今天给大家介绍一个基于图像和文本的编辑的框架D-Edit,它是第一个可以通过掩码编辑实现图像编辑的项目,近期已经在HuggingFace开放使用,并一度冲到了热门项目Top5。
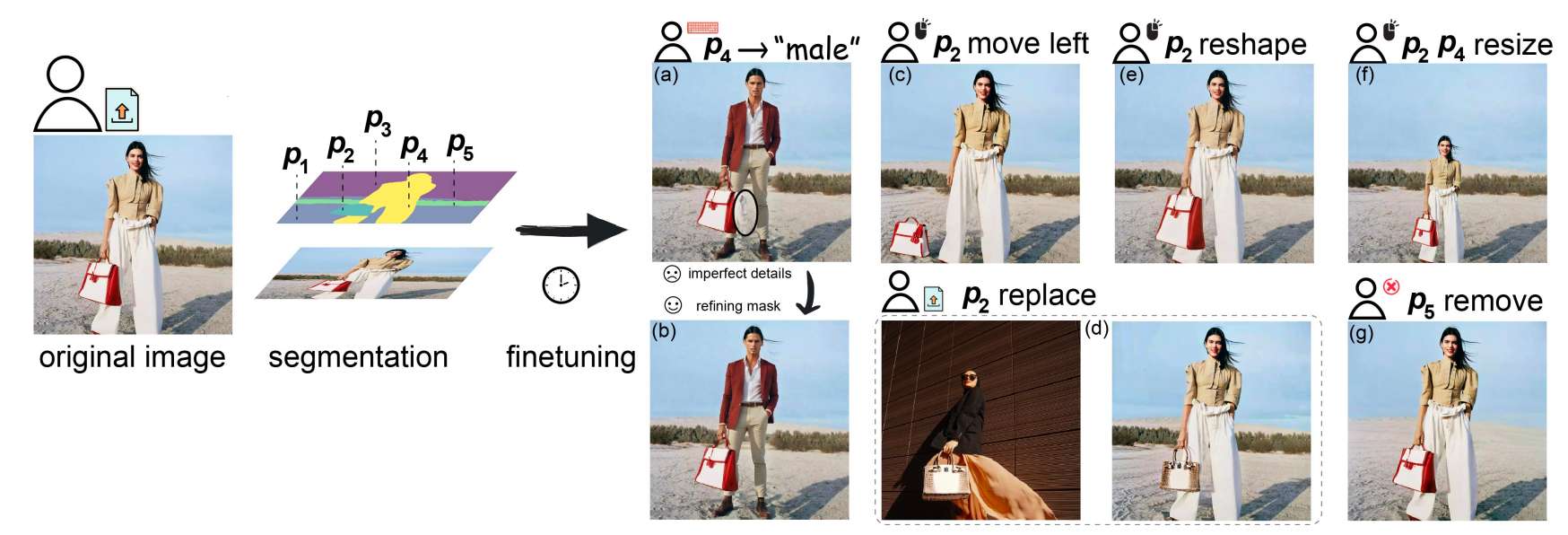
使用 D-Edit 的编辑流程。用户首先上传一张分割成多个项目的图像。微调 DPM 后,用户可以进行各种类型的控制,包括
(a) 使用文本提示替换模型;
(b) 细化分割造成的不完美细节;
(c) 将包移到地面;
(d) 将手提包替换为参考图另一个手提包;
(e) 重塑手提包;
(f) 调整模型和手提包的大小;
(g) 去除背景。
相关链接
论文地址:https://arxiv.org/pdf/2403.04880
代码链接:https://github.com/collovlabs/d-edit
试用地址:https://huggingface.co/spaces/Collov-Labs/d-edit
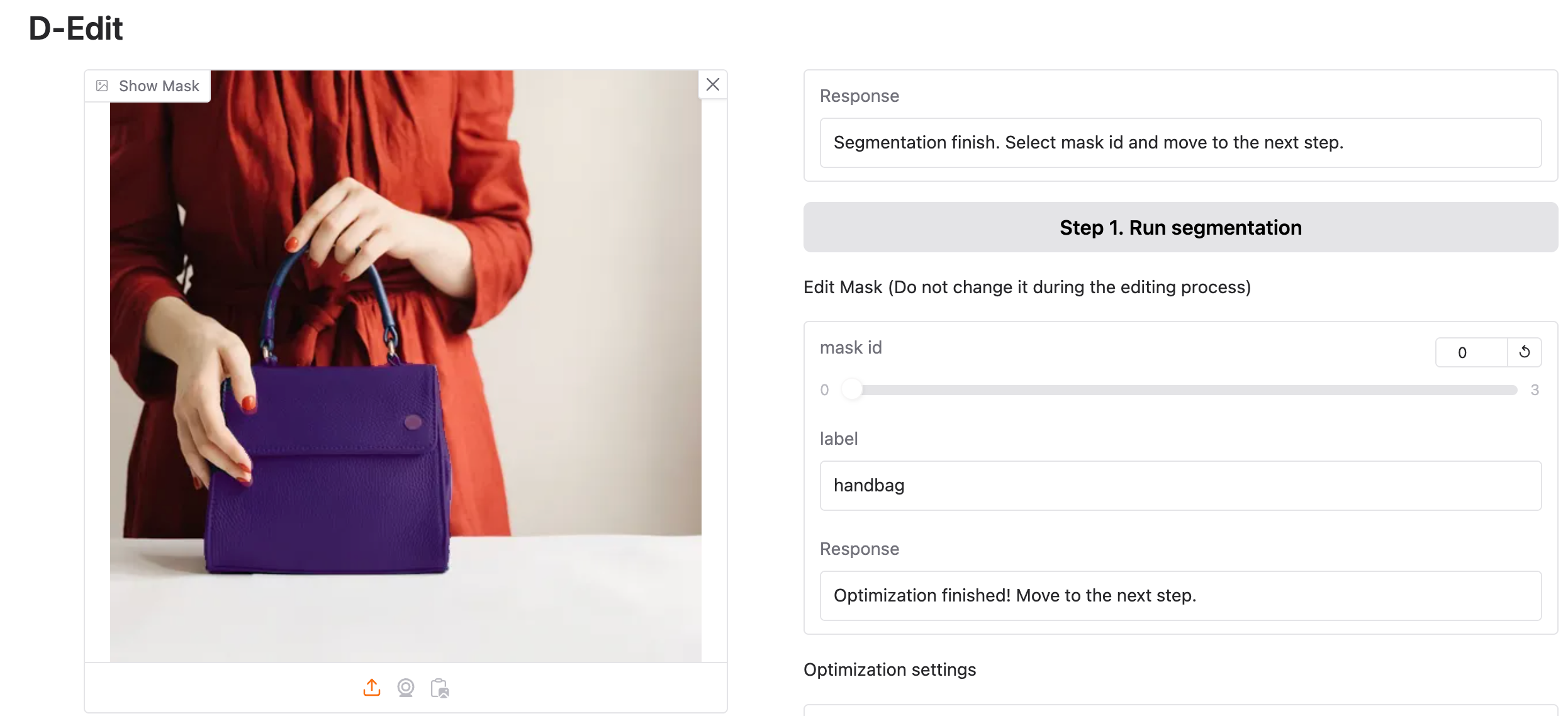
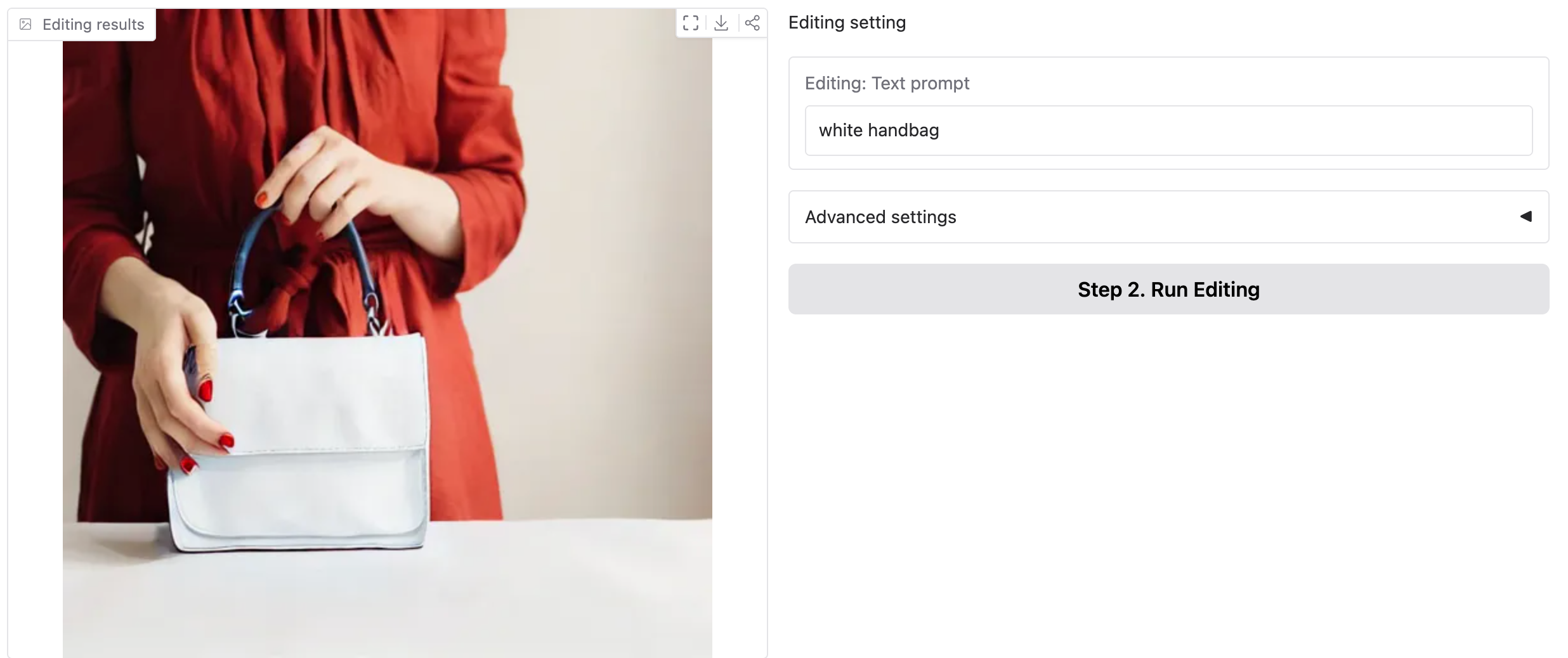
论文介绍

基于文本到图像扩散模型 (DPM) 的成功,图像编辑是实现人类与 AI 生成内容交互的重要应用。在各种编辑方法中,提示空间内的编辑因其容量大和控制语义的简单性而受到更多关注。然而,由于扩散模型通常是在描述性文本标题上进行预训练的,直接编辑文本提示中的单词通常会导致完全不同的生成图像,违反了图像编辑的要求。另一方面,现有的编辑方法通常考虑引入空间掩码来保留未编辑区域的身份,而这些区域通常会被 DPM 忽略,因此导致不和谐的编辑结果。
针对这两个挑战,在这项工作中,我们建议将综合图像提示交互分解为几个项目提示交互,每个项目都链接到一个特殊的学习提示。由此产生的框架名为 D-Edit,基于预训练的扩散模型,交叉注意层已解开,并采用两步优化来构建项目提示关联。然后,可以通过操作相应的提示将多功能图像编辑应用于特定项目。我们展示了四种编辑操作的最新结果,包括基于图像、基于文本、基于掩码的编辑和项目删除,涵盖了大多数类型的编辑应用程序,所有这些都在一个统一的框架内。值得注意的是,D-Edit 是第一个可以 (1) 通过掩码编辑实现项目编辑和 (2) 结合基于图像和文本的编辑的框架。我们通过定性和定量评估展示了各种图像集合的编辑结果的质量和多功能性。
方法
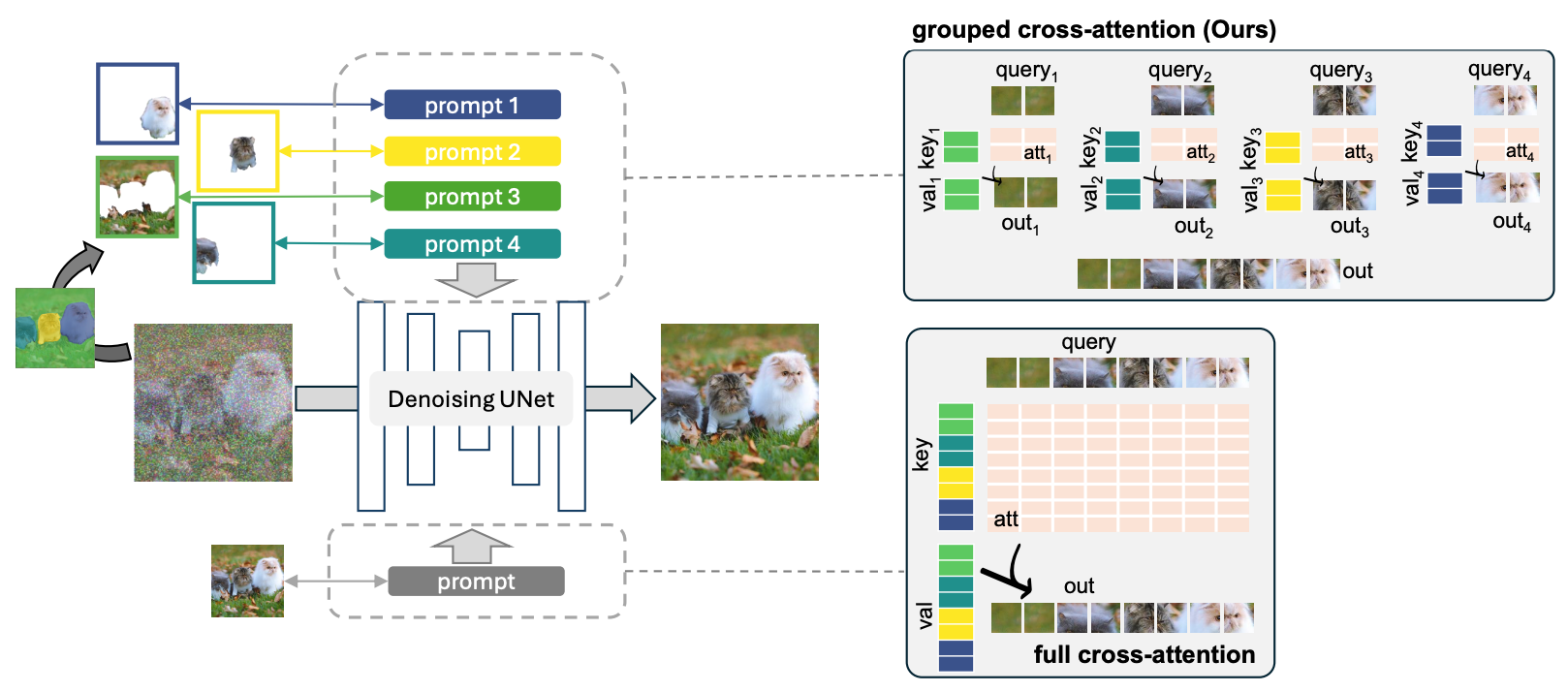
传统全交叉注意和分组交叉注意的比较。查询、键和值显示为一维向量。对于分组交叉注意,每个项目(对应于某些像素/块)仅关注分配给它的 文本提示(两个标记)。
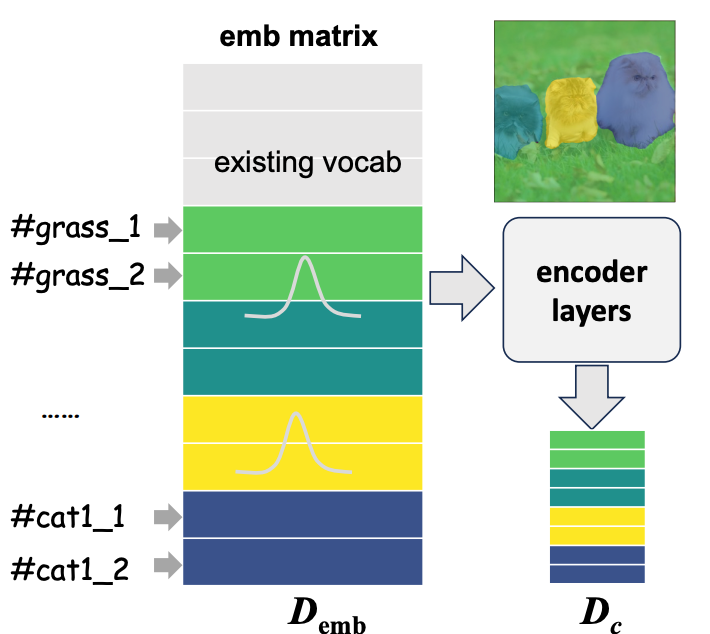
嵌入层在文本编码器。新令牌 插入随机初始化。

不同类型的图像所需的操作 编辑。每个彩色道具都有一个独特的提示符p。
实验

文本引导编辑。D-Edit允许选择 任何项目分割和编辑使用文本提示。


图像引导编辑的定性比较。在项目替换和面部交换方面,D-Edit 与 Anydoor、Paint-by-Example 和 TF-ICON 进行了比较。

图像引导编辑:图像中的任何项目都可以被来自相同或不同图像的另一个项目所替换
结论
这项工作提出了基于扩散模型的多功能图像编辑框架 D-Edit。D-Edit 将给定图像分割成多个项目,每个项目都分配有一个提示来控制其在提示空间中的表示。图像提示交叉注意力被解开为一组项目提示交互。通过调整扩散模型来建立项目提示关联,该模型学习使用给定的一组项目提示来重建原始图像。定性和定量评估展示了在收集的各种图像中编辑结果的质量和多功能性。











![单神经元建模:基于电导的模型[神经元结构、静息电位和等效电路]](https://i-blog.csdnimg.cn/direct/45d5aac417314dbbba626d94d2e6d6fb.png)




