并谨慎考虑持续追求最先进技术是否会产生令人信服的普遍结论。
主要贡献:
现有基于 nuScenes 的开环自动驾驶模型的规划性能受到自车状态(ego status) (速度、加速度、偏航角)的高度影响。当自车状态(ego status) 参与进来,模型最终预测的轨迹基本上由它主导,导致对感知信息的使用减少。
现有的规划指标未能完全捕捉到模型的真实性能。模型的评估结果在不同指标之间可能会有显著差异。本文主张采用更多样化和全面的指标,以防止模型在特定指标上实现局部最优,这可能会导致忽视其他安全隐患。
与在现有的 nuScenes 数据集上推动最先进性能相比,本文认为开发更合适的数据集和指标代表了一个更为关键和紧迫的挑战。
论文设计:
端到端自动驾驶旨在以全栈方式共同考虑感知和规划[1, 5, 32, 35]。一个基本的动机是将自动驾驶车辆(AV)的感知作为达成目的(规划)的手段来评估,而不是过度拟合某些感知度量标准。
与感知不同,规划通常更加开放式且难以量化[6, 7]。理想情况下,规划的开放式特性将支持闭环评估设置,在该设置中,其他代理可以对自车的行为做出反应,原始传感器数据也可以相应地变化。然而,到目前为止,在闭环模拟器中进行代理行为建模和真实世界数据模拟[8, 19]仍然是具有挑战性的未解决问题。因此,闭环评估不可避免地引入了与现实世界相当大的域差距(domain gaps)。
另一方面,开环评估旨在将人类驾驶视为真实情况,并将规划表述为模仿学习[13]。这种表述允许通过简单的日志回放,直接使用现实世界的数据集,避免了来自模拟的域差距(domain gaps)。它还提供了其他优势,例如能够在复杂和多样的交通场景中训练和验证模型,这些场景在模拟中经常难以高保真度生成[5]。因为这些好处,一个已经建立的研究领域集中于使用现实世界数据集的开环端到端自动驾驶[2, 12, 13, 16, 43]。
目前流行的端到端自动驾驶方法[12, 13, 16, 43]通常使用 nuScenes[2] 来进行其规划行为的开环评估。例如,UniAD[13] 研究了不同感知任务模块对最终规划行为的影响。然而,ADMLP[45] 最近指出,一个简单的MLP网络也能仅依靠自车状态(ego status) 信息,就实现最先进的规划结果。这激发了本文提出一个重要问题:
开环端到端自动驾驶是否只需要自车状态(ego status) 信息?
本文的答案是肯定的也是否定的,这考虑到了在当前基准测试中使用自车状态(ego status) 信息的利弊:
是。自车状态(ego status) 中的信息,如速度、加速度和偏航角,显然应有利于规划任务的执行。为了验证这一点,本文解决了AD-MLP的一个公开问题,并移除了历史轨迹真实值(GTs)的使用,以防止潜在的标签泄露。本文复现的模型,Ego-MLP(图1 a.2),仅依赖自车状态(ego status) ,并且在现有的L2距离和碰撞率指标方面与最先进方法不相上下。另一个观察结果是,只有现有的方法[13, 16, 43],将自车状态(ego status) 信息纳入规划模块中,才能获得与 Ego-MLP 相当的结果。尽管这些方法采用了额外的感知信息(追踪、高清地图等),但它们并未显示出比 Ego-MLP 更优越。这些观察结果验证了自车状态(ego status) 在端到端自动驾驶开环评估中的主导作用。
不是。很明显,作为一个安全至关重要的应用,自动驾驶在决策时不应该仅仅依赖于自车状态(ego status) 。那么,为什么仅使用自车状态(ego status) 就能达到最先进规划结果的现象会发生呢?为了回答这个问题,本文提出了一套全面的分析,涵盖了现有的开环端到端自动驾驶方法。本文识别了现有研究中的主要缺陷,包括与数据集、评估指标和具体模型实现相关的方面。本文在本节的其余部分列举并详细说明了这些缺陷:
数据集不平衡。NuScenes 是一个常用的开环评估任务的基准[11–13, 16, 17, 43]。然而,本文的分析显示,73.9%的 nuScenes 数据涉及直线行驶的场景,如图2所示轨迹分布反映的那样。对于这些直线行驶的场景,大多数时候保持当前的速度、方向或转向率就足够了。因此,自车状态(ego status) 信息可以很容易地被作为一种捷径来适应规划任务,这导致了 Ego-MLP 在 nuScenes 上的强大性能。
现有的评估指标不全面。NuScenes 数据中剩余的26.1%涉及更具挑战性的驾驶场景,可能是规划行为更好的基准。然而,本文认为广泛使用的当前评估指标,如预测与规划真实值之间的L2距离以及自车与周围障碍物之间的碰撞率,并不能准确衡量模型规划行为的质量。通过可视化各种方法生成的众多预测轨迹,本文注意到一些高风险轨迹,如驶出道路可能在现有指标中不会受到严重惩罚。为了回应这一问题,本文引入了一种新的评估指标,用于计算预测轨迹与道路边界之间的交互率(interaction rate)。当专注于与道路边界的交汇率(intersection rates) 时,基准将经历一个实质性的转变。在这个新的评估指标下,Ego-MLP 倾向于预测出比 UniAD 更频繁偏离道路的轨迹。
自车状态(ego status)偏见与驾驶逻辑相矛盾。由于自车状态(ego status) 可能导致过拟合,本文进一步观察到一个有趣的现象。本文的实验结果表明,在某些情况下,从现有的端到端自动驾驶框架中完全移除视觉输入,并不会显著降低规划行为的质量。这与基本的驾驶逻辑相矛盾,因为感知被期望为规划提供有用的信息。例如,在 VAD [16] 中屏蔽所有摄像头输入会导致感知模块完全失效,但如果有自车状态(ego status) 的话,规划的退化却很小。然而,改变输入的自身速度可以显著影响最终预测的轨迹。
总之,本文推测,最近在端到端自动驾驶领域的努力及其在 nuScenes 上的最先进成绩很可能是由于过度依赖自车状态(ego status) ,再加上简单驾驶场景的主导地位所造成的。此外,当前的评估指标在全面评估模型预测轨迹的质量方面还不够。这些悬而未决的问题和不足可能低估了规划任务的潜在复杂性,并且造成了一种误导性的印象,那就是在开环端到端自动驾驶中,自车状态(ego status) 就是你所需要的一切。
当前开环端到端自动驾驶研究中自车状态(ego status) 的潜在干扰引出了另一个问题:是否可以通过从整个模型中移除自车状态(ego status) 来抵消这种影响?然而,值得注意的是,即使排除了自车状态(ego status) 的影响,基于 nuScenes 数据集的开环自动驾驶研究的可靠性仍然存疑。
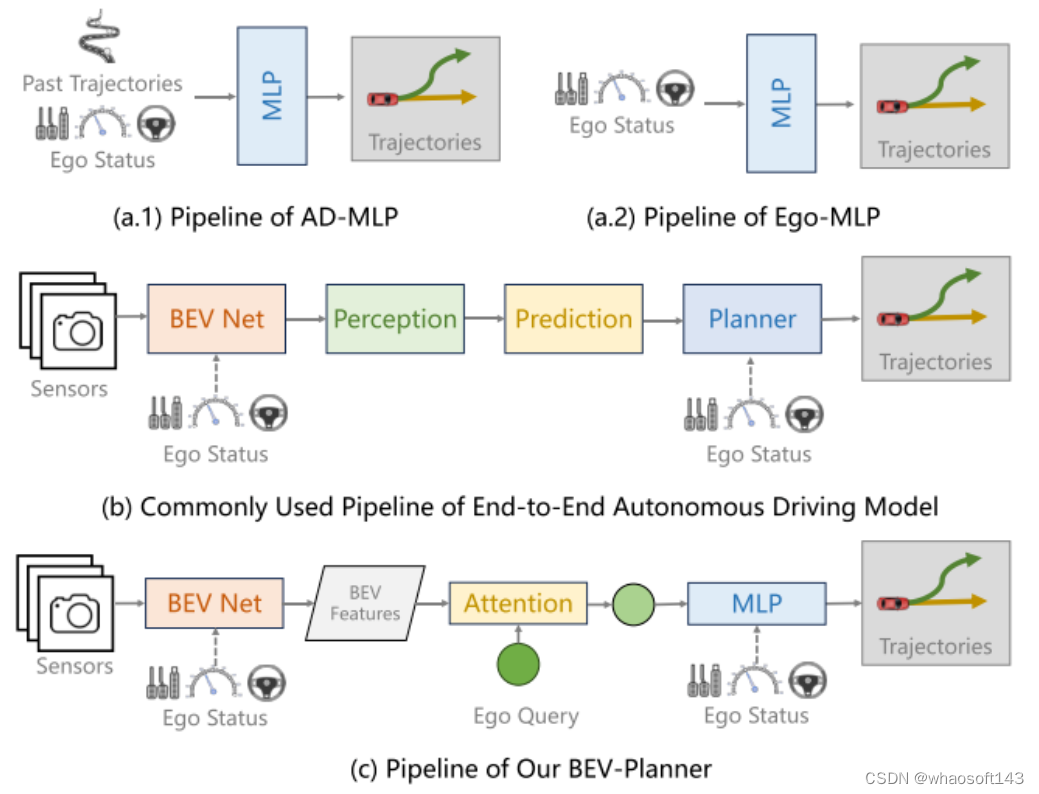
图1。(a) AD-MLP 同时使用自车状态(ego status) 和过去轨迹的真实值作为输入。本文复现的版本(Ego-MLP)去掉了过去的轨迹。(b) 现有的端到端自动驾驶流程包括感知、预测和规划模块。自车状态(ego status) 可以集成到鸟瞰图(BEV)生成模块或规划模块中。(c) 本文设计了一个简单的基线以便与现有方法进行比较。这个简单的基线不利用感知或预测模块,而是直接基于 BEV 特征预测最终轨迹。
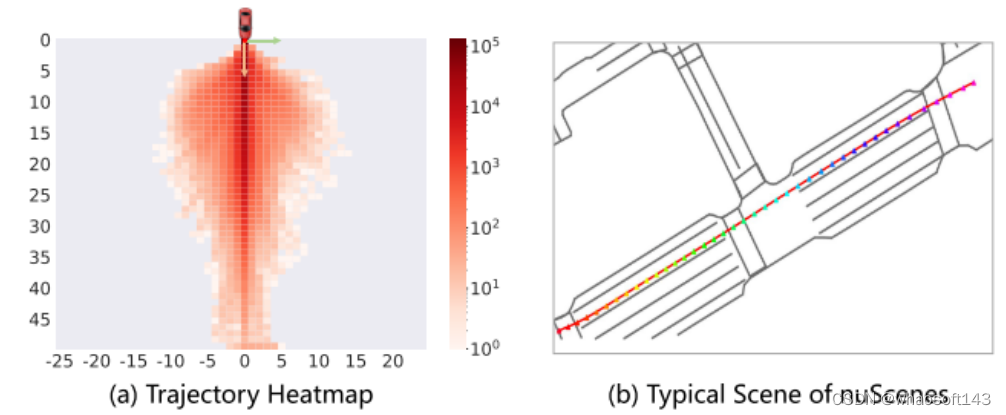
图2。(a) nuScenes 数据集中的自车轨迹热图。(b) nuScenes 数据集中的大多数场景由直行驾驶情况组成。

图3。当前方法[12, 13, 16]忽略了考虑自车的偏航角变化,始终保持0偏航角(由灰色车辆表示),从而导致假阴性(a)和假阳性(b)的碰撞检测事件增加。本文通过估计车辆轨迹的变化来估计车辆的偏航角(由红色车辆表示),以提高碰撞检测的准确性。

图4。本文展示了 VAD 模型(在其规划器中结合了自车状态(ego status) )在各种图像损坏情况下的预测轨迹。给定场景中的所有轨迹(跨越20秒)都在全局坐标系统中呈现。每个三角形标记代表自车的真实轨迹点,不同的颜色代表不同的时间步。值得注意的是,即使输入为空白图像,模型的预测轨迹仍保持合理性。然而,红色框内的轨迹是次优的,如图5中进一步阐述的。尽管对所有环视图像都进行了损坏处理,但为了便于可视化,只显示了初始时间步对应的前视图像。

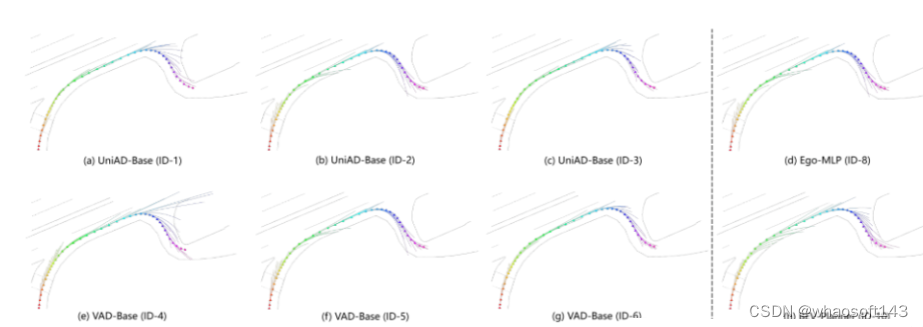
图5。在开环自动驾驶方法中,从自车的起始位置预测未来轨迹。在模仿学习范式内,预测轨迹理想情况下应该与实际的真实轨迹密切对齐。此外,连续时间步预测的轨迹应保持一致性,从而保证驾驶策略的连续性和平滑性。因此,图4 中红色框显示的预测轨迹不仅偏离了真实轨迹,而且在不同的时间戳上显示出显著的分歧。
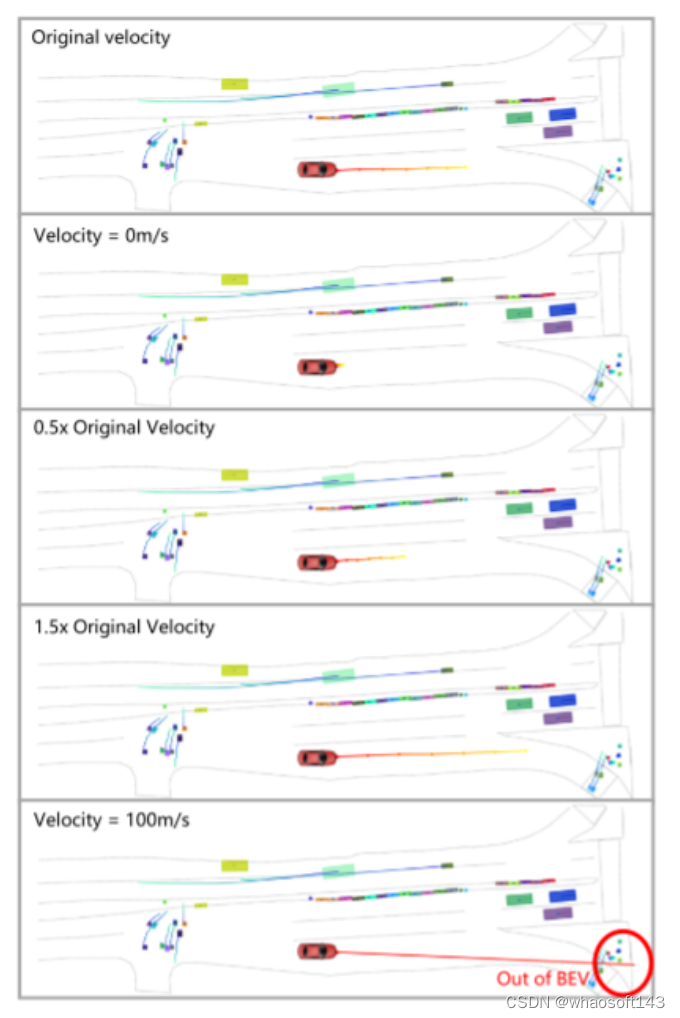
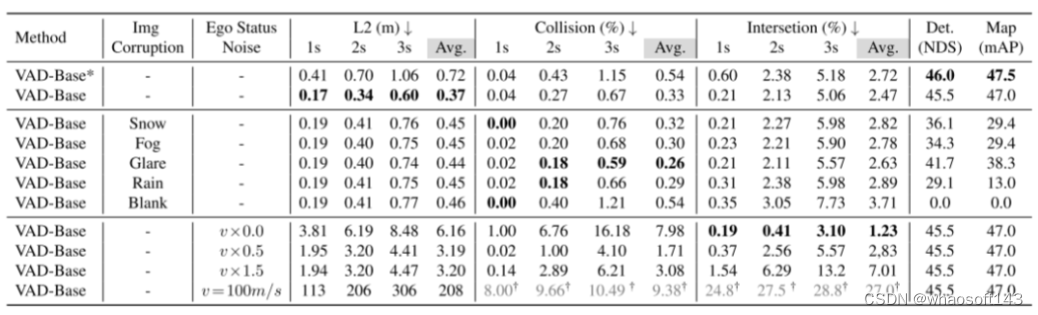
图6。对于在其规划器中结合了自车状态(ego status) 的基于VAD的模型,本文在视觉输入保持恒定的情况下,向自车速度引入噪声。值得注意的是,当自车的速度数据被扰动时,结果轨迹显示出显著的变化。将车辆的速度设置为零会导致静止的预测,而速度为100米/秒会导致预测出不切实际的轨迹。这表明,尽管感知模块继续提供准确的周围信息,模型的决策过程过分依赖于自车状态(ego status) 。
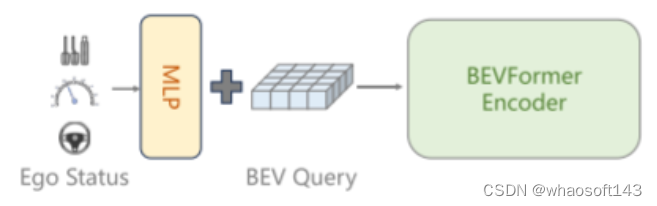
图7。BEVFormer在 BEV查询的初始化过程中结合了自车状态(ego status) 信息,这是当前端到端自动驾驶方法[13, 16, 43]未曾涉及的细节。
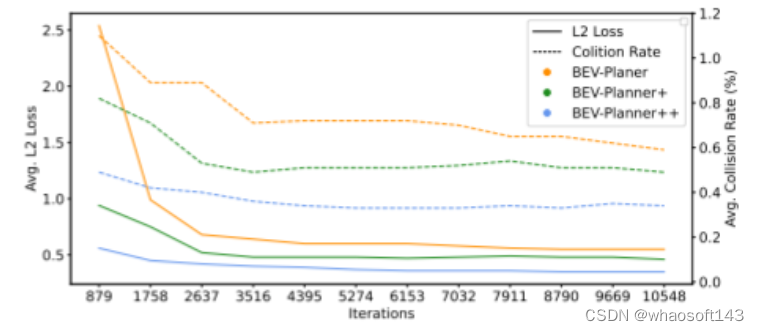
图8。在 BEV-Planner++ 中引入自车状态(ego status) 信息使得模型能够非常快速地收敛。
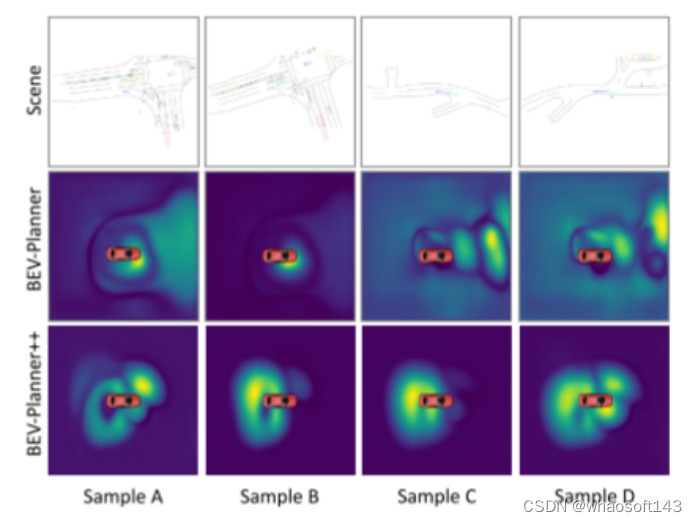
图9。比较本文基线的 BEV特征与相应的场景。
实验结果:





论文总结:
本文深入分析了当前开环端到端自动驾驶方法固有的缺点。本文的目标是贡献研究成果,促进端到端自动驾驶的逐步发展。