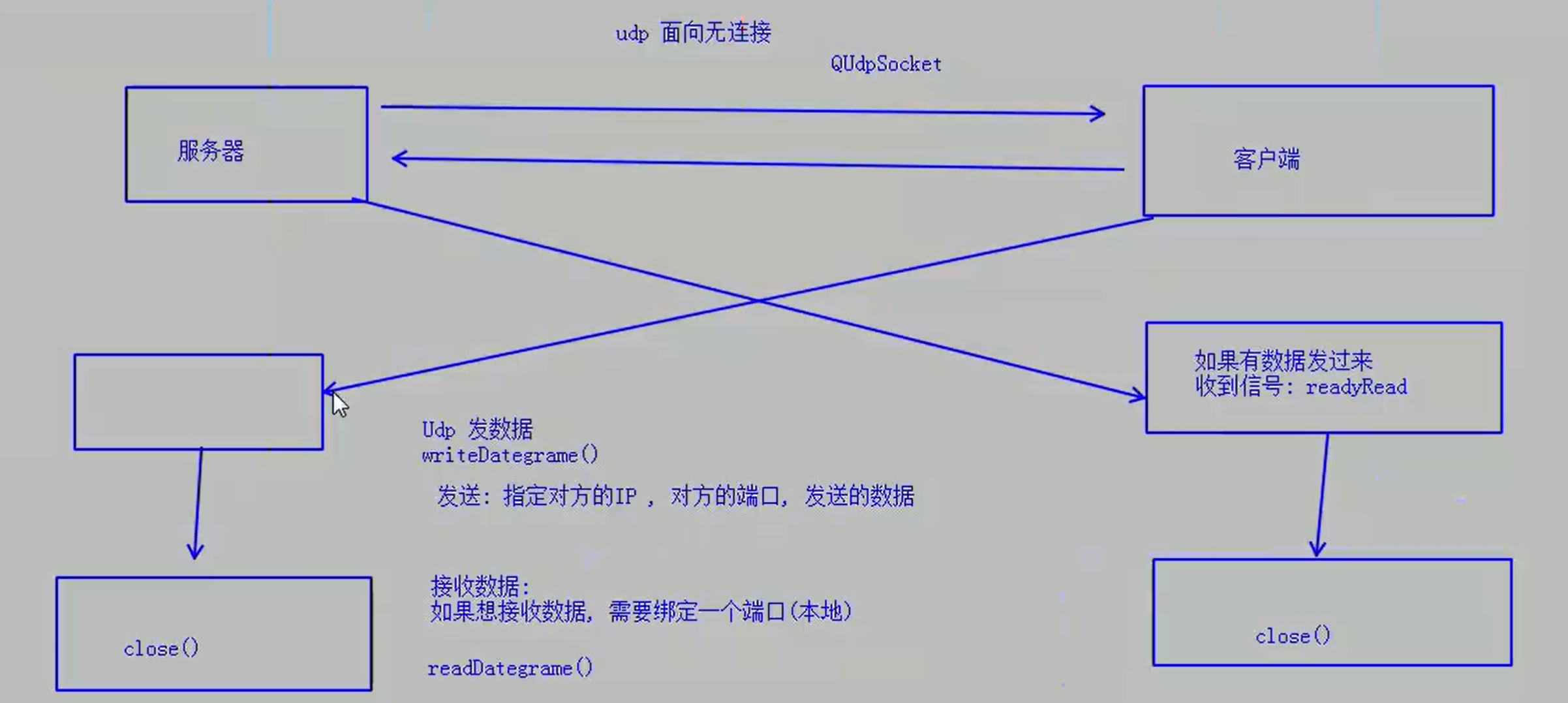
为什么要有原码 反码 补码的概念?
因为在计算机中最终只能识别机器码,是以 0000 0000 二进制作为表示形式,对于一个数,计算机要使用一定的编码方式进行存储,原码 反码 补码是机器存储一个数值的编码方式,最终,在计算机里都是以补码的形式来存储数据的。而且,计算机基本都只支持加法,例如: 1-1 ----> 在计算机中计算时实际上是:1 + -1,下面我们来看看这个过程。
原码 反码 补码:
原码 : 是人分析的码,给人看的 ---> 将一个数转为二进制形式,用最高位表示正负。
反码 : 构建原码和补码的桥梁 ---> 在原码的基础上,符号位不变,其他位取反
补码 : 是机器码,用来机器存储的 ---> 在反码的基础上 +1(符号位参与运算符,正数的补码就是原码)
任何的数值,都会有拥有其对应的二进制格式
正数: 1 ---> 0| 000 0000 0000 0001
2 ---> 0| 000 0000 0000 0010
3 ---> 0| 000 0000 0000 0010
负数: -1 ---> 1| 000 0000 0000 0001 --->最高位:1 --> 因为第一位是符号位,表示数值的正负,这里是:负数
或者,有另外一种术语:*将带符号位的机器数对应的真正数值*称为*机器数的真值*。
0000 0001 的真值= +000 0001 = +1
1000 0001 的真值= -000 0001 = -1
所以,8位二进制数的取值范围为:[ 1111 1111,0 ] ~ [ 0,0111 1111 ] ---> [ -127,127 ] ---> -2^7 ~ +2^7(首位是符号位,不参与实际的数据存储)实际一个自己的取值范围:[ -128,127 ] 为什么负数的取值区间多了一位呢?后面解释,慢慢来
原码是最容易理解和计算的表示方式。因为它正如字面意义,以二进制的形式表示数值的大小。
那么,为什么不直接使用原码就够了呢?还需要反码、补码这么麻烦。
这是因为,如果只使用原码进行计算会出现一些问题。例如计算:1-1=0,会变成什么样子呢?

这样的计算结果是错误的。所以,我们需要引入其他的编码方式:反码:在原码的基础上,符号位不变,其他位取反 —> (正数的反码不变,只改变负数)

因此,用反码计算,结果为 -0,而 0 没有正负之分。所以,这个结果不可取。所以,我们还需要引入其他的编码方式:补码:在反码的基础上 +1(符号位参与运算符,正数的补码就是原码)

补码的计算结果溢出了,最终为 1 0000 0000,由于八个位的存储空间有限,溢出的部分不可装进来了。最终,补码的计算结果为:1 + -1 = 0;这个计算结果才是正确的。所以,整数在计算机中,都是以补码的形式进行存储的。

上述问题:为什么一个字节的取值范围是 [ -128,127 ],而不是 [ -127,127 ]呢?
因为,反码中有一个 -0,数据中 0 就是 0,没有 +0 和 -0 的表示形式,因此,-0 被放在了最末一位存储了下来,规定了,用 -0 来表示 -128 占位,刚刚好,因此取值范围中 负数比正数多表示了一位。所以,一个字节的取值范围是:[ -128,127 ]
原码、反码、补码
正数:原=反=补 三码合一
负数:原码:二进制
反码:原码符号位不变,其他位置取反 (0变1 1变0)
补码:反码 + 1(符号位参与运算符,正数的补码就是原码)
因为计算机基本都只支持加法: ---> 所以计算机具有原码 反码 补码的概念
1 - 1 ---> 1 +(-1) 这个计算方式尤为重要,特别是在指针的运算过程中
例子:
int a = 3892;
1. 分析: 3892 为正数
原码 : 人为分析: 00000000 00000000 00001111 00110100
反码 : 正数的反码 = 原码 00000000 00000000 00001111 00110100
补码 : 正数的补码 = 反码 00000000 00000000 00001111 00110100
故 int a = 3892; 在 计算机中的 a 存储就是 补码: 00000000 00000000 00001111 00110100
int b = -666;
2. 分析: -666 为负数
原码 : 人为分析: 10000000 00000000 00000010 10011010
反码 : 正数符号位不变,其他取反 11111111 11111111 11111101 01100101
补码 : 反码 + 1 11111111 11111111 11111101 01100110
故 int b = -666; 在计算机中的 b 存储就是 补码: 11111111 11111111 11111101 01100110
我们都知道各种数据类型的取值范围:

我们这里拿 有符号短整型 和 无符号短整型 举例说明。众所周知,int 的存储空间为4个字节大小,short的存储空间为2个字节大小,有符号短整型 取值范围是:-32768~32767;无符号短整型 取值范围是:0~65535,这个取值范围是如何计算得出的呢?
按照 上述 原码 反码 补码 的运算方式,在内存中,定义 short a;

其他的数据类型的取值范围同理。
以上。
我是一个十分热爱技术的程序员,希望这篇文章能够对您有帮助,也希望认识更多热爱程序开发的小伙伴。
感谢!